本文和传统的内存优化不一样,不是讲如何降低内存占用,而是讲编程开发中要注意的内存问题以及一些内存技术的演变与原理。
本文很长,目录如下:
(1)Application进程的内存分段;
(2)OS动态内存分配与手动内存管理;
(3)什么是内存碎片,避免内存碎片常用手段;
(4)什么是内存泄漏,预防与追踪内存泄漏的常用方法;
(5)GC自动回收的实现原理与如何避免GC峰值冲击;
对啦!这里有个游戏开发交流小组里面聚集了一帮热爱学习游戏的零基础小白,也有一些正在从事游戏开发的技术大佬,欢迎你来交流学习。
1: Application进程的内存分段
应用程序的内存分为: 代码段, 数据段, 栈, 堆。
代码段:
用来存放代码的二进制指令与一些常量和常量字符串, 进程启动以后划分出来,把代码指令加载到代码段,一直占用内存,并且只读不可修改。
数据段:
用来存放代码中的静态全局变量,进程启动后,加载程序文件后,内存分配出来,并一直占用内存,直到进程结束。
栈:
函数在调用的过程中,局部变量,函数参数,函数调用时函数地址的跳转与返回执行下一条指令,这些都是使用栈来存储数据。随着函数调用返回,之前函数里面的局部变量,参数等使用的栈内存都会被回收。栈中内存如何被回收呢?其实就是一个栈顶指针,把栈顶指针往下移动,分配内存,回收内存把栈顶指针往上移动,所以局部变量是随着函数调用,在栈上反复的使用内存。如图1.1所示:
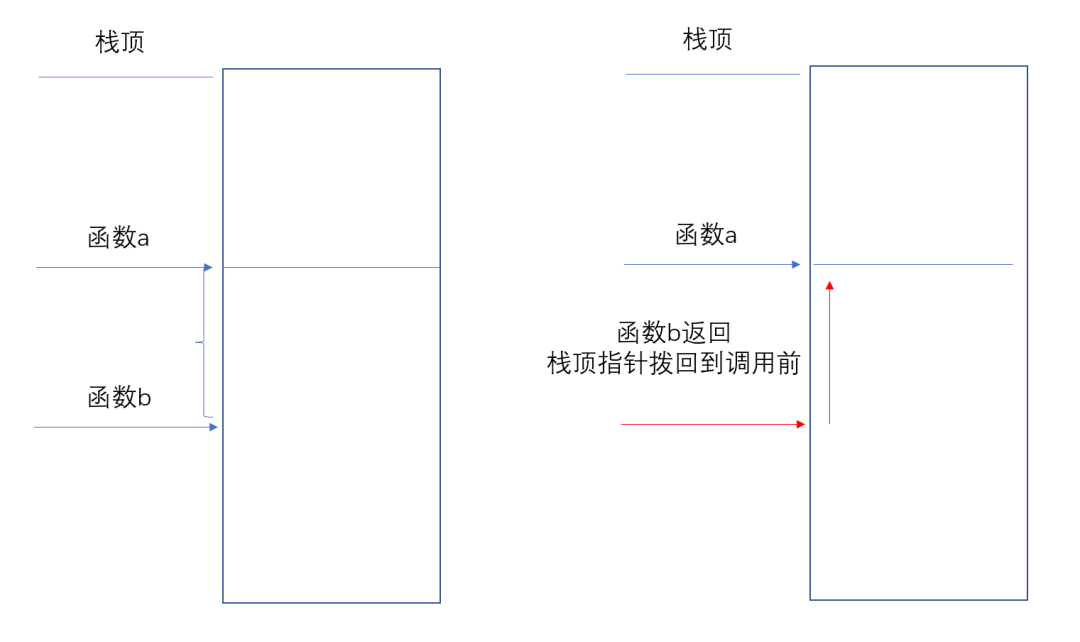
图1.1
栈有多大呢?其实栈的内存大小是相对比较小的,一般是由编译器生成执行文件的时候指定的,这个编程发布者可以改的,你在发布代码的时候,可以给编译器设置栈大小。一般栈默认是几百k, 有时候为了应对特殊的情况,配置编译器,把栈大小调整到1M甚至更大。栈溢出, 当栈的使用超过大小的额定范围,OS会抛出异常”栈溢出”,然后杀掉溢出的进程。比如一个算法是用递归写的,由于递归的层次比较深,导致栈溢出,这时候我们可以减少栈的内存使用或调整编译器来配置更大的栈。如图1.2 vs 编译C++时栈的配置:
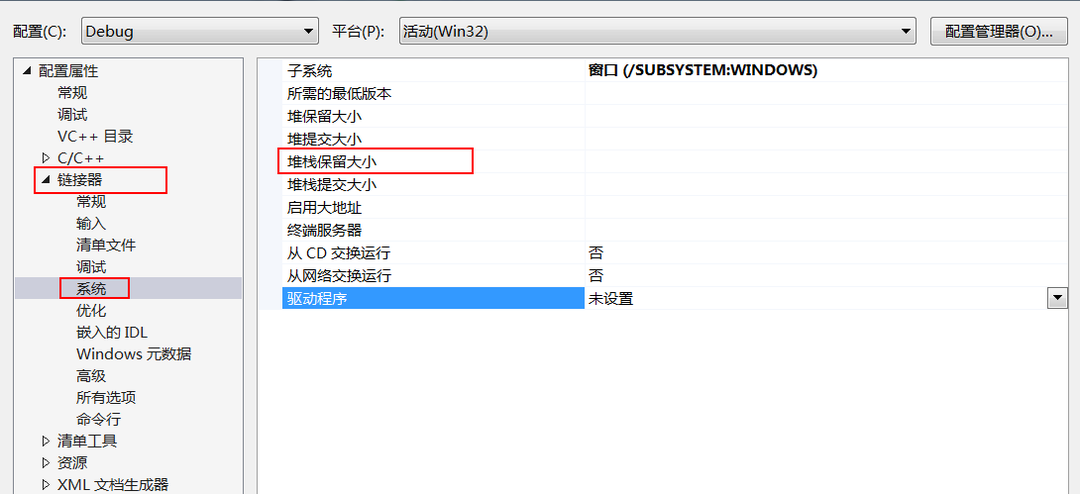
图1.2
堆:
当我们希望用到内存时就分配,不用时释放, 内存的生命周期和函数调用无关,完全由开发者自己决定,也不像全局变量一样,运行后内存一直占用,直到进程退出,所以OS给我们提供了一个动态内存分配机制,它提供一个系统调用malloc来分配特定大小的内存,提供一个接口free来释放这块内存,把内存还给OS, OS会划一块区域出来专门用来动态内存分配,叫做堆。
2: OS动态内存分配与手动内存管理
OS系统调用malloc/free的原理:
