在 backtrader 中交易加密货币的分数大小
原文:
www.backtrader.com/blog/posts/2019-08-29-fractional-sizes/fractional-sizes/
首先,让我们用两行总结一下backtrader的工作方式:
-
就像一个基本构建块(
Cerebro)的构建套件,可以将许多不同的部件插入其中 -
基本分发包含许多部件,如指标、分析器、观察器、调整器、过滤器、数据源、经纪人、佣金/资产信息方案,...
-
新的构建模块可以很容易地从头开始构建,或者基于现有的构建模块
-
基本构建块(
Cerebro)已经自动进行了一些"插入",使得在不必担心所有细节的情况下更容易使用该框架。
因此,该框架预先配置为提供具有默认行为的行为,例如:
-
使用单个/主数据源
-
1-day时间框架/压缩组合 -
10,000 单位的货币
-
股票交易
这可能适合或不适合每个人,但重要的是:它可以根据每个交易者/程序员的个人需求进行定制
交易股票:整数
如上所述,默认配置是用于股票交易,当交易股票时,购买/出售完整股票(即:1、2...50...1000,而不是像1.5或1001.7589股票那样的金额。
这意味着当用户在默认配置中执行以下操作时:
def next(self):
# Apply 50% of the portfolio to buy the main asset
self.order_target_percent(target=0.5)
以下发生了:
-
系统计算需要多少份资产股票,以便给定资产组合中的价值尽可能接近
50% -
但由于默认配置是使用股票进行操作,因此得到的股票数量将是一个整数,即:一个整数
注意
请注意,默认配置是使用单个/主数据源进行操作,这就是为什么在调用order_percent_target时没有指定实际数据。当操作多个数据源时,必须指定要获取/出售的数据(除非是主要数据)
交易加密货币:分数
很明显,在交易加密货币时,即使有 20 位小数,也可以购买"半个比特币"。
好处在于,实际上可以更改有关资产的信息。这是通过可插入的CommissionInfo系列实现的。
一些文档:文档 - 佣金方案 - https://www.backtrader.com/docu/commission-schemes/commission-schemes/
注意
必须承认这个名字不太幸运,因为这些方案不仅包含有关佣金的信息,还包含其他信息。
在分数场景中,该方案的方法是:getsize(price, cash),其具有以下文档字符串
Returns the needed size to meet a cash operation at a given price
方案与经纪人密切相关,通过经纪人 API,可以在系统中添加方案。
经纪人文档位于:文档 - 经纪人 - https://www.backtrader.com/docu/broker/
相关方法为:addcommissioninfo(comminfo, name=None)。除了添加一个适用于所有资产的方案(当name为None时),还可以设置仅适用于具有特定名称资产的方案。
实施分数方案
这可以通过扩展现有的基础方案CommissionInfo来轻松实现。
class CommInfoFractional(bt.CommissionInfo):
def getsize(self, price, cash):
'''Returns fractional size for cash operation @price'''
return self.p.leverage * (cash / price)
同上并完成。通过子类化CommissionInfo并编写一行方法,实现了目标。因为原始方案定义支持leverage,这一点已经考虑在内,以防加密货币可以使用杠杆购买(其中默认值为1.0,即:无杠杆)
代码后面,该方案将被添加(通过命令行参数控制),如下所示
if args.fractional: # use the fractional scheme if requested
cerebro.broker.addcommissioninfo(CommInfoFractional())
也就是说:子类方案的一个实例(注意用()进行实例化)被添加了。如上所述,未设置name参数,这意味着它将应用于系统中的所有资产。
测试野兽
下面提供了一个完整的脚本,实现了一个简单的移动平均线交叉策略,用于长/短仓位,可以直接在 shell 中使用。测试的默认数据源来自backtrader仓库中的一个数据源。
整数运行:无分数 - 无趣
$ ./fractional-sizes.py --plot
2005-02-14,3079.93,3083.38,3065.27,3075.76,0.00
2005-02-15,3075.20,3091.64,3071.08,3086.95,0.00
...
2005-03-21,3052.39,3059.18,3037.80,3038.14,0.00
2005-03-21,Enter Short
2005-03-22,Sell Order Completed - Size: -16 @Price: 3040.55 Value: -48648.80 Comm: 0.00
2005-03-22,Trade Opened - Size -16 @Price 3040.55
2005-03-22,3040.55,3053.18,3021.66,3050.44,0.00
...
一个大小为16单位的短期交易已经开启。由于显而易见的原因,整个日志未显示,其中包含许多其他操作,都是以整数大小进行交易。
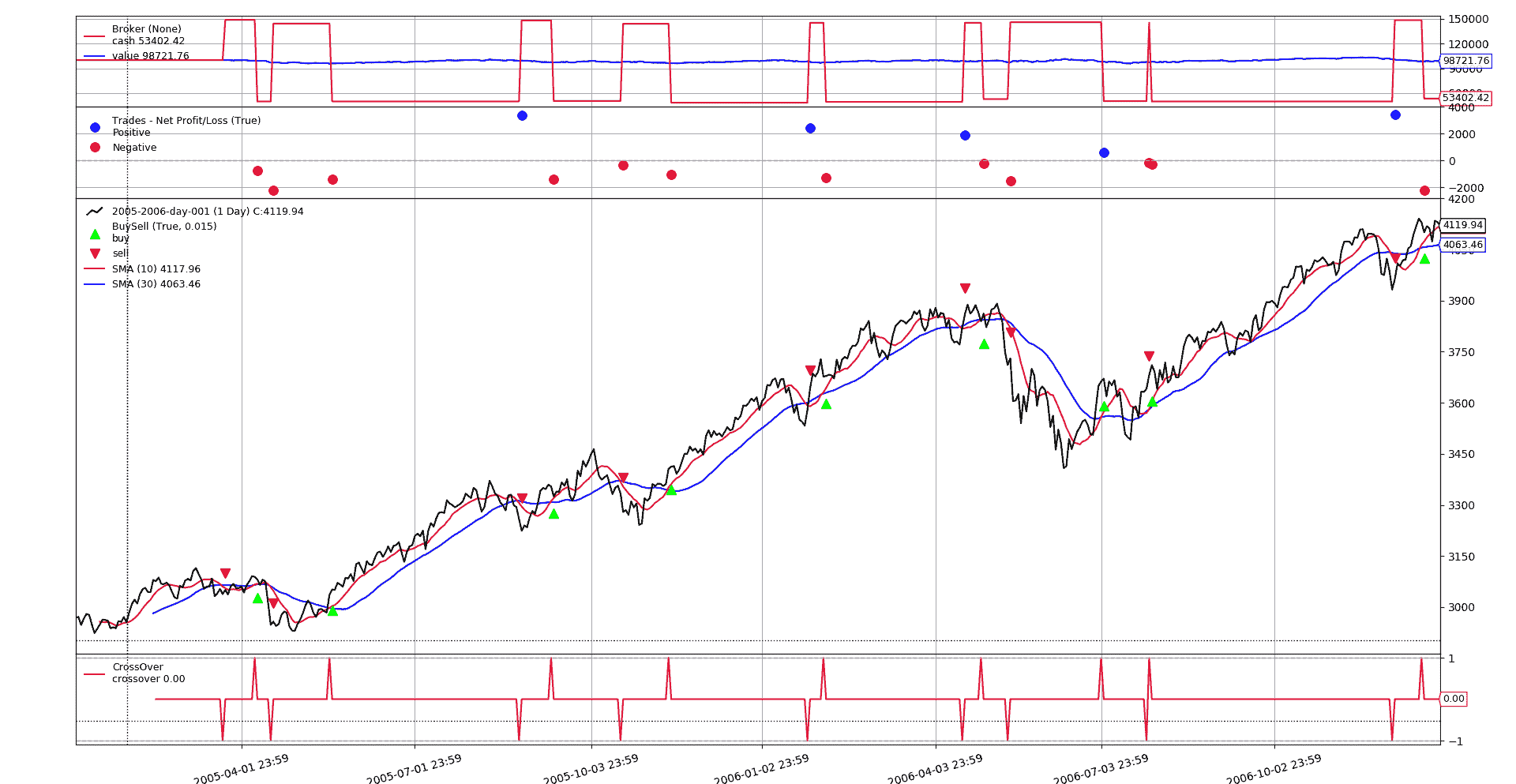
分数运行
经过分数的艰苦子类化和一行代码的工作后...
$ ./fractional-sizes.py --fractional --plot
2005-02-14,3079.93,3083.38,3065.27,3075.76,0.00
2005-02-15,3075.20,3091.64,3071.08,3086.95,0.00
...
2005-03-21,3052.39,3059.18,3037.80,3038.14,0.00
2005-03-21,Enter Short
2005-03-22,Sell Order Completed - Size: -16.457437774427774 @Price: 3040.55 Value: -50039.66 Comm: 0.00
2005-03-22,Trade Opened - Size -16.457437774427774 @Price 3040.55
2005-03-22,3040.55,3053.18,3021.66,3050.44,0.00
...
