2012~2018
Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment
文章核心观点:
这篇文章介绍了一种名为MTransE的多语言知识图谱嵌入模型,旨在实现跨语言知识对齐。该模型由知识模型和匹配模型两部分组成,其中知识模型采用TransE对每个语言的实体和关系进行编码,而匹配模型则学习不同语言空间之间的跨语言转换。文章提出了三种跨语言转换表示方法,包括距离校准、翻译向量和线性变换,并基于不同的损失函数得到了MTransE的五个变体。实验结果表明,采用线性变换的变体在跨语言实体匹配和三元组对齐验证任务上表现最优。同时,MTransE在单语言任务上也能保持与TransE相当的性能。综合来看,MTransE为构建统一的多语言知识图谱提供了一个有效的自动对齐解决方案。
方法:
- 定义多语言知识图谱,包含每个语言的知识图谱和已有对齐信息。
- 构建知识模型,采用TransE对每个语言的知识图谱进行编码,将实体和关系表示为低维向量。
- 构建对齐模型,学习实体和关系向量在不同语言间的转换,提出三种转换表示方法:距离轴校准、翻译向量和线性变换。
- 整合知识模型和对齐模型,MTransE最小化损失函数,以学习实体和关系的嵌入表示以及跨语言转换。
- 训练模型,使用在线随机梯度下降法进行模型训练,同时交替优化知识模型和对齐模型的损失。
转移范例:参数
转移资源:multilingual word embeddings
评估语言:英,法,德
评估数据集:WK3l,self-generated
Cross-Lingual Entity Alignment via Joint Attribute-Preserving Embedding
文章核心观点:
这篇文章介绍了一种基于联合属性保持嵌入的跨语言实体对齐方法。该方法提出了结构嵌入和属性嵌入两个模块,分别用于学习两个知识库的关系三元组和属性三元组的嵌入表示。结构嵌入模块利用已有的对齐实体和关系作为桥梁,在统一向量空间中学习两个知识库的结构表示。而属性嵌入模块则通过抽象属性值并捕获属性之间的相关性,计算实体之间的相似度。最后,将两个模块的结果合并,在统一向量空间中表示所有实体,并通过搜索最近邻来实现跨语言实体的对齐。在真实数据集上的实验结果显示,该方法显著优于两种基于嵌入的跨语言实体对齐方法,并且可以与基于机器翻译的方法互补。
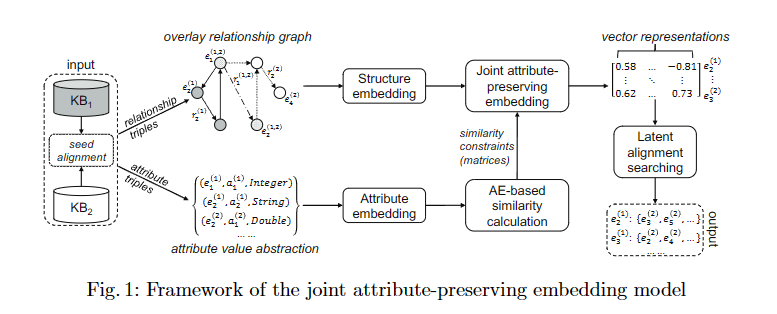
方法:
-
结构嵌入(Structure Embedding, SE):将两个知识库的关系三元组嵌入到统一的空间中,利用种子对齐作为桥梁,学习近似表示潜在的对齐三元组。

-
属性嵌入(Attribute Embedding, AE):利用种子对齐建立跨语言属性之间的相关性,并通过最小化目标函数,使相关的属性嵌入到相近的空间中。
计算实体相似度:利用属性嵌入计算实体之间的相似度,将实体的表示定义为属性向量的规范平均。 -
联合嵌入:将结构嵌入和属性嵌入结合,利用实体相似度矩阵作为监督信息,优化联合目标函数,使相似的实体嵌入到相近的空间中。
-
实体对齐:在联合嵌入空间中,为源实体搜索最近的跨语言邻居作为对齐的目标实体。
补充:为了进一步研究结合的可能性,对于每对潜在对齐的实体,我们考虑两个结果中较低的排名作为组合排名。令人惊讶的是,组合结果显著更好,这揭示了JAPE和机器翻译之间的相互补充性。我们认为,在跨语言知识库之间对齐实体时,如果机器翻译的质量难以保证,或者许多实体缺乏有意义的标签,JAPE可以作为一个实用的替代方案
转移范例:参数
转移资源:multilingual word embeddings,机器翻译
评估语言:英语,中文,日,法
评估数据集:DBP15K
相关工作:
现有的跨语言知识库对齐工作通常分为两类:跨语言本体匹配和跨语言实体对齐。在跨语言本体匹配方面,Fu等人[8,9]提出了一个通用框架,该框架利用机器翻译工具将标签翻译成同一种语言,并使用单语言本体匹配方法来找到映射。Spohr等人[21]利用基于翻译的标签相似性和本体结构作为特征,通过机器学习技术(例如SVM)学习跨语言映射函数。在所有这些工作中,机器翻译是一个不可或缺的组成部分。
在跨语言实体对齐方面,MTransE[5]结合了TransE,将知识库结构编码到特定语言的向量空间中,并设计了五种对齐模型,以学习不同语言知识库之间的翻译,使用种子对齐。JE[11]利用TransE将不同的知识库嵌入到一个统一的空间中,目的是让每个种子对齐具有相似的嵌入,这可以扩展到跨语言场景。Wang等人[23]提出了一个图模型,该模型仅利用语言独立的特征(例如出链/入链)来寻找Wiki知识库之间的跨语言链接。Gentile等人[10]利用基于嵌入的方法对Web表中的实体进行对齐。与他们不同,我们的方法一起嵌入两个知识库,并利用属性嵌入来改进。
不足:
- 受TransE影响,结构嵌入受到multi-mapping的影响,冲突映射(N-1,1-N,N-N)
- 属性嵌入中丢弃了属性值
Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment
文章核心观点:
本文介绍了一种基于协同训练的多语言知识图谱嵌入方法KDCoE,用于跨语言实体对齐。该方法结合了多语言知识图谱嵌入模型和实体描述嵌入模型,通过在弱对齐的多语言知识图谱上进行协同训练,逐步增强跨语言学习的监督信息。实验结果表明,该方法在实体对齐任务上优于先前的方法,并展示了在零样本实体对齐和跨语言知识图谱补全方面的潜力。
方法:
- 定义两个嵌入模型:KG嵌入模型(KGEM)和描述嵌入模型(DEM)。
- KGEM采用TransE模型学习每个语言的实体和关系的嵌入表示,同时加入一个线性变换对齐模型来建模跨语言知识。
- DEM使用门控循环单元编码器(AGRU)和多语言词嵌入学习实体描述的嵌入表示。
- 在迭代协同训练过程中,首先初始化两个模型,然后依次训练KGEM和DEM,并利用它们预测新的跨语言链接加入训练集。
- 重复上述过程,直到两个模型都无法提出新的跨语言链接。
- 在实体对齐任务中,使用KGEM和DEM的嵌入表示计算候选实体对的相似度,并选择相似度最高的作为预测结果。
- 在零样本实体对齐中,直接使用DEM的嵌入表示进行相似度计算和预测。
- 在跨语言知识图谱补全任务中,KGEM可以进行跨语言三元组补全预测。
补充1:使用门控循环单元(GRU)对实体描述进行编码,以捕捉描述的顺序信息。在GRU层上加入自注意力机制,以突出描述中共享的语义信息。利用预训练的多语言词嵌入来表示描述中的每个词,并固定词嵌入参数。将词向量序列输入GRU编码器,得到描述的隐藏状态表示。使用平均池化层聚合GRU的最后一层输出,得到描述的嵌入表示。通过最小化描述嵌入和其跨语言对应描述嵌入之间的欧氏距离,学习匹配不同语言描述的嵌入表示。
补充2:KDCoE能够基于描述的表示处理零样本场景。
转移范例:参数
转移资源:multilingual word embeddings
评估语言:英语,法语,德语
评估数据集:WK3l60k
相关工作:多语言知识图谱嵌入。最近的工作将嵌入模型扩展到知识图谱上的多语言学习。其中一个代表性的工作是MTransE [Chen等人,2017a]。MTransE通过一个共同训练的对齐模型将单语言模型连接起来,该模型采用了三种对齐技术,即轴校准(调整嵌入空间以使跨语言对应物共位,MTransE-AC)、向量平移(MTransE-TV)以及不同语言间的嵌入空间线性变换(MTransE-LT)。其中MTransE-LT在知识对齐任务上取得了最佳性能。JAPE在[Sun等人,2017]中被介绍,它基于实体属性的相似性,加强了基于MTransE-AC的跨语言学习。这个模型在提供数值实体属性的知识库上表现良好,尽管这样的属性在许多知识库中通常不可用。另一个相关的模型ITransE [Zhu等人,2017]将自我训练纳入了MTransE-AC的硬对齐版本。ITransE用于对齐具有一致词汇表和三元组的单语言知识库中的实体,但我们发现它不适应不一致的多语言场景。请注意,包括LM [Mikolov等人,2013a]、CCA [Faruqui和Dyer,2014]以及基于正交变换的OT [Xing等人,2015]在内的离线多语言词嵌入模型也可以扩展到知识图谱,但在跨语言任务上被MTransE超越。