(1)每个进程都有自己的虚拟内存空间, 这个空间是一段地址范围,进程启动后这个内存空间并没有分配对应的物理内存。不同进程之间虚拟内存是独立的。比如进程A的内存地址0x123456与进程B的内存地址0x123456对应的不是同一个内存。好处每个进程运行时候内存都是独立的,如何做到的呢?OS从虚拟内存地址空间里面分配一段空间出来,比如起始地址是0x123456, 范围为128字节。(注意这里是空间不是内存),并不是真实的物理内存,然后OS会为这段虚拟内存地址空间做物理内存映射,映射物理内存后(虚拟地址与物理内存的映射是基于内存页的,一个页一个页的映射,linux内核2.6内存页大小是4k)内存就可以正常访问了,应用通过虚拟内存地址读写数据,把数据读写到物理内存中。这样做还有一个好处是把可用的物理内存通过OS管理起来,来分配给不同进程使用,当多任务的时,可以在OS级别来做物理内存页交换,用有限的物理内存来支撑更多的任务内存需求。
(2)malloc: OS分配虚拟内存空间,映射好物理内存,把虚拟内存空间地址返回给程序使用。
(3)当进程不用这个内存的时候,调用free,把虚拟内存地址空间还给OS,如果对应的物理页没有人使用了,还会把可用的物理页还给OS,重新做映射。
手动内存管理就是由程序员自己控制,当需要内存的时候调用malloc,不用的时候free。这种的缺点就是程序员容易忘记free。
3:什么是内存碎片,避免内存碎片常用手段
上面给大家讲解了,虚拟内存空间与物理内存以及映射相关的概念与原理。接下来分析什么是内存碎片。内存碎片是可用的虚拟内存空间越来越少,内存碎片是针对进程的虚拟内存而言的,并不是物理内存。内存碎片也不是开发者忘记把不用的内存回收(那个叫内存泄漏,下文讲解),而是随着系统的运行,把进程的虚拟内存空间分隔成了一些很小的颗粒度的内存块(内存碎片),而这些颗粒度,分布在虚拟内存空间中,能用,但是大小太小不满足进程使用的需求,所以随着系统长时间运行,这种碎片在内存中越来越多,系统可用的虚拟内存空间越来越少,最后被碎片吞噬而无法正常的请求到内存分配。
具体分析一下内存碎片在实际中的产生过程,如图1.3为一个线性的虚拟内存空间,
图1.3
(1)进程申请malloc 128字节,系统分配了左边第一个蓝色的块(红色块覆盖的蓝色块,那时没有红色块)。
(2)接着进程申请malloc 128字节,系统分配了左边第二个蓝色的块(没有红色块覆盖的蓝色块)
(3)进程申请释放第一个蓝色的块,free 128字节,这时候第一个蓝色块的内存空间被释放。
(4)进程申请malloc 110字节,OS从左边的地址开始分配了110大小,如红色的块所示,注意这个时候第一个蓝色块-红色块中间有个绿色块的空隙大小为18字节(128-110),可被分配,但是进程没有任何需求去用这么小的18个字节,所以就”导致内存碎片”,可用,但太小同时散落在内存空间中,无法用。
