从贝叶斯定理到卡尔曼滤波
可以选择直接跳至卡尔曼滤波部分
开始之前
一个问题引入:如何确定一个随机事件发生的概率
频率学派认为可以利用大数定理,重复进行无数次随机试验,用最终得到的稳定频率来估计概率,而这里存在一个问题:随机试验必须可以重复进行,而有一些问题无法重复进行,如明天是否会下雨(因为你无法回到过去重复进行试验)。
贝叶斯学派则提供了另外一种思路:概率不再定义为事件的一种“固定属性”,而是站在观测者的角度,认为概率是一种信念(belief),表征观测者对某一事件发生的主观相信程度。观测者对于随机事件背后产生机制的认识是不断迭代的,在看到机制产生的结果(evidence)前,人们对此抱一个最初的信念(先验信念),然后人们陆陆续续看到了很多结果,再相应地更新信念(后验信念),不断迭代,使得人们不断接近对机制本质的认识。
而贝叶斯定理便体现了贝叶斯学派的这一思路:先主观赋值,然后再引入外部观测,对主观赋值进行修正,通过“学习”得到一个相对客观的概率。但在介绍贝叶斯定理之前,先让我们先复习一下条件概率公式:
\[P(A|B)=\frac{P(A\cap B)}{P(B)} \]其中\(P(A|B)\)称为条件概率(conditional probability),表示事件A在事件B发生的条件下发生的概率;\(P(A\cap B)\)称为联合概率(joint probability),表示两个事件共同发生的概率,也可以表示为\(P(AB)\),或\(P(A,B)\)。
移项一下,我们可以得到事件A,B同时发生的概率\(P(A\cap B)=P(A|B)P(B)\),特别的,当事件A,B独立时,因为\(P(A|B)=P(A)\),则又有\(P(A\cap B)=P(A)P(B)\)。
这时,我们注意到\(P(A\cap B)\)不仅可以通过\(P(A|B)P(B)\)得到,还可以通过\(P(B|A)P(A)\)得到,即
\[P(A\cap B)=P(A|B)P(B)=P(B|A)P(A) \]移项一下,即通过条件概率推导出了贝叶斯公式:
\[P(A|B)=\frac{P(B|A)P(A)}{P(B)} \]贝叶斯公式
我们将上面的A,B替换为字母H(hypothesis,意为假设 ),E(evidence,意为证据),这样更能体现出贝叶斯公式蕴含着通过新的证据对原有的假设进行更新的思想,即上文提到的“学习修正”能力。
\[P(H|E)=P(H)\frac{P(E|H)}{P(E)} \]我们称\(P(H)\)为先验概率(prior probability),即上文提到的那个先验信念,
称\(P(H|E)\)为后验概率(posterior probability),即上文提到的那个被新的证据所更新的后验信念,
称\(P(E|H)\)为条件似然(conditional likelihood),表示在假设\(H\)下,证据\(E\)发生的概率
称\(P(E)\)为整体似然(total likelihood),表示在所有假设下,证据\(E\)发生的概率
再将条件似然除以整体似然的这个整体,即\(\frac{P(E|H)}{P(E)}\),称为标准似然度(standardized likelihood)
于是贝叶斯公式可以表示为:后验概率 = 先验概率 × 标准似然度
标准似然度可以体现证据\(E\)发生后,对假设\(H\)的更新修正效果。
当标准似然度大于1,即\(\frac{P(E|H)}{P(E)}>1\)时,表示在假设\(H\)下证据\(E\)很有可能发生(在假设\(H\)下证据\(E\)发生的概率大于了所有假设下证据\(E\)发生的概率),所以当证据\(E\)发生时,假设\(H\)更有可能成立,假设\(H\)成立的概率变大了,体现在数学上即是:先验概率乘以大于1的标准似然度后得到的后验概率变大了。
当标准似然度小于或等于1时,同理。
于是假设\(H\)就这样被证据\(E\)更新了,通过新的证据\(E\)完成了对先验概率的修正。
进一步,此时假设\(H\)已经被证据\(E_1\)更新,得到了被修正的后验概率\(P(H|E_1)\),此时考虑新的证据\(E_2\)尝试在证据\(E_1\)基础上继续修正假设\(H\),于是得到贝叶斯定理的推广:Bayes Rule with Background Knowledge
\[P(H|E_1,E_2)=P(H|E_1)\frac{P(E_2|H,E_1)}{P(E_2|E_1)} \]这里我们还可以再展开\(P(H|E_1)\),再由\(P(A|H)P(B|A,H)=P(AB|H)\)(易证)得到:
