前言 本文引入了一个区域特定的损失来提升隐含的均匀加权假设,以实现更好的学习,将整个体积划分为多个子区域,每个子区域都构建了一个针对最佳局部性能的个性化损失。有效地,这个方案对更难分割的子区域施加了更高的权重,反之亦然。此外,在训练步骤中为每个输入图像计算了区域的假阳性和假阴性误差,并相应地调整了区域惩罚,以提高预测的整体准确性。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文转载自PaperEveryday
仅用于学术分享,若侵权请联系删除
招聘高光谱图像、语义分割、diffusion等方向论文指导老师
题目:Adaptive Region-Specific Loss for Improved Medical Image Segmentation
自适应区域特定损失:提高医学图像分割性能
作者:Yizheng Chen; Lequan Yu; Jen-Yeu Wang; Neil Panjwani; Jean-Pierre Obeid; Wu Liu; Lianli Liu; Nataliya Kovalchuk
关键词
- 深度学习 (Deep learning)
- 损失函数 (Loss function)
- 医学图像 (Medical image)
- 神经网络 (Neural network)
- 分割 (Segmentation)
I. 引言
在医学图像上进行器官轮廓的描绘是许多临床程序中的关键步骤,通常在临床实践中是手动完成的[1][2]。然而,手动描绘涉及的器官是一项劳动密集且耗时的任务,并且结果可能依赖于操作者[3][4]。以头颈癌病例为例,剂量测量师或医生可能需要花费数小时来描绘放射治疗计划中的数十个器官,这在很大程度上限制了患者护理的质量和效率。因此,临床上迫切需要自动描绘工具[5][6]。
近期,深度学习方法在自动分割方面取得了巨大成功。事实上,基于卷积神经网络(CNN)的算法[7][8][9][10][11][12][13][14][15][16]和新兴的基于变换器网络的方法[17][18][19][20]正越来越多地被用于计算机断层扫描(CT)、磁共振成像、超声等医学成像方式中的肿瘤和正常组织的自动分割。
在深度学习中,损失函数通常用于测量网络预测与真实标注之间的差异,并指导网络参数的优化[21][22][23][24][25][26][27]。Dice损失和交叉熵损失是该任务中最有代表性的两种损失函数[28][29][30]。简单来说,前者计算预测分割体积与真实标注之间的重叠程度,而后者则测量两者之间的逐像素差异。然而,这两种损失函数都没有考虑到系统的异质性[31][32][33],对所有像素一视同仁。一些像素,如组织对比度低的器官边界附近的像素,通常更难被描绘。这些“困难”的像素通常是限制当前深度学习网络性能的因素。因此,更多地关注这些像素可能会提高学习效率和自动分割性能。
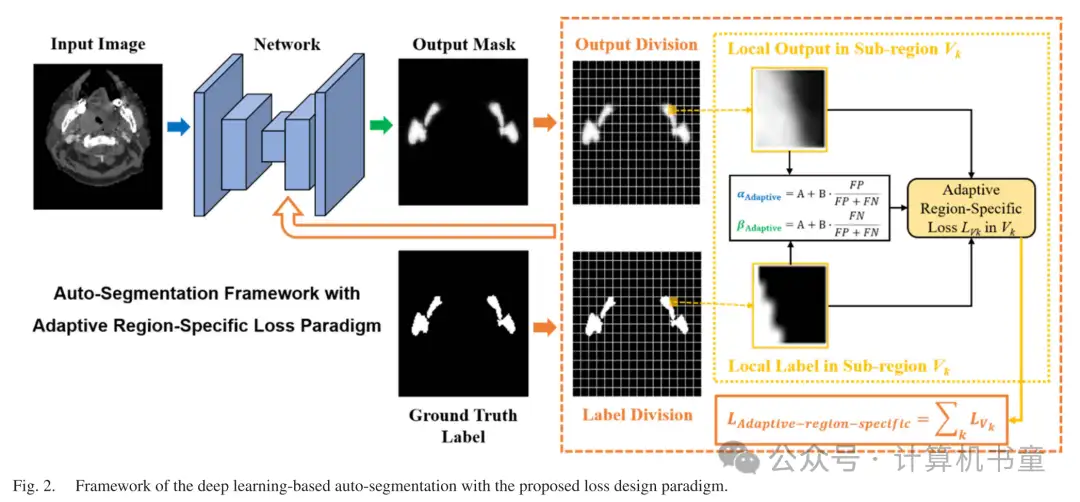
在本研究中,我们提出了一种区域特定的损失方案,以改善深度学习的决策。如图1所示,与计算整个图像体积的预测和真实标注之间重叠的传统Dice损失不同,我们将体积划分为子区域,并分别优化每个子区域的网络预测。这种区域特定的损失允许自动调整每个子区域的权重,以便更多地强调难以实现高预测准确性的子区域。
