设置每帧时间预算
帧率(fps)并不是衡量游戏稳定体验的理想指标。考虑以下情况:在运行时的前0.75s内渲染了59帧。然后接下来的1帧需要0.25s才能渲染完毕。虽然是60fps,但实际上会让玩家感觉卡顿。
这是需要设置帧时间预算的重要原因之一。这为您提供了一个目标,在对游戏进行分析和优化时可以朝着这个目标努力,最终创造更流畅、更稳定的游戏体验。
基于目标fps,每帧都将有一个时间预算。一个目标30fps的应用程序每帧时间预算不应超过33.33ms(1000ms/30fps);同理,目标60fps分配给每帧的时间预算为16.66ms。
在非交互式情况(例如显示UI菜单或场景加载)中,可以超过这个时间预算,但在游戏玩法过程中不行。即使只有一帧的时间超过了预算,也会导致卡顿。
在VR游戏中,始终保持高帧率非常重要,这样才能避免给玩家造成不适。
FPS:具有欺骗性的指标
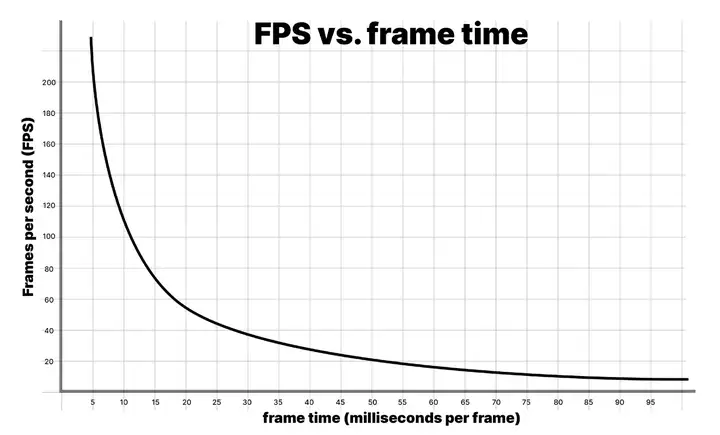
游戏玩家常用的衡量性能的方法是帧率(fps)。然而建议改用帧时间。请看下面这幅以fps和帧时间为变量的图表。
 fps vs. frame time
fps vs. frame time
考虑以下数字:
1000ms/900帧=每帧1.111ms
1000ms/450帧=每帧2.222ms
1000ms/60帧=每帧16.666ms
1000ms/56.25帧=每帧17.777ms
如果应用程序以900fps运行,这意味着每帧的帧时间为1.111ms。在450fps时,每帧的帧时间为2.222ms。这表示,即使帧速率下降了一半,每帧的差别也仅为1.111ms。
如果比较60fps和56.25fps之间的差异,那么每帧的帧时间分别为16.666ms和17.777ms。同样这也表示每帧多了1.111ms的时间,但在这里,帧速率下降在百分比上感觉要小得多。
这就是为什么开发人员使用平均帧时间来衡量游戏速度,而不是使用fps。别担心fps,除非帧率掉到了目标帧率之下。
移动端挑战:发热管理和电池续航
发热管理是移动端开发的重要优化方向之一。如果CPU或GPU由于低效的代码而一直保持满负荷,会产生芯片发热问题。为了避免芯片受损,操作系统将降低设备的时钟速度以降温,会导致帧率卡顿和用户体验下降。同时移动设备发热也会影响电池寿命。
高帧率和增加代码执行(或DRAM访问操作)会导致更大的电量消耗和发热。糟糕的性能还可能直接排除了低端设备,这可能会导致错失市场机会。
在解决发热问题时,要考虑到全局预算来解决问题。通过使用早期分析技术来优化游戏,为目标硬件配置项目设置,以应对发热和电池问题。
调整移动设备的帧时间预算
为了延长游戏可玩时长,并解决发热问题,通常建议每帧保留约35%的空闲时间。这给移动芯片提供了降温时间,并有助于防止过度耗电。设定目标帧时间为33.33ms(30fps),设备的帧时间预算将约为22ms。
公式如下:(1000ms/30)* 0.65 = 21.66ms
要达到60fps,使用上面的公式得出(1000ms/60)* 0.65 = 10.83ms。这在许多移动设备上很难实现,并且会使耗电速度2倍于30fps时。因此,多数移动游戏的目标帧率选择30fps而不是60fps。使用Application.targetFrameRate来设置帧率。
在性能分析时,移动芯片的频率缩放可能会影响识别帧空闲时间。在优化之前和优化之后,使用自定义工具(如FTrace或Perfetto),来监测移动芯片的频率、空闲时间和频率调节。
