Bid-Ask 数据到 OHLC
原文:
www.backtrader.com/blog/posts/2016-04-14-bidask-data-to-ohlc/bidask-data-to-ohlc/
最近,backtrader 通过实现线覆盖来执行了从 ohlcland 的逃逸,这允许重新定义整个层次结构,例如拥有仅包含 bid、ask 和 datetime 行的数据源。
(这里是原始 Escape from OHLC Land)
这引发了如何可视化此类数据的问题,这在OHLC格式中最有效地完成(无论是bar还是candlestick)
所需步骤:
-
定义一个可以读取给定
bid/ask格式的数据源加载器 -
决定将值分配给哪些字段,即:
open、high、low和close(也许还有volume) -
决定一个重新采样方案
源数据(10 行 bid-ask 数据):
Date,Time,Symbol,Status,Bid,Ask,Bid Vol,Ask Vol
01/03/16,23:43:11,EUR/JPY,D,,130.520,,1000000
01/03/16,23:43:27,EUR/JPY,D,,130.520,,2000000
01/03/16,23:49:19,EUR/JPY,D,,130.510,,500000
01/03/16,23:49:22,EUR/JPY,D,,130.530,,1500000
01/03/16,23:49:25,EUR/JPY,D,,130.540,,750000
01/03/16,23:49:27,EUR/JPY,D,,130.550,,900000
01/03/16,23:51:25,EUR/JPY,D,,130.500,,1200000
01/03/16,23:52:27,EUR/JPY,D,,130.495,,1100000
01/03/16,23:53:25,EUR/JPY,D,,130.480,,600000
01/03/16,23:54:27,EUR/JPY,D,,130.470,,900000
之后:
-
阅读数据不会是一个主要问题,因为最终结果必须是 OHLC,这是内置数据源在解析后提供的内容。因为这是另一种csv的变体。我们甚至可以重用现有的
GenericCSVData数据源。感谢上帝,它是通用的 -
只有单个价格元素和单个成交量元素的情况下,价格分配是清晰的:将价格分配给四个价格元素,将成交量分配给成交量
-
当涉及到重新采样时,与上采样到更大时间框架不同,关键将是条数,即:compression
而内置的重采样器已经可以提供相同的timeframe但是压缩了。
使用GenericCSVData将数据转换为 OHLC 格式:
data = btfeeds.GenericCSVData(
dataname=args.data,
dtformat='%d/%m/%y',
# tmformat='%H%M%S', # already the default value
# datetime=0, # position at default
time=1, # position of time
open=5, # position of open
high=5,
low=5,
close=5,
volume=7,
openinterest=-1, # -1 for not present
timeframe=bt.TimeFrame.Ticks)
一些参数甚至不需要更改,即:
-
tmformat:因为数据源中的时间已经与默认格式匹配 -
datetime:因为日期在 csv 流中的第一个位置
其他:
-
time=1:指示时间不在单个字段中与date一起,并指定其位置 -
open=5(对于high、low、close也是一样):流中哪个字段将用作价格的源 -
volume=7:与上述相同 -
openinterest=-1:负值表示此字段不存在
一旦数据准备就绪,就只需对其进行重新采样:
cerebro.resampledata(data,
timeframe=bt.TimeFrame.Ticks,
compression=args.compression)
我们提供相同的timeframe,数据携带的是TimeFrame.Ticks,以确保数据不被上采样。而compression是从命令行中传递的参数,因此:compression=args.compression
一个示例执行:
$ ./bidask-to-ohlc.py --compression 2
2016-03-01 23:43:27,130.52,130.52,130.52,130.52,3000000.0
2016-03-01 23:49:22,130.51,130.53,130.53,130.53,2000000.0
2016-03-01 23:49:27,130.54,130.55,130.55,130.55,1650000.0
2016-03-01 23:52:27,130.5,130.5,130.5,130.495,2300000.0
2016-03-01 23:54:27,130.48,130.48,130.48,130.47,1500000.0
不出所料,我们已经从Bid/Ask格式转换为OHLC格式,并且由于分配给压缩的2,数据已经从10行减少到5行。
也不应该让人惊讶,backtrader不能创造奇迹,如果compression因子不是原始行数的除数,它将传递rows / compression + 1行新行:
$ ./bidask-to-ohlc.py --compression 3
2016-03-01 23:49:19,130.52,130.52,130.52,130.51,3500000.0
2016-03-01 23:49:27,130.53,130.55,130.55,130.55,3150000.0
2016-03-01 23:53:25,130.5,130.5,130.5,130.48,2900000.0
2016-03-01 23:54:27,130.47,130.47,130.47,130.47,900000.0
在这种情况下,10 / 3 = 3.33333,这就是为什么会传递4行的原因。
当然,现在手中有了 OHLC 数据,结果可以绘制出来。由于数据量少且数据变化小以及 matplotlib 内部处理此情况的方式,图表看起来并不怎么好看。
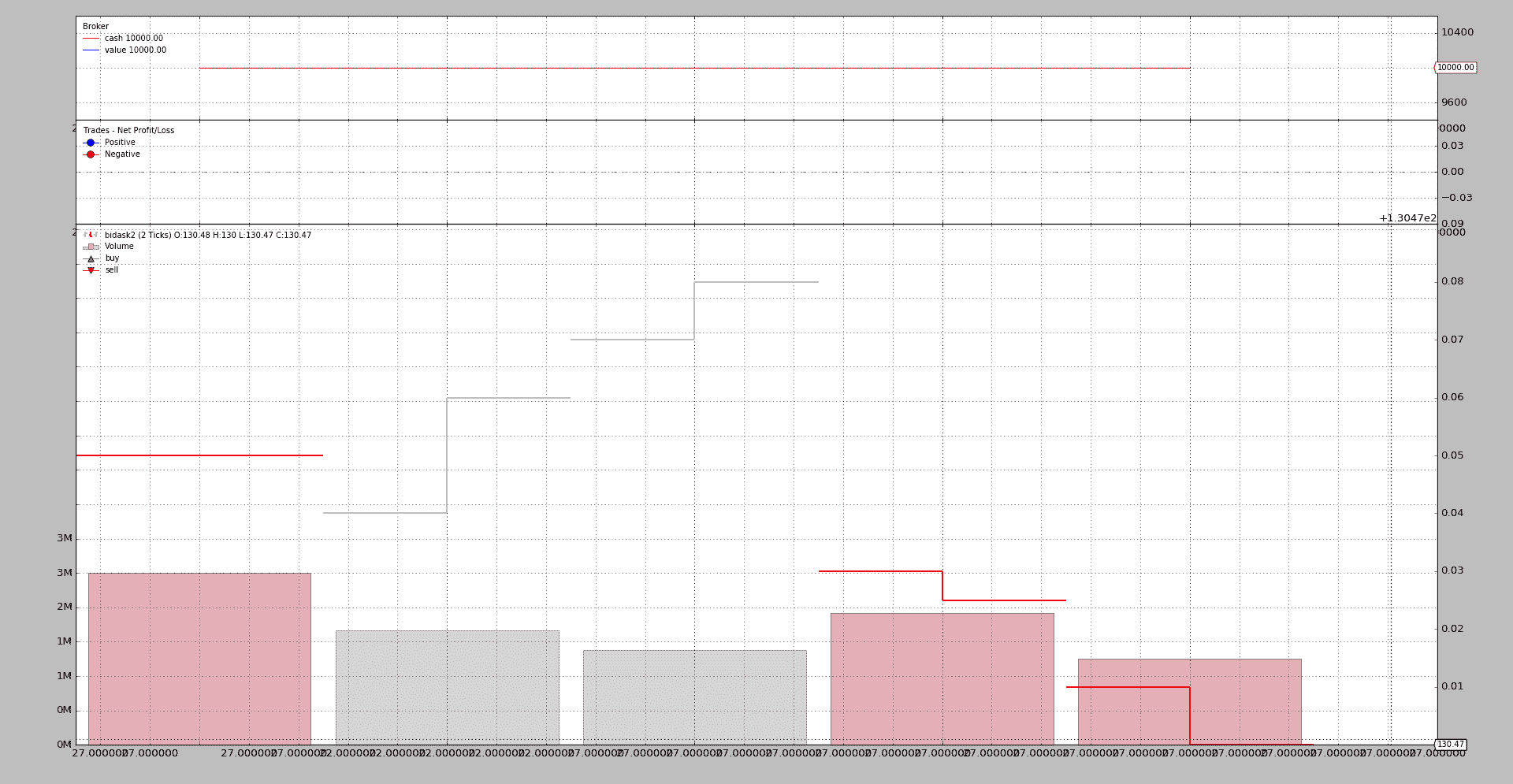
样例代码(包含在 backtrader 的源代码中)
from __future__ import (absolute_import, division, print_function,)
# unicode_literals)
import argparse
import datetime
import backtrader as bt
import backtrader.feeds as btfeeds
class St(bt.Strategy):
def next(self):
print(','.join(str(x) for x in [
self.data.datetime.datetime(),
self.data.open[0], self.data.high[0],
self.data.high[0], self.data.close[0],
self.data.volume[0]]))
def runstrat():
args = parse_args()
cerebro = bt.Cerebro()
data = btfeeds.GenericCSVData(
dataname=args.data,
dtformat='%d/%m/%y',
# tmformat='%H%M%S', # already the default value
# datetime=0, # position at default
time=1, # position of time
open=5, # position of open
high=5,
low=5,
close=5,
volume=7,
openinterest=-1, # -1 for not present
timeframe=bt.TimeFrame.Ticks)
cerebro.resampledata(data,
timeframe=bt.TimeFrame.Ticks,
compression=args.compression)
cerebro.addstrategy(St)
cerebro.run()
if args.plot:
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='BidAsk to OHLC')
parser.add_argument('--data', required=False,
default='../../datas/bidask2.csv',
help='Data file to be read in')
parser.add_argument('--compression', required=False, default=2, type=int,
help='How much to compress the bars')
parser.add_argument('--plot', required=False, action='store_true',
help='Plot the vars')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
逃离 OHLC 之地
原文:
www.backtrader.com/blog/posts/2016-03-08-escape-from-ohlc-land/escape-from-ohlc-land/
在 backtrader 的构思和开发过程中应用的一个关键概念是灵活性。Python 的元编程和内省能力是保持许多灵活性的基础,同时仍能够交付成果。
一篇旧文章展示了扩展概念。
基础知识:
from backtrader.feeds import GenericCSVData
class GenericCSV_PE(GenericCSVData):
lines = ('pe',) # Add 'pe' to already defined lines
完成。backtrader在后台定义了最常见的线:OHLC。
如果我们深入研究GenericCSV_PE的最终方面,继承加上新定义的线的总和将产生以下线:
('close', 'open', 'high', 'low', 'volume', 'openinterest', 'datetime', 'pe',)
这可以随时通过getlinealiases方法检查(适用于DataFeeds、Indicators、Strategies和Observers)
机制是灵活的,通过对内部进行一些探索,你实际上可以得到任何东西,但已经证明这还不够。
Ticket #60询问是否支持高频数据,即:Bid/Ask 数据。这意味着以OHLC形式预定义的lines层次结构不够用。Bid和Ask价格、成交量和交易数量可以适应现有的OHLC字段,但这不会感觉自然。如果只关注Bid和Ask价格,会有太多未触及的字段。
这需要一个解决方案,已经在发布 1.2.1.88中实施。这个想法可以总结为:
- 现在不仅可以扩展现有的层次结构,还可以用新的层次结构替换原有的层次结构
只有一个约束条件:
-
必须存在一个
datetime字段(希望其中包含有意义的datetime信息)这是因为
backtrader需要一些用于同步的东西(多个数据源、多个时间框架、重新采样、重播),就像阿基米德需要杠杆一样。
这是它的工作原理:
from backtrader.feeds import GenericCSVData
class GenericCSV_BidAsk(GenericCSVData):
linesoverride = True
lines = ('bid', 'ask', 'datetime') # Replace hierarchy with this one
完成。
