神经网络基础
线性函数(得分函数)
计算每个类别的得分:每个像素点都会影响结果(像素点的权重参数)
f(image,parameters)
每个像素点都需要有一个权重,每个像素点会按RGB拆分成三个矩阵中的元素
单行矩阵(每个像素点的权重)x像素点(所有像素点) = 1x1矩阵(得分)
f(x,W) = Wx + b
简而言之,就是每个类需要一个预设的权重模板,把图像用每个权重模板(单行矩阵)都计算一次得分,在某一模板下得分最高,代表这个图像最适用于这个模板,也就属于这个类
模板矩阵通过不断优化得到,需要不断迭代调整
损失函数
衡量每次分类结果的好坏程度(量化)
实例:
损失程度 = 求和所有的max
(0,某分类结果类得分 - 真实类得分+1),不包含正确类本身
+1是设置容忍程度
如果分类结果得分 和 真实类得分 相差的不够高(差值为-0.01),或者刚好相等时,这样的分类结果也不够好,+1后就需要真实值得分至少比某个类得分高1分才算没有损失
计算出相同损失的模型也有好坏之分
尽量让权重能考虑全面,过度拟合的模型是无效的,只是对训练集的判别效果好,但是对测试集的判别效果反而不好,需要增加正则化惩罚项,避免出现过拟合,即权重出现某一区域过低,考虑不全面。
取舍时,要选择在测试集上表现最好的
一种可能的惩罚项是a*R(W),R(W)为把权重每一项平方后求和,a的大小可以调整惩罚力度
DROP-OUT是一种常见的规避过拟合方法,每次训练都会选择一部分神经元杀死,不参与迭代(一般一个模型需要迭代百万次)
Softmax分类器
将每个得分转化成概率值
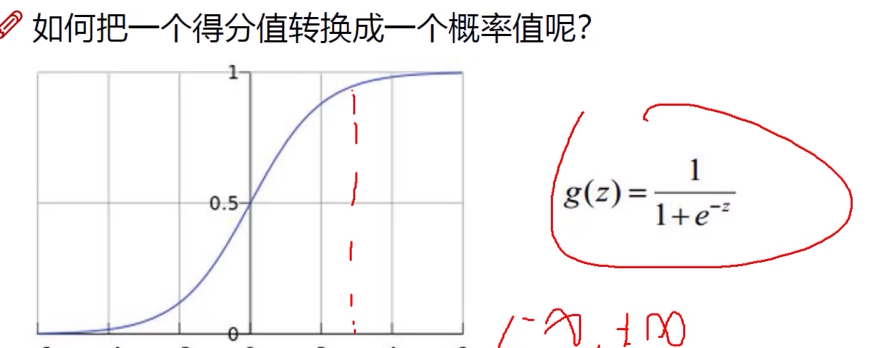