\[P(H|E_1,E_2)=P(H)\frac{P(E_1|H)}{P(E_1)}\frac{P(E_2|H,E_1)}{P(E_2|E_1)}=P(H)\frac{P(E_1E_2|H)}{P(E_1E_2)} \]更进一步,我们还可以将上面的\(2\)个证据推广至\(n\)个
\[P(H|E_1E_2\dots E_n)=P(H)\frac{P(E_1E_2\dots E_n|H)}{P(E_1E_2\dots E_n)} \]特别的,若所有证据均互相独立,则有\(P(E_1E_2\dots E_n|H)=P(E_1|H)P(E_2|H)\dots P(E_n|H)=\prod_{i=1}^nP(E_i|H)\)
其实朴素贝叶斯分类器(Naive Bayes classifier)就是利用了这样的思想:给\(n\)个样本特征\(e_i(i=1,2,\dots,n)\),\(m\)个样本类别\(h_i(i=1,2,\dots,m)\),其中使\(P(h_i|e_1e_2\dots e_n)\)最大的\(h_i\)即可被认为是当前数据最有可能的分类。
\[classify(e_1,e_2,\dots,e_n)=\mathop{\arg\max}_{h}P(H=h)\prod_{i=1}^nP(E=e_i|H=h) \]另外,让我们再考虑一下贝叶斯定理的连续形式,同样的,我们通过条件概率来推导贝叶斯定理。
先复习一下相关概念符号:
设\((X,Y)\)为二维连续型变量,则
\(f_{X,Y}(x,y)\)为联合分布概率密度函数(Joint probability distribution),表示当\(X=x,Y=y\)时的概率
\(f_X(x)=\begin{equation*}\int_{-\infty}^{+\infty} f_{X,Y}(x,y)dy\end{equation*}\)为随机变量\(X\)的边缘概率密度函数(Marginal Probability Density Function),表示在所有\(Y\)下,随机变量\(X\)的概率密度
由随机变量\(X\)的条件概率密度函数(Conditional Probability Density Function)可知,在\(Y=y\)条件下,随机变量\(X\)的概率密度为:
\[f_{X|Y}(x|y)=\frac{f_{X,Y}(x,y)}{f_Y(y)} \]移项得到,\(f_{X,Y}(x,y)=f_X(x)f_{X|Y}(x,y)\)。
类似的,\(f_{X,Y}(x,y)\)还可以通过随机变量\(Y\)的条件概率密度求出,即
\[f_{X,Y}(x,y)=f_X(x)f_{X|Y}(x,y)=f_Y(x)f_{Y|X}(x,y) \]再移项一下,便得到了连续型变量的贝叶斯定理:
\[f_{X|Y}(x|y)=\frac{f_{Y|X}(y|x)f_X(x)}{f_Y(y)} \]贝叶斯滤波
介绍卡尔曼滤波之前,先介绍贝叶斯滤波。
因为测量传感器并不完全可靠,测量得到的数据含有噪声,需要“去噪声”,去噪声的过程即所谓的滤波。而贝叶斯滤波便是一种滤波算法,可以去噪声,对动态系统进行状态估计。
模型的定义与简化
首先为了方便研究问题,我们对非线性动态系统的噪声和测量建立一个离散差分模型:
\[\begin{aligned} x_k&=f(x_{k-1}, u_k)+w_k \\ z_{k}&=h(x_k)+v_k \end{aligned} \]其中,\(\boldsymbol{x_k}\)表示\(k\)时刻下系统的真实状态,\(\boldsymbol{u_k}\)表示\(k\)时刻对系统施加的控制量,\(\boldsymbol{f}\)表示可能非线性的状态转移方程,\(\boldsymbol{w_k}\)表示过程噪声;\(\boldsymbol{z_k}\)表示在\(k\)时刻下对系统进行测量得到的状态,\(h\)表示测量方程,\(\boldsymbol{v_k}\)表示测试噪声。
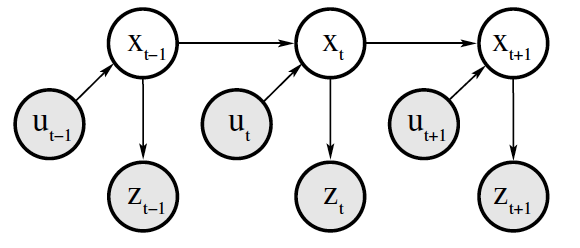
贝叶斯滤波要解决的问题就是:在第\(t\)时刻,已知系统控制量\(u_{1:t}\)和状态测量量\(z_{1:t}\),求此时系统真实状态\(x_t\)的后验概率\(P\)。