好的,不完全是因为我们正在查看从csv源加载的行。层次结构实际上已经被替换为bid, ask datetime定义,这要归功于linesoverride=True设置。
原始的GenericCSVData类解析一个csv文件,并需要提示哪里是对应于lines的fields。原始定义如下:
class GenericCSVData(feed.CSVDataBase):
params = (
('nullvalue', float('NaN')),
('dtformat', '%Y-%m-%d %H:%M:%S'),
('tmformat', '%H:%M:%S'),
('datetime', 0),
('time', -1), # -1 means not present
('open', 1),
('high', 2),
('low', 3),
('close', 4),
('volume', 5),
('openinterest', 6),
)
新的重新定义层次结构类可以轻松完成:
from backtrader.feeds import GenericCSVData
class GenericCSV_BidAsk(GenericCSVData):
linesoverride = True
lines = ('bid', 'ask', 'datetime') # Replace hierarchy with this one
params = (('bid', 1), ('ask', 2))
表明Bid价格是 csv 流中的字段#1,Ask价格是字段#2。我们保留了基类中的datetime #0 定义不变。
为此制作一个小数据文件有所帮助:
TIMESTAMP,BID,ASK
02/03/2010 16:53:50,0.5346,0.5347
02/03/2010 16:53:51,0.5343,0.5347
02/03/2010 16:53:52,0.5543,0.5545
02/03/2010 16:53:53,0.5342,0.5344
02/03/2010 16:53:54,0.5245,0.5464
02/03/2010 16:53:54,0.5460,0.5470
02/03/2010 16:53:56,0.5824,0.5826
02/03/2010 16:53:57,0.5371,0.5374
02/03/2010 16:53:58,0.5793,0.5794
02/03/2010 16:53:59,0.5684,0.5688
将一个小测试脚本添加到等式中(对于那些直接转到源代码中的示例的人来说,增加一些内容)(见最后的完整代码):
$ ./bidask.py
输出说明一切:
1: 2010-02-03T16:53:50 - Bid 0.5346 - 0.5347 Ask
2: 2010-02-03T16:53:51 - Bid 0.5343 - 0.5347 Ask
3: 2010-02-03T16:53:52 - Bid 0.5543 - 0.5545 Ask
4: 2010-02-03T16:53:53 - Bid 0.5342 - 0.5344 Ask
5: 2010-02-03T16:53:54 - Bid 0.5245 - 0.5464 Ask
6: 2010-02-03T16:53:54 - Bid 0.5460 - 0.5470 Ask
7: 2010-02-03T16:53:56 - Bid 0.5824 - 0.5826 Ask
8: 2010-02-03T16:53:57 - Bid 0.5371 - 0.5374 Ask
9: 2010-02-03T16:53:58 - Bid 0.5793 - 0.5794 Ask
10: 2010-02-03T16:53:59 - Bid 0.5684 - 0.5688 Ask
瞧!Bid/Ask价格已经被正确读取、解析和解释,并且策略已能通过self.data访问数据源中的.bid和.ask行。
重新定义lines层次结构却带来一个广泛的问题,即已预定义的Indicators的用法。
-
例如:Stochastic是一种依赖于close、high和low价格来计算其输出的指标。
即使我们把Bid视为close(因为它是第一个),仅有另一个price元素(Ask),而不是另外两个。而概念上,Ask与high和low没有任何关系。
有可能,与这些字段一起工作并在高频交易领域操作(或研究)的人并不关心Stochastic作为首选指标
-
其他指标如移动平均完全正常。它们对字段的含义或暗示不做任何假设,且乐意接受任何东西。因此,可以这样做:
mysma = backtrader.indicators.SMA(self.data.bid, period=5)`并且将提供最后 5 个bid价格的移动平均线
测试脚本已经支持添加SMA。让我们执行:
$ ./bidask.py --sma --period=3
输出:
3: 2010-02-03T16:53:52 - Bid 0.5543 - 0.5545 Ask - SMA: 0.5411
4: 2010-02-03T16:53:53 - Bid 0.5342 - 0.5344 Ask - SMA: 0.5409
5: 2010-02-03T16:53:54 - Bid 0.5245 - 0.5464 Ask - SMA: 0.5377
6: 2010-02-03T16:53:54 - Bid 0.5460 - 0.5470 Ask - SMA: 0.5349
7: 2010-02-03T16:53:56 - Bid 0.5824 - 0.5826 Ask - SMA: 0.5510
8: 2010-02-03T16:53:57 - Bid 0.5371 - 0.5374 Ask - SMA: 0.5552
9: 2010-02-03T16:53:58 - Bid 0.5793 - 0.5794 Ask - SMA: 0.5663
10: 2010-02-03T16:53:59 - Bid 0.5684 - 0.5688 Ask - SMA: 0.5616
注意
绘图仍然依赖于open、high、low、close和volume存在于数据源中。
一些情况可以通过简单地用Line on Close绘图并仅取对象中的第 1 个定义行来直接覆盖。但是必须开发一个合理的模型。针对即将推出的backtrader版本
测试脚本用法:
$ ./bidask.py --help
usage: bidask.py [-h] [--data DATA] [--dtformat DTFORMAT] [--sma]
[--period PERIOD]
Bid/Ask Line Hierarchy
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system (default:
../../datas/bidask.csv)
--dtformat DTFORMAT, -dt DTFORMAT
Format of datetime in input (default: %m/%d/%Y
%H:%M:%S)
--sma, -s Add an SMA to the mix (default: False)
--period PERIOD, -p PERIOD
Period for the sma (default: 5)
而测试脚本本身(包含在backtrader源代码中)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class BidAskCSV(btfeeds.GenericCSVData):
linesoverride = True # discard usual OHLC structure
# datetime must be present and last
lines = ('bid', 'ask', 'datetime')
# datetime (always 1st) and then the desired order for
params = (
# (datetime, 0), # inherited from parent class
('bid', 1), # default field pos 1
('ask', 2), # default field pos 2
)
class St(bt.Strategy):
params = (('sma', False), ('period', 3))
def __init__(self):
if self.p.sma:
self.sma = btind.SMA(self.data, period=self.p.period)
def next(self):
dtstr = self.data.datetime.datetime().isoformat()
txt = '%4d: %s - Bid %.4f - %.4f Ask' % (
(len(self), dtstr, self.data.bid[0], self.data.ask[0]))
if self.p.sma:
txt += ' - SMA: %.4f' % self.sma[0]
print(txt)
def parse_args():
parser = argparse.ArgumentParser(
description='Bid/Ask Line Hierarchy',
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument('--data', '-d', action='store',
required=False, default='../../datas/bidask.csv',
help='data to add to the system')
parser.add_argument('--dtformat', '-dt',
required=False, default='%m/%d/%Y %H:%M:%S',
help='Format of datetime in input')
parser.add_argument('--sma', '-s', action='store_true',
required=False,
help='Add an SMA to the mix')
parser.add_argument('--period', '-p', action='store',
required=False, default=5, type=int,
help='Period for the sma')
return parser.parse_args()
def runstrategy():
args = parse_args()
cerebro = bt.Cerebro() # Create a cerebro
data = BidAskCSV(dataname=args.data, dtformat=args.dtformat)
cerebro.adddata(data) # Add the 1st data to cerebro
# Add the strategy to cerebro
cerebro.addstrategy(St, sma=args.sma, period=args.period)
cerebro.run()
if __name__ == '__main__':
runstrategy()
发布版本 1.2.1.88
原文:
www.backtrader.com/blog/posts/2016-03-07-release-1.2.1.88/release-1.2.1.88/
将次版本号从 1 更改为 2 花费了一些时间,但旧的 DataResampler 和 DataReplayer 的弃用导致了这一变化。
readthedocs上的文档
文档已更新,只引用了现代化的resampling和replaying方式。操作如下:
...
data = backtrader.feeds.BacktraderCSVData(dataname='mydata.csv') # daily bars
cerebro.resampledata(data, timeframe=backtrader.TimeFrame.Weeks) # to weeks
...
