diffusion model原理
https://segmentfault.com/a/1190000043744225#item-4
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
变分自编码器:
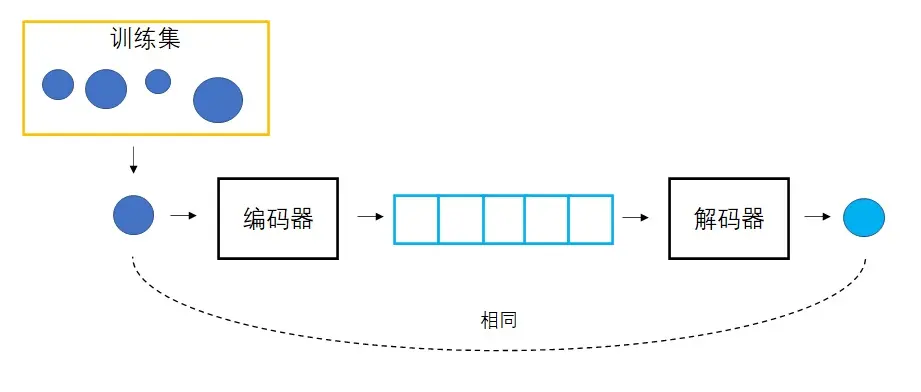
把某图像变成向量,再用该向量生成图像。
扩散模型是一种特殊的VAE,其灵感来自于热力学:一个分布可以通过不断地添加噪声变成另一个分布。放到图像生成任务里,就是来自训练集的图像可以通过不断添加噪声变成符合标准正态分布的图像。从这个角度出发,我们可以对VAE做以下修改:1)不再训练一个可学习的编码器,而是把编码过程固定成不断添加噪声的过程;2)不再把图像压缩成更短的向量,而是自始至终都对一个等大的图像做操作。
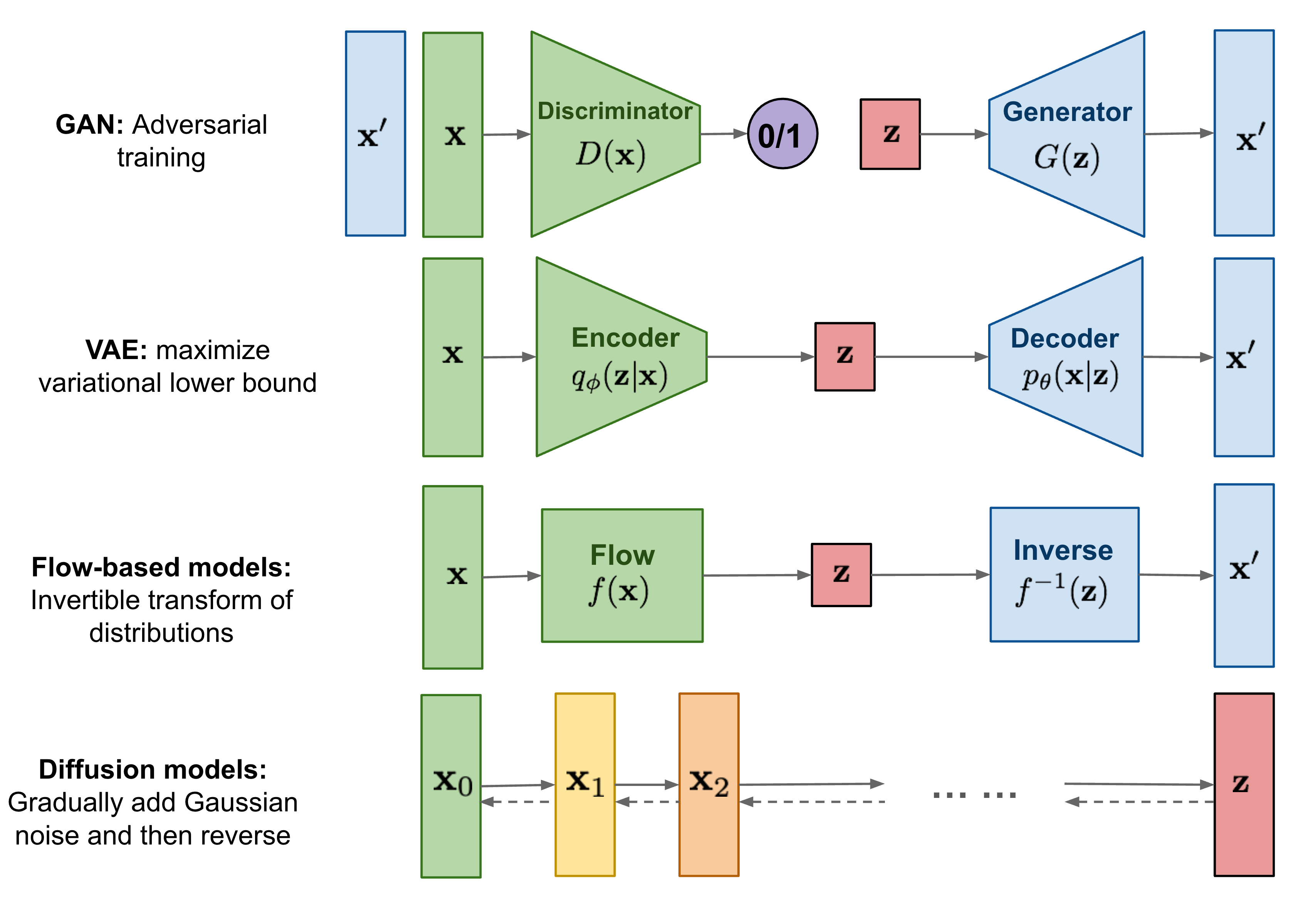
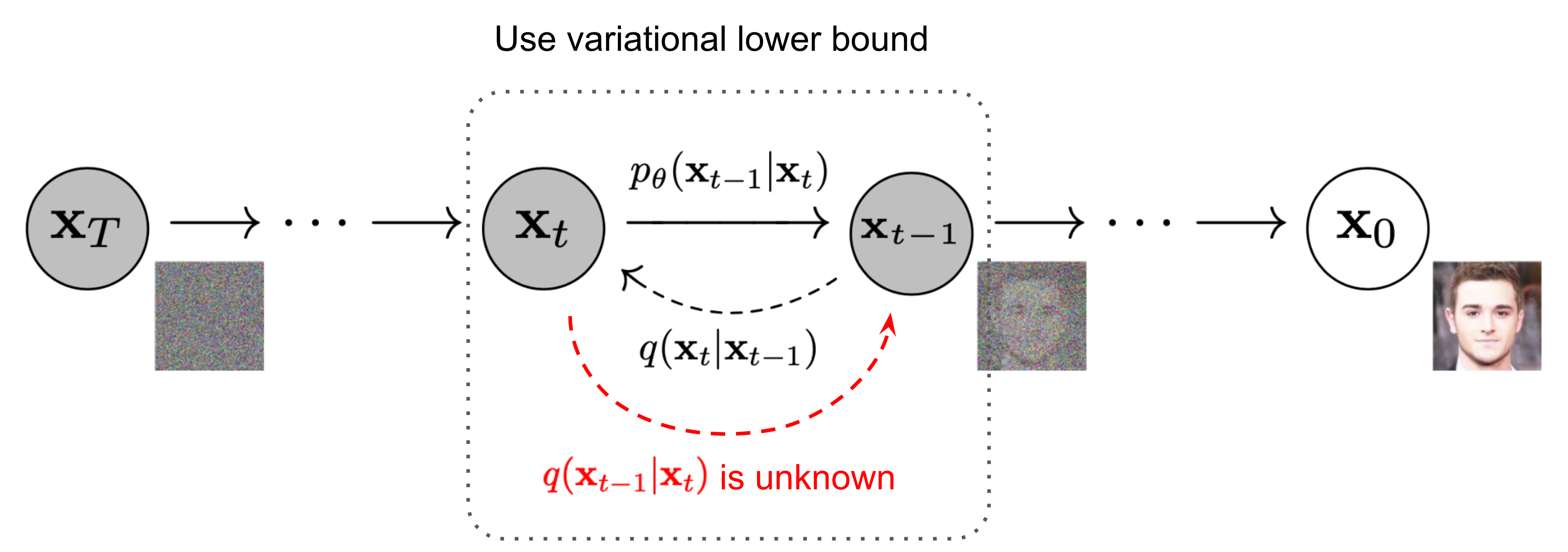
具体来说,扩散模型由正向过程和反向过程这两部分组成,对应VAE中的编码和解码。在正向过程中,输入$\mathbf{x}_0$会不断混入高斯噪声。经过$T$次加噪声操作后,图像$\mathbf{x}_T$会变成一幅符合标准正态分布的纯噪声图像。而在反向过程中,我们希望训练出一个神经网络,该网络能够学会$T$个去噪声操作,把$\mathbf{x}_T$还原回$\mathbf{x}_0$。网络的学习目标是让$T$个去噪声操作正好能抵消掉对应的加噪声操作。训练完毕后,只需要从标准正态分布里随机采样出一个噪声,再利用反向过程里的神经网络把该噪声恢复成一幅图像,就能够生成一幅图片了。
stable diffusion
https://cloud.tencent.com/developer/article/2393003
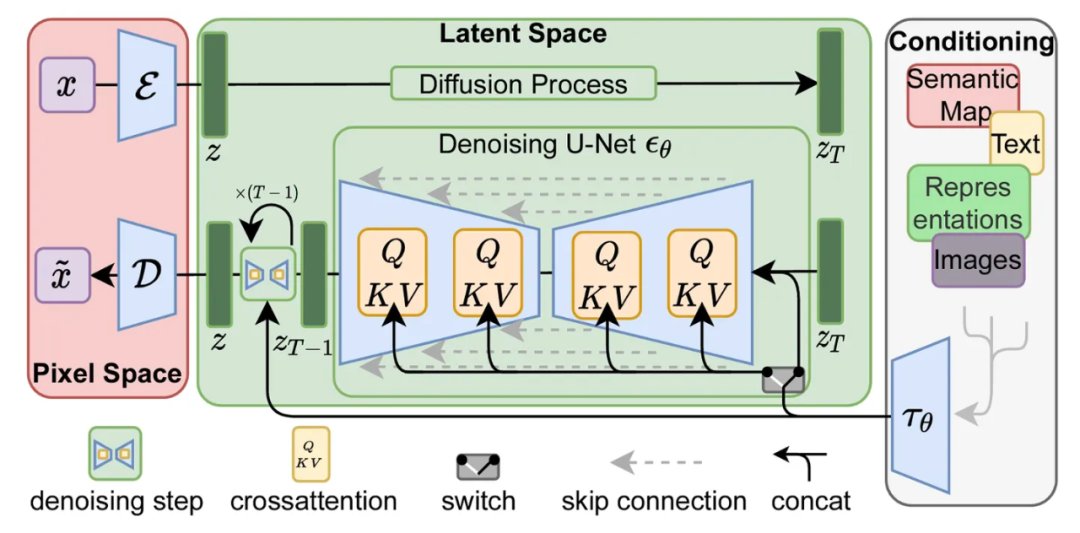
相比于扩散模型,多了condition组件,也就相当于贝叶斯中的条件概率,通过条件控制生成的方向。
本文diffusion Policy详解
https://blog.csdn.net/SherylBerg/article/details/139148787
https://zhuanlan.zhihu.com/p/670555655
背景知识
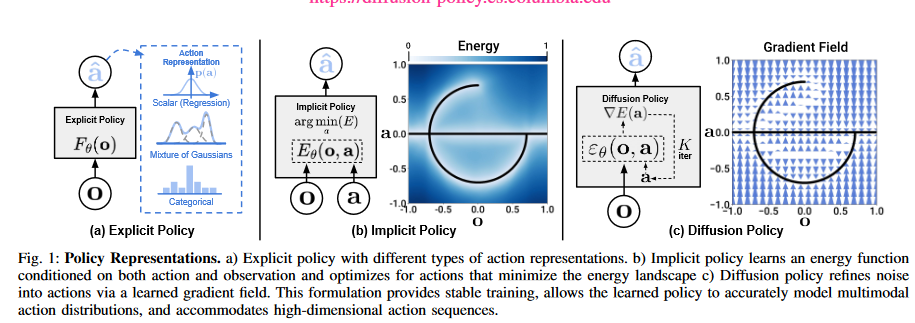
a)显式策略:行为克隆,将观察o映射到动作a,图中有3种动作表示方法:
1. 标量:将动作表示为实数,连续动作空间
2. 混合高斯:离散动作空间
3. 分类:离散动作空间
b)隐式策略:基于能量的模型 Energy-based models(EBM)。每个动作被分配一个能量值,动作预测对应于寻找最小能量动作的优化问题。
能量函数参考文献:
-
