GNN基础理论
1、图神经网络基础知识
对于图神经网络的提出背景:常规算法(机器学习、卷积神经网络等)处理的大多为欧几里得空间数据(Euclidean space)[一般指:图片等数据]
欧几里德数据:数据特点是排列整齐。对于某个节点,很容易可以找出其邻居节点,就在旁边,不偏不倚。最常见到的是图片(image)和视频(video)以及语音(voice)。
非欧几里德数据:排列不整齐,比较的随意。具体体现在:对于数据中的某个点,难以定义出其邻居节点出来,或者是不同节点的邻居节点的数量是不同的。
但是对于一些非欧几里得空间数据(比如家族图谱、人物关系图谱等)对于传统神经网络来说几乎是处理不了的(换句话来说:世间万物之间都是彼此相互联系的,传统的深度学习、机器学习处理的都是单一/简单数据问题),因此提出图神经网络(\(Graph \quad Neural \quad Network\))
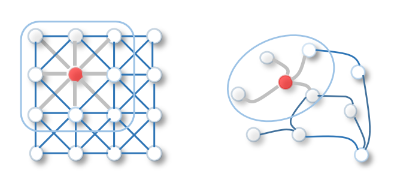
对于一组图定义为:\(G=(V,E,R,T)\)其中:1、节点:\(v_i \in V\);2、不同节点之间联系:\((v_i, r, v_j)\);3、节点之间相关性:\(r \in R\);4、节点类型:\(T(v_i)\)。简单上理解一幅“图”就是若干个节点在若干节点之间彼此联系(连接| 联系类型分为:有向、无向、权重、自循环等),便于数学上理解将一幅图(定义比较宽泛:可以是人物关系图谱、图片像素联系等)转化成一组邻接矩阵(Adjacency Matrices)
更加简单定义:\(G=(V,E)\)其中:\(V\)代表图中的节点;\(E\)代表不同节点之间的边(点之间权重、有向/无向);
基础理论:
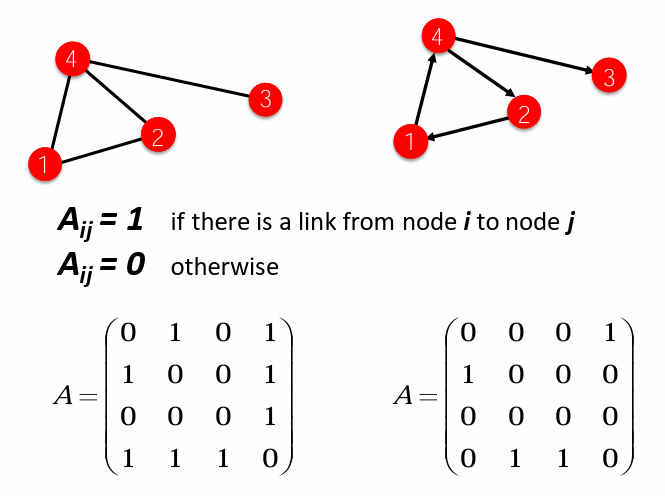
1、邻接矩阵 \(A\)
\[A_{i,j}=\begin{cases} 1 \qquad 如果i,j之间存在边\\ 0 \end{cases} \]2、度矩阵 \(D\)
\[D_{i,j}=\begin{cases} deg(v_i)\qquad 如果i=j\\ 0 \end{cases} \]也就是说计算与节点\(i\)连接的边的个数
\(D^{- 1/2}\) 相当于对于每一个元素开根号

2、基本图神经网络
2.1 图卷积神经网络
沿用论文[1]中对图神经网络的定义:
\[f(X,A)= \sigma(D^{- 1/2}(A+I)D^{- 1/2}XW) \]其中:
\[A:邻接矩阵(n*n),I:单位矩阵(n*n),D:度矩阵(n*n),\\ X:输入数据(n*d),W:权重参数(d*w), \sigma():激活函数 \]从函数定义上,和一般的神经网络很相似:设计一个网络结构(就是我们的参数\(W\)),输出数据然后通过优化算法去对参数进行优化。
- 1、\(A+I\) 理解
我们知道在一组图(社交网络等)中节点之间彼此联系,并且节点自身具有特性( 那么就需要对两个都进行考虑 ),那么在构建模型过程中需要保证 对于节点自身以及节点之间信息 进行充分考虑(亦或者说:对信息进行传递)。正如上面(图的定义)所提到的,我们需要把一组图转化为一个邻接矩阵\(A\)对其进行数学表示。但是为什么不将函数设计成:
\[f(X,A)= \sigma(AXW) \tag{1} \]- 1、没有考虑到自身节点信息自传递的问题;
- 2、\(A\)通常未标准化,因此与\(A\)相乘将完全改变特征向量的尺度)
所以对于邻接矩阵(\(A\))加上单位矩阵(\(I\))就相当于在图中添加一个自循环
- 2、\(D^{- 1/2}(A+I)D^{- 1/2}\) 的理解
对于\(D^{- 1/2}(A+I)D^{- 1/2}\) 被称为:normalize the adjacency matrix
为什么要执行标准化 ?为什么不直接用
\[f(X,A)= \sigma(DAXW) \tag{2} \]回顾图的定义:一组图由两部分构成点和边(以节点分类任务为例);对于结点 \(i\) 我们需要通过结合与节点 \(i\) 相连接的其它节点和他们之间的边的信息来对 \(i\) 进行判断。那么也就是说我们要首先对邻接节点信息进行汇聚(Aggregate information)而后后续操作。既然要对对数据进行汇聚,那么问题来了:在图中有些结点与其它节点之间存在较多连接,而有些节点可能就只有一个节点和他连接。
如果直接用公式\((2)\) 这样虽然考虑到节点之间信息但是在后续对于参数优化上就会照成困难,所以一个最直接的例子就是:既然连接点数量之间存在差异,那么我直接去除以你的节点个数!!