对于replaying只需将resampledata更改为replaydata。还有其他方法可以做到,但这是最直接的接口,可能是唯一会被任何人使用的接口。
根据Ticket #60,很明显扩展机制允许向数据源(实际上是任何基于lines的对象)添加额外行不足以支持票号中建议的内容。
因此,实现了一个额外的parameter到lines对象,允许完全重新定义行层次结构(逃离 OHLC 领域可能是一个合适的电影标题)
已经添加了一个名为data-bid-ask的示例到数据源中。从这个示例中:
class BidAskCSV(btfeeds.GenericCSVData):
linesoverride = True # discard usual OHLC structure
# datetime must be present and last
lines = ('bid', 'ask', 'datetime')
# datetime (always 1st) and then the desired order for
params = (
('dtformat', '%m/%d/%Y %H:%M:%S'),
('datetime', 0), # field pos 0
('bid', 1), # default field pos 1
('ask', 2), # defult field pos 2
)
通过指定linesoverride,常规的lines继承机制被绕过,对象中定义的行将取代任何先前的行。
此版本可从pypi获取,并可通过常规方式安装:
pip install backtrader
或者如果更新:
pip install backtrader --upgrade
2015
数据过滤器
原文:
www.backtrader.com/blog/posts/2015-11-21-data-filters/data-filling-filtering/
一段时间前,票证#23 让我考虑在该票证的上下文中进行的讨论的潜在改进。
在票证中,我添加了一个DataFilter类,但这太过复杂。实际上,这让人想起了内置了相同功能的DataResampler和DataReplayer中构建的复杂性。
因此,自几个版本以来,backtrader支持向数据源添加一个filter(如果愿意,可以称之为processor)。重新采样和重播使用该功能进行了内部重新实现,一切似乎变得不那么复杂(尽管仍然是)
过滤器在起作用
鉴于现有的数据源,您可以使用数据源的addfilter方法:
data = MyDataFeed(name=myname)
data.addfilter(filter, *args, **kwargs)
显然,filter必须符合给定的接口,即:
-
一个接受此签名的可调用对象:
callable(data, *args, **kwargs)`
或者
-
一个可以实例化和调用的类
- 在实例化期间,init方法必须支持以下签名:
def __init__(self, data, *args, **kwargs)`- 这个对象的call和 last 方法如下:
def __call__(self, data) def last(self, data)`
可调用/实例将被调用以处理数据源产生的每个数据。
对票证#23 的更好解决方案
那张票想要:
-
一个基于白天的相对成交量指标
-
白天数据可能丢失
-
预/后市场数据可能到达
实施几个过滤器可以缓解回测环境的情况。
过滤预/后市场数据
以下过滤器(已经在backtrader中可用)挺身而出:
class SessionFilter(with_metaclass(metabase.MetaParams, object)):
'''
This class can be applied to a data source as a filter and will filter out
intraday bars which fall outside of the regular session times (ie: pre/post
market data)
This is a "non-simple" filter and must manage the stack of the data (passed
during init and __call__)
It needs no "last" method because it has nothing to deliver
'''
def __init__(self, data):
pass
def __call__(self, data):
'''
Return Values:
- False: data stream was not touched
- True: data stream was manipulated (bar outside of session times and
- removed)
'''
if data.sessionstart <= data.datetime.tm(0) <= data.sessionend:
# Both ends of the comparison are in the session
return False # say the stream is untouched
# bar outside of the regular session times
data.backwards() # remove bar from data stack
return True # signal the data was manipulated
该过滤器使用数据中嵌入的会话开始/结束时间来过滤条形图
-
如果新数据的日期时间在会话时间内,则返回
False以指示数据未受影响 -
如果日期时间超出范围,则数据源将向后发送,有效地擦除最后生成的数据。并返回
True以指示数据流已被操作。
注意
调用data.backwards()可能/可能是低级的,过滤器应该具有处理数据流内部的 API
脚本末尾的示例代码可以在有或无过滤的情况下运行。第一次运行是 100%未经过滤且未指定会话时间:
$ ./data-filler.py --writer --wrcsv
查看第 1 天的开始和结束:
===============================================================================
Id,2006-01-02-volume-min-001,len,datetime,open,high,low,close,volume,openinterest,Strategy,len
1,2006-01-02-volume-min-001,1,2006-01-02 09:01:00,3602.0,3603.0,3597.0,3599.0,5699.0,0.0,Strategy,1
2,2006-01-02-volume-min-001,2,2006-01-02 09:02:00,3600.0,3601.0,3598.0,3599.0,894.0,0.0,Strategy,2
...
...
581,2006-01-02-volume-min-001,581,2006-01-02 19:59:00,3619.0,3619.0,3619.0,3619.0,1.0,0.0,Strategy,581
582,2006-01-02-volume-min-001,582,2006-01-02 20:00:00,3618.0,3618.0,3617.0,3618.0,242.0,0.0,Strategy,582
583,2006-01-02-volume-min-001,583,2006-01-02 20:01:00,3618.0,3618.0,3617.0,3617.0,15.0,0.0,Strategy,583
584,2006-01-02-volume-min-001,584,2006-01-02 20:04:00,3617.0,3617.0,3617.0,3617.0,107.0,0.0,Strategy,584
585,2006-01-02-volume-min-001,585,2006-01-03 09:01:00,3623.0,3625.0,3622.0,3624.0,4026.0,0.0,Strategy,585
...
2006 年 1 月 2 日从 09:01:00 到 20:04:00 进行会话运行。
现在使用SessionFilter运行,并告诉脚本使用 09:30 和 17:30 作为会话的开始/结束时间:
$ ./data-filler.py --writer --wrcsv --tstart 09:30 --tend 17:30 --filter
===============================================================================
Id,2006-01-02-volume-min-001,len,datetime,open,high,low,close,volume,openinterest,Strategy,len
1,2006-01-02-volume-min-001,1,2006-01-02 09:30:00,3604.0,3605.0,3603.0,3604.0,546.0,0.0,Strategy,1
2,2006-01-02-volume-min-001,2,2006-01-02 09:31:00,3604.0,3606.0,3604.0,3606.0,438.0,0.0,Strategy,2
...
...
445,2006-01-02-volume-min-001,445,2006-01-02 17:29:00,3621.0,3621.0,3620.0,3620.0,866.0,0.0,Strategy,445
446,2006-01-02-volume-min-001,446,2006-01-02 17:30:00,3620.0,3621.0,3619.0,3621.0,1670.0,0.0,Strategy,446
447,2006-01-02-volume-min-001,447,2006-01-03 09:30:00,3637.0,3638.0,3635.0,3636.0,1458.0,0.0,Strategy,447
...
数据输出现在从 09:30 开始,到 17:30 结束。已经过滤掉预/后市场数据。
填充缺失数据
对输出的深入检查显示如下:
...
61,2006-01-02-volume-min-001,61,2006-01-02 10:30:00,3613.0,3614.0,3613.0,3614.0,112.0,0.0,Strategy,61
62,2006-01-02-volume-min-001,62,2006-01-02 10:31:00,3614.0,3614.0,3614.0,3614.0,183.0,0.0,Strategy,62
63,2006-01-02-volume-min-001,63,2006-01-02 10:34:00,3614.0,3614.0,3614.0,3614.0,841.0,0.0,Strategy,63
64,2006-01-02-volume-min-001,64,2006-01-02 10:35:00,3614.0,3614.0,3614.0,3614.0,17.0,0.0,Strategy,64
...
缺少分钟 10:32 和 10:33 的数据。作为一年中的第 1 个交易日,可能根本没有进行交易。或者数据源可能未能捕获到这些数据。
为了解决票号 #23 的问题,并能够将给定分钟的成交量与前一天的同一分钟进行比较,我们将填补缺失的数据。
backtrader中已经存在一个SessionFiller,按预期填补了缺失的数据。代码很长,比过滤器的复杂性更多(请参阅末尾的完整实现),但让我们看看类/参数定义:
class SessionFiller(with_metaclass(metabase.MetaParams, object)):
'''
Bar Filler for a Data Source inside the declared session start/end times.
The fill bars are constructed using the declared Data Source ``timeframe``
and ``compression`` (used to calculate the intervening missing times)
Params:
- fill_price (def: None):
If None is passed, the closing price of the previous bar will be
used. To end up with a bar which for example takes time but it is not
displayed in a plot ... use float('Nan')
- fill_vol (def: float('NaN')):
Value to use to fill the missing volume
- fill_oi (def: float('NaN')):
Value to use to fill the missing Open Interest
- skip_first_fill (def: True):
Upon seeing the 1st valid bar do not fill from the sessionstart up to
that bar
'''
params = (('fill_price', None),
('fill_vol', float('NaN')),
('fill_oi', float('NaN')),
('skip_first_fill', True))
示例脚本现在可以过滤和填充数据了:
./data-filler.py --writer --wrcsv --tstart 09:30 --tend 17:30 --filter --filler
...
62,2006-01-02-volume-min-001,62,2006-01-02 10:31:00,3614.0,3614.0,3614.0,3614.0,183.0,0.0,Strategy,62
63,2006-01-02-volume-min-001,63,2006-01-02 10:32:00,3614.0,3614.0,3614.0,3614.0,0.0,,Strategy,63
64,2006-01-02-volume-min-001,64,2006-01-02 10:33:00,3614.0,3614.0,3614.0,3614.0,0.0,,Strategy,64
65,2006-01-02-volume-min-001,65,2006-01-02 10:34:00,3614.0,3614.0,3614.0,3614.0,841.0,0.0,Strategy,65
...
