zotero-key: 5HGRISJQ
zt-attachments:
- "786"
title: "BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View"
citekey: huangBEVDetHighperformanceMulticamera2022b
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Abstract
Autonomous driving perceives its surroundings for decision making, which is one of the most complex scenarios in visual perception. The success of paradigm innovation in solving the 2D object detection task inspires us to seek an elegant, feasible, and scalable paradigm for fundamentally pushing the performance boundary in this area. To this end, we contribute the BEVDet paradigm in this paper. BEVDet performs 3D object detection in Bird-Eye-View (BEV), where most target values are defined and route planning can be handily performed. We merely reuse existing modules to build its framework but substantially develop its performance by constructing an exclusive data augmentation strategy and upgrading the Non-Maximum Suppression strategy. In the experiment, BEVDet offers an excellent trade-off between accuracy and time-efficiency. As a fast version, BEVDet-Tiny scores 31.2% mAP and 39.2% NDS on the nuScenes val set. It is comparable with FCOS3D, but requires just 11% computational budget of 215.3 GFLOPs and runs 9.2 times faster at 15.6 FPS. Another high-precision version dubbed BEVDet-Base scores 39.3% mAP and 47.2% NDS, significantly exceeding all published results. With a comparable inference speed, it surpasses FCOS3D by a large margin of +9.8% mAP and +10.0% NDS. The source code is publicly available for further research at https://github.com/HuangJunJie2017/BEVDet .
Comments
BEVDet是很多公司BEV方案的基础,弄懂BEVDet的pipepline很重要
Q&A
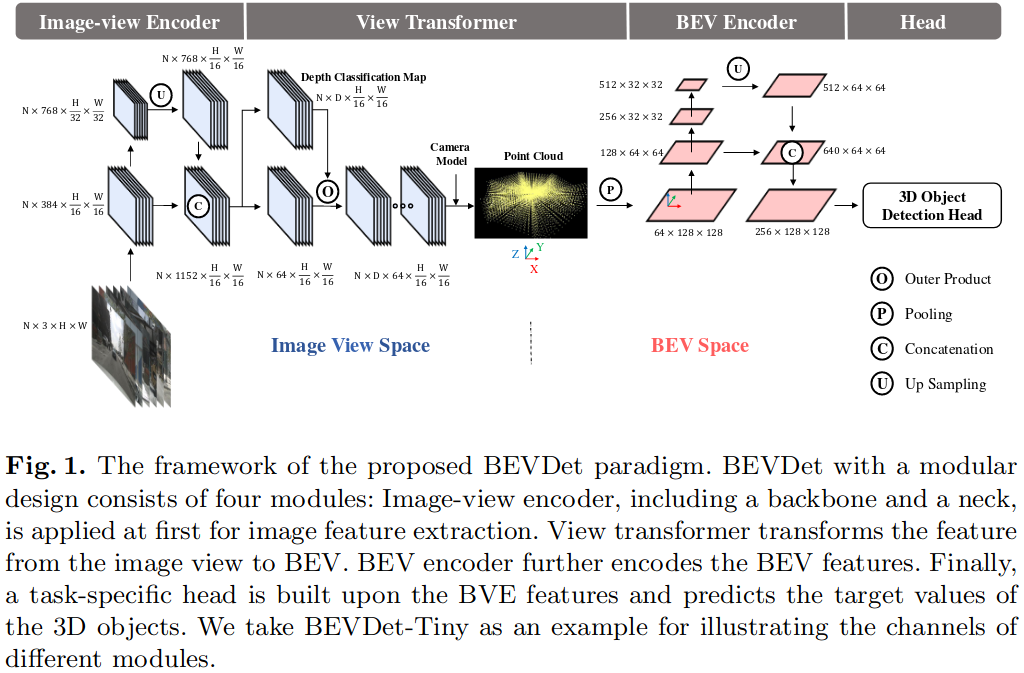
1.是怎样将多视图图像转换到BEV视角下的
基于LSS的方法
input: image-view的feature
通过分类方式密集预测深度,然后,使用分类分数和image-view的feature来渲染预定义的点云,
最后在点云的z轴做pooling得到bev feature
LSS中获取BEV feature是通过对每一个pillar中的feature进行 cumsum实现的sum_pooling,但是该操作的推理延迟与总体点数成正比,最后得到的feature越大,需要遍历的点就越多,LSS需要的时间也就越多

Voxel pooling
为了删除这个耗时的操作,BEVDet引入了一个辅助索引来记录相同的体素索引之前出现过多少次
有了这个辅助索引和体素索引,将点分配到一个二维矩阵中,并通过单独的辅助轴的求和运算将同一体素内的特征组合起来。
在推理时相机内外参数固定的前提下,辅助索引和体素索引固定,可以在初始化阶段计算
值得注意的是,这种修改需要额外的内存,该内存由体素的数量和辅助索引的最大值决定。在实践中,我们将辅助指标的最大值限制为300,并删除剩余的点。该操作对模型精度的影响可以忽略不计
2.数据增强方法做了哪些创新?
