基于深度学习的轻量化姿态检测模型设计
摘 要: 随着深度神经网络和智能移动设备的快速发展,单目人体姿态检测的技术门槛逐步降低,网络结构轻量化设计逐渐成为前沿且热门的研究方向。当单目人体姿态检测与模型轻量化相结合,在低配置的移动终端如单片机上进行保证精度的人体姿态检测便成为可能。阐述深度学习的单目人体姿态检测模型轻量化网络结构设计方法,对比分析人工设计的轻量化方法、基于神经网络结构搜索的轻量化方法和基于自动模型压缩的轻量化方法以及在深度学习基础上单目输入与深度、红外光源、射频信号、多视图输入等传统检测方法上的创新点与优劣势,同时对其应用方向及未来发展趋势进行展望。 关键词: 深度学习;轻量化设计;单目姿态检测;神经网络结构搜索;模型压缩;1. 引言
1.1 论文研究背景及意义
1.1.1 自动驾驶
随着自动驾驶技术的逐渐推广,随之而来的是社会各界对于其安全性的质疑,再加上智能驾驶汽车导致的伤亡的消息不断,这给自动驾驶隶属的人工智能和计算机视觉领域带来了阴霾。究其原因,车载的行人、障碍物检测系统终究只是一个片上系统(SOC),无法实现低延迟的识别和判断可能是导致惨剧发生的原因,而寻找性能更加优越的人体姿态估计网络可以弥补这一缺陷。通过基于深度学习的人体姿态估计网络课已通过对行人的意图进行判断,来减弱行人检测系统对实时性的要求。即便如此,自动驾驶技术与生命息息相关,因此网络轻量化在这一方面仍然是任重而道远,而行人检测算法虽然有了一定进步,但面对实际复杂场景的能力还有待增强。
1.1.2 智慧房间
随着传感器网络的不断发展,我们所能采集到的数据量也日益庞大,人体姿态估计与各种传感器进行配合,在一个房间内便能实现对其中人员从外部视觉到内部各项生理指标的采集。我们便可以对体弱人群如老人、小孩和病患的照顾,或对危险人群如监狱犯人的监控。目前国内外已经有很多企业和学术机构进行相关方面的研究,如Google、MIT和百度等。随着这些研究的深入,智慧房间的需求也越来越强,成为各界共同关注的问题。
1.1.3 检测和监测
将智慧房间的范围扩大,如覆盖到整个火车站、机场、银行或者政府大楼,通过学习人体姿态序列可以发现不正常的行为,帮助治安人员预防和及时控制危险人员。在这样的场景下,人体数量成为了此时网络运算速率的影响因素。虽说已有自下而上方法速度不受人体数量的影响,但目前为止这种方法实现的精度暂时无法媲美自上而下的方法。
1.1.4 运动学指导
人体姿态估计标记处的是关节这些稀疏关键点和关节之间的连线——骨骼,通过骨骼的运动可以精确地判断出人体的动作,通过三维人体姿态估计,运动员和教练可以无死角地观察优秀运动员的动作,便于教练和老师的指导。而对于单目人体姿态估计一个很重要的部分就是对于被遮挡的肢体的预测,当出现重合部分时,自下而上的方法便展现出优势,而自上而下的方法一定会将人体分割,导致无法判断系数关键点之间的正确连接。
1.2 国内外研究现状
人体姿态估计技术的发展已经有近十年的时间,在检测速度和检测精度两方面都有了长足的进步。笔者感觉最近几年提出的基于深度学习的姿态估计模型都有几个显著的共同点:
通过multi-stage更多使用Refinement-Stage来提高精度,通过multi-resolution(多尺度)信息融合提取更多的特征信息,更多的使用heatmap(置信图)生成与原图尺寸一致的关节点概率分布图,增大感受野使模型能够利用更多的全局信息对关节点进行更精确的位置预测。