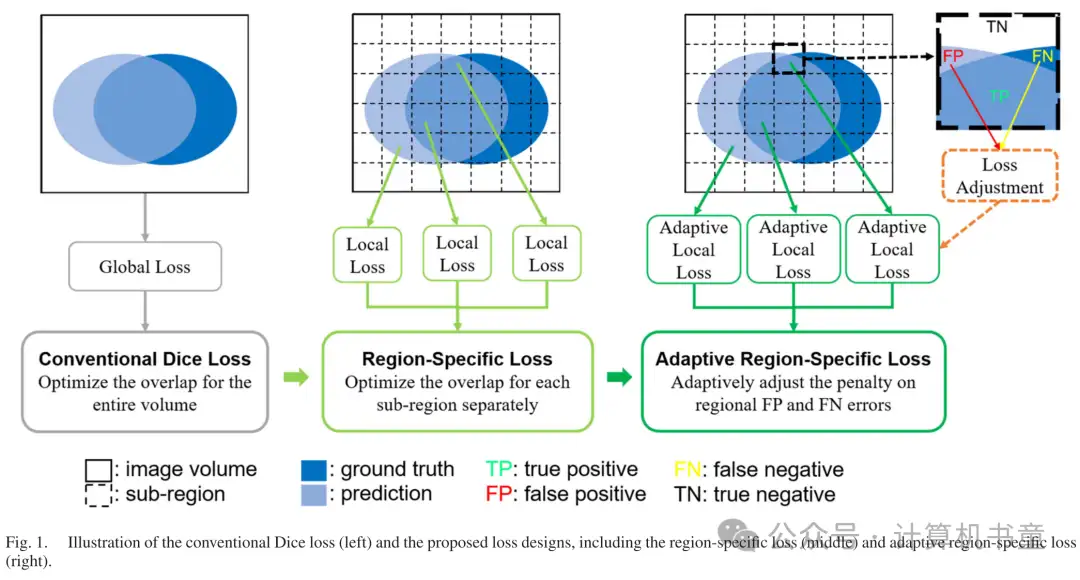
通常,随着训练步骤的进行,由于假阳性(FP)和假阴性(FN)两种类型的分割误差在训练过程中的变化,网络预测的准确性也会变化[34]。换句话说,使用预定义的损失函数并不总是能够获得最优的网络学习结果。例如,在Dice损失中,FP和FN误差被同等强调,这对应于精确度和召回率的调和平均。在某些情况下,医学图像自动分割中两种误差类型可能存在严重的不平衡。当分割目标远小于背景时,网络通常更容易出现FN误差而不是FP误差。Dice损失被扩展为Tversky损失[35],以实现两种类型误差之间的灵活权衡。然而,这种损失函数的性能对控制两种类型误差之间权衡的超参数非常敏感。Seo等人[34]进一步将Tversky损失扩展为一个通用损失函数,设计了一种策略,在训练过程中逐步调整损失参数,以获得更好的性能。为了获得最佳性能,我们采用了类似的策略,通过在网络训练过程中根据局部预测结果自适应调整FP和FN误差之间的权衡,来优化区域特定的损失。
本研究的主要贡献如下:
- 我们提出了一种新颖的区域特定损失概念,以提高深度学习预测的性能。
- 我们开发了一种算法,在训练过程中自适应调整区域特定损失函数的超参数,以优化局部FP和FN误差之间的平衡。
- 我们在不同的CT分割数据集上进行了实验,并证明了所提出方法的有效性。
所得到的自适应区域特定损失函数非常广泛,可以应用于大多数分割学习框架,无需修改网络架构或更改数据预处理程序。区域特定框架也可以推广到许多其他深度学习任务。接下来,我们首先在第二节中讨论相关工作,并在第三节中详细阐述我们的方法。实验条件和结果在第四节中描述。然后我们在第五节中讨论我们方法的关键点和结果,并在第六节中得出结论。
III. 提出的方法
A. 传统的Dice损失
在图像分割中,网络预测由每个像素属于目标器官还是背景的概率组成。Dice相似系数(DSC)[49]通常用于衡量网络预测体积与真实标注之间的空间重叠程度。它定义为:
其中P和G分别表示预测和真实标注的体积。基于DSC,提出了深度学习基础的分割的Dice损失函数,大致等于1-DSC,定义为:
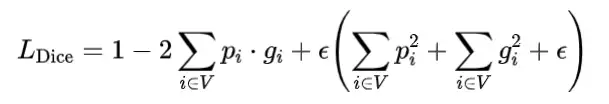
其中 表示网络预测像素i属于目标器官的概率, 表示相应的二进制真实标注值。V表示整个图像体积,常数 在这里使用,以避免除以零的奇异性。因此,Dice损失的优化目标是完全重叠预测和真实标注体积。Dice损失方程可以针对预测的第j个像素进行微分,得到梯度:
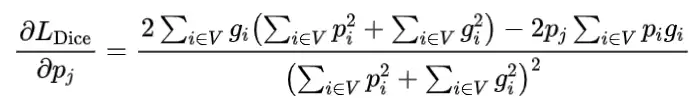
在自动分割学习过程中,目标器官的某些部分,如内部区域或具有明显对比度的一些地标,通常可以被网络以高准确度轻松预测。另一方面,对于一些其他部分,如成像对比度低的器官边界区域,网络可能难以准确分类像素,导致分割结果较差[26][30][36]。遗憾的是,传统的Dice损失只针对整个体积重叠进行优化,因此目标或背景区域内的每个像素都被同等对待,没有考虑不同子区域可能出现的各种分割困难,这可能导致次优网络。
B. 区域特定损失