2.1 image视角下的数据增强
给定图像中的一个像素点\(p_{image}=[x_i,y_i,1]^T\) ,其深度为\(d\),camera 内参是\(I\in R^{3\times 3}\) 那么其在3D空间camera坐标下的坐标\(p_{camera}\)可以通过下式计算:
\[p_{camera} = I^{-1}(p_{image}*d) \]图像中常用的数据增强手段 fliping, cropping,rotating都可以表示为一个\(3\times 3\)的转移矩阵 \(A\):
The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
假设图像大小\(h*w\)
horizon flip:
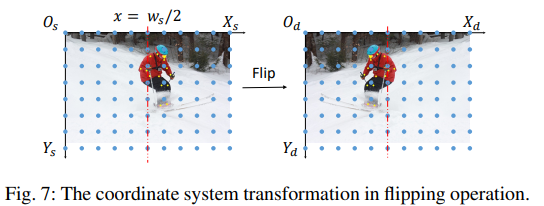
\((x,y)\to (w-x,y)\)
rotating
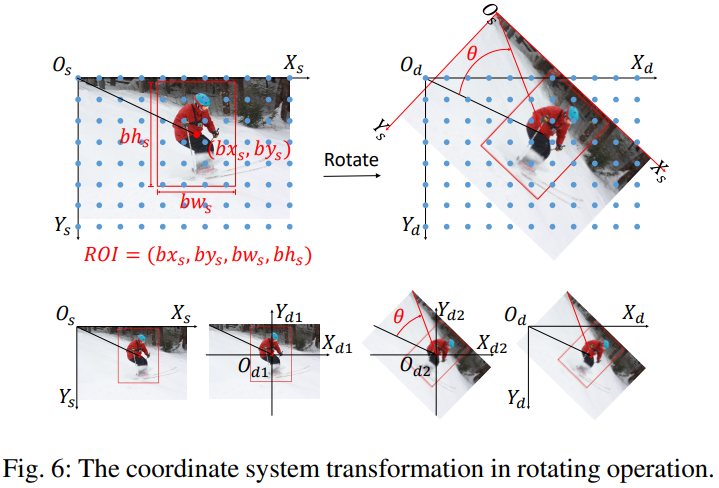
围绕roi的中心进行旋转,分为三步:
-
将坐标系上下翻转,并移动到旋转中心
-
顺时针旋转指定角度 \(\theta\)

-
再把坐标系翻转回去,即1的逆操作,roi的中心在旋转前后坐标不变
矩阵形式:
resizing
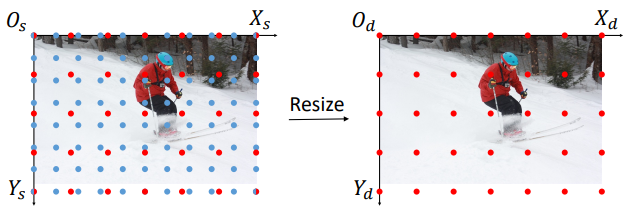
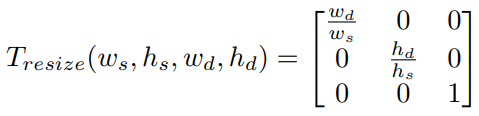
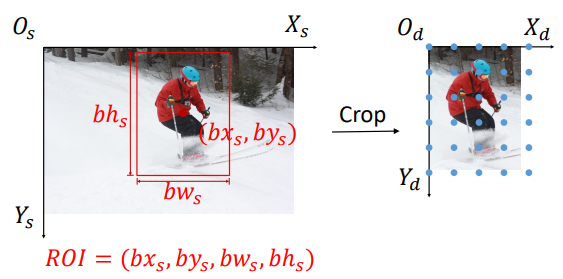
cropping
把源坐标原点移动到roi的左上角
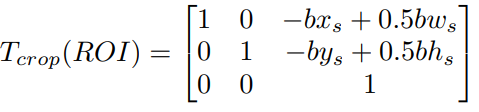
对输入图像做数据增强后得到 \(p_{image}'=Ap_{image}\)
在LS时为了保持feature和BEV空间中对应点的空间一致性,需要对图像做逆变换
因此图像空间中应用的数据增强策略不会改变BEV空间中特征的空间分布
这里等式成立的前提是预测的depth在数据增强前后保持一样,可以保证吗?
2.2 BEV空间下的数据增强
multi-camera的配置下,图像空间每一个样本有多个相机的照片,但是BEV只有一个,由于缺少数据,BEV空间下的学习很容易陷入过拟合;
使用3D目标检测中常用的数据增强手段:flipping, scaling, and rotating.
