Diffusion-LM improves controllable text generation 扩散语言模型改善可控文本生成(翻译)
论文作者:Xiang Lisa Li …… Stanford University
论文链接:https://arxiv.org/abs/2205.14217
论文代码:https://github.com/XiangLi1999/Diffusion-LM
摘要
目前的自然语言处理在控制简单的句子属性(如情感)方面取得了成功,但是在复杂的细粒度控制(如语法结构)方面进展甚微。介于目前扩散模型的大热,作者提出了一个基于连续扩散的非自回归(non-autoregressive)语言模型,称之为扩散语言模型(Diffusion-LM )。扩散语言模型迭代地将一系列高斯噪声转换为词向量形式的隐变量。这些隐变量的连续、分层性质使得基于梯度的简单算法能够执行复杂、可控的生成任务。文章展示了六个具有挑战性的细粒度控制任务。
1 引言

连续扩散模型在视觉和音频领域上非常成功,但是由于文本的固有离散性质,它们还尚未应用于文本。将这类模型调整为适用文本的需要:我们向标准扩散过程中添加了一个嵌入步骤和舍入步骤,同时设计了一个学习嵌入的训练目标并提出了改进舍入的技术。我们使用基于梯度的方法控制Diffusion-LM,如Figure 1所示。此方法使我们能够将文本生成的过程转向满足目标结构和语义控制的输出。迭代地对Diffusion-LM的连续隐变量进行梯度更新,以平衡流畅度和控制满意度。
为了演示Diffusion LM的控制,我们考虑了从细粒度属性(例如,语义内容)到复杂结构(例如,解析树)的六个控制目标。我们的方法几乎是以前即插即用方法的成功率的两倍,并且在所有这些分类器引导的控制任务上匹配或优于微调预言机,我们证明,我们可以成功地组合多个分类器引导的控件,以生成具有所需语义内容和句法结构的句子。最后,我们考虑跨度锚定控件,如长度控制和填充。扩散LM允许我们在没有分类器的情况下执行这些控制任务,并且我们的扩散LM显著优于先前的即插即用方法,并且与针对填充任务从头训练的自回归LM相当。
2 相关工作
Diffusion Models for Text.扩散模型在连续数据域中取得了巨大成功,产生了具有最先进样本质量的图像和音频。为了处理离散数据,过去的工作研究了离散状态空间上的文本扩散模型,该模型定义了离散数据上的破坏过程(例如,每个令牌都有一定概率被破坏为吸收或随机令牌)。在本文中,我们专注于文本的连续扩散模型,据我们所知,我们的工作是第一次探索这种设置。与离散扩散LMs相比,我们的连续扩散LMs诱导了连续的潜在表示,这使得基于梯度的有效方法能够用于可控生成。
Autoregressive and Non-autoregressive LMs.大多数大型预训练LMs是从左到右自回归的(例如,GPT-3,PaLM)。固定的生成顺序限制了模型在许多可控制的生成设置中的灵活性,特别是那些在左右上下文中全局施加控制的设置。一个例子是填充,它对正确的上下文施加词汇控制;另一个例子是句法结构控制,它控制涉及左右上下文的全局属性。由于自回归LMs不能直接在正确的环境下进行调节,先前的工作已经为这些任务开发了专门的训练和解码技术。扩散LM可以以任意分类器为条件,这些分类器着眼于句子的复杂全局属性。还有其他非自回归LMs已被开发用于机器翻译和语音到文本任务。然而,这些方法专门用于语音和翻译设置,其中有效输出的熵很低,并且已经表明,这些方法无法用于语言建模。
Plug-and-Play Controllable Generation. 即插即用可控生成旨在保持LM冻结,并使用潜在功能(例如分类器)控制其输出。给定一个测量生成的文本满足期望控制程度的概率潜在函数,生成的文本应针对控制满意度(由潜在函数测量)和流畅度(由LM概率测量)进行优化。有几种基于自回归LM的即插即用方法:FUDGE[44]用部分序列的控制满意度估计值重新加权每个标记的LM预测;GeDi[22]和DExperts[24]使用针对控制任务微调/训练的较小LM重新加权每个令牌的LM预测。
