title: Paper Gestalt笔记
banner_img: https://cdn.studyinglover.com/pic/2023/07/5deff473fdf93539d3952d3d6894add3.png
date: 2023-7-27 10:57:00
Paper Gestalt笔记
最近读到了一篇CVPR2010非常优秀的论文,叫做Paper Gestalt ,他考虑到近年来(2010年的近年来)CVPR的投稿两出现了大量增长,但是作者很可能接触到一个不优秀的审稿人,所以训练了一个视觉分类器来判断一篇CVPR的论文是否应该被接受来辅助审稿。当然模型效果非常优秀了,在误分类15%的goog paper (应该被接受)的情况下可以筛选掉50% bad paper。
在这项工作中,作者构建了一种简单的直觉,即一篇论文的质量可以通过浏览总体的视觉效果来估计,并使用这种直觉来构建一个系统,该系统使用基本的计算机视觉技术来预测论文是否应该被接受或拒绝。这个任务中具有判别能力的视觉特征集就被称为Paper Gestalt。
最有意思的一点是,作者训练出来的默认为认为他的论文有88.4%的可能被接受。
作者将这个任务认为是一个二分类任务\(\{(x_1,y_1),(x_2,y_2),...(x_n,y_n)\}\) ,其中\(x_i\) 是一个图片的视觉特征,\(y_i\) 则是对论文的一个标签。
给定一篇论文的图像,需要计算可插入分类系统的视觉特征的数量。作者选择了一些标准的计算机视觉特征来捕捉渐变、纹理、颜色和纹理信息。特别是作者是基于LUV直方图、直方图的定向梯度和梯度幅度来计算特征。
作者选用了AdaBoost作为分类器,公式是$$h(x)=\sum_{t=1}^T\alpha_th_t(x)$$
\(h_t\)就是一个弱分类器,这里选用的是决策树\(h_t(x)=\mathbf{1}[f_t(x)>\theta]\) ,\(\theta\) 是阈值,\(f_t\) 是图像特征,整体的训练流程如图所示。(实话实话,对于我这种2020年才接触深度学习的人来说AdaBoost真的是老古董技术了(ง •̀_•́)ง,只在计算机视觉课上听过这种技术用于人脸检测)

