Abstract
训练GNN通常需要大量的特定于任务的标记数据,这些获取是非常昂贵的,减少标记工作的一种有效方法是对具有自监督的表达性GNN进行预训练,然后将学习到的模型转移到只有少量标签的下游任务中,本文提出了GPT-GNN的框架,通过生成式预训练来初始化GNN,GPT-GNN引入了一个自监督的属性图生成任务来对GNN进行预训练,从而能够捕获图的结构和语义属性。我们将图生成的可能性分解为两个组成部分,属性生成和边缘生成,通过对这两个组件进行建模,GPT-GNN捕获了生成过程中节点属性和图结构之间的内在依赖关系。
Introduction
我们提出预先训练图神经网络进行图挖掘,预训练的目标是让GNN能够捕获输入图的结构和语义属性,这样它就可以很容易地泛化到任何下游任务,并且在同一域内的图上有几个微调步骤。为了实现这一目标,我们提出通过学习重构输入的属性图来建模图的分布
为了对基于图重建的GNN进行预训练,一个直接的选择是直接采用神经图生成技术。但是它们不适合设计为预训练GNN。首先它们大多数只关注生成没有属性的图结构,而不捕获节点属性和图结构之间的底层模式,这是GNN中卷积聚合的核心
本文的贡献如下:
- 在这项工作中,我们设计了一个自监督的属性图生成任务的GNN预训练,在该任务中,图的结构和属性都被建模。在此基础上我们提出了一种用于图神经网络生成式预训练的GPT-GNN框架。然后可以将输入图上预先训练的GNN作为同一类型图上不同下游任务的模型的初始化。
- 首先我们设计了一个属性图生成任务来建模节点属性和图结构。我们将图的生成目标分解为两个组成部分,属性生成和边生成,它们的联合优化等价于最大化整个属性图的概率似然。在此过程中,预训练好的模型可以捕获节点属性和图结构之间的内在依赖关系
- 其次我们提出了一个有效的框架GPT-GNN来进行上述任务的生成式预训练,GPT-GNN可以同时计算每个节点的属性和边缘生成损失,因为对图只需要运行一次GNN即可,此外GPT-GNN还可以处理具有子图采样的大规模图,并通过自适应嵌入队列来减轻负采样带来的不准确损失
Preliminaries
以往的研究提出利用预训练来学习节点表示主要分为两类,第一类通常称为网络/图嵌入,它直接参数化节点嵌入向量并通过保留一些相似度度量来优化它们,如网络接近度或随机游走的统计量。但是以这种方式学习到的嵌入不能用于初始化其他模型。所有我们考虑了一个迁移学习设置,其中的目标是预先训练一个可以处理不同任务的通用GNN
之后是探索对未注释数据的GNN进行预训练的方向,虽然这项方法比纯监督的学习设置有所增强,但是学习任务通过强制附近的节点有相似的嵌入来实现,而忽略了图中丰富的语义和高阶结构,我们的工作提出了通过置换生成目标对GNN进行预训练,这是一个更困难的图任务,因此可以指导模型学习更复杂的语义和输入图的结构
