前言
其实很早就看到过了,下定决心去学的,居然是因为翻到之前口胡的题目,然后发现之前做法假了,继续尝试做的时候发现需要这个算法,于是,题目就绿->黑了。
Step.1 引入
求一个数的所有因数,这个问题伴随了我们很久了,现在又要翻出来鞭尸。
最开始的时候,我们使用的是最朴素的 \(O(n)\) 试除法,即一个数一个数去试,但是当 \(n\) 超过 \(10^8\) 或者更大的时候就不太现实了,于是我们学习了 \(O(\sqrt n)\) 的改进版试除法,只在 \([1,\sqrt n]\) 之间尝试,找到了就可以找到其在 \([\sqrt n,n]\) 之间唯一对应的因数,因此只需要试 \(\sqrt n\) 次,同样地,当 \(n\) 超过 \(10^{16}\) 时,也变得不现实。
现在,我们需要解决的便是这样一个问题。
Step.2 从悖论出发
悖论,即数学模型与平时的经验产生了极大的反差。
这里将举出几个例子:
生日悖论,如果一共有 \(k\) 人,设 \(p\) 为存在两个人生日相同的概率,不考虑闰年,那么当 \(k\) 达到 \(23\) 人的时候,\(p\) 就已经超过了 \(0.5\)。
如果你没有听过,那么这个悖论可能会让你难以置信,我们不妨来简单计算一下概率。
直接计算 \(p\) 是不方便的,我们可以求不存在两个人生日相同的概率,第一个人的生日是随便的,第二个人不能和第一个人一样,概率为 \(\frac {364}{365}\),第三个人不能和前两个人一样,概率为 \(\frac {363}{365}\),依此类推,再将所有的概率乘在一起。
可以得到一个 \(k\) 个人时的通式 \(\prod_{i=1}^k \frac{365-i+1} {365}\)。
当 \(k\) 取 \(23\) 的时候,就是 \(\frac{365!}{342!\times 365^{23}}\)。
通过计算机可以得到答案为 \(0.4927\),那么 \(p\) 就是 \(1-0.4927=0.5073\),已经超过一半。
如果我们再把 \(k\) 扩大,扩大到 \(50\),答案约为 \(0.0296\),已经非常小了,\(p\) 则已经超过了 \(0.97\)。
再来一个例子,如果我们在 \([1,1000000]\) 中等概率地随机选一个数,那么刚好选到 \(114514\) 的概率只有 \(\frac 1 {1000000}\),但是如果我们选择两个数 \(a\) 和 \(b\),那么满足 \(|a-b|=114514\) 的概率就会提升很多,比 \(\frac 1 {500000}\) 要小一些。
可以感性理解,如果我们选择了一个数 \(a\),那么满足条件的 \(b\) 可以是 \(a-114514\) 也可以是 \(a+114514\),当然了如果 \(a\) 较小或者较大,则只有一种方式合法,所以比 \(\frac 1 {500000}\) 要小一些。
可以发现,我们直接等概率取,想要取到特定的值概率会较小,但是如果我们取多个,并通过限制,也就是扩大范围,就可以有效地让概率提升。
更进一步,我们在一个范围内随机生成数,每多生成一个数,就等于多了一个限制条件,那么想要生成两个相同的数,需要的数期望会很少,可以参考知乎的这个回答,在 \([1,n]\) 范围内,每次随机选择一个数,在出现重复数字之前,期望会选择 \(\sqrt \frac{\pi n} 2\) 个数。
Step.3 基于随机数的“乱搞”做法
回到我们需要求的问题,找到 \(n\in[1,10^{18}]\) 的因数。
首先,可以直接随机,然后判断是否是因数,但是这样做概率实在太小了,最坏情况甚至会一直找不到,显然还不如 \(O(\sqrt n)\) 优秀。
所以考虑扩大范围,来让概率尽可能地提升。
可以发现,我们原本的随机实际上是有损失的,比如:\(n=24\),随机的数是 \(18\),显然,\(18\) 不是 \(24\) 的因子,但是它们都共同拥有因子 \(6\),所以我们可以尝试通过最大公因数找因子。
假设随机到的数是 \(p\),那么 \(\gcd(p,n)\) 就一定是 \(n\) 的因子,当然,\(\gcd(p,n)=1\) 的情况是无意义的。
所以我们完全可以通过 \(\gcd(p,n)\) 去寻找因数,这样提升的概率是很显著的。