最接近我们的工作是PPLM[6],它在自回归LM的隐藏激活上运行梯度上升,以控制下一个令牌以满足控制并保持流畅性。因为PPLM基于自回归LMs,所以它只能从左到右生成。这将防止PPLM修复和恢复上一代步骤中发生的错误。尽管它们在属性(例如,主题)控制方面取得了成功,但我们将在§7.1中展示这些自回归LMs的即插即用方法在更复杂的控制任务上失败,例如控制句法结构和语义内容。我们证明,通过将分类器引导的梯度更新应用于扩散LM诱导的潜在变量的连续序列,扩散LM能够进行即插即用的可控生成。
3 问题陈述和背景
我们首先定义了可控生成(§3.1),然后回顾了连续扩散模型(§3.3)。
3.1 生成模型和文本的可控生成
文本生成是从经过训练的语言模型\(p_{lm}(w)\)中采样\(w\)的任务,其中\(w=[w_1··w_n]\)是离散单词序列,\(p_{lm}(w)\)是单词序列上的概率分布。可控文本生成是从条件分布\(p(w|c)\)中采样w的任务,其中\(c\)表示控制变量。对于语法控制,\(c\)可以是目标语法树(图1),而对于情感控制,\(c\)可能是期望的情感标签。可控生成的目标是生成满足控制目标\(c\)的\(w\)。
考虑即插即用可控生成设置:我们得到了一个从大量未标记文本数据中训练的语言模型\(p_{lm}(w)\),对于每个控制任务,我们得到了从少量标记文本数据训练的分类器\(p(c|w)\)(例如,对于句法控制,分类器是一个概率解析器)。目标是利用这两个模型通过贝叶斯规则\(p(w|c)\propto{p_{lm}(w)·p(c|w)}\)从后验\(p(w|c)\)近似采样。这里,\(p_{lm}(w)\)鼓励\(w\)流畅,而\(p(c|w)\)则鼓励\(w\)符合控制目标。
3.2 自回归语言模型
自回归的标准方法中语言建模因子\(p_{lm}\)为从左到右,\(p_{\operatorname{lm}}(\mathbf{w})=p_{\operatorname{lm}}\left(w_{1}\right) \prod_{i=2}^{n} p_{\operatorname{lm}}\left(x_{i} \mid x_{<i}\right)\)。在这种情况下,文本生成被简化为根据目前生成的部分序列重复预测下一个令牌的任务。下一个令牌预测\(p_{lm}(x_i | x_{<i})\)通常由Transformer体系结构参数化。
3.3 连续域的扩散模型
扩散模型是将数据\(x_0\in\mathbb R^d\)建模为马尔可夫链\(x_T...x_0\)。\(x_T\)为高斯分布。扩散模型对隐变量序列\(x_{T:1}\)去噪到服从目标数据分布的样本(图2)。初始状态\(p_\theta(\textbf{x}_T)≈\mathcal N(0,\textbf I)\),且每个去噪过程\(x_T→ x_{t−1}\)都被参数化为模型\(p_θ(\textbf x_{t-1}|\textbf x_t)=\mathcal N(\textbf x_{t-1};µ_θ(\textbf x_t,t),\Sigma_θ(\textbf x_t,t))\)。 例如,\(µ_θ\)和\(\Sigma_θ\)可以通过U-Net或transformer计算。

为了训练扩散模型,我们定义了一个构造中间隐变量\(\textbf x_{1:T}\)的正向过程。该正向过程会逐步将高斯噪声添加到数据\(\textbf x_0\)中,直到扩散步骤\(T\),样本$ \textbf x_T\(近似为高斯分布。每个加躁过程\)\textbf x_{t-1}→\textbf x_t\(通过\)q(\textbf x_t|\textbf x_{t-1})=\mathcal N(\textbf x_t;\sqrt{1-β_t}\textbf x_{t-1},β_t\textbf I)\(进行参数化,其中超参数\)β_t\(是在步骤\)t\(中添加的噪声量。正向过程\)q\(的参数化包含不可训练的参数,并允许我们定义一个训练目标,该目标包含根据预定义的前向过程\)q$来生成噪声数据,并训练模型来建模逆向过程以重建数据。
训练扩散模型以最大化数据的对数似然\(\mathbb E_{\textbf x_0〜p_{data}}[log~p_θ(\textbf x_0)]\),并且规范目标是\(log~p_θ(\textbf x_0)\)的变分下界,