V 为胜利。短期交易已经通过相同的交叉方式开启,但这次是以-16.457437774427774的分数大小。
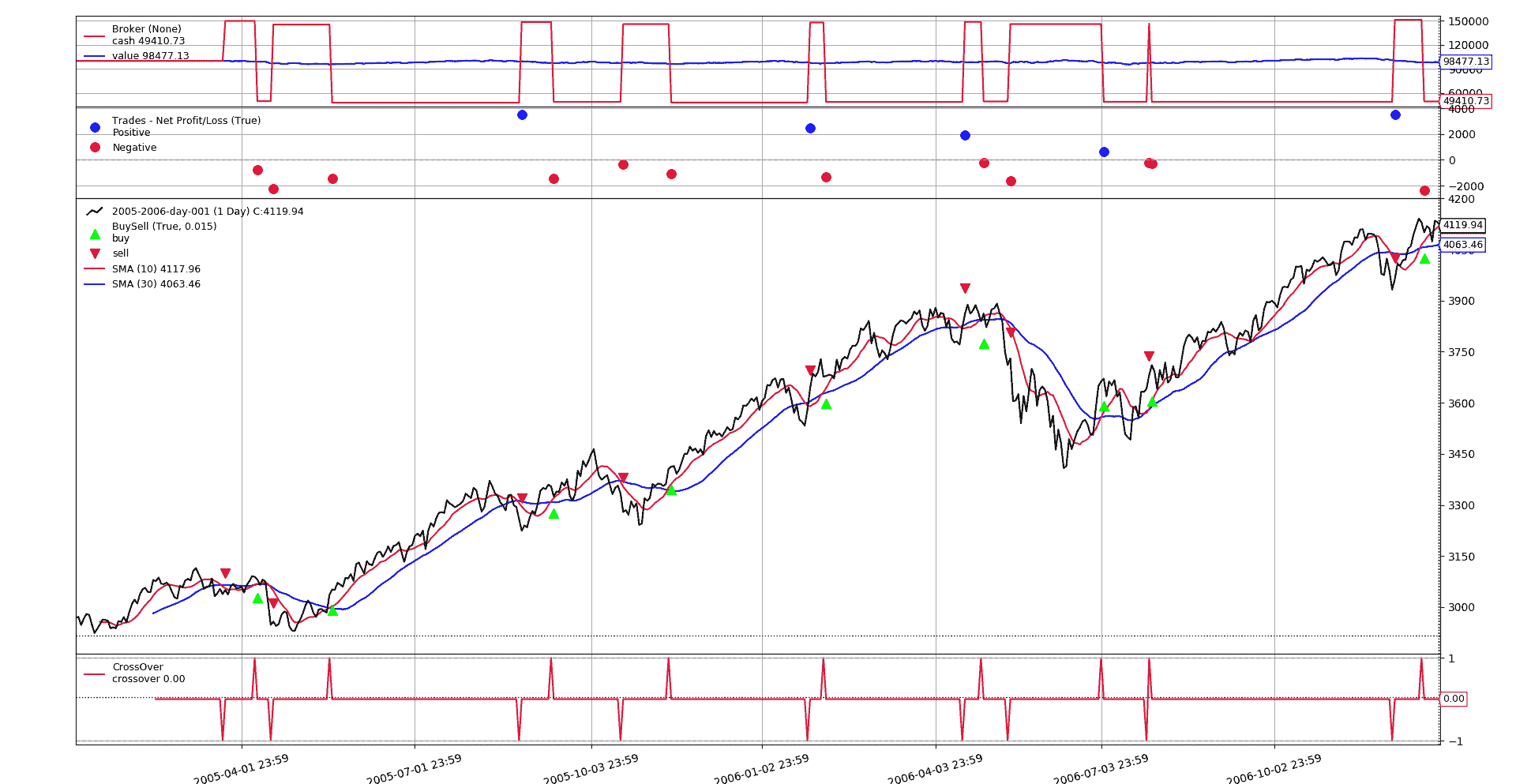
请注意,图表中的最终投资组合价值不同,这是因为实际交易大小不同。
结论
是的,backtrader 可以。采用可插拔/可扩展的构建工具方法,很容易将行为定制为交易程序员的特定需求。
该脚本
#!/usr/bin/env python
# -*- coding: utf-8; py-indent-offset:4 -*-
###############################################################################
# Copyright (C) 2019 Daniel Rodriguez - MIT License
# - https://opensource.org/licenses/MIT
# - https://en.wikipedia.org/wiki/MIT_License
###############################################################################
import argparse
import logging
import sys
import backtrader as bt
# This defines not only the commission info, but some other aspects
# of a given data asset like the "getsize" information from below
# params = dict(stocklike=True) # No margin, no multiplier
class CommInfoFractional(bt.CommissionInfo):
def getsize(self, price, cash):
'''Returns fractional size for cash operation @price'''
return self.p.leverage * (cash / price)
class St(bt.Strategy):
params = dict(
p1=10, p2=30, # periods for crossover
ma=bt.ind.SMA, # moving average to use
target=0.5, # percentage of value to use
)
def __init__(self):
ma1, ma2 = [self.p.ma(period=p) for p in (self.p.p1, self.p.p2)]
self.cross = bt.ind.CrossOver(ma1, ma2)
def next(self):
self.logdata()
if self.cross > 0:
self.loginfo('Enter Long')
self.order_target_percent(target=self.p.target)
elif self.cross < 0:
self.loginfo('Enter Short')
self.order_target_percent(target=-self.p.target)
def notify_trade(self, trade):
if trade.justopened:
self.loginfo('Trade Opened - Size {} @Price {}',
trade.size, trade.price)
elif trade.isclosed:
self.loginfo('Trade Closed - Profit {}', trade.pnlcomm)
else: # trade updated
self.loginfo('Trade Updated - Size {} @Price {}',
trade.size, trade.price)
def notify_order(self, order):
if order.alive():
return
otypetxt = 'Buy ' if order.isbuy() else 'Sell'
if order.status == order.Completed:
self.loginfo(
('{} Order Completed - '
'Size: {} @Price: {} '
'Value: {:.2f} Comm: {:.2f}'),
otypetxt, order.executed.size, order.executed.price,
order.executed.value, order.executed.comm
)
else:
self.loginfo('{} Order rejected', otypetxt)
def loginfo(self, txt, *args):
out = [self.datetime.date().isoformat(), txt.format(*args)]
logging.info(','.join(out))
def logerror(self, txt, *args):
out = [self.datetime.date().isoformat(), txt.format(*args)]
logging.error(','.join(out))
def logdebug(self, txt, *args):
out = [self.datetime.date().isoformat(), txt.format(*args)]
logging.debug(','.join(out))
def logdata(self):
txt = []
txt += ['{:.2f}'.format(self.data.open[0])]
txt += ['{:.2f}'.format(self.data.high[0])]
txt += ['{:.2f}'.format(self.data.low[0])]
txt += ['{:.2f}'.format(self.data.close[0])]
txt += ['{:.2f}'.format(self.data.volume[0])]
self.loginfo(','.join(txt))
def run(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
data = bt.feeds.BacktraderCSVData(dataname=args.data)
cerebro.adddata(data) # create and add data feed
cerebro.addstrategy(St) # add the strategy
cerebro.broker.set_cash(args.cash) # set broker cash
if args.fractional: # use the fractional scheme if requested
cerebro.broker.addcommissioninfo(CommInfoFractional())
cerebro.run() # execute
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def logconfig(pargs):
if pargs.quiet:
verbose_level = logging.ERROR
else:
verbose_level = logging.INFO - pargs.verbose * 10 # -> DEBUG
logger = logging.getLogger()
for h in logger.handlers: # Remove all loggers from root
logger.removeHandler(h)
stream = sys.stdout if not pargs.stderr else sys.stderr # choose stream
logging.basicConfig(
stream=stream,
format="%(message)s", # format="%(levelname)s: %(message)s",
level=verbose_level,
)
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Fractional Sizes with CommInfo',
)
pgroup = parser.add_argument_group('Data Options')
parser.add_argument('--data', default='../../datas/2005-2006-day-001.txt',
help='Data to read in')
pgroup = parser.add_argument_group(title='Broker Arguments')
pgroup.add_argument('--cash', default=100000.0, type=float,
help='Starting cash to use')
pgroup.add_argument('--fractional', action='store_true',
help='Use fractional commission info')
pgroup = parser.add_argument_group(title='Plotting Arguments')
pgroup.add_argument('--plot', default='', nargs='?', const='{}',
metavar='kwargs', help='kwargs: "k1=v1,k2=v2,..."')
pgroup = parser.add_argument_group('Verbosity Options')
pgroup.add_argument('--stderr', action='store_true',
help='Log to stderr, else to stdout')
pgroup = pgroup.add_mutually_exclusive_group()
pgroup.add_argument('--quiet', '-q', action='store_true',
help='Silent (errors will be reported)')
pgroup.add_argument('--verbose', '-v', action='store_true',
help='Increase verbosity level')
# Parse and process some args
pargs = parser.parse_args(pargs)
logconfig(pargs) # config logging
return pargs
if __name__ == '__main__':
run()
击败随机进入
原文:
www.backtrader.com/blog/2019-08-22-practical-backtesting-replication/practical-replication/
最近有一些关于在reddit/r/algotrading上成功复制已发布的算法交易策略的帖子。首先
-
我已经重现了 130 多篇关于“预测股市”的研究论文,从头开始编码,并记录了结果。这是我学到的东西
因为这里已被删除,快速摘要如下:
-
这些策略不起作用
-
如果作者声称某种策略停止工作是由于阿尔法衰减,那么测试将针对过去的数据运行,而且仍然无法工作
-
底线是:这都是过度拟合,p-值调整或微小的阿尔法,不需要衰减,因为佣金已经破坏了阿尔法。
-
Artem Kaznatcheev撰写的复制问题的复制品在以下位置:
接下来是:
前两者是理论的(即使第一个提到已经实施了 130 种策略),而“过度拟合”提供了实际代码。
在这么多事情发生的情况下,那么试图复制一些已经发布但不是作为论文的东西呢,就像在“过度拟合”案例中一样,采取实践方法。某些发表在著名书籍中的东西。
目标:“尝试击败随机进入”。这是本书的第 3 部分第八章中的一节:
书中提出了一种有结构的方法参与算法交易,特别强调:仓位大小和仓位管理(即:何时实际退出交易)。这比例如入场设置更重要,后者显然大多数人认为是主要驱动因素。
在第八章中,范·K·塞尔普与汤姆·巴索交谈并说:“从你的讲话听起来,你似乎可以通过随机进入并智能地确定仓位来稳定赚钱。” 对此的回答是他可能可以。
规则:
-
基于抛硬币的进入
-
始终处于市场中 - 多头或空头
-
一旦给出退出信号,立即重新进入
-
市场的波动性由 10 天的“平均真实范围”的“指数移动平均”确定
-
从收盘价的距离追踪止损是波动性的 3 倍
-
止损只能朝着交易的方向移动
-
固定仓位(1 份合约)或 1%风险模型(书中第十二章)
结果
-
测试对 10 个市场
-
固定投注:80%的时间赚钱
-
1%风险模型:100%的时间赚钱
-
可靠性水平:38%(获胜交易的百分比)
缺失的部分:
-
测试市场
-
测试期间
-
如果始终处于市场中意味着“今天”关闭交易并在“明天”重新进入市场,或者意味着同时发出关闭/重新开放订单。
这实际上是最容易克服的。
对于最后两个项目,书中说 1991 年进行了谈话并使用了期货。为了对书本公平,将使用 1991 年之前的期货数据。鉴于提到了10 日指数移动平均线,还假设了 1 天的价格条。
最明显的问题似乎是正确地获得算法,但在这种情况下,书中对简单算法和结果的描述做得很好。为了完成它,让我们总结一下 “百分比风险模型”(书中称为“模型 3”的)第十二章。
-
最大损失:限制在账户价值的x%(即:百分比风险) -
合约风险:根据给定的算法,它将是初始止损距离(3 倍波动性)乘以未来的倍数 -
合同金额:
最大损失 / 合约风险
复制细节
数据
将使用 1985 年至 1990 年(即 6 年)的 CL(原油)期货数据。合同规格为:
-
跳变大小:
0.01(即:每个点 100 跳变) -
每个跳变成本:
$10
有了这个想法,我们将使用1000乘以每个1 点的乘数(100 个跳点/点 x 10 美元/跳 = 1000 美元)
佣金
每次交易的合同将使用2.00货币单位(类似 IB)
一些实现细节
抛硬币被建模为一个指标,以便于可视化翻转的位置(例如,如果几个条目朝着相同的方向,这在随机情况下是可以预料的)
为了也能很好地可视化止损及其移动方式,止损价格计算和逻辑也嵌入到了指标中。注意,止损计算逻辑有两个不同的阶段
-
当交易开始时,止损价格必须与前一个止损价格无关地设置在给定距离之内
-
当交易进行时,如果可能,止损价格将根据趋势进行调整。
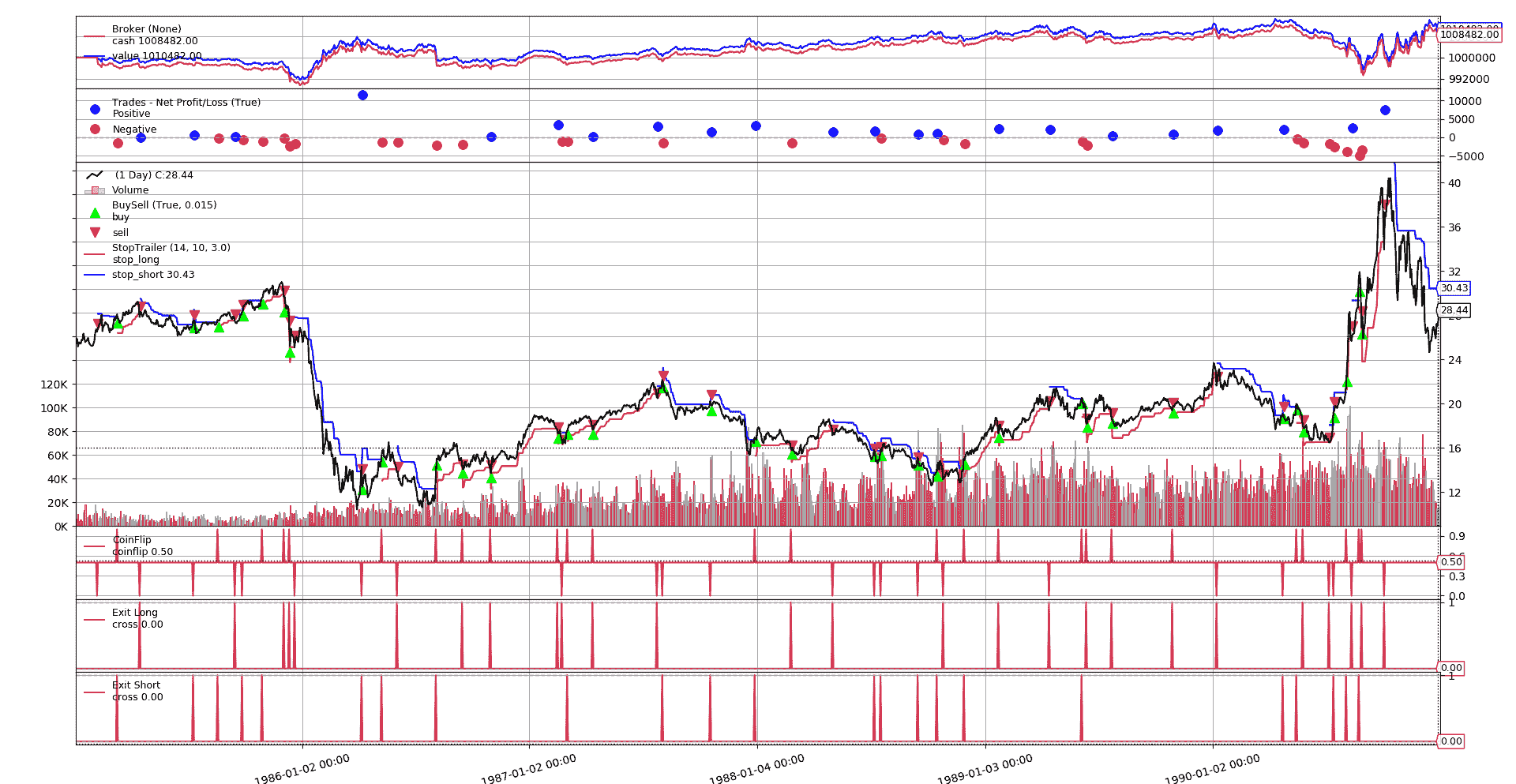
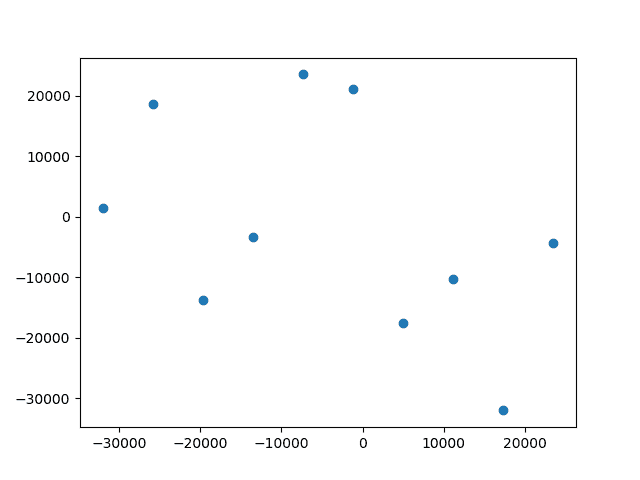
绘图
代码产生两种类型的图表
-
包含单次测试运行详细信息的图表(
--plot选项)。在运行单次迭代(--iterations 1)时使用它最有意义 -
显示运行的利润和损失的散点图。
1 样本
10 次运行的#2 样本
脚本的样本调用
固定大小投注和绘图的单次运行
./vanktharp-coinflip.py --years 1985-1990 --fixedsize --sizer stake=1 --iterations 1 --plot
**** Iteration: 1
-- PNL: 10482.00
-- Trades 49 - Won 22 - %_Won: 0.45
**** Summary of Runs
-- Total : 1
-- Won : 1
-- % Won : 1.00
**** Summary of Trades
-- Total : 49
-- Total Won : 22
-- % Total Won : 0.45
使用 1%风险模型、10 次迭代和散点图的 100 次运行
(为了实际目的,输出已缩短)
$ ./vanktharp-coinflip.py --years 1985-1990 --percrisk --sizer percrisk=0.01 --iterations 100 --scatter
**** Iteration: 1
-- PNL: -18218.00
-- Trades 60 - Won 24 - %_Won: 0.40
**** Iteration: 2
...