对于合数,与它互质的数字个数不是很多,但是想要保证概率还是困难的。
想到悖论的第二个例子,我们可以选择若干个数 \(x_i\),通过计算 \(\gcd(|x_i-x_j|,n),i\not = j\) 来寻找 \(n\) 的因子,可以证明(虽然我不会),大约选择 \(n^{\frac 1 4}\) 个数字就可以有大概率找到至少一个因子。
但是显然,如果选择那么多个因子,再两两相减找因子,那复杂度又退化到了 \(O(\sqrt n)\)。这不是吃饱了没事干吗
不过不需要着急,直到现在,都还没有出现本次的主题 Pollard-Rho 呢。
Step.4 Pollard 随机数立大功
Pollard 构造了一个伪随机数生成的函数:\(f(x)=(x^2+c)\bmod n\),其中 \(c\) 是一个随机常量。
然后通过递归生成随机数,如,从 \(x_0\) 开始生成随机数,其中 \(x_0\) 可以任意选择,然后就可以用以下规则生成随机数,\(x_i=(x_{i-1}^2+c)\bmod n\)。
因为每次生成都会对 \(n\) 取模,所以值域是固定的,在经过若干次生成后,必然会陷入一个循环,形成的序列很像 \(\rho\),所以叫做 Pollard-Rho。
下图就是我随手画的 \(n=10000,c=23\) 的图(很丑,将就看):
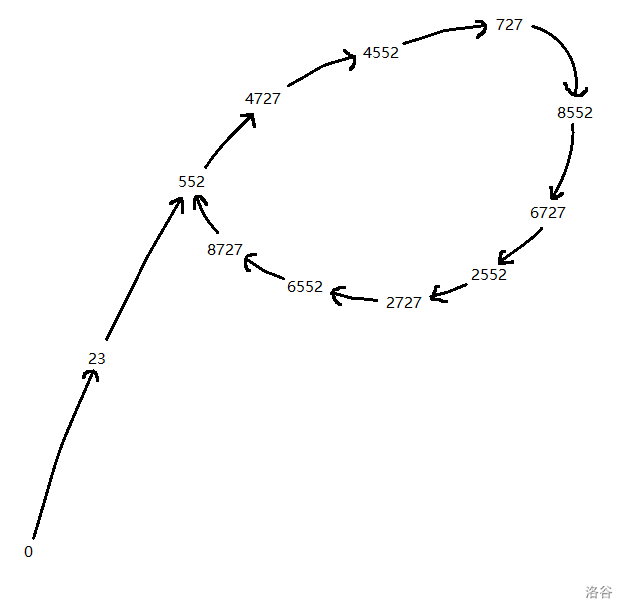
事实上,说这个序列长得像 \(\rho\) 我觉得有点牵强,他的真实含义应该是,前面有部分序列不是循环节,后面是循环节的意思,\(\rho\) 应该是一个比较形象的比喻。
就是因为存在环,所以这是一个伪随机生成函数。
那么,为什么不使用现在比较常用的随机数生成方法,而专门构造一个生成方式呢?
这是因为按照这种方式生成的序列具有一个很重要的性质:对于所有的 \(x,y\),如果满足 \(x\equiv y \pmod p,p\mid n\),那么就有 \(f(x)\equiv f(y) \pmod p\)。
证明比较简单,先令 \(x=ap+d,y=bp+d,a,b\in \mathbb{Z},d\in [0,p)\)。
那么,对于 \(f(x)=x^2+c\),我们可以将 \(x=ap+d\) 代入得到,\(f(x)=(ap+d)^2+c=(ap)^2+2apd+d^2+c\)。
那么 \(f(x)\bmod p=d^2+c=f(d)\)。
同理,\(f(y)\bmod p=f(d)\)。
所以 \(f(x)\equiv f(y) \bmod p\)。
这个性质的作用非常大,但是目前我们还用不到,将会在下一步出现,不过,同样的,如果某个随机数生成方法也有这个性质,那么也可以使用这个随机数生成方法,但是一般情况 Pollard 的随机数生成方法已经足够优秀了。
那么,我们将 \(p\) 选择为 \(n\) 的最小非 \(1\) 因子,那么显然 \(p<\sqrt n\)。
根据前面的理论,所有的 \(x_i\bmod p\) 中随机选择,直到出现环,也就是出现重复的数字,忽略常熟,那么生成的不同的值大约有 \(\sqrt p\) 个。
这也是为什么复杂度有个奇怪的 \(n^{\frac 1 4}\),但是目前的算法还没有得到进展,想要真正地变为 \(O(n^{\frac 1 4})\) 还有几步需要走。
Step.5 判环
因为随机数序列存在环,所以判环就是很重要的环节了,如果选择 map 等 STL 较为暴力地判环,复杂度就不够优秀,这里介绍一种 Pollard-Rho 基本上都会用的判环方法--Floyd 判环。需要注意,这个 Floyd 和最短路的 Floyd 不一样,仅仅是同一个人发明的而已。
我们可以想象有两个人在赛跑,如果一个人的速度比另外一个人快,那么他们一定会相遇,并且跑的距离差一定是圈长,但是因为并不是每个时刻都会检查,所以可能要快的人超了慢的人几圈了我们才会发现。
那么现在,这个思想也可以应用于判环,取 \(a=f(1)\),取 \(b=f(f(1))\),那么这样就可以将 \(b\) 看作 \(a\) 的两倍速度,这样只需要判断 \(a\) 是否等于 \(b\) 就可以判断是否进入环了,如果进入环了也没找到,则可以重新随机 \(c\) 继续找。