分钟 10:32 和 10:33 已存在。脚本使用最后已知的“收盘”价格填充价格值,并将成交量和持仓量字段设置为 0。脚本接受一个--fvol参数,将成交量设置为任何值(包括'NaN')
完成票号 #23
使用SessionFilter和SessionFiller完成了以下工作:
-
未提供盘前/盘后市数据
-
不存在数据(在给定时间范围内)丢失
现在,在实施RelativeVolume指标的 Ticket 23 中讨论的“同步”不再需要,因为所有日期的条形图数量完全相同(在示例中从 09:30 到 17:30 的所有分钟都包括在内)
请记住,默认情况下将缺失的成交量设置为0,可以开发一个简单的RelativeVolume指标:
class RelativeVolume(bt.Indicator):
csv = True # show up in csv output (default for indicators is False)
lines = ('relvol',)
params = (
('period', 20),
('volisnan', True),
)
def __init__(self):
if self.p.volisnan:
# if missing volume will be NaN, do a simple division
# the end result for missing volumes will also be NaN
relvol = self.data.volume(-self.p.period) / self.data.volume
else:
# Else do a controlled Div with a built-in function
relvol = bt.DivByZero(
self.data.volume(-self.p.period),
self.data.volume,
zero=0.0)
self.lines.relvol = relvol
使用backtrader中的内置辅助功能,足够聪明,可以避免除零错误。
在下次脚本调用中将所有部分组合起来:
./data-filler.py --writer --wrcsv --tstart 09:30 --tend 17:30 --filter --filler --relvol
===============================================================================
Id,2006-01-02-volume-min-001,len,datetime,open,high,low,close,volume,openinterest,Strategy,len,RelativeVolume,len,relvol
1,2006-01-02-volume-min-001,1,2006-01-02 09:30:00,3604.0,3605.0,3603.0,3604.0,546.0,0.0,Strategy,1,RelativeVolume,1,
2,2006-01-02-volume-min-001,2,2006-01-02 09:31:00,3604.0,3606.0,3604.0,3606.0,438.0,0.0,Strategy,2,RelativeVolume,2,
...
RelativeVolume指标在第 1 个条形图期间产生了预期外的输出。周期在脚本中计算为:(17:30 - 09:30 * 60) + 1。让我们直接看看相对成交量在第二天的 10:32 和 10:33 是如何看待的,考虑到第 1 天,成交量值被填充为0:
...
543,2006-01-02-volume-min-001,543,2006-01-03 10:31:00,3648.0,3648.0,3647.0,3648.0,56.0,0.0,Strategy,543,RelativeVolume,543,3.26785714286
544,2006-01-02-volume-min-001,544,2006-01-03 10:32:00,3647.0,3648.0,3647.0,3647.0,313.0,0.0,Strategy,544,RelativeVolume,544,0.0
545,2006-01-02-volume-min-001,545,2006-01-03 10:33:00,3647.0,3647.0,3647.0,3647.0,135.0,0.0,Strategy,545,RelativeVolume,545,0.0
546,2006-01-02-volume-min-001,546,2006-01-03 10:34:00,3648.0,3648.0,3647.0,3648.0,171.0,0.0,Strategy,546,RelativeVolume,546,4.91812865497
...
如预期那样,它被设置为0。
结论
数据源中的filter机制打开了完全操纵数据流的可能性。请谨慎使用。
脚本代码和用法
在backtrader的源码中提供了示例:
usage: data-filler.py [-h] [--data DATA] [--filter] [--filler] [--fvol FVOL]
[--tstart TSTART] [--tend TEND] [--relvol]
[--fromdate FROMDATE] [--todate TODATE] [--writer]
[--wrcsv] [--plot] [--numfigs NUMFIGS]
DataFilter/DataFiller Sample
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--filter, -ft Filter using session start/end times
--filler, -fl Fill missing bars inside start/end times
--fvol FVOL Use as fill volume for missing bar (def: 0.0)
--tstart TSTART, -ts TSTART
Start time for the Session Filter (HH:MM)
--tend TEND, -te TEND
End time for the Session Filter (HH:MM)
--relvol, -rv Add relative volume indicator
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--writer, -w Add a writer to cerebro
--wrcsv, -wc Enable CSV Output in the writer
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
代码:
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import math
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.utils.flushfile
import backtrader.filters as btfilters
from relativevolume import RelativeVolume
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Get the session times to pass them to the indicator
# datetime.time has no strptime ...
dtstart = datetime.datetime.strptime(args.tstart, '%H:%M')
dtend = datetime.datetime.strptime(args.tend, '%H:%M')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate,
timeframe=bt.TimeFrame.Minutes,
compression=1,
sessionstart=dtstart, # internally just the "time" part will be used
sessionend=dtend, # internally just the "time" part will be used
)
if args.filter:
data.addfilter(btfilters.SessionFilter)
if args.filler:
data.addfilter(btfilters.SessionFiller, fill_vol=args.fvol)
# Add the data to cerebro
cerebro.adddata(data)
if args.relvol:
# Calculate backward period - tend tstart are in same day
# + 1 to include last moment of the interval dstart <-> dtend
td = ((dtend - dtstart).seconds // 60) + 1
cerebro.addindicator(RelativeVolume,
period=td,
volisnan=math.isnan(args.fvol))
# Add an empty strategy
cerebro.addstrategy(bt.Strategy)
# Add a writer with CSV
if args.writer:
cerebro.addwriter(bt.WriterFile, csv=args.wrcsv)
# And run it - no trading - disable stdstats
cerebro.run(stdstats=False)
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=True)
def parse_args():
parser = argparse.ArgumentParser(
description='DataFilter/DataFiller Sample')
parser.add_argument('--data', '-d',
default='../../datas/2006-01-02-volume-min-001.txt',
help='data to add to the system')
parser.add_argument('--filter', '-ft', action='store_true',
help='Filter using session start/end times')
parser.add_argument('--filler', '-fl', action='store_true',
help='Fill missing bars inside start/end times')
parser.add_argument('--fvol', required=False, default=0.0,
type=float,
help='Use as fill volume for missing bar (def: 0.0)')
parser.add_argument('--tstart', '-ts',
# default='09:14:59',
# help='Start time for the Session Filter (%H:%M:%S)')
default='09:15',
help='Start time for the Session Filter (HH:MM)')
parser.add_argument('--tend', '-te',
# default='17:15:59',
# help='End time for the Session Filter (%H:%M:%S)')
default='17:15',
help='End time for the Session Filter (HH:MM)')
parser.add_argument('--relvol', '-rv', action='store_true',
help='Add relative volume indicator')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--writer', '-w', action='store_true',
help='Add a writer to cerebro')
parser.add_argument('--wrcsv', '-wc', action='store_true',
help='Enable CSV Output in the writer')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
SessionFiller
来自backtrader源码:
class SessionFiller(with_metaclass(metabase.MetaParams, object)):
'''
Bar Filler for a Data Source inside the declared session start/end times.
The fill bars are constructed using the declared Data Source ``timeframe``
and ``compression`` (used to calculate the intervening missing times)
Params:
- fill_price (def: None):
If None is passed, the closing price of the previous bar will be
used. To end up with a bar which for example takes time but it is not
displayed in a plot ... use float('Nan')
- fill_vol (def: float('NaN')):
Value to use to fill the missing volume
- fill_oi (def: float('NaN')):
Value to use to fill the missing Open Interest
- skip_first_fill (def: True):
Upon seeing the 1st valid bar do not fill from the sessionstart up to
that bar
'''
params = (('fill_price', None),
('fill_vol', float('NaN')),
('fill_oi', float('NaN')),
('skip_first_fill', True))
# Minimum delta unit in between bars
_tdeltas = {
TimeFrame.Minutes: datetime.timedelta(seconds=60),
TimeFrame.Seconds: datetime.timedelta(seconds=1),
TimeFrame.MicroSeconds: datetime.timedelta(microseconds=1),
}
def __init__(self, data):
# Calculate and save timedelta for timeframe
self._tdunit = self._tdeltas[data._timeframe] * data._compression
self.seenbar = False # control if at least one bar has been seen
self.sessend = MAXDATE # maxdate is the control for bar in session
def __call__(self, data):
'''
Params:
- data: the data source to filter/process
Returns:
- False (always) because this filter does not remove bars from the
stream
The logic (starting with a session end control flag of MAXDATE)
- If new bar is over session end (never true for 1st bar)
Fill up to session end. Reset sessionend to MAXDATE & fall through
- If session end is flagged as MAXDATE
Recalculate session limits and check whether the bar is within them
if so, fill up and record the last seen tim
- Else ... the incoming bar is in the session, fill up to it
'''
# Get time of current (from data source) bar
dtime_cur = data.datetime.datetime()
if dtime_cur > self.sessend:
# bar over session end - fill up and invalidate
self._fillbars(data, self.dtime_prev, self.sessend + self._tdunit)
self.sessend = MAXDATE
# Fall through from previous check ... the bar which is over the
# session could already be in a new session and within the limits
if self.sessend == MAXDATE:
# No bar seen yet or one went over previous session limit
sessstart = data.datetime.tm2datetime(data.sessionstart)
self.sessend = sessend = data.datetime.tm2datetime(data.sessionend)
if sessstart <= dtime_cur <= sessend:
# 1st bar from session in the session - fill from session start
if self.seenbar or not self.p.skip_first_fill:
self._fillbars(data, sessstart - self._tdunit, dtime_cur)
self.seenbar = True
self.dtime_prev = dtime_cur
else:
# Seen a previous bar and this is in the session - fill up to it
self._fillbars(data, self.dtime_prev, dtime_cur)
self.dtime_prev = dtime_cur
return False
def _fillbars(self, data, time_start, time_end, forcedirty=False):
'''
Fills one by one bars as needed from time_start to time_end
Invalidates the control dtime_prev if requested
'''
# Control flag - bars added to the stack
dirty = False
time_start += self._tdunit
while time_start < time_end:
dirty = self._fillbar(data, time_start)
time_start += self._tdunit
if dirty or forcedirty:
data._save2stack(erase=True)
def _fillbar(self, data, dtime):
# Prepare an array of the needed size
bar = [float('Nan')] * data.size()
# Fill datetime
bar[data.DateTime] = date2num(dtime)
# Fill the prices
price = self.p.fill_price or data.close[-1]
for pricetype in [data.Open, data.High, data.Low, data.Close]:
bar[pricetype] = price
# Fill volume and open interest
bar[data.Volume] = self.p.fill_vol
bar[data.OpenInterest] = self.p.fill_oi
# Fill extra lines the data feed may have defined beyond DateTime
for i in range(data.DateTime + 1, data.size()):
bar[i] = data.lines[i][0]
# Add tot he stack of bars to save
data._add2stack(bar)
return True
用户定义的佣金
佣金方案实现不久前进行了重新设计。最重要的部分是:
-
保留原始的 CommissionInfo 类和行为
-
为轻松创建用户定义的佣金打开大门
-
将格式 xx%设置为新佣金方案的默认值,而不是 0.xx(只是一种口味),保持行为可配置
在扩展佣金中概述了基础知识。
注意
请参见下文CommInfoBase的文档字符串以获取参数参考
定义佣金方案
它涉及 1 或 2 个步骤
-
子类化
CommInfoBase简单地更改默认参数可能就足够了。
backtrader已经在模块backtrader.commissions中对一些定义进行了这样的更改。期货的常规行业标准是每合约和每轮固定金额。定义可以如下进行:class CommInfo_Futures_Fixed(CommInfoBase): params = ( ('stocklike', False), ('commtype', CommInfoBase.COMM_FIXED), )`对于股票和百分比佣金:
class CommInfo_Stocks_Perc(CommInfoBase): params = ( ('stocklike', True), ('commtype', CommInfoBase.COMM_PERC), )`如上所述,百分比的默认解释(作为参数
commission传递)为:xx%。如果希望使用旧的/其他行为 0.xx,可以轻松实现:class CommInfo_Stocks_PercAbs(CommInfoBase): params = ( ('stocklike', True), ('commtype', CommInfoBase.COMM_PERC), ('percabs', True), )` -
覆盖(如果需要)
_getcommission方法定义如下:
def _getcommission(self, size, price, pseudoexec): '''Calculates the commission of an operation at a given price pseudoexec: if True the operation has not yet been executed '''`更多实际示例的细节见下文
如何将其应用于平台
一旦CommInfoBase子类就位,诀窍就是使用broker.addcommissioninfo而不是通常的broker.setcommission。后者将在内部使用旧有的CommissionInfoObject。
说起来比做起来容易:
...
