前置芝士:
神经网络
前言
人脑视觉机理,是指视觉系统的信息处理在可视皮层是分级的,大脑的工作过程是一个不断迭代、不断抽象的过程。视网膜在得到原始信息后,首先经由区域V1初步处理得到边缘和方向特征信息,其次经由区域V2的进一步抽象得到轮廓和形状特征信息,如此迭代地经由更多更高层的抽象最后得到更为精细的分类。
比如,人眼判断一只气球的过程如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。

如图来说,人眼所得到的最基础的信息是各种像素,在往上会提取到各种边缘,然后是各个局部(比如眼睛,嘴巴),最后形成对整个物体的印象。
卷积神经网络就是从人眼受到启发,从而实现了一种由局部特征判断整体的方法。
一.简介
在卷积神经网络出现前,计算机图像处理是个很麻烦的东西。首先图像本身数据量非常大,其次对于计算机来说,图像其实就是一个数组,失去了人眼看来的物体特征,无法一眼看出图像中是什么东西。
卷积神经网络 Convolutional Neural Network (CNN)的出现,使得计算机拥有了提取图片特征的能力。它在我上述提到的两个地方做出了优化。
1.缩小图像规模
一个数据量很大的图像,保留了非常多无用的细节(指的是判断上),以贴近生活的例子来说,当我们看视频时,不论使用蓝光4K还是标清360P,都能看出画面的主体是人还是什么动物。卷积神经网络使用了池化来减小图像的规模
一般池化采用的方式有平均值池化和最值池化,就是对目标区域取平均值或者最值填到对应区域内。
2.提取图像特征
这里是用到了卷积的方式。
他的大体过程就是利用卷积核对图像进行过滤,得到一个新的图像。如果过滤后的结果越大,表示图像越接近卷积核的特征
二.结构
从网络上找到了一张图,可以比较清晰地看出卷积神经网络的结构

最左边是数据输入层,一般进行的操作是去均值(就是所有的数据都同时减去均值)。这样可以防止数据过拟合。因为在神经网络特征值x较大时,很容易导致w*x+b较大,这样在进行激活函数输出时,会导致对应变化量很小。而在反向传播中,我们用到了梯度下降法,过小的变化量会导致梯度消散,更加易于拟合,效果不好。
CONV是卷积层,它的主要作用是用一个滤波器去卷积一个给定的输入,再加上对应的偏置,得到一个新的图层。