值得注意的是,这种数据增强策略是建立在视图转换器能够将图像视图编码器与后续模块解耦的前提下的;
但是BEV空间下进行数据增强得到的feature和实际采集得到的feature应该也是不一样的
比如旋转后,yaw是0的car变化到了旋转后的yaw,但是可以观测到的面是不会变的,与实际情况不符
现在来看使用Nerf是一个比较好的选择
数据增强消融实验:
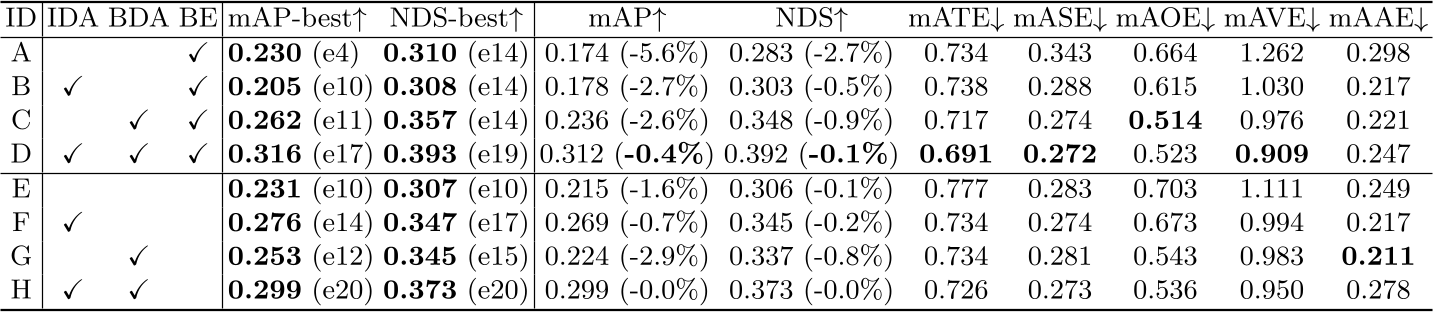
左边第三列是性能最好的epoch,第四列是最后一个epoch的结果,括号中的数值是相比与最好的结果,下降了多少
在使用BEV-Encoder的情况下,
A 不做任务数据增强,第四个epoch之后就开始过拟合
B 仅仅使用图像数据增强,过拟合现象被推迟到了第10个epoch,但是最佳性能比A还要差,有负面影响
C 仅仅使用BEV下的数据增强,过拟合现象被推迟到了第11个epoch,最佳性能提升了很多,BDA比IDA重要很多,也暗示很多lidar的改进也许可以移植到bev中
D 全部DA都使用,性能最佳
在不使用BEV-Encoder的情况下,IDA对性能有正面的提升
推测是BEV Encoder的强大感知能力只能建立在BDA的存在之上
也许image encoder和bev-encoder做的事情是不一样的,end2end来训练的情况下,只做IDA,使它们的不一致更加严重,不是很好解释为什么IDA+BDA性能是更好的
3.NMS做了哪些改进
不同类别的物体在图像空间中的空间分布与在BEV下的空间分布很不一样。
在图像视图空间中,由于相机的透视成像机制,所有类别都具有相似的空间分布
由于透视成像,model的输出结果之间天然的会有较大的overlap,直接表现为在gt的位置会有大量的检测框,而另外的gt的检测框会离得比较远,这时利用传统的NMS,使用固定的iou阈值,便可以将得分较高的只保留一个
但是在BEV下,不同类别物体之间的IoU差异很大,有些类别的检测框之间的IoU有可能是0
现有的目标检测范式,倾向于输出更多的框,通过NMS等后处理滤除多余的框。
对于BEV下的pedestrian、cone检测来说,它们的size大小有可能小于网络输出的分辨率,这就会导致在gt附近的检出框之间的IoU很小,甚至是0,FP无法被NMS滤除
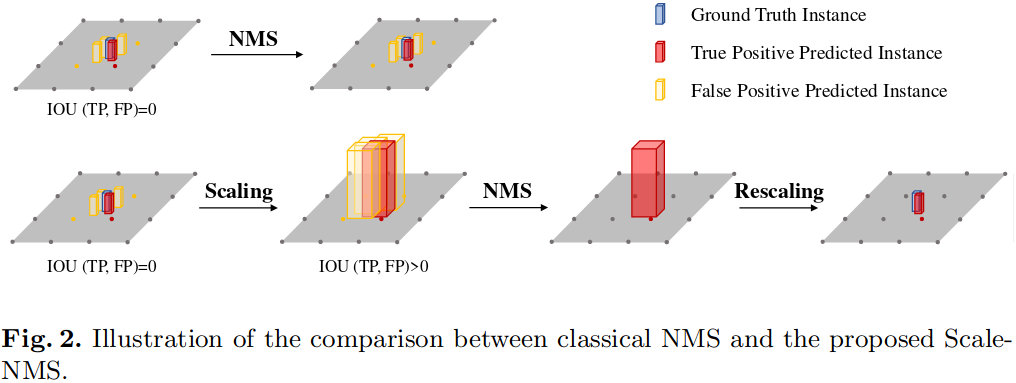
为此提出了scale-NMS,在进行经典的NMS之前,先根据类别对不同的检测框进行大小的缩放,这样TP和FP之间的IoU就会与NMS需要的阈值匹配上了
scale的系数是通过在验证集上进行超参数搜索生成的。
scale-NMS确实有点道理,对于3D检测是通用的,但是在拥堵场景下是不是会滤掉TP 造成FN?

pedestrian提升很多
4.BEVDet中的训练过拟合出现的原因以及解决方法
数据增强中有说明
与camera图片相比,BEV视角在同一个batch中缺少训练数据
Pipeline