降低游戏的Drawcall,是渲染优化很重要的手段,接下来从以下4个方面来分析如何降低DrawCall:
(1) 降低Drawcall的意义是什么?如何查看游戏的Drawcall;
(2) Drawcall合批的常用的技术手段原理与优缺点;
(3) 组织项目让Drawcall最小需要注意的点;
搞清楚这些,Drawcall的优化基本上就能很好的掌握好。
降低Drawcall的意义是什么?如何查看游戏的Drawcall
游戏引擎遍历游戏场景中的所有的物体,然后得到一个物体的渲染顺序,然后按照顺序提交给GPU来绘制游戏画面出来。每次渲染时,CPU把每次绘制要使用的数据传递给GPU,然后向GPU下达绘制DrawCall指令,GPU接收到指令以后”开机”绘制游戏物体出来。假设我们有100个物体需要渲染,如果分100次提交给GPU,每次GPU渲染一个,完成后再渲染下一个,这样CPU就要向GPU传送数据100次,同时下达100次的渲染命令。如果是这样,CPU提交数据给GPU,下达指令会有额外的开销,GPU每次可以处理很多个面,但是由于每次只送进来一个物体,导致GPU的处理能力没有发挥出来。假设把100个物体一次提交给GPU一起绘制, CPU不用反反复复的给GPU下达指令,重复传送数据,GPU一次开机把100个物体一次处理好,发挥最大的性能。把N个物体合并到一起来提交给GPU,GPU一次绘制,这个过程我们叫做合批。CPU给GPU下达一次渲染指令叫Drawcall。提交绘制一个游戏场景,场景中的物体分几次提交给GPU进行绘制我们叫做批次数目(Batches),又叫Drawcall次数。如果100个物体分100次提交给GPU, Drawcall/批次数目(Batches) 为100, 100个物体分2次提交给GPU,Drawcall/批次数目(Batches) 为2。
如何查看游戏运行时Drawcall的数目,如下图所示:
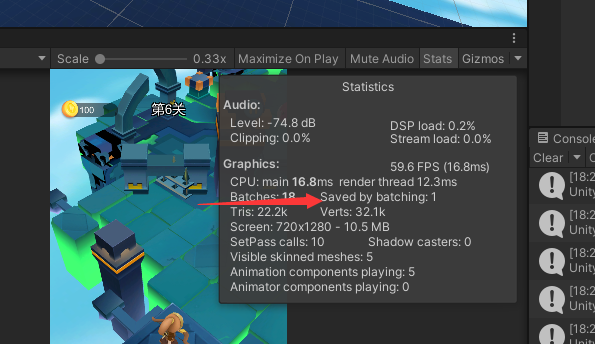
总结一下降低Drawcall次数的意义:
a:避免CPU反复多次的提交数据给GPU而产生的开销;
b:每次提交尽可能多的物体,能最大限度发挥GPU的性能,提升GPU的吞吐量;
Drawcall合批的常用的技术手段原理与优缺点
尽可能的让我们的游戏场景的物体能最少的批次完成渲染,一次渲染尽可能多的物体,降低Drawcall能提升渲染的性能。Unity游戏开发中有哪些常用的技术能将物体合批,降低Drawcall呢?
首先物体能合批的首要条件就是提交绘制的物体一定要是”同一个材质”,只有这些物体才有合批的可能。假设我们提交给GPU渲染的物体排列如下: A1A2A3A4A5A6B1B2B3B4B5B6其中A1, …A6表示这6个物体使用同一个材质A,B1,…B6标识6个物体使用同一个材质B。
静态合批:
游戏引擎会将"能够合批“(同一个材质球)的"静态物体"(所以你要标记为静态不可移动物体) 预先合并好成一个新的整体的网格,提交给GPU渲染。
静态合批处理的局限性(缺点)
a: 要求物体是静态不可移动的;
b: 预先计算好合并整体网格,合并后的内存开销增加;
c: N个物体使用同一个网格, 把所有的网格合并到一起, 合并后会有N个网格的数据导致内存暴涨,这时候要关闭静态的合批。例如森林有1000棵树,采用 静态合批后做成一个1000个树合在一起的网格,合并后的网格占用的内存空间就会很大,所以这种情况下一般关闭静态合批。
动态合批:
游戏引擎将"能够动态合批"的(同一个材质球) 物体的每个顶点,根据世界变换矩阵,用CPU来计算合批物体的每个顶点对应的世界空间的坐标,然后就把计算后的物体的顶点(世界空间下的顶点)与单位矩阵一起提交给GPU,GPU一起把他们渲染出来出来。
由上可知,动态合批是一个双刃剑,虽然可以获得合批提升的渲染性能,但同时CPU计算出顶点的世界坐标会产生额外的运算开销, 使用动态的合批的时候,我们要关注一下, 付出+得到是不是成比例。
动态合批是引擎会自动处理的,所以引擎会对能够动态合批的物体,会有一些条件的限制,引擎和系统给的合批的限制是顶点数目不应过多;
最后总结一下动态合批的缺点:CPU的开销和drawcall减少得到性能提升之间来做平衡;
GPU Instancing合批:
同一个网格对象的N个实例的绘制可以采用GPU Instancing合批。它的本质就是提交一次网格物体给GPU, GPU绘制出这个物体的N个实例到不同的地方(位置,旋转,缩放)。如1000个小兵采用GPU Instancing 合批,提交一个小兵的网格对象给GPU, GPU根据1000个小兵的位置来绘制出来我们1000个实例。
1000个实例,可以在同一个批次进行完成(1000个实例< GPU每次处理的极限),如果1000个兵一起合批超过了显卡的极限就分多批如: 800兵一批,200兵一批;
GPU Instacing合批是非常好的一种方式,它的缺点就是有些老的显卡不支持。
组织项目让Drawcall更小需要注意的点
合理的安排物体, 注意不要打乱物体的合批。3D物体的渲染顺序是引擎自动计算出来的,尽可能的在3D场景里面让物体使用同一个材质,尽可能的在同一个渲染队列里面使用同一个材质,尽可能的在3D场景里面使用同一个种shader,不要根据物体渲染的需顺序来回切换shader(Set Pass Call开销很大)。2D UI物体尽可能的安排同一个图集的物体在一起,如任务系统UI,尽量的让任务系统这些UI物体在一个图集里,这样可以合批渲染;
将多个物体的纹理合并到一起,如游戏地图上的障碍物,可以将这些障碍物与地图的纹理合并到一起,这样地图和障碍物可以由合批的可能。
最后 美术把能合批的物体生成到一个fbx模型里面,这样从美术的层次来减少渲染批次。
今天的分享就到这里了,关注我们可以获得更详细的官方给出的合批的一些规定,帮助大家优化Drawcall。
标签:合批,渲染,Drawcall,Unity,提交,GPU,优化,物体 From: https://www.cnblogs.com/bycw/p/17815360.html