大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。
DNA甲基化与转录调控、基因组印记、干细胞分化、胚胎发育和炎症等过程有关。DNA甲基化异常可能揭示疾病状态,包括癌症和神经系统疾病。因此,人类基因组中5-甲基胞嘧啶(5mC)分布和位点是一个重要的研究方向。全基因组重亚硫酸盐测序(Whole-genome bisulfite sequencing, WGBS)是一种用于分析DNA甲基化的高通量方法,本文综述了WGBS的关键步骤,总结了可用且最新的分析工具,比较了比对算法,并分享了数据处理的示例代码,为科研人员的DNA甲基化研究提供参考。

标题:Analysis and Performance Assessment of the Whole Genome Bisulfite Sequencing Data Workflow: Currently Available Tools and a Practical Guide to Advance DNA Methylation Studies
期刊:《small methods》
时间:2022年3月
影响因子:10.7
WGBS文库制备
广泛使用的亚硫酸盐转化文库构建方法:Accel-NGS Methyl-Seq(Accel)、TruSeq DNA Methylation(TruSeq)和SPlinted ligation adapter tagging(SPLAT)。
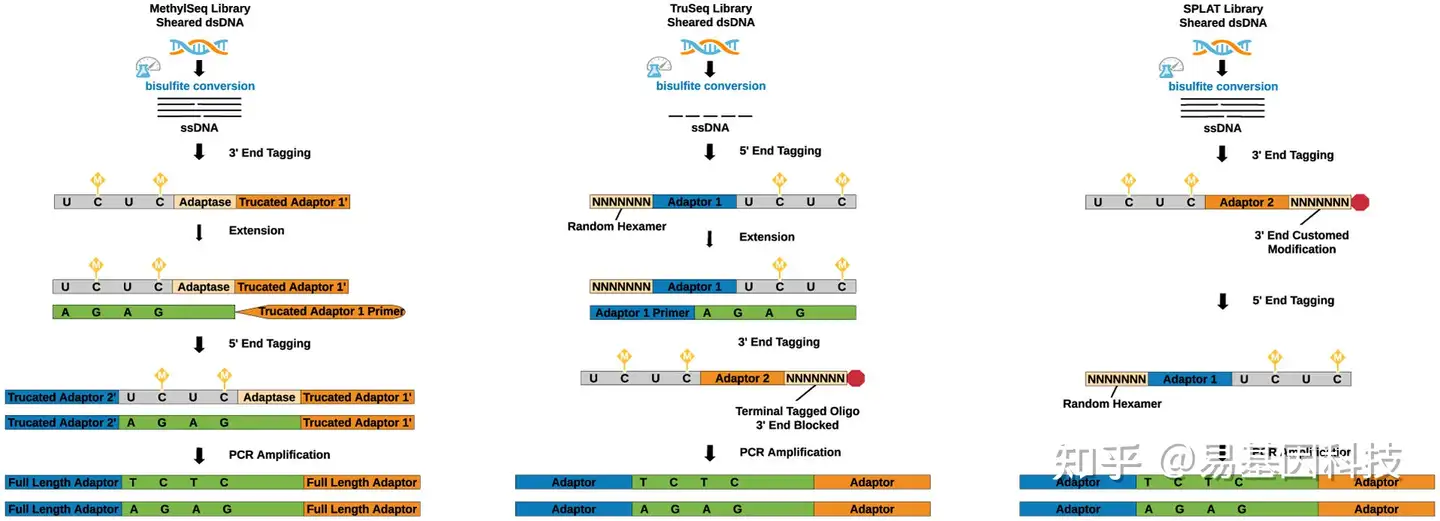
图1:WGBS的亚硫酸盐转后文库制备方法。
WGBS分析流程
在处理原始测序数据时,生物信息学分析流程的可重复性和一致性至关重要。由于WGBS数据通常很庞大,因此需要大量的计算资源、内存和存储空间。这就要求分析流程不仅要稳定,还要高效地使用内存和时间。
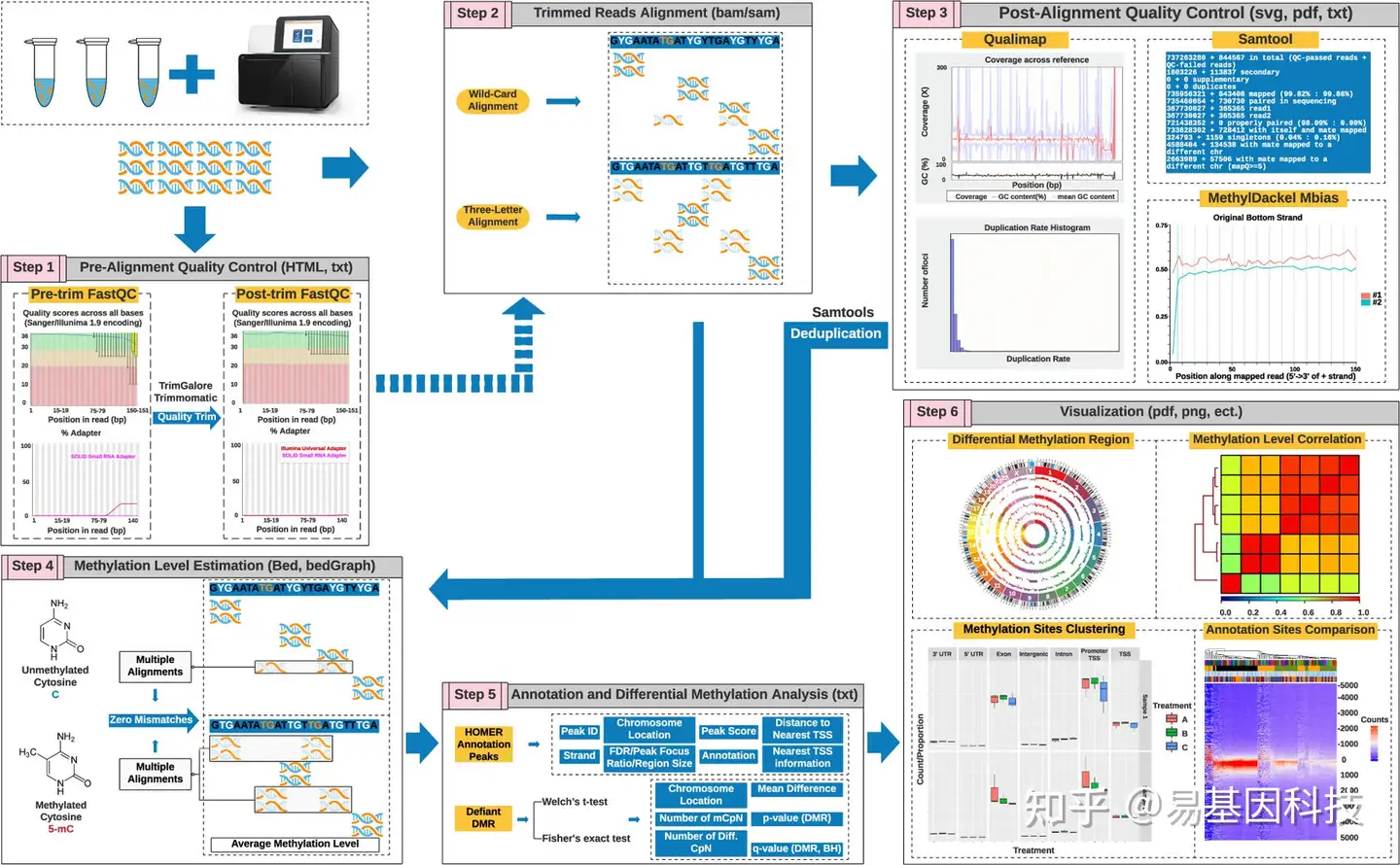
图2:WGBS数据处理和分析流程概述和原则。
a)质量评估:预比对质控(QC)以进行测序质量评估、接头检测和序列偏倚。然后对原始数据reads进行质量过滤和接头修剪。
b)数据比对:处理后的数据使用专门设计的软件与参考基因组进行比对,生成标准的SAM/BAM格式结果。比对软件会考虑到胞嘧啶和胸腺嘧啶的不匹配分布变化,并进行相应的调整。
c)比对后的质量评估:可以通过一些比对软件或使用外部软件如Samtools或Qualimap来获得比对后的质控结果。甲基化偏差(M-bias)图表示reads中每个位点的平均甲基化水平,应该是恒定的。如果不是,则需要在甲基化calling中修剪偏倚reads。
d)甲基化calling:甲基化calling过程会在参考基因组中迭代,为胞嘧啶背景(CpG、CHG和CHH)生成原始甲基化要求。在某些情况下,比对软件的选择可能会影响甲基化分析结果。最终的甲基化calling报告会列出每个位点的甲基化百分比和覆盖率。