可通过e的x次方进行扩大映射,小的会更小(绝对值),大的会更大,负数变正数
再进行归一化,即变为占比
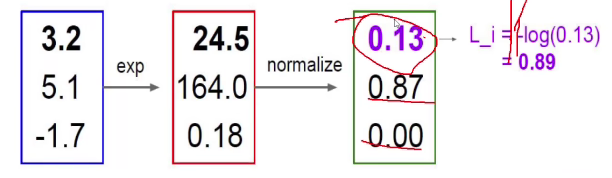
最后,用-log(任意值)(正确概率),一般以10为底
从数学来说,即为 -ln(正确概率值),概率值越趋于1,映射值(损失程度)越趋于0
前向传播
梯度下降法
逐层求导,链式法则,偏导值相乘
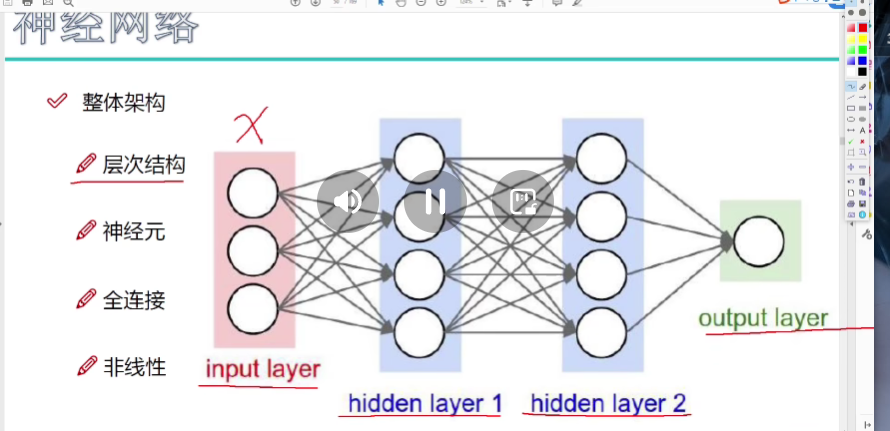
整体架构
输入预处理
输入数据处理后(根据数据类型预处理)进入输入层
总体过程
数据先经过预处理(居中,缩放)后进入输入层,输入层与隐蔽层之间、隐蔽层与隐蔽层之间用参数矩阵全连接,并综合所有特征再创造出一个易于计算机识别的特征,本层所有神经元对数据进行处理后用激活函数(主流是Relu函数)进行一次非线性变换,再交给下一层神经元处理,知道最后给出结果(损失程度)。
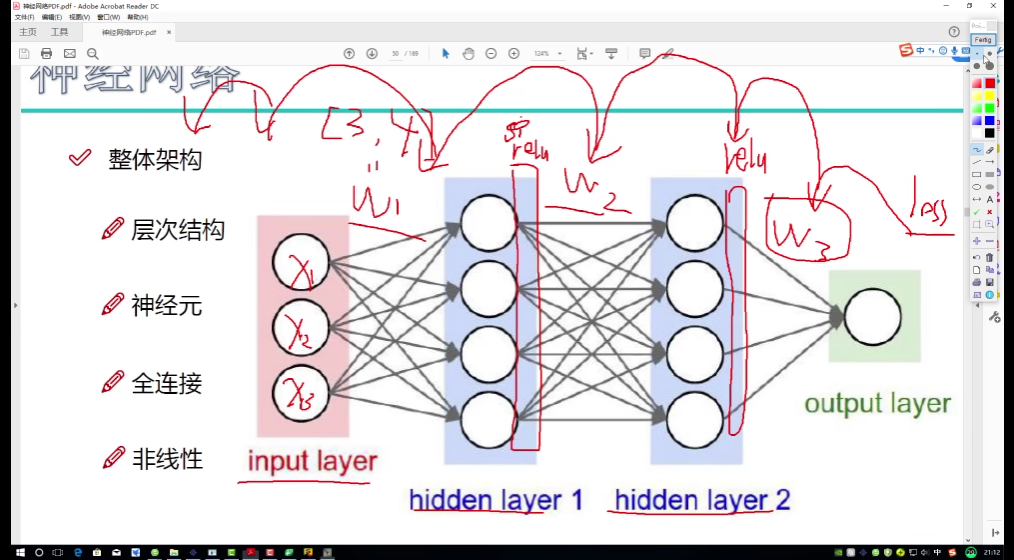
进行反向传播时,由loss值对第一层权重求偏导,再对relu求偏导(从数学上要求,但是relu函数的特性决定了其不会影响结果,怎么求都是1,任何数乘1还是本身)。最终目的是寻找层之间的权重
卷积神经网络
输入层:输入图像数据
卷积层:提取特征
池化层:压缩特征
全连接层:和神经网络相同
卷积:将输入图像分块后,依次做卷积,能够将大图像提取出小特征
RGB通道(三个通道)分别计算后相加
同一个卷积层中,卷积核的大小必须相同,三个维度做完一次卷积后得到一个特征图(feature map)
“权重模板”即为卷积核,一般情况下都是多个卷积核提取出多种特征,下一次卷积是在上一次卷积结果之上进行的!