2.1.1 卷积图神经网络理解
对上述公式\(f(X,A)= \sigma(D^{- 1/2}(A+I)D^{- 1/2}XW)\)将其简化为\(f(X,A)=\sigma(\widehat{A}XW)\)
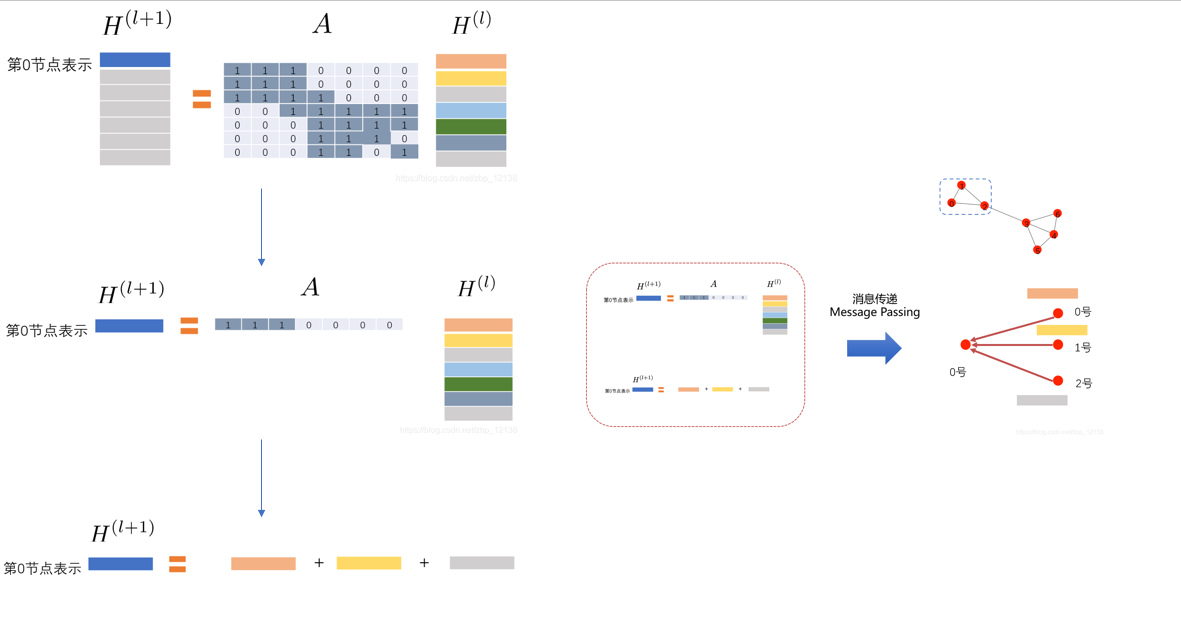
借用如下图[4]理解图卷积算法(其中\(H\)对应上述公式中的\(X\))
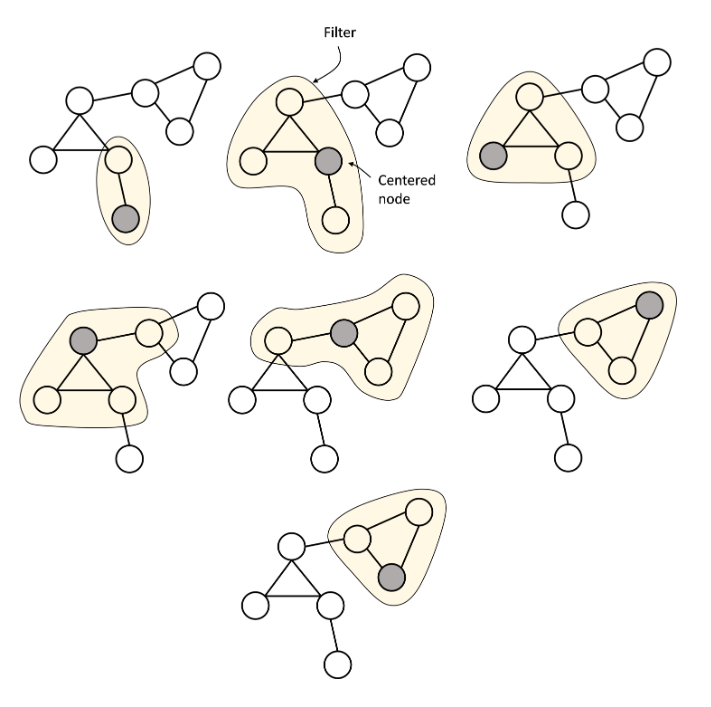
回顾简化的图卷积函数( \(f(X,A)=\sigma(\widehat{A}XW)\) ),图卷积网络在设计上借鉴了卷积神经网络,矩阵\(\widehat{A}\)中存在许多0也就是说,我们可以通过对于某个节点设计一个 “卷积核” ,去对与之相连接的节点进行“卷积运算”而后进行“池化”操作
2.1.2 GCN代码
from torch_geometric.nn import GCNConv
import torch.nn.functional as F
# 实现形式1
class GCN(nn.Module):
def __init__(self, input_dim: int, class_label: int):
super(GCN, self).__init__()
self.conv1 = GCNConv(input_dim, 16)
self.conv2 = GCNConv(16, class_label)
def forward(self, data):
x = self.conv1(x, edge_index)
x = F.relu(x)
output = self.conv2(x, edge_index)
return output
# GCN定义
from dgl.nn import GraphConv
class GCN(nn.Module):
def __init__(self, in_feats, h_feats, num_classes) -> None:
super(GCN, self).__init__()
self.conv1 = GraphConv(in_feats, h_feats)
self.conv2 = GraphConv(h_feats, num_classes)
def forward(self, g, in_feats):
h = self.conv1(g, in_feats)
h = F.relu(h)
h = self.conv2(g, h)
return h
参考:
1、http://arxiv.org/abs/1609.02907
2、https://mbernste.github.io/posts/gcn/