e)甲基化calling结果的注释和分析:甲基化calling结果可以进行注释或进行差异甲基化区域(DMR)分析,并可以通过多种方法(如BedGraph)进行可视化。处理大量数据,如人类基因组,可能需要降维以提高速度并避免内存“耗尽”。
(1)质量评估(Quality Assessment)
预比对质量评估确保了原始数据的正确输入并提高了可比对性。多维度评估审查了低质量reads、接头序列、污染序列和重复reads。合成测序(增加测序的碱基数量)会降低质量,尤其是Illumina平台。在测序过程中,DNA簇中的单个分子可能无法成功合成。错误合成的分子聚类会导致motif calling错误,这些错误与片段长强正相关。文库构建中长片段比例越高,可能会导致更多的calling错误、较低的Phred得分和更高的不匹配率,特别是对于成对末端对齐。建议保留质量分数≥30的碱基,这表示对motif calling准确性99.9%。DNA测序反应读长通常比DNA片段长,片段两端的接头序列可能被错误地测序,这会引入构成性的甲基化C,并在随后的甲基化calling中引起偏差,因此建议提前检查并修剪接头。数据可能被污染,包括在文库制备步骤中添加引物和载体序列,以及为校准测序反应中的序列质量而添加的Phi X噬菌体DNA。过度表示的污染物通常呈现显著高于核基因组的reads深度,导致在比对过程中失败。当同一DNA片段被双重计数时,可能会发生重复reads(两个具有相同基因位点的reads)。
长插入片段可能会从更高比例的高质量reads、较少接头污染和更高有效reads深度(增加基因组覆盖效率)中受益。TruSeq文库制备需要特别注意重复reads,其PCR扩增cycles数量大约是Accel的两倍(10-12 cycles对比6-9 cycles)。
建议使用FastQC对原始FASTQ文件在修剪前后进行质量评估。QC结果包括一个.HTML格式的摘要和包含质量图表的.zip文件夹。检测每个样本的总reads数、每个碱基的序列质量和接头检测图,以确保良好的质量比对和比对reads数量。在亚硫酸盐转化过程中观察到GC比率和内容分布的偏倚,修剪后的FastQC报告作为双重保障,确保在修剪后(去除接头)每个样本的总reads数保持不变,并确保随机引物引起的碱基序列变化。
(2)reads修剪(Trimming)