RELU是激励层,这个名字的原因是使用了RELU函数。这层我在不同博客的讲解中见到了不同的说法,有的把它作为卷积层的一部分,有的把它单独拿出来。我这里为了让整个过程更直观,还是把它单独拿出来了。
POOL是池化层,它的作用是将数据降维,可以减少数据量并且保留它的特征。
FC是全连接层,它的作用是根据不同任务输出想要的结果。
三.卷积层
首先定义卷积的操作

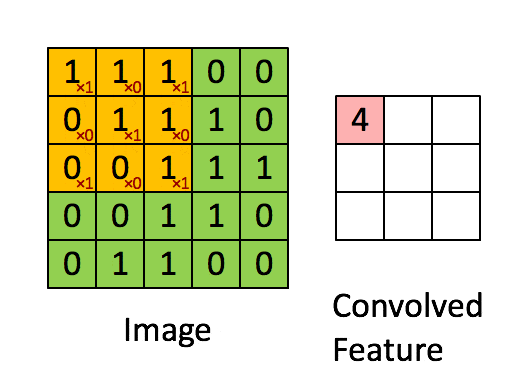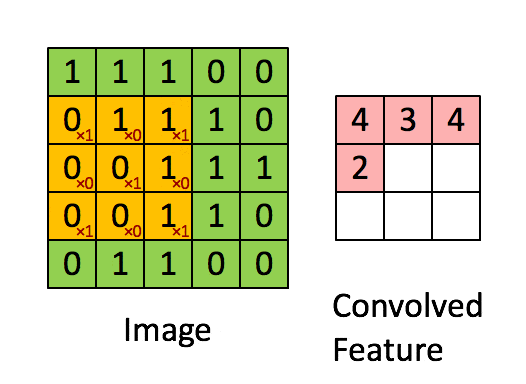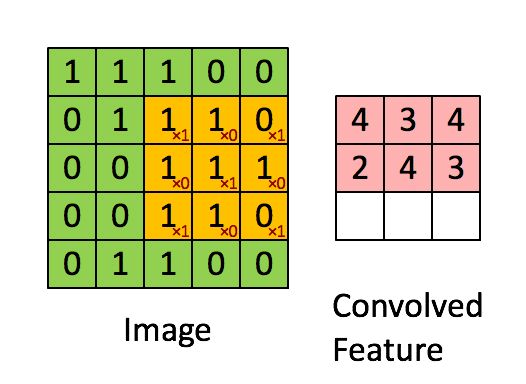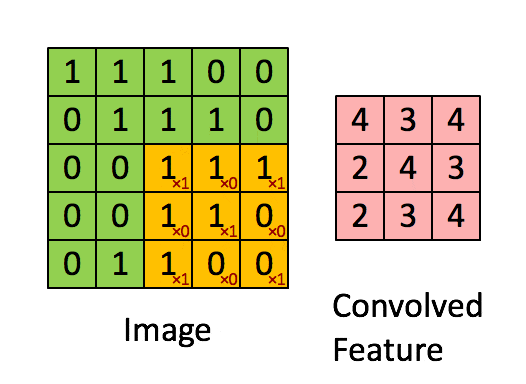
具体如下,首先在给定的矩阵中选择一个3*3的部分记为A,给定一个卷积核记为B,卷积得到的是一个数,如下

\(A = \begin{bmatrix}
1 & 1 &1\\
1&1&0\\
1&0&0
\end{bmatrix}\ \ \
B = \begin{bmatrix}
1 & 0 &1\\
0&1&0\\