https://blog.csdn.net/qq_51221943/article/details/121108242
文章中提到的能量函数实际上也就是损失函数,是施加噪声和预测噪声的mse。基于能量的模型看起来更像是一个概念,求极大似然看起来就是求最小能量函数。
什么是Diffusion Policy
解决的是机器人输出的问题,输入端使用非常普通的东西,聚焦于机器人的动作端

sd模型输出图片,Diffusion Policy输出机器人动作
机器人Multi-Modal分布问题
和深度学习的多模态不一样,机器人的多模态讲的是解决某一特定任务的方式是多样的,而不是唯一的。但神经网络预测只能给出单一方式。
关于什么是机器人Multi-Moda问题,迟宬给了非常清晰的解释:假设我现在在开车,前面有一棵树。比如说,我雇佣了100个司机来解决这个问题。在这种情况下,有可能有50个司机选择往左拐,绕过树的左边,还有50个司机选择从树的右边绕过去。在这种情况下,往左绕和往右绕都是完全合理的。然而,当我们将所有这些解决方案合并为一个时,问题就变成了一个多模态分布,即我看到的相同场景有两种不同的选择。这对传统神经网络的预测来说并不友好,因为它通常使用均方误差(MSE)损失进行训练,而这无法有效处理Multi-Modal情况。
这和传统机器人控制需要对机器人动作严格控制的思路相违背,每次只执行一项任务,整个机器人系统都被认为是受到严格控制的。这也是为什么大多数人没有把机器人动作生成表现为一个概率分布的原因。
Action Space Scalability的问题
关于Action Space Scalabiltiy或者sequential correlation问题,我简单理解就是机器人对未来动作的预测不应该只局限于眼前的一步两步动作,而应该更有前瞻性,可以往前预测数十步动作。
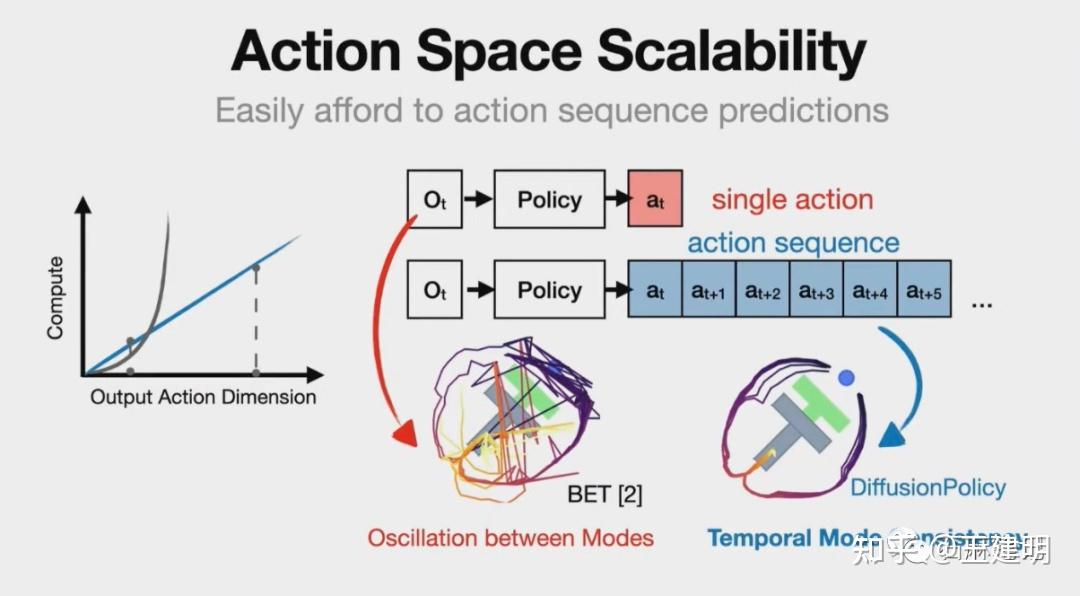
使用分类网络单步预测,随着动作维度增加,计算成本呈指数级增长。
我们再回到了之前提到的问题。假设我们在驾驶车辆,我们可以在下一步稍微往左偏一点,再下一步再进一步左偏。实际上,我们所绘制的行车轨迹有两种可行的选择。一种是持续向左开,从左侧绕过去,一直保持这种路径。另一种是持续向右开,从右侧绕过去。在预测这个动作时,我们可以逐步进行预测,即在每个时刻,预测下一步应该怎么走。然而,采用这种方式可能会导致问题,例如,如果我稍微向左偏了一点,我可能会左右摇摆;如果我稍微向右偏了一点,也有可能左右摇摆。这个问题被称为动作不一致(Action Inconsistent),即当我希望向左行驶时,神经网络的预测中仍然存在一定概率是向右的情况,这时候就会发现决策非常犹豫,时而向左,时而向右,这是一个问题。
Training Stability问题
Diffusion Policy和其他使用生成式模型的策略比,他的最大特点是训练过程非常稳定。
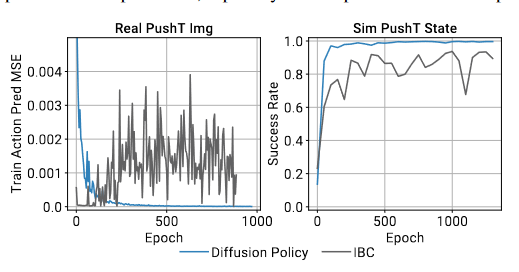