使用FastQC对原始FASTQ文件进行质量评估后,可以利用Trim Galore软件(具有简化的命令行和参数,能够自动识别技术序列)和Trimmomatic软件对低质量reads、接头序列、污染序列、重复序列进行去除。这一步骤称之为修剪(Trimming)。WGBS数据修剪主要有两个方面:质量修剪和接头去除。质量修剪侧重于原始reads端的质量下降,以及序列组成的头部和尾部偏差。修剪方法包括剪除低于特定质量阈值的区域(Phred默认分数为20,表示1/100的碱基可能是错误的),或者从reads开始和结束修剪自定数量碱基。对于非亚硫酸盐测序的接头去除,依赖于“过度表示的序列”和“每条序列的GC含量”。由于CG含量在WGBS数据中不适用,过度表示的序列作为接头污染的指标,在Trim Galore中通常被检测到。修剪参数的其他考虑因素是文库方向和输入reads的成对/单端特性。Trim Galore对文库的默认设置具有方向性,在Trim Galore中应指定成对末端的特性,以保持成对reads,以便进一步比对。两个文件的reads数不匹配和reads名称不一致会触发警告。
(3)比对(Alignment)
WGBS的原理是对未甲基化的胞嘧啶(Cs)通过亚硫酸盐处理转化为胸腺嘧啶(Ts),同时保留甲基化的Cs。理想情况下,当reads序列比对到参考基因组时,可以识别未甲基化的Cs。然而亚硫酸盐转化带来数据比对两大计算挑战:C-T比对不匹配和序列复杂性降低。C-T比对不匹配指的是在测序reads中,T可能与参考基因组中的C比对,反之则不然。序列复杂性降低使得难以区分转化后的Ts与系统错误,夸大了比对不准确。
为了解决这种变化带来的reads与参考基因组不匹配的问题,有两种主要的比对策略:三字符策略和通配符策略。三字符策略通过将参考基因组和序列reads中的所有Cs转换为Ts,将基于四字符的基因组简化为基于三字符的基因组。之后使用标准的比对工具处理reads序列,如Bowtie1或Bowtie2、BWA mem和GEM3,主要采用Burrows-Wheeler变换(BWT)回溯算法。而通配符策略用基因组中的Cs转换为Ys,这可以与reads序列中的Cs和Ts进行匹配。在选择比对工具时,比对的准确性和计算时间是主要的考虑因素。Bock(2012)建议,通配符比对策略实现了更高的基因组覆盖率,但增加了高甲基化水平评估偏差的可能,而三字符策略则相反。通配符比对软件在BS转化reads中保留Cs,并将序列复杂性提高到确保与参考基因组唯一比对水平,而三字符比对软件在BS转化reads中去除Cs,降低序列复杂性,增加了模糊比对位点的机会。但覆盖差异和M偏差仅在基因组中的高相似区域中表现出来,因此在如人类基因组的长序列reads比对不太相关。因此在比对软件选择中优先考虑计算速度和内存消耗。研究表明如Bismark和BWA-METH等三字符比对软件在运行时间和峰值内存使用方面优于如BRAT_BW、BSMAP和GSnap的通配符比对软件。