\[\mathcal L_{vlb}(\textbf x_0)=\mathop{\mathbb E}\limits_{q(\textbf x_{1:T}|\textbf x_0)}\bigg[log\frac{q(\textbf x_T|\textbf x_0)}{p_{\theta}(\textbf x_T)}+\sum^T_{t=2}log\frac{q(\textbf x_{t-1}|\textbf x_0,\textbf x_t)}{p_{\theta}(\textbf x_{t-1}|\textbf x_t)}-log~p_{\theta}(\textbf x_0|\textbf x_1)\bigg].\tag{1} \]但是,这个目标可能是不稳定的,需要许多优化技巧才能稳定。为了解决这个问题,Ho et al.设计了一个简单可替代的目标,该目标扩展并重加权\(\mathcal L_{vlb}\)中的每个KL散度项,最终得到均方误差损失(附录E中给出了推导),如下所示:
\[\mathcal L_{simple}(\textbf x_0)=\sum^T_{t=1}\mathop{\mathbb E}\limits_{q(\textbf x_t|\textbf x_0)}||\mu_{\theta}(\textbf x_t,t)-\hat{\mu}(\textbf x_t,\textbf x_0)||^2 \]其中\(\hat{\mu}(\textbf x_t,\textbf x_0)\)是后验\(q(\textbf x_{t-1}|\textbf x_0,\textbf x_t)\)的均值,其接近高斯分布,\(\mu_{\theta}(\textbf x_t,t)\)是由神经网络通过计算\(p_{\theta}(\textbf x_{t-1}|\textbf x_t)\)得到的均值。尽管\(\mathcal L_{simple}\)不再是变分下界,经验上发现,这能使先验网络更易训练且提高采样质量。我们在扩散LM中将使用类似的简化目标来稳定训练并提高采样质量(4.1节)。
4 扩散LM:连续扩散语言模型
构建Diffusion-LM需要对标准的扩散模型进行一些修改。首先,我们必须定义一个嵌入函数,将离散的文本映射到一个连续的空间。为了解决这个问题,我们提出了一个用于学习嵌入的端到端训练目标(§4.1)。第二,我们需要一个四舍五入的方法来将嵌入空间中的向量映射回单词。为了解决这个问题,我们提出了训练和解码时间的方法来促进四舍五入(§4.2)。
4.1 端到端训练
为了将连续扩散模型应用于离散文本,我们定义了一个嵌入函数\(EMB(w_i)\),它将每个词映射到\(\mathbb R^d\)中的一个向量。我们将长度为n的序列\(w\)的嵌入定义为:\(EMB(w) = [EMB(w_1), ... , EMB(w_n)] ∈\mathbb R^{nd}\)。
我们提出了对扩散模型训练目标的修改(式1),联合学习扩散模型的参数和词嵌入。在预备知识实验中,我们探索了随机高斯嵌入,以及预训练的词嵌入。我们发现,与端到端训练相比,这些固定嵌入对Diffusion-LM来说是次优的。
根据图2显示,我们的方法增加了一个马尔科夫转移从离散的单词\(w\)到\(x_0\)的前向过程,参数符合\(q_{\phi}(\textbf x_0|\textbf w)=\mathcal N(EMB(\textbf w),σ_0\textbf I)\)。在反向过程中,我们添加了一个可训练的近似步骤,参数化为\(p_θ(\textbf w|\textbf x_0)=\prod^n_{i=1}p_θ(w_i|x_i)\),其中\(p_θ(w_i|x_i)\)是一个softmax分布。第3节中引入的训练目标现在变为:
\[\begin{array}{cc}\mathcal L^{e2e}(\textbf w)=\mathop{\mathbb E}\limits_{q_{\phi}(\textbf x_0|\textbf w)}[\mathcal L_{vlb}(\textbf x_0)+log~q_{\phi}(\textbf x_0|\textbf w)-log~p_{\theta}(\textbf w|\textbf x_0)],\\ \mathcal L^{e2e}_{simple}(\textbf w)=\mathop{\mathbb E}\limits_{q_{\phi}(\textbf x_{0:T}|\textbf w)}[\mathcal L_{simple}(\textbf x_0)+||EMB(\textbf w)-\mu_{\theta}(\textbf x_1,1)||^2-log~p_{\theta}(\textbf w|\textbf x_0)]. \end{array}\tag{2} \]我们采用类似3.3节中的简化方法,从\(\mathcal L^{e2e}_{vlb}(\textbf w)\)得出\(\mathcal L^{e2e}_{simple}(\textbf w)\),我们的推导细节在附录E中。由于我们需要训练嵌入函数,因此\(q_{\phi}\)现在包含了可训练的参数,我们使用重参数化技巧来反向传播。从经验上讲,我们发现了有意义的嵌入类簇:具有相同词性标签(句法角色)的单词倾向于聚集在一起,如图3所示。

4.2 减少舍入误差
学习的嵌入方式定义了从离散文本到连续\(\textbf x_0\)的映射。现在,我们描述了将预测的\(\textbf x_0\)返回到离散文本的逆过程。基于\(argmax~p_θ(\textbf w |\textbf x_0)=\prod^n_{i=1}p_θ(w_i|x_i)\),可以通过在每个位置选择最可能的单词来实现近似。理想情况下,这个argmax近似足够将\(\textbf x_0\)映射回离散文本,因为去躁步骤应确保\(\textbf x_0\)完全保存某些单词的嵌入。但是,从经验上讲,该模型无法生成能够照顾每一个单词的\(\textbf x_0\)。
此现象的一种解释是,我们等式2中的\(\mathcal L_{simple}(\textbf x_0)\)项不足以对\(\textbf x_0\)的结构进行建模。回想一下,我们定义了\(\mathcal L_{simple}(\textbf x_0)=\sum^T_{t=1}\mathbb E_{\textbf x_t}||µ_θ(\textbf x_t,t)-\hat{\mu}(\textbf x_t,\textbf x_0)||^2\),其中我们的模型\(µ_θ(\textbf x_t,t)\)直接在每个去躁步骤\(t\)来预测\(p_θ(\textbf x_{t -1}|\textbf x_t)\)的均值。在这个目标中,\(\textbf x_0\)必须关注每个单词嵌入的约束只会出现在\(t\)接近0的项中,我们发现此参数化需要细粒度的调整以迫使目标来关注这些项(请参阅附录H)。
我们的方法将\(\mathcal L_{simple}\)重新构造以迫使扩散LM在目标的每个项中显式建模\(\textbf x_0\)。具体而言,我们得到了通过\(\textbf x_0\)参数化的和\(\mathcal L_{simple}\)类似的变种,\(\mathcal L^{e2e}_{\textbf x_0-simple}(\textbf x_0)=\sum^T_{t=1}\mathbb E_{\textbf x_t}||f_{\theta}(\textbf x_t,t)-\textbf x_0||^2\),其中我们的模型\(f_{\theta}(\textbf x_t,t)\)直接预测\(\textbf x_0\)。 这迫使神经网络在每个项内都能预测\(\textbf x_0\),我们发现使用该目标训练的模型很快就会学到\(\textbf x_0\)关注单词嵌入。