另外,\(b-a\) 可以看作差值,因为上一步我们证明了如果 \(a\equiv b \pmod p\),则有 \(f(a)\equiv f(b)\pmod p\),所以我们想要 \(\gcd(|x_i-x_j|,n)>1\),实际需要验证的 \(i,j\) 的范围是可以缩小的,也就是 \(|i-j|\bmod n\) 相同的所有组,我们只需要验证一组即可,因为 \(b\) 的速度要快 \(a\) 一倍,在相遇之前我们每次都是在判断一个不同的 \(|i-j|bmod n\),又因为只会存在 \(O(n^{\frac 1 4})\) 个不同的数字,那么期望在 \(O(n^{\frac 1 4})\) 检查到环。
这样,我们就避免了需要两两相减,逐一判断导致复杂度退化回去的尴尬情况,而是判断 \(O(n^{\frac 1 4})\) 次,减少了大部分 \(|i-j|\bmod n\) 相同的情况的检验。
但是复杂度依然不是 \(O(n^{\frac 1 4})\),因为每次检查求 \(\gcd\) 的过程都需要一个 \(\log n\)。
尽管已经很快了,但是我们需要追求极限,不是吗?
Step.6 积累的力量
假如 \(\gcd(x,n)>1\),那么 \(\gcd(kx,n)>1\) 所以我们找到一个 \(|x_a-x_b|\) 可以不必立马检验,而是积累一会儿,再一起检查。
选择的数量一般为 \(127\),有些时候需要看实际情况进行调整,但一般都是 \(2^k-1\) 比较优,具体原因我也不太清楚,大概是经验。
那么在有了积累,我们的复杂度就可以成功地降到 \(O(n^{\frac 1 4})\),但实际上的复杂度要低很多。
Step.7 一些细节
因为 Pollard-Rho 不具备检查是否为质数的能力,如果用一个质数一直去尝试寻找因子,那么就会一直找不到,所以还需要判断素数,可以使用 Miller Rabin 快速判断,并且可能一次 Pollard-Rho 也找不到,所以这种情况可以返回原数,然后重新随机一个 \(c\) 再次尝试。
下面给出代码:
inline long long f(long long x,long long c,long long n){return ((lll)x*x+c)%n;}//随机数生成方法,lll转换位__int128防止溢出
inline long long pollard_rho(long long x)
{
long long c=rand()%(x-1)+1,a=0,b=0,mul=1;
do
{
for(long long i=1;i<128;++i)//累计127次
{
a=f(a),b=f(f(b)),mul=(lll)mul*abs(a-b)%x;
if(a==b||!mul) break;//如果相等或者累乘出现0则代表遇到环,应该推出
}
long long gcd=__gcd(mul,x);
if(gcd>1) return gcd;//找到因数了
}while(a!=b)
return x;//每找到
}
inline void get_fac(long long x)
{
if(prime(x)) return;//先判质数
long long p=x;
while(p==x) p=pollard_rho(p);//一直找直到找到为止
}
Step.8 例子
判断素数可以直接 Miller Rabin 快速判断,然后发现要求的不是一个因子,而是最大的质因子。
可以考虑递归求解。
每次判断 \(x\) 是不是质数,如果是,就更新答案,如果不是,就使用 Pollard-Rho 找到一个因数 \(p\)。
然后将 \(x\) 中所有因数 \(p\) 都除掉,再去递归求解 \(x\) 和 \(p\)。
inline void sol(long long x)
{
if(x<=ans||x<2) return;//剪枝,如果小于答案则可以返回了
if(prime(x)) return ans=max(ans,x),void();//如果是质数,则更新答案
long long p=x;
while(p==x) p=PR(x);//找因子
while(x%p==0) x/=p;//除去因子
fac(x),fac(p);//递归求解
}