为了克服上述Dice损失的限制,我们提出了一种新颖的方法,进行区域特定增强。为了解决对图像体积不同部分强调需求的差异,我们将预测体积V划分为K个不同的子体积 ,并分别对它们进行Dice损失计算。通过这种方式,每个局部或区域Dice损失只关注一个特定子区域的预测优化,与其他子区域的优化无关。最终的区域特定损失是所有子区域的区域Dice损失的总和:
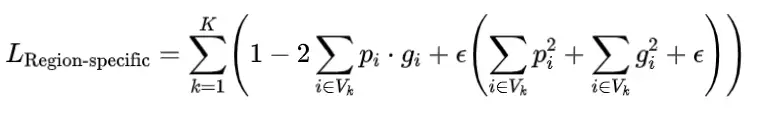
根据(3),区域特定损失的梯度只受子区域内的预测和标签分布的影响,而不是像全局Dice损失那样受整个图像体积的分布影响。由于预测和标签分布在子区域之间是不同的,像素的预测对网络优化的贡献取决于其位置。如果子区域可以被网络轻松预测,则该子区域内的预测值将非常接近相应的真实标注值。这导致该子区域内的最终梯度值接近零,对该子区域的预测优化分配的权重较小。因此,所提出的区域特定损失可以隐式地并且自动地通过降低被良好预测的子区域的重要性,在训练过程中实现区域特定的加权,从而提高深度学习效率。在本研究中,每个案例的预测体积被划分为16×16×16子区域网格,用于区域特定损失的计算。
C. 自适应区域特定损失
在像素级分割学习中,网络尝试最大化真正例(TP)预测并最小化假正例(FP)和假负例(FN)误差。DSC可以被视为精确度(P = TP/(TP + FP))和召回率(R = TP/(TP + FN))的调和平均[30],因此在Dice损失函数中,FP和FN被同等加权。对于医学图像分割,一些目标器官的体积通常比背景体积要小得多,这可能导致严重的数据不平衡问题,使网络预测偏向背景,FN误差在网络训练期间往往比FP误差更为主导。为了在精确度和召回率性能之间实现更好的权衡,开发了Tversky损失函数[35],定义如下:
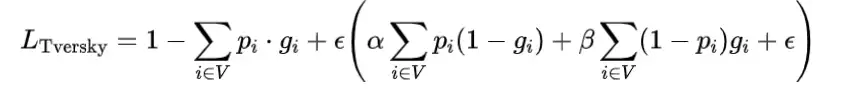
注意,Tversky损失比Dice损失更通用,并且当α = β = 0.5时,它退化为1-DSC。当β大于α时,Tversky损失更多地强调FN误差以提高召回率。原始Tversky损失中的α和β参数在训练前预定义。由于这些参数的选择严重影响最终学习性能,它们的值通常通过手动试错进行微调以实现最优预测,这是一个计算成本高昂的过程。此外,网络在训练过程中的召回率和精确度性能会发生变化,因此使用预先选定的超参数可能导致次优性能[34]。在这里,我们进一步引入了基于所提出的区域特定损失的每个子区域的自适应误差惩罚。考虑到Tversky损失比Dice损失更通用,可以控制FP和FN误差之间的权衡,因此在本研究中,它被用作自适应区域特定损失计算的基础:
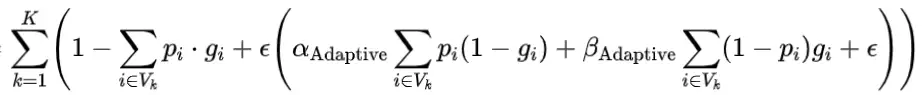
其中参数 和 在训练过程中进行微调,以强调不同类型的区域误差并优化网络学习。根据Tversky损失(5),α和β分别惩罚FP和FN误差。在特定子区域中,如果FP误差大于FN误差,则应增加α的值以增加对FP误差的惩罚并提升精确度。同样,β的值将增加以惩罚FN误差并提升召回率。具体来说,设计了以下算法根据给定子区域Vk中FP和FN误差的比例调整 和 参数:
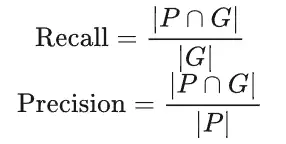