只要保持在目标帧时间预算内(30 fps为33.33ms),并且帧率和设备温度都很稳定,那么就没什么问题。
 使用FTrace或Perfetto等工具监视CPU频率和空闲状态,以帮助识别帧预算优化的结果
使用FTrace或Perfetto等工具监视CPU频率和空闲状态,以帮助识别帧预算优化的结果
在移动设备上,每帧分配空闲时间的另一个原因是考虑到现实中的温度变化。在炎热的天气里,移动设备的发热和散热问题会加重,将会导致游戏性能下降。留出一定比例的帧预算将有助于避免这些情况。
减少内存访问操作
在移动设备上,DRAM访问是一种耗能操作。optimization advice for graphics content on mobile devices指出,LPDDR4内存访问成本约为每字节100皮焦耳。
通过以下方式减少内存访问:
- 降低帧率
- 在允许的情况下降低显示分辨率
- 使用顶点数量较少和属性精度较低的网格
- 使用纹理压缩和多级纹理映射技术
当需要专注于Arm或Arm Mali设备时,Arm Mobile Studio(特别是Streamline Performance Analyzer)等工具,可用于识别内存带宽问题。这些工具针对每个Arm GPU代进行了列出和解释,如Mali-G78。请注意,Mobile Studio GPU分析依赖Arm Mali。
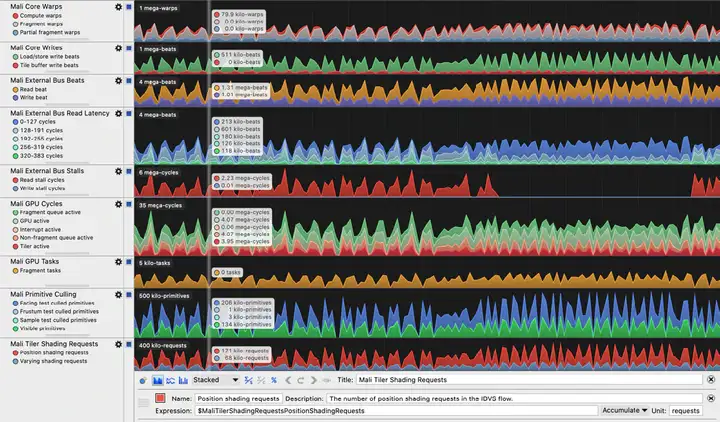 Arm的Streamline Performance Analyzer包含大量性能计数信息,可以在目标Arm硬件上进行实时分析时捕获该信息。有助于识别由overdraw引起的内存带宽饱和等性能问题。
Arm的Streamline Performance Analyzer包含大量性能计数信息,可以在目标Arm硬件上进行实时分析时捕获该信息。有助于识别由overdraw引起的内存带宽饱和等性能问题。
为基准测试建立硬件分级
在不同的平台下,还需要为设备做档位分级,并分别确定一个最低规格设备,并做针对性性能分析和优化。 例如,在移动平台下支持三个档位,基于目标硬件做品质控制(启用或关闭一些特性)。然后针对各级别中的最低规格设备进行优化。
从高到低级别的性能分析
在性能分析时(禁用Deep Profiling),使用自顶向下的方法收集数据并记录哪些情况会导致核心循环中出现不必要的托管分配或太多的CPU时间。
首先需要收集GC.Alloc标记的调用堆栈。
如果报告的调用堆栈详情不足以跟踪分配源,那么启用Deep Profiling进行第二次性能分析,以查找分配源。
早期性能分析
在项目早期阶段开始性能分析可以获得最佳的优化效果。在项目早期,定期进行性能分析,以便您和团队了解项目的性能水平。如果性能出现急剧下降,就能够轻松地发现并解决问题。在目标设备上运行游戏,同时利用平台特定的工具进行性能分析,以获得最准确的分析结果。
找出瓶颈
在一些平台上,很容易确定您的应用程序是由CPU或GPU限制。例如,从Xcode运行iOS游戏时,帧率面板显示了一个柱状图,其中包括CPU和GPU的总时间,可以看到对比。注意,CPU时间包括等待VSync(移动设备上始终是启用的)的时间。
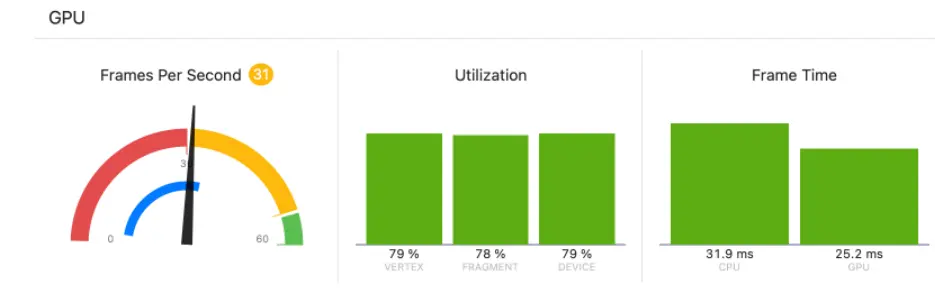 Xcode fps视图,显示了游戏运行时,CPU和GPU都运行在33.3ms内。
Xcode fps视图,显示了游戏运行时,CPU和GPU都运行在33.3ms内。
什么是VSync?