在众多比对软件中,BitMapperBS和FMtree相对更节省时间,但与Bismark、BWA-METH和gemBS比对软件相比,在1,000,000 bp成对末端模拟数据read上,并没有观察到6-7倍的计算时间减少。对于处理大型哺乳动物测序项目的人来说,从大约24小时减少到7-8小时可能是有说服力的,尽管在追求速度时可能会牺牲比对质量。BitMapperBS可能无法保证在有多个不匹配的情况下获得最高质量比对,因此作者更为推荐Bismark、BWA-METH、gemBS,这几款软件能节省约1/3的运行时间且能良好的平衡运行时间与比对质量之间的关系。
用于亚硫酸盐处理reads比对算法在运行时间和比对质量上的差异会影响下游的甲基化calling。在Accel-NGS MethylSeq、SPLAT和TruSeq等WGBS框架以及TrueMethyl和EMSeq的氧化亚硫酸盐测序中,对广泛应用的比对软件Bismark、BitMapperBS、BWA-METH和gemBS进行评估。通过使用Seqtk的相同数据检测的五种文库制备方法,从样本数据中减去1,000,000 bp成对末端reads,比较其运行速度。比较结果显示,BitMapperBS具有最高的对齐速度,平均每秒约550-650 reads(表1)。Bismark、BWA-METH和gemBS显示出相同的比对速度(约每秒200-300reads0;而Bismark最不稳定。
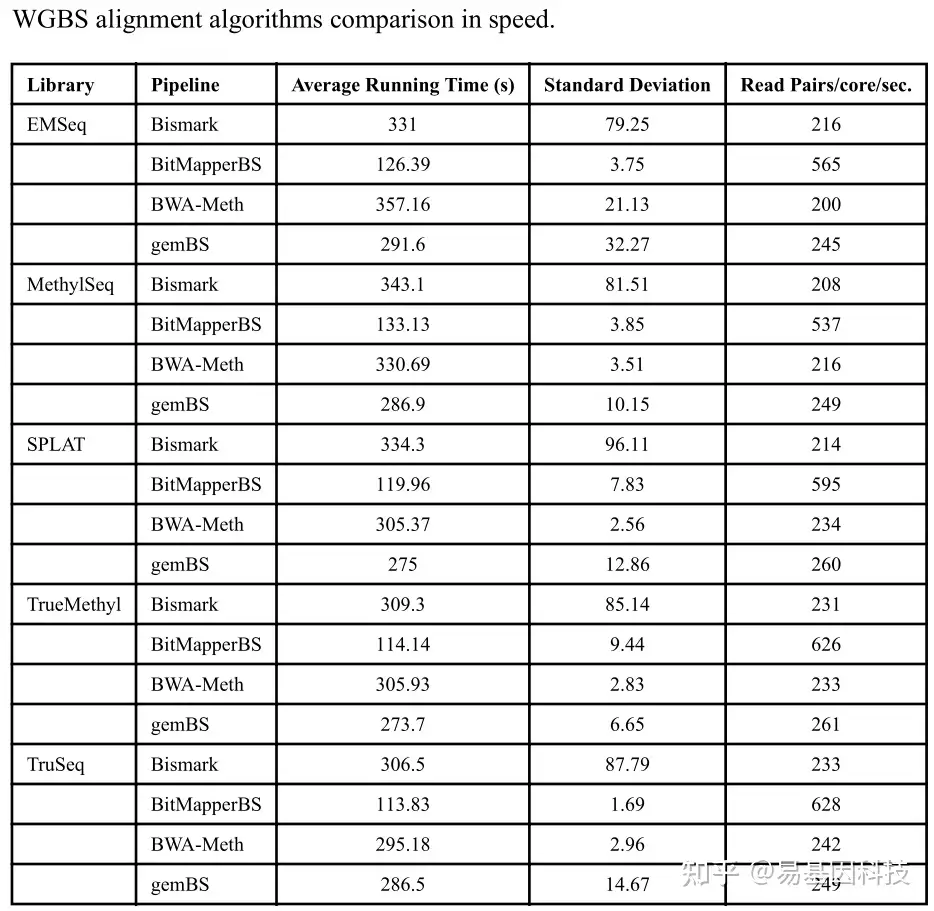
表1:WGBS比对软件在速度上的比较。
四个比对工具在甲基化calling后的比对质量显示,BWA-METH和gemBS有最高的唯一比对率和最少的未比对reads(图3A)。在每个染色体的平均CpG覆盖度≤×10时存在微小差异,在≥×20覆盖度时,BWA-METH比其他方法有略好的覆盖度(图3B)。DNA片段两端未甲基化的Cs数量对于从比对结果中获得合格的DNA甲基化calling至关重要。使用M-bias图对每个流程比对结果的影响规模非常相似,尽管在不同文库之间存在较大差异(图3C)。使用比对软件在基因组上calling的CpGs一致性显示,在每个注释区域和转录起始位点(TSSs)周围的平均甲基化水平上显示出可比的基因组富集分布(图3D-E)。与此同时,甲基化extraction水平不受比对软件选择的影响,因为Bismark与其他三种比对软件相比,甲基化calling相关性只略降低(图4)。
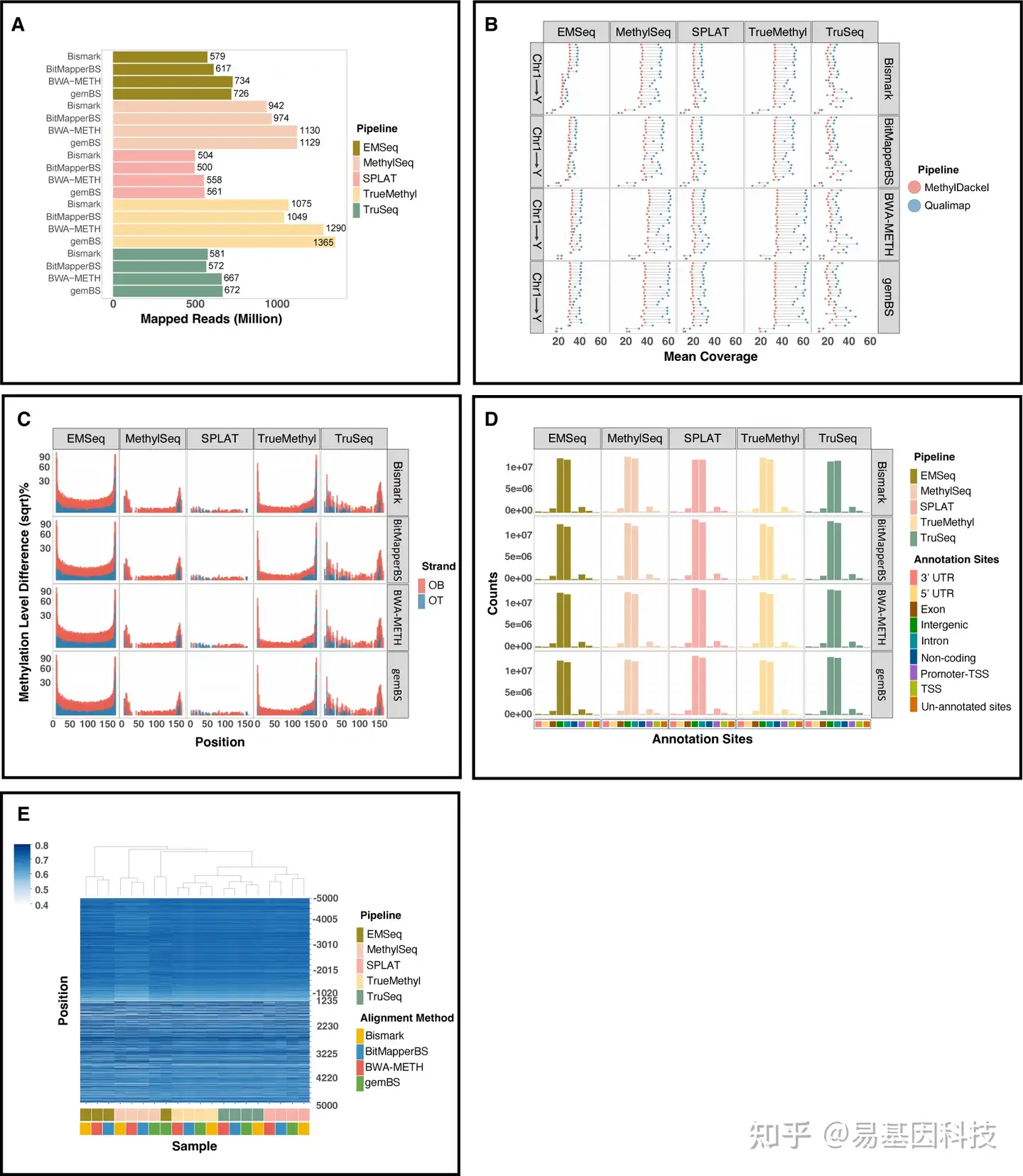
图3:四种比对算法的比对质量比较。
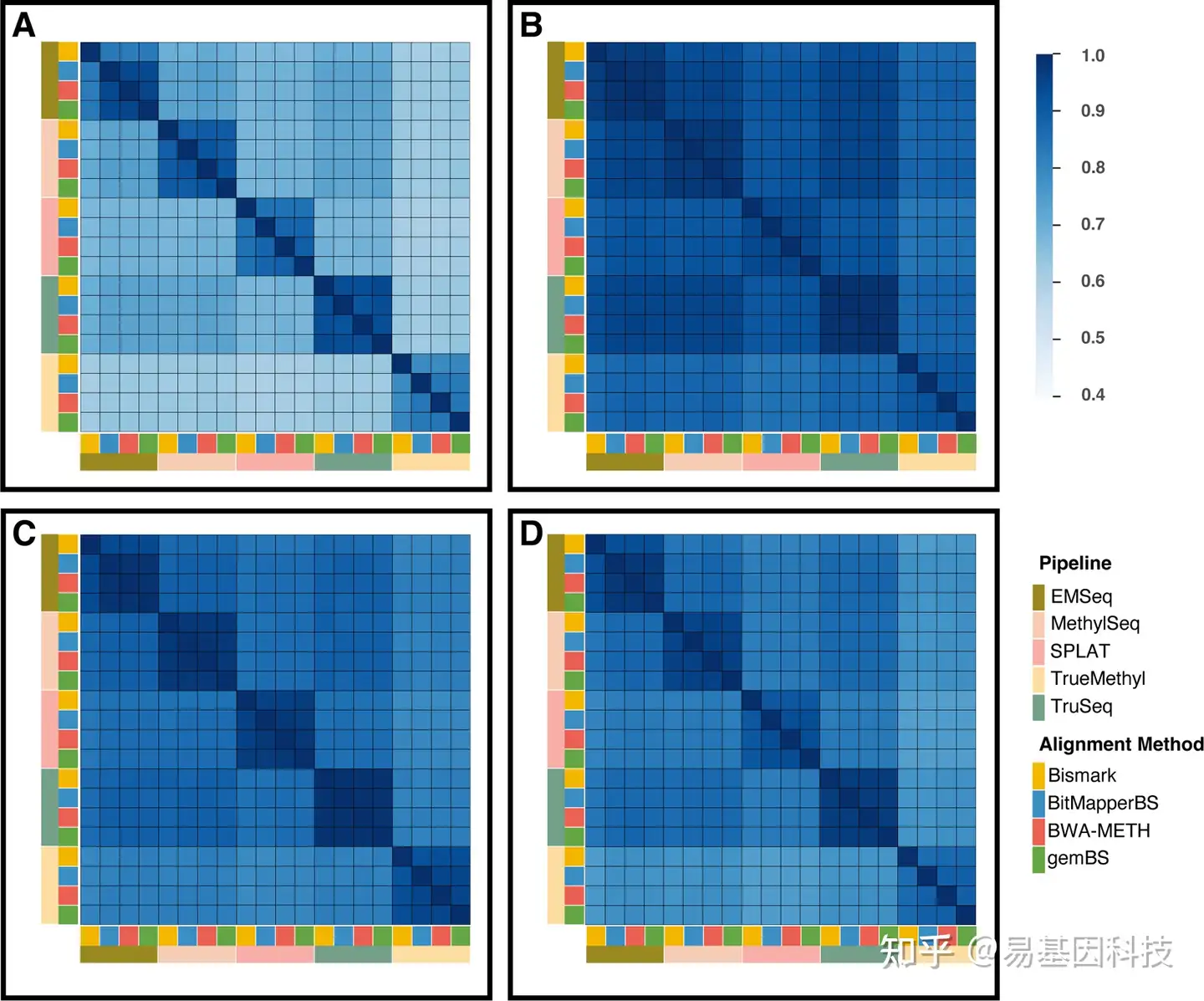
图4:所有 CpG 位点的全基因组甲基化水平的相关性矩阵
(4)比对质量评估(Alignment quality control)
比对后的QC在WGBS中至关重要,WGBS的内在混杂变量会使甲基化估计偏向于过高或过低的估计,主要通过M-bias图来检测。在亚硫酸盐处理过程中可能会发生部分(不完全)甲基化,此时可以观察到C和T的peaks值,这通常会导致检测过高。高于98.5%的比率可以确保没有偏差。可以在所有背景中(CpG、CHG和CHH)向甲基化样本中添加带有未甲基化C的Spike序列,然后计数未甲基化C和T数量,并计算添加序列的转化率。
