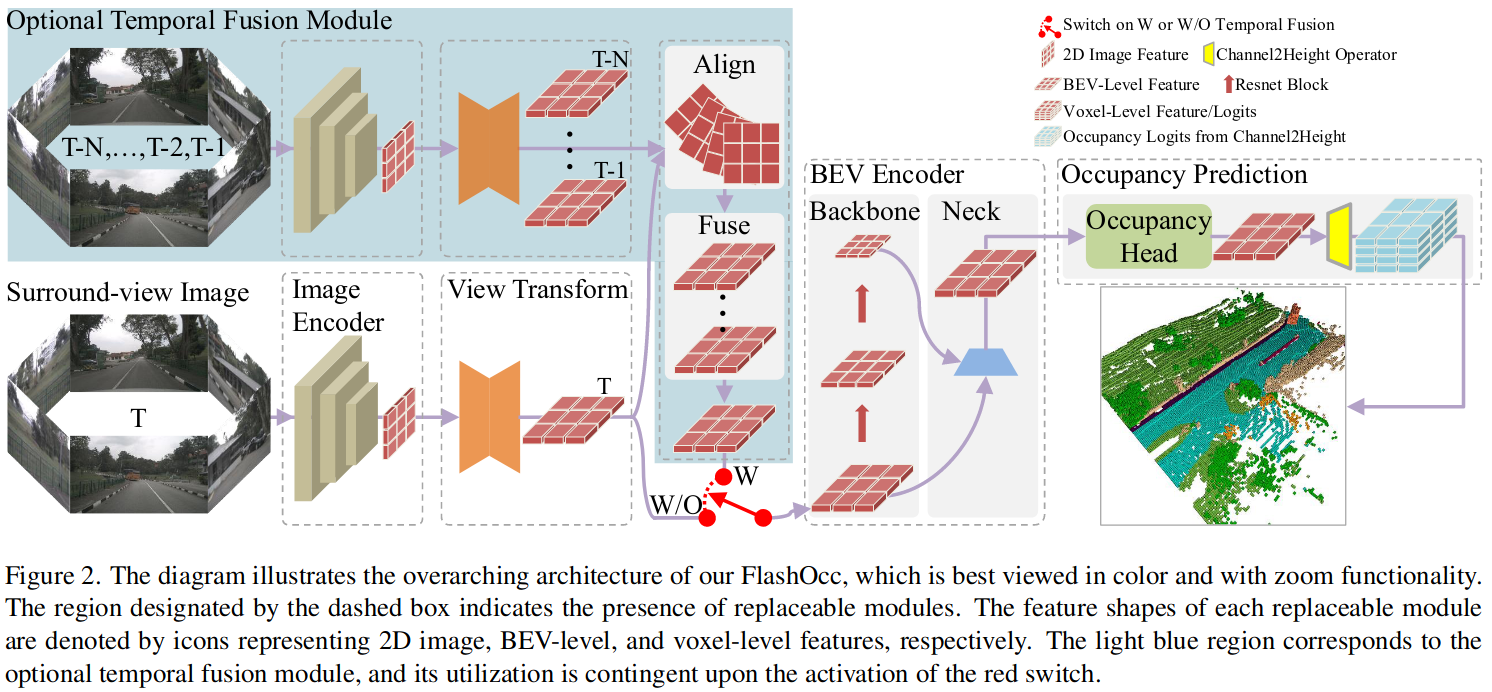
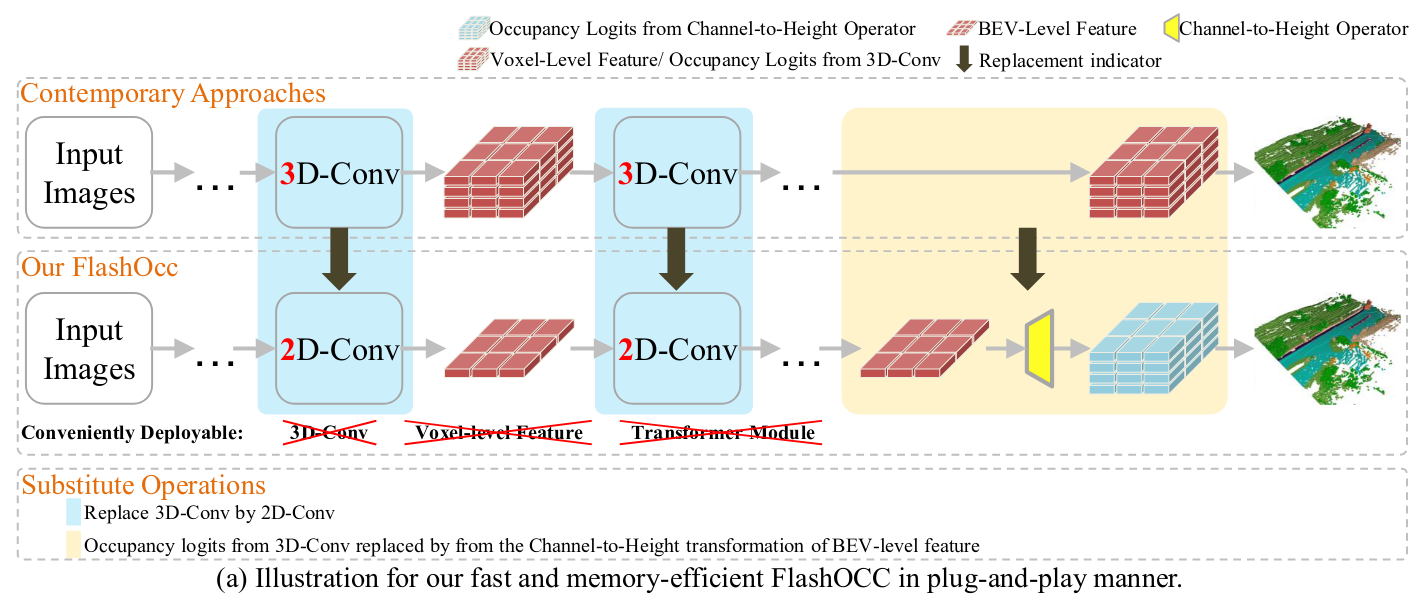
FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Abstract
Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.
Comments

[!NOTE]
We thought the problem for several days.
As the baseline methods (i.e. BEVDetOCC, UniOCC and FBOCC) based on voxel-level features would learn large number of non-object regions, thus
- the easy non-object region can dominate training process and result in degenerated models,
- the imbalanced samples increase learning difficulty for models. The above two issues offset the excellent performance of 3D-Conv.
使用 2d-conv 替代 3d-conv 可以获得更好的性能原因猜测:
3d-conv 直接在 voxel-level feature 上处理,空白的地方很多
Q&A
1. 2DTo3D 怎么做的
没有新提出方法
2. 多帧融合如何做的
- 将历史帧的 feature align 到当前帧
- fusion 没有仔细说怎么做的
3. Channel-to-Height 怎么做的? 应对 BEV grid 有悬挂物效果怎么样?