这些机器学习方法的性能很大程度上决定于特征的选取。正是因为这个原因,为了提升算法的性能,研究者往往将大量的时间精力投入在选取更合适的特征上面。这种“特征工程”虽然效果显著,但是本身要借助人类本身先验性的知识和经验,因此不仅要消耗大量的人力,更重要的是它使用的算法没有自己去从数据中学习特征的能力。而深度学习的宗旨正是使机器能够在对输入信息中学习一种无损或是低损的数据的表达,使得提取对分类器或预测器有用的信息更加容易。《Learning Deep Architectures from AI》一文从理论上证明了在解决复杂问题(如视觉信号、音频信号处理)方面,深度网络结构比浅层结构具有达到更好表现的潜力。因此深度学习在行人检测领域有潜力取得比传统方法更好的成绩。
随着近年来工业界对于人体姿态估计技术需求的快速增长,以及前几年深度学习技术的提出和广泛应用,人体姿态估计技术从2012年的AlexNet的提出开始进入了深度学习的时代,自此深度学习在计算机视觉领域开始被广泛应用,也因此出现了GoogleNet、VGG、ZF等新型网络结构,并且用途从分类器扩展到了检测器。每年在图像处理和计算机视觉领域的顶级期刊(如PAMI、IJCV等)和顶级会议(如CVPR、ICCV等)上都有很多与人体姿态估计相关的文章。2017年发表的SENet算法ImageNeyt测试集上的top-5 err已经达到了2.251%。
1.3 本文主要内容
本文设计了一种基于OpenPose的轻量化网络结构,使得网络模型在几乎不降低AP(Average Precision,平均精度)的前提下,将参数量减少至原网络的15%。
2. 系统设计方案与可行性分析
2.1 设计要求与指标
要求设计一款基于深度学习算法的针对视频或单目摄像头输入视频进行人体姿态估计的网络结构,要求采用OpenPose或基于OpenPose的其它人体姿态检测算法作为检测器,对视频中的人体姿态能够进行检测并在视频输出中绘制出人体的骨骼姿态。要求算法AP不低于40,运行所需时间和存储空间具有实际可行性。
![[人体姿态估计评价指标]]
2.2 总体设计方案
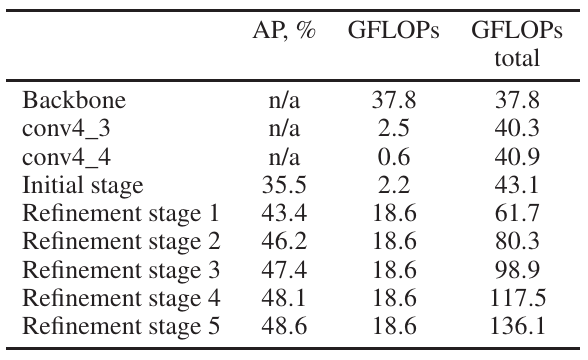
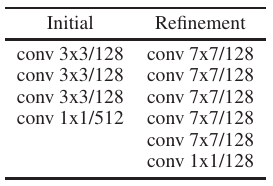
本文基于OpenPose的人体姿态估计算法,以bottom-top作为pipeline,使用已有的特征提取网络进行剪枝和蒸馏。我们已知OpenPose的backbone(特征提取)部分是以VGG-19为主体,在initial-stage分为两个分支,一个输出对人体稀疏关键点的预测的heatmaps,另一个输出将关键点按照相关置信度连接的PAFs,最后经过5个refinement-stage(优化阶段)。但是以现在的眼光来看:该网络的backbone所使用的VGG-19并没有在运算量和精度方面有太大的优势,可以替换为GoogleNet或MobileNet等其他轻量化网络;initial-stage两个分支的前三层网络是完全相同的,可以合成一个分支;而5层refinement-stage虽将AP(平均准确率)提升了5个点,但运算量达到优化前的221%,并且从第1层refinement-stage之后,便再无较大的准确率的提升,所以可以选择只是用第一层refinement-stage;同时对于refinement-stage来说,它的结构中一个两个 \(3 \times 3\) 卷积的感受野大小与 \(7 \times 7\) 卷积的感受野相同,故可以使用 \(1 \times 1,\; 3 \times 3,\; 3 \times 3\) 的三个卷积级联,代替一个 \(7 \times 7\) 卷积,同时为了减少深度增加带来的梯度消失,使用残差结构将 \(1 \times 1\) 卷积层与最后一层 \(3 \times 3\) 卷积层连接。最后可以在该层之前的步骤中弥补5个点精度的损失。
