SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
Abstract
3D scene understanding plays a vital role in vision-based autonomous driving. While most existing methods focus on 3D object detection, they have difficulty describing real-world objects of arbitrary shapes and infinite classes. Towards a more comprehensive perception of a 3D scene, in this paper, we propose a SurroundOcc method to predict the 3D occupancy with multi-camera images. We first extract multi-scale features for each image and adopt spatial 2D-3D attention to lift them to the 3D volume space. Then we apply 3D convolutions to progressively upsample the volume features and impose supervision on multiple levels. To obtain dense occupancy prediction, we design a pipeline to generate dense occupancy ground truth without expansive occupancy annotations. Specifically, we fuse multi-frame LiDAR scans of dynamic objects and static scenes separately. Then we adopt Poisson Reconstruction to fill the holes and voxelize the mesh to get dense occupancy labels. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our method. Code and dataset are available at https://github.com/weiyithu/SurroundOcc
Comments
- 网络可以根据周围的语义信息预测出被遮挡的区域,深度估计无法做到这一点
Q&A
1. 可以解决通用类别检测吗?
Semantic occupancy
3D scene reconstruction
如果只是预测占据的话,也许可以
2.2DTo3D 怎样做的
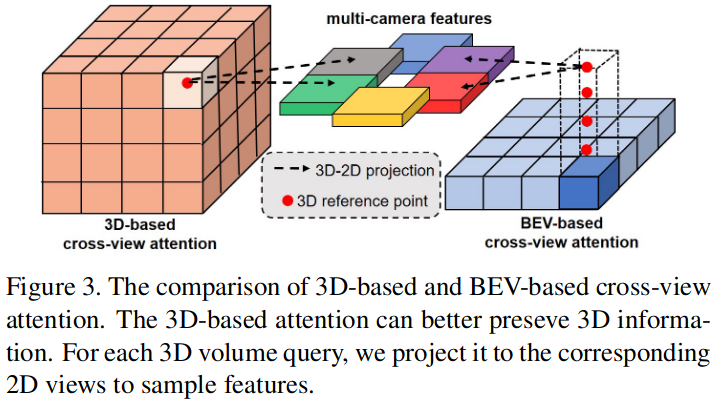
现有的 2DTo3D ,不同视角的图像对于最终得到的 3Dfeature 贡献是平等的,但这样是不合理的,因为在有些 3D 位置处,一些视角的图像是被严重遮挡的,为了解决这个问题,SurroundOcc 使用 cross-view attention 来融合多视角特征。
利用相机内外参将 3D reference points 投影到 2D, 使用 deformable attention 来 query points 并聚合信息。
与 BEV query 不同,使用 3D query 可以更好的保留立体信息,如上图所示,BEV query 是在每一个 BEV grid 中预设很多 3D reference points ,从 2D 中得到 feature 然后得到 grid-feature, 3D query 是在每一个 voxel 中设置 3D reference points ,得到 voxel-feature.
熟悉 Transformer 后再看

3. 怎样获取真值的?
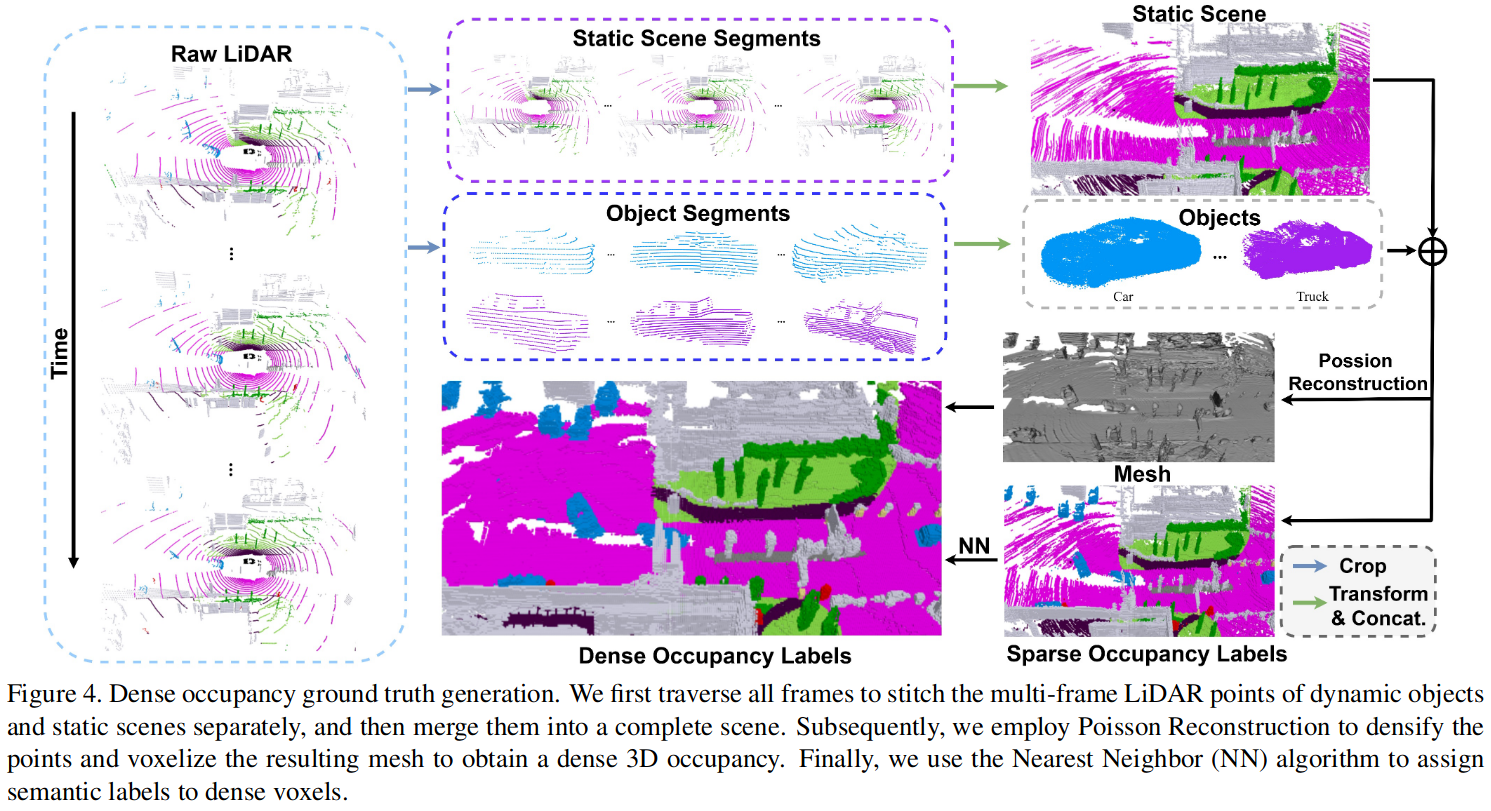
3.1 多帧拼接
- 对于每一帧点云,根据
3D object label的bbox把可移动的物体点云切出来,\(P=P_s+P_{move}\) - 便历场景中的每一帧,将静态点云和动态点云分别放在两个集合中,通过
ego_pose和标定参数,将它们的坐标转换到全局坐标系下,得到静态场景和动态目标点云结合:\(P_{ss}=\{P_{ss}^1,P_{ss}^2,...,P_{ss}^n\}\) 和 \(P_{os}=\{P_{os}^1,P_{os}^2,...,P_{os}^m\}\) n 表示帧数,m 表示动态障碍物个数 - 静态点云可以直接拼在一起,动态障碍物根据标注 id 将点云拼接在一起
- 根据当前帧的
ego_pose将拼接好的静态点云转移到当前帧,动态障碍物根据 id 使用拼接好的点云替代
3.2 使用泊松重建致密化
尽管 3.1 得到的真值已经很致密了,但由于 lidar 的扫描特性,难免有空洞,并且数据分布不均匀。为了解决这个问题:
- 在局部邻域内,根据空间分布计算法向量
- 将带有法向量的点云 \(P\) 输入泊松表面重建,得到三角形网格 \(M\),这样会填充 \(P\) 中的空洞并且数据分布均匀
- 将 \(M\) 转换成致密的体素 \(V_d\)
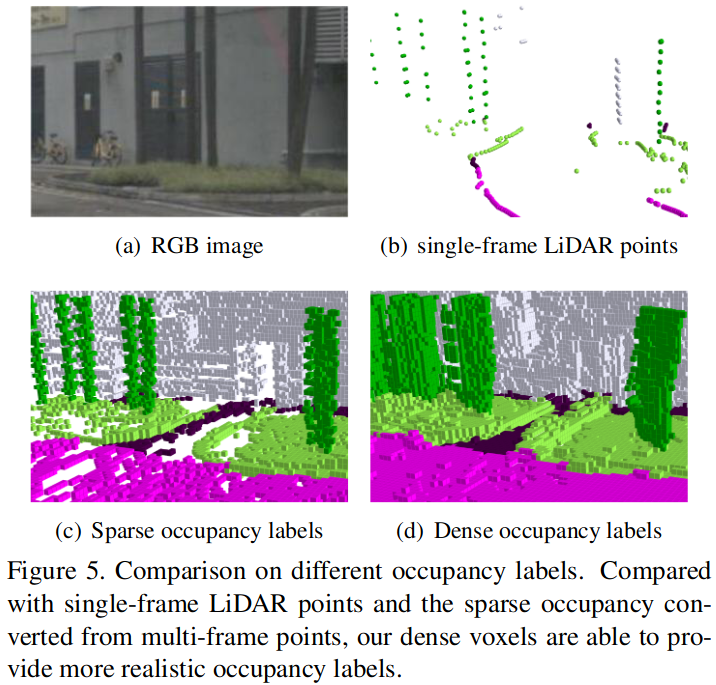
Figure 4 中的结果还是有空洞
障碍物会被膨胀吗?