同时,由于估计过低导致的偏差会捕获到假阴性的甲基化位点。例如,通过酶介导的碎片化双链DNA末端修复会在片段两端引入未甲基化的C,从而导致人为的甲基化水平低估。这在M-bias图中反映为问题两端的平均甲基化水平急剧下降,这应在提取甲基化之前予以丢弃。亚硫酸盐介导的降解是WGBS中偏差的主要来源,因为降解非随机,发生在未甲基化的胞嘧啶上,这些胞嘧啶从文库中舍弃。这导致许多随后的序列偏差和整体甲基化的高估。
(5)甲基化信息提取(Methylation extraction)
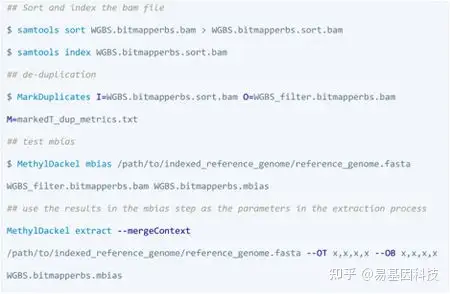
在经过BitMapperBS、BWA-METH、Bismark和GemBS等比对软件进行比对后,推荐利用MethylDackel进行甲基化信息提取。例如用MethylDackel对BitMapperBS比对后的甲基化信息提取。甲基化评估通过比较测序reads和参考基因组进行,如果在参考基因组中某个位点显示为C,在上述位点注意到C时,就分配100%的甲基化,当指示为T时,则分配0%的甲基化。计算加权平均值,并在计算该位点的C和T数量后,将其指定为最终的甲基化水平。如10/10 Cs显示完全胞嘧啶甲基化,6/10 Cs显示部分甲基化(60%),0/10 Cs代表未甲基化胞嘧啶。在提取之前,对两个链中每个位点的平均甲基化水平进行M-bias分析,以识别提取reads时的基本技术偏差作为修剪参考。从理论上讲,reads应该是恒定的,但每对中的第一和第二reads通常在5'和3'端有偏倚。reads中的人为噪声会在提取过程中引发错误的甲基化calling。MethylDackel在顶部和底部线条上给出了修剪建议,这些建议可以作为后续提取的参数。MethylDackel通过比对得到的BAM文件生成bedGraph文件,记录甲基化与未甲基化位点信息,这些可以用来进行数据过滤和进一步数据分析。
数据归一化与统计分析
(1)CpG甲基化
文库制备方法会显著影响每个CpG位点的平均覆盖度。与甲基化芯片数据不同,测序数据没有标准化的归一化方法。但数据归一化对下游差异甲基化检测至关重要。降采样(Downsampling)通过减少reads序列数量,使其与相似序列数据相匹配,从而实现归一化。比对产生的BAM文件和甲基化提取产生的bedGraph文件都可以降采样。在比对阶段降采样可能在时间和内存上要求很高,而在提取阶段降采样则需要较少的时间和内存,同时保证了相似的甲基化calling数量、检测到的CpG位点、reads数分布和平均覆盖度的准确性。因此,在进行进一步的数据比较之前,建议先对bedGraph文件进行降采样,特别是对于差异甲基化区域(DMRs)的检测。