...
**** Iteration: 100
-- PNL: 111366.00
-- Trades 50 - Won 26 - %_Won: 0.52
**** Summary of Runs
-- Total : 100
-- Won : 50
-- % Won : 0.50
**** Summary of Trades
-- Total : 5504
-- Total Won : 2284
-- % Total Won : 0.41
测试运行混合
进行了 100 次迭代的 10 次测试运行,混合了以下变量:
-
固定大小的投注额为 1,或者使用 1%的百分比风险模型。
-
在同一根或连续的几根柱子上执行入场/出场操作
结果摘要
-
平均而言,有 49%的交易是盈利的。固定大小的投注在测试中保持在 50%左右,而百分比风险模型的变化较大,一次测试的盈利交易率最低为 39%,另一次测试的盈利交易率最高为 65%(共进行了 10 次测试)。
-
平均而言,有 39%的交易是盈利的(小偏差)
回想书中所说的:
-
当使用固定大小的投注额为 1 时,有 80%的交易是盈利的。
-
使用 1%百分比风险模型,有 100%的交易是盈利的。
-
有 38%的盈利交易
因此似乎:
- 只有最后一项被复制了。
结论
正如阿尔捷姆·卡兹纳切夫所指出的,复制危机可能是由于:
-
使用错误的数据集
-
未能正确实施算法
或者原始实施可能并没有遵循自己的规则,或者并没有发布所有细节。
注意
无论如何,我个人仍然建议阅读这本书。未能复制特定情况并不意味着这本书不值得一读,它展示了一种实用的算法交易方法。
完整的脚本
祝好运!
代码也可在:
#!/usr/bin/env python
# -*- coding: utf-8; py-indent-offset:4 -*-
###############################################################################
# Copyright (C) 2019 Daniel Rodriguez - MIT License
# - https://opensource.org/licenses/MIT
# - https://en.wikipedia.org/wiki/MIT_License
###############################################################################
import argparse
import random
import pandas as pd
import backtrader as bt
def read_dataframe(filename, years):
colnames = ['ticker', 'period', 'date', 'time',
'open', 'high', 'low', 'close', 'volume', 'openinterest']
colsused = ['date',
'open', 'high', 'low', 'close', 'volume', 'openinterest']
df = pd.read_csv(filename,
skiprows=1, # using own column names, skip header
names=colnames,
usecols=colsused,
parse_dates=['date'],
index_col='date')
if years: # year or year range specified
ysplit = years.split('-')
# left side limit
mask = df.index >= ((ysplit[0] or '0001') + '-01-01') # support -YYYY
# right side liit
if len(ysplit) > 1: # multiple or open ended (YYYY-ZZZZ or YYYY-)
if ysplit[1]: # open ended if not years[1] (YYYY- format)
mask &= df.index <= (ysplit[1] + '-12-31')
else: # single year specified YYYY
mask &= df.index <= (ysplit[0] + '-12-31')
df = df.loc[mask] # select the given date range
return df
# DEFAULTS - CAN BE CHANGED VIA COMMAND LINE OPTIONS
COMMINFO_DEFAULT = dict(
stocklike=False, # Futures-like
commtype=bt.CommissionInfo.COMM_FIXED, # fixed price per asset
commission=2.0, # Standard IB Price for futures
mult=1000.0, # multiplier
margin=2000.0, # $50 x 50 => $2500
)
class PercentRiskSizer(bt.Sizer):
'''Sizer modeling the Percentage Risk sizing model of Van K. Tharp'''
params = dict(percrisk=0.01) # 1% percentage risk
def _getsizing(self, comminfo, cash, data, isbuy):
# Risk per 1 contract
risk = comminfo.p.mult * self.strategy.stoptrailer.stop_dist[0]
# % of account value to risk
torisk = self.broker.get_value() * self.p.percrisk
return torisk // risk # size to risk
class CoinFlip(bt.Indicator):
lines = ('coinflip',)
HEAD, TAIL = 1, 0
def next(self):
self.l.coinflip[0] = 0.5 # midway
pass
def flip(self):
# self.l.coinflip[0] = cf = random.randrage(-1, 2, 2) # -1 or 1
self.l.coinflip[0] = cf = random.randint(0, 1)
return cf
def head(self, val=None):
if val is None:
return self.lines[0] == self.HEAD
return val == self.HEAD
class StopTrailer(bt.Indicator):
_nextforce = True # force system into step by step calcs
lines = ('stop_long', 'stop_short',)
plotinfo = dict(subplot=False, plotlinelabels=True)
params = dict(
atrperiod=14,
emaperiod=10,
stopfactor=3.0,
)
def __init__(self):
self.strat = self._owner # alias for clarity
# Volatility which determines stop distance
atr = bt.ind.ATR(self.data, period=self.p.atrperiod)
emaatr = bt.ind.EMA(atr, period=self.p.emaperiod)
self.stop_dist = emaatr * self.p.stopfactor
# Running stop price calc, applied in next according to market pos
self.s_l = self.data - self.stop_dist
self.s_s = self.data + self.stop_dist
def next(self):
# When entering the market, the stop has to be set
if self.strat.entering > 0: # entering long
self.l.stop_long[0] = self.s_l[0]
elif self.strat.entering < 0: # entering short
self.l.stop_short[0] = self.s_s[0]
else: # In the market, adjust stop only in the direction of the trade
if self.strat.position.size > 0:
self.l.stop_long[0] = max(self.s_l[0], self.l.stop_long[-1])
elif self.strat.position.size < 0:
self.l.stop_short[0] = min(self.s_s[0], self.l.stop_short[-1])
class St1(bt.Strategy):
SHORT, NONE, LONG = -1, 0, 1
params = dict(
atrperiod=14, # measure volatility over x days
emaperiod=10, # smooth out period for atr volatility
stopfactor=3.0, # actual stop distance for smoothed atr
verbose=False, # print out debug info
samebar=True, # close and re-open on samebar
)
def __init__(self):
self.coinflip = CoinFlip()
# Trailing Stop Indicator
self.stoptrailer = st = StopTrailer(atrperiod=self.p.atrperiod,
emaperiod=self.p.emaperiod,
stopfactor=self.p.stopfactor)
# Exit Criteria (Stop Trail) for long / short positions
self.exit_long = bt.ind.CrossDown(self.data,
st.stop_long, plotname='Exit Long')
self.exit_short = bt.ind.CrossUp(self.data,
st.stop_short, plotname='Exit Short')
def start(self):
self.entering = 0
self.start_val = self.broker.get_value()
def stop(self):
self.stop_val = self.broker.get_value()
self.pnl_val = self.stop_val - self.start_val
self.log('Start Value: {:.2f}', self.start_val)
self.log('Final Value: {:.2f}', self.stop_val)
self.log('PNL Value: {:.2f}', self.pnl_val)
def notify_trade(self, trade):
if trade.size > 0:
self.log('Long Entry at: {:.2f}', trade.price)
elif trade.size < 0:
self.log('Short Entry at: {:.2f}', trade.price)
else: # not trade.size - trade is over
self.log('Trade PNL: {:.2f}', trade.pnlcomm)
def next(self):
self.logdata()
# logic
closing = None
if self.position.size > 0: # In the market - Long
self.log('Long Stop Price: {:.2f}', self.stoptrailer.stop_long[0])
if self.exit_long:
closing = self.close()
elif self.position.size < 0: # In the market - Short
self.log('Short Stop Price {:.2f}', self.stoptrailer.stop_short[0])
if self.exit_short:
closing = self.close()
self.entering = self.NONE
if not self.position or (closing and self.p.samebar):
# Not in the market or closing pos and reenter in samebar
if self.coinflip.flip():
self.entering = self.LONG if self.buy() else self.NONE
else:
self.entering = self.SHORT if self.sell() else self.NONE
def logdata(self):
if self.p.verbose: # logging
txt = []
txt += ['{:.2f}'.format(self.position.size)]
txt += ['{:.2f}'.format(self.data.open[0])]
txt += ['{:.2f}'.format(self.data.high[0])]
txt += ['{:.2f}'.format(self.data.low[0])]
txt += ['{:.2f}'.format(self.data.close[0])]
self.log(','.join(txt))
def log(self, txt, *args):
if self.p.verbose:
out = [self.datetime.date().isoformat(), txt.format(*args)]
print(','.join(out))
def runstrat(args):
cerebro = bt.Cerebro()
# Data feed kwargs
dataargs = dict(dataname=read_dataframe(args.data, args.years))
dataargs.update(eval('dict(' + args.dargs + ')'))
cerebro.adddata(bt.feeds.PandasData(**dataargs))
# Strategy
cerebro.addstrategy(St1, **eval('dict(' + args.strat + ')'))
# Broker
brokerargs = dict(cash=args.cash)
brokerargs.update(eval('dict(' + args.broker + ')'))
cerebro.broker = bt.brokers.BackBroker(**brokerargs)
# Commission
commargs = COMMINFO_DEFAULT
commargs.update(eval('dict(' + args.commission + ')'))
cerebro.broker.setcommission(**commargs)
# Sizer
szcls = PercentRiskSizer if args.percrisk else bt.sizers.FixedSize
cerebro.addsizer(szcls, **(eval('dict(' + args.sizer + ')')))
# Analyze the trades
cerebro.addanalyzer(bt.analyzers.TradeAnalyzer, _name='trades')
# Execute
strats = cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
return strats[0]
def run(args=None):
args = parse_args(args)
results = []
sum_won_trades = 0
sum_total_trades = 0
for i in range(0, args.iterations):
strat = runstrat(args)
pnl = strat.pnl_val
results.append(pnl)
trades = strat.analyzers.trades.get_analysis()
print('**** Iteration: {:4d}'.format(i + 1))
print('-- PNL: {:.2f}'.format(pnl))
total_trades = trades.total.closed
total_won = trades.won.total
perc_won = total_won / total_trades
print('-- Trades {} - Won {} - %_Won: {:.2f}'.format(
total_trades, total_won, perc_won))
sum_won_trades += total_won
sum_total_trades += total_trades
total = len(results)
won = sum(1 for x in results if x > 0)
print('**** Summary of Runs')
print('-- Total : {:8d}'.format(total))
print('-- Won : {:8d}'.format(won))
print('-- % Won : {:.2f}'.format(won / total))
perc_won = sum_won_trades / sum_total_trades
print('**** Summary of Trades')
print('-- Total : {:8d}'.format(sum_total_trades))
print('-- Total Won : {:8d}'.format(sum_won_trades))
print('-- % Total Won : {:.2f}'.format(perc_won))
if args.scatter:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(min(results), max(results), num=len(results))
y = np.asarray(results)
plt.scatter(x, y)
plt.show()
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Van K. Tharp/Basso Random Entry Scenario',
)
parser.add_argument('--iterations', default=1, type=int,
help='Number of iterations to run the system')
pgroup = parser.add_argument_group(title='Data Options')
pgroup.add_argument('--data', default='cl-day-001.txt',
help='Data to read in')
pgroup.add_argument('--years', default='',
help='Formats: YYYY-ZZZZ / YYYY / YYYY- / -ZZZZ')
parser.add_argument('--dargs', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
pgroup = parser.add_argument_group(title='Cerebro Arguments')
pgroup.add_argument('--cerebro', default='', metavar='kwargs',
help='Cerebro kwargs in key=value format')
pgroup = parser.add_argument_group(title='Commission Arguments')
pgroup.add_argument('--commission', default=str(COMMINFO_DEFAULT),
metavar='kwargs',
help='CommInfo kwargs in key=value format')
pgroup = parser.add_argument_group(title='Broker Arguments')
pgroup.add_argument('--broker', default='', metavar='kwargs',
help='Broker kwargs in key=value format')
pgroup.add_argument('--cash', default=1000000.0, type=float,
help='Default cash')
pgroup = parser.add_argument_group(title='Strategy Arguments')
pgroup.add_argument('--strat', default='', metavar='kwargs',
help='Strategy kwargs in key=value format')
pgroup = parser.add_argument_group(title='Sizer Options')
pgroup.add_argument('--sizer', default='', metavar='kwargs',
help='Sizer kwargs in key=value format')
pgroup = pgroup.add_mutually_exclusive_group()
pgroup.add_argument('--percrisk', action='store_true',
help='Use Percrisk Sizer')
pgroup.add_argument('--fixedsize', action='store_true',
help='Use Fixed Statke Sizer')
pgroup = parser.add_argument_group(title='Plotting Options')
pgroup.add_argument('--plot', default='', nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
pgroup.add_argument('--scatter', action='store_true',
help='Plot a scatter diagram of PNL results')
return parser.parse_args(pargs)
if __name__ == '__main__':
run()
使用保守公式重新平衡
原文:
www.backtrader.com/blog/2019-07-19-rebalancing-conservative/rebalancing-conservative/
保守公式方法在本文中提出:The Conservative Formula in Python: Quantitative Investing made Easy
这是许多可能的重新平衡方法之一,但是易于理解。方法概要:
-
从
Y(1000 中的 100)的宇宙中选取了x支股票。 -
选择标准是:
-
低波动率
-
高净支付收益
-
高动量
-
每月重新平衡
-
有了这个想法,让我们去提出backtrader中的一种可能实现吧。
数据
即使有一个获胜的策略,如果没有为该策略提供数据,也不会真正获胜。这意味着必须考虑数据的外观以及如何加载数据。
假定一组CSV(“逗号分隔值”)文件可用,包含以下功能
-
ohlcv月度数据 -
在
v后增加了一个额外的字段,包含净支付收益(npy),以获取ohlcvn数据集。
因此,CSV数据的格式如下
date, open, high, low, close, volume, npy
2001-12-31, 1.0, 1.0, 1.0, 1.0, 0.5, 3.0
2002-01-31, 2.0, 2.5, 1.1, 1.2, 3.0, 5.0
...