然后我们再简化模型,假设系统满足马尔可夫性质(Markov property),即这个随机过程满足:未来的状态仅依赖于当前的状态,与过去状态无关(条件独立)。于是模型可化简为:真实的状态\(x_t\)只与上一个时刻的\(x_{t-1}\)和当前施加的控制量\(u_t\)有关,传感器测得的状态\(z_t\)只与当前的真实状态有关\(x_t\)。
算法推导
我们开始推导,贝叶斯滤波有两个过程:预测和更新。
预测过程(Prediction step)指:在第\(t\)时刻施加控制量\(u\)后系统真实状态由\(x_{t-1}\)转移为\(x_t\),得到先验概率;
更新过程(Correction step)指:再用\(t\)时刻测量得到的测量状态\(z_t\)来更新先验概率,得到后验概率。
下面分别推导离散和连续两种形式:
离散形式
对于离散变量,我们定义\(p_{k,t}\)为第\(t\)时刻第\(i\)个状态的后验概率(此时控制量为\(u_t\),测量量为\(z_t\)),即\(p_{k,t}:=P(X_t=x_k|u_{t},z_{t})\)。
预测过程,便是\(P(X_{t-1}=x_i|u_{t-1},z_{t-1})\)(即\(p_{i,t-1}\))推导出\(P(X_{t}=x_k|u_{t},z_{t-1})\)(施加了控制\(u_t\),但还未考虑观测\(z_t\)),将其记作\(\overline{p}_{k,t}\),即先验概率。
由离散变量的全概率公式\(f_X(x)=\sum_{i}P(x|y_i)P(y_i)\)可得:
\[\begin{aligned} \overline{p}_{k,t} :&=P(X_{t}=x_k|u_{t},z_{t-1})\\ & = \sum_i P(X_t=x_k|X_{t-1}=x_i,u_{t})P(X_{t-1}=x_i|u_{t-1}) \\ & = \sum_i P(X_t=x_k|X_{t-1}=x_i,u_{t})p_{i,t-1} \end{aligned} \]更新过程,便是\(P(X_{t}=x_k|u_t,z_{t-1})\)(即\(\overline{p}_{k,t}\))推导出\(P(X_t=x_k|u_t,z_t)\)(即\(p_{k,t}\)),即考虑了测量\(z_t\),先验概率\(\overline{p}_{k,t}\)被测量量\(z_t\)更新,得到后验概率\(p_{k,t}\)
由上文已证明的贝叶斯公式的推广\(P(H|E_1,E_2)=P(H|E_1)\frac{P(E_2|H,E_1)}{P(E_2|E_1)}\),则有:
\[\begin{aligned} p_{k,t}:&=P(X_t=x_k|z_t,u_t)\\ &= P(X_t=x_k|z_{t-1},u_{t})\frac{P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)}{P(z_t,u_t|z_{t-1},u_t)}\\ &=\overline{p}_{k,t} \frac{P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)}{P(z_t,u_t|z_{t-1},u_t)}\\ \end{aligned} \]其中,\(P(z_t,u_t|z_{t-1},u_t)\)表示在任意状态下,测得状态为\(z_t\)的概率,而此与当前状态\(k\)的取值无关,故可以视为常数\(\frac{1}{\eta}\);\(P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)\)表示在\(t\)时刻,测得状态为\(z_t\)的概率,又可写作\(P(z_{t}|X_t=x_k)\)。
上式简化为
\[p_{k,t}=\eta\,\overline{p}_{k,t}P(z_{t}|X_t=x_k) \]综上两步,便得到了贝叶斯滤波的离散型递推公式
\[p_{k,t}=\eta\,\sum_i [P(X_t=x_k|X_{t-1}=x_i,u_{t})p_{i,t-1}]\, P(z_{t}|X_t=x_k) \]连续形式
对于连续变量,我们定义\(bel(x_t)\)为后验概率,即\(bel(x_t):=P(x_t|u_{t},z_{t})\);
首先是预测过程,
对于连续变量,即由\(bel(x_{t-1})\)(即\(P(x_{t-1}|u_{t-1},z_{t-1})\))推导出\(P(x_t|u_{t},z_{t-1})\),记作\(\overline{bel}(x_t)\),即先验概率。