2.3 可行性分析
卷积神经网络CNN主要用于识别具有位移、缩放等形式畸变不变性的二维图形。由于CNN的特征检测层从训练数据中学习,因此避免了显式特征提取,而隐式地从训练数据中学习;此外,由于同一特征映射面上的神经元权值相同,网络可以并行学习,这也是卷积网络相对于神经元相互连接网络的一个主要优势。卷积神经网络以其独特的局部权值共享结构,在语音识别和图像处理方面具有独特的优势。它的布局更接近实际的生物神经网络。权重共享降低了网络的复杂度,尤其是多维输入向量的图像可以直接输入到网络中,避免了特征提取和分类过程中数据重构的复杂性。
现有的非深度学习分类方法几乎都是基于统计特征的,这意味着在进行识别之前必须提取一些特征。然而,在某些应用问题中,显式特征提取并不容易,也不总是可靠的。卷积神经网络避免了显式特征采样,并隐式地从训练数据中学习。这使得卷积神经网络明显不同于其他基于神经网络的分类器。通过结构重组和减重,将特征提取功能集成到多层感知器中。它可以直接处理灰度图像,也可以直接用于处理基于图像的分类。
卷积神经网络较一般神经网络在图像处理方面有如下优点:
1. 输入图像和网络的拓扑结构能很好的吻合;
2. 特征提取和模式分类同时进行,并同时在训练中产生;
3. 权重共享可以减少网络的训练参数,使神经网络结构变得更简单,适应性更强。
深度学习算法已广泛应用于目标和行人检测领域。2012年,Hinton的学生Krizhevsky使用卷积神经网络将国际大型视觉识别比赛(ILSVRC)分类任务的Top-5 err从传统方法的26.2%降至15.3%。在这次赛事中,谷歌的谢尔盖·伊夫(Sergey Ioffe)和其他人在2015年使用了深度学习算法,将Top-5 err减少到4.8%,首次超过了人类的识别能力(5.1%),这足以说明深度学习算法的强大力量。
在2013年的IEEE计算机视觉和模式识别国际会议(CVPR)上,中大欧阳万里提出联合深度学习模式,将卷积神经网络、遮挡模型和可变形组件模型DPM集成到一个用于联合学习的网络中,取得了良好的效果;Pierre Sermanet基于卷积稀疏编码提出的无监督深度学习ConvNet-U,它表明,只要稍加修改,卷积网络,当用于人体姿态估计领域时,它可以达到与当时最先进的人工设计特征算法相同的性能。
此外,在系统方案的实施中,以往的成功也提供了更大的便利。加州大学伯克利分校的贾洋清在其博士学位论文中使用C++编写了深度学习框架Caffe,使学术界和业界不必为底层算法的编写而挣扎,这为深度学习的训练和测试提供了极大的便利。同时,学术研究的积累也提供了许多网络预培训的成果,可以在其基础上直接优化网络,节省大量计算资源和时间,为本次毕业设计的顺利实施提供了良好的条件。因此,综上所述,本次毕业设计的可行性是好的。
2.4 技术难点
2.4.1 梯度消失/梯度爆炸
特征提取网络替换为MobileNet v1进行模型训练,当测试精度达到74%时,无论增加多少组迭代,都无法使精度在提高一个点。通过查阅发现,ResNet在训练时出现了类似问题,其原因是由于MobileNet v1虽然减少了参数量,但是网络深度却增加了,而深度增加的网络不一定会使精度增加,可能出现的其他状况就是梯度消失或梯度爆炸,而ResNet使用残差结构这一理念可以解决该问题。
3. 实施方案与技术路线
3.1 功能/模块设计方案
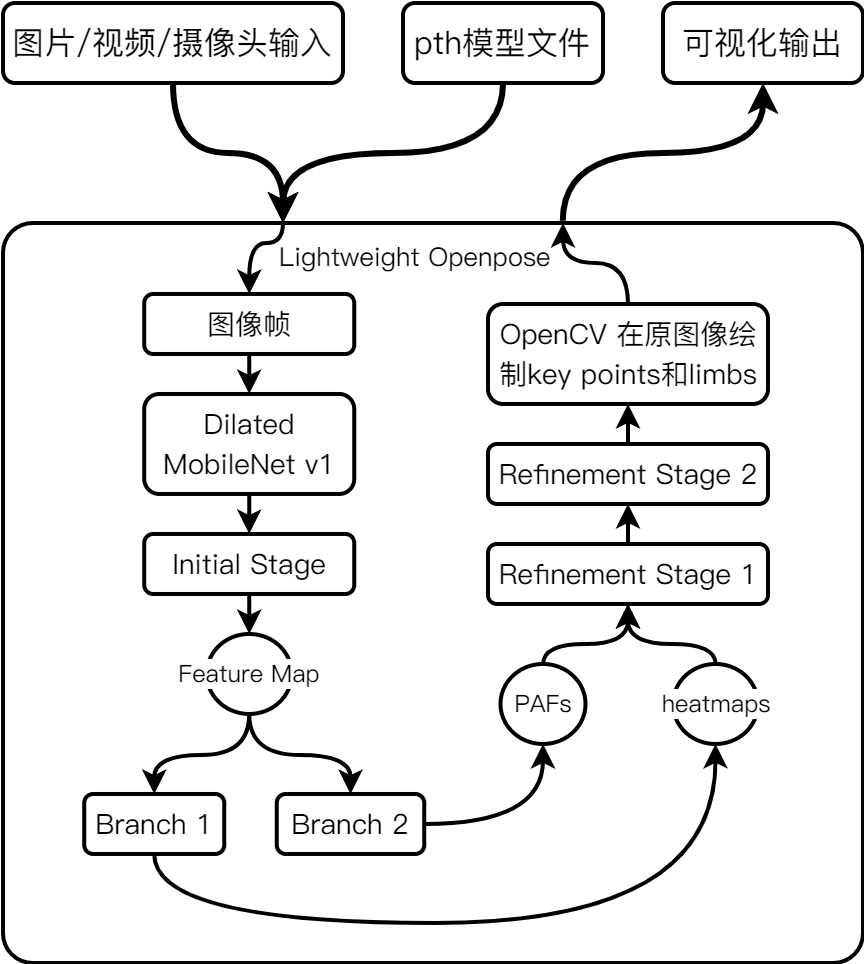
如上图所示,从功能上来看,本系统只有包含检测算法部分,由待检测图像和训练好权重的模型文件作为输入,经过与模型文件相匹配的网络得到一张标记处人体稀疏关键点和肢体的输出图像。
目录结构:
.