Diffusion方法的强大之处在于,它的性能不逊色于GAN,但其训练过程非常稳定。基本上,你可以随便调整参数,生成器就能够输出结果,可能效果不是最优的,但基本上都能work。
代码复现
在论文中,我们使用了模仿学习,即由人类遥控机器人执行动作,收集数据,并通过学习将其转化为策略。这种学习过程通过遥控机器人完成一系列动作开始,然后将其迁移到机器人身上。输入数据包括过去几帧的图像,而输出涉及对未来动作的预测。
命令行
python train.py --config-dir=. --config-name=image_pusht_diffusion_policy_cnn.yaml training.seed=42 training.device=cuda:0 hydra.run.dir='data/outputs/${now:%Y.%m.%d}/${now:%H.%M.%S}_${name}_${task_name}'
训练
条件控制怎么加的
if self.obs_as_global_cond: # true
# reshape B, T, ... to B*T
this_nobs = dict_apply(nobs,
lambda x: x[:,:self.n_obs_steps,...].reshape(-1,*x.shape[2:]))
nobs_features = self.obs_encoder(this_nobs)
# reshape back to B, Do
global_cond = nobs_features.reshape(batch_size, -1)
这里面nobs就是输入图像,经过一个encoder以后reshape,传入model
diffusion_policy/policy/diffusion_unet_hybrid_image_policy.py,compute_loss函数。
这里pred_type == 'epsilon',所以模型输出的是noise。
# Predict the noise residual
pred = self.model(noisy_trajectory, timesteps,
local_cond=local_cond, global_cond=global_cond)
pred_type = self.noise_scheduler.config.prediction_type
if pred_type == 'epsilon':
target = noise
elif pred_type == 'sample':
target = trajectory
else:
raise ValueError(f"Unsupported prediction type {pred_type}")
loss = F.mse_loss(pred, target, reduction='none')