由连续变量的全概率公式\(f_X(x)=\begin{equation*}\int_{-\infty}^{+\infty} f_{X|Y}(x|y)f_Y(y)dy\end{equation*}\)可得:
\[\begin{aligned} \overline{bel}(x_t) :&=P(x_{t}|u_{t},z_{t-1}) \\ & =\begin{equation*}\int P(x_t|x_{t-1},u_t)P(x_{t-1}|u_{1:t-1},z_{1:t-1})dx_{t-1}\end{equation*} \\ & = \int P(x_t \mid x_{t-1}, u_t) bel(x_{t-1}) \, \mathrm{d} x_{t-1} \end{aligned} \]然后是更新,即由\(\overline{bel}(x_t)\)推导出\(bel(x_t)\),即先验概率\(\overline{bel}(x_t)\)被
由上文已证明的贝叶斯公式的推广\(P(H|E_1,E_2)=P(H|E_1)\frac{P(E_2|H,E_1)}{P(E_2|E_1)}\),则有:
\[\begin{aligned} bel(x_t) :&=P(x_t|u_{t},z_{t})\\ &= P(X_t=x_k|z_{t-1},u_{t})\frac{P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)}{P(z_t,u_t|z_{t-1},u_t)}\\ &=\overline{bel}(x_t) \frac{P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)}{P(z_t,u_t|z_{t-1},u_t)}\\ \end{aligned} \]其中,\(P(z_t,u_t|z_{t-1},u_t)\)表示在任意状态下,测得状态为\(z_t\)的概率,而此与当前状态\(k\)的取值无关,故可以视为常数\(\frac{1}{\eta}\);\(P(x_k,z_{t},u_t|x_k,z_{t-1},u_t)\)表示在\(t\)时刻,测得状态为\(z_t\)的概率,又可写作\(P(z_{t}|X_t=x_k)\)。
上式简化为
\[bel(x_t)=\eta\,\overline{bel}(x_t)P(z_t|x_t) \]综上两步,便得到了贝叶斯滤波的连续型递推公式
\[\begin{aligned}bel(x_t) & = \eta\,P(z_t|x_t)\,\overline{bel}(x_t) \\ & = \eta\,P(z_t|x_t)\,\int P(x_t \mid x_{t-1}, u_t) bel(x_{t-1})\,\mathrm{d} x_{t-1} \end{aligned} \]然而在实际应用时,贝叶斯滤波因为涉及无穷积分,很难直接应用,所以我们可以作一些合理的理想假设限定,比:如我们假设状态转移函数\(f(x)\)和观测函数\(h(x)\)均为线性函数,过程噪声和观察噪声均服从均值为0的正态分布,于是我们便得到了应用性更强的卡尔曼滤波。
卡尔曼滤波
模型的再次简化
通过上述的理想化假设限定,我们将模型再次简化为:
\[\begin{aligned} x_k&=Ax_{k-1}+Bu_{k}+w\\ z_k&=Hx_k+v\\ \end{aligned} \]其中\(w\)为过程噪声,\(v\)为测量噪声,假定两种噪声分别都满足均值为零的正态分布,即\(p(w)\sim N(0,Q),\,p(v)\sim N(0,R)\),其中矩阵\(Q\)为过程激励噪声(预测噪声)的协方差,矩阵\(R\)为观测噪声(测量噪声)的协方差,这里假定噪声都不变;矩阵\(A\)表示从真实状态\(x_{k-1}\)到真实状态\(x_k\)的转移方程,矩阵\(B\)表示控制模型,将控制量\(u_k\)作用到真实状态\(x_{k-1}\),矩阵\(H\)表示观测模型,将真实状态空间映射到观测空间。
实际上,很多真实世界的动态系统都并不确切的符合这个模型;但由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了。
符号的定义与推导