comminfo = CommInfo_Stocks_PercAbs(commission=0.005) # 0.5%
cerebro.broker.addcommissioninfo(comminfo)
addcommissioninfo方法的定义如下:
def addcommissioninfo(self, comminfo, name=None):
self.comminfo[name] = comminfo
设置name意味着comminfo对象只适用于具有该名称的资产。None的默认值意味着它适用于系统中的所有资产。
一个实际的示例
Ticket #45要求有一个适用于期货的佣金方案,按比例计算,并使用合同的整个“虚拟”价值的佣金百分比。即:在佣金计算中包括期货乘数。
这应该很容易:
import backtrader as bt
class CommInfo_Fut_Perc_Mult(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_PERC), # Apply % Commission
# ('percabs', False), # pass perc as xx% which is the default
)
def _getcommission(self, size, price, pseudoexec):
return size * price * self.p.commission * self.p.mult
将其放入系统中:
comminfo = CommInfo_Fut_Perc_Mult(
commission=0.1, # 0.1%
mult=10,
margin=2000 # Margin is needed for futures-like instruments
)
cerebro.broker.addcommission(comminfo)
如果默认值偏好格式为 0.xx,只需将参数percabs设置为True:
class CommInfo_Fut_Perc_Mult(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_PERC), # Apply % Commission
('percabs', True), # pass perc as 0.xx
)
comminfo = CommInfo_Fut_Perc_Mult(
commission=0.001, # 0.1%
mult=10,
margin=2000 # Margin is needed for futures-like instruments
)
cerebro.broker.addcommissioninfo(comminfo)
所有这些都应该奏效。
解释pseudoexec
让我们回顾一下_getcommission的定义:
def _getcommission(self, size, price, pseudoexec):
'''Calculates the commission of an operation at a given price
pseudoexec: if True the operation has not yet been executed
'''
pseudoexec参数的目的可能看起来很模糊,但它确实有用。
-
平台可能会调用此方法进行可用现金的预先计算和一些其他任务
-
这意味着该方法可能会(而且实际上会)多次使用相同的参数进行调用。
pseudoexec 指示调用是否对应于实际执行订单。虽然乍一看这可能看起来“不相关”,但如果考虑到以下情景,它就是相关的:
-
一家经纪人在协商合同数量超过 5000 单位后,将提供期货往返佣金 50%的折扣。
在这种情况下,如果没有
pseudoexec,对该方法的多次非执行调用将很快触发折扣已经生效的假设。
将场景投入实际运作:
import backtrader as bt
class CommInfo_Fut_Discount(bt.CommInfoBase):
params = (
('stocklike', False), # Futures
('commtype', bt.CommInfoBase.COMM_FIXED), # Apply Commission
# Custom params for the discount
('discount_volume', 5000), # minimum contracts to achieve discount
('discount_perc', 50.0), # 50.0% discount
)
negotiated_volume = 0 # attribute to keep track of the actual volume
def _getcommission(self, size, price, pseudoexec):
if self.negotiated_volume > self.p.discount_volume:
actual_discount = self.p.discount_perc / 100.0
else:
actual_discount = 0.0
commission = self.p.commission * (1.0 - actual_discount)
commvalue = size * price * commission
if not pseudoexec:
# keep track of actual real executed size for future discounts
self.negotiated_volume += size
return commvalue
pseudoexec 的目的和存在意义现在应该是清楚的了。
CommInfoBase 文档字符串和参数
这里是:
class CommInfoBase(with_metaclass(MetaParams)):
'''Base Class for the Commission Schemes.
Params:
- commission (def: 0.0): base commission value in percentage or monetary
units
- mult (def 1.0): multiplier applied to the asset for value/profit
- margin (def: None): amount of monetary units needed to open/hold an
operation. It only applies if the final ``_stocklike`` attribute in the
class is set to False
- commtype (def: None): Supported values are CommInfoBase.COMM_PERC
(commission to be understood as %) and CommInfoBase.COMM_FIXED
(commission to be understood as monetary units)
The default value of ``None`` is a supported value to retain
compatibility with the legacy ``CommissionInfo`` object. If
``commtype`` is set to None, then the following applies:
- margin is None: Internal _commtype is set to COMM_PERC and
_stocklike is set to True (Operating %-wise with Stocks)
- margin is not None: _commtype set to COMM_FIXED and _stocklike set
to False (Operating with fixed rount-trip commission with Futures)
If this param is set to something else than None, then it will be
passed to the internal ``_commtype`` attribute and the same will be
done with the param ``stocklike`` and the internal attribute
``_stocklike``
- stocklike (def: False): Indicates if the instrument is Stock-like or
Futures-like (see the ``commtype`` discussion above)
- percabs (def: False): when ``commtype`` is set to COMM_PERC, whether
the parameter ``commission`` has to be understood as XX% or 0.XX
If this param is True: 0.XX
If this param is False: XX%
Attributes:
- _stocklike: Final value to use for Stock-like/Futures-like behavior
- _commtype: Final value to use for PERC vs FIXED commissions
This two are used internally instead of the declared params to enable the
compatibility check described above for the legacy ``CommissionInfo``