3.1 灵感来源
灵感来自一篇图像超分别率重建论文:ESPCN_CVPR2016
最后一层得到 \(r^2 \times H \times W\) 的 feature, 恢复成 \(r \times H \times r\times W\) 的图像
这篇论文提出了一种亚像素卷积的方法来对图像进行超分辨率重建,速度特别快。虽然论文里面称提出的方法为亚像素卷积(sub-pixel convolution),但是实际上并不涉及到卷积运算,是一种高效、快速、无参的像素重排列的上采样方式。由于很快,直接用在视频超分中也可以做到实时。其在Tensorflow中的实现称为depth_to_space ,在Pytorch中的实现为PixelShuffle
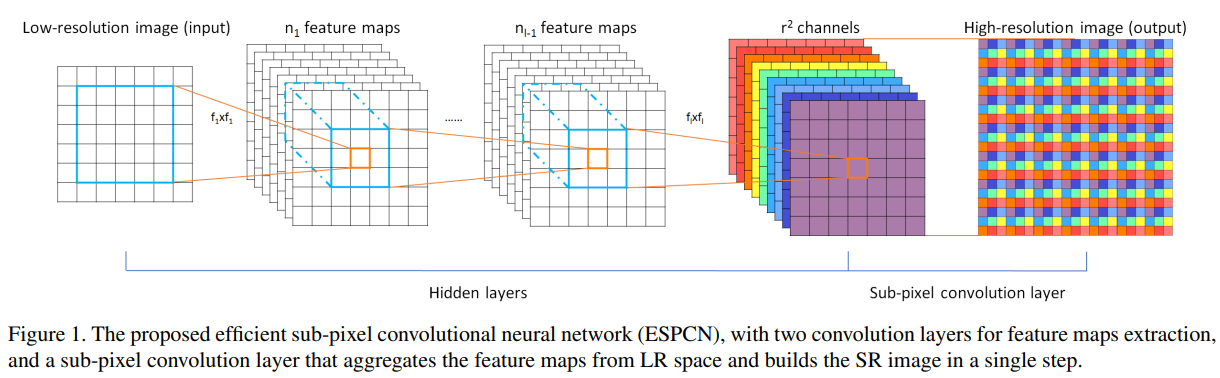
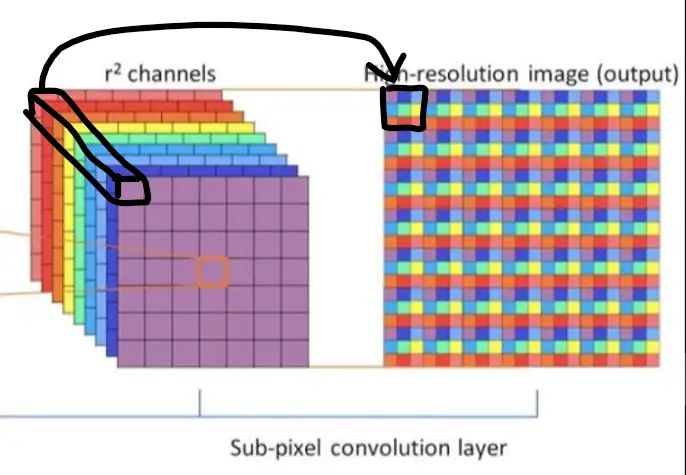
Sub-pixel convolution 是一种巧妙的图像及特征图upscale的方法,又叫pixel shuffle(像素洗牌)。用深度学习处理图像,经常需要对特征图放大。常见的方法有直接上采样,双线性插值,反卷积等。超分辨率中经常使用的 upscale 方法 —— sub-pixel convolution.
采用CNN对feature map 进行放大的方法,除了有 deconvolition 之外,还有一个叫做 sub- pixel convolution 。如果做SR(超分辨率)的话,需要将一张低分辨率图像转换成一张高分辨率图像。如果直接用 deconvolution 作为 upscale 手段的话,通常会带入过多人工因素进来。而 sub-pixel conv 会大大降低这个风险。sub-pixel:
前面就是一个普通的CNN网络,到后面的彩色部分就是 sub- pixel conv 的操作了。