即:每月一行。现在数据加载器引擎可以准备好创建一个简单的扩展,与backtrader一起提供的通用内置 CSV 加载器。
class NetPayOutData(bt.feeds.GenericCSVData):
lines = ('npy',) # add a line containing the net payout yield
params = dict(
npy=6, # npy field is in the 6th column (0 based index)
dtformat='%Y-%m-%d', # fix date format a yyyy-mm-dd
timeframe=bt.TimeFrame.Months, # fixed the timeframe
openinterest=-1, # -1 indicates there is no openinterest field
)
那就是。注意添加基本数据到ohlcv数据流是多么容易。
-
通过使用表达式
lines=('npy',)。其他常规字段(open、high等)已经包含在GenericCSVData中 -
通过使用
params = dict(npy=6)指示加载位置。其他字段具有预定义的位置。
时间框架也已在参数中更新,以反映数据的每月性质。
注意
请参阅文档 - 数据源参考 - GenericCSVData以获取实际字段和加载位置(所有这些都可以自定义)
数据加载器将必须用文件名正确实例化,但这是稍后的事情,当下面提供标准样板以获得完整的脚本时。
策略
让我们将逻辑放入标准的backtrader策略中。为了尽可能使其通用和可定制化,将使用与数据相同的params方法,就像之前用数据一样。
在深入研究策略之前,让我们考虑快速摘要中的一个要点
- 从
Y的宇宙中选择了x支股票。
策略本身并不负责向宇宙中添加股票,但负责选择。如果在代码中固定了x和Y,但宇宙中只添加了 50 支股票,仍然尝试选择 100 支股票,就会出现这样的情况。为了应对这种情况,将执行以下操作:
-
具有值为
0.10(即:10%)的selperc参数,表示从宇宙中选择的股票数量。这意味着如果有 1000 只股票,只会选择 100 只,如果宇宙由 50 只股票组成,则只会选择 5 只。
至于排名股票的公式,看起来像这样:
-
(动量 * 净支付) / 波动率这意味着具有较高动量、较高支付和较低波动率的股票将获得较高的分数。
对于momentum,将使用RateOfChange指标(又名ROC),它测量一段时间内价格的变化比率。
净支付已经是数据源的一部分。
要计算波动率,将使用股票的n-periods回报的标准差(n-periods,因为事物将保持为参数)。
有了这些信息,策略就可以用正确的参数进行初始化,设置指标和计算,这些将在每月迭代中使用。
首先是声明和参数。
class St(bt.Strategy):
params = dict(
selcperc=0.10, # percentage of stocks to select from the universe
rperiod=1, # period for the returns calculation, default 1 period
vperiod=36, # lookback period for volatility - default 36 periods
mperiod=12, # lookback period for momentum - default 12 periods
reserve=0.05 # 5% reserve capital
)
注意,上面未提及的内容已添加,即参数reserve=0.05(即5%),用于计算每只股票的百分比分配,保留一定资金在银行中。虽然对于模拟,人们可能想要使用 100%的资本,但这样做可能会遇到一些问题,如价格差距、浮点精度等,最终可能会错过一些市场入场机会。
在任何其他事情之前,创建一个小的日志记录方法,它将允许记录组合如何重新平衡。
def log(self, arg):
print('{} {}'.format(self.datetime.date(), arg))
在__init__方法的开头,计算要排名的股票数量,并应用保留资本参数以确定银行的每只股票百分比。
def __init__(self):
# calculate 1st the amount of stocks that will be selected
self.selnum = int(len(self.datas) * self.p.selcperc)
# allocation perc per stock
# reserve kept to make sure orders are not rejected due to
# margin. Prices are calculated when known (close), but orders can only
# be executed next day (opening price). Price can gap upwards
self.perctarget = (1.0 - self.p.reserve) % self.selnum
最后,初始化完成,计算每只股票的波动率和动量指标,然后将其应用于每只股票的排名公式计算中。
# returns, volatilities and momentums
rs = [bt.ind.PctChange(d, period=self.p.rperiod) for d in self.datas]
vs = [bt.ind.StdDev(ret, period=self.p.vperiod) for ret in rs]
ms = [bt.ind.ROC(d, period=self.p.mperiod) for d in self.datas]
# simple rank formula: (momentum * net payout) / volatility
# the highest ranked: low vol, large momentum, large payout
self.ranks = {d: d.npy * m / v for d, v, m in zip(self.datas, vs, ms)}
现在是每个月迭代的时候了。排名在self.ranks字典中可用。每次迭代都必须对键/值对进行排序,以确定哪些项必须离开,哪些项必须成为组合的一部分(保留或添加)。
def next(self):
# sort data and current rank
ranks = sorted(
self.ranks.items(), # get the (d, rank), pair
key=lambda x: x[1][0], # use rank (elem 1) and current time "0"
reverse=True, # highest ranked 1st ... please
)
可迭代物按照相反顺序排序,因为排名公式为排名靠前的股票提供更高的分数。
现在是重新平衡的时候了。
重新平衡 1:获取排名靠前和具有开仓头寸的股票。
# put top ranked in dict with data as key to test for presence
rtop = dict(ranks[:self.selnum])
# For logging purposes of stocks leaving the portfolio
rbot = dict(ranks[self.selnum:])
这里发生了一些 Python 的诡计,因为使用了一个dict。原因是,如果将排名靠前的股票放入一个list中,Python会在内部使用运算符==来检查运算符in的存在。尽管不太可能,但两只股票可能在同一天具有相同的值。使用dict时,检查项存在性时会使用哈希值作为键的一部分。
注意:出于日志记录目的,还创建了rbot(排名底部),其中包含未在rtop中出现的股票。
为了后续区分必须离开投资组合的股票、那些只需重新平衡的股票以及新的排名靠前的股票,准备了投资组合中当前的股票列表。
# prepare quick lookup list of stocks currently holding a position
posdata = [d for d, pos in self.getpositions().items() if pos]
重新平衡 2:卖出不再排名靠前的股票
就像在现实世界中一样,在backtrader生态系统中,在买入之前卖出是必须的,以确保有足够的现金。
# remove those no longer top ranked
# do this first to issue sell orders and free cash
for d in (d for d in posdata if d not in rtop):
self.log('Exit {} - Rank {:.2f}'.format(d._name, rbot[d][0]))
self.order_target_percent(d, target=0.0)
当前拥有仓位但不再排名靠前的股票被出售(即target=0.0)。
注意
这里一个简单的self.close(data)就足够了,而不是明确说明目标百分比。
重新平衡 3:为所有排名靠前的股票发布目标订单
总投资组合价值随时间变化,已经在投资组合中的股票可能必须略微增加/减少当前仓位以匹配预期的百分比。order_target_percent是进入市场的理想方法,因为它会自动计算是否需要buy或sell订单。
# rebalance those already top ranked and still there
for d in (d for d in posdata if d in rtop):
self.log('Rebal {} - Rank {:.2f}'.format(d._name, rtop[d][0]))
self.order_target_percent(d, target=self.perctarget)
del rtop[d] # remove it, to simplify next iteration
在将新股票添加到投资组合之前,重新平衡已有仓位的股票,因为新股票只会发布buy订单并消耗现金。在重新平衡后从rtop[data].pop()中移除现有股票后,rtop中剩余的股票是将新添加到投资组合中的股票。
# issue a target order for the newly top ranked stocks
# do this last, as this will generate buy orders consuming cash
for d in rtop:
self.log('Enter {} - Rank {:.2f}'.format(d._name, rtop[d][0]))
self.order_target_percent(d, target=self.perctarget)
运行所有并评估它!