loss = loss * loss_mask.type(loss.dtype)
loss = reduce(loss, 'b ... -> b (...)', 'mean')
loss = loss.mean()
return loss
推理
diffusion_policy/policy/diffusion_unet_hybrid_image_policy.py,predict_action函数调用conditional_sample函数。
预测出的是噪声model_output,然后通过DDPMScheduler根据噪声推理出前一幅图像(action、轨迹、坐标)。
这个数据集是pushT image,任务是把一个T型零件推到纸上画的线里

所以数据集中的action或者trajectory是二维的,代表xy坐标。
# set step values
scheduler.set_timesteps(self.num_inference_steps)
for t in scheduler.timesteps:
# 1. apply conditioning
trajectory[condition_mask] = condition_data[condition_mask]
# 2. predict model output
model_output = model(trajectory, t,
local_cond=local_cond, global_cond=global_cond)
# 3. compute previous image: x_t -> x_t-1
trajectory = scheduler.step(
model_output, t, trajectory,
generator=generator,
**kwargs
).prev_sample
# finally make sure conditioning is enforced
trajectory[condition_mask] = condition_data[condition_mask]
return trajectory
DDPMScheduler模块需要讲一下。代码解释可以看:
https://blog.csdn.net/Lizhi_Tech/article/details/133928749
结果
wandb: Run summary:
wandb: epoch 3049
wandb: global_step 512399
wandb: lr 0.0
wandb: test/mean_score 0.85039
wandb: test/sim_max_reward_100000 1.0
wandb: test/sim_max_reward_100001 0.68677
wandb: test/sim_max_reward_100002 1.0
wandb: test/sim_max_reward_100003 0.88879