Cross-lingual knowledge graph alignment via graph convolutional networks
文章核心观点:
这篇文章介绍了一种基于图卷积网络(GCN)的多语言知识图谱实体对齐方法。该方法利用GCN为每个知识图谱中的实体生成嵌入表示,并基于实体嵌入之间的距离来发现新的实体对齐。文章的主要贡献包括:(1) 使用GCN建模实体之间的等效关系,专注于建模跨语言知识图谱中的实体对齐;(2) 可以有效融合实体的关系三元组和属性三元组信息,从而提高对齐结果;(3) 实验证明该方法优于基于嵌入的其他知识图谱对齐方法。总的来说,这篇文章提出了一种简单高效的多语言知识图谱实体对齐方法,取得了很好的对齐效果。
方法:
- GCN基于实体嵌入:
- 使用GCN对每个KG中的实体进行嵌入,得到实体的结构和属性特征向量。
- 利用实体关系构建GCN的图结构,同时计算邻接矩阵以反映实体之间的信息传播概率。
- GCN模型包含多个图卷积层,每层学习新的特征表示,并最终得到实体的低维向量表示。
- 对齐预测:
- 基于实体在GCN表示空间中的距离,计算不同KG中实体对之间的距离。
- 通过预定义的距离函数,对距离进行计算,并选择距离最小的实体对作为对齐候选。
- 模型训练:
- 使用已知的对齐实体作为训练数据。
- 通过最小化排名损失函数,使已知的对齐实体在嵌入空间中更接近,而非对齐实体更远。
转移范例:参数
转移资源:multilingual word embeddings
评估语言:英语,中文,日,法
评估数据集:DBP15K
相关工作:
JE(Hao等人,2016)在统一的向量空间中联合学习多个知识图谱的嵌入,以对齐知识图谱中的实体。JE使用一组种子实体对齐来连接两个知识图谱,然后使用修改后的TransE模型通过添加实体对齐的损失到其全局损失函数中来学习嵌入。
MTransE(Chen等人,2017)使用TransE在各自的嵌入空间中对每个知识图谱的实体和关系进行编码;它还为每个嵌入向量提供了转换到其他空间中的跨语言对应物的转换。MTransE的损失函数是两个组件模型损失的加权和(即,知识模型和对齐模型)。为了训练对齐模型,MTransE需要两组知识图谱的一组对齐的三元组。
JAPE(Sun等人,2017)结合结构嵌入和属性嵌入来匹配不同知识图谱中的实体。结构嵌入遵循TransE模型,学习两个知识图谱叠加图的实体的向量表示。属性嵌入遵循Skip-gram模型,旨在捕获属性之间的相关性。为了获得理想的结果,JAPE需要两个知识图谱的关系和属性事先被对齐。
ITransE(Zhu等人,2017)是一种适用于多个知识图谱的联合知识嵌入方法,也适用于跨语言知识图谱对齐问题。ITransE首先学习遵循TransE的实体和关系嵌入;然后它根据一组种子实体对齐学习将不同知识图谱的知识嵌入映射到一个联合空间中。ITransE通过使用新发现的实体对齐来更新实体的联合嵌入,执行迭代实体对齐。ITransE要求所有关系在知识图谱中共享。
上述方法遵循类似的框架来匹配不同知识图谱中的实体。它们都依赖于TransE模型来学习实体嵌入,然后定义对齐实体嵌入之间的某种转换。与这些方法相比,我们的方法使用了一个完全不同的框架;它使用图卷积网络(GCNs)在统一的向量空间中嵌入实体,期望对齐的实体尽可能接近。我们的方法只关注在两个知识图谱中匹配实体,并不学习关系的嵌入。MTransE、JAPE和ITransE都需要知识图谱中的关系被对齐或共享;我们的方法不需要这种先验知识。