拥有数据加载器类和策略是不够的。就像任何其他框架一样,需要一些样板。以下代码使其成为可能。
def run(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
dkwargs = dict(**eval('dict(' + args.dargs + ')'))
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
if args.fromdate:
fmt = dtfmt + tmfmt * ('T' in args.fromdate)
dkwargs['fromdate'] = datetime.datetime.strptime(args.fromdate, fmt)
if args.todate:
fmt = dtfmt + tmfmt * ('T' in args.todate)
dkwargs['todate'] = datetime.datetime.strptime(args.todate, fmt)
# add all the data files available in the directory datadir
for fname in glob.glob(os.path.join(args.datadir, '*')):
data = NetPayOutData(dataname=fname, **dkwargs)
cerebro.adddata(data)
# add strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# set the cash
cerebro.broker.setcash(args.cash)
cerebro.run() # execute it all
# Basic performance evaluation ... final value ... minus starting cash
pnl = cerebro.broker.get_value() - args.cash
print('Profit ... or Loss: {:.2f}'.format(pnl))
在以下情况下完成:
-
解析参数并使其可用(这显然是可选的,因为一切都可以硬编码,但是良好的实践是好的实践)
-
创建一个
cerebro引擎实例。是的,这是西班牙语中的“大脑”,是框架的一部分,负责在黑暗中协调编排的操作。虽然它可以接受几个选项,但默认值对于大多数用例来说应该足够了。 -
加载数据文件,使用
args.datadir的简单目录扫描完成,并使用NetPayOutData加载所有文件,并将其添加到cerebro实例中 -
添加策略
-
设置现金,默认为
1,000,000。考虑到使用情况是100支股票在500支股票的宇宙中,似乎有些现金是可以用的。这也是一个可以更改的参数。 -
并调用
cerebro.run() -
最后评估性能
为了能够直接从命令行运行具有不同参数的事务,下面提供了一个启用了argparse的样板,其中包含了整个代码
性能评估
通过最终结果值的形式添加了一个简单的性能评估,即:最终净资产价值减去起始现金。
backtrader生态系统提供了一组内置性能分析器,也可以使用,如:SharpeRatio、Variability-Weighted Return、SQN等。参见文档 - 分析器参考
完整的脚本
最后,作品的大部分呈现为整体。享受吧!
import argparse
import datetime
import glob
import os.path
import backtrader as bt
class NetPayOutData(bt.feeds.GenericCSVData):
lines = ('npy',) # add a line containing the net payout yield
params = dict(
npy=6, # npy field is in the 6th column (0 based index)
dtformat='%Y-%m-%d', # fix date format a yyyy-mm-dd
timeframe=bt.TimeFrame.Months, # fixed the timeframe
openinterest=-1, # -1 indicates there is no openinterest field
)
class St(bt.Strategy):
params = dict(
selcperc=0.10, # percentage of stocks to select from the universe
rperiod=1, # period for the returns calculation, default 1 period
vperiod=36, # lookback period for volatility - default 36 periods
mperiod=12, # lookback period for momentum - default 12 periods
reserve=0.05 # 5% reserve capital
)
def log(self, arg):
print('{} {}'.format(self.datetime.date(), arg))
def __init__(self):
# calculate 1st the amount of stocks that will be selected
self.selnum = int(len(self.datas) * self.p.selcperc)
# allocation perc per stock
# reserve kept to make sure orders are not rejected due to
# margin. Prices are calculated when known (close), but orders can only
# be executed next day (opening price). Price can gap upwards
self.perctarget = (1.0 - self.p.reserve) / self.selnum
# returns, volatilities and momentums
rs = [bt.ind.PctChange(d, period=self.p.rperiod) for d in self.datas]
vs = [bt.ind.StdDev(ret, period=self.p.vperiod) for ret in rs]
ms = [bt.ind.ROC(d, period=self.p.mperiod) for d in self.datas]
# simple rank formula: (momentum * net payout) / volatility
# the highest ranked: low vol, large momentum, large payout
self.ranks = {d: d.npy * m / v for d, v, m in zip(self.datas, vs, ms)}
def next(self):
# sort data and current rank
ranks = sorted(
self.ranks.items(), # get the (d, rank), pair
key=lambda x: x[1][0], # use rank (elem 1) and current time "0"
reverse=True, # highest ranked 1st ... please
)
# put top ranked in dict with data as key to test for presence
rtop = dict(ranks[:self.selnum])
# For logging purposes of stocks leaving the portfolio
rbot = dict(ranks[self.selnum:])
# prepare quick lookup list of stocks currently holding a position
posdata = [d for d, pos in self.getpositions().items() if pos]
# remove those no longer top ranked
# do this first to issue sell orders and free cash
for d in (d for d in posdata if d not in rtop):
self.log('Leave {} - Rank {:.2f}'.format(d._name, rbot[d][0]))
self.order_target_percent(d, target=0.0)
# rebalance those already top ranked and still there
for d in (d for d in posdata if d in rtop):
self.log('Rebal {} - Rank {:.2f}'.format(d._name, rtop[d][0]))
self.order_target_percent(d, target=self.perctarget)
del rtop[d] # remove it, to simplify next iteration
# issue a target order for the newly top ranked stocks
# do this last, as this will generate buy orders consuming cash
for d in rtop:
self.log('Enter {} - Rank {:.2f}'.format(d._name, rtop[d][0]))
self.order_target_percent(d, target=self.perctarget)
def run(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
dkwargs = dict(**eval('dict(' + args.dargs + ')'))
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
if args.fromdate:
fmt = dtfmt + tmfmt * ('T' in args.fromdate)
dkwargs['fromdate'] = datetime.datetime.strptime(args.fromdate, fmt)
if args.todate:
fmt = dtfmt + tmfmt * ('T' in args.todate)
dkwargs['todate'] = datetime.datetime.strptime(args.todate, fmt)
# add all the data files available in the directory datadir
for fname in glob.glob(os.path.join(args.datadir, '*')):
data = NetPayOutData(dataname=fname, **dkwargs)
cerebro.adddata(data)
# add strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# set the cash
cerebro.broker.setcash(args.cash)
