数据供稿 - 过滤器
过滤器
此功能是相对较晚添加到backtrader中的,并且必须适应已经存在的内部结构。这使得它不像希望的那样灵活和 100%功能齐全,但在许多情况下仍然可以实现目的。
尽管实现尝试允许即插即用的过滤器链接,但是现有的内部结构使得很难确保总是可以实现。因此,一些过滤器可能被链接,而另一些则可能没有。
目的
- 转换由数据源提供的值以提供不同的数据源
实现是为了简化可以通过cerebro API 直接使用的两个明显过滤器的实现。这些是:
-
重新采样(
cerebro.resampledata)在这里,过滤器转换了传入数据源的
时间框架和压缩。例如:(Seconds, 1) -> (Days, 1)`这意味着原始数据提供的是分辨率为1 秒的柱状图。 重新采样过滤器拦截数据并将其缓冲,直到可以提供1 天柱状图。当看到下一天的1 秒柱状图时,将会发生这种情况。
-
重播(
cerebro.replaydata)对于上述相同的时间段,该过滤器将使用1 秒分辨率的柱状图来重建1 天柱状图。
这意味着1 天柱状图会被提供与看到的1 秒柱状图一样多次,并更新以包含最新信息。
例如,这模拟了实际交易日的发展方式。
注意
数据的长度,
len(data)以及策略的长度在天不变的情况下保持不变。
过滤器工作中
给定现有的数据源,您可以使用数据源的addfilter方法:
data = MyDataFeed(dataname=myname)
data.addfilter(filter, *args, **kwargs)
cerebro.addata(data)
即使它恰好与重新采样/重播过滤器兼容,也可以执行以下操作:
data = MyDataFeed(dataname=myname)
data.addfilter(filter, *args, **kwargs)
cerebro.replaydata(data)
过滤器接口
一个filter必须符合给定的接口,即:
-
一个可调用的函数,接受此签名:
callable(data, *args, **kwargs)`
或者
-
一个可以实例化和调用的类
- 在实例化期间,
__init__方法必须支持此签名:
def __init__(self, data, *args, **kwargs)`__call__方法具有以下签名:
def __call__(self, data, *args, **kwargs)`对于来自数据源的每个新输入值,将调用该实例。
\*args和\*kwargs与__init__传递的相同。返回值:
* `True`: the inner data fetching loop of the data feed must retry fetching data from the feed, becaue the length of the stream was manipulated * `False` even if data may have been edited (example: changed `close` price), the length of the stream has remain untouched`在基于类的过滤器的情况下,可以实现 2 个附加方法
- 具有以下签名的
last:
def last(self, data, *args, **kwargs)`当数据源结束时,将调用此方法,允许过滤器传递它可能已经缓冲的数据。一个典型的情况是重新采样,因为柱状图被缓冲,直到看到下一个时间段的数据。当数据源结束时,没有新数据来推送缓冲的数据出去。
last提供了将缓冲数据推送出去的机会。 - 在实例化期间,
注意
很明显,如果过滤器根本不支持任何参数,并且将添加而无任何参数,则签名可以简化为:
def __init__(self, data, *args, **kwargs) -> def __init__(self, data)
一个示例过滤器
一个非常快速的过滤器实现:
class SessionFilter(object):
def __init__(self, data):
pass
def __call__(self, data):
if data.p.sessionstart <= data.datetime.time() <= data.p.sessionend:
# bar is in the session
return False # tell outer data loop the bar can be processed
# bar outside of the regular session times
data.backwards() # remove bar from data stack
return True # tell outer data loop to fetch a new bar
这个过滤器:
-
使用
data.p.sessionstart和data.p.sessionend(标准数据源参数)来判断条是否在会话中。 -
如果在会话中,返回值为
False,以指示未执行任何操作,可以继续处理当前条目 -
如果不在会话中,则从流中移除该条,并返回
True以指示必须获取新条。注意