首先如果对原图放大3倍,那么就要生成3^2=9 (通道数)个相同尺寸的特征图。然后将9个相同尺寸的特征图拼接成一个x3的大图,也就是对应的 sub - pixel convolution 操作;
其实也就是要放大r倍的话,那就生成r^2 个channel的特征图,这里的r也可以称为上采样因子;
这对应的是抽样的反思想,如果把一张 x3 的大图,每隔三个点抽样依次,那么就得到9张低分辨率的图像;反过来可以先通过CNN来获得这么9张低分辨率的图像, 即 r^2 个 channel 个特征图,然后再组成一张高分辨率大图;
BEV segmentation 中的 [[PETRv2_ A Unified Framework for 3D Perception from Multi-Camera Images]] 也使用了相似的想法
3.2 channel-to-height
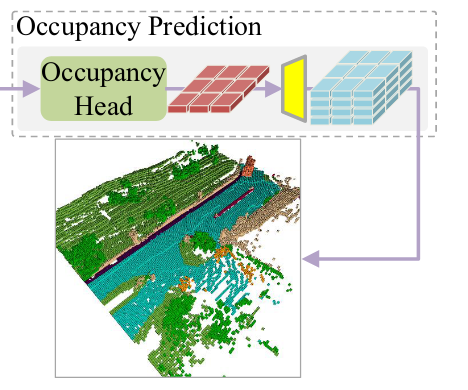
简单的进行 reshape: \(B\times C\times H\times W \to B\times C^* \times Z \times H\times W\)
其中 \(C^*\) 表示预测类别数据 ZHW 表示 voxel尺寸
这个操作和超分上采样类似,但是深层次的联系还没有搞清楚,最后的 voxel 怎样下采样可以得到 BEV feature?
没有说对于悬挂物的影响,但是看论文提供的图没有影响
4. center feature 的丢失如何处理的?
The issue of center features missing (for LSS) or aliasing artifacts (for LS) is improved via feature diffusion after several blocks in the backbone.
Pipeline