对一个事物的评价往往会涉及多个因素或者多个指标,评价是在多个因素相互作用下的一个综合判断。多指标综合评价方法具有以下的特点:包含若干个指标,分别说明被评价对象的不同方面,评价方法最终要对被评价对象作出一个整体性的评判,用一个总指标来说明被评价对象的一般水平。层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.Saaty)正式提出。它是一种定性和定量相结合的、系统化、层次化的分析方法。由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。
一、层次分析法概述
层次分析法的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。不妨用假期旅游为例:假如有3个旅游胜地A、B、C供你选择,你会根据诸如景色、费用和居住、饮食、旅途条件等一些准则去反复比较这3个候选地点.首先,你会确定这些准则在你的心目中各占多大比重,如果你经济宽绰、醉心旅游,自然分别看重景色条件,而平素俭朴或手头拮据的人则会优先考虑费用,中老年旅游者还会对居住、饮食等条件寄以较大关注。其次,你会就每一个准则将3个地点进行对比,譬如A景色最好,B次之;B费用最低,C次之;C居住等条件较好等等。最后,你要将这两个层次的比较判断进行综合,在A、B、C中确定哪个作为最佳地点。
1.1 层次分析法的基本步骤
> 建立层次结构模型。在深入分析实际问题的基础上,将有关的各个因素按照不同属性自上而下地分解成若干层次,同一层的诸因素从属于上一层的因素或对上层因素有影响,同时又支配下一层的因素或受到下层因素的作用。最上层为目标层,通常只有1个因素,最下层通常为方案或对象层,中间可以有一个或几个层次,通常为准则或指标层。当准则过多时(譬如多于9个)应进一步分解出子准则层。
构造成对比较阵。从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,用成对比较法和1—9比较尺度构造成对比较阵,直到最下层。
| 表1 比例标度表 | |
|-----------|---------|
| 因素i比因素j | 量化值 |
| 同等重要 | 1 |
| 稍微重要 | 3 |
| 较强重要 | 5 |
| 强烈重要 | 7 |
| 极端重要 | 9 |
| 两相邻判断的中间值 | 2,4,6,8 |
计算权向量并做一致性检验。对于每一个成对比较阵计算最大特征根及对应特征向量,利用一致性指标、随机一致性指标和一致性比率做一致性检验。若检验通过,特征向量(归一化后)即为权向量:若不通过,需重新构造成对比较阵。
计算组合权向量并做组合一致性检验。计算最下层对目标的组合权向量,并根据公式做组合一致性检验,若检验通过,则可按照组合权向量表示的结果进行决策,否则需要重新考虑模型或重新构造那些一致性比率较大的成对比较阵。
1.2 指标权重的确定
层次分析法在应用过程中,最明显的特点是要【构建判断矩阵】,让专家进行【两两的重要性对比打分】。做1轮专家打分即可。调查问卷的格式如下:
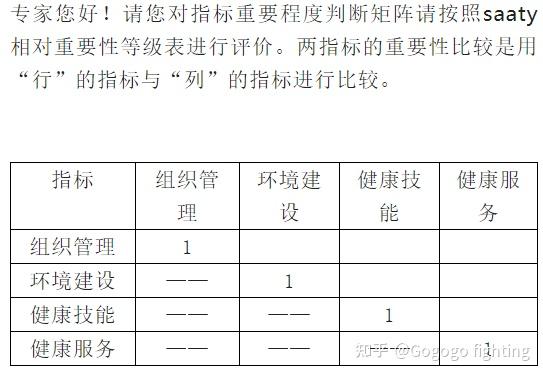
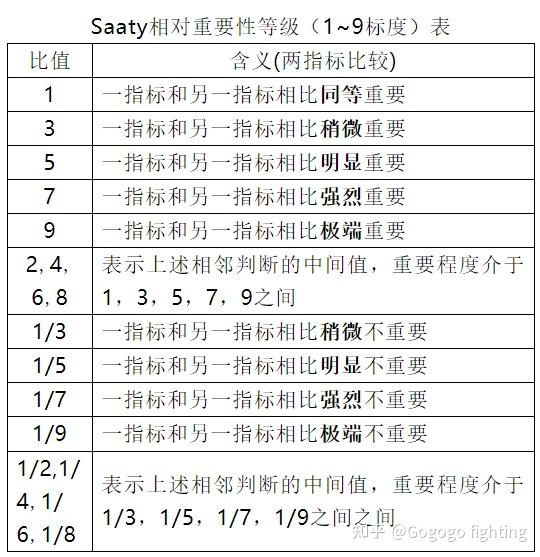
由于是正互反矩阵,所以,只需要填写一半就可以,另一半在数据收集后进行倒数的填补就可以。其中saaty相对重要性等级表如下。
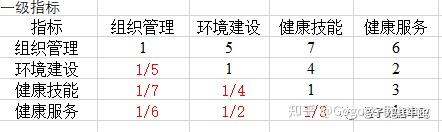
由于数据是一个正互反矩阵,因此在数据录入的时候,要保持数据的矩阵格式,可以采取的录入格式如下:
1.3 层次分析法的计算过程
层次分析法在分析过程中,需计算以下内容:
计算指标初始权重系数
一般有算术均值,和积法,也有方根法,以方根法为例:
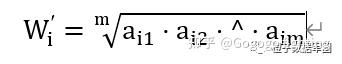
对权重系数归一化
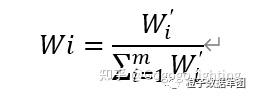
计算最大特征根\(λ_max\)
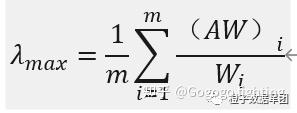
进行一致性检验(CR值)
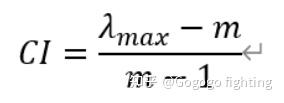