wandb: test/sim_max_reward_100004 1.0
wandb: test/sim_max_reward_100005 0.97553
wandb: test/sim_max_reward_100006 0.66709
wandb: test/sim_max_reward_100007 0.9642
wandb: test/sim_max_reward_100008 1.0
wandb: test/sim_max_reward_100009 0.90598
wandb: test/sim_max_reward_100010 0.98676
wandb: test/sim_max_reward_100011 1.0
wandb: test/sim_max_reward_100012 0.99331
wandb: test/sim_max_reward_100013 0.12877
wandb: test/sim_max_reward_100014 1.0
wandb: test/sim_max_reward_100015 0.68957
wandb: test/sim_max_reward_100016 1.0
wandb: test/sim_max_reward_100017 1.0
wandb: test/sim_max_reward_100018 1.0
wandb: test/sim_max_reward_100019 0.67922
wandb: test/sim_max_reward_100020 1.0
wandb: test/sim_max_reward_100021 0.60691
wandb: test/sim_max_reward_100022 0.72734
wandb: test/sim_max_reward_100023 0.0
wandb: test/sim_max_reward_100024 0.0
wandb: test/sim_max_reward_100025 1.0
wandb: test/sim_max_reward_100026 1.0
wandb: test/sim_max_reward_100027 1.0
wandb: test/sim_max_reward_100028 1.0
wandb: test/sim_max_reward_100029 0.99959
wandb: test/sim_max_reward_100030 0.60766
wandb: test/sim_max_reward_100031 0.8071
wandb: test/sim_max_reward_100032 1.0
wandb: test/sim_max_reward_100033 1.0
wandb: test/sim_max_reward_100034 1.0
wandb: test/sim_max_reward_100035 1.0