根据(7)和(8), 和 的值在[A, A+B]范围内变化,并分别随着FP和FN误差的比例线性增加。因此,根据训练过程中子区域内网络预测结果,损失函数对FP和FN误差的强调会自适应地进行微调。我们在本研究中经验性地将常数系数A和B设置为0.3和0.4,并在消融研究中进一步探索超参数调整范围的影响。请注意,在子区域中FP = FN的情况下, ,这意味着损失函数对两种预测误差给予同等的重要性,接近(4)。提出的具有自适应区域特定损失(6)-(8)的深度学习框架如图2所示。所提出的损失方案不仅提供了通过更多地关注难以预测的不同子区域的有效方法,而且还实现了在训练过程中根据自动调整的函数参数对每个子区域进行自适应误差惩罚,这有望实现更有效的自动分割学习。
D. 网络和训练细节
我们实现了一个带有批量归一化[50]和dropout[51]的V-Net[28]架构,用于医学图像中3D多器官自动分割。网络的输入是整个图像体积,输出是基于Softmax激活的所需目标器官和背景的相应像素级概率图。我们在实验中使用传统的Dice损失和交叉熵损失作为基线损失函数的组合,这已在多器官分割研究中广泛使用[52][53][54]:
其中C是目标器官总数加一(背景),λ是Dice损失 和交叉熵损失 之间的权衡。采用Adam算法[55]来优化网络权重。通过使用包括随机翻转、平移和缩放在内的各种图像变换,应用了即时数据增强,以增加不同数据表示的多样性。该框架在PyTorch中实现,并在具有11 GB内存的NVIDIA GeForce RTX 2080 Ti GPU上执行计算。
IV. 实验
A. 数据集和预处理
为了分析我们方法的有效性,我们使用了两个独立的医学图像数据集来进行头颈部器官的自动分割,另外两个腹部和肝脏数据集在消融研究中使用以进一步验证。PDDCA 数据集:第一个公共数据集是来自 2015 年 MICCAI 头颈部自动分割挑战赛的公共计算解剖数据库 (PDDCA) [56]。该数据集包含来自 48 个患者案例的头颈部 CT 图像,每个案例都标注了九个器官的轮廓:脑干、视神经交叉、下颌骨、左和右视神经、左和右腮腺、左和右下颌下腺。每个器官的二进制掩码从相应的轮廓数据生成,并作为网络训练的标签。背景的掩码也根据器官掩码生成。每个 CT 图像的平面像素间距范围从 0.76 到 1.27 毫米,层间距从 1.25 到 3.0 毫米。图像和标签体积被裁剪以适应患者轮廓,然后调整到固定的分辨率为 1.5 毫米 × 1.5 毫米 × 1.5 毫米。采用 [-200, 400] 窗口对图像像素强度进行阈值处理,然后将强度重新缩放到 [-1, 1] 以去除不相关细节。总体上,选择了 32 个案例进行网络训练,6 个案例进行验证,10 个案例进行测试。内部数据集:第二个内部数据集包含从斯坦福大学医学中心收集的 67 个临床头颈部 CT 扫描,符合机构审查委员会 (IRB) 指南。对于每个患者扫描,医生手动描绘了 14 个器官并用作真实标注,包括脑干、左和右臂丛、食管、喉、嘴唇、下颌骨、口腔、左和右腮腺、咽、脊髓、左和右下颌下腺。原始图像体积被裁剪并重新采样为 128 × 144 × 256 大小。图像强度被截断到 [-160, 240],然后归一化到 [-1, 1]。总体上,随机选择了 49 个案例进行训练,8 个案例进行验证,10 个案例进行测试。腹部数据集:为了进一步验证所提出方法在不同身体部位的有效性,使用了在 MICCAI 2015 多图谱腹部标记挑战赛 [57] 中发布作为消融研究的数据集。该数据集包含 30 个来自患者的对比增强 3D 腹部 CT 扫描。