object
'''
COMM_PERC, COMM_FIXED = range(2)
params = (
('commission', 0.0), ('mult', 1.0), ('margin', None),
('commtype', None),
('stocklike', False),
('percabs', False),
)
扩展佣金
原文:
www.backtrader.com/blog/posts/2015-11-05-commission-schemes-extended/commission-schemes-extended/
佣金和相关功能由一个单独的类CommissionInfo管理,该类主要通过调用broker.setcommission来实例化。
有一些帖子讨论了这种行为。
-
佣金:股票 vs 期货
-
改进佣金:股票 vs 期货
这个概念仅限于具有保证金的期货和具有基于价格/大小百分比的佣金的股票。 即使它已经达到了它的目的,它也不是最灵活的方案。
我自己的实现中只有一件事我不喜欢,那就是CommissionInfo将百分比值以绝对值(0.xx)而不是相对值(xx%)的方式传递
GitHub 的增强请求#29导致一些重新设计,以:
-
保持
CommissionInfo和broker.setcommission与原始行为兼容 -
对代码进行清理
-
使佣金方案灵活以支持增强请求和进一步可能性
进入示例之前的实际工作:
class CommInfoBase(with_metaclass(MetaParams)):
COMM_PERC, COMM_FIXED = range(2)
params = (
('commission', 0.0), ('mult', 1.0), ('margin', None),
('commtype', None),
('stocklike', False),
('percabs', False),
)
引入了一个CommissionInfo的基类,将新参数添加到混合中:
-
commtype(默认:None)这是兼容性的关键。 如果值为
None,则CommissionInfo对象和broker.setcommission的行为将与以前相同。 即:-
如果设置了
margin,则佣金方案适用于具有固定合约佣金的期货 -
如果未设置
margin,则佣金方案适用于具有基于百分比的股票方法
如果值为
COMM_PERC或COMM_FIXED(或派生类中的任何其他值),则这显然决定了佣金是固定的还是基于百分比的 -
-
stocklike(默认:False)如上所述,旧的
CommissionInfo对象中的实际行为由参数margin决定如上所述,如果将
commtype设置为除None之外的其他值,则此值指示资产是否为类似期货的资产(将使用保证金,并执行基于条的现金调整)或者这是类似股票的资产 -
percabs(默认:False)如果为
False,则百分比必须以相对术语传递(xx%)如果为
True,则百分比必须以绝对值(0.xx)传递CommissionInfo是从CommInfoBase派生的,将此参数的默认值更改为True以保持兼容的行为
所有这些参数也可以在broker.setcommission中使用,现在看起来像这样:
def setcommission(self,
commission=0.0, margin=None, mult=1.0,
commtype=None, percabs=True, stocklike=False,
name=None):
请注意以下内容:
percabs设置为True,以保持与旧调用的CommissionInfo对象上述行为的兼容
重新设计了用于测试commissions-schemes的旧样本,以支持命令行参数和新行为。 使用帮助:
$ ./commission-schemes.py --help
usage: commission-schemes.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--stake STAKE]
[--period PERIOD] [--cash CASH] [--comm COMM]
[--mult MULT] [--margin MARGIN]
[--commtype {none,perc,fixed}] [--stocklike]
[--percrel] [--plot] [--numfigs NUMFIGS]
Commission schemes
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system (default:
../../datas/2006-day-001.txt)
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format (default:
2006-01-01)
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format (default:
2006-12-31)
--stake STAKE Stake to apply in each operation (default: 1)
--period PERIOD Period to apply to the Simple Moving Average (default:
30)
--cash CASH Starting Cash (default: 10000.0)
--comm COMM Commission factor for operation, either apercentage or
a per stake unit absolute value (default: 2.0)
--mult MULT Multiplier for operations calculation (default: 10)
--margin MARGIN Margin for futures-like operations (default: 2000.0)
--commtype {none,perc,fixed}
Commission - choose none for the old CommissionInfo
behavior (default: none)
--stocklike If the operation is for stock-like assets orfuture-
like assets (default: False)
--percrel If perc is expressed in relative xx{'const': True,
'help': u'If perc is expressed in relative xx%
ratherthan absolute value 0.xx', 'option_strings': [u'
--percrel'], 'dest': u'percrel', 'required': False,
'nargs': 0, 'choices': None, 'default': False, 'prog':
'commission-schemes.py', 'container':
<argparse._ArgumentGroup object at
0x0000000007EC9828>, 'type': None, 'metavar':
None}atherthan absolute value 0.xx (default: False)
--plot, -p Plot the read data (default: False)
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures (default: 1)
让我们进行一些运行,以重新创建原始佣金方案帖子的原始行为。
期货的佣金(固定和带保证金)
执行和图表:
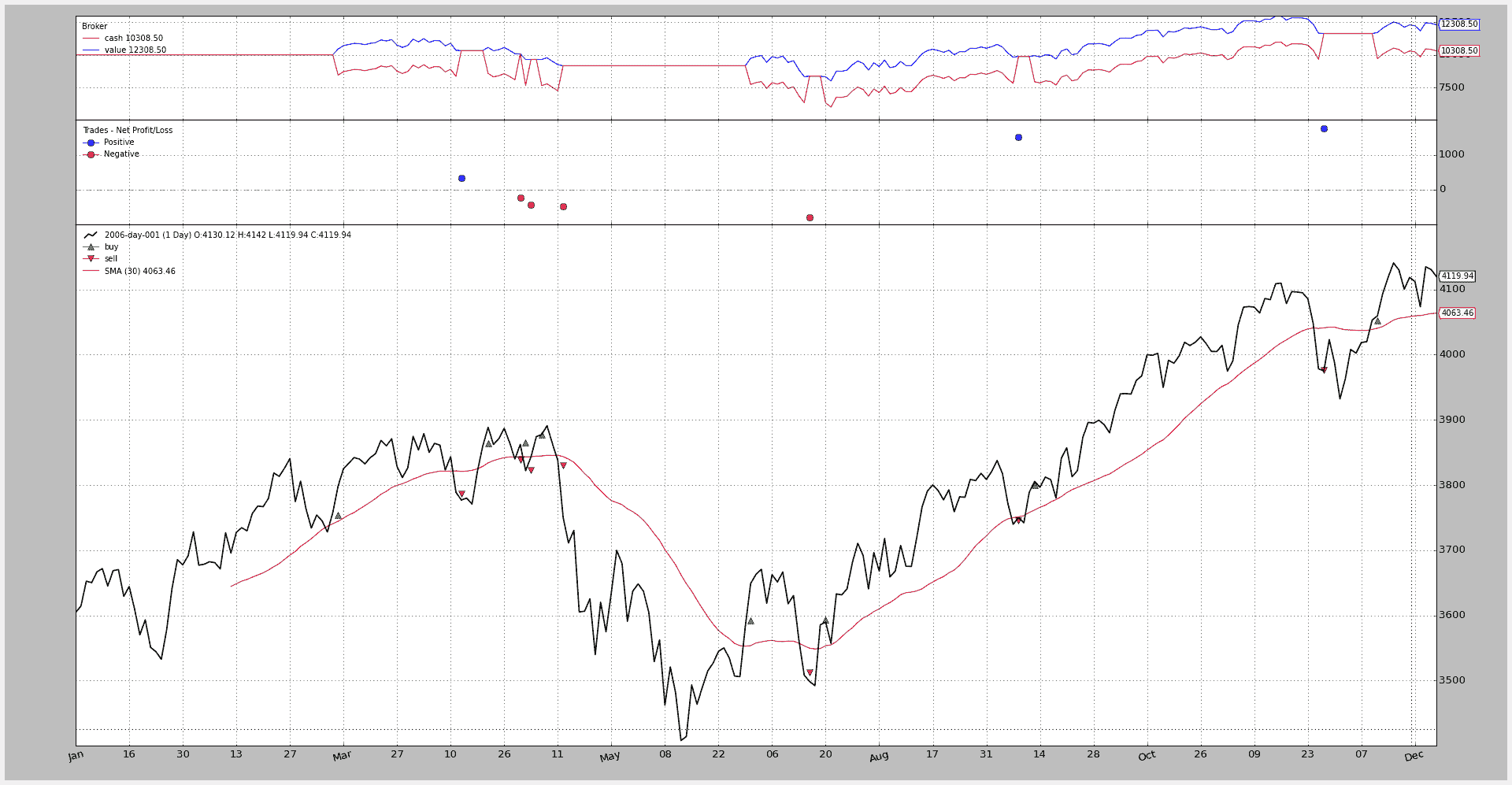
$ ./commission-schemes.py --comm 2.0 --margin 2000.0 --mult 10 --plot
并且输出显示固定佣金为 2.0 货币单位(默认押注为 1):
2006-03-09, BUY CREATE, 3757.59
2006-03-10, BUY EXECUTED, Price: 3754.13, Cost: 2000.00, Comm 2.00
2006-04-11, SELL CREATE, 3788.81
2006-04-12, SELL EXECUTED, Price: 3786.93, Cost: 2000.00, Comm 2.00
2006-04-12, TRADE PROFIT, GROSS 328.00, NET 324.00
...
股票的佣金(百分比和无保证金)
执行和图表:
$ ./commission-schemes.py --comm 0.005 --margin 0 --mult 1 --plot
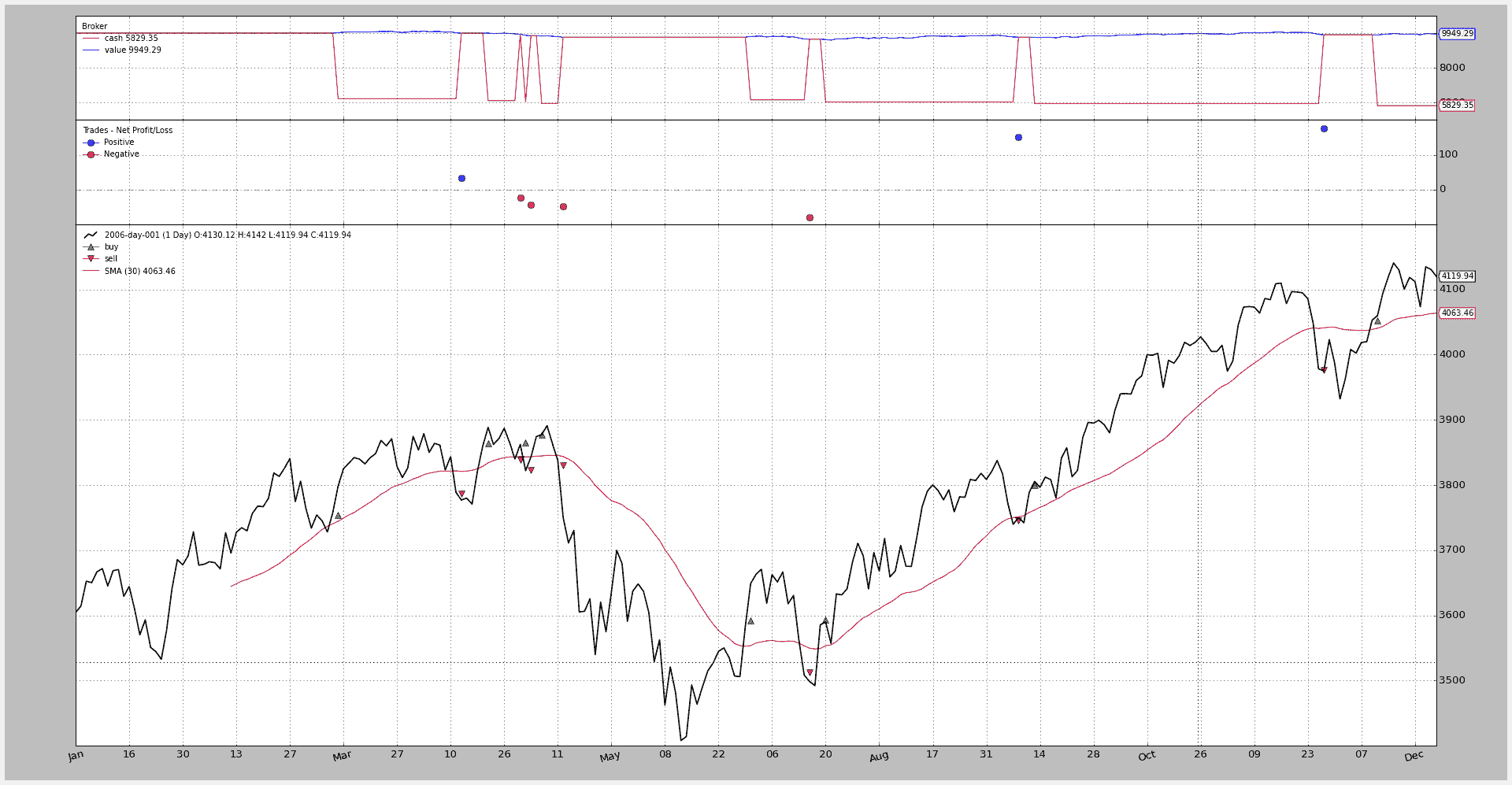
为了提高可读性,可以使用相对%值:
$ ./commission-schemes.py --percrel --comm 0.5 --margin 0 --mult 1 --plot
现在0.5直接表示0.5%
输出在两种情况下都是:
2006-03-09, BUY CREATE, 3757.59
2006-03-10, BUY EXECUTED, Price: 3754.13, Cost: 3754.13, Comm 18.77
2006-04-11, SELL CREATE, 3788.81
2006-04-12, SELL EXECUTED, Price: 3786.93, Cost: 3754.13, Comm 18.93
2006-04-12, TRADE PROFIT, GROSS 32.80, NET -4.91
...
