title: "Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?"
tags:
- paper
Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
Abstract
Building 3D perception systems for autonomous vehicles that do not rely on high-density LiDAR is a critical research problem because of the expense of LiDAR systems compared to cameras and other sensors. Recent research has developed a variety of camera-only methods, where features are differentiably "lifted" from the multi-camera images onto the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. This line of work has produced a variety of novel "lifting" methods, but we observe that other details in the training setups have shifted at the same time, making it unclear what really matters in top-performing methods. We also observe that using cameras alone is not a real-world constraint, considering that additional sensors like radar have been integrated into real vehicles for years already. In this paper, we first of all attempt to elucidate the high-impact factors in the design and training protocol of BEV perception models. We find that batch size and input resolution greatly affect performance, while lifting strategies have a more modest effect -- even a simple parameter-free lifter works well. Second, we demonstrate that radar data can provide a substantial boost to performance, helping to close the gap between camera-only and LiDAR-enabled systems. We analyze the radar usage details that lead to good performance, and invite the community to re-consider this commonly-neglected part of the sensor platform.
Comments
ICRA 2023
分割任务
LSS类的方法中,如果深度估计非常完美,那么3D中只有物体的可见面会被feature占据,而不是整个物体被占据,类似lidar的扫描
Q&A
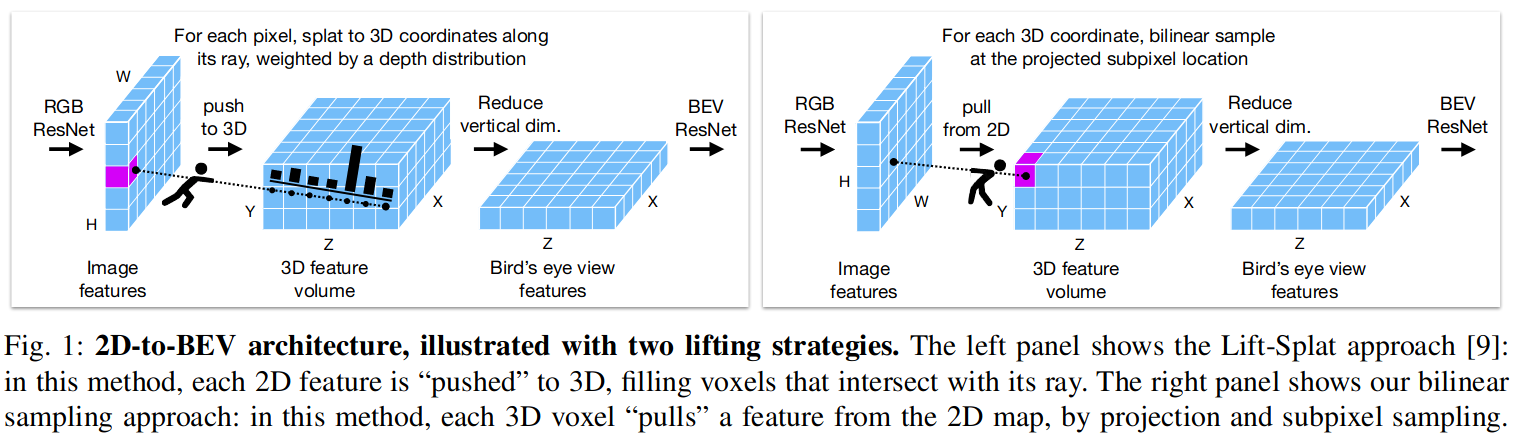
0.怎样获得BEV feature的?
- 在相机坐标系构建一个3D空间,X左右 Y上下 Z前后, 3D空间range
100mx10mx100m3Dfeature 尺寸200x8x200 - camera image经过backbone得到feature,\(3\times H\times W \to C\times H/8\times W/8\)
- 把预先定义好的3D坐标投影到所有的2D feature,使用双线性差值得到3D位置的feature
- 计算每一个3D坐标是否在每一个camera的视锥内 得到一个valid mask
- 因为同一个3D点可能同时投影到多个相机中,使用valid-weighted average处理3D空间中的feature,得到\(C\times Z\times Y\times X\) 在高度方向压缩得到\((C\times Y)\times Z\times X\)
LS without depth estimation
sampling:
因为预先定义好的3D空间是均匀采样的,由于相机投影,距离相机光心近处的3D位置从图像中采样得非常稀疏(即更分散),而远处的3D位置采样得非常密集(即更挤在一起),但每个体素都会接收到一个2D特征,除了那些不在相机fov范围内的
LS
基于Splatting的方法 从 2D 坐标网格开始,沿其光线“shoot”每个像素,以固定的深度间隔填充与该光线相交的体素。因此,LS方法会为近距离体素产生多个样本,而为远处体素产生很少的样本(有时为零)每一个像素点一条射线,近处射线之间很致密,远处就很稀疏了
LSS在短距离上稍微优越,而采样在长距离上稍微优越
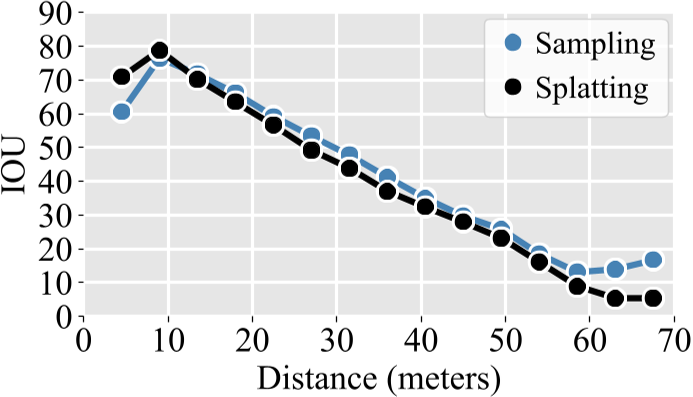
simpleBEV 需要做32w次采样才能得到单个camera的3Dfeature?