Method
模型的整体结构如下:
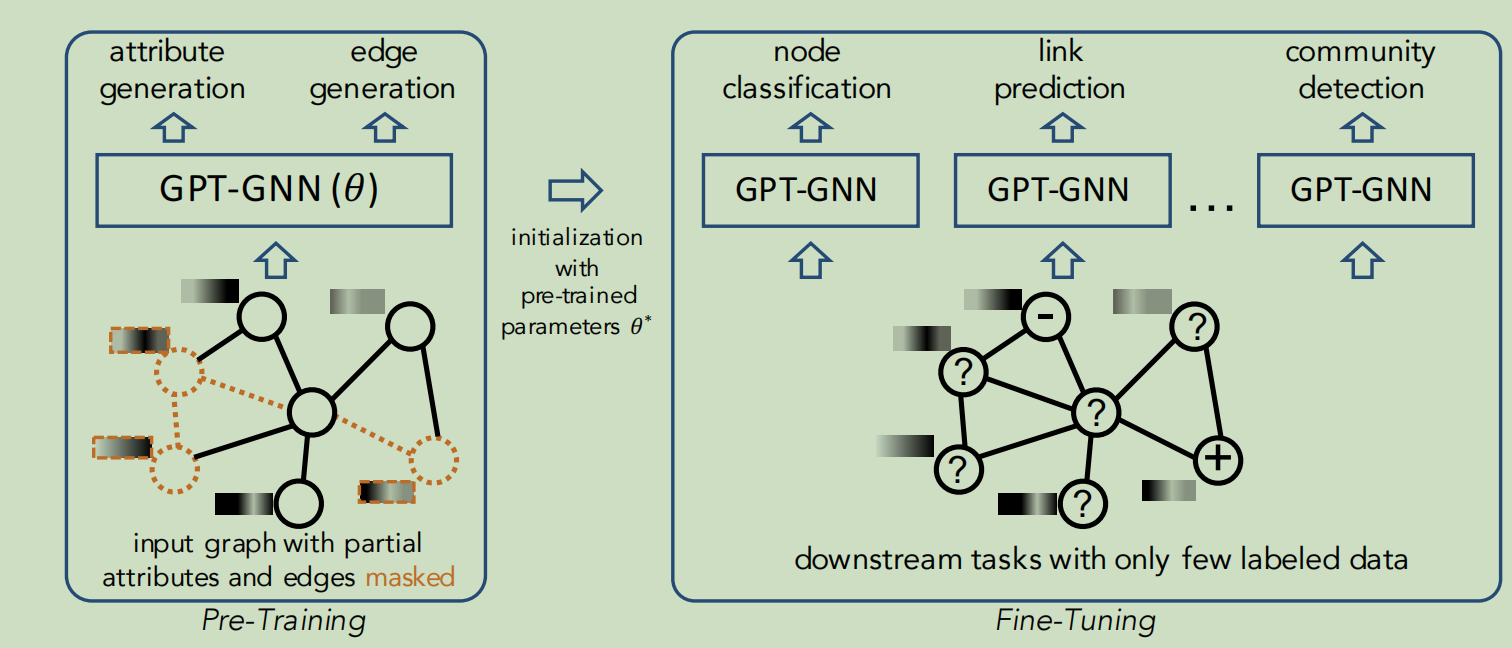
GNN预训练存在的问题
大多数任务需要足够的数据,但是获得足够的数据是很困难的,所以我们希望有一个预训练的GNN模型,可以用很少的标签来生成。概念上讲,这个模型应该:捕获图背后的内在结构和属性模式,从而有利于这个图上的各种下游任务
接下来简单介绍一下GNN预训练的任务
任务是训练一个生成的GNN模型\(f_\theta\) 依赖一个没有标签数据的图,这样\(f_\theta\) 是对相同的图或相同域的图上的各种下游任务的一个很好的初始化。为了学习这样一个没有图上标记数据的GNN模型,出现了一个很自然的问题,如何在图上设计一个无监督的学习任务来对GNN模型进行预训练
生成式的预训练框架
我们提出了GPT-GNN,它通过重构/生成输入图的结构和属性来对GNN进行预训练。
我们将这个GNN在图上的似然性建模为\(p(G;\theta)\),这个表示G中的节点是如何归属和连接的。GPT-GNN的目标是通过最大化图的似然性来对GNN模型进行预训练
然后第一个问题是如何正确地建模\(p(G;\theta)\),目前大多数的图生成方法都采用自回归的方式来分解概率目标,即图中的节点按概率顺序出现,而边是通过连接每个新到达的节点到现有的节点来生成的。我们用一个排列向量\(\pi\) 来确定节点排序, 其中\(i^{\pi}\)表示排序中的第i个节点,所以图分布\(p(G;\theta)\)等价于所有可能排列的期望似然,即:
\(p(G;\theta)=\mathbb{E}_\pi\left[p_\theta(X^\pi,E^\pi)\right]\)
\(X^\pi\)表示排列的节点属性,\(E^{\pi}\)表示与节点\(i^{\pi}\)连接的所有边
为简单起见,我们假设观察任何节点排序都有相等的概率,给定一个排列顺序,我们可以将对数似然自回归分季节,每次迭代生成一个节点
\(\log p_\theta(X,E)=\sum_{i=1}^{|\mathcal{V}|}\log p_\theta(X_i,E_i\mid X_{<i},E_{<i})\)
在每个步骤中,我们使用在i之前生成的所有节点,它们的属性以及这些节点之间的结构来生成一个新的节点,包括节点的属性以及与现有节点的连接
然后问题变成了如何建模条件概率\(p_\theta(X_i,E_i|X_{<i},E_{<i})\)
属性图生成的一个示例图如下:
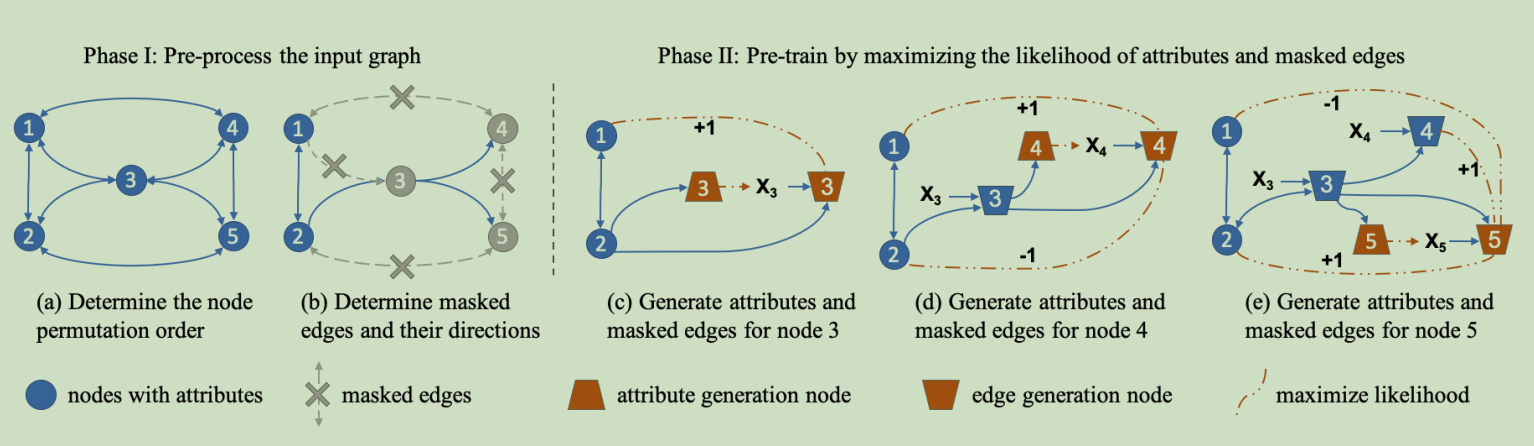
分解属性图生成
先假设X和E是独立的,于是可以变成这样