1&0&1
\end{bmatrix}\)
\(C = \begin{bmatrix}
1\times 1 & 1\times 0 &1\times 1\\
1\times 0&1\times 1&0\times 0\\
1\times1&0\times0&0\times 1
\end{bmatrix} = 4\)
还是比较直观的,就是对应的元素相乘,再把所有这样的结果相加
完整的动图如下
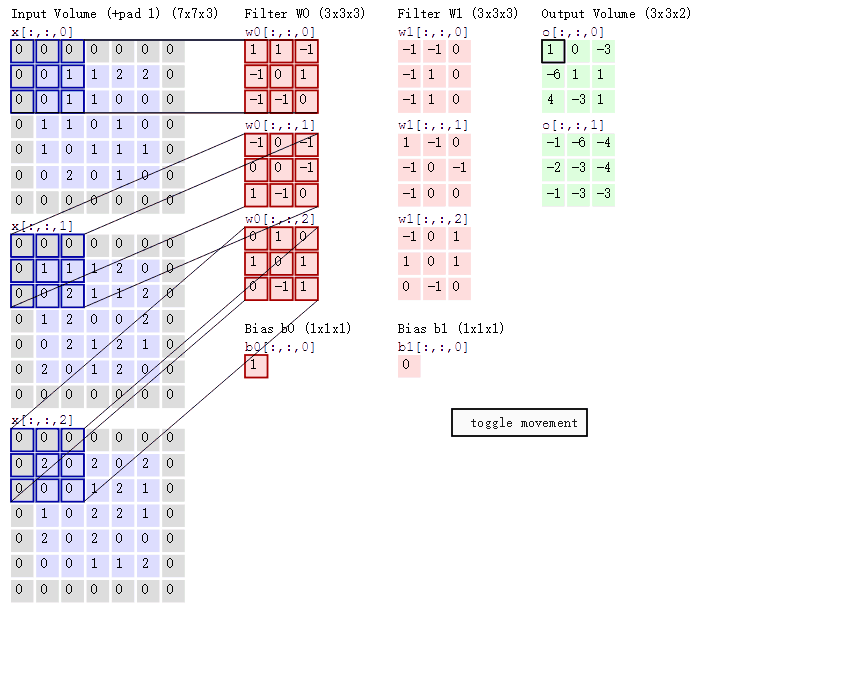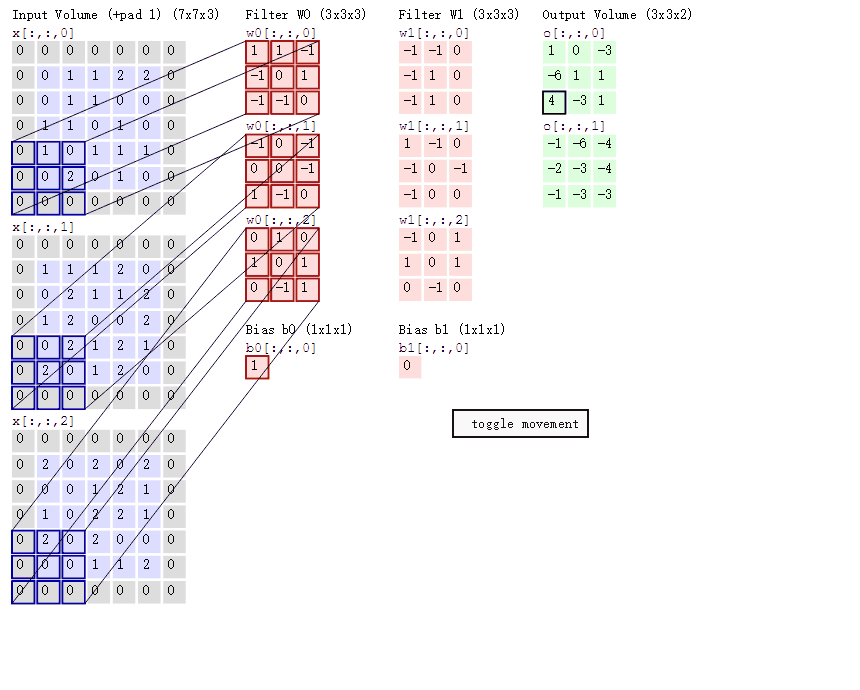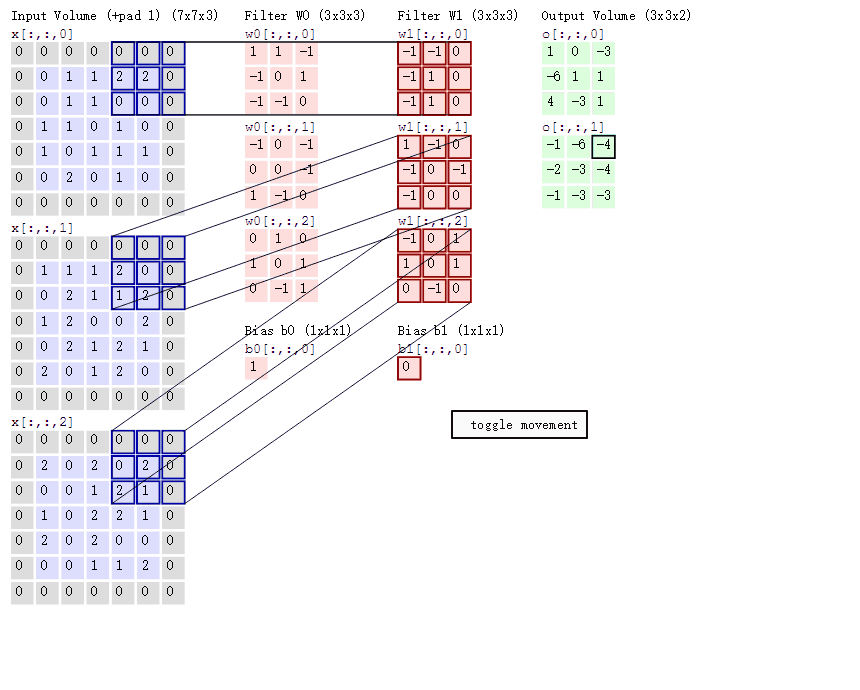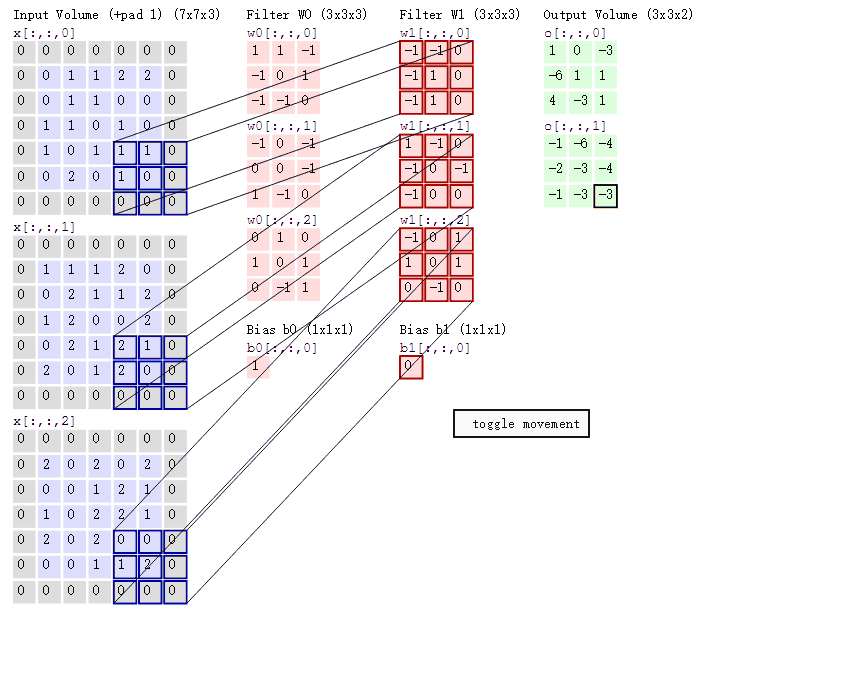
如果输入通道不止一个,那么这个卷积核是三阶的。
此时对每一个输入通道单独确定一个卷积核,然后将每一个对应的区域卷积得到的值加起来,最后加上偏置,就得到了对应的输出。
不同的卷积核用于提取不同特征。
可以看下图
四.激励层