期货的佣金(百分比和带保证金)
使用新参数,基于百分比的期货:
$ ./commission-schemes.py --commtype perc --percrel --comm 0.5 --margin 2000 --mult 10 --plot
改变佣金...最终结果发生变化并不奇怪
输出显示佣金现在是可变的:
2006-03-09, BUY CREATE, 3757.59
2006-03-10, BUY EXECUTED, Price: 3754.13, Cost: 2000.00, Comm 18.77
2006-04-11, SELL CREATE, 3788.81
2006-04-12, SELL EXECUTED, Price: 3786.93, Cost: 2000.00, Comm 18.93
2006-04-12, TRADE PROFIT, GROSS 328.00, NET 290.29
...
在上一次运行中设置了 2.0 货币单位(默认押注为 1)
另一篇文章将详细介绍新的类别和自制佣金方案的实施。
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class SMACrossOver(bt.Strategy):
params = (
('stake', 1),
('period', 30),
)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.datas[0].datetime.date(0)
print('%s, %s' % (dt.isoformat(), txt))
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# Buy/Sell order submitted/accepted to/by broker - Nothing to do
return
# Check if an order has been completed
# Attention: broker could reject order if not enougth cash
if order.status in [order.Completed, order.Canceled, order.Margin]:
if order.isbuy():
self.log(
'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
else: # Sell
self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
def notify_trade(self, trade):
if trade.isclosed:
self.log('TRADE PROFIT, GROSS %.2f, NET %.2f' %
(trade.pnl, trade.pnlcomm))
def __init__(self):
sma = btind.SMA(self.data, period=self.p.period)
# > 0 crossing up / < 0 crossing down
self.buysell_sig = btind.CrossOver(self.data, sma)
def next(self):
if self.buysell_sig > 0:
self.log('BUY CREATE, %.2f' % self.data.close[0])
self.buy(size=self.p.stake) # keep order ref to avoid 2nd orders
elif self.position and self.buysell_sig < 0:
self.log('SELL CREATE, %.2f' % self.data.close[0])
self.sell(size=self.p.stake)
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data)
# Add a strategy
cerebro.addstrategy(SMACrossOver, period=args.period, stake=args.stake)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcash(args.cash)
commtypes = dict(
none=None,
perc=bt.CommInfoBase.COMM_PERC,
fixed=bt.CommInfoBase.COMM_FIXED)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcommission(commission=args.comm,
mult=args.mult,
margin=args.margin,
percabs=not args.percrel,
commtype=commtypes[args.commtype],
stocklike=args.stocklike)
# And run it
cerebro.run()
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=False)
def parse_args():
parser = argparse.ArgumentParser(
description='Commission schemes',
formatter_class=argparse.ArgumentDefaultsHelpFormatter,)
parser.add_argument('--data', '-d',
default='../../datas/2006-day-001.txt',
help='data to add to the system')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--stake', default=1, type=int,
help='Stake to apply in each operation')
parser.add_argument('--period', default=30, type=int,
help='Period to apply to the Simple Moving Average')
parser.add_argument('--cash', default=10000.0, type=float,
help='Starting Cash')
parser.add_argument('--comm', default=2.0, type=float,
help=('Commission factor for operation, either a'
'percentage or a per stake unit absolute value'))
parser.add_argument('--mult', default=10, type=int,
help='Multiplier for operations calculation')
parser.add_argument('--margin', default=2000.0, type=float,
help='Margin for futures-like operations')
parser.add_argument('--commtype', required=False, default='none',
choices=['none', 'perc', 'fixed'],
help=('Commission - choose none for the old'
' CommissionInfo behavior'))
parser.add_argument('--stocklike', required=False, action='store_true',
help=('If the operation is for stock-like assets or'
'future-like assets'))
parser.add_argument('--percrel', required=False, action='store_true',
help=('If perc is expressed in relative xx% rather'
'than absolute value 0.xx'))
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
MultiTrades
原文:
www.backtrader.com/blog/posts/2015-10-05-multitrades/multitrades/
现在可以为每笔交易添加唯一标识符,即使在相同数据上运行。
根据Tick Data and Resampling的请求,在backtrader的 1.1.12.88 版本中支持“MultiTrades”,即:为订单分配tradeid的能力。此 id 传递给Trades,使得可以拥有不同类别的交易并同时开放。
当:
-
使用带有关键字参数
tradeid的 Calling Strategy.buy/sell/close -
使用带有关键字参数
tradeid的 Calling Broker.buy/sell -
创建带有关键字参数
tradeid的订单实例
如果未指定,默认值为:
tradeid = 0
已实现了一个小脚本进行测试,通过实现自定义的MTradeObserver来可视化结果,根据tradeid分配不同的标记在图表上(测试值使用 0、1 和 2)
该脚本支持使用三个 id(0、1、2)或仅使用 0(默认值)
未启用多个 id 的执行:
$ ./multitrades.py --plot
结果图表显示所有交易都携带 id 0,因此无法区分。
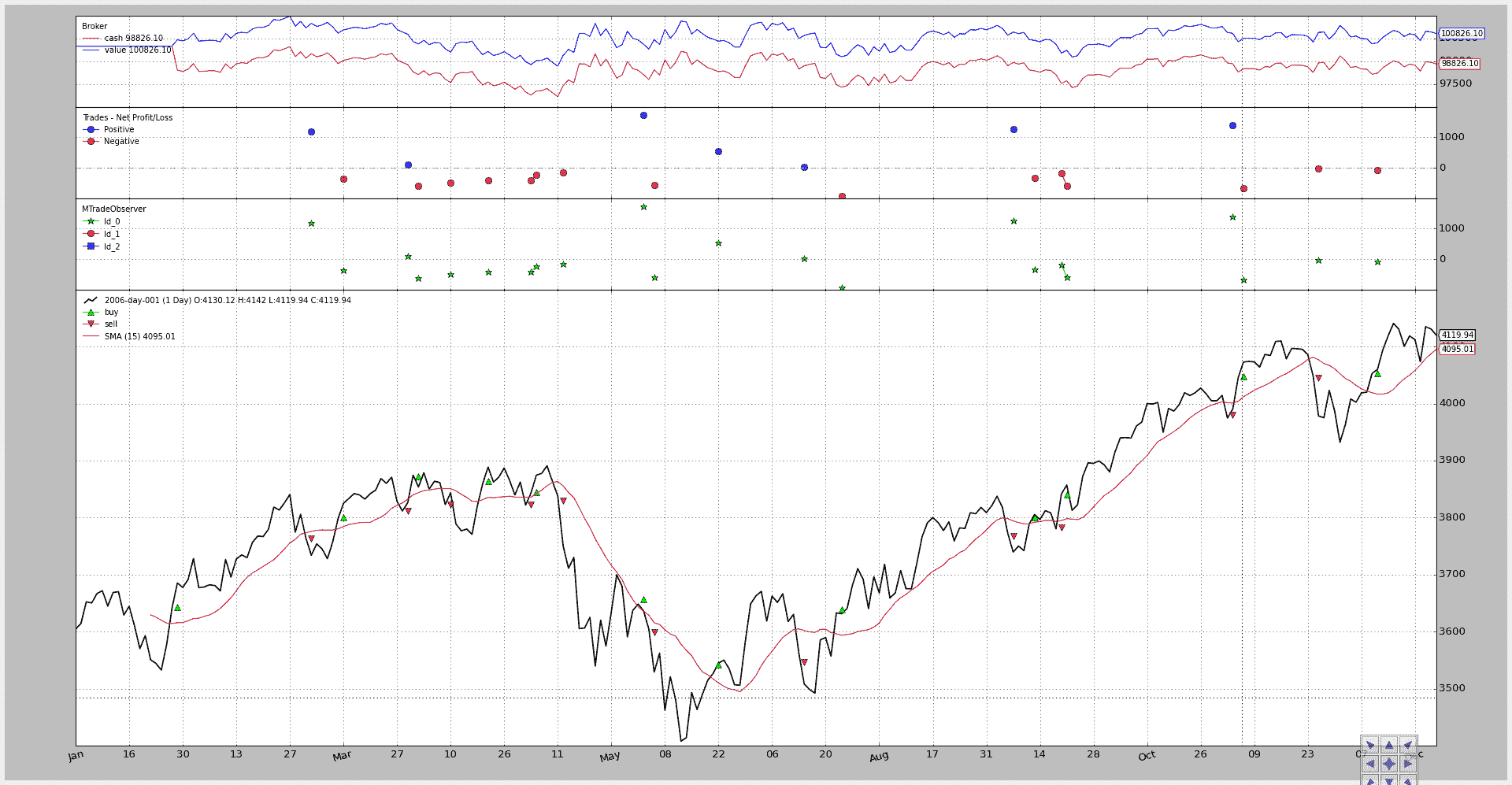
第二次执行通过在 0、1 和 2 之间循环实现多交易:
$ ./multitrades.py --plot --mtrade
现在 3 个不同的标记交替显示,每个交易都可以使用tradeid成员进行区分。
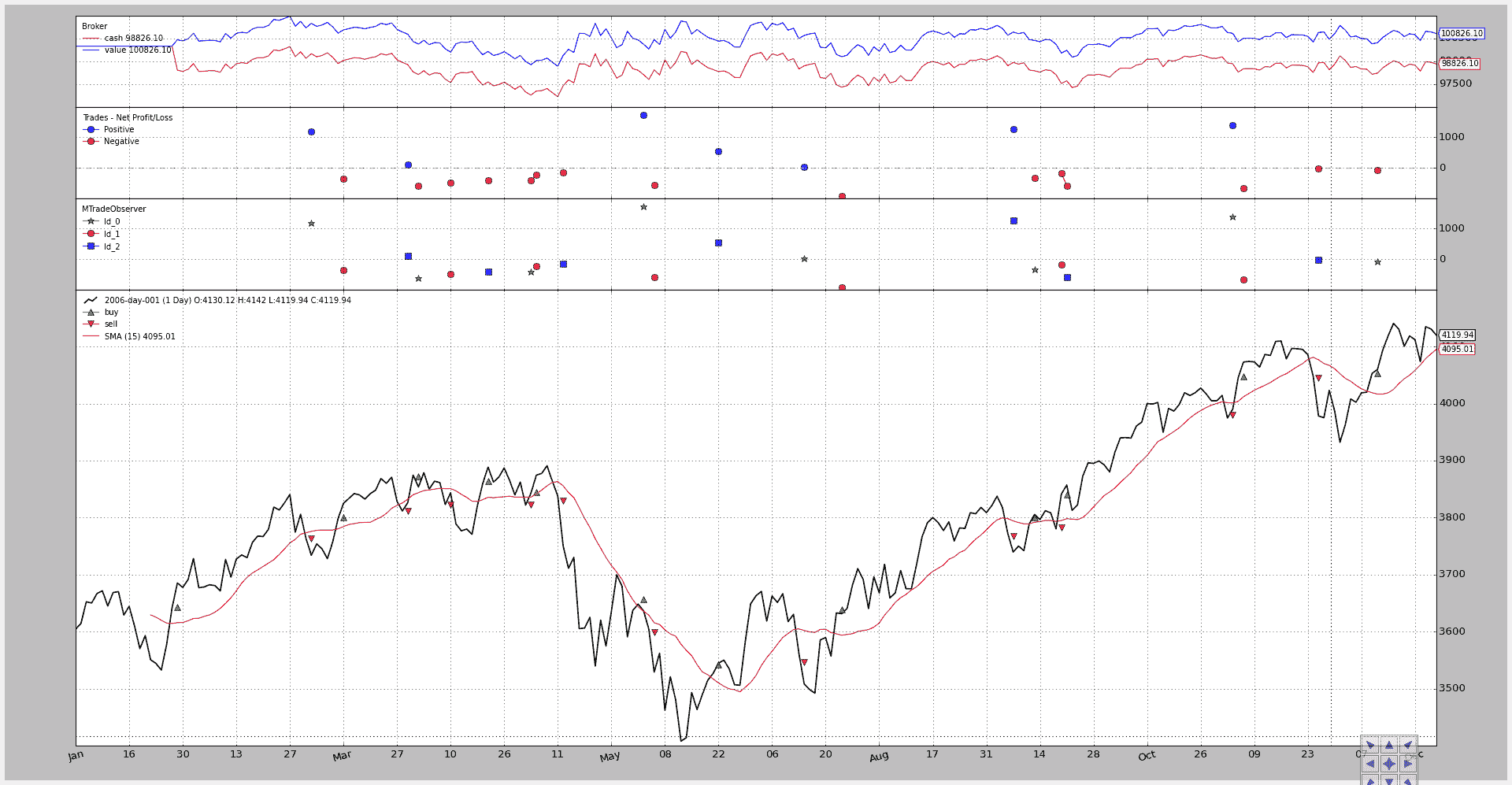
注意
backtrader尝试使用模拟现实的模型。因此,“交易”不是由仅负责订单的Broker实例计算的。
交易由策略计算。
因此,tradeid(或类似的内容)可能不会被真实经纪人支持,在这种情况下,需要手动跟踪经纪人分配的唯一订单 id。
现在,自定义观察者的代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import math
import backtrader as bt
class MTradeObserver(bt.observer.Observer):
lines = ('Id_0', 'Id_1', 'Id_2')
plotinfo = dict(plot=True, subplot=True, plotlinelabels=True)
plotlines = dict(
Id_0=dict(marker='*', markersize=8.0, color='lime', fillstyle='full'),