│ demo.py # demo
│ requirements.txt # 所需第三方库 pip install -r requirments.txt
│ run-cam-demo.ps1 # demo执行脚本
│ train.py # 训练
│ val.py # train.py训练中验证
│
├───datasets # 数据集
│ coco.py # train.py加载COCO数据集实现类
│ transformations.py # train.py对COCO数据集transform操作实现类
│ __init__.py # 生成文件
│
│
├───models # 训练模型输出目录
│ checkpoint_iter_370000.pth # pytorch模型文件
│ model_mobilenet.py # MobileNet v1实现,继承自torch.nn.Module
│ model_vgg19.py # 原OpenPose网络结构vgg-19实现,继承自torch.nn.Module
│ __init__.py # 生成文件
│
└───scripts # 常用脚本
convert_to_onnx.py # 转换为onnx开放式模型标准脚本
make_val_subset.py # 生成训练验证集
prepare_train_labels.py # 生成训练标签
3.2 具体技术路线与实现方法
对于本文在章节2.2中提出的几个网络轻量化方案,笔者本着理解网络每层所能得到的数据的理念,分别按照几位前辈学者论文给出的网络结构直接进行了一一映射的实现,在细节的优化方面还存在些许问题。
3.2.1 OpenPose的实现
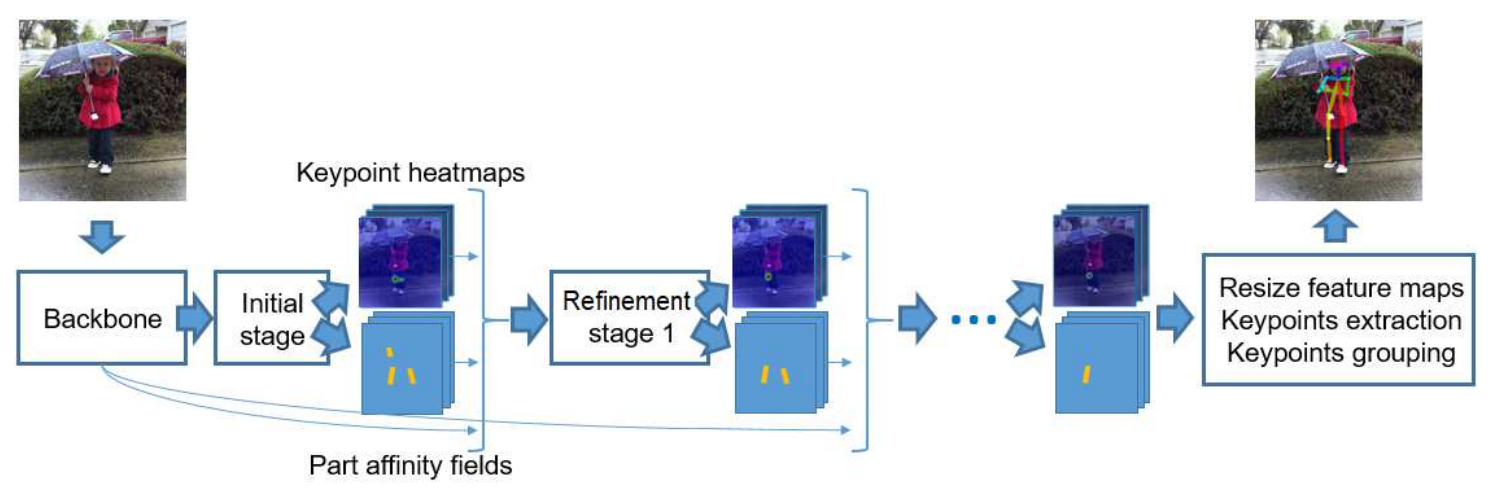
OpenPose的人体姿态估计算法,以bottom-top作为pipeline,使用已有的特征提取网络进行剪枝和蒸馏。我们已知OpenPose的backbone(特征提取)部分是以VGG-19为主体,在initial-stage分为两个分支,一个输出对人体稀疏关键点的预测的heatmaps,另一个输出将关键点按照相关置信度连接的PAFs,最后经过5个refinement-stage(优化阶段)。
在本文中,对于OpenPose在Python下的实现直接参考了OpenPose原作者给出的网络结构,使用PyTorch实现,而非编译CMU官方github给出的C++源码得到Python API,因此网络在实际的表现中会与OpenPose作者给出的数据有所偏差。网络输出张量的形状如图5。

3.2.2 MobileNet v1的实现
图6来自Lightweight OpenPose的paper,Type / Stride栏给出了卷积层的类型和卷积步长,dw是指深度可分离卷积,也叫逐通道卷积,由图7可以看出深度可分离卷积不改变输入图像的通道数量,s1 / s2给出了卷积步长的大小:stride=1 / stride=2;Filter Shape给出了卷积核的形状:高 \(\times\) 宽 \(\times\) 输入通道数 \(\times\) 输出通道数;Input Size给出了上一层输出也是该层输入的形状:图像高 \(\times\) 图像宽 \(\times\) 通道数量。