1.batch size和输入分辨率对模型性能有何影响
1.1 图片分辨率
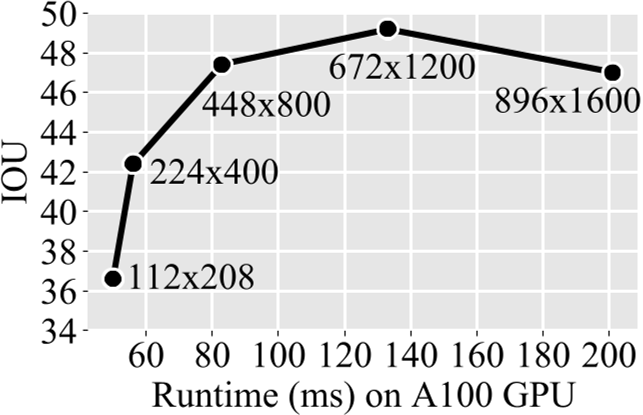
在不更改backbone的情况下,根据实验结果672x1200的模型获得了最高的性能,但是增加到896x1600后性能有所下降,更换backbone也许会解决性能下降的问题
1.2 batchsize
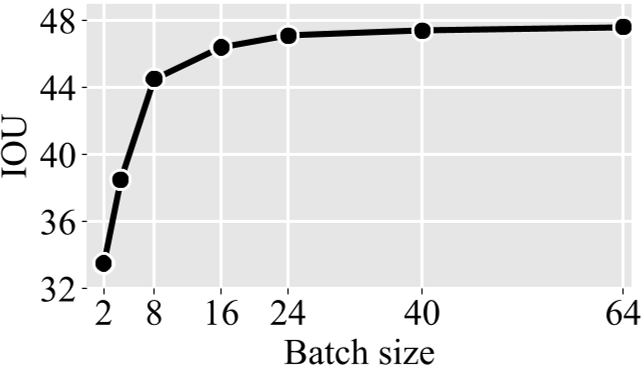
逐步增加batch size 性能会逐步提升 但是回报率越来越低
2.为什么说不同的2DTo3D转换方法对模型性能影响很小?
没有细说
3.怎样将radar和camera融合的,对camera-only的模型有何影响
如果提供了radar信息,将其编码成和2D bev相同大小的BEV feature \(R\times X\times Z\), R代表radar的特征维度,等于0表示不使用radar
nuscene提供的radar点有18维信息,其中5维是位置和速度信息 x y z vx vy,其他是内置处理器的信息
把radar点栅格化,投影到距离最近的grid中,使用除了位置之外的15维信息编码radar,得到\(R\times X\times Z, R=15\)大小的feature,将其和RGB BEV concatenate在一起再经过一个3x3卷积得到维度维C的BEV feature: \((R+C\times y)*Z\times X\to C\times Z\times X\)

key:
- 不使用nuscene提供做过滤波的radar点,使用原始点,filter可能会把一些TP滤除
- 将连续3帧的radar点叠加在一起使用 避免单帧太稀疏
Pipeline
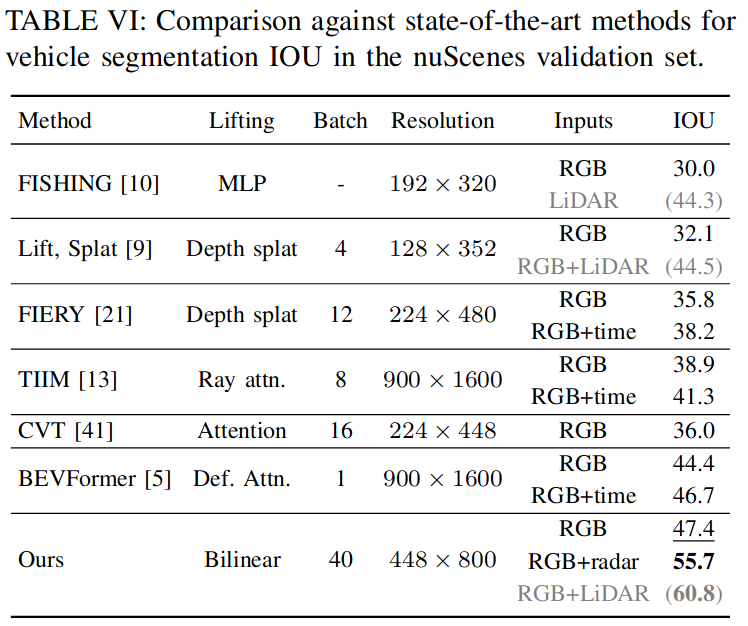
Performance