(2)DMR
DMR(差异甲基化区域)检测是核心甲基化分析之一,涉及对多个样本中的基因组区域进行分析。最常见的应用是在癌症和正常样本之间寻找可能作为生物标志物或揭示疾病生物学的异常甲基化区域。基于DMR统计分析方法因软件而异,以下是一些主要方法。
BSmooth:使用局部似然平滑方法(local likelihood smoothing approach)来鉴定样本特异性甲基化信息中的DMR。应用Welch's t-test(Student's t-test变体)比较多个样本。DMR是具有观察到的P值高于预定义β值的CpG位点。然而预定义阈值可能导致II类错误(假阴性),从而影响结果。
BiSeq:通过纳入错误发现率和β二项分布模型来解决这一问题,充分考虑到生物学重复。然后通过triangular kernel模型调整分层过程引起的显著变化,计算目标区域的统计显著性。P值被归一化、转换为z分数、平均值进行比较。
MethylSig:类似于BiSeq,应用β二项分布模型来考虑reads覆盖度和生物学意义。
Metilene:结合了二项分割和多变量Kolmogorov-Smirnov拟合优度检验(K-S 检验)。这种非参数方法使用逐步分割基因组区域,被稳步地最小化到CpG数量少于预定义下限的区域,或在统计显著性上没有改善的区域。这种方法对累积样本分布的差异性更敏感。
methylKit:对单样本情况使用Fisher's精确检验,对多重复样本使用基于logistical回归的统计方法计算组间差异。
Defiant:是一个独立的程序,使用加权Welch扩展鉴定DMR。对于只有一个重复的两个样本,使用Fisher's精确检验,对于有多个重复的样本,使用Welch's t-test,基于覆盖度对无偏样本方差进行加权。
Benjamini-Hochberg:应用于调整DMR鉴定中多重t检验的P值。数据分布本质上是二项的,因为大多数甲基化分布要么是完全甲基化的,要么是完全未甲基化的,表明二项分布模型性能优于其他模型。
由于reads覆盖度变化和人口统计参数(如性别、年龄和种族)的共变异对DMR检测有强相关,因此数据的归一化转换和协变量调整至关重要。
案例研究
WGBS 数据的计算分析具有挑战性,包括分析 FASTQ 读长、甲基化估计、位点注释、DMR 检测和可视化。以下为WGBS数据分析的综合案例研究。
(1)分析工具
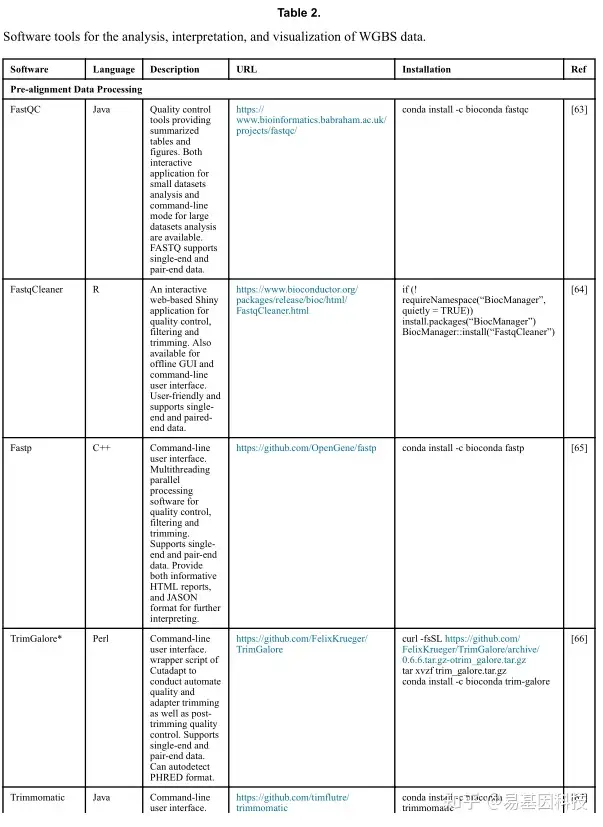
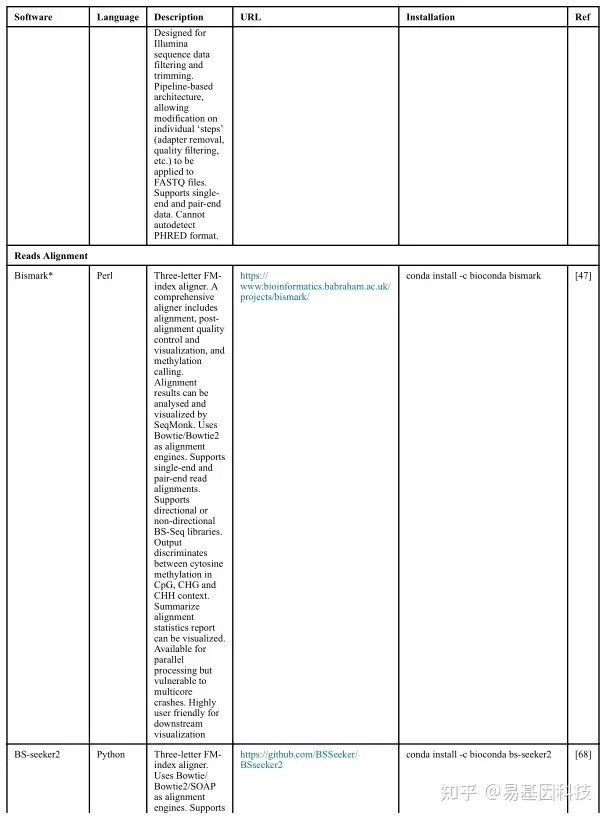
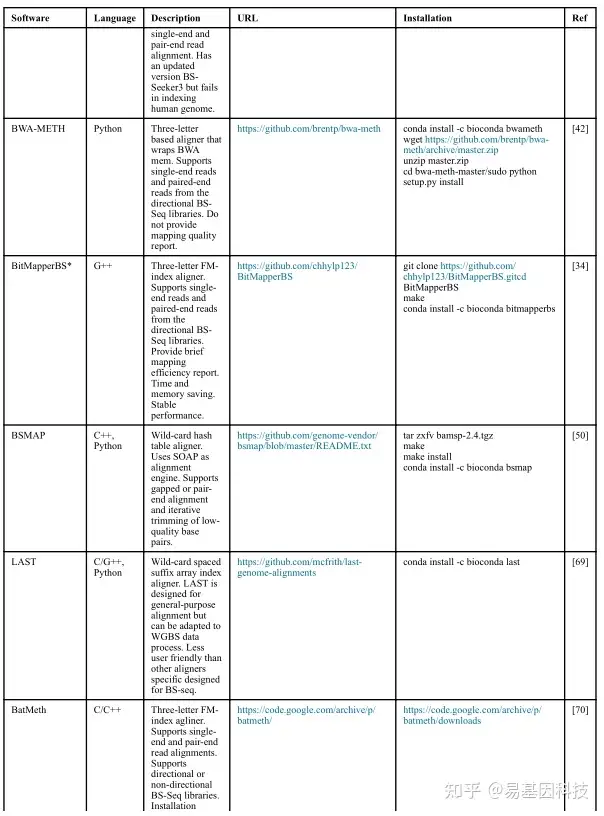
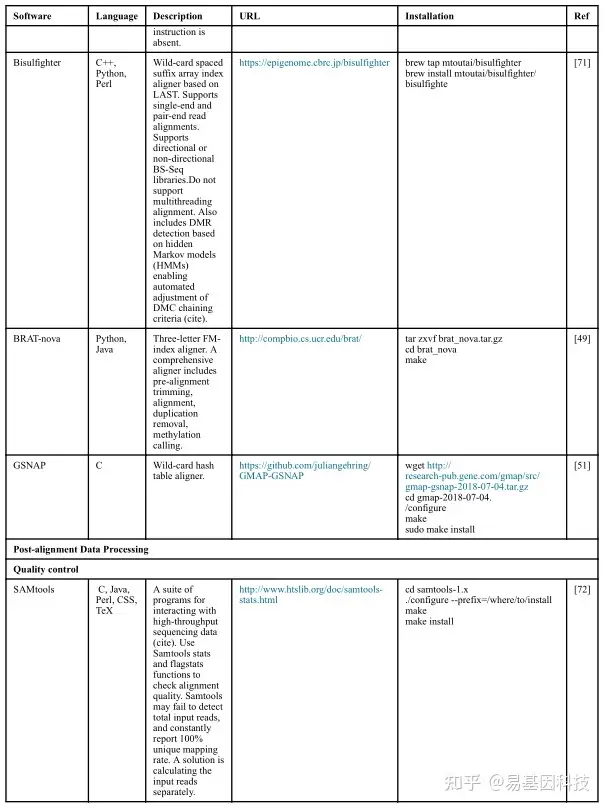
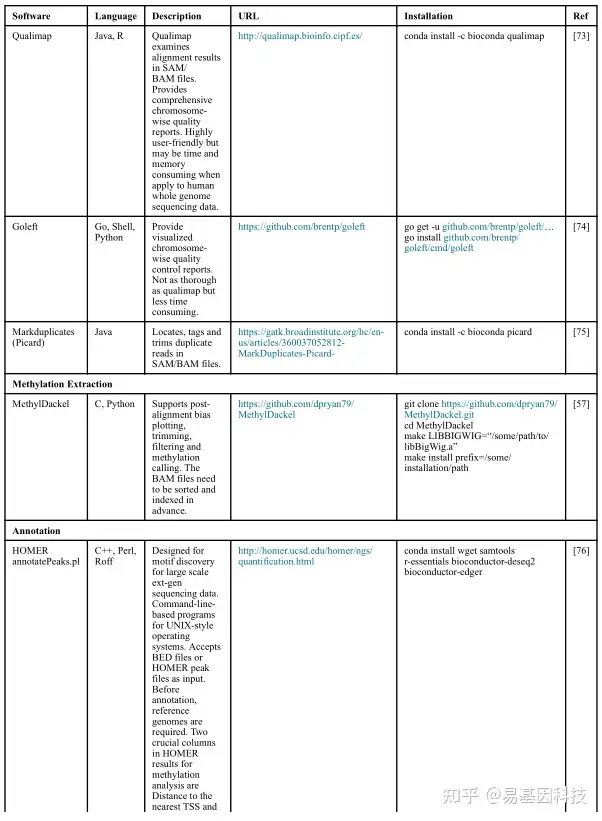