# 深度可分离卷积对比标准卷积 IPython
In [1]: import torch
In [2]: # 定义shape(batch_size=1, channels=3, height=12, width=12)的随机张量
In [3]: tensor = torch.randn((1, 3, 12, 12))
In [5]: tensor.shape
Out[5]: torch.Size([1, 3, 12, 12])
In [6]: # 定义普通二维卷积
In [7]: conv = torch.nn.Conv2d(in_channels=3, out_channels=256, kernel_size=5, stride=1, padding=0)
In [8]: # 定义深度卷积
In [11]: conv_dw = torch.nn.Conv2d(in_channels=3, out_channels=3, kernel_size=5, stride=1, padding=0)
In [12]: # 定义逐点卷积
In [13]: conv_pw = torch.nn.Conv2d(in_channels=3, out_channels=256, kernel_size=1, stride=1, padding=0)
In [14]: # 定义深度可分离卷积序列
In [15]: conv_dp = torch.nn.Sequential(conv_dw, conv_pw)
In [16]:
In [16]: tensor.shape
Out[16]: torch.Size([1, 3, 12, 12])
In [17]: tensor_conv = conv(tensor)
In [18]: tensor_conv_dp = conv_dp(tensor)
In [19]: tensor_conv.shape, tensor_conv_dp.shape
Out[19]: (torch.Size([1, 256, 8, 8]), torch.Size([1, 256, 8, 8]))
In [20]: # 证明两种卷积方式得到相同结果
In [21]: tensor_conv.shape == tensor_conv_dp.shape
Out[21]: True
In [22]: # 定义计算标准卷积1000次用时函数
In [23]: def timer_conv(tensor):
...: import time
...: start_time = time.time()
...: for i in range(1000):
...: tensor_conv = conv(tensor)
...: print(time.time() - start_time)
...:
In [24]: # 定义计算深度可分离卷积1000次用时函数
In [25]: def timer_conv_dp(tensor):
...: import time
...: start_time = time.time()
