title: LISA(推理分割)笔记
banner_img: https://cdn.studyinglover.com/pic/2023/08/10f885319b150cc20093124185e25c3b.png
index_img: https://cdn.studyinglover.com/pic/2023/08/ded90e7e3f84739b187dd679c39bd8dd.png
date: 2023-8-18 15:05:00
categories:
- 笔记
tags:
- 多模态
LISA(推理分割)笔记
简介
这篇论文题目中文翻译是 基于大型语言模型的语义分割, 提出了一个新任务-推理分割。大概就是给一张图和一段话,模型使用大语言模型分割出目标。作者给了一个例子,从图片中分割出富含维生素C的物品。
作者说这篇论文有三个贡献,提出了推理分割的任务,建立了一个推理分割基准,ReasonSeg, 还有训练了一个模型。
项目主页GitHub
LISA可以完成四种任务
- complex reasoning;
- world knowledge;
- explanatory answers;
- multi-turn conversation
模型架构
生成mask
这里作者提出了一些问题,就是大部分llm是不具备视觉能力,有视觉能力的泛化型不好还不好训练。相比之下,训练 LISA-7B 在 8 个 NVIDIA 24G 3090 GPU 上只需要 10,000 个训练步骤。(嗯8块3090)
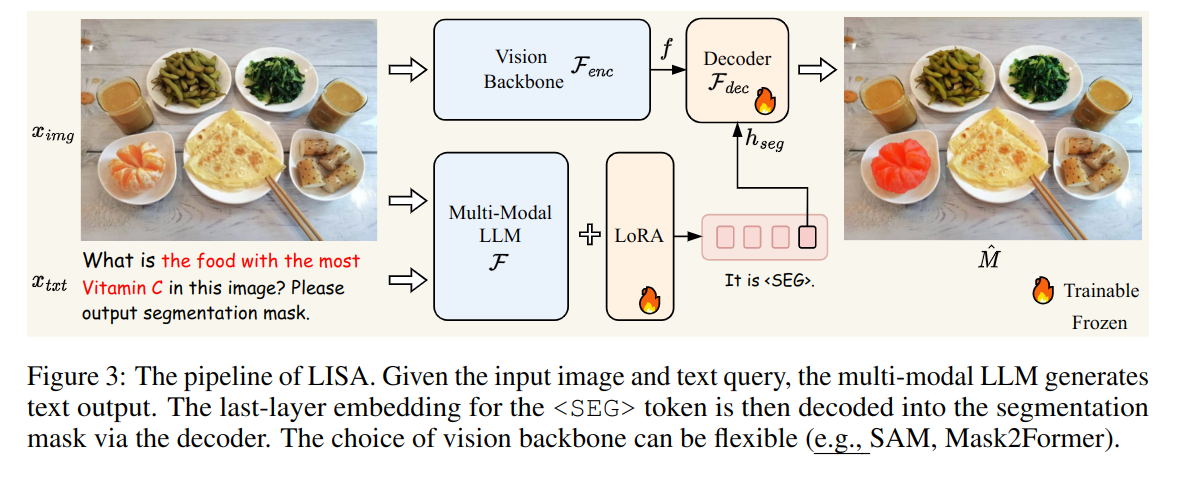
模型结构就是上面这张图,右下角标了火花的就说明是需要训练或者微调的。首先扩充词表,加入<SEG> ,接下来给出一张图片\(x_{img}\)和一段文本\(x_{txt}\), 将他们送入大语言模型\(\mathcal{F}\) ,写成公式就是$$\hat{\boldsymbol{y}}{txt}=\mathcal{F}(x,\boldsymbol{x}_{txt}).$$
当LLM倾向于生成二进制分割掩码时,输出\(\hat{\boldsymbol{y}}_{txt}\)应该包含一个<SEG>令牌。所以提取最后一层嵌入\(\hat{h}_{seg}\) (因为他和<SEG> token 是相关的), 并用一个MLP \(\gamma\) 将其投影到\(h_{seg}\)。
同时,视觉编码器\(\mathcal{F_{enc}}\) 会从图片中提取出视觉特征\(\text{f}\) 。
最后\(h_{seg}\)和\(\text{f}\) 会被送入一个和SAM有相同架构的解码器,获得最后的mask.
整个过程表示出来就是$$\begin{gathered}\boldsymbol{h}{seg}=\gamma(\hat{\boldsymbol{h}}),\quad\boldsymbol{f}=\mathcal{F}{enc}(\boldsymbol{x}),\\hat{\boldsymbol{M}}=\mathcal{F}{dec}(\boldsymbol{h},\boldsymbol{f}).\end{gathered}$$
训练目标
训练目标是文本生成损失 \(\mathcal{L}_{txt}\) 和分割掩码损失 \(\mathcal{L}_{mask}\) 进行端到端训练。总体目标 \(L\) 是这些损失的加权和,由 \(\lambda_{txt}\) 和 \(\lambda_{mask}\) 确定$$\mathcal{L}=\lambda_{txt}\mathcal{L}{txt}+\lambda\mathcal{L}_{mask}.$$
训练
数据集
训练数据由三部分组成,都是开源数据集
- Semantic Segmentation Dataset
- Vanilla Referring Segmentation Dataset
- Visual Question Answering Dataset
值得注意的是,LISA具有zero-shot能力,因为训练集不包含任何推理分割的内容。
需要训练的参数
为了保持llm的泛化能力作者用了lora,解码器可以被微调,llm的词嵌入和投影最后一层潜入的mlp也可以微调
标签:分割,训练,boldsymbol,笔记,mathcal,LISA,txt,推理 From: https://www.cnblogs.com/studyinglover/p/17857329.html