求卷积时要加Bias常量,卷积其实就是内积
卷积层涉及的参数
滑动窗口步长:每次移动的像素点数
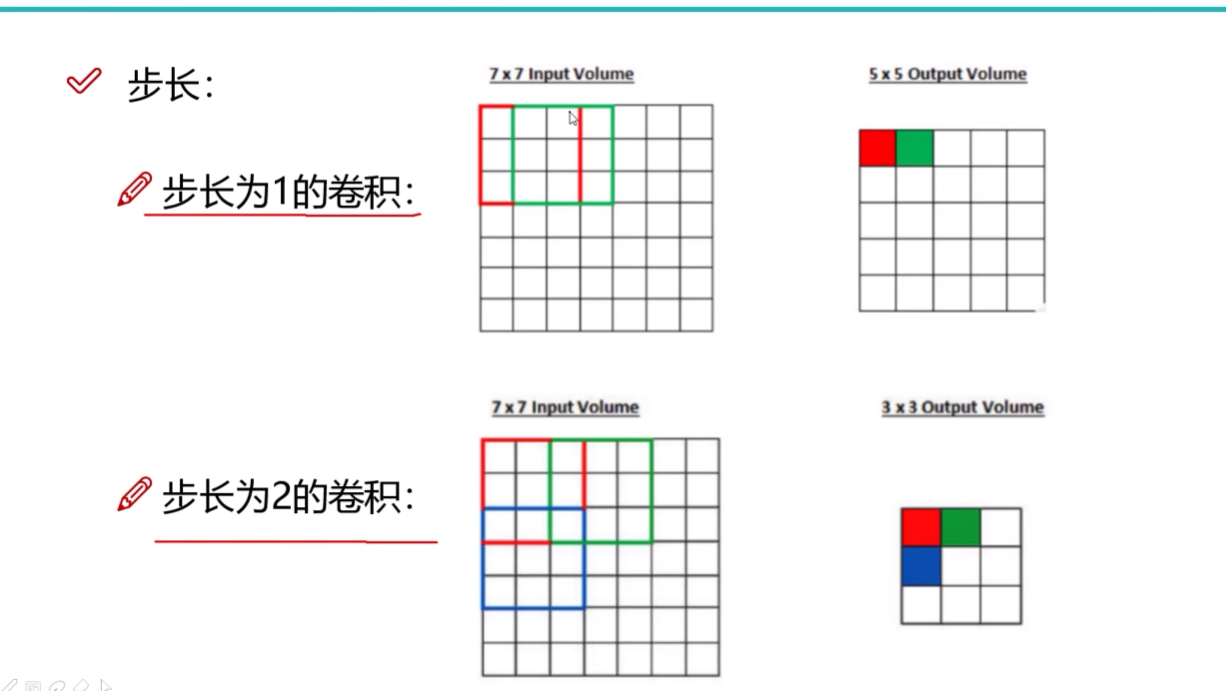
步长越大,得到的特征图越小
最常用的步长为1
步长为2时效率高,但是准确率不一定高
卷积核尺寸
图像任务卷积核一般为正方形(3x3或更大)
文本任务卷积核为长方形
边缘填充
Input Volume(+pad 1)
+pad 1即为给边缘填充一圈0
能够一定程度上弥补边界特征利用不全的问题
卷积核个数
要得到多少个特征图,就用几个卷积核,在卷积神经网络训练中,这些卷积核中的数字互不相同,且会各自调整自己的参数
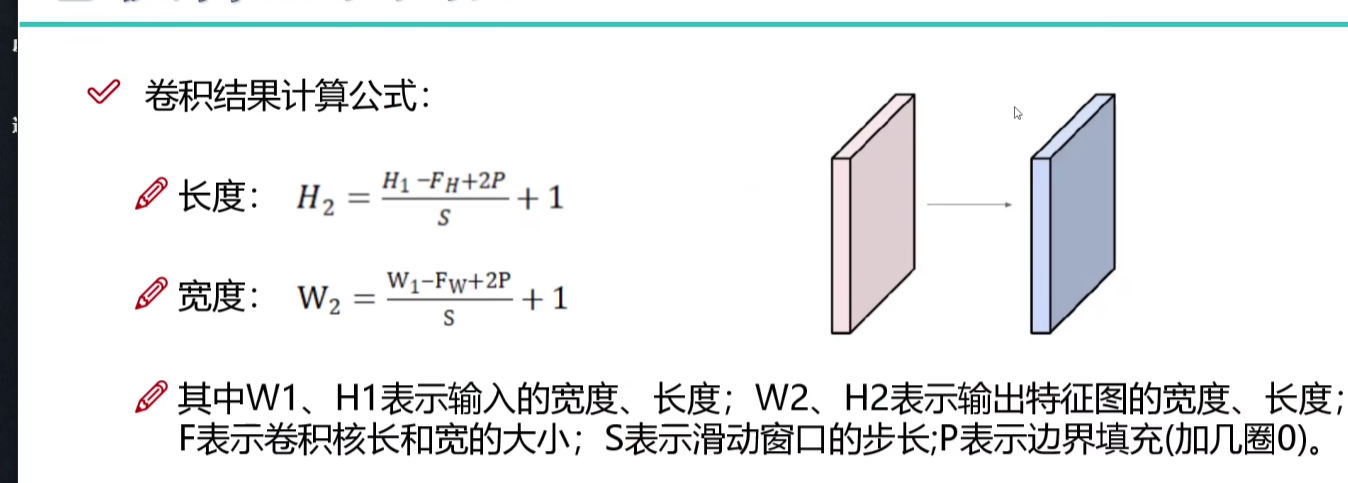
卷积结果计算公式
涉及到:输入长宽、卷积核长宽、边缘填充圈数
卷积参数共享
一个Filter的一个通道中,不同位置的卷及操作用的卷积核是相同的,这样能够减少参数量
池化层
最大池化(MAX POOLING)
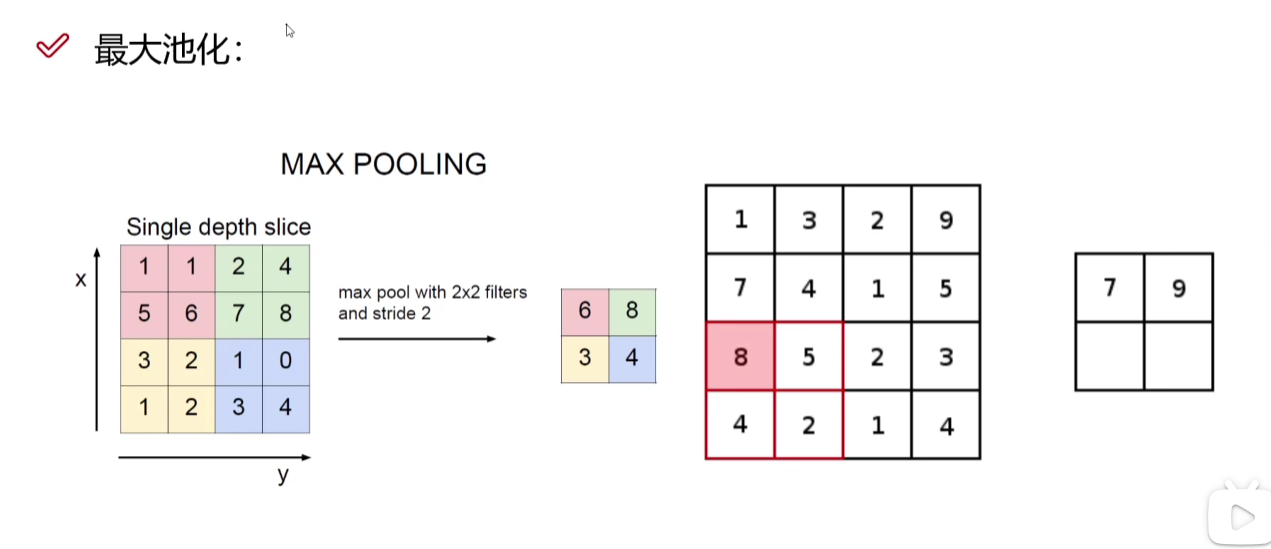
取每个小区域(图中是2x2)中的最大值作为最大特征,因为数值大小由权重决定,越大代表越重视这个特征
带参数计算的才算一层,没有参数参与计算的,反向传播不会影响它