\(p_\theta(X_i,E_i|X_{<i},E_{<i})=p_\theta(X_i|X_{<i},E_{<i})\cdot p_\theta(E_i|X_{<i},E_{<i})\)
但是这样的分解策略,每个节点的属性和连接之间的依赖关系就完全被忽略了,但是被忽略的依赖性是属性图的核心属性,所以不能这样做
为了解决这个问题,我们提出了属性图生成过程的依赖感知因子分解机制。具体来说,当估计一个节点的新属性时,我们会得到它的结构信息,反之亦然。在此过程中,一部分边已经被观察到(或生成)。然后将生成可以分解为两个耦合部分
- 给定观察到的边,生成节点属性
- 给定观察到的边和生成的节点属性,生成剩余的边
通过这种方式,模型可以捕获每个节点的属性和结构之间的依赖关系
形式上,我们定义了一个变量o来表示E内所有观测边的索引向量。因此\(E_{i,o}\)表示所观察到的边。同样¬o表示要生成所有的掩码边的索引,有了这个方法,我们可以将条件概率重写为所有观察边的期望可能性
该因子分解设计能够建模节点i的属性以及其关联的连接之间的依赖关系。第一项表示节点属性的生成,基于观察到的边缘,我们收集目标节点的领域信息,生成其属性。第二项表示掩码边的生成。基于观察到的边和生成的属性,我们生成目标节点的表示,并预测\(E_{i,\neg o}\)中的每条边是否存在
到目前为止,我们将属性图生成过程分解为节点属性生成步骤和边生成步骤。我们在这里需要回答的问题是:如何通过优化属性和边缘生成任务来有效地预训练GNN
高效的属性和边缘生成
为了提高效率,我们需要通过对输入图只运行一次GNN来计算属性生成和边生成的损失。此外,我们期望同时进行属性生成和边缘生成。但是,边缘生成需要节点属性作为输入,这可能会泄露给属性生成。为了避免信息泄漏,我们设计将每个节点分为两种类型:
- 属性生成节点。我们通过用一个虚拟标记替换这些节点的属性来掩盖这些节点的属性,并学习一个共享向量\(X_{init}\)来表示它。
- 边生成节点。对于这些节点,我们保留它们的属性,并将它们作为GNN的输入
然后,我们将修改后的图输入到GNN模型中,并生成输出表示。我们使用\(h^{Attr}\)和\(h^{Edge}\)分别表示属性生成节点和边生成节点的输出嵌入。由于属性生成节点的属性被掩盖,\(h^{Attr}\)包含的信息一般少于\(h^{Edge}\)。因此,在进行GNN消息传递时,我们只使用边生成节点的输出\(h^{Edge}\)作为外部消息。然后使用这两组节点的表示来生成具有不同解码器的属性和边。
对于属性生成,我们将其解码器表示为\(Dec^{Attr}(\cdot)\),它以\(h^{Attr}\)作为输入,并生成掩蔽属性。解码器建模的选择取决于属性的类型,比如输入属性是文本,那么就可以使用LSTM来生成,如果输入是一个标准向量,我们可以用一个MLP来生成,此外,我们将距离函数定义为生成的属性和真实属性之间的度量。属性生成损失函数如下:
\(\mathcal{L}_i^{Attr}=Distance(Dec^{Attr}(h_i^{Attr}),X_i)\)
对于边生成,我们假设每条边的生成与其他边是独立的,这样我们就可以分解可能性
\(p_\theta(E_{i,\neg o}\mid E_{i,o},X_{\leq i},E_{<i})=\prod_{j^+\in E_{i,\neg o}}p_\theta(j^+\mid E_{i,o},X_{\leq i},E_{<i})\)
接下来,在得到边缘生成节点表示\(h^{Edge}\)后,我们通过\(Distance(Dec^{Edge}(h_i^{Edge},h_j^{Edge})\)建模节点i与节点j连接的可能性,其中\(Dec^{Edge}\)是一个成对的分数函数。最后,我们采用负对比估计来计算每个链接节点j+的似然值。我们将所有未连接的节点准备为Si−,然后计算对比损失
\(\mathcal{L}_i^{Edge}=-\sum_{j^+\in E_{i,-o}}\log\frac{\exp\left(Dec^{Edge}(h_i^{Edge},h_{j^+}^{Edge})\right)}{\sum_{j\in S_i^-\cup\{j^+\}}\exp\left(Dec^{Edge}(h_i^{Edge},h_j^{Edge})\right)}\)
GPT-GNN的具体算法流程如下

自适应节点表示队列
为了估计等式中的对比损失、需要遍历输入图的所有节点。然而,我们只能访问子图中的采样节点来估计这种损失,这使得自监督只关注局部信号。为了缓解这一问题,我们提出了自适应队列,它将节点表示作为负样本存储在以前采样的子图中。每次我们处理一个新的子图时,我们都会通过添加最新的节点表示和删除最老的节点表示来逐步更新这个队列。由于模型参数不会被严格更新,因此存储在队列中的负样本是一致的和准确的。自适应队列使我们能够使用更大的负样本池。此外,在不同采样子图上的节点可以为对比学习带来全局结构指导
Conclusion
在本工作中,我们研究了图神经网络的预训练问题。我们提出了GPT-GNN,一个生成的GNN预训练框架。在GPT-GNN中,我们设计了图生成因子分解来指导基本GNN模型自动回归重构输入图的属性和结构。此外,我们建议分离属性节点和边生成节点,以避免信息泄漏。此外,我们还引入了自适应节点表示队列,以减轻采样图和全图上的可能性之间的差距。
标签:训练,笔记,生成,Edge,GPT,GNN,节点,属性 From: https://www.cnblogs.com/anewpro-techshare/p/18028066