我们描述了重参数化有助于模型训练,但我们还发现,在我们称为clamping技巧的技术中,同样可以在解码时使用。在\(\textbf x_0\)参数化模型的标准生成方法中,模型首先通过\(f_{\theta}(\textbf x_t,t)\)计算\(\textbf x_0\)的估计值以将\(\textbf x_t\)转到\(\textbf x_{t-1}\),其中\(\bar{\alpha}_t=\prod^t_{s=0}(1-\beta_s)\)且\(\epsilon\sim\mathcal N(0,I)\),然后在此估计中采样\(\textbf x_{t-1}:\textbf x_{t-1}=\sqrt{\bar \alpha}f_{\theta}(\textbf x_t,t)+\sqrt{1-\alpha}\epsilon\)。 在clamping技巧中,该模型还将预测的向量\(f_θ(\textbf x_t,t)\)映射到其最接近的单词嵌入序列。现在,采样步骤就变为\(\textbf x_{t-1}=\sqrt{\bar{\alpha}}·Clamp(f_θ(\textbf x_t,t))+\sqrt{1-\bar{\alpha}}\epsilon\)。clamping技巧迫使在中间扩散步骤预测的向量就能关注到单词,从而使矢量预测更加精确并减少近似错误。
5 基于扩散LM的解码与可控生成
第4节我们描述了扩散LM,现在我们将考虑可控文本生成(5.1节)和解码(5.2节)的问题。
5.1 可控文本生成
现在,我们描述了一个可以在扩散LM上进行可插拔控制的过程。我们的控制方法受3.1节中的贝叶斯公式的启发,但我们没有直接对离散文本执行控制,而是对在扩散LM上定义的连续潜在变量\(\textbf x_{0:T}\)的序列进行控制,并应用近似步骤将这些潜在变量转到文本。
控制\(\textbf x_{0:T}\)等于从后验\(p(\textbf x_{0:T}|\textbf c)=\prod^T_{t=1}p(\textbf x_{t-1}|\textbf x_t,\textbf c)\)进行解码,我们将此联合推理问题分解为在每个扩散步骤进行控制的问题:\(p(\textbf x_{t-1}|\textbf x_t,\textbf c)∝p(\textbf x_{t-1}|\textbf x_t)·p(\textbf c|\textbf x_{t-1},\textbf x_t)\)。我们通过条件独立性假设来进一步简化\(p(\textbf c|\textbf x_{t-1},\textbf x_t)=p(\textbf c|\textbf x_{t -1})\)。因此,对于第\(t\)步,我们在\(\textbf x_{t-1}\)上运行梯度更新:
其中,\(log~p(\textbf x_{t-1}|\textbf x_t)\)和\(log~p(\textbf c|\textbf x_{t-1})\)是可微分的,其中第一项由扩散LM参数化,第二项由一个神经网络分类器参数化。
与图像中的工作类似,我们在基于扩散潜在变量训练一个分类器,并在潜在空间\(\textbf x_{t-1}\)上运行梯度更新,以控制其满足目标。这些工作在每个扩散步骤中按\(\nabla_{x_{t-1}}~log~p(\textbf c|\textbf x_{t-1})\)进行梯度更新。为了提高文本的性能并加快解码的速度,我们引入了两个关键的修改:流畅度正则化和多梯度步骤。
为了生成流畅的文本,我们使用流畅性正则化目标来进行梯度更新:\(λlog~p(\textbf x_{t-1}|\textbf x_t)+log~p(\textbf c|\textbf x_{t-1})\),其中\(λ\)是一个超参数,可在在流畅度(第一项)和控制度(第二项)之间进行平衡。虽然现有的可控生成方法目标中不包括\(λlog~p(\textbf x_{t-1}|\textbf x_t)\)项,但我们发现该项对生成流畅的文本具有重要作用。所得的可控生成过程可以看作是一种平衡最大化和采样\(p(\textbf x_{t-1}|\textbf x_t,\textbf x)\)随机解码方法,这与nucleus sampling或low temperature采样文本生成技术一样。为了提高控制质量,我们在每个扩散步骤采取了多个梯度更新步骤:我们为每个扩散步骤运行3次Adagrad更新。为了减轻计算成本的增加,我们将扩散步骤从2000降到200,从而加快了我们可控生成算法而不会损害样本质量。
5.2 最小贝叶斯风险解码