VSync将应用程序的帧率与显示器的刷新速率同步。这意味着,如果您有一个60Hz的显示器,并且游戏的帧预算在16.66ms内,则它会强制以60fps运行,而不允许更快。将帧率与显示器的刷新速率同步,可以减轻GPU的负担并解决屏幕撕裂等视觉图像瑕疵。在Unity中,通过Quality settings 可以设置VSync Count (Edit > Project Settings > Quality)。
Unity Profiler提供了足够的信息来定位性能瓶颈。下面的流程图说明了初始的分析过程,后面的部分提供了每个步骤的详细信息。
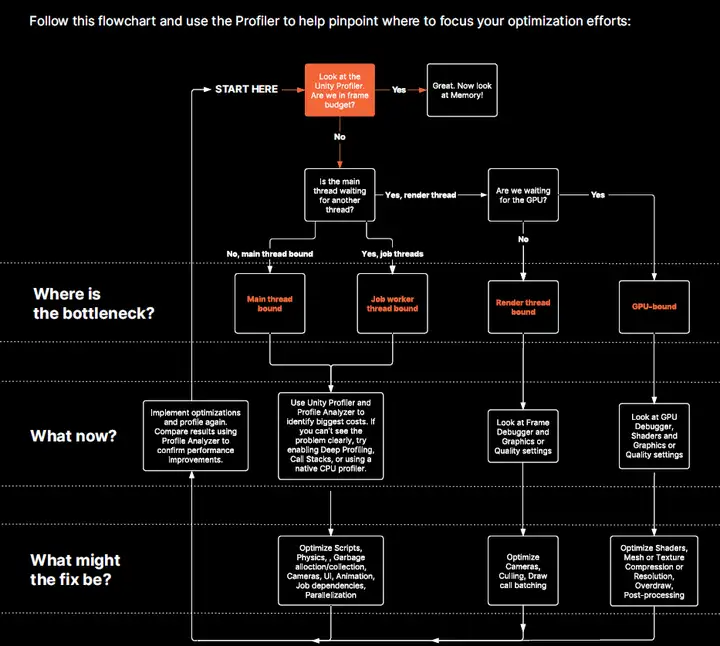
为了全面了解所有CPU活动,包括等待GPU时的情况,可以使用Profiler CPU usage模块中的timeline视图。熟悉常见的Profiler marker以帮助正确理解捕获结果。一些Profiler marker可能因目标平台而异,因此花时间在每个目标平台上浏览捕获结果,了解“正常”捕获结果的特征。
项目的性能受限于芯片或线程中最耗时的部分。优化工作也应该集中在这些部分。假设游戏的目标帧时间预算为33.33ms,并启用了VSync:
- 如果CPU帧时间(不包括VSync)为25ms,GPU时间为20ms,那就没有问题了!虽然受限于CPU,但时间在预算内,优化也不会再提高帧率(除非将CPU和GPU都降到16.66ms以下,并提高到60 fps)。
- 如果CPU帧时间为40ms,GPU为20ms,这时受限于CPU,并需要优化CPU性能。优化GPU性能没有任何帮助,可以将一些CPU工作转移到GPU上,例如使用计算着色器而不是C#代码,以平衡出其差异。
- 如果CPU帧时间为20ms,GPU为40ms,这时受限于GPU,需要优化GPU工作。
- 如果CPU和GPU都达到了40ms,那么受限于两者,需要将它们都优化到33.33ms以下才能达到30 fps。
是否在帧预算内?