我们再定义:\(\hat x_k^-\)表示先验估计,即通过上一个状态\(x_{k-1}\)和现在施加的控制量\(u_{k}\)预测得到的现在的真实状态\(x_k\)的先验概率,\(\hat x_k\)表示后验估计,即先验估计值被测量数据修正后的估计值,即使用第\(k\)时刻得到的测量量\(z_k\),对状态\(x_k\)更新后\(x_k\)的后验概率。
定义先验概率所估计的状态\(\hat x_k^-\)与真实状态\(x_k\)的误差的协方差为\(P_k^-\):
\[P_k^-=cov(x_k-\hat x_k^-) \]定义后验概率所估计的状态\(\hat x_k\)与真实状态\(x_k\)的误差的协方差为\(P_k\):
\[P_k=cov(x_k-\hat x_k) \]而卡尔曼滤波要解决的问题就是:面对两个估计值—— 一个是通过上一个状态\(x_k\)和控制量\(u_k\)推导出的先验估计值\(\hat x_k^-\),一个是当前传感器得到的测量值\(z_k\)——来找到一个合适的权重系数\(K\),使得同时考虑到先验估计\(\hat x_k^-\)和测量量\(z_k\),最终使后验估计的协方差最小,让后验估计更接近真实值,来得到一个更加合理科学的后验概率\(\hat x_k\)。这个过程可以表示为:
\[\begin{aligned} \widetilde{y}_k &= z_k-H\hat x_k^-\\ \hat x_k&=\hat x_k^-+K_k\widetilde{y}_k\\ \end{aligned} \]其中,\(\widetilde{y}_k\)被称为残差(residual, or measurement innovation),反映了先验估计值与实际测量值的差异;
权重系数\(K_k\)又被称为卡尔曼增益系数,体现了实际测量值对于先验估计的修正程度。
为了最小化后验概率的协方差,系数\(K_k\)被定义为:
\[\begin{aligned} K_k&=\frac{P_k^-H^T}{HP_k^-H^T+R} \end{aligned} \]可以注意到,当测量噪声的协方差\(R\)趋近于零时,系数\(K_k\)会趋向于\(H^{-1}\),\(\hat x_k\)会趋向于\(z_kH^{-1}\),即测量得到的状态,表示充分信任传感器得到的测量数据;
当先验概率估计误差的协方差\(P_K^-\)趋近于零时,系数\(K_k\)会趋向于\(0\),\(\hat x_k\)会趋向于\(\hat x_k^-\),即先验估计的状态,表示充分信任先验估计。
其实这个系数\(K\)的定义是可以推导出来的,这样的定义被称为最优卡尔曼增益,具体推导可以参考这里,总之系数\(K\)的目的就是为了最小化后验概率的协方差,使得后验估计尽可能解决真实值。
另外,先验估计协方差\(P_k^-\)的递推式推导:
\[P_k^-=AP_kA^T+Q \]表示从当前时刻的先验估计是由上一个时刻的后验估计通过矩阵\(A\)转移而来,同时存在预测噪声\(Q\)。
后验估计协方差\(P_k\)的递推式推导:
\[\begin{aligned} P_k:&=cov(x_k-\hat x_k) \\ &=cov(x_k-(\hat x_{k}^-+K_k\widetilde{y}_k)) \\ &=cov(x_k-(\hat x_{k}^-+K_k(z_k-H\hat x_k^-)))) \\ &=cov(x_k-(\hat x_{k}^-+K_k(Hx_k+v-H\hat x_k^-)))) \\ &=cov((I-K_kH)(x_k-\hat x_k^-)-K_kv) \\ \end{aligned} \]即依次展开\(\hat x_k,\widetilde y_k, z_k\),然后合并同类项。
这里因为测量误差\(v_k\)与其他项非相关的,故上式还可以化简为:
\[\begin{aligned} P_k &=cov((I-K_kH)(x_k-\hat x_k^-)-K_kv) \\ &=cov((I-K_kH)(x_k-\hat x_k^-))+cov(K_kv) \end{aligned} \]又有协方差的性质(\(cov(AX)=Acov(X)A^T\)),上式还可以化简为:
\[\begin{aligned} P_k &=cov((I-K_kH)(x_k-\hat x_k^-))+cov(K_kv) \\ &=(I-{K_k}H)cov(x_k-\hat x_k^-)(I-{K_k}H)^T+K_kcov(v){K_k}^T \\ &=(I-{K_k}H)P_k^-(I-{K_k}H)^T+{K_k}R{K_k}^T \\ \end{aligned} \]而当卡尔曼增益\(K_k\)被定义为最优卡尔曼增益时,即上文所定义的那样\(K_k=\frac{P_k^-H^T}{HP_k^-H^T+R}\)时,上式还能化简