...: for i in range(1000):
...: tensor = conv_dp(tensor)
...: print(time.time() - start_time)
...:
In [26]: conv_time = timer_conv(tensor)
0.19627785682678223
In [27]: conv_dp_time = timer_conv_dp(tensor)
0.19127202033996582
In [28]: ratio = 0.19627785682678223/0.19127202033996582
In [29]: ratio
Out[29]: 1.0261712950902022
| Type / Stride | Filter Shape | Input Size |
|---|---|---|
| Conv / s2 | 3×3×3×32 | 224×224×3 |
| Conv dw / s1 | 3×3×32 dw | 112×112×32 |
| Conv / s1 | 1×1×32×64 | 112×112×32 |
| Conv dw / s2 | 3×3×64 dw | 112×112×64 |
| Conv / s1 | 1×1×64×128 | 56×56×64 |
| Conv dw / s1 | 3×3×128 dw | 56×56×128 |
| Conv / s1 | 1×1×128×128 | 56×56×128 |
| Conv dw / s2 | 3×3×128 dw | 56×56×128 |
| Conv / s1 | 1×1×128×256 | 28×28×128 |
| Conv dw / s1 | 3×3×256 dw | 28×28×256 |
| Conv / s1 | 1×1×256×256 | 28×28×256 |
| Conv dw / s2 | 3×3×256 dw | 28×28×256 |
| Conv / s1 | 1×1×256×512 | 14×14×256 |
| 5× Conv dw / s1 | 3×3×512 dw | 14×14×512 |
| Conv / s1 | 1×1×512×512 | 14×14×512 |
| Conv dw / s2 | 3×3×512 dw | 14×14×512 |
| Conv / s1 | 1×1×512×1024 | 7×7×512 |
| Conv dw / s2 | 3×3×1024 dw | 7×7×1024 |
| Conv / s1 | 1×1×1024×1024 | 7×7×1024 |
| Avg Pool / s1 | Pool 7×7 | 7×7×1024 |
| FC / s1 | 1024×1000 | 1×1×1024 |
| Softmax / s1 | Classifier | 1×1×1000 |
3.2.3 带有残差结构的空洞卷积的实现
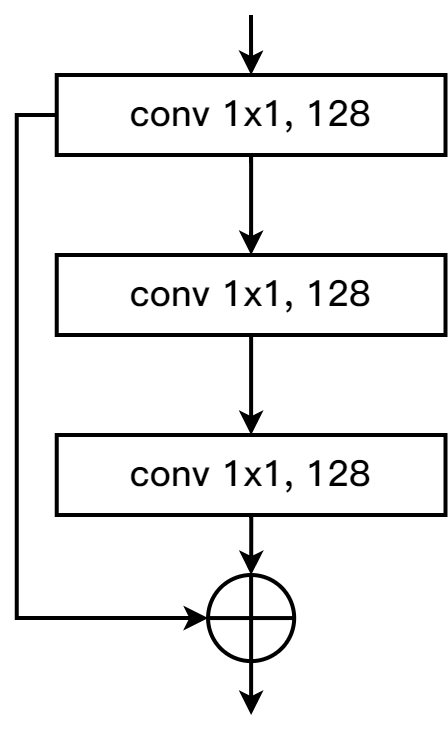