在开发中定期进行分析和优化,以确保CPU线程和整体GPU帧时间都在帧预算内。
下图是一款移动游戏的分析捕获图像,该游戏在高配手机上达到60 fps,在中/低配手机上达到30 fps。
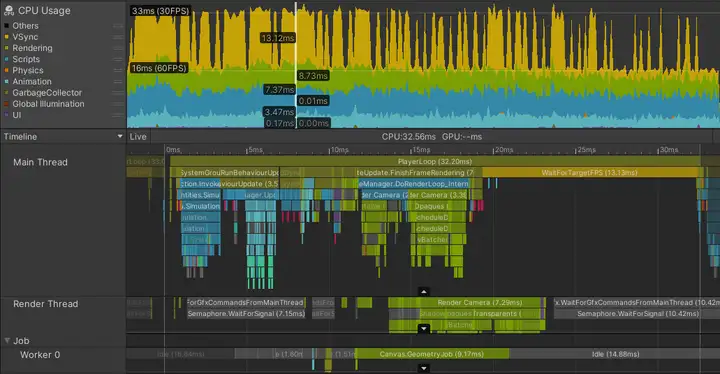 该游戏在不超过22毫秒的帧预算内,以30 fps流畅运行且不会过热。直到VSync,主线程的WaitForTargetfps会填充主线程时间,而渲染线程和工作线程中还有灰色的空闲时间。同时,可以通过查看Gfx.Present帧结束时间来观察VBlank间隔。
该游戏在不超过22毫秒的帧预算内,以30 fps流畅运行且不会过热。直到VSync,主线程的WaitForTargetfps会填充主线程时间,而渲染线程和工作线程中还有灰色的空闲时间。同时,可以通过查看Gfx.Present帧结束时间来观察VBlank间隔。
注意到当前帧的近一半时间都由黄色的WaitForTargetfps Profiler标记占据。应用程序设置Application.targetFrameRate为30 fps,并且启用了VSync。主线程上的实际处理工作在约19ms,其余时间花在等待,然后开始下一帧。
标记在不同平台或禁用VSync时可能不同。重要的是检查主线程是否控制在帧预算时间内运行,或者显示有某种标记,代表主线程正在处于等待VSync或者其他线程的空闲时间内。
空闲时间由灰色或黄色的标记表示。上图中显示,渲染线程正处于Gfx.WaitForGfxCommandsFromMainThread的空闲状态,这表明它已经完成了一帧中对GPU的draw call发送,并正在等待下一帧中来自CPU的draw call请求。同样,虽然Job Worker 0线程在Canvas.GeometryJob中花费了一些时间,但大部分时间是空闲的。这些代表应用程序在帧预算内流畅运行。
CPU受限
如果CPU超出了帧预算时间,下一步是调查哪个线程最繁忙。分析找出瓶颈作为优化的目标;如果依靠猜测,可能会优化游戏中非瓶颈的部分,导致整体性能几乎没有改善。有些“优化”甚至反而会降低游戏的整体性能。
CPU成为瓶颈的情况相当少。现代CPU具有许多不同的核心,能够独立并行地执行任务。不同的线程运行在CPU核心上。Unity使用不同的线程以达到不同目标。查找性能问题的常见线程有:
- 主线程:默认情况下,这是所有游戏逻辑和脚本执行其工作的地方,在像物理、动画、用户界面和渲染等特性和系统中花费大部分时间。
- 渲染线程:在渲染过程中,主线程检查场景并执行相机剪裁、深度排序和draw call batching,生成需要渲染的对象列表。这个列表传递给渲染线程,后者将其从Unity内部的平台无关表示转换成特定的图形API调用,以指示GPU在特定平台上执行工作。
- Job worker线程:可以使用C# job系统安排某些工作在job worker线程上运行,以分担主线程的工作量。Unity的某些系统和特性也使用job系统,如物理、动画和渲染等。
主线程
下图显示了一个主线程受限的情况。
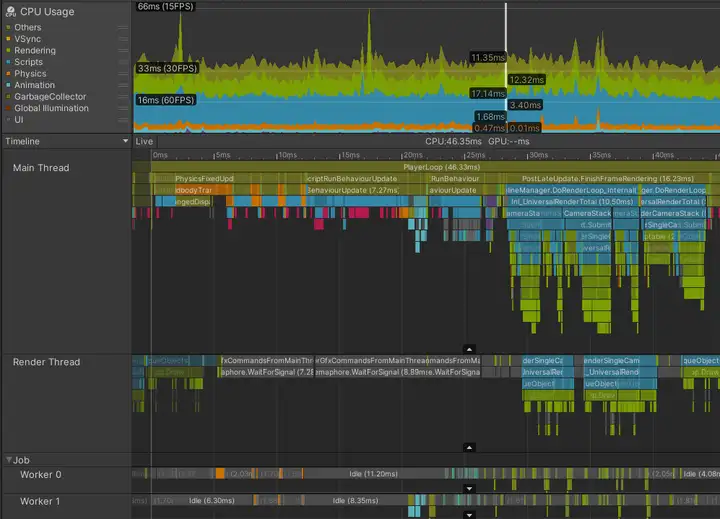 主线程受限的项目中捕获的结果
主线程受限的项目中捕获的结果
