Prometheus 告警事件中的 $value 表示当前告警触发时的值,但是在告警恢复时,Resolved 事件中的 $value 仍然是最新告警时的值,并非是恢复时的值,这是什么原因和原理?是否有办法来解决呢?
不废话,先说原理。
原理
告警规则是配置在 prometheus.yaml 中的,由 Prometheus 负责做规则判定。Prometheus 规则判定的逻辑也很简单,就是周期性的,拿着 promql 去查询数据,如果查到了数据,并且连续多次满足 for 指定的时长,就触发告警事件,如果查不到数据,就认为指标是正常健康的状态。比如:
cpu_usage_idle < 5
如上例,告警规则的 promql 中是带有阈值(< 5)的,所以只要查到了数据,就说明当前的值小于 5,只要没查到数据,就说明当前的值大于等于 5,即当前数据是健康的状态。注意,查不到数据的时候,时序库不返回数据,换句话说,数据正常的时候,因为时序库不返回数据,上层就拿不到正常状态时的值,既然拿不到正常状态时的值,也就没法在恢复时展示当前最新的值啦。
实际上,恢复时的事件,是 Alertmanager 根据 resolve_timeout 生成的,而不是 Prometheus 生成的。Alertmanager 生成恢复事件时,会把上次告警的标签和注解带过去,值呢?就是上次告警时的值,Alertmanager 不会再去查询 Prometheus 拿到最新的值。
Alertmanager 可以拿到恢复时的值么?
坦白讲,很难。Alertmanager 需要根据上次告警的标签和注解去查询 Prometheus 拿到上次告警时的值,Alertmanager 不会这么干的,核心是:
- 从职能上,Alertmanager 去查询 Prometheus,就反向依赖了,Alertmanager 是告警的分发中心,不止是接收 Prometheus 推送过来的事件,还会接收其他告警源推送过来的事件,如果 Alertmanager 要去查询 Prometheus,那就耦合太过严重。
- Prometheus 的告警规则中可以附加标签,和监控指标的标签一起,作为事件的标签集发给 Alertmanager,Alertmanager 需要根据这些标签去查询 Prometheus,拿到原始数据,这在某些场景下是不可行的。一个是要把标签中的附加标签剔除,只留数据标签,Alertmanager 没有办法做到;其次,有些 promql 查询结果压根就没有标签,根本没法查;再次,Alertmanager 需要解析 promql,把阈值的部分拿掉,而有些 promql 压根就不是数字阈值。
