DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
arxiv:http://arxiv.org/abs/2406.19101
视觉处理器+LLM:视觉处理器:Swin Transformer
创新点:通过:1、去除图片冗余像素;2、去除冗余token。来减小模型中的视觉处理器的参数量

现存的文档理解多模态模型面临3个主要问题:1、高分辨率;2、密集文本;3、复杂的文档布局。针对此问题作者提出:1、Adaptive Pixel Slimming(APS);2、Dynamic Token Slimming(DTS)
模型结构

1、Adaptive Pixel Slimming(APS):自适应的像素缩减:移除图片中不重要的部分(比如说图片的边缘、空白等)处理之后 保持图片的纵横比 不变(因为如果纵横比发生改变容易导致文字扭曲,视觉处理上效果就不是很好)。
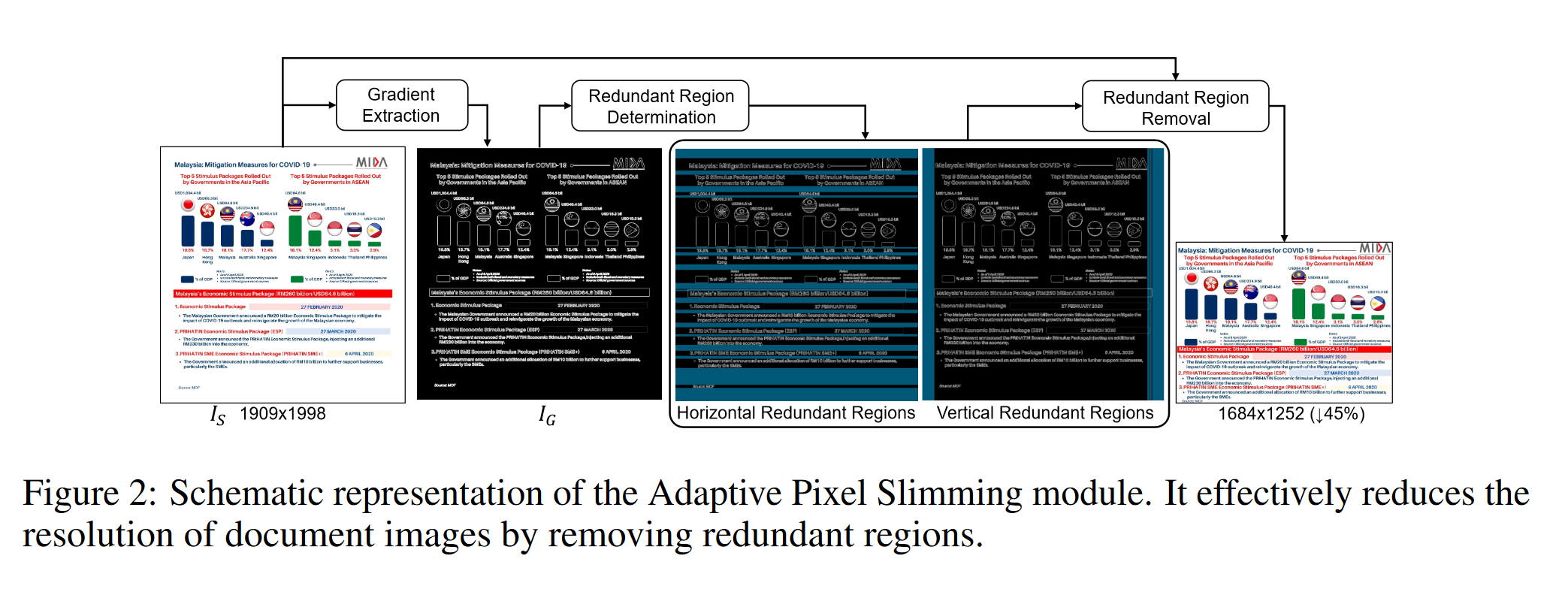
只适合处理布局简单的图像,比如说:文档等,因为这些图像而言存在较多的冗余部分可以被删除
处理流程:对于给定的一张图片通过 梯度提取 (简单理解为将图片转化为黑白图片),而后通过设定的阈值(可以类似于opencv中联通区域算法,将一些列的阈值小于某个值的内容进行“拼接”)来判断是不是冗余的(如果没有文字/内容纯白背景就会转化为黑色),而后根据:水平/竖直方向来将冗余的部分进行“丢弃”。(存在缺陷:对于简单的水平/竖直处理很方便,但是复杂之后提取效果就不是很好)