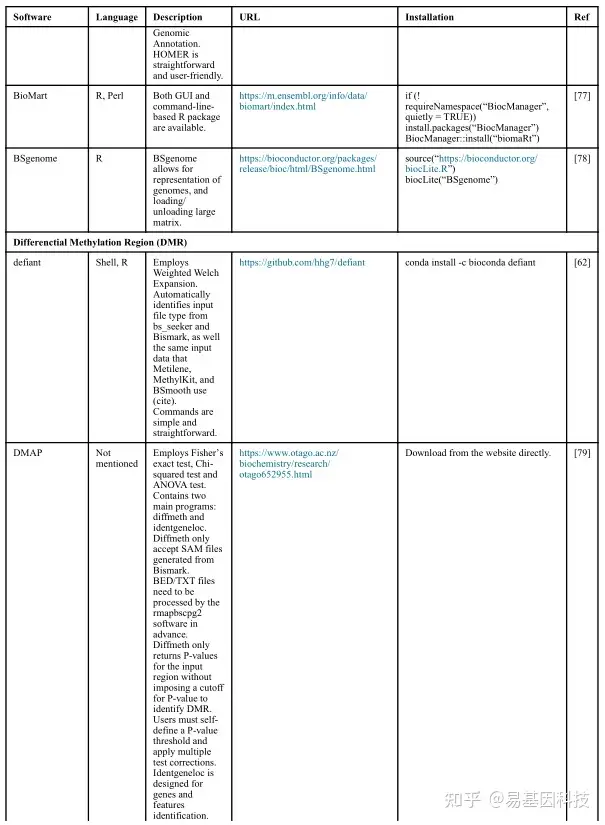
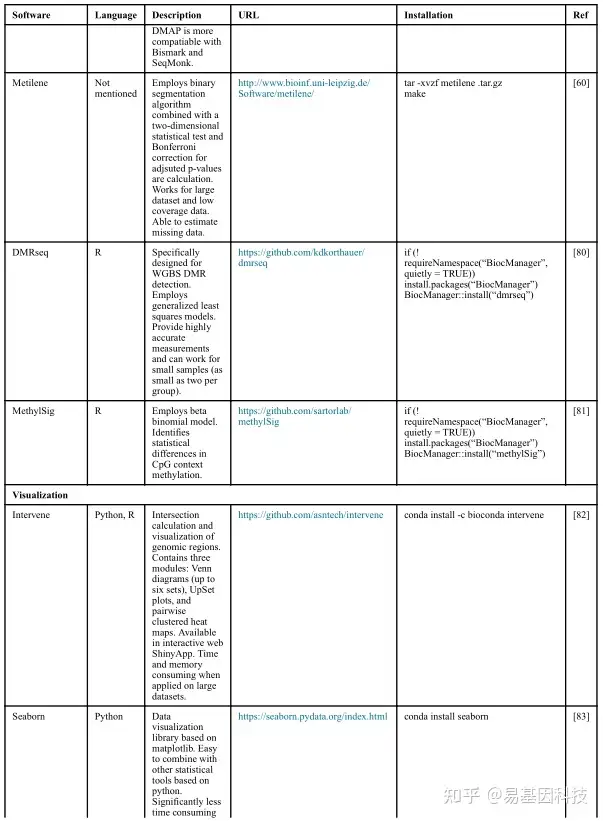
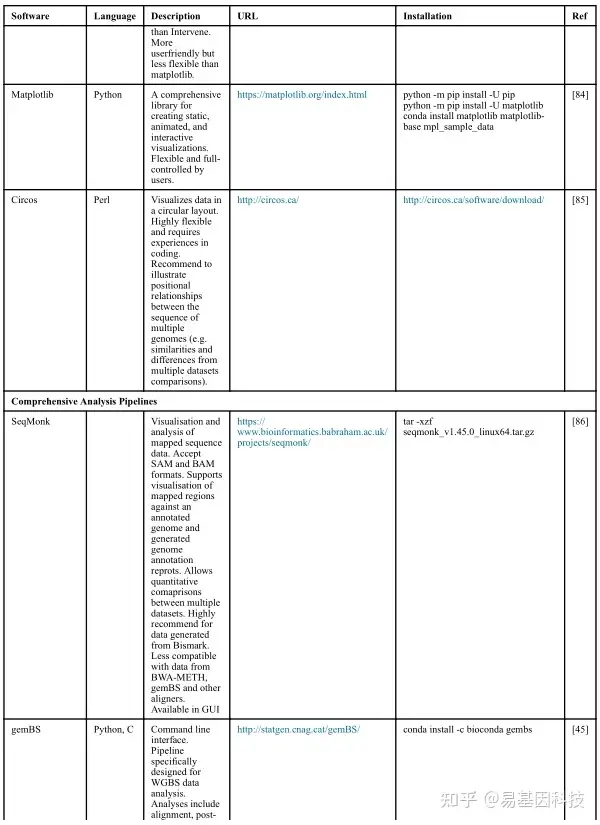
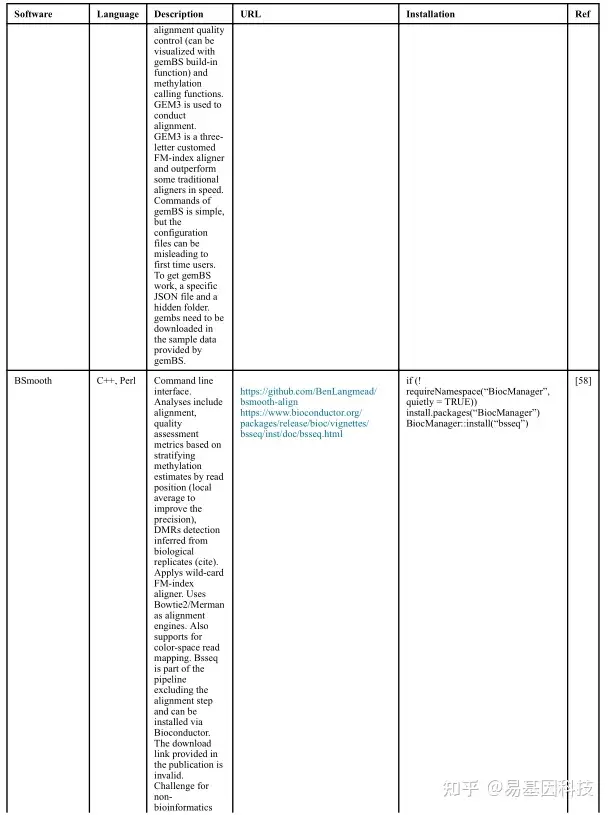
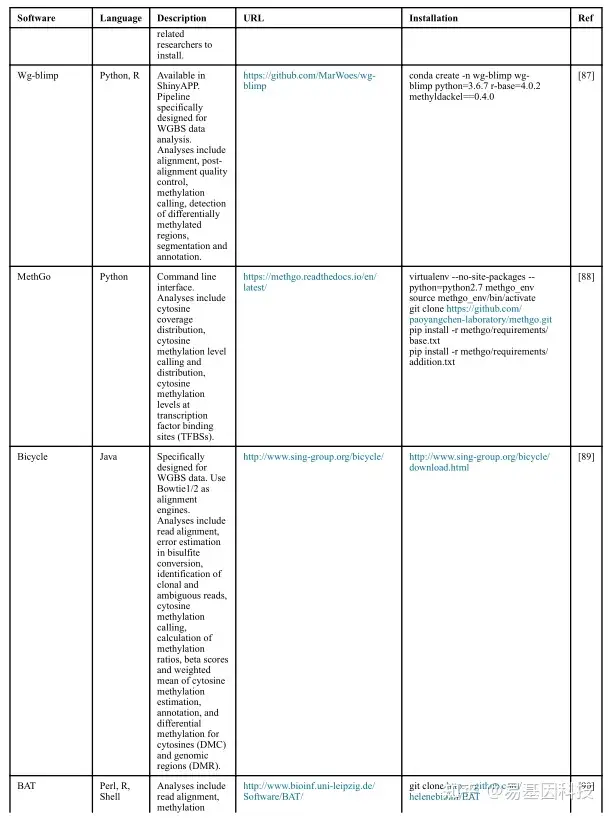
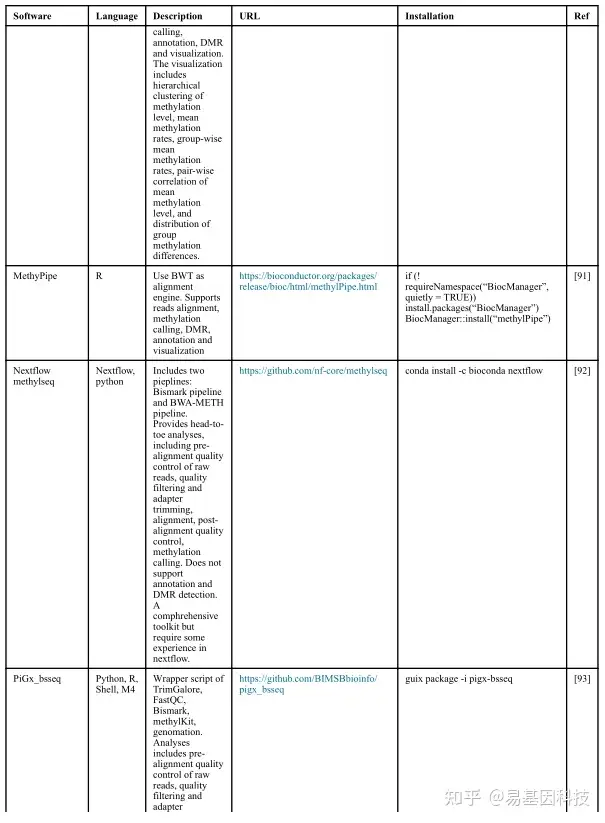
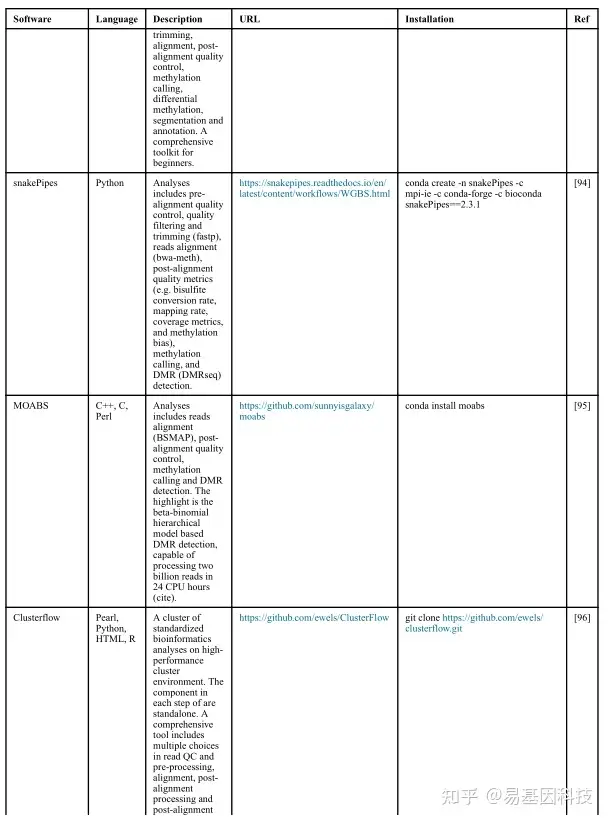

(2)数据分析
① Pre-alignment
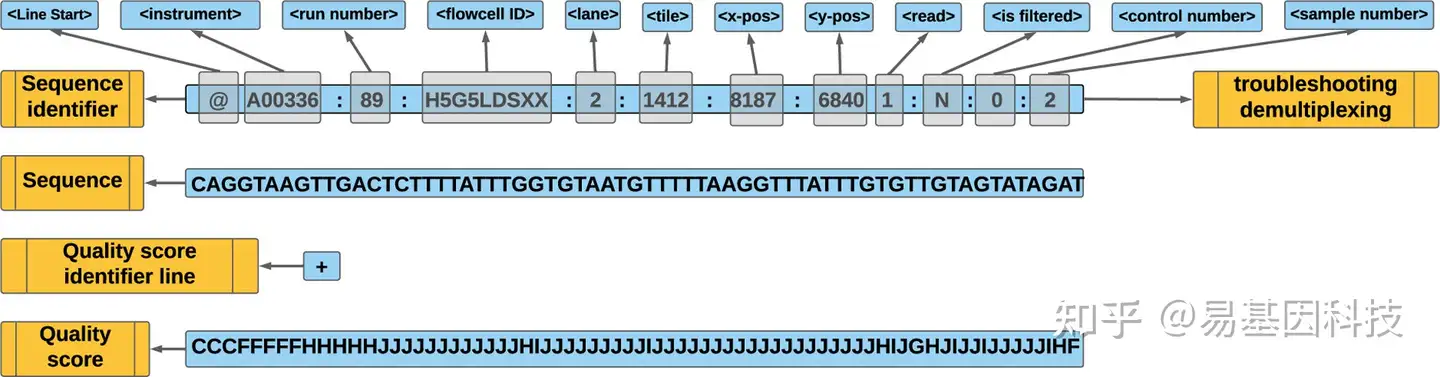
图5:FASTQ 文件元素
使用以下代码检测 R1 (WGBS_R1.fastq) 和 R2 (WGBS_R2.fastq) 读取的原始 FASTQ 质量:
结果包括一个.html格式的摘要和一个带有质量数字的.zip文件夹。MultiQC 将具有多个 FastQC 结果的样品合并到一份.html报告中。
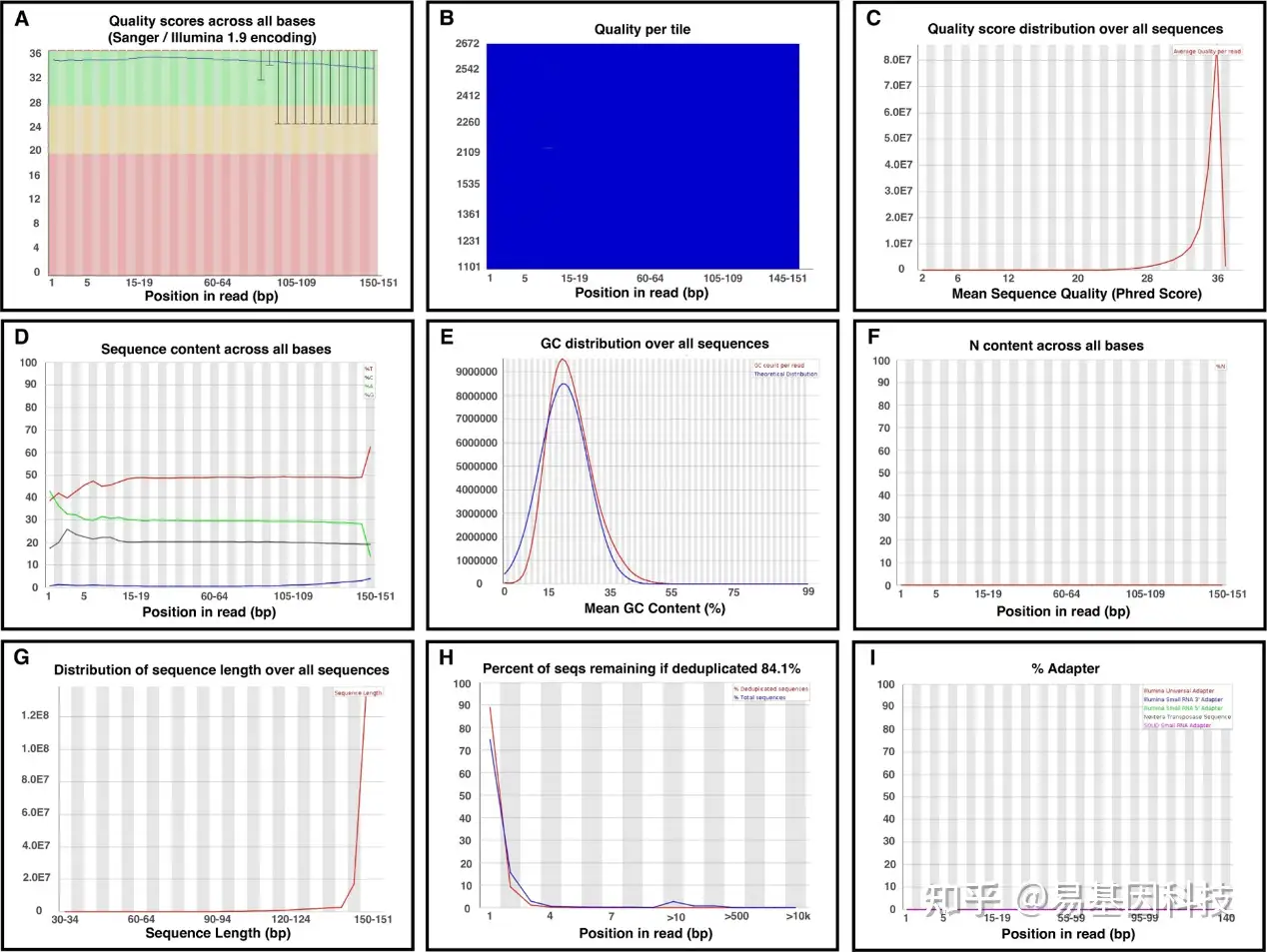
图6:FastQC的质控报告

② reads修剪

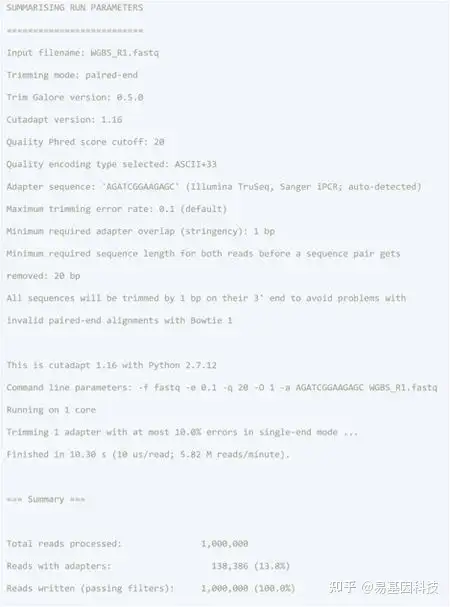
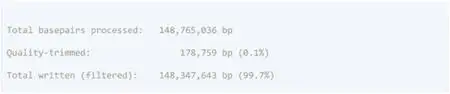
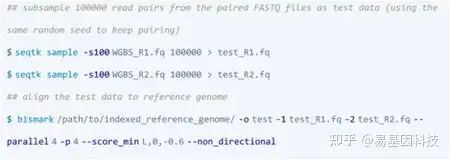
③ 比对和甲基化calling
Bismark:




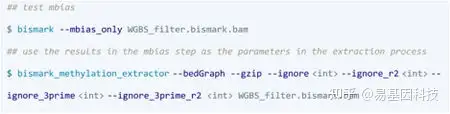
BitMapperBS:

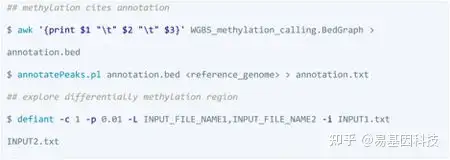
DMR的注释和分析
易小结:
DNA甲基化和其他表观基因组分析的动态标记与不同人类疾病的诊断和预后相关联。对甲基化结果的深刻且低偏倚解释是下游生物学机制研究的核心。本综述讨论了分析WGBS数据的计算方法,并介绍了使用现有工具从原始reads检测DMR所需的基本QC分析步骤。此外,还提出了甲基化文库制备和数据处理中固有的潜在混杂因素及其对策。希望潜在用户能够理解WGBS的基本概念,从而加速人类疾病的发现。
关于易基因全基因组重亚硫酸盐测序(WGBS)
全基因组重亚硫酸盐甲基化测序(WGBS)可以在全基因组范围内精确的检测所有单个胞嘧啶碱基(C碱基)的甲基化水平,是DNA甲基化研究的金标准。WGBS能为基因组DNA甲基化时空特异性修饰的研究提供重要技术支持,能广泛应用在个体发育、衰老和疾病等生命过程的机制研究中,也是各物种甲基化图谱研究的首选方法。