3、https://zhuanlan.zhihu.com/p/89503068
4、https://blog.csdn.net/zbp_12138/article/details/110246797
2.2 图注意力网络 GAT
GAT网络特征:
- 1、可以跨越节点就行并行化操作
- 2、它可以通过为邻居节点指定任意权重,应用于具有不同度的图节点
此处区别GCN,GCN是直接计算邻居节点的平均(权重是恒定的)
- 3、该模型直接适用于归纳学习问题,包括模型必须泛化到完全看不见的图形的任务
Global graph attention[5]
就是每一个顶点\(i\)都对于图上任意顶点都进行attention运算。完全不依赖于图的结构,可能造成:(1)丢掉了图结构的这个特征,效果可能会很差(2)运算面临着高昂的成本
(1) the operation is efficient, since it is parallelizable across nodeneighbor pairs;
(2) it can be applied to graph nodes having different degrees by specifying arbitrary weights to the neighbors;
(3) the model is directly applicable to inductive learning problems, including tasks where the model has to generalize to completely unseen graphs.
2.2.1 GAT网络定义
论文[6]中定义:输入一系列节点特征\(h=\{\vec{h_1},...,\vec{h_N} \}\)其中\(\vec{h_i} \in R^F\),\(N\)代表节点的数量,\(F\)代表每一个节点特征数量。GAT算法步骤
- 第一步:对于每一个节点添加一个共享线性映射
其中\(W\in R^{{F^ \prime}*F}\),通过计算进而对顶点特征就行增维,\(||\)去对特征就行拼接
- 第二步:对于线性映射的节点添加注意力机制(self-attention)
其中\(e_{ij}\)代表 注意力系数 用来计算节点 \(i\) 邻居节点 \(j\) 对其的重要性,\(a\)是一层前馈神经网络。这样一来模型允许每个节点参与到其它节点上,进而省去了所有的结构信息,并且使用\(LeakyReLU\)作为激活函数。
masked attention
we only compute eij for nodes j ∈ Ni, where Ni is some neighborhood of node i in the graph.