许多条件文本生成任务需要单个高质量的输出序列,例如机器翻译或句子填充。在这些设置中,我们应用最小贝叶斯风险(MBR)解码[23]来聚合从扩散LM提取的一组样本\(\mathcal S\),并选择在损失函数\(\mathcal L\)(例如,负BLEU分数)下实现最小预期风险的样本:\(\hat w= argmin_{w∈S} ∑_{w'∈S} \frac{1}{|S|}\mathcal L(w, w')\)。我们发现MBR解码通常返回高质量的输出,因为低质量的样本将与剩余样本不同,并受到损失函数的惩罚。
6 实验设置
通过上述对训练(第4节)和解码(第5节)的改进,我们为两个语言模型任务训练Diffusion-LM。然后,我们将可控生成方法应用于5个分类器引导的控制任务,并将MBR解码应用于一个无分类器的控制任务(即填充)。
6.1 数据集和超参数
我们在两个数据集上训练Diffusion-LM。E2E[28]和ROCStories[26]。E2E数据集由5万条Restaurant评论组成,这些评论由8个字段标注,包括食物类型、价格和顾客评价。ROCStories数据集由9.8万个五句话的故事组成,捕捉了日常事件之间丰富的因果和时间常识关系。这个数据集比E2E更具挑战性,因为这些故事包含更大的11K单词表和更多样化的语义内容。
我们的扩散-LM是基于Transformer[42]架构,有80M的参数,序列长度n=64,扩散步骤T=2000和平方根噪声计划(详见附录A)。我们将嵌入维度作为一个超参数,为E2E设置d=16,为ROCStories设置d=128。关于超参数的细节见附录B。在解码时,我们将E2E的扩散步数降至200步,ROCStories则保持2000步。200步的扩散-LM解码仍然比自回归LM的解码慢7倍。对于可控生成,我们基于扩散-LM的方法比FUDGE慢1.5倍,但比PPLM快60倍。
6.2 控制任务
我们考虑了表1中所示的6个控制任务:前4个任务依赖于分类器,后2个任务是无分类器的。对于每个控制任务(例如语义内容),我们从验证分片中抽取200个控制目标c(例如,评级=5星),我们为每个控制目标生成50个样本。为了评估生成文本的流畅性,我们遵循先前的工作[44, 6],将生成的文本送入教师LM(即仔细微调的GPT-2模型),并报告教师LM下生成文本的困惑度。我们称这个指标为lm-score(表示为lm):lm-score越低表示样本质量越好。我们对每个控制任务的成功度量定义如下。

语义内容。给定一个字段(如评级)和价值(如五星),生成一个涵盖字段=价值的句子,并通过 "价值 "的精确匹配报告成功率。
词性部分。给出一串词性部分(POS)标签(例如,代词动词定语名词),生成一串相同长度的词,其POS标签(在一个神谕POS标签器下)与目标(例如,我吃了一个苹果)相匹配。我们通过词级精确匹配来量化成功。
句法树。给定一个目标句法解析树(见图1),生成其句法解析与给定解析相匹配的文本。为了评估成功与否,我们用一个现成的解析器[20]解析生成的文本,并报告F1 Score。
句法跨度。给定一个目标(跨度,句法类别)对,生成在跨度[i, j]上的解析树与目标句法类别(如介词短语)相匹配的文本。我们通过完全匹配的跨度的百分比来量化成功。
长度。给出一个目标长度10, ... . 40,产生一个长度在目标值±2以内的序列。在Diffusion-LM的情况下,我们将其作为一个无分类器的控制任务。
填充。从aNLG数据集[2]中给出一个左边的上下文(O1)和一个右边的上下文(O2),而目标是生成一个逻辑上连接O1和O2的句子。对于评估,我们报告了来自Genie排行榜[17]的自动和人工评估。
6.3 分类器引导的控制基线
对于前5个控制任务,我们将我们的方法与PPLM、FUDGE和一个微调oracle进行了比较。PPLM和FUDGE都是基于自回归LM的即插即用的可控生成方法,我们使用GPT-2小型架构[33]从头开始训练。
PPLM[6]。这种方法在LM激活上运行梯度上升,以增加分类器概率和语言模型概率,并在简单的属性控制上获得了成功。我们应用PPLM来控制语义内容,但没有应用其余4个需要位置信息的任务,因为PPLM的分类器缺乏位置信息。