图像体积被裁剪并重新采样为 144 × 96 × 112 大小。图像强度被截断到 [-500, 800],然后归一化到 [-1, 1]。我们报告了八个腹部器官(主动脉、胆囊、左肾、右肾、肝脏、胰腺、脾脏、胃)的 DSC。采用三重交叉验证,20 个案例用于训练,10 个案例用于验证。LiTS 数据集:另一个公共肝脏数据集来自 2017 年肝脏肿瘤分割 (LiTS) 挑战赛 [58],[59]。该数据集包括 131 个患者案例,每个案例都有对比增强的 3D CT 扫描,每个案例都标注了肝脏和肝脏肿瘤的轮廓。原始图像体积被裁剪并重新采样为 192 × 144 × 80 大小。图像强度被截断到 [-250, 250],然后归一化到 [-1, 1]。在训练过程中,随机选择了 86 个案例,用于训练过程,15 个案例分配给验证,其余 30 个案例保留用于测试目的。
B. 性能评估
为了评估我们提出的区域特定增强和自适应误差惩罚方法在分割任务上的性能,对于每个数据集,我们在相同的网络和训练条件下进行多器官分割学习,使用三种不同的损失函数组合:1) 仅使用基线损失(9)进行网络优化(基线),以获得基线结果;2) 结合基线损失和区域特定损失(4)进行优化(基线+区域特定),以评估区域特定损失的增强,其中每个子区域被分别和不同地处理;3) 在训练期间结合基线损失和自适应区域特定损失(6)(基线+自适应区域特定),进一步展示自适应微调区域特定损失中超参数的效果,展示最终提出的损失方案的性能。此外,交叉熵损失[29]和Dice损失[28]在网络训练期间也单独使用,以进行比较。在评估研究中,DSC 作为主要的性能指标,用于衡量自动分割结果和真实标注之间的空间重叠[36]。此外,还计算了召回率和精确度[60]、95 百分位 Hausdorff 距离(HD95)[61]和平均表面距离(ASD)[62],以进行更全面的评价。这四个指标定义如下:
其中 表示像素 i 和像素 j 之间的欧几里得距离。
C. 实验结果
- 定量结果:使用两个头颈部数据集研究了所提出的区域特定损失和自适应区域特定损失在自动分割学习中的性能。每个目标器官的评估 DSC 结果分别在表格 I 和 II 中总结,分别对应公共的 PDDCA 和内部数据集。平均而言,基线损失和两种提出的方法都比常规的交叉熵损失和 Dice 损失在两个数据集上显示出更好的 DSC 结果。由于基线损失表示为 Dice 损失和交叉熵损失的组合,并且在性能上超过了任一单独的损失函数,因此它被用作分析的基准。通过在基线损失的基础上采用区域特定损失,两个数据集的平均 DSC 分别从 0.751 和 0.657 提高到 0.764 和 0.669,证明了区域特定网络优化的有效性。当在训练过程中自适应调整控制 FP 和 FN 误差权衡的区域特定损失的超参数时,平均 DSC 进一步增强到 0.772 和 0.685。
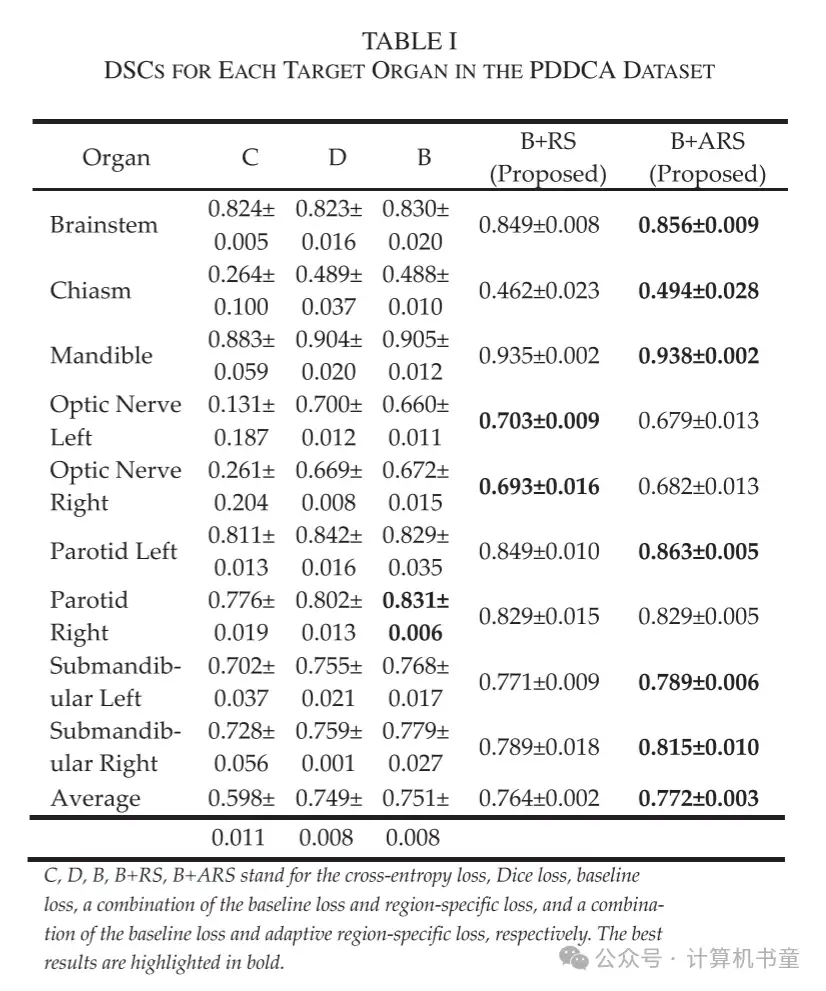
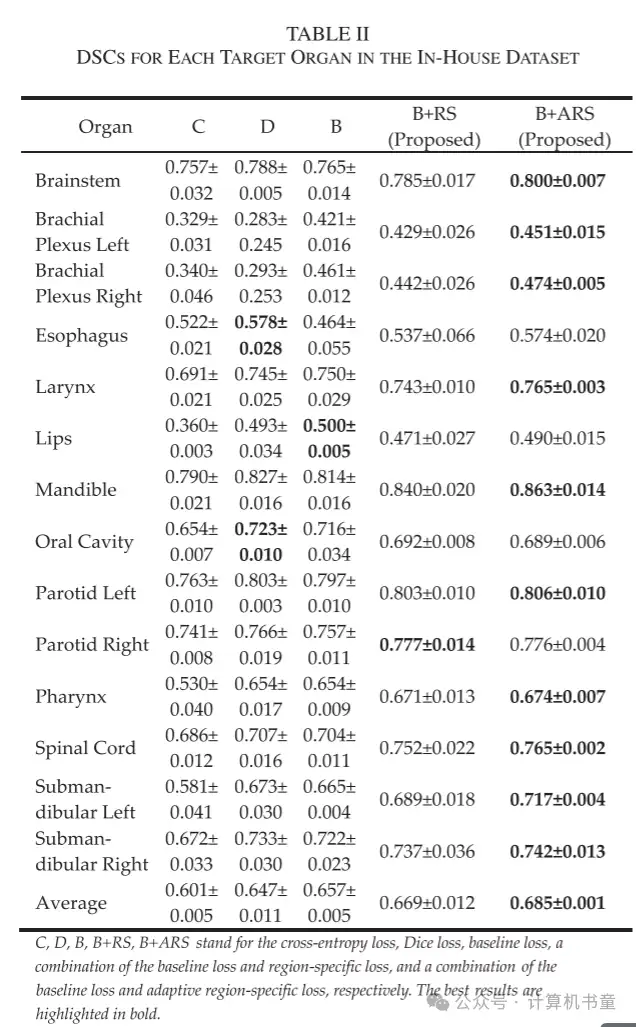
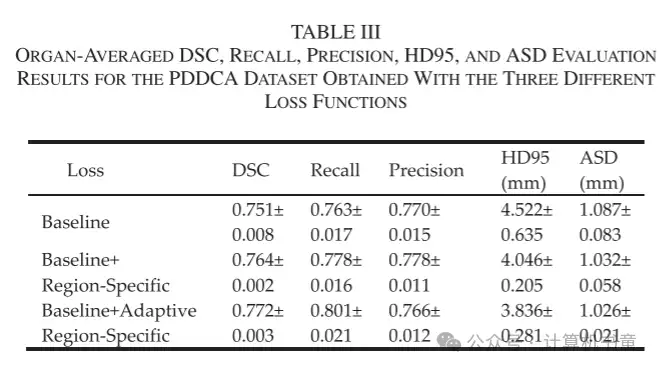
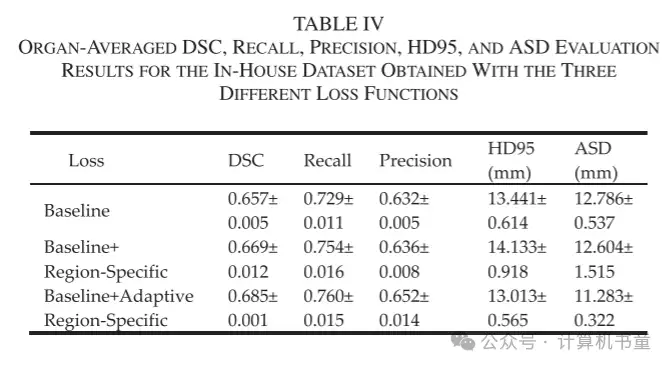