2、Dynamic Token Slimming:动态token缩减。出发点作者认为一个合适的视觉处理器应该是“区分”出在图片中那些是重要的,那些是不重要的
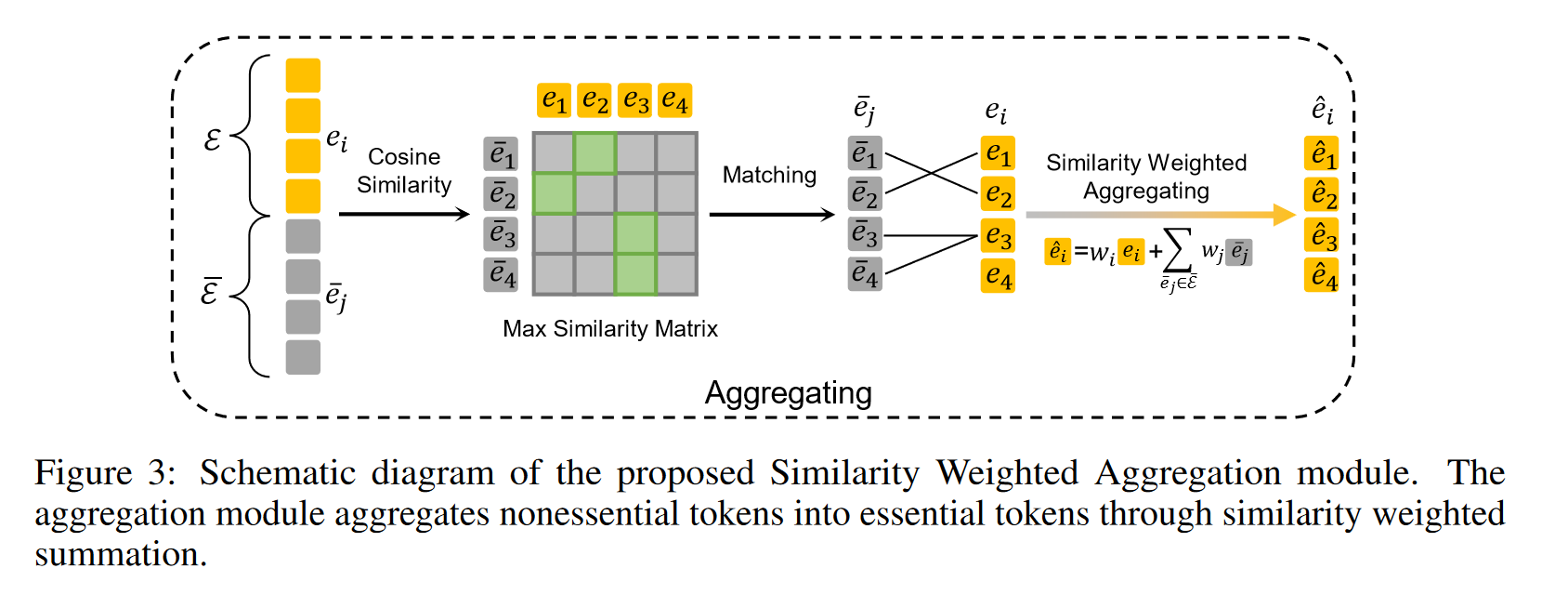
如果视觉处理器能够处理处理出那些属于 essential 那些属于 no-essential,那么后续就只需要将 必要的 和 非必要的进行分类即可。但是对于模型而言无法进行判断,但是非必要的存在一个问题:nonessential tokens typically lack uniqueness(缺乏独立性) and are often similar to other tokens(与其他token相似).那么就可以通过计算 相似性将非必要的token融合到必要的token中。
 标签:Slimming,Efficient,token,Multimodal,Visual,处理器,视觉,冗余
From: https://www.cnblogs.com/Big-Yellow/p/18381556
标签:Slimming,Efficient,token,Multimodal,Visual,处理器,视觉,冗余
From: https://www.cnblogs.com/Big-Yellow/p/18381556