data.backwards()利用LineBuffer接口。 这深入到backtrader的内部。
这种过滤器的用法:
- 一些数据源包含非常规交易时间外的数据,这些数据可能不受交易者的关注。 使用此过滤器仅将会话内条考虑在内。
用于过滤器的数据伪-API
在上述示例中,已经展示了过滤器如何调用data.backwards()以从流中移除当前条。 数据源对象的有用调用,旨在作为过滤器的伪-API:
-
data.backwards(size=1, force=False):通过将逻辑指针向后移动来从数据流中删除size条(默认为1)。 如果force=True,则物理存储也将被删除。移除物理存储是一项细致的操作,仅用作内部操作的黑客方法。
-
data.forward(value=float('NaN'), size=1):将size条移动到存储区向前移动,必要时增加物理存储并用value填充。 -
data._addtostack(bar, stash=False):将bar添加到堆栈以供以后处理。bar是一个包含与数据源的lines一样多的值的可迭代对象。如果
stash=False,则添加到堆栈的条将立即被系统消耗,在下一次迭代开始时。如果
stash=True,则条将经历整个循环处理,包括可能被过滤器重新解析 -
data._save2stack(erase=False, force=False):将当前数据条保存到堆栈以供以后处理。 如果erase=True,则将调用data.backwards并将接收参数force。 -
data._updatebar(bar, forward=False, ago=0):使用可迭代对象bar中的值来覆盖数据流中ago位置的值。 默认情况下,ago=0将更新当前条。 如果是-1,则是前一个。
另一个示例:粉鱼过滤器
这是一个可以链接的过滤器的示例,并且旨在如此,以连接到另一个过滤器,即replay 过滤器。 Pinkfish名称来自于其主页描述该想法的库:使用每日数据执行仅在分时数据中才可能的操作。
要实现效果:
-
每日条将分解为 2 个组件:
OHL然后是C。 -
这两个部分通过重播链接以在流中发生以下情况:
With Len X -> OHL With Len X -> OHLC With Len X + 1 -> OHL With Len X + 1 -> OHLC With Len X + 2 -> OHL With Len X + 2 -> OHLC ...`
逻辑:
-
收到
OHLC条时,将其复制到一个可迭代对象中,并分解为以下内容:-
一个
OHL条。 由于这个概念实际上并不存在,收盘价格被替换为开盘价格以真正形成一个OHLO条。 -
一个不存在的
C条,实际上会被传递为一个刻度CCCC -
成交量在这两部分之间分配
-
当前条被从流中移除
-
OHLO部分被放入堆栈中进行即时处理 -
CCCC部分被放入存储区,在下一轮处理中处理 -
因为堆栈中有一些需要立即处理的内容,过滤器可以返回
False来指示这一点。
-
这个过滤器与以下内容一起工作:
- 重播 过滤器将
OHLO和CCCC部分组合在一起,最终生成一个OHLC条。
使用案例:
- 看到像是如果今天的最大值是过去 20 个交易日中的最高最大值,就发出一个
Close订单,该订单在第 2 个刻度执行。
代码:
class DaySplitter_Close(bt.with_metaclass(bt.MetaParams, object)):
'''
Splits a daily bar in two parts simulating 2 ticks which will be used to
replay the data:
- First tick: ``OHLX``
The ``Close`` will be replaced by the *average* of ``Open``, ``High``
and ``Low``
The session opening time is used for this tick
and
- Second tick: ``CCCC``
The ``Close`` price will be used for the four components of the price
The session closing time is used for this tick
The volume will be split amongst the 2 ticks using the parameters:
- ``closevol`` (default: ``0.5``) The value indicate which percentage, in
absolute terms from 0.0 to 1.0, has to be assigned to the *closing*
tick. The rest will be assigned to the ``OHLX`` tick.
**This filter is meant to be used together with** ``cerebro.replaydata``
'''
params = (
('closevol', 0.5), # 0 -> 1 amount of volume