与基线损失相比,PDDCA 数据集中 9 个器官中的 8 个和内部数据集中 14 个器官中的 12 个在训练期间引入区域特定增强或自适应误差惩罚后 DSC 结果有所提高。以下颌骨为例,在 PDDCA 数据集和内部数据集上,使用两种提出的损失函数分别将 DSC 提高了 0.030 和 0.033,以及 0.026 和 0.049。表格 III 和 IV 显示了使用三种不同损失函数在 PDDCA 和内部数据集上获得的每个器官的平均 DSC、召回率、精确度、HD95 和 ASD 的评估结果。除了平均 DSC 外,平均召回率、精确度、HD95 和 ASD 也几乎通过区域特定损失得到了改善,为其实效性提供了更多证据。此外,引入自适应误差惩罚进一步提高了平均 DSC、HD95 和 ASD 值。我们注意到它对两个数据集的召回率和精确度的影响是不同的。对于 PDDCA 数据集,平均召回率增加了 0.023(从 0.778 到 0.801),而精确度降低了 0.012(从 0.778 到 0.766),表明为了提高召回率,精确度略有牺牲。对于内部数据集,召回率仅增加了 0.006,而精确度增加了 0.016。
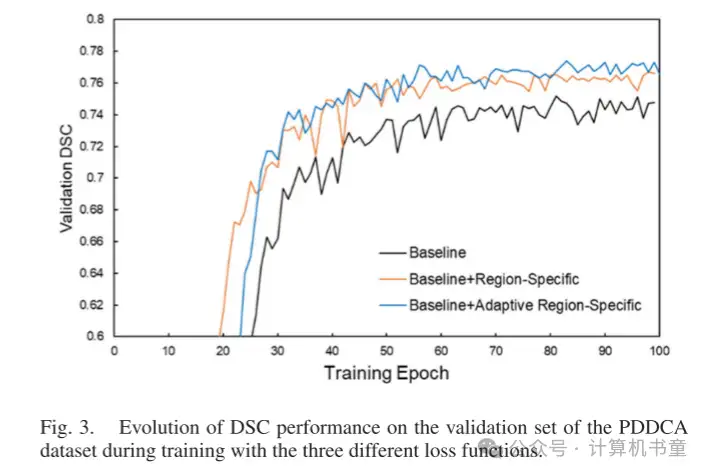
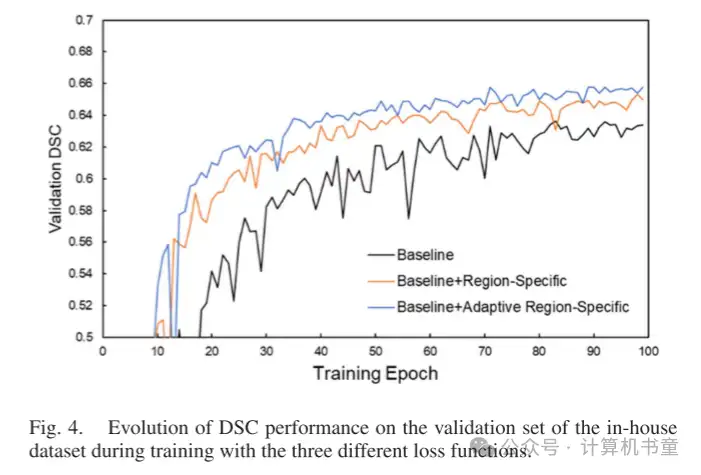
在训练期间,三个不同的损失函数在验证数据集上的 DSC 性能演变如图 3 和 4 所示,分别为 PDDCA 和内部数据集。可以观察到,验证性能随着学习过程逐渐增加,并在大约 80 个周期后逐渐饱和。使用自适应区域特定损失的学习曲线优于使用区域特定损失的曲线,并且两者都以明显的优势优于仅使用基线损失的曲线,展示了提出方法的好处。
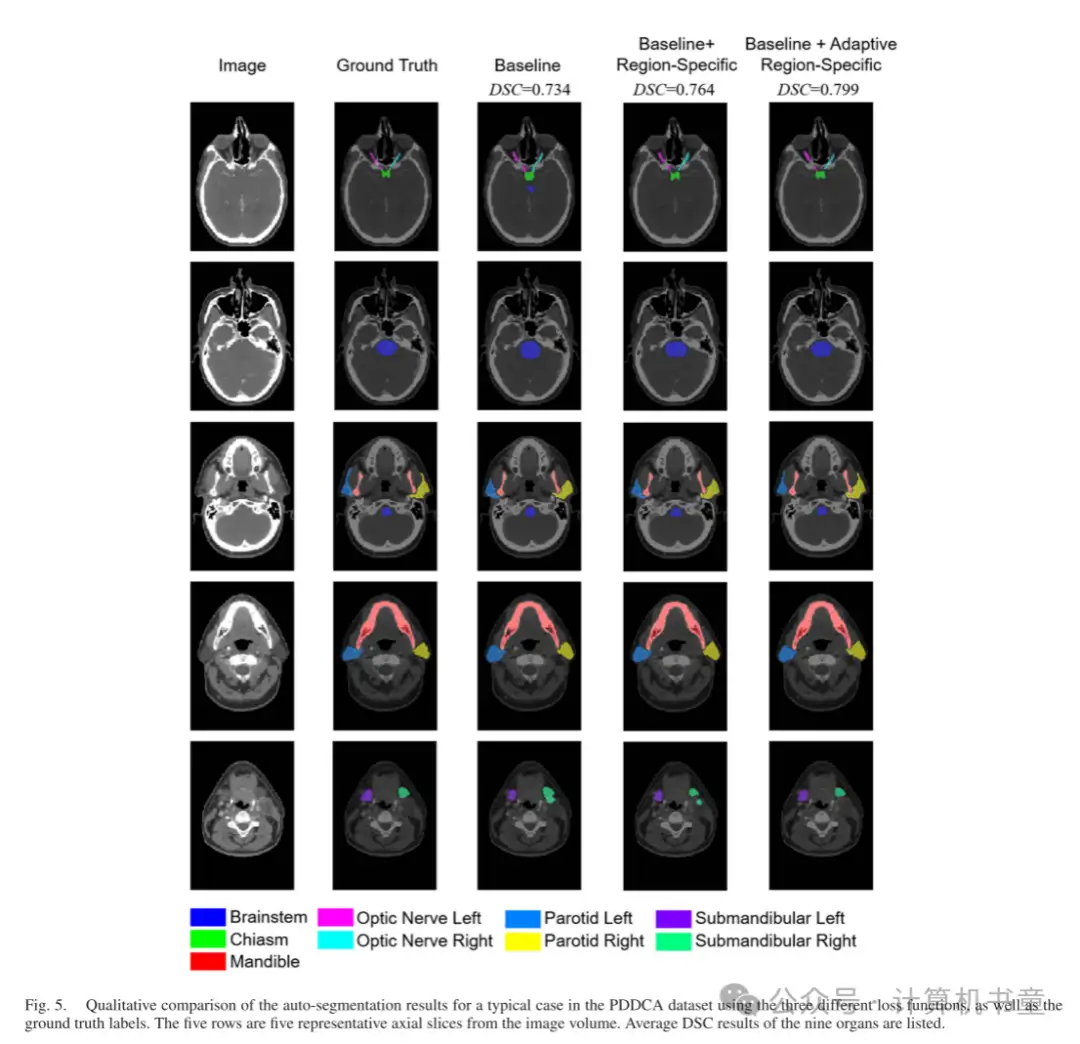
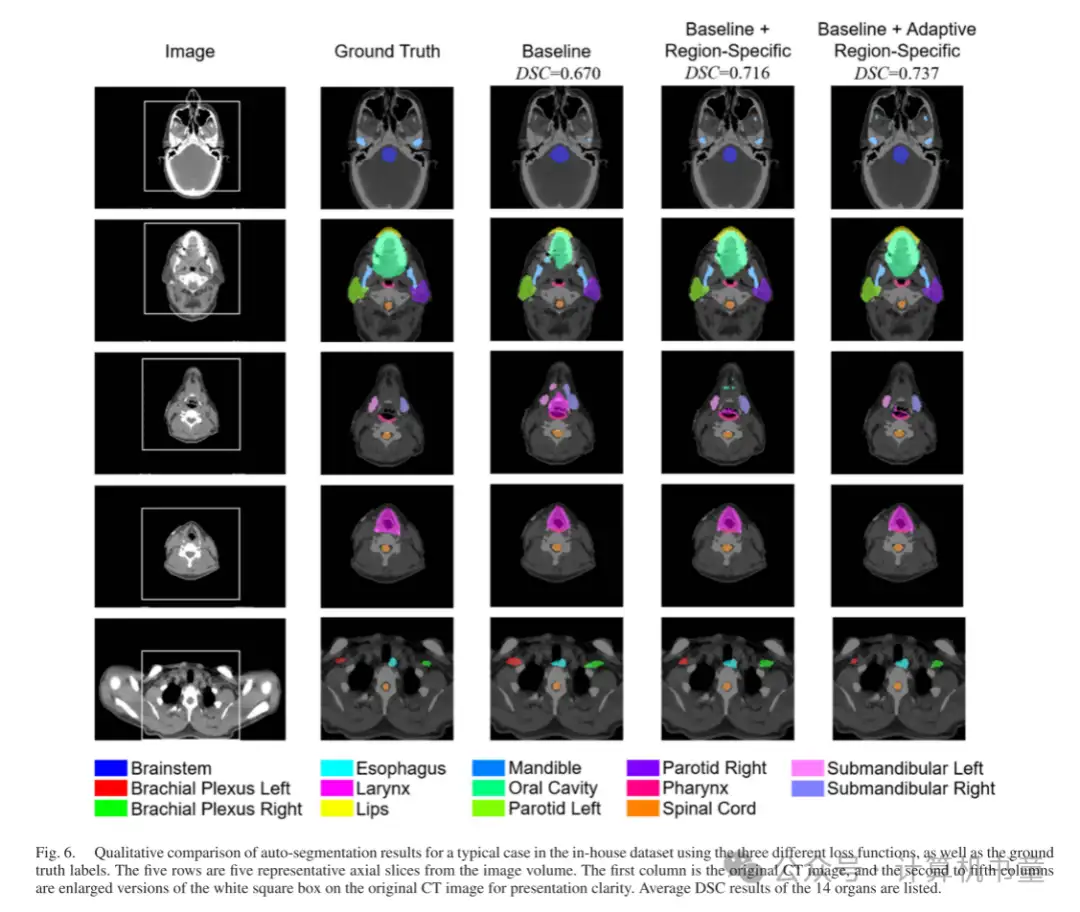
- 定性结果:图 5 和 6 展示了自动分割结果的定性分析。通过使用区域特定损失和自适应区域特定损失,预测的器官掩模得到了改善,并且更接近真实标注标签,明显优于基线结果。以右侧下颌下腺为例,如图 5 的最后一行和图 6 的第三行所示,基线网络倾向于预测比真实标注标签大得多的掩模。这通过所提出的损失函数得到了纠正。通过目视检查预测掩模,我们的方法有望用于临床自动分割。
- 消融研究:为了进一步验证所提出的区域特定损失和自适应区域特定损失的有效性,我们进行了一些消融研究,主要在 PDDCA 数据集上。首先,我们研究了子区域划分对区域特定损失性能的影响。通过使用不同的划分系数(DCs),范围从 1 到 16,这意味着整个图像体积被均匀地划分为 DC × DC × DC 子区域,区域特定损失在公共 PDDCA 数据集上的 DSC 性能如图 7 所示。值得注意的是,DC = 1 对应于传统的全局 Dice 损失。结果表明,随着划分的子区域数量增加和每个子区域的体积减小,区域特定损失的性能逐渐提高。
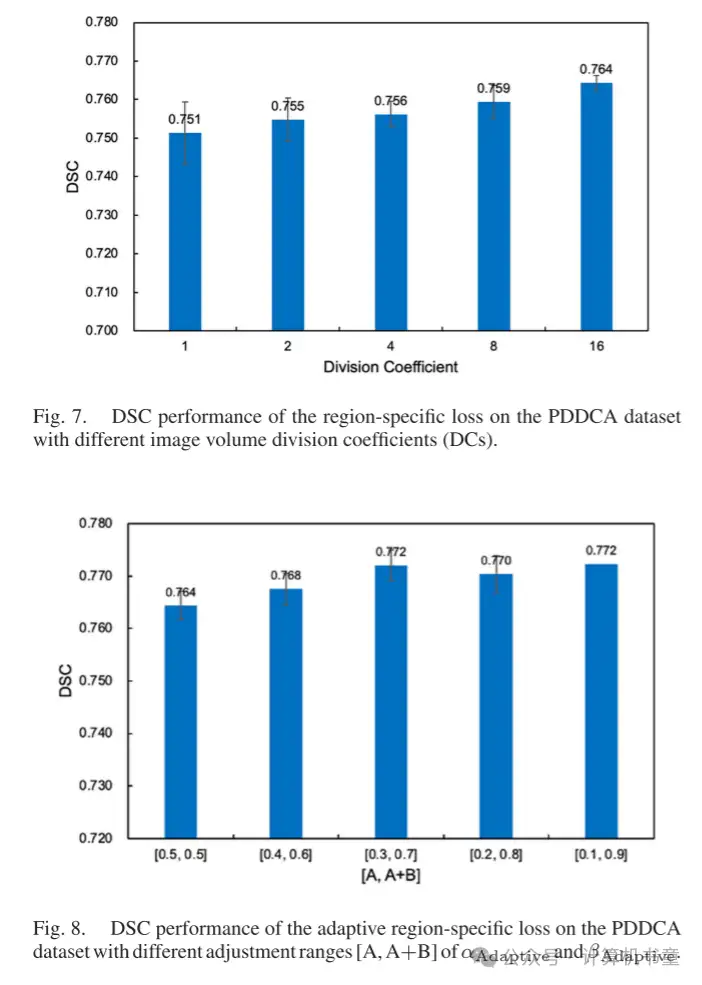
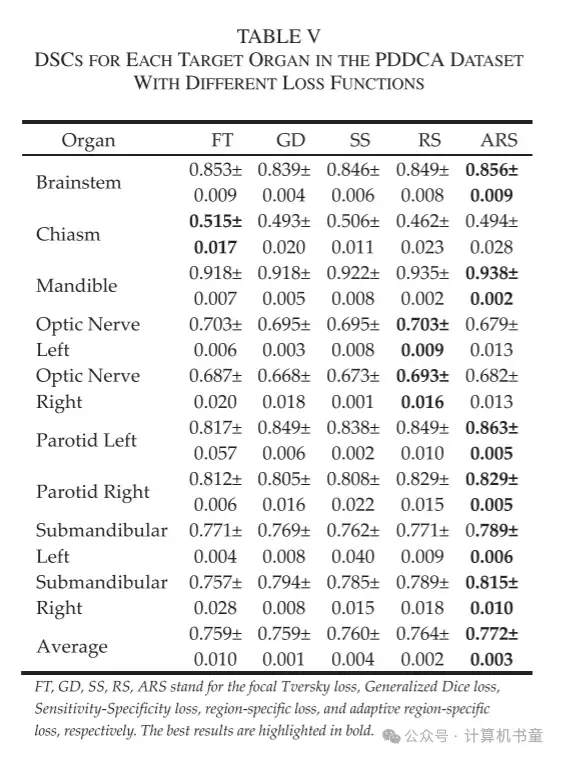