wandb: test/sim_max_reward_100036 1.0
wandb: test/sim_max_reward_100037 1.0
wandb: test/sim_max_reward_100038 0.99934
wandb: test/sim_max_reward_100039 1.0
wandb: test/sim_max_reward_100040 0.72388
wandb: test/sim_max_reward_100041 0.03105
wandb: test/sim_max_reward_100042 0.99354
wandb: test/sim_max_reward_100043 0.46994
wandb: test/sim_max_reward_100044 1.0
wandb: test/sim_max_reward_100045 1.0
wandb: test/sim_max_reward_100046 1.0
wandb: test/sim_max_reward_100047 1.0
wandb: test/sim_max_reward_100048 1.0
wandb: test/sim_max_reward_100049 0.98717
wandb: train/mean_score 0.7752
wandb: train/sim_max_reward_0 0.71402
wandb: train/sim_max_reward_1 1.0
wandb: train/sim_max_reward_2 0.60603
wandb: train/sim_max_reward_3 0.72395
wandb: train/sim_max_reward_4 1.0
wandb: train/sim_max_reward_5 0.60723
wandb: train_action_mse_error 0.46457
wandb: train_loss 0.00025
wandb: val_loss 0.23961
wandb:
wandb: Synced 2023.01.16-20.20.06_train_diffusion_unet_hybrid_pusht_image: https://wandb.ai/zhaowenyi7-zjlab/diffusion_policy_debug/runs/y8onqtcx
wandb: Synced 6 W&B file(s), 366 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./data/outputs/2024.11.07/14.06.17_train_diffusion_unet_hybrid_pusht_image/wandb/run-20241107_140631-y8onqtcx/logs