FUDGE[44]。对于每个控制任务,FUDGE需要一个未来判别器,该判别器接收一个前缀序列并预测完整的序列是否满足约束条件。在解码时,FUDGE通过判别器的分数对LM的预测进行重新加权。
FT。对于每个控制任务,我们在(控制,文本)对上对GPT-2进行微调,产生一个不是即插即用的神谕条件语言模型。我们报告了微调模型的采样(温度为1.0)和beam search(beam大小为4)输出,分别表示为FT-sample和FT-search。
6.4 填充基线
我们与过去工作中为填充任务开发的3种专门的基线方法进行比较。
DELOREAN[30]。这个方法连续地放松了从左到右的自回归LM的输出空间,并迭代地对连续空间进行梯度更新,以执行与右边上下文的流畅连接。这就产生了一个连续的矢量,它被四舍五入为文本。
COLD[31]。COLD指定了一个基于能量的模型,包括流畅性(从左到右和从右到左的LM)和连贯性约束(从词汇重叠)。它从这个基于能量的模型中提取连续向量,并将其四舍五入为文本。
AR-infilling。我们从头开始训练一个自回归LM来完成句子填充任务[9]。与训练Diffusion-LM类似,我们在ROCStories数据集上进行训练,但是通过将句子从(O1,Omid,O2)重新排序到(O1,O2,Omid)进行预处理。在评估时,我们输入O1和O2,模型就会生成中间的句子。
7 主要结果
我们在E2E和ROCStories数据集上训练Diffusion-LMs。就负样本对数似然(NLL,越低越好)而言,我们发现Diffusion-LM NLL的变分上界低于等效的自回归Transformer模型(E2E为2.28对1.77,ROC Stories为3.88对3.05),尽管扩大模型和数据集的规模部分地弥补了差距(ROCStories为3.88→-3.10)。我们的最佳对数可能性需要从第4节中进行一些修改;我们在附录F中解释这些修改并给出详细的对数可能性结果。尽管可能性较差,但基于我们的扩散-LM的可控生成的结果明显优于基于自回归LM的系统,正如我们将在§7.1,§7.2和§7.3中显示的那样
7.1 分类器指导下的可控文本生成结果
如表2所示,Diffusion-LM在所有分类器引导的控制任务中都取得了很高的成功率和流畅性。它在所有5个任务中都明显优于PPLM和FUDGE基线。令人惊讶的是,我们的方法在控制句法解析树和跨度方面优于微调oracal,而在其余3项任务中取得了类似的性能。
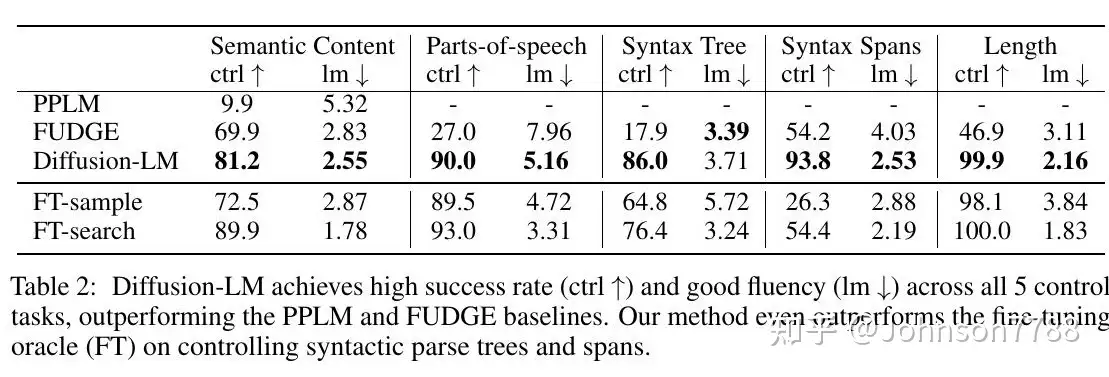
表2: Diffusion-LM在所有5个控制任务中都取得了较高的成功率(ctrl ↑)和良好的流畅性(lm ↓),优于PPLM和FUDGE基线。我们的方法在控制句法解析树和跨度方面甚至超过了微调神谕(FT)。
控制句法解析树和跨度是微调的挑战性任务,因为对解析树的调节需要对解析树的嵌套结构进行推理,而对跨度的调节则需要前瞻规划以确保正确的成分出现在目标位置。
我们观察到PPLM在语义内容控制方面的失败,并推测这是因为PPLM是为控制粗粒度的属性而设计的,对于更有针对性的任务可能没有用处,例如强制要求Restaurant评论中包含对星巴克的引用。
FUDGE在语义内容控制方面表现良好,但在其余四项任务中表现不佳。对FUDGE来说,控制结构化输出(Parts-of-speech和Syntax Tree)是很难的,因为在前缀的任何地方犯一个错误都会使判别器给所有的延续分配低概率。在其他需要规划的控制任务中(长度和句法跨度),未来判别器很难训练,因为它必须隐含地执行前瞻规划。
我们的Diffusion-LM的非自回归性质使它能够轻松解决所有需要精确未来规划的任务(句法跨度和长度)。我们认为,它对涉及全局结构的复杂控制(语篇、语法树)效果很好,因为从粗到细的表示方法允许分类器对整个序列(接近t = T )以及单个token(接近t = 0)施加控制。
定性结果。表3显示了句法树控制的样本。我们的方法和微调都提供了大部分满足控制的流畅的句子,而FUDGE在前几个词之后就偏离了约束。我们的方法和微调的一个关键区别是,Diffusion-LM能够纠正失败的跨度,让后缀跨度与目标相匹配。在第一个例子中,生成的跨度("家庭友好的印度食品")是错误的,因为它比目标多包含一个词。幸运的是,这个错误并没有传播到后面的跨度,因为Diffusion-LM通过放弃连词进行调整。类似地,在第二个例子中,FT模型产生了一个失败的跨度("磨坊"),其中包含的词少了一个。然而,FT模型未能在后缀中进行调整,导致后缀中出现许多错位的错误。