我们进一步研究了自适应区域特定损失中超参数调整范围的影响,即 (7) 和 (8) 中的 A 和 B 值对其性能的影响。如图 8 所示,随着 αAdaptive 和 βAdaptive 的调整范围 [A, A+B] 的增加,自适应区域特定损失的 DSC 性能逐渐增加然后饱和。因此,损失函数更大的动态调整范围可能承诺实现两种类型误差之间更灵活的权衡,并实现更准确的整体预测。所提出的区域特定损失和自适应区域特定损失的性能也与其他基于区域的分割损失进行了比较,即焦点 Tversky 损失 [46]、广义 Dice 损失 [47] 和敏感性-特异性损失 [48]。这些损失函数在 PDDCA 数据集上的 Dice 结果如表格 V 所示。它表明区域特定损失和自适应区域特定损失均优于其他三种基于区域的分割损失函数。
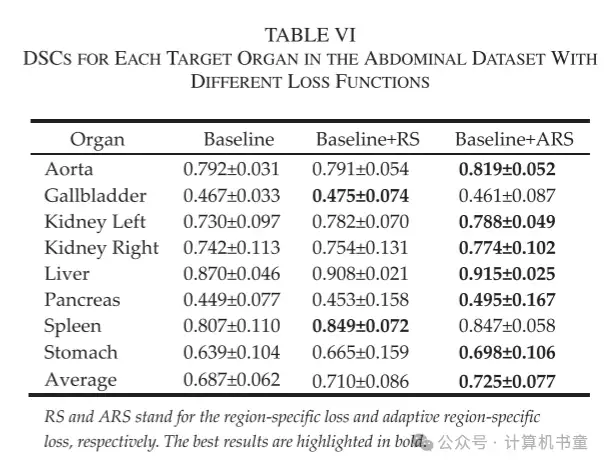
为了进一步验证我们提出的损失范式的普适性,我们将其应用于另一个公共腹部数据集。结果如表格 VI 所示,表明所提出的区域特定损失和自适应区域特定损失都能提高该腹部数据集的自动分割性能,器官平均 DSC 分别从 0.687 提高到 0.710 和 0.725。此外,我们的方法导致所有八个器官的 DSC 值提高。因此,我们的损失范式有望提高不同身体部位的自动分割性能。
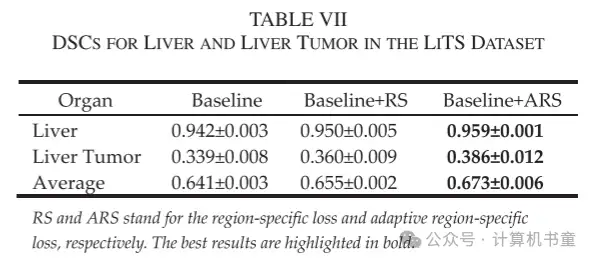
我们的方法在公共 LiTS 数据集上的 Dice 性能如表格 VII 所示。应用所提出的区域特定损失和自适应区域特定损失已经导致肝脏和肝脏肿瘤的自动分割结果得到改善。具体来说,肝脏的 DSC 从 0.942 提高到 0.950 和 0.959,肝脏肿瘤的 DSC 从 0.339 提高到 0.360 和 0.386。这些改进进一步验证了我们提出的损失范式的有效性。
V. 讨论
图像自动分割是临床实践中的一项关键任务。许多研究致力于使用深度学习来自动化分割过程。在本研究中,我们首次引入了一种区域特定的损失,通过局部和分别优化网络预测结果来改善基于深度学习的分割。与传统的Dice损失不同,后者隐含地将图像体积内的所有像素同等对待,我们的区域特定损失考虑了不同子区域实现准确分割的个别能力。在网络训练期间,传统Dice损失在像素上的梯度取决于整个图像体积内的网络预测和真实标注值。因此,即使对于预测结果准确的像素,如果整体预测不完全准确,Dice损失在这些像素上仍然会产生非零梯度值(3)。也就是说,这些像素可能仍然会在训练期间为网络优化做出贡献。相比之下,所提出的区域特定损失通过将整个体积划分为多个子区域来减轻这个问题。这样,区域损失梯度仅取决于局部预测和真实标注值,在预测准确的子区域内梯度值接近零。因此,与传统损失方案相比,我们的方法允许算法更多地关注预测准确度较低的子区域。我们的实验结果清楚地证明了区域特定损失优于传统损失函数。基于区域特定损失,我们进一步开发了一种自适应区域特定损失,它在网络训练期间具有自适应误差惩罚。与在训练前预定义的传统损失函数不同,所提出的损失函数根据区域预测结果自适应调整FP和FN误差的相对重点,通过微调惩罚参数。由于自适应区域特定损失分别应用于每个子区域,优化重点的确切调整和最终损失计算在不同子区域之间有所不同。最终的损失计算使得每个子区域具有区域特定增强和自适应误差惩罚,以改善深度学习。值得注意的是,这里的关键见解是根据学习过程中的区域预测结果自适应调整损失函数的重点。虽然在我们的自适应区域特定优化中使用了Tversky损失作为示例,但应强调该方法是相当通用的,其他损失函数,如敏感性-特异性损失[48],也可以在我们的方法中采用。