易基因全基因组甲基化测序技术通过T4-DNA连接酶,在超声波打断基因组DNA片段的两端连接接头序列,连接产物通过重亚硫酸盐处理将未甲基化修饰的胞嘧啶C转变为尿嘧啶U,进而通过接头序列介导的 PCR 技术将尿嘧啶U转变为胸腺嘧啶T。
应用方向:
WGBS广泛用于各种物种,要求全基因组扫描(不错过关键位点)
- 全基因组甲基化图谱课题
- 标志物筛选课题
- 小规模研究课题
技术优势:
- 应用范围广:适用于所有参考基因组已知物种的甲基化研究;
- 全基因组覆盖:最大限度地获取完整的全基因组甲基化信息,精确绘制甲基化图谱;
- 单碱基分辨率:可精确分析每一个C碱基的甲基化状态。

易基因提供全面的表观基因组学(DNA甲基化、DNA羟甲基化)和表观转录组学(m6A、m5C、m1A、m7G)、染色质结构与功能组学技术方案(ChIP-seq、ATAC-seq),详询易基因:0755-28317900.
相关阅读:
1. Cell|易基因微量DNA甲基化测序助力中国科学家成功构建胚胎干细胞嵌合体猴,登上《细胞》封面
2. Nature | 易基因DNA甲基化测序助力人多能干细胞向胚胎全能8细胞的人工诱导3. WGBS+RNA-seq揭示黄瓜作物的“源-库”关系受DNA甲基化调控
4. WGBS等揭示SOX30甲基化在非梗阻性无精症中的表观遗传调控机制
5. WGBS+RNA-seq揭示PM2.5引起男性生殖障碍的DNA甲基化调控机制
6. WGBS+RNA-seq揭示松材线虫JIII阶段形成过程中的DNA甲基化差异
7. 微量DNA甲基化分析揭示MeCP2在卵子发生和卵巢衰老中的表观遗传调控
8. 单细胞DNA甲基化与转录组分析揭示猪生发泡卵母细胞成熟的关键调控机制
9. 植入前胚胎的全基因组DNA甲基化和转录组分析揭示水牛胚胎基因组激活进展
10. 微量DNA甲基化分析揭示MeCP2在卵子发生和卵巢衰老中的表观遗传调控
13. 微量样本及单细胞DNA甲基化研究如何发高分SCI文章(特别适用珍稀样本)
参考文献:
1、Gong T, Borgard H, Zhang Z, Chen S, Gao Z, Deng Y. Analysis and Performance Assessment of the Whole Genome Bisulfite Sequencing Data Workflow: Currently Available Tools and a Practical Guide to Advance DNA Methylation Studies. Small Methods. 2022 Mar;6(3):e2101251. doi: 10.1002/smtd.202101251. PubMed PMID: 35064762.
标签:DNA,测序,基因组,甲基化,reads,WGBS From: https://www.cnblogs.com/E-GENE/p/18306986