cerebro.run() # execute it all
# Basic performance evaluation ... final value ... minus starting cash
pnl = cerebro.broker.get_value() - args.cash
print('Profit ... or Loss: {:.2f}'.format(pnl))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=('Rebalancing with the Conservative Formula'),
)
parser.add_argument('--datadir', required=True,
help='Directory with data files')
parser.add_argument('--dargs', default='',
metavar='kwargs', help='kwargs in k1=v1,k2=v2 format')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in k1=v1,k2=v2 format')
parser.add_argument('--cash', default=1000000.0, type=float,
metavar='kwargs', help='kwargs in k1=v1,k2=v2 format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in k1=v1,k2=v2 format')
return parser.parse_args(pargs)
if __name__ == '__main__':
run()
MFI 通用
原文:
www.backtrader.com/blog/2019-07-17-mfi-generic/mfi-generic/
在最近的规范与非规范文章中,开发了MFI(也称为MoneyFlowIndicator)。
尽管它是以规范方式开发的,但仍然存在一些改进和通用化的空间。
让我们关注实现的第 1 行,创建典型价格的行
class MFI_Canonical(bt.Indicator):
lines = ('mfi',)
params = dict(period=14)
def __init__(self):
tprice = (self.data.close + self.data.low + self.data.high) / 3.0
mfraw = tprice * self.data.volume
...
典型的实例化可能如下所示
class MyMFIStrategy(bt.Strategy):
def __init__(self):
mfi = bt.MFI_Canonical(self.data)
这里的问题应该是显而易见的:“需要为具有close、low、high和volume组件(也称为backtrader生态系统中的lines)的指标提供输入”
当然,可能会有这样一种情况,即希望使用来自不同数据源(数据源的线或其他指标的线)的组件创建MoneyFlowIndicator,就像想要给close赋予更大的权重一样,而无需开发特定的指标。考虑到行业标准的OHLCV字段排序,一个多输入、额外加权close的实例化可能如下所示
class MyMFIStrategy2(bt.Strategy):
def __init__(self):
wclose = self.data.close * 5.0
mfi = bt.MFI_Canonical(self.data.high, self.data.low,
wclose, self.data.volume)
或者因为用户之前使用过ta-lib,喜欢多输入样式。
支持多个输入
backtrader 尽可能地遵循pythonic的原则,self.datas数组包含系统中数据源的列表(并且自动提供给您的策略),可以查询其长度。让我们使用这个来区分调用者想要的内容,并正确计算tprice和mfraw
`def init(self):
if len(self.datas) == 1:
# 传递了 1 个数据源,必须有分量
tprice = (self.data.close + self.data.low + self.data.high) / 3.0
mfraw = tprice * self.data.volume
否则:
# 如果有多个数据源,则按照 OHLCV 的顺序提取各个分量
tprice = (self.data0 + self.data1 + self.data2) / 3.0
mfraw = tprice * self.data3
# 与之前的实现相比没有变化
flowpos = bt.ind.SumN(mfraw * (tprice > tprice(-1)), period=self.p.period)
flowneg = bt.ind.SumN(mfraw * (tprice < tprice(-1)), period=self.p.period)
mfiratio = bt.ind.DivByZero(flowpos, flowneg, zero=100.0)
self.l.mfi = 100.0 - 100.0 / (1.0 + mfiratio)`
注意
请注意,如何引用各个分量,例如self.dataX(例如self.data0、self.data1)
这与使用self.datas[x]相同,如self.datas[0]...
让我们从图形上看到,这个指标产生了与规范相同的结果,当多个输入对应于数据源的原始组件时也是如此。为此,它将在策略中运行,如下所示
class MyMFIStrategy2(bt.Strategy):
def __init__(self):
MFI_Canonical(self.data)
MFI_MultipleInputs(self.data, plotname='MFI Single Input')
MFI_MultipleInputs(self.data.high,
self.data.low,
self.data.close,
self.data.volume,
plotname='MFI Multiple Inputs')
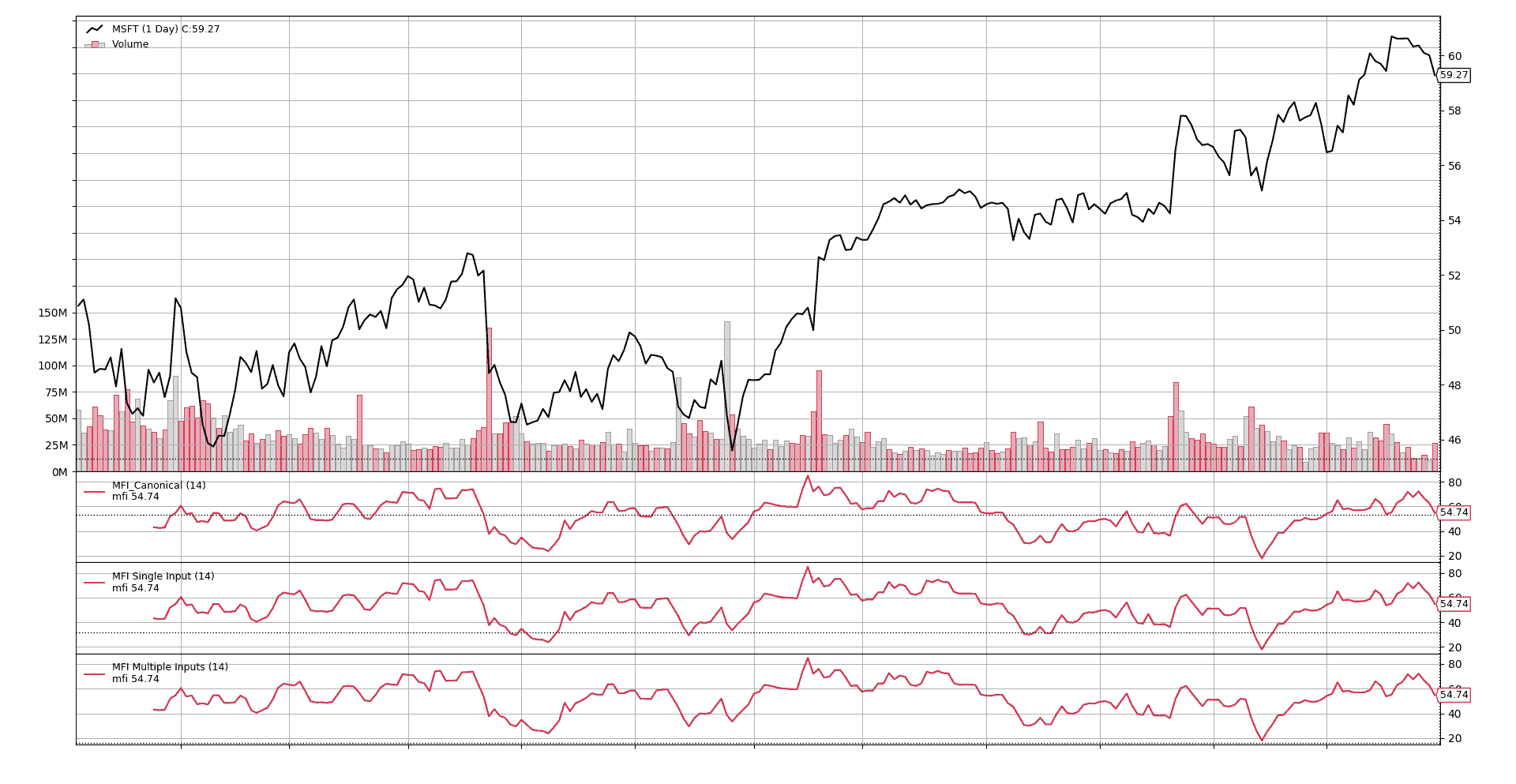
无需每个值都进行检查,从图片上显然可以看出这三个结果是相同的。
最后让我们看看如果给close加上更多的权重会发生什么。让我们这样运行。
class MyMFIStrategy2(bt.Strategy):
def __init__(self):
MFI_MultipleInputs(self.data)
MFI_MultipleInputs(self.data.high,
self.data.low,
self.data.close * 5.0,
self.data.volume,
plotname='MFI Close * 5.0')
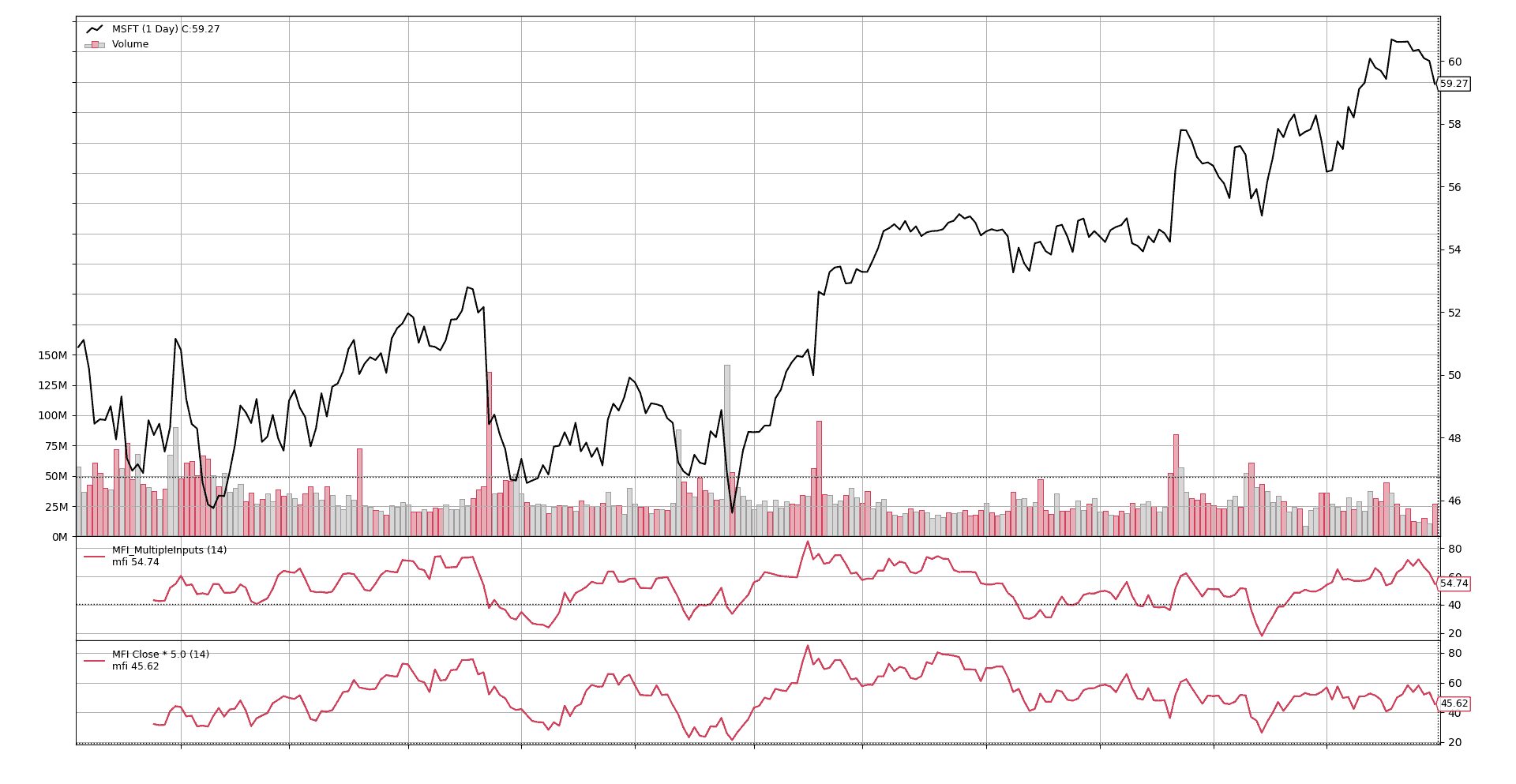
这是否有意义留给读者决定,但可以清楚地看到给close添加权重已经改变了模式。
结论
通过简单使用 Pythonic 的len,一个人可以将一个使用多个组件(和固定名称)的数据源的指标转换为接受多个通用输入的指标。
规范与非规范指标
原文:
www.backtrader.com/blog/2019-07-08-canonical-or-not/canonical-or-not/
这个问题已经出现了几次,或多或少地是这样的:
- 如何使用backtrader最佳/规范地实现这个或那个?
作为backtrader的目标之一是灵活地支持尽可能多的情况和用例,答案很简单:“至少有几种方法”。总结一下指标,这是最常见的问题:
-
__init__方法中的 100%声明 -
next方法中的 100%逐步操作 -
在复杂情况下,将上述两者混合在一起,以满足声明部分无法覆盖所有所需计算的需求。
对backtrader内置指标的快速查看表明,它们都是以声明方式实现的。原因是
-
更容易做到
-
更易读
-
更优雅
-
矢量化和基于事件的实现会自动管理
什么?!?!自动实现矢量化??
是的。如果一个指标完全在__init_方法中实现,Python 中的元类和运算符重载的魔法将产生以下结果
-
矢量化实现(在运行回测时的默认设置)
-
基于事件的实现(例如用于实时交易)
另一方面,如果指标的任何部分在next方法中实现:
-
这是直接用于基于事件的运行的代码。
-
矢量化将通过在后台为每个数据点调用
next方法来模拟注意
这意味着即使某个特定指标没有矢量化实现,所有其他具有矢量化实现的指标仍将以矢量化方式运行
资金流指数:一个例子
社区用户@Rodrigo Brito发布了一个使用next方法进行实现的"资金流指数(Money Flow Index)"指标的版本。
代码
class MFI(bt.Indicator):
lines = ('mfi', 'money_flow_raw', 'typical', 'money_flow_pos', 'money_flow_neg')
plotlines = dict(
money_flow_raw=dict(_plotskip=True),
money_flow_pos=dict(_plotskip=True),
money_flow_neg=dict(_plotskip=True),
typical=dict(_plotskip=True),
)
params = (
('period', 14),
)
def next(self):
typical_price = (self.data.close[0] + self.data.low[0] + self.data.high[0]) / 3
money_flow_raw = typical_price * self.data.volume[0]
self.lines.typical[0] = typical_price
self.lines.money_flow_raw[0] = money_flow_raw
self.lines.money_flow_pos[0] = money_flow_raw if self.lines.typical[0] >= self.lines.typical[-1] else 0
self.lines.money_flow_neg[0] = money_flow_raw if self.lines.typical[0] <= self.lines.typical[-1] else 0
pos_period = math.fsum(self.lines.money_flow_pos.get(size=self.p.period))
neg_period = math.fsum(self.lines.money_flow_neg.get(size=self.p.period))
if neg_period == 0:
self.lines.mfi[0] = 100
return
self.lines.mfi[0] = 100 - 100 / (1 + pos_period / neg_period)
注意
保持原样发布,包括需要水平滚动的长行
@Rodrigo Brito 已经注意到临时线条的使用(除了mfi之外的所有线条)可能需要优化。确实,但在作者的谦逊意见中,实际上一切都可以稍加优化。
为了有共同的工作基础,可以使用StockCharts的"资金流指数(Money Flow Index)"定义,并查看上述实现是否良好。这是链接:
有了这个,一个快速的规范实现MFI指标
class MFI_Canonical(bt.Indicator):
lines = ('mfi',)