如果你想通过修改 Alertmanager 达成所愿,放弃吧。
有没有办法解决?
有。通常的解决办法有两种:
- 告警规则里,顺便配置恢复时的 promql
- 把阈值从 promql 中拿掉,promql 只用于查询原始数据,然后在上层做阈值判定,不管监控指标当前是否健康,都会查到原始数据
下面我以一些监控产品为例,具体来说明。
告警规则里配置恢复时的 promql
使用这个方法的产品,以夜莺(Nightingale)监控为例,来讲解具体做法。核心是配置两个地方,一个是在告警规则里配置恢复时的 promql,另一个是在告警模板里配置恢复时的值的渲染。
比如我有一个告警规则用来侦测 HTTP 地址探测失败:
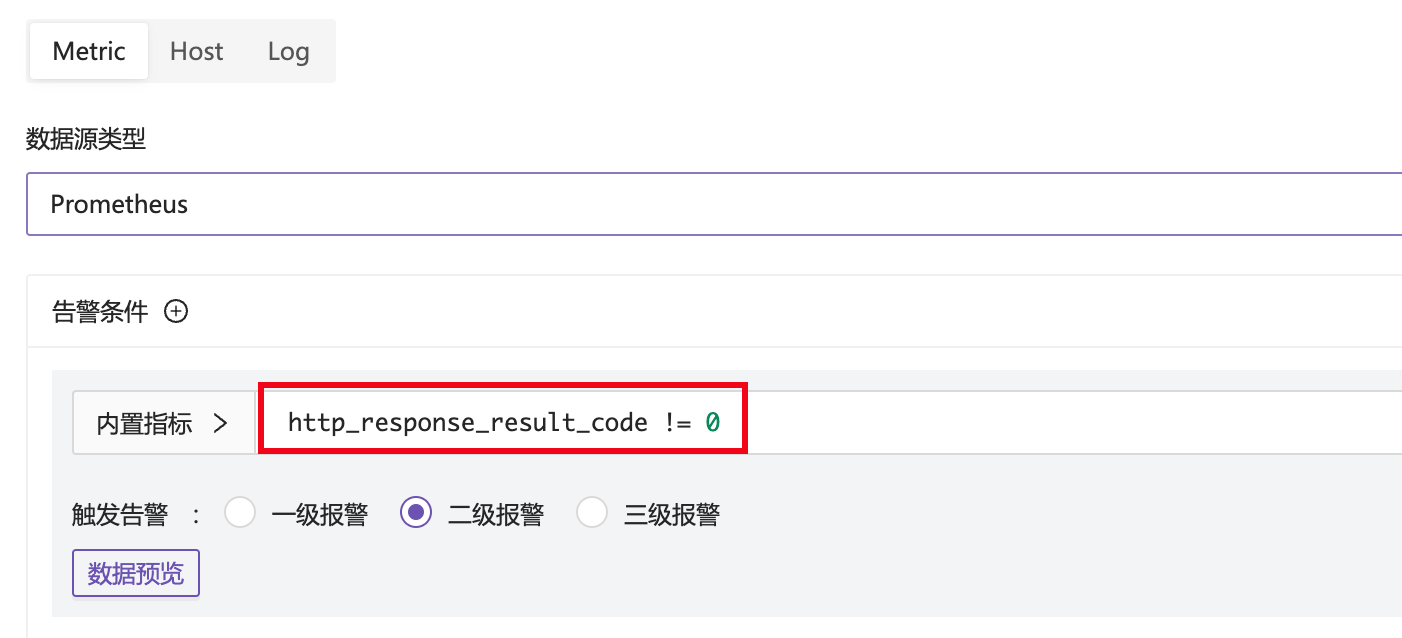
需要在告警规则最下面的自定义字段里,增加 recovery_promql 的配置,如下:

要理解这个工作逻辑,我们先来看看 http_response_result_code 这个指标的数据长什么样子:
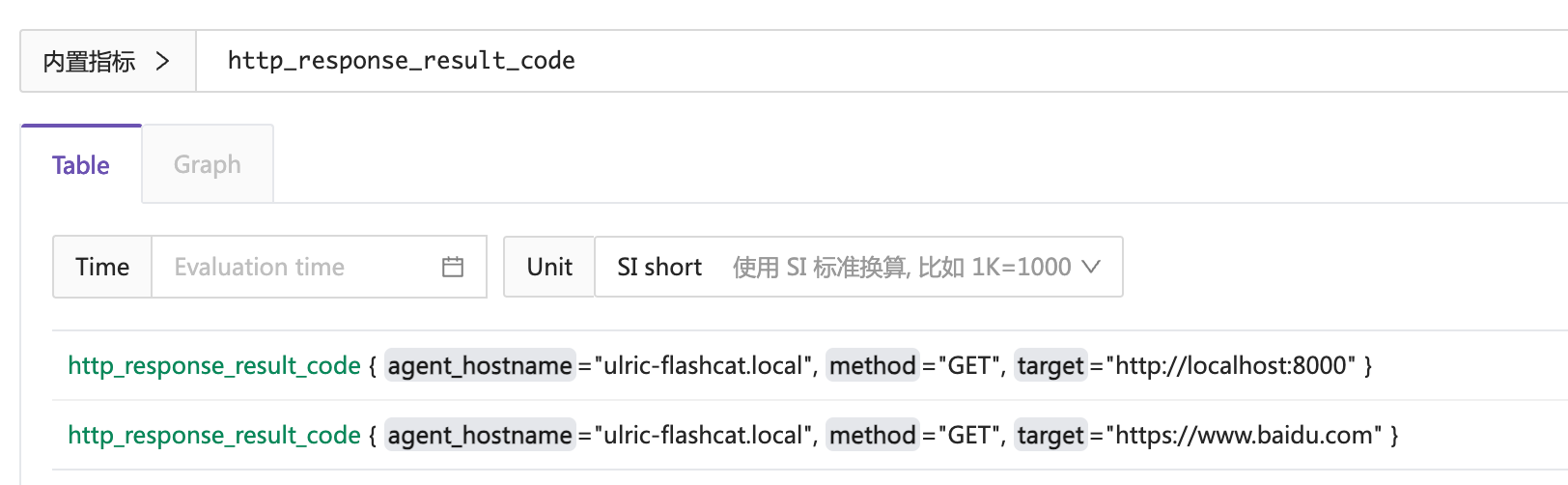
从上图可以看出,这个指标包含两个 series,其中 agent_hostname 和 method 字段相同,target 字段可以区分开这俩 series。告警规则 http_response_result_code != 0 如果触发,告警事件中一定会带有 target 标签,所以,如果告警事件恢复的时候,我们用高警时的那个 target 标签去查询,一定就可以准确查到恢复时的值了。所以 recovery_promql 的配置中引用了 target 标签,其值是变量,这个变量就是告警事件中的 target 标签值。
然后,我们在告警模板里,增加一个恢复时的值的渲染,以钉钉模板为例:
#### {{if .IsRecovered}}<font color="#008800">
标签:Alertmanager,恢复,Prometheus,promql,标签,告警
From: https://www.cnblogs.com/ulricqin/p/18387088