3.3 使用最近邻算法打语义标签
- 将带有语义标签的点云 \(P\) 体素化得到 \(V_s\)
- 便历 \(V_d\) 中每一个被占据的
voxel_d_i, 使用最近邻搜索(NN)找到 \(V_s\) 中最近的voxel_s_i,将其 label 赋给voxel_d_i
NN 受到标注噪声影响比较大
4. 怎样训练的?
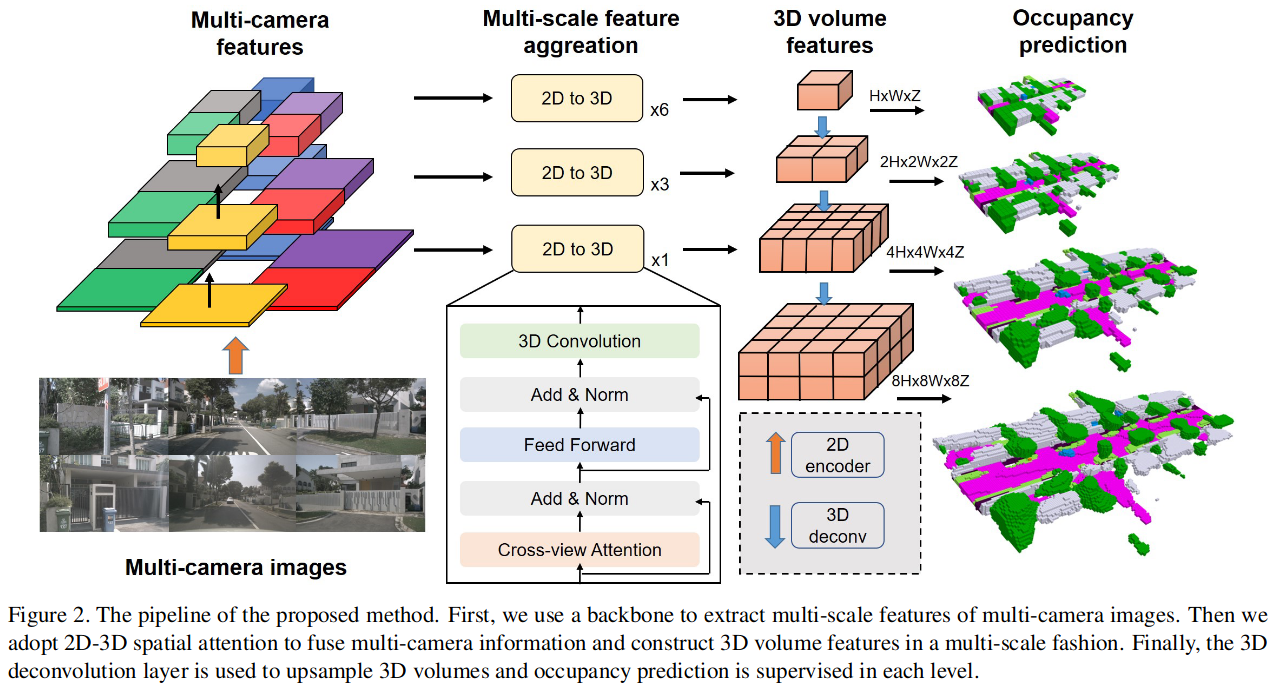
- 输入多视角 \(N\) 图片,首先经过一个 backbone 提取 \(M\) 层多尺度 feature \(X=\{\{X_i^j \}_{i=1}^N \}_{j=1}^M\)
- 对于每一个尺度的多视角特征,使用
spatial cross attention融合多视角特征,得到一个 3D 的立体特征,而不是一个 BEV 特征,最终得到多尺度的3D volume feature\(\{F_j\in R^{C_j\times H_j\times W_j\times Z_j}\}_{j=1}^M\) - 使用 3D 卷积对立体特征进行上采样并将多尺度的特征拼接在一起(类似 FPN), 使用
3D deconvolution上采样 \(j-1\) 层的3D feature\(Y_{j-1}\),并将其和 \(j\) 层特征融合得到第 \(j\) 层的3D volum features:
- 不同 level 的
3D volum feature预测不同分辨率的占据结果 \(V_j=R^{C_j\times H_j\times W_j\times Z_j}\) - 每个级别的占用预测由生成的密集占用 gt 来监督, 损失函数:交叉熵和场景类亲和力损失,每一层占总损失比重不一样,分辨率越小占比越大,\(\alpha_j=\frac{1}{2^j}\)
Pipeline