表3: 句法树控件的定性例子。句法解析树由代表成分的嵌套括号线性化,我们使用标准的PTB句法类别。每个跨度内的token都用*表示。我们将失败的跨度染成红色,并将我们在§7.1中讨论的感兴趣的跨度加粗。
7.2 控制措施的构成
即插即用可控生成的一个独特能力是其模块化。给定多个独立任务的分类器,梯度引导的控制使得从多个控制的交叉点上通过对分类器对数概率之和取梯度来生成变得简单。
我们对语义内容+句法树控制和语义内容+语篇控制的组合进行评估。如表4所示,我们的Diffusion-LM对这两个部分都取得了很高的成功率,而FUDGE则放弃了更全面的句法控制。这是意料之中的事,因为FUDGE自己不能控制句法。
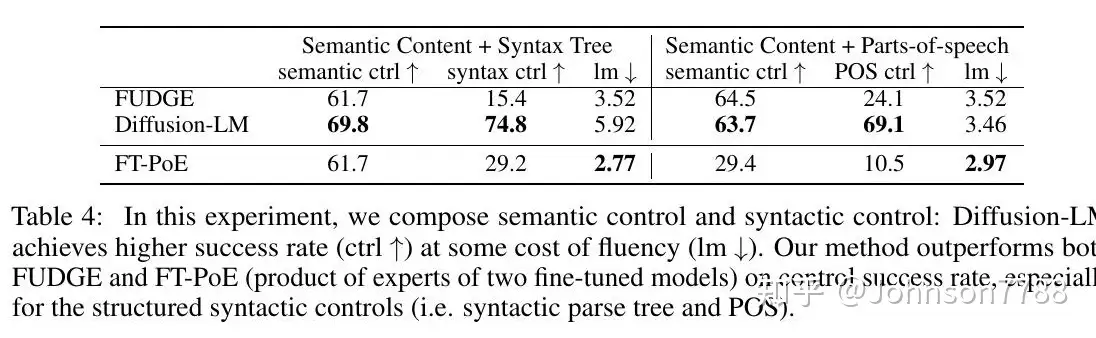
表4: 在这个实验中,我们把语义控制和句法控制结合起来。扩散-LM在以流畅性(lm ↓)为代价的情况下实现了更高的成功率(ctrl ↑)。我们的方法在控制成功率上优于FUDGE和FT-PoE(两个微调模型的专家产品),特别是对于结构化的句法控制(即句法解析树和POS)。
微调模型在单独的POS和语义内容控制方面表现良好,但在专家产品(PoE)方面却不能很好地组成这两种控制,导致两种约束的成功率大幅下降。
7.3 填充结果
如表5所示,我们的扩散LM明显优于基于连续松弛的填充方法(COLD和DELOREAN)。此外,我们的方法取得了与为该任务微调专门模型相当的性能。我们的方法的自动评估得分略高,而人类评估发现这两种方法在统计学上都没有明显的改进。这些结果表明,Diffusion LM可以解决许多类型的可控生成任务,这些任务依赖于生成顺序或词汇约束(如填充),而无需专门的训练。

表5: 在句子填充方面,Diffusion-LM明显优于先前的工作COLD[31]和Delorean[30](数字取自论文),并且与从头开始训练的自回归LM(AR)的性能相匹配,可以做填充。
7.4 消融研究
我们通过两个消融研究来验证我们在第4节中提出的设计选择的重要性。我们用500个样本的lm-score来衡量Diffusion-LM的样本质量§6.2。
学习型嵌入与随机型嵌入(§4.1)。在ROC Stories中,学习嵌入的表现优于随机嵌入,这是一个更难的语言模型任务。同样的趋势也适用于E2E数据集,但幅度较小。
目标参数化(§4.2)。我们建议让扩散模型直接预测x0。在这里,我们将其与图像生成中的标准参数化进行比较,后者通过噪声项ε进行参数化。图4(右)显示,通过x0进行参数化在各个维度上都能获得良好的性能,而通过ε进行参数化在小维度上效果良好,但在大维度上很快就崩溃了。
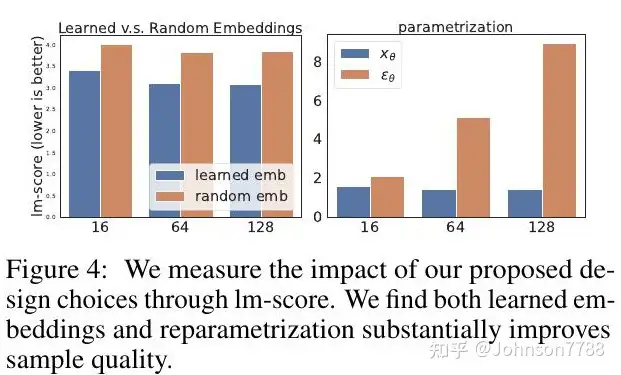
图4:我们通过lm-score来衡量我们提出的设计选择的影响。我们发现学习到的嵌入和重构都大大改善了样本质量。
8 结论和局限性
我们提出了Diffusion-LM,一种基于连续扩散的新型可控语言模型,它可以实现新形式的复杂细粒度控制任务。我们证明了Diffusion-LM在6个细粒度控制任务中的成功:我们的方法几乎是先前方法控制成功率的两倍,与需要额外训练的基线微调方法相比具有竞争力。
我们发现Diffusion-LM实现的复杂控制很有说服力,而且扩散-LM是对目前离散自回归生成范式的实质性背离,这让我们感到兴奋。与任何新技术一样,我们构建的Diffusion-LMs也有缺点:(1)它的困惑度更高;(2)解码速度大大降低;(3)训练收敛更慢。我们相信,通过更多的后续工作和优化,这些问题中的许多都可以得到解决,这种方法将变成一种引人注目的大规模可控生成的方式。
标签:Diffusion,controllable,控制,generation,LM,textbf,扩散,生成,我们 From: https://www.cnblogs.com/zhouyeqin/p/17063356.html