ReLU,全称为:Rectified Linear Unit,是一种人工神经网络中常用的激活函数,通常意义下,其指代数学中的斜坡函数
\(f(x)=max(0,x)\)
它的的图像如下
ReLU看起来更像一个线性函数,一般来说,当神经网络的行为是线性或接近线性时,它更容易优化 。
这个特性的关键在于,使用这个激活函数进行训练的网络几乎完全避免了梯度消失的问题,因为梯度仍然与节点激活成正比。
缺点也同样明显:输出不是0对称;由于小于0的时候激活函数值为0,梯度为0,所以存在一部分神经元永远不会得到更新。
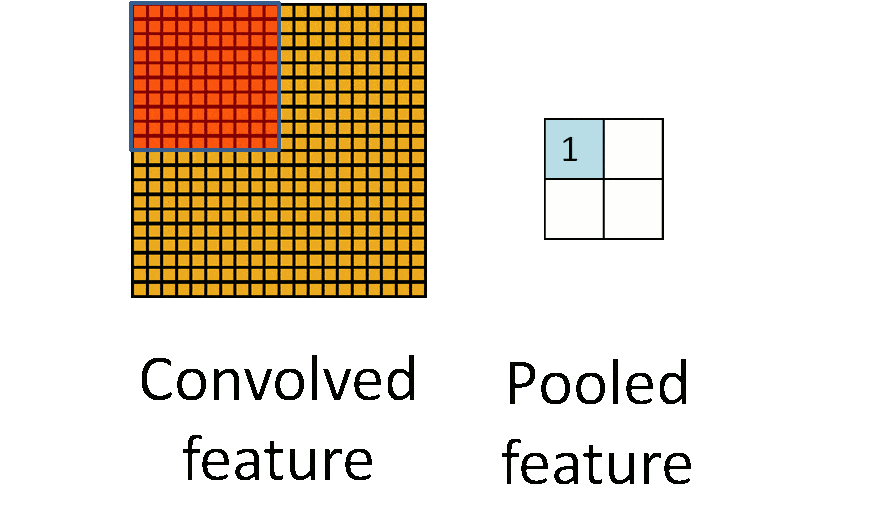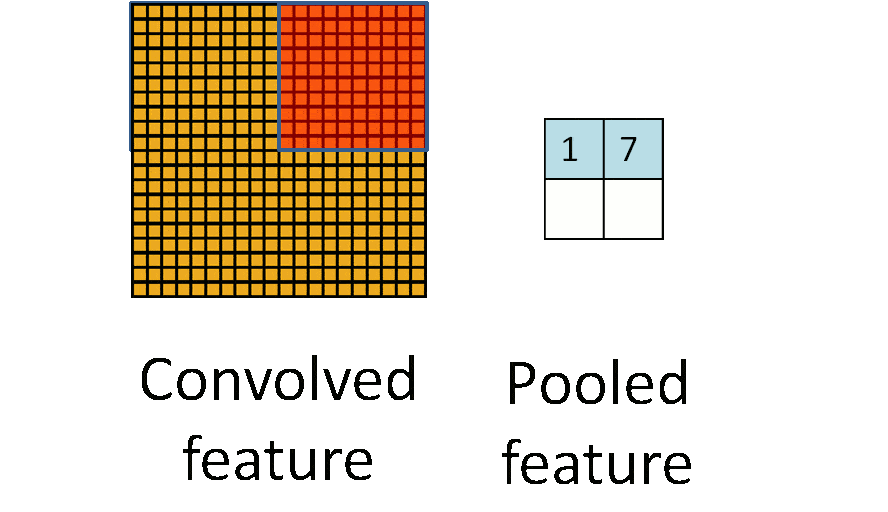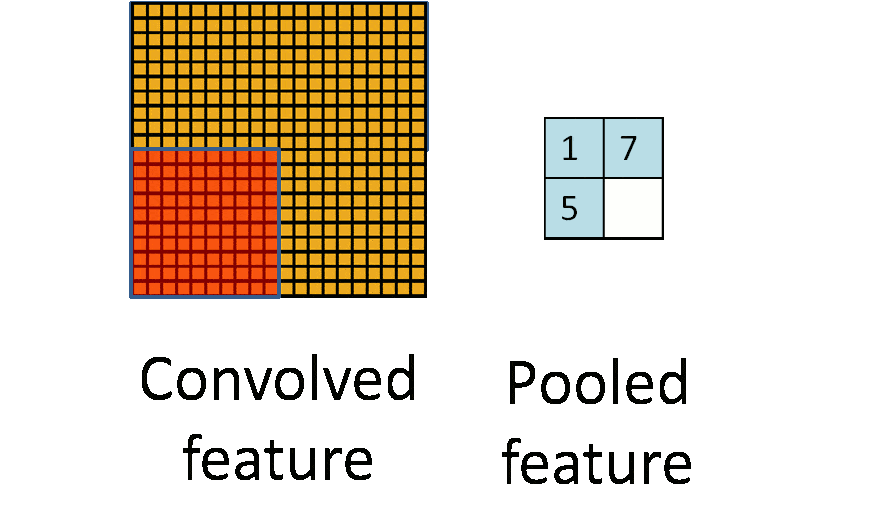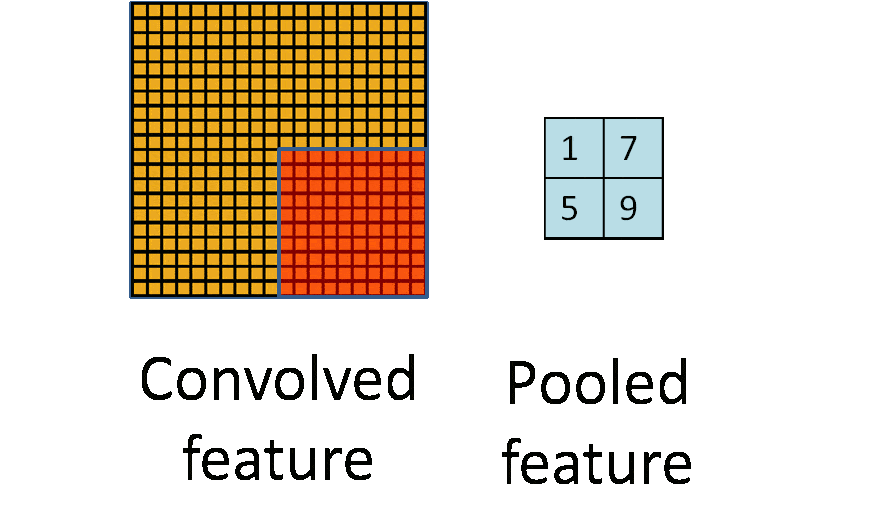
五.池化层
一般使用区域平均值或者最大值的方式,其他还有L2池化等
池化也有步长和补齐的概念,但是很少使用,通常选择框以不重叠的方式,在padding=0的输入数据上滑动,生成一张新的特征图
参考:
链接
链接