即使考虑到帧末段的少量分析器开销,主线程也占用了超过45ms,这意味着帧率不到22fps。这里没有显示主线程等待VSync的空闲时间的标记;主线程整个帧期间都处于工作状态。
下一步是确定当前帧中占用时间最长的部分,并了解原因。当前帧中,PostLateUpdate.FinishFrameRendering占用了16.23ms,超过整个帧率预算时间。检查发现,有5个名为Inl_RenderCameraStack标记的实例,表明有5个处于活动状态的相机在渲染场景。Unity中每个相机都会调用整个渲染管道,包括剔除、排序和批量处理,因此当下最优先的任务是减少活动相机的数量,最好只保留一个活动相机。
BehaviourUpdate标记(表示所有MonoBehaviour Update()),占用了7.27ms,同时timeline中品红色部分表示脚本中分配托管堆内存的位置。切换到Hierarchy视图,在搜索栏中输入GC.Alloc进行过滤,可以看到在当前帧中分配内存占用约0.33ms。但是,这不是衡量内存分配对CPU性能影响的准确方法。
GC.Alloc标记实际上不是通过测量开始到结束点的时间来计时的。为了降低开销,它们只记录开始的时间戳加上分配的大小。为确保它们可见,Profiler会为它们分配一小部分时间。实际上分配可能需要更长的时间,特别是需要从系统申请新的内存时。为了清晰地看到影响,可以在对应的代码周围打上Profiler标记,在深度分析中,timeline视图中品红色GC.Alloc采样之间的间隔,指示了它们可能的消耗时长。
此外,分配新内存可能对性能产生负面影响,这些影响更难以直接测量:
- 从系统请求新内存可能会影响移动设备上的电源,导致系统降低CPU或GPU的运行速度。
- 新内存可能需要加载到CPU的L1缓存中,从而推出现有的缓存行。
- 当托管内存中的可用空间不足时,可能直接或延迟触发GC。
在当前帧开始时,4个 Physics.FixedUpdate 实例占用了 4.57ms。随后,LateBehaviourUpdate标记(MonoBehaviour.LateUpdate())占用了 4 ms, Animator 大约占用 1 ms。
为了项目达到预期帧率,需要调查主线程的所有问题并找到适当的优化方法。通过优化时间占比最长的部分来实现最大的性能提升。
以下是主线程受限时,查找问题容易获益的地方:
- 物理
- MonoBehaviour 脚本更新
- 垃圾分配和回收
- 相机剔除和渲染
- draw call batching问题
- UI 更新、布局和重建
- 动画
针对具体问题,使用其他工具:
- 对于 MonoBehaivour 脚本,可以在代码中添加 Profiler 标记或启用深度分析。
- 对于分配托管内存的脚本,启用 Allocation Call Stacks 定位分配来源。也可以启用深度分析或使用 Project Auditor。
- 使用 Frame Debugger 来调查draw call batching。
渲染线程
以下显示了渲染线程受限的情况。其目标帧预算为 33.33 ms。
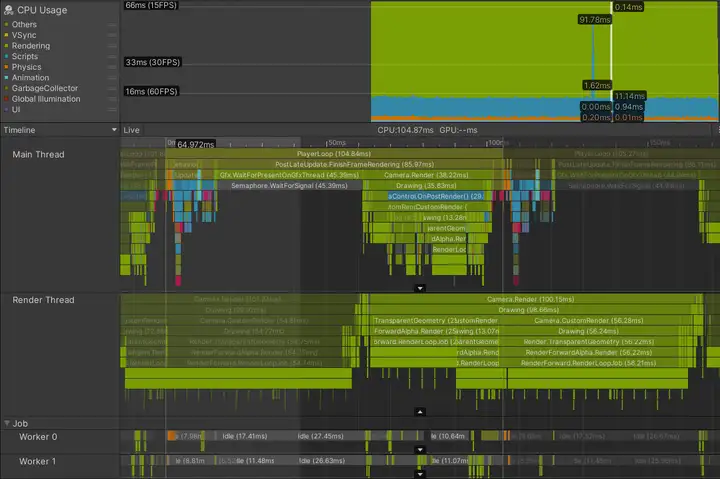
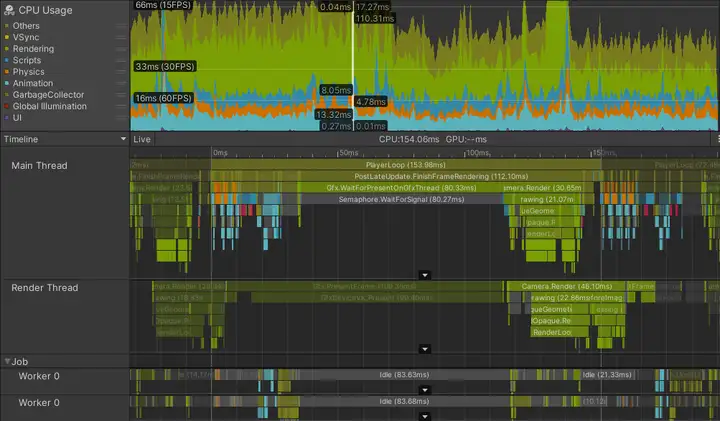