Id_1=dict(marker='o', markersize=8.0, color='red', fillstyle='full'),
Id_2=dict(marker='s', markersize=8.0, color='blue', fillstyle='full')
)
def next(self):
for trade in self._owner._tradespending:
if trade.data is not self.data:
continue
if not trade.isclosed:
continue
self.lines[trade.tradeid][0] = trade.pnlcomm
主要脚本用法:
$ ./multitrades.py --help
usage: multitrades.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--mtrade] [--period PERIOD]
[--onlylong] [--cash CASH] [--comm COMM] [--mult MULT]
[--margin MARGIN] [--stake STAKE] [--plot]
[--numfigs NUMFIGS]
MultiTrades
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--mtrade Activate MultiTrade Ids
--period PERIOD Period to apply to the Simple Moving Average
--onlylong, -ol Do only long operations
--cash CASH Starting Cash
--comm COMM Commission for operation
--mult MULT Multiplier for futures
--margin MARGIN Margin for each future
--stake STAKE Stake to apply in each operation
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
脚本的代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import itertools
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
import mtradeobserver
class MultiTradeStrategy(bt.Strategy):
'''This strategy buys/sells upong the close price crossing
upwards/downwards a Simple Moving Average.
It can be a long-only strategy by setting the param "onlylong" to True
'''
params = dict(
period=15,
stake=1,
printout=False,
onlylong=False,
mtrade=False,
)
def log(self, txt, dt=None):
if self.p.printout:
dt = dt or self.data.datetime[0]
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
# To control operation entries
self.order = None
# Create SMA on 2nd data
sma = btind.MovAv.SMA(self.data, period=self.p.period)
# Create a CrossOver Signal from close an moving average
self.signal = btind.CrossOver(self.data.close, sma)
# To alternate amongst different tradeids
if self.p.mtrade:
self.tradeid = itertools.cycle([0, 1, 2])
else:
self.tradeid = itertools.cycle([0])
def next(self):
if self.order:
return # if an order is active, no new orders are allowed
if self.signal > 0.0: # cross upwards
if self.position:
self.log('CLOSE SHORT , %.2f' % self.data.close[0])
self.close(tradeid=self.curtradeid)
self.log('BUY CREATE , %.2f' % self.data.close[0])
self.curtradeid = next(self.tradeid)
self.buy(size=self.p.stake, tradeid=self.curtradeid)
elif self.signal < 0.0:
if self.position:
self.log('CLOSE LONG , %.2f' % self.data.close[0])
self.close(tradeid=self.curtradeid)
if not self.p.onlylong:
self.log('SELL CREATE , %.2f' % self.data.close[0])
self.curtradeid = next(self.tradeid)
self.sell(size=self.p.stake, tradeid=self.curtradeid)
def notify_order(self, order):
if order.status in [bt.Order.Submitted, bt.Order.Accepted]:
return # Await further notifications
if order.status == order.Completed:
if order.isbuy():
buytxt = 'BUY COMPLETE, %.2f' % order.executed.price
self.log(buytxt, order.executed.dt)
else:
selltxt = 'SELL COMPLETE, %.2f' % order.executed.price
self.log(selltxt, order.executed.dt)
elif order.status in [order.Expired, order.Canceled, order.Margin]:
self.log('%s ,' % order.Status[order.status])
pass # Simply log
# Allow new orders
self.order = None
def notify_trade(self, trade):
if trade.isclosed:
self.log('TRADE PROFIT, GROSS %.2f, NET %.2f' %
(trade.pnl, trade.pnlcomm))
elif trade.justopened:
self.log('TRADE OPENED, SIZE %2d' % trade.size)
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data)
# Add the strategy
cerebro.addstrategy(MultiTradeStrategy,
period=args.period,
onlylong=args.onlylong,
stake=args.stake,
mtrade=args.mtrade)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcash(args.cash)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcommission(commission=args.comm,
mult=args.mult,
margin=args.margin)
# Add the MultiTradeObserver
cerebro.addobserver(mtradeobserver.MTradeObserver)
# And run it
cerebro.run()
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=False, zdown=False)
def parse_args():
parser = argparse.ArgumentParser(description='MultiTrades')
parser.add_argument('--data', '-d',
default='../../datas/2006-day-001.txt',
help='data to add to the system')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--mtrade', action='store_true',
help='Activate MultiTrade Ids')
parser.add_argument('--period', default=15, type=int,
help='Period to apply to the Simple Moving Average')
parser.add_argument('--onlylong', '-ol', action='store_true',
help='Do only long operations')
parser.add_argument('--cash', default=100000, type=int,
help='Starting Cash')
parser.add_argument('--comm', default=2, type=float,
help='Commission for operation')
parser.add_argument('--mult', default=10, type=int,
help='Multiplier for futures')
parser.add_argument('--margin', default=2000.0, type=float,
help='Margin for each future')
parser.add_argument('--stake', default=1, type=int,
help='Stake to apply in each operation')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()