已有一些研究将注意力直接引向目标体积的特定区域。例如,提出了基于边界的损失,以专注于提高器官边界附近的预测结果[26][30][32]。然而,由于在优化过程中直接区分距离测量度量标准是困难的,因此在应用损失函数之前必须预先计算距离图。此外,一些复杂的网络结构,如FocusNet[63]、Ua-Net[5]和SOARS[45]也已开发用于准确的自动分割,它们首先检测特定器官的兴趣区域(ROI),然后在ROI内进行精细的自动分割。在本研究中,所提出的区域特定损失可以直接应用于大多数自动分割研究,无需额外的数据准备或修改神经网络架构。我们损失设计范式的基本元素是Dice损失或Tversky损失,可以作为相同情况下全局Dice损失或全局Tversky损失的有效补充。基于区域的损失[21][30](如Dice损失)是深度学习领域中的一种重要损失函数。从理论上讲,我们的区域特定损失可以推广到其他适用基于区域损失的任务,如弱监督图像配准[64][65],以改善现有的预测结果。顺便提一下,区域特定惩罚也作为放射治疗计划和剂量优化的一种通用技术被提出[66]。在极端情况下,如果一个子区域没有真实前景,但预测包含前景,那么根据(3),预测值的区域特定损失的梯度始终为零,这使得优化预测误差变得困难(如果不可能)。从计算上,这种不良影响可以被缓解或最小化。一方面,在子区域内,如果特定分割目标没有前景像素,那么这些像素意味着它们属于其他目标或背景类别。通过优化其他目标或背景类别的FN误差预测,所提出的区域特定损失可以间接改善这一极端情况下特定分割目标的FP优化。另一方面,由于在网络训练期间已知子区域内的真实标注,我们将不会对不在子区域内的类别应用区域特定损失。换句话说,我们将只对我们的损失应用于存在于子区域内的类别,以提高计算效率(请注意,这不会影响梯度计算)。本研究的主要目的是引入区域特定和自适应误差惩罚概念用于损失计算,以展示这种方案对自动分割学习的承诺,但本研究的每个部分都采用了简单的设计,未来的研究可以对其进行改进。例如,在我们的计算中,预测体积被经验性地划分为16×16×16网格以生成每个子区域,而没有考虑不同目标器官特征的潜在差异。未来的一个方向是检查更智能地划分子区域的方法,以适应目标器官的大小。根据目标器官的形状,每个子区域也可以被赋予非立方体形状,这可以进一步探索我们的区域特定损失方案的潜力。最后,本研究使用线性关系根据FP和FN误差的比例微调惩罚参数。一种更好地将误差惩罚与区域预测结果相关的算法可能会进一步提高网络学习。
VI. 结论
本研究提出了一种新颖的深度学习自动分割的局部损失概念。我们的方法能够在训练过程中实现不同子区域的区域特定增强和每个子区域的自适应误差惩罚,从而促进了更有效的网络学习。在不同的医学图像数据集上的实验结果表明,我们的方法在不修改网络架构或需要额外数据准备的情况下显著提高了自动分割性能。因此,所提出的自适应区域特定损失为改善深度学习决策提供了一种有用的方法。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:误差,分割,Dice,TPAMI,损失,2024,区域,图像,特定 From: https://www.cnblogs.com/wxkang/p/18365612