经过进程运行,一段时间后,大量的分配与释放,重新分配,有无数的”18字节”出来了,这就是内存碎片。内存碎片产生的原因其实就是系统反复大量的分配和释放大小不一的内存,导致进程要内存,系统有内存空间,但是这些空间不连续,大小满足不了申请要求,导致分配失败。
搞清楚内存碎片产生的原因,如何避免呢?大量的大小不一的内存块的申请与释放请求导致了碎片,那么解决方案就出来:
a:尽量让分配与释放的内存空间大小统一, 例如Unity ECS基于trunk来生成各种大小不同的大量Entity,每个trunk的大小是一样的。
b:对于大量分配的同一个大小的内存块,我们在进程层面做好缓存池,不还给OS,重复利用,比如物体缓存池等。
4:什么是内存泄漏,预防与追踪内存泄漏的常用方法
内存泄漏:
进程向OS malloc内存,不用后,却忘记调用free来释放,还给OS,导致系统认为这块内存进程还在用,而进程没有变量指向这块内存,无法用这块内存,可用的内存越来越少,这种情况叫”内存泄漏”。
内存泄漏会不会影响其它的进程任务运行?
进程A内存泄漏了,会不会影响进程B的可用内存越来越少呢?答案是不会,因为进程A内存泄漏,进程A中泄漏的内存不能用了,一段时间后,OS会判定 进程A泄漏的内存块对应的物理内存页长时间没有用,当物理内存吃紧的时候,会把这个物理内存页判断为”长时间不用”的物理内存页,就把泄漏对应的物理内存页的数据交换到磁盘,然后释放物理页给其它的进程B使用,所以进程A的内存泄漏,不会从根本上影响其它进程的内存使用(OS做内存页交换的开销肯定会有)。
内存泄漏的危害: 导致有内存泄漏的进程可用内存越来月少,最后导致进程无法分配内存而停止运行。
追踪内存泄漏的工具: 从系统级别给malloc与free函数,加入调试信息,运行时收集,找出来哪些地方的内存可能没有free,提示给开发者。比如Valgrind工具等,xcode也自动这种追踪工具,原理都一样。
预防内存泄漏:
(1)编写内存分配与释放函数,让大家统一来使用 这个接口来分配/释放内存,代替直接系统与库的调用。这种做法能快速的统计出是否有内存泄漏,比如怀疑有内存泄漏,那么你可以基于这个接口来加上统计信息来看,比如加上调用栈信息,看哪个地方在调用这个函数分配内存,然后查代码这个分配的在什么时候释放的,来快速的找出忘记free的对象。
(2)review代码,从代码上来review,熟悉整个内存的使用情况,来提早发现有内存泄漏的代码,毕竟等所有的项目代码都写好了再去追内存泄漏心里压力还是蛮大的。
(3)编写自动的垃圾回收机制,引入内存自动回收。现在的编程语言除了C/C++以外几乎都有基于垃圾回收的自动回收机制。
5: GC自动回收的实现原理与如何避免GC峰值冲击
基于自动垃圾回收的机制是如何实现?