先展开上式:
\[\begin{aligned} P_k &=(I-{K_k}H)P_k^-(I-{K_k}H)^T+{K_k}R{K_k}^T \\ &=P_k^--K_kHP_k^--P_k^-H^TK^T+K_k(HP_k^-H^T){K_k}^T+K_kR{K_k}^T \\ &=P_k^--K_kHP_k^--P_k^-H^TK^T+K_k(HP_k^-H^T+R){K_k}^T \\ \end{aligned} \]然后对\(K_k\)变形:
\[\begin{aligned} K_k&=\frac{P_k^-H^T}{HP_k^-H^T+R} \\ K_k(HP_k^-H^T+R)&=P_k^-H^T \\ K_k(HP_k^-H^T+R){K_k}^T&=P_k^-H^T{K_k}^T \end{aligned} \]将这个关系代入上式,后两项抵消,化简上式得到:
\[\begin{aligned} P_k &= P_k^--K_kHP_k^--P_k^-H^TK^T+K_k(HP_k^-H^T+R){K_k}^T \\ &= P_k^--K_kHP_k^-\\ \end{aligned} \]最终后验估计协方差\(P_k\)的递推式被化简为:
\[P_k = P_k^--K_kHP_k^- \]算法推导
推导出这些符号的关系后,我们开始推导卡尔曼滤波,类似的,卡尔曼滤波也分为预测和更新两个过程,思想也与贝叶斯滤波类似。
预测过程:
\[\begin{aligned} \hat x_k^-&=A\hat x_{k-1}+Bu_k \\ P_k^-&=AP_kA^T+Q \\ \end{aligned} \]即使用上一状态的后验估计\(\hat x_{k-1}\),施加控制量\(u_k\),通过矩阵\(A\)转移状态,预测出当前状态的先验估计\(\hat x_k^-\);
当前状态的先验估计误差协方差\(P_k^-\)从上一个状态的后验估计误差协方差转移而来。
其中状态转移矩阵\(A\),控制模型\(B\),预测噪声\(Q\),具体详见上文
更新过程:
\[\begin{aligned} \hat x_k&=\hat x_k^-+K_k\widetilde y_k \\ P_k&= P_k^--K_kHP_k^- \end{aligned} \]即依据卡尔曼增益系数\(K_k\)作为权重,利用当前状态的测量数据\(z_k\)对当前的先验估计\(\hat x_k^-\)进行修正更新,得到当前状态的后验估计\(\hat x_k\);
递推求得当前状态的后验估计误差协方差\(P_k\),推导详见上文。
其中残差\(\widetilde{y}_k = z_k-H\hat x_k^-\),测量模型\(H\),卡尔曼增益\(K_k=\frac{P_k^-H^T}{HP_k^-H^T+R}\),测量噪声\(R\),具体详见上文。
算法的实现与调参
一维滤波
一维实际应用时,算法参数被简化如下:
一维,所以所有矩阵变为标量;
真实状态空间\(x\)与测量状态空间\(z\)相同,所以观测模型系数\(H=1\);
过程的状态不随时间变化,所以状态转移系数\(A=1\);
预测噪声协方差\(Q\)自己设定,越小越信任自己的预测模型,对于测量数据的变化越不敏感,反应越慢,一般不要设定为0;
测量噪声协方差\(R\)需要对测量仪器进行实验,如对于陀螺仪,标定方法为:保持陀螺仪不动,统计其输出数据,数据近似满足正态分布,按照\(3\sigma\)原则,取正态分布的\((3\sigma)^2\)作为\(R\)即可;
初始化后验估计误差协方差\(P_0\),\(P_0\)的选择并不关键,任何\(P_0\neq 0\)都可以让滤波器收敛,这里让\(P_0=1\);
P=1;
while(1){
z = get_sensor_data();
u = get_control_data();
// predict
x_ = x + u;
P_ = P + Q;
// correct
K = P_ / (P_ + R);
x = x_ + K*(z - x_);
P = P_ - K*P_;
}
实际实现程序时,通常会合并P和P_变量,如果没有控制输入,u=0即可。
多维滤波
即将标量实现换成矩阵运算实现即可。Todo