将原来的 \(7 \times 7\) 的卷积替换成的 \(1 \times 1,\; 3 \times 3,\; 3 \times 3\) 卷积级联。为了让这个级联结构与 \(7 \times 7\) 的卷积核有同样的感受野,在最后一个 \(3 \times 3\) 的卷积中,使用dilation=2的空洞卷积。这样造成的一个问题就是网络的深度和广度虽然增加,但可能会出现梯度消失或梯度爆炸的问题(实际实验中已经出现),为了解决这一问题,还在每一组卷积( \(1 \times 1,\; 3 \times 3,\; 3 \times 3\) )使用了residual connection结构,如图6所示。
3.2.4 Part Affinity Fields 原理
这是曹哲团队提出的一个新的概念,可以译为关节亲和向量场。就是对肢体进行标注(肢体分割),目的是通过肢体找关键点直接的连接。
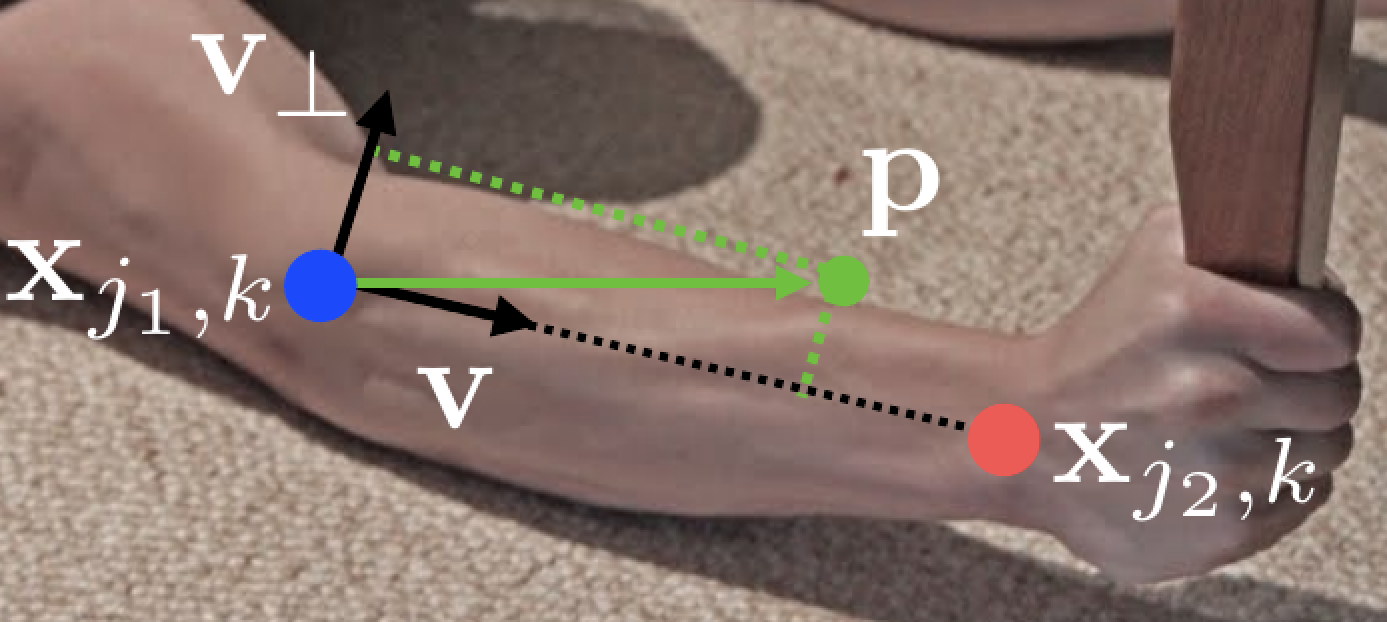
\(x_{j1,k}\) 和 \(x_{j2,k}\) 表示第 \(k\) 个体的肢体 \(c\) 的部位 \(j1\) 和 \(j2\) 的肢体坐标(该坐标已经通过计算的另一个分支得到关节置信图确定)。如果一个点 \(p\) 落在肢体上,则 \(L^{\star}_{c,k} \left( p \right)\) 的值是一个从 \(j1\) 指向 \(j2\) 的单位向量;对于其它点,向量的值为0。
训练的时候,PAF在 \(p\) 的Ground Truth值为:
\[\mathbf{L}^{\star}_{c,k} \left( \mathbf{p} \right) = \begin{cases} \mathbf{v} \quad \text{ if } \mathbf{p} \text{ on limb } c,k \\ \mathbf{0} \quad \text{ otherwise } \end{cases} \]其中, \(v = \left ( x_{j2,k} - x_{j1,k} \right ) / \left \| x_{j2,k} - x_{j1,k} \right\|_{2}\) 是肢体的单位向量。
点 \(p\) 的范围如下:
\[0 \le \mathbf{v} \; \cdot \; \left ( \mathbf{p} - \mathbf{x}_{j1,k} \right ) \le l_{c,k} \quad \text{and} \quad \left | \mathbf{v_{\bot}} \; \cdot \; \left ( \mathbf{p} - \mathbf{x}_{j1,k} \right ) \right | \le \sigma_{l} \]\(\sigma_{l}\) 是肢体宽度, \(l_{c,k} = \left \| x_{j1,k} - x_{j2,k} \right \|_{2}\) 是肢体长度, \(v_{\bot}\) 正交于 \(v\) 。这样向量 \((p - x_{j1,k})\) 与 \(v\) 点乘得到的是 \(v\) 方向上该向量投影的长度,显然该长度要大于零小于肢体的长度。同理该向量在 \(v_{\bot}\) 方向的投影长度小于肢体的宽度。