params = dict(period=14)
def __init__(self):
tprice = (self.data.close + self.data.low + self.data.high) / 3.0
mfraw = tprice * self.data.volume
flowpos = bt.ind.SumN(mfraw * (tprice > tprice(-1)), period=self.p.period)
flowneg = bt.ind.SumN(mfraw * (tprice < tprice(-1)), period=self.p.period)
mfiratio = bt.ind.DivByZero(flowpos, flowneg, zero=100.0)
self.l.mfi = 100.0 - 100.0 / (1.0 + mfiratio)
人们应该立即注意到
-
定义了一个单行
mfi。没有临时变量。 -
没有需要
[0]数组索引的需求,看起来更干净 -
这里或那里没有单个
if -
更紧凑但更易读
如果将两个运行对同一数据集绘制的图表,会是这样的
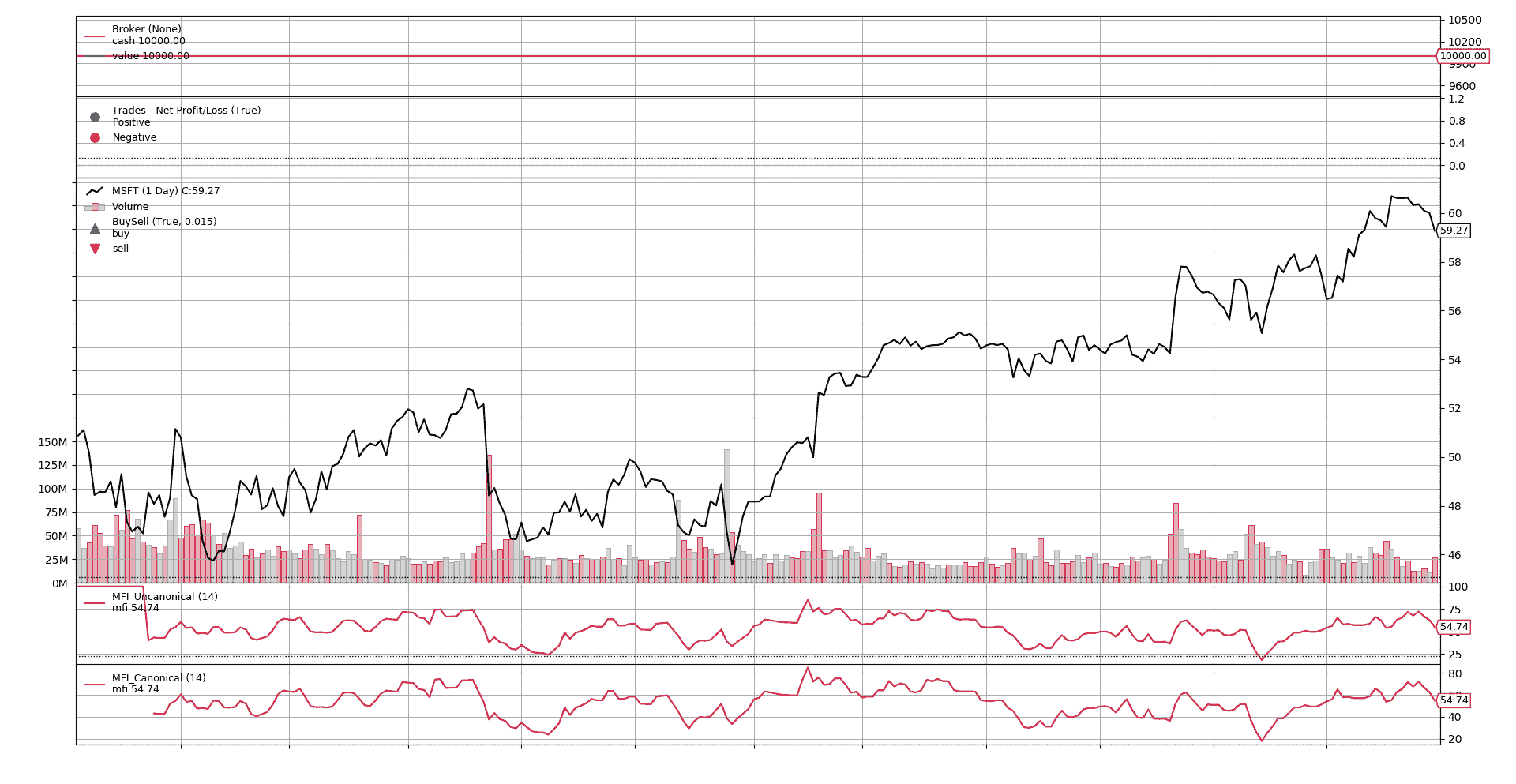
图表显示,规范和非规范版本在开始时除外,显示相同的值和发展。
-
非规范版本从一开始就提供值
-
它提供了无意义的值(100.0,直到提供额外的 1 个值,这也不好),因为它无法正确地提供
相比之下:
-
规范版本在达到最短预热时间后自动开始提供数值。
-
没有人为干预是必需的(肯定是 "人工智能" 或 "机器学习",... 双关语)
查看受影响区域的近景图片
注意
当然,可以尝试通过以下方式缓解非规范版本的这种情况:
- 从已经具有
period参数并知道如何处理它的bt.ind.PeriodN子类化(并在__init__期间调用super)
还要注意,规范版本也像逐步next代码一样考虑了公式中可能出现的除零情况。
if neg_period == 0:
self.lines.mfi[0] = 100
return
self.lines.mfi[0] = 100 - 100 / (1 + pos_period / neg_period)
这是另一种方法
mfiratio = bt.ind.DivByZero(flowpos, flowneg, zero=100.0)
self.l.mfi = 100.0 - 100.0 / (1.0 + mfiratio)
不是有很多行,一个return语句和对输出行的不同赋值,而是对mfiratio计算的单个声明和对输出行mfi的单个赋值(按照StockCharts公式)
结论
希望这能解释在规范(即:在__init__中声明式)或非规范方式(逐步进行,使用数组索引在next中)中实现某些内容时的差异。
使用 backtrader 进行买入并持有
原文:
www.backtrader.com/blog/2019-06-13-buy-and-hold/buy-and-hold/
这有时是用来测试给定策略表现的基线之一,即:“如果精心设计的逻辑无法击败简单的买入并持有方法,那么该策略可能不值一文”
一个简单的“买入并持有”策略,只需在第一个传入的数据点上买入,并查看最后一个数据点可用的投资组合价值。
提示
下面的代码片段省略了导入和设置样板。完整脚本在末尾可用。
在收盘时作弊
在许多情况下,像买入并持有这样的方法并不意味着要精确复制订单执行和价格匹配。这是关于评估大量数据。这就是为什么backtrader中默认经纪人的cheat-on-close模式将被激活。这意味着
-
由于只会发出
Market订单,执行将根据当前的close价格进行。 -
请注意,当价格可用于交易逻辑(在本例中为
close)时,该价格已经消失。它可能会在一段时间内可用,但实际上无法保证执行。
买入并忘记
class BuyAndHold_1(bt.Strategy):
def start(self):
self.val_start = self.broker.get_cash() # keep the starting cash
def nextstart(self):
# Buy all the available cash
size = int(self.broker.get_cash() / self.data)
self.buy(size=size)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.val_start) - 1.0
print('ROI: {:.2f}%'.format(100.0 * self.roi))
class BuyAndHold_1(bt.Strategy):
def start(self):
self.val_start = self.broker.get_cash() # keep the starting cash
def nextstart(self):
# Buy all the available cash
self.order_target_value(target=self.broker.get_cash())
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.val_start) - 1.0
print('ROI: {:.2f}%'.format(100.0 * self.roi))
这里发生了以下情况:
-
发出了一个单独的做多操作以进入市场。可以是
-
buy和手动计算size所有可用的
cash都用于购买资产的固定单位数量。请注意,它被截断为int。这适用于股票、期货等。
或者
order_target_value并让系统知道我们要使用所有现金。该方法将自动计算大小。
-
-
在
start方法中,初始现金金额被保存 -
在
stop方法中,通过当前投资组合价值和初始现金金额计算回报
注意
在backtrader中,当数据/指标缓冲区可以提供数据时,将精确地调用nextstart方法。默认行为是将工作委托给next。但是因为我们想要仅一次购买,并且使用第一个可用数据,这是正确的时机。
提示
由于只考虑了1个数据源,因此无需指定目标数据源。系统中的第一个(也是唯一的)数据源将被用作目标。
如果存在多个数据源,则可以使用命名参数data来选择目标,如下所示
self.buy(data=the_desired_data, size=calculated_size)
下面的示例脚本可以按以下方式执行
$ ./buy-and-hold.py --bh-buy --plot
ROI: 34.50%
$ ./buy-and-hold.py --bh-target --plot
ROI: 34.50%
图形输出对于两者都是相同的
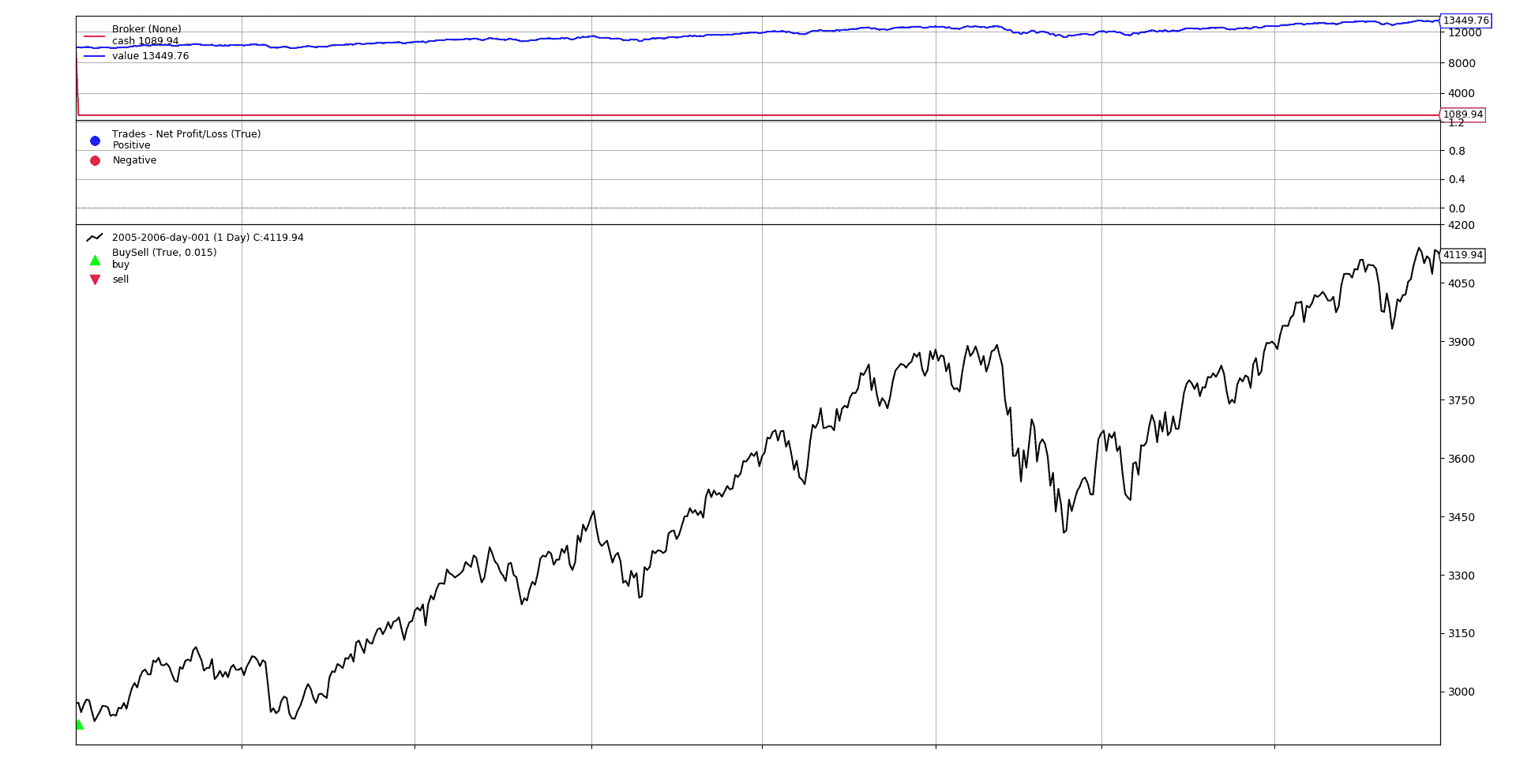
买入和再买入
但实际上,普通人通常有一份日常工作,可以每个月将一定金额投入股市。这个人不关心趋势、技术分析等。唯一的关注点是在每个月的第 1 天将资金投入市场。
鉴于罗马人留给我们的日历中月份的天数不同(28、29、30、31),并考虑到非交易日,不能确定使用以下简单方法:
- 每隔X天购买
需要使用一种方法来识别月份的第一个交易日。这可以通过backtrader中的计时器来完成
注意
下面的示例中只使用order_target_value方法。
class BuyAndHold_More(bt.Strategy):
params = dict(
monthly_cash=1000.0, # amount of cash to buy every month
)
def start(self):
self.cash_start = self.broker.get_cash()
self.val_start = 100.0
# Add a timer which will be called on the 1st trading day of the month
self.add_timer(
bt.timer.SESSION_END, # when it will be called
monthdays=[1], # called on the 1st day of the month
monthcarry=True, # called on the 2nd day if the 1st is holiday
)
def notify_timer(self, timer, when, *args, **kwargs):
# Add the influx of monthly cash to the broker
self.broker.add_cash(self.p.monthly_cash)
# buy available cash
target_value = self.broker.get_value() + self.p.monthly_cash
self.order_target_value(target=target_value)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.cash_start) - 1.0
print('ROI: {:.2f}%'.format(self.roi))
在start阶段添加了一个计时器
# Add a timer which will be called on the 1st trading day of the month
self.add_timer(
bt.timer.SESSION_END, # when it will be called
monthdays=[1], # called on the 1st day of the month
monthcarry=True, # called on the 2nd day if the 1st is holiday
)
-
将在会话结束时调用的计时器(
bt.timer.SESSION_END)注意
对于日线图表来说,这显然不相关,因为整个柱状图一次性交付。
-
计时器仅将每个月的第
1天列为必须调用计时器的日期 -
如果第
1天恰好是非交易日,则monthcarry=True确保计时器仍将在月的第一个交易日被调用。
计时器在notify_timer方法中接收,该方法被重写以执行市场操作。
def notify_timer(self, timer, when, *args, **kwargs):
# Add the influx of monthly cash to the broker
self.broker.add_cash(self.p.monthly_cash)
# buy available cash
target_value = self.broker.get_value() + self.p.monthly_cash
self.order_target_value(target=target_value)
提示
注意,购买的不是每月现金流入,而是账户的总价值,包括当前投资组合和我们添加的资金。原因
-
可能有一些初始现金要消耗
-
月度操作可能不会消耗所有现金,因为一个月可能不足以购买股票,而且在购买股票后会有余额
在我们的示例中,实际上是这样的,因为默认的每月现金流入额为
1000,而资产的价值超过3000 -
如果目标是可用现金,那么这可能小于实际价值
执行
$ ./buy-and-hold.py --bh-more --plot
ROI: 320.96%
$ ./buy-and-hold.py --bh-more --strat monthly_cash=5000.0
ROI: 1460.99%
雷霆万钧!!!默认的1000货币单位的ROI为320.96%,而5000货币单位的ROI更高,为1460.99%。我们可能找到了一台印钞机...
- 每个月我们添加的资金越多...我们赚的就越多...无论市场如何。
当然不是...