profiler显示,在当前帧开始渲染之前,主线程在等待渲染线程(Gfx.WaitForPresentOnGfxThread 标记)。渲染线程仍在提交上一帧的draw call命令,并且还没有准备好接受主线程的新draw calls;渲染线程中Camera.Render 正在耗时。
可以通过标记的颜色区分当前帧标记和其他帧标记,后者颜色更暗。还可以看到,一旦主线程能够继续发出draw call给渲染线程,渲染线程需要超过 100 ms的时间来处理当前帧,这也给下一帧制造了瓶颈。
进一步的调查发现,该游戏有一个复杂的渲染设置,涉及9个相机和许多由替换着色器引起的额外pass。使用前向渲染路径渲染超过 130 个点光源,每个光源可以增加多个附加的透明draw call。这些问题合在一起,每帧会产生超过 3000 次draw call。
以下是常见的导致渲染线程受限的原因,需要进一步排查:
- draw call batching问题,特别是在旧的图形 API上(如 OpenGL 或 DirectX 11)。
- 相机过多。除非制作的是分屏多人游戏,一般只需要一个活动相机。
- 剔除问题,导致渲染物体过多。调查相机的截锥体大小和剔除层掩码。考虑启用遮挡剔除,甚至创建自定义遮挡剔除系统。查看场景中有多少投射阴影的对象 - 阴影剔除与“常规”剔除是在不同的通道中进行的。
Rendering profiler显示每帧draw call batches和 SetPass call数量的概述。查看draw call batches的最佳工具是 Frame Debugger。
GPU受限
如果主线程在Profiler标记(例如Gfx.WaitForPresentOnGfxThread)中花费大量时间,而渲染线程同时显示Gfx.PresentFrame或<GraphicsAPIName>.WaitForLastPresent等标记,则应用程序出现了GPU受限。
下图捕获自三星Galaxy S7(Vulkan)。尽管Gfx.PresentFrame中的一些时间可能与等待VSync有关,但此Profiler标记的长度表明大部分时间都在等待GPU完成上一帧的渲染。
在这个游戏中,特定的游戏事件触发了使用一个着色器,将GPU渲染的draw call增加了三倍。当分析GPU性能时,需要调查以下常见问题:
- 全屏后处理效果,包括环境光遮蔽和泛光等
- 片元着色器:分支逻辑;使用完全浮点精度而不是半精度;过多地使用影响GPU波前占用率的寄存器
- 透明渲染队列中的overdraw:低效的UI、粒子系统或后处理效果
- 过高的屏幕分辨率,例如4K显示器或移动设备的视网膜屏
- 密集的网格,缺乏使用LOD
- 缓存未命中和浪费GPU内存带宽:由未压缩的纹理或未启用mipmap的高分辨率纹理引起
- 几何或镶嵌着色器,如果启用动态阴影,则可能每帧运行多次
如果怀疑GPU受限,可以使用Frame Debugger快速了解发送到GPU的绘制调用批次。但是此工具不能提供任何特定的GPU时间信息。
标签:渲染,时间,Unity,线程,ms,GPU,CPU From: https://www.cnblogs.com/flamesky/p/18168065