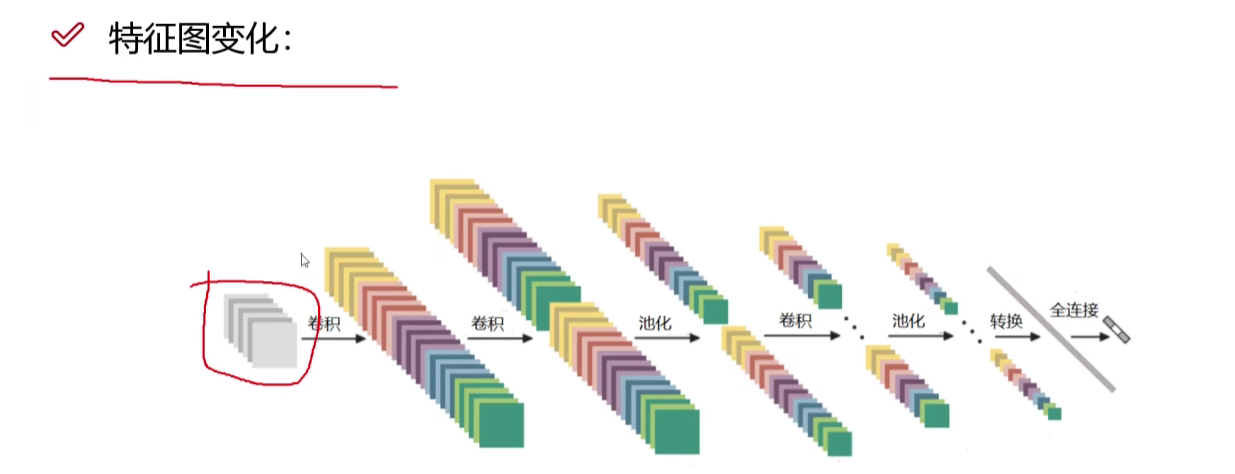
池化和卷积交替进行
最后把立体特征图转换成矩阵进行全连接
感受野
当前层的感受野就是,这层的某一个值,涉及到原始输入数据的几个值,就是这层的感受野
相同的感受野,尽量用小的卷积核(3x3),能减少参数量

77的例子中,第一个C是特征图数量,77是卷积核大小,最后的C是输入的通道数
在VGG网络中,核心思路就是用小的卷积核提取特征
递归神经网络
RNN网络
递归神经网络是对传统神经网络的改进
简而言之,其预测结果会考虑之前的输入结果,常用语自然语言处理(上下文或给一句话分部分)
其也有明显弊端,及最后的输出总会考虑之前的所有结果,而语言处理往往只需要考虑最后结果的前几句输入
LSTM网络
解决RNN网络弊端,通过引入控制参数C,对之前的信息进行选择性保留和遗忘。
简而言之LSTM网络就是在RNN网络基础上引入控制参数,降低模型复杂度
自然语言处理模型-词向量模型(Word2Vec)
将文本向量化
1.词序不同,向量化结果必须不同
2.两个词义相近的向量,所在位置应该离得很近
二维向量能表达的特征太少了,不能用于文本向量化,谷歌给出的文本向量维度在50维到300维之间,维度越高月、越准确,但是计算速度也会有所下降
在训练中,神经网络要做的就是不断调整词汇对应的向量,使得整个模型能够更好的预测下一个词汇是什么