AdaBoost有许多吸引人的理论特性。例如,众所周知,经验误差是有界的$$\epsilon(h)\leq\prod_{t=1}^T2\sqrt{\epsilon_t(1-\epsilon_t)}$$
虽然这个公式摆在这没有任何用,但是作者发现数学公式多了有利于论文被接受,所以他又摆上了 Maxwell’s equations
哦你问视觉分类器跟Maxwell’s equations 到底有啥关系?这就是这篇论文的结论部分了,作者使用了一些论文作为例子分析了效果。
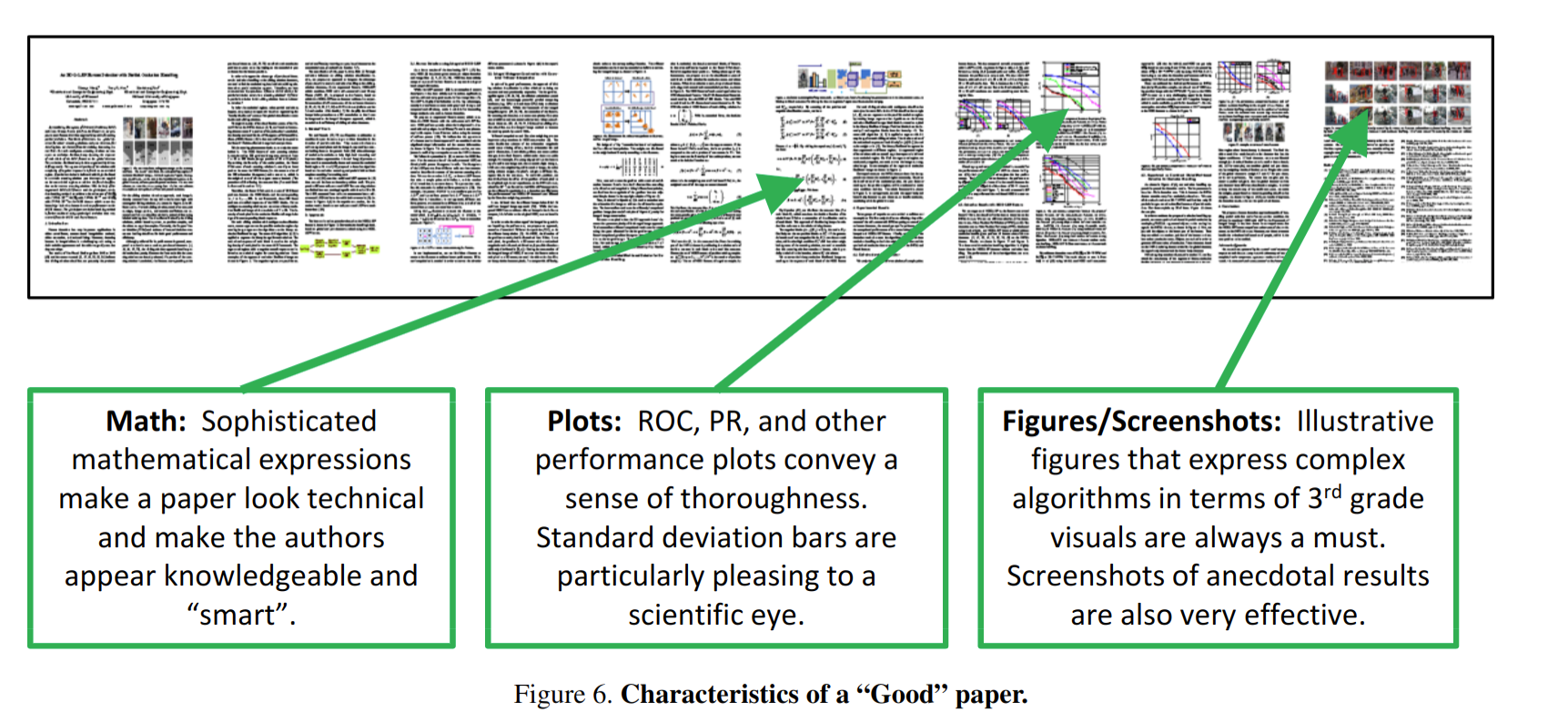
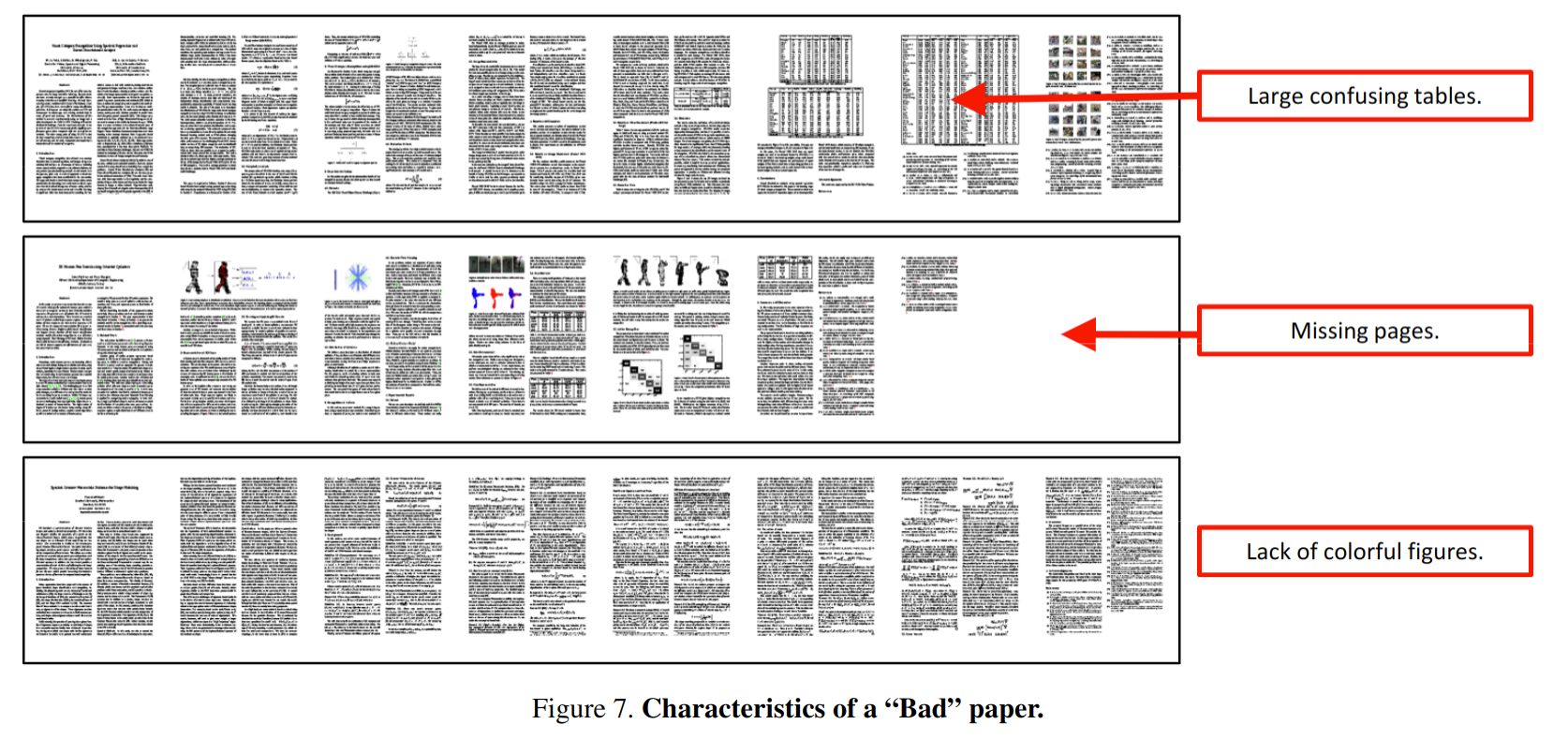
我们从作者给出的图可以发现,一篇被接受的论文有数学公式,有图表还有图像,而被拒的论文有令人困惑的大表格,缺少页数还有缺少五颜六色的图片。
说到令人困惑的大表格不知道你有没有想到一篇论文,对就是我们巨有钱的OPENAI做的CLIP。这表格属实看的人眼睛疼,被显卡的钱亮瞎了狗眼。

作者还不忘了夸一下他的论文,说他的固然存在缺页/空白页的问题,但其色彩斑斓的图表和令人印象深刻的数学公式构成非常漂亮。问题是你这图也不对呀,有的图片位置都和最终论文不一样。

还有一点需要指出的是,作者的模型分析一篇论文只需要0.5秒。
在我找原文的时候,我发现arXiv上挂了一篇18年的文章Deep Paper Gestalt ,据说他训练的模型把自己拒掉了。按照这个趋势我是不是可以搞一篇论文叫做Paper Gestalt with Latent Space?
标签:一篇,论文,笔记,作者,vec,Paper,Gestalt From: https://www.cnblogs.com/studyinglover/p/17857334.html