3.2.5 二分图匹配算法
后期补充
3.2.6 Bottom-up 人体姿态估计流程
(从关键点到人)先使用一个model检测(locate)出图片中所有关键点,然后把这些关键点分组(group)到每一个人。
单人图像输入:
根据置信图确定关节位置,得到PAFs:
标记的图片:
得到置信图(heatmaps):
根据置信图确定关节位置,得到PAFs:
标记的图片:
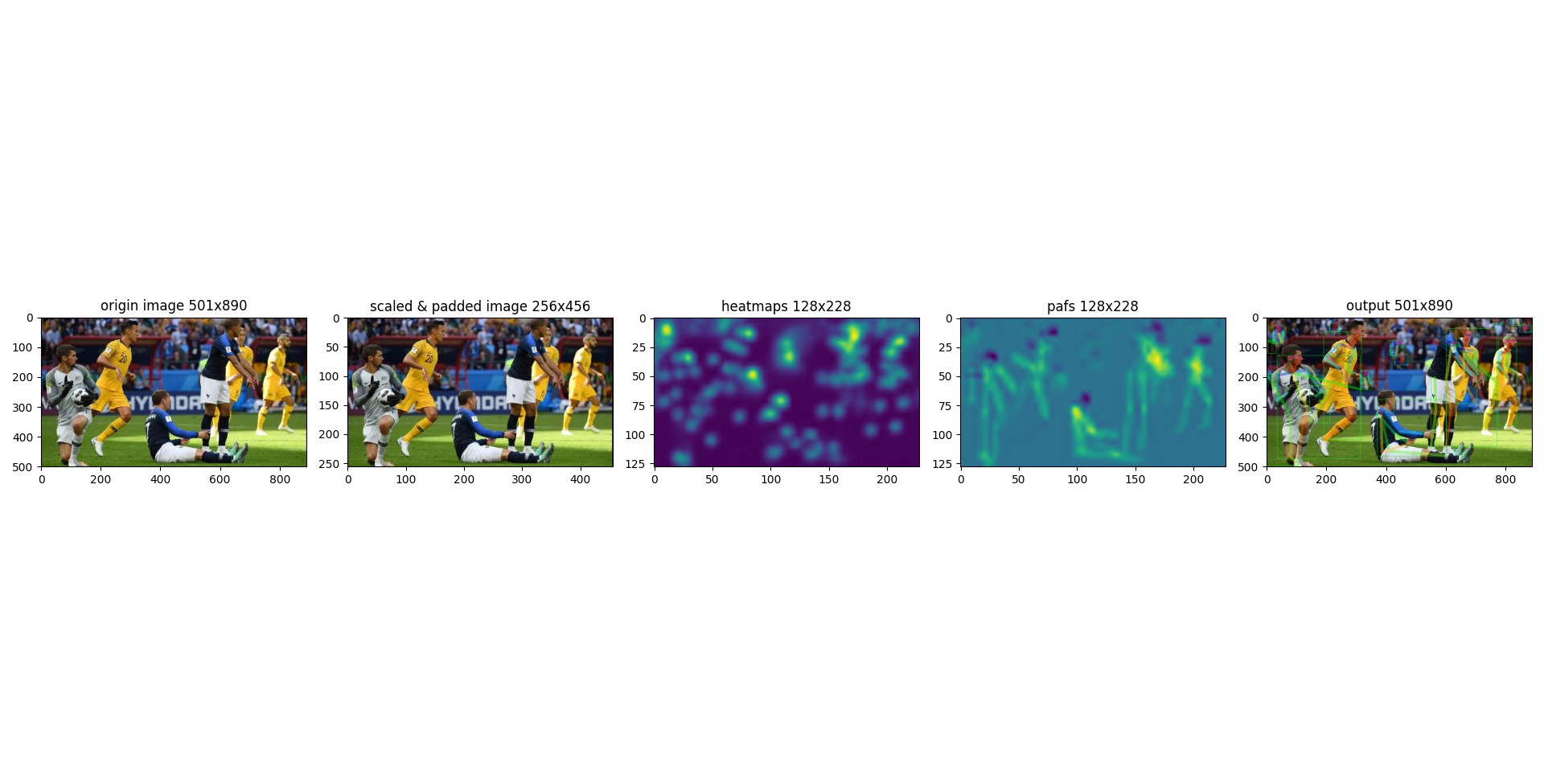
4.1 测试结果与分析
以下结果部分通过Python第三方库pthflops计算得出。关于运行时间与训练速度采用随机生成图片张量,传入网络进行假运算测试得出。
4.1.1 运行时间和所需存储空间
| 网络模型 | Process Time(s) | Process Rate(Images/s) |
|---|---|---|
| Openpose(VGG-19) | 36.4 | 2.75 |
| Openpose(MobileNet v1) | 4.2 | 23.94 |
| 网络模型 | Process Time(s) | Process Rate(Images/s) |
|---|---|---|
| Openpose(VGG-19) | 10.45 | 9.57 |
| Openpose(Dilated MobileNet v1) | 1.9 | 53.68 |
| 网络模型 | \(\#P(Million)\) | \(GFLOPs\) |
|---|---|---|
| Openpose(VGG-19) | 52.31 | 50.41 |
| Openpose(Dilated MobileNet v1) | 2.88 | 9.21 |
4.1.2 检测质量
| 执行步骤 | \(AP,\%\) | \(GFLOPs\) | \(GFLOPs\) 合计 |
|---|---|---|---|
| Dilated MobileNet v1 | n/a | 3.7 | 3.7 |
| conv4_3 | n/a | 0.3 | 4 |
| conv4_4 | n/a | 0.3 | 4.3 |
| Initial stage | 35 | 1.3 | 5.6 |
| Refinement stage 1 | 41.4 | 3.4 | 9 |
%
| 模型 | \(AP\) | \(AP^{50}\) | \(AP^{75}\) | \(AP^{M}\) | \(AP^{L}\) |
|---|---|---|---|---|---|
| OpenPose(VGG-19) | 48.6 | 71.3 | 64.2 | 42.8 | 56.5 |
| OpenPose(Dilated MobileNet v1) | 41.4 | 65.4 | 48.3 | 36.9 | 53.7 |
5. 成果与展示
在相同输入分辨率下,轻量化操作之后的网络模型运算帧数提高到了每秒30帧以上,而在CPU(i5-8300H)上的表现则贴近于原网络在GPU(GTX 1060 6G)下的运行速度。