向量相似度计算
通过计算两个向量支架欧氏距离,余弦距离等等
词向量中的输入和输出
给神经网络输入单词前进行Look ip embedding(在词库中找到对应词,将词变成向量)
用于训练词向量的数据,只要是符合人类正常说话逻辑的文本,都可以用于训练
构架训练数据
将一段文本用长度为3(或其他奇数)的窗口滑动生成(步长为1,使得预测结果能成为一下词的训练数据)
训练词向量模型
CBOW模型:
窗口长度为5,输入为上下文各两个字,需要预测中间第三个字
Skipgram模型:
输入中间的字,预测上下文
和图像分类不同的是,自然语言处理在最后一层需要大量分类,例如词库中有50000个词,就需要进行50000分类,而自然语言处理会将输出结果当做输入,通过神经网络预测原本的输入和被当做输入的输出结果是否能构成上下文,能则预测为1,不能则为0,相当于把1个任务的5w分类转化成5w个任务的二分类,因此自然语言处理模型需要通过神经网络反向传播更新权重参数矩阵W,更新输入数据词库(词向量库)以及sigmoid()函数
标签:得分,人工智能,导论,卷积,神经网络,Deeplearning,向量,像素点,输入 From: https://www.cnblogs.com/cupCheng/p/17557478.html