- 在
stop期间存储在self.roi中的计算不再有效。每月简单地向经纪人添加现金会改变规模(即使这些资金没有用于任何事情,它仍然会被计算为增量)
以 1000 货币单位的图形输出
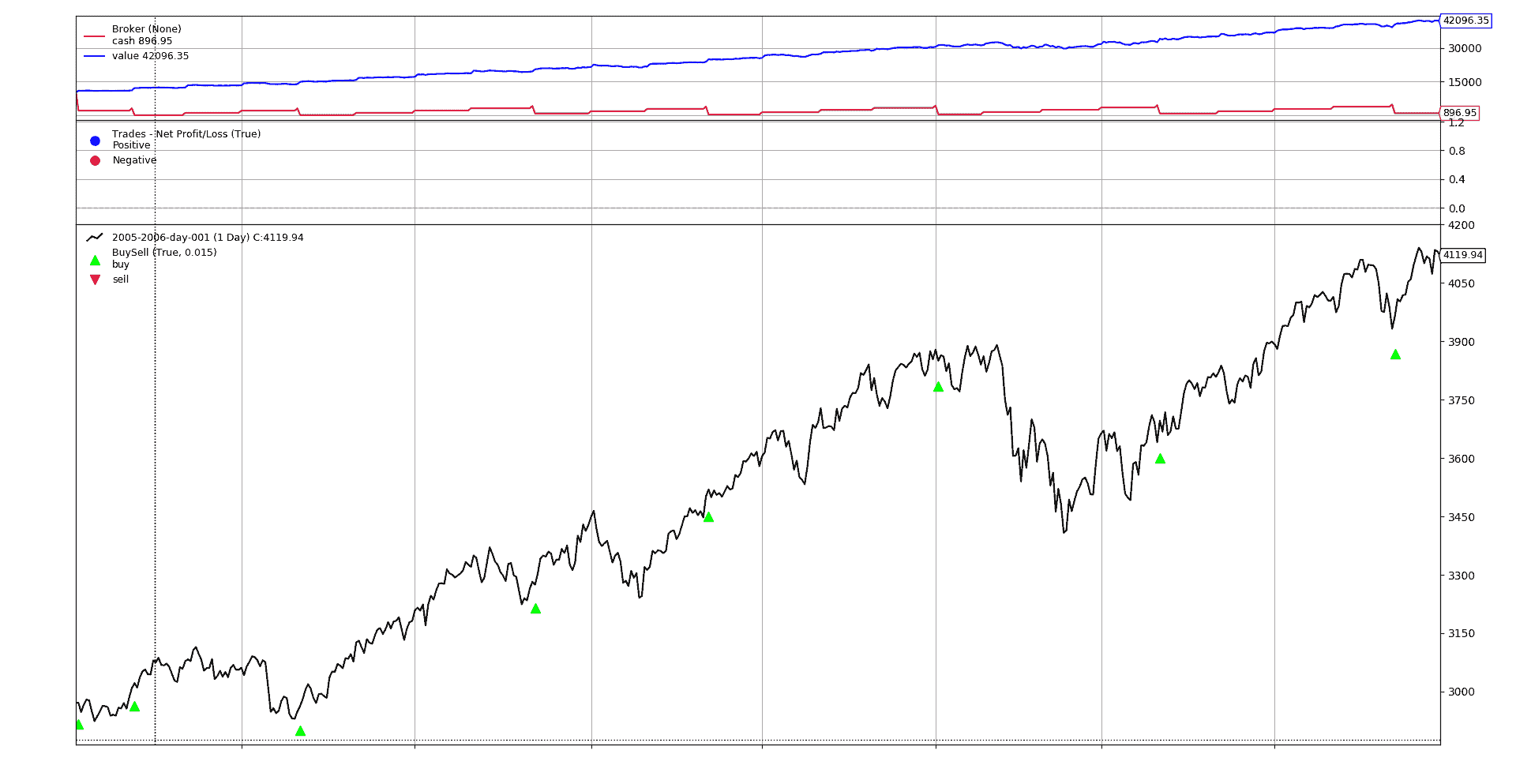
注意市场实际操作之间的间隔,因为1000货币单位不足以购买1单位的资产,必须积累资金直到操作成功。
以 5000 货币单位的图形输出
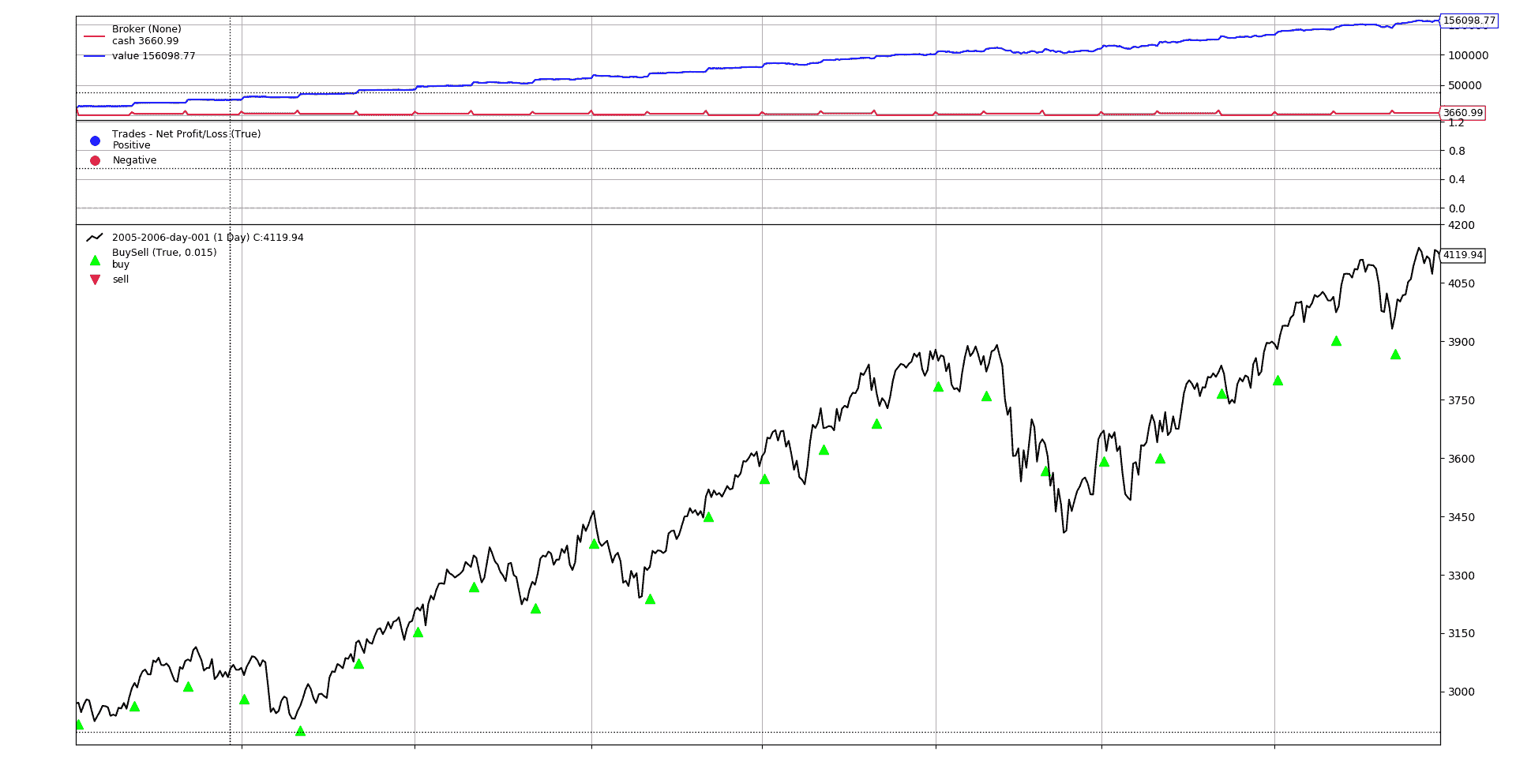
在这种情况下,5000货币单位始终可以购买1单位的资产,市场操作每个月都会发生。
购买和增加购买的绩效跟踪
如上所述,当现金被添加到(有时从中提取出)系统时,绩效必须以不同的方式进行衡量。没有必要发明什么,因为很久以前就已经发明了,这就是基金管理所做的事情。
-
perf_value被设置为跟踪绩效的参考值。很多时候,这将是100 -
使用该绩效值和初始现金金额,计算一定数量的
股份,即:shares = cash / perf_value -
每当现金被添加到/从系统中减去时,
股份的数量会发生变化,但perf_value保持不变。 -
有时将现金投资,并更新每日的
value,如perf_value = portfolio_value / shares
使用该方法可以计算实际的绩效,并且不受对系统的现金添加/提取的影响。
幸运的是,backtrader已经可以自动完成所有这些。
class BuyAndHold_More_Fund(bt.Strategy):
params = dict(
monthly_cash=1000.0, # amount of cash to buy every month
)
def start(self):
# Activate the fund mode and set the default value at 100
self.broker.set_fundmode(fundmode=True, fundstartval=100.00)
self.cash_start = self.broker.get_cash()
self.val_start = 100.0
# Add a timer which will be called on the 1st trading day of the month
self.add_timer(
bt.timer.SESSION_END, # when it will be called
monthdays=[1], # called on the 1st day of the month
monthcarry=True, # called on the 2nd day if the 1st is holiday
)
def notify_timer(self, timer, when, *args, **kwargs):
# Add the influx of monthly cash to the broker
self.broker.add_cash(self.p.monthly_cash)
# buy available cash
target_value = self.broker.get_value() + self.p.monthly_cash
self.order_target_value(target=target_value)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() - self.cash_start) - 1.0
self.froi = self.broker.get_fundvalue() - self.val_start
print('ROI: {:.2f}%'.format(self.roi))
print('Fund Value: {:.2f}%'.format(self.froi))
在start期间
-
使用默认的起始值
100.0激活基金模式。def start(self): # Activate the fund mode and set the default value at 100 self.broker.set_fundmode(fundmode=True, fundstartval=100.00)`
在stop期间
-
计算基金的
ROI。因为起始值为100.0,所以操作相当简单def stop(self): # calculate the actual returns ... self.froi = self.broker.get_fundvalue() - self.val_start`
执行
$ ./buy-and-hold.py --bh-more-fund --strat monthly_cash=5000 --plot
ROI: 1460.99%
Fund Value: 37.31%
在这种情况下:
-
与以前一样,实现了同样令人难以置信的纯
ROI,即1460.99% -
将其视为基金时,考虑到示例数据,实际的
ROI更为适度和现实,为37.31%。
注意
输出图表与之前执行的图表相同,使用了5000货币单位。
示例脚本
import argparse
import datetime
import backtrader as bt
class BuyAndHold_Buy(bt.Strategy):
def start(self):
self.val_start = self.broker.get_cash() # keep the starting cash
def nextstart(self):
# Buy all the available cash
size = int(self.broker.get_cash() / self.data)
self.buy(size=size)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.val_start) - 1.0
print('ROI: {:.2f}%'.format(100.0 * self.roi))
class BuyAndHold_Target(bt.Strategy):
def start(self):
self.val_start = self.broker.get_cash() # keep the starting cash
def nextstart(self):
# Buy all the available cash
size = int(self.broker.get_cash() / self.data)
self.buy(size=size)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.val_start) - 1.0
print('ROI: {:.2f}%'.format(100.0 * self.roi))
class BuyAndHold_More(bt.Strategy):
params = dict(
monthly_cash=1000.0, # amount of cash to buy every month
)
def start(self):
self.cash_start = self.broker.get_cash()
self.val_start = 100.0
# Add a timer which will be called on the 1st trading day of the month
self.add_timer(
bt.timer.SESSION_END, # when it will be called
monthdays=[1], # called on the 1st day of the month
monthcarry=True, # called on the 2nd day if the 1st is holiday
)
def notify_timer(self, timer, when, *args, **kwargs):
# Add the influx of monthly cash to the broker
self.broker.add_cash(self.p.monthly_cash)
# buy available cash
target_value = self.broker.get_value() + self.p.monthly_cash
self.order_target_value(target=target_value)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.cash_start) - 1.0
print('ROI: {:.2f}%'.format(100.0 * self.roi))
class BuyAndHold_More_Fund(bt.Strategy):
params = dict(
monthly_cash=1000.0, # amount of cash to buy every month
)
def start(self):
# Activate the fund mode and set the default value at 100
self.broker.set_fundmode(fundmode=True, fundstartval=100.00)
self.cash_start = self.broker.get_cash()
self.val_start = 100.0
# Add a timer which will be called on the 1st trading day of the month
self.add_timer(
bt.timer.SESSION_END, # when it will be called
monthdays=[1], # called on the 1st day of the month
monthcarry=True, # called on the 2nd day if the 1st is holiday
)
def notify_timer(self, timer, when, *args, **kwargs):
# Add the influx of monthly cash to the broker
self.broker.add_cash(self.p.monthly_cash)
# buy available cash
target_value = self.broker.get_value() + self.p.monthly_cash
self.order_target_value(target=target_value)
def stop(self):
# calculate the actual returns
self.roi = (self.broker.get_value() / self.cash_start) - 1.0
self.froi = self.broker.get_fundvalue() - self.val_start
print('ROI: {:.2f}%'.format(100.0 * self.roi))
print('Fund Value: {:.2f}%'.format(self.froi))
def run(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict(**eval('dict(' + args.dargs + ')'))
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
data = bt.feeds.BacktraderCSVData(dataname=args.data, **kwargs)
cerebro.adddata(data)
# Strategy
if args.bh_buy:
stclass = BuyAndHold_Buy
elif args.bh_target:
stclass = BuyAndHold_Target
elif args.bh_more:
stclass = BuyAndHold_More
elif args.bh_more_fund:
stclass = BuyAndHold_More_Fund
cerebro.addstrategy(stclass, **eval('dict(' + args.strat + ')'))
# Broker
broker_kwargs = dict(coc=True) # default is cheat-on-close active
broker_kwargs.update(eval('dict(' + args.broker + ')'))
cerebro.broker = bt.brokers.BackBroker(**broker_kwargs)
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Backtrader Basic Script'
)
)
parser.add_argument('--data', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
parser.add_argument('--dargs', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', '--strategy', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
pgroup = parser.add_mutually_exclusive_group(required=True)
pgroup.add_argument('--bh-buy', required=False, action='store_true',
help='Buy and Hold with buy method')
pgroup.add_argument('--bh-target', required=False, action='store_true',
help='Buy and Hold with order_target method')
pgroup.add_argument('--bh-more', required=False, action='store_true',
help='Buy and Hold More')
pgroup.add_argument('--bh-more-fund', required=False, action='store_true',
help='Buy and Hold More with Fund ROI')
return parser.parse_args(pargs)
if __name__ == '__main__':
run()
$ ./buy-and-hold.py --help
usage: buy-and-hold.py [-h] [--data DATA] [--dargs kwargs]
[--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]]
(--bh-buy | --bh-target | --bh-more | --bh-more-fund)
Backtrader Basic Script
optional arguments:
-h, --help show this help message and exit
--data DATA Data to read in (default:
../../datas/2005-2006-day-001.txt)
--dargs kwargs kwargs in key=value format (default: )
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs, --strategy kwargs
kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
--bh-buy Buy and Hold with buy method (default: False)
--bh-target Buy and Hold with order_target method (default: False)
--bh-more Buy and Hold More (default: False)
--bh-more-fund Buy and Hold More with Fund ROI (default: False)