这里给大家分享一种基于引用计数的垃圾回收机制的原理与实现,让你对垃圾回收器有一个全面的了解,其它的垃圾回收机制大同小异,只是判断”垃圾”的方式不一样而已。
实现一个基类我们叫做Object(现在你知道为什么很多垃圾回收的对象基类都是Object了吧,没有错,就是干这个事情的),
class Object {
int refCount; //为0表示为垃圾,增加引用,计数+1,减少引用,计数-1
…
重载operator=() {改变引用计数}
};
以后所有的自动回收的对象都要继承自这个Object。
接下来重载赋值操作符operator=, 当把一个变量赋值为新的Object的时候,把原来的Object引用计数减1,把新的Object的引用计数加1。
定义一个全局的内存分配器负责对象的内存分配与释放,我们暂时叫它Allocator,并提供接口 New,所有的Object的对象创建都基于这个全局的分配器来创建的,同时每分配一个对象出去,内存分配器保存好这个对象的地址或引用。当我们把对象赋值给变量的时候,老对象与新对象会触发引用计数的减加。比如:var a = xxx; a = null, 把a原来的老对象xxx引用计数-1。当没有变量指向xxx,那么它就会被定义为垃圾。
接下来就是给Allocator编写一个垃圾回收的接口叫GarbageCollection,它遍历Allocator记录的所有的分配出去的基于Object的对象,看看这些Object的引用计数是不是为0,如果是,就是垃圾,进而调用OS的释放函数回收内存,把垃圾对象回收。
编写了回收接口后什么时候调用呢?我们一般提供两种方式:手动强制回收垃圾(程序员直接调用)与特定时期的系统自动回收(系统检测,到达一些阈值条件后,调用Allocator的垃圾回收接口)。一般使用系统自动回收,这种还有一个好处,就是前面的垃圾对象还可以反复的再分配出去,比如已经是垃圾的同一类型物体,没有还给OS,但是下次分配又可以直接分配出去,可以避免内存碎片。(这样程序员只管new 对象,有家长帮你管对象了)
如何避免GC峰值冲击?
GC峰值: 某一瞬间,大量的物体的释放,导致GC花了很多时间来计算与回收垃圾,从而导致GC占用了CPU,卡住了程序。
如何避免GC峰值:可以通过平滑掉回收来避免在性能的关键时刻长时间触发GC。
举个例子,比如一个场景,有满屏的敌人,某个玩家放了一个技能,让大量的敌人瞬间全部死亡,如果在清屏的时候,触发了GC,回收大量的”敌人垃圾”,导致游戏长时间卡在了GC上,到导致帧率下降,这个就属于GC卡顿。假设GC 1万个对象卡了3秒, 我们就可以通过调节参数与阈值来避免对这1万个对象一次做回收,而是把1万个对象平滑到一个相对比较长的时间段去回收。每次只回收一部分,分多次回收。这样避免GC峰值带来的性能冲击。具体可以通过问题分析来做出相应的解决方案。
本文到此结束,很长,希望大家有所收获,关注我,一起来讨论内存相关的技术问题。
标签:泄漏,优化,回收,Unity,内存,进程,OS,虚拟内存 From: https://www.cnblogs.com/bycw/p/17815365.html