一般情况下,\(CR<0.1\),代表判断矩阵具有一致性。对所有专家的所有判断矩阵都需要进行一致性检验,其次汇总所有归一化系数,得到各级指标的权重系数。层次分析法的判断矩阵在后期分析时,有些矩阵难免CR值>0.1,因此常见的方法是进行微调。
二、层次分析法应用示例
某单位拟从3名干部中选拔一名领导,选拔标准有政策水平、工作作风、业务知识、口才、写作能力和健康状况六项,下面使用AHP进行综合评估。对于选拔的六个标准,我们认为健康水平、业务知识、写作能力和政策水平同等重要,健康状况相对于口才处于稍微重要与明显重要之间,即标度为4,工作作风相对于健康状况处于同等重要和稍微重要之间,标度为2等等。对此我们可以构造判断矩阵:
options(digits = 3)
A<-c(1,1,1,4,1,1/2,1,1,2,4,1,1/2,1,1/2,1,5,3,1/2,
1/4,1/4,1/5,1,1/3,1/3,1,1,1/3,3,1,1,2,2,2,3,1,1)
names<-c("健康情况","业务知识","写作能力","口才","政策水平","工作作风")
judgeMatrix<-matrix(A,nrow = 6,byrow = TRUE,dimnames = list(names,names))
judgeMatrix
判断矩阵输出为:

同理我们可以得到这3名干部关于选拔标准的六个判断矩阵,将其设定为A1,A2,A3,A4,A5,A6
#健康状况
name<-c("甲","乙","丙")
a1<-c(1,1/4,1/2,4,1,3,2,1/3,1)
A1<-matrix(a1,nrow = 3,byrow = TRUE,dimnames = list(name,name))
#业务知识
a2<-c(1,1/4,1/4,4,1,1/2,4,2,1)
A2<-matrix(a2,nrow = 3,byrow = TRUE,dimnames = list(name,name))
#写作能力
a3<-c(1,3,1/3,1/3,1,1/6,3,6,1)
A3<-matrix(a3,nrow = 3,byrow = TRUE,dimnames = list(name,name))
#口才
a4<-c(1,1/3,5,3,1,7,1/5,1/7,1)
A4<-matrix(a4,nrow = 3,byrow = TRUE,dimnames = list(name,name))
#政策水平
a5<-c(1,1,7,1,1,7,1/7,1/7,1)
A5<-matrix(a5,nrow = 3,byrow = TRUE,dimnames = list(name,name))
#工作作风
a6<-c(1,7,9,1/7,1,2,1/9,1/2,1)
A6<-matrix(a6,nrow = 3,byrow = TRUE,dimnames = list(name,name))
A1;A2;A3;A4;A5;A6
输出结果为:

利用自编函数weight对七个判断矩阵进行权重的计算
输入:judgeMatrix 判断矩阵;round 结果约分位数
输出:权重
weight <- function (judgeMatrix, round=3) {
n = ncol(judgeMatrix)
cumProd <- vector(length=n)
cumProd <- apply(judgeMatrix, 1, prod) ##求每行连乘积
weight <- cumProd^(1/n) ##开n次方(特征向量)
weight <- weight/sum(weight) ##求权重
round(weight, round)}
W<-weight(judgeMatrix);W
w1<-weight(A1);w1
w2<-weight(A2);w2
w3<-weight(A3);w3
w4<-weight(A4);w4
w5<-weight(A5);w5
w6<-weight(A6);w6
输出结果为:

填充好权重矩阵之后,需要对判断矩阵后进行一致性检验
若计算得到一致性比例CR<0.1,则通过检验,权重矩阵有效
CRtest为自编一致性检验函数
注:CRtest调用了weight函数
输入:judgeMatrix
输出:CI, CR
CRtest <- function (judgeMatrix, round=3){
RI <- c(0, 0, 0.52, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49, 1.51) #随机一致性指标
Wi <- weight(judgeMatrix) ##计算权重
n <- length(Wi)
if(n > 11){
cat("判断矩阵过大,请少于11个指标 \n")
}
if (n > 2) {
W <- matrix(Wi,ncol = 1)
judgeW <- judgeMatrix %*% W
JudgeW <- as.vector(judgeW)
la_max <- sum(JudgeW/Wi)/n
CI = (la_max - n)/(n - 1)
CR = CI/RI[n]
cat("\n 判断矩阵为:",judgeMatrix,"\n")
cat("\n CI=", round(CI, round), "\n")
cat("\n CR=", round(CR, round), "\n")
if (CR <= 0.1) {
cat(" 通过一致性检验 \n")
cat("\n Wi: ", round(Wi, round), "\n")
}
else {
cat(" 请调整判断矩阵,使CR<0.1 \n")
Wi = NULL
}
}
else if (n <= 2) {
return(Wi)
consequence <- c(round(CI, round), round(CR, round))
names(consequence) <- c("CI", "CR")
consequence }
}
对七个判断矩阵进行一致性检验
相应的权重矩阵为W,w1,w2,w3,w4,w5,w6
结果表明均通过一致性检验
CRtest(judgeMatrix)
CRtest(A1)
CRtest(A2)
CRtest(A3)
CRtest(A4)
CRtest(A5)
CRtest(A6)
输出结果为:

计算方案层得分向量
由结果可知:三位干部的评分分别是0.377,0.325,0.299,干部甲评分最高。
w_matrix<-cbind(w1,w2,w3,w4,w5,w6)
point<-w_matrix %*% W;point
总结
层次分析法是指将一个复杂的多目标决策问题作为一个系统,将目标分解为多个目标或准则,进而分解为多指标(或准则、约束)的若干层次,通过定性指标模糊量化方法算出层次单排序(权数)和总排序,以作为目标(多指标)、多方案优化决策的系统方法。层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。目前大多数研究都是将德尔菲法和层次分析法两个方法相结合进行研究,结合的方法是先用德尔菲法对指标体系进行筛选,然后确定指标体系以后,然后再用层次分析法确定权重。
参考文献
R语言实现AHP层次分析法
层次分析法
R语言:层次分析法(AHP)