也就是说对于节点\(i\)只计算与之相联系的节点
此处也印证了GAT的特征3,对于inductive learning problems,在GAT中去改变网络结构无非就是改变\(N_i\)
- 第三步:添加激活函数以及计算\(softmax\)
其中\(T\)代表转置,\(||\)代表串联操作
- 第四步:多头注意力处理
其中\(\sigma\)代表非线性激活。对于多头注意力:
\[\\ concat: \vec{h}_i^{\prime}= ||_{k=1}^{K} \sigma\left(\sum_{j\in N_i}\alpha_{ij}^{k}\mathbf{W^k}\vec{h}_j\right) \\ avg: \vec{h}_i^{\prime}= \sigma\left(\frac{1}{K} \sum_{k=1}^K \sum_{j\in N_i}\alpha_{ij}^{k}\mathbf{W^k}\vec{h}_j\right) \]算法流程图:
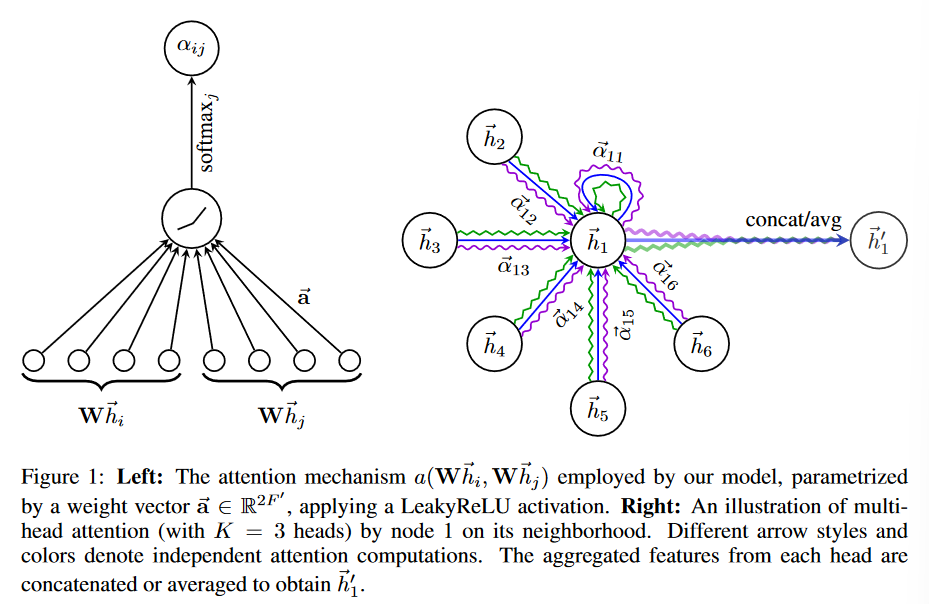
对于上图左半部分( 注意力机制 )很好理解:就相当于对节点做一个矩阵相乘(\(W\)),而后通过前馈神经网络(\(LeakyReLU\)和\(softmax\))进行处理得到\(\alpha_{ij}\)。对于右半部分:对于节点\(\vec{h_1}\)假设6个节点与其联系。对于每一个联系节点通过 3层(上述图中3中颜色)注意力进行处理。对后续结果进行拼接/平均(\(concat/avg\))得到\(\vec{h_1^·}\)。
2.3 STGNN(Spatio-Temporal Graph Convolutional Networks)
作者[7]在处理交通网络预测过程中出现:交通流的非线性以及复杂性,不是借助传统的 卷积单元 和 循环单元 而是通过图神经网络进行处理。并且提出时空图卷积网络(STGNN)
作者对于交通预测描述如下:
也就是说:根据\(M\)个过去时间节点数据预测未来\(H\)时刻数据,其中\(v_t \in R^n\)代表在\(n\)条道路在时间\(t\)下的观察向量(记录道路的流量)
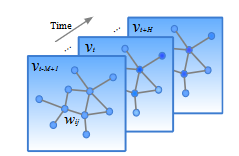
因此作者将上述结构定义如下图神经网络:$G_t= (V_t, \varepsilon, w) $分别代表有限节点集合、边、权重。
2.3.1 网络结构
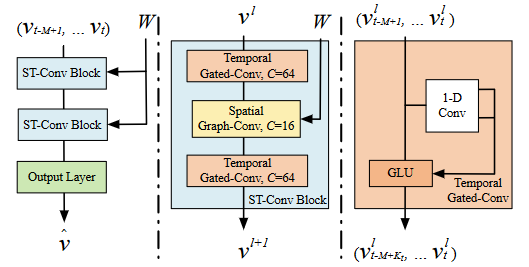
输入数据(\(V_{t-M+1},...,V_t\))而后通过两层ST-Conv Blovk以及全连接层进行预测输出。ST-Conv Block结构(中间部分)包含两个时间门控卷积层(Temporal Gated-Conv),中间包含一个空间图形卷积层(Spatial Graph-Conv)。在每个块内部应用了残差连接和瓶颈策略。
- ST-Conv Block
ST-Conv Block结构由:Temporal Gated-Conv(TGC) + Spatial Graph-Conv(SGC) + Temporal Gated-Conv,对于此类结构作者给出的解释:可以通过时间卷积实现从图卷积到空间状态的快速传播。"三明治"结构还帮助网络充分运用瓶颈策略,通过图卷积层对通道C进行降尺度和升尺度处理,实现尺度压缩和特征压缩。此外,在每个ST-Conv块中使用层归一化来防止过拟合
Can achieve fast spatial-state propagation from graph convolution through temporal convolutions. The “sandwich” structure also helps the network sufficiently apply bottleneck strategy to achieve scale compression and feature squeezing by downscaling and upscaling of channels C through the graph convolutional layer. Moreover, layer normalization is utilized within every ST-Conv block to prevent overfitting
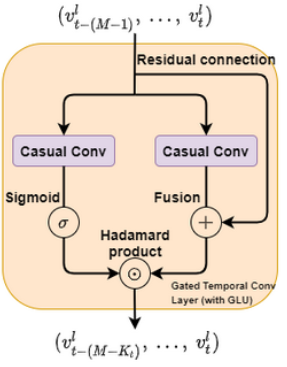
- Temporal Gated-Conv(TGC)
对于TGC通过 1-D casual convolution 和 gated linear units(GLU[8]) 构成
参考
1、http://arxiv.org/abs/1709.04875
2、https://zhuanlan.zhihu.com/p/286445515
2.4 Gated Graph Sequence Neural Network[9]
从名字上很好理解,\(GGSNN\)(门控序列图神经网络)是作为一种可以对序列进行预测的图神经网络,作者提到该网络添加:1、门控序列单元(gated recurrent units);2、“优化”方法(modern optimization techniques)
- 1、门控图神经网络(Gated Graph Neural Network)
2.4 Spectral domain (频谱域) and Spatial domain (空间域)
2.4.1 Spatial domain
2.4.2 Spectral domain
Spectral domain的思想是调制图信号的频率,使得其中一些频率分量被保留或放大,而另一些频率分量被移除或减小[10]。整个过程算法很好理解,但是要是去仔细研究每一个步骤有一定难度。 Spectral domain 主要思想如下:
- 第一步:对于输入的图信号\(X \in R^{n*k}\)进行傅里叶变换(graph Fourier transform GFT)得到系数: \(U^T X\)
- 第二步:对系数进行 滤波操作得到滤波后的系数: \(\widehat{g}(\Lambda )U^TX\)
- 第三步:对滤波后的系数进行图傅里叶逆变换( IGFT ) 将信号重建到图域:\(U\widehat{g}(\Lambda )U^TX\)
在论文[11]里面提到有意思一点:在许多基于Spectral的GCN中关键在于对于滤波器\(\widehat{g}(\Lambda )\)的设计
- 对于第一步:
上述过程中涉及到:1、拉普拉斯矩阵(特征分解等);2、傅里叶变换;3、傅里叶的逆变换。具体了解:
1、https://archwalker.github.io/blog/2019/06/16/GNN-Spectral-Graph.html#谱分解
2、http://ieeexplore.ieee.org/document/6494675/
Kipf, T. N. & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. Preprint at http://arxiv.org/abs/1609.02907(2017). ↩︎
https://blog.csdn.net/zbp_12138/article/details/110246797 ↩︎
Veličković, P. et al. Graph Attention Networks. Preprint at http://arxiv.org/abs/1710.10903 (2018). ↩︎
Yu, B., Yin, H. & Zhu, Z. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence 3634–3640 (2018). doi:10.24963/ijcai.2018/505. ↩︎
Li, Y., Tarlow, D., Brockschmidt, M. & Zemel, R. Gated Graph Sequence Neural Networks. Preprint at http://arxiv.org/abs/1511.05493 (2017). ↩︎
Wu, Z. et al. A Comprehensive Survey on Graph Neural Networks. Ieee T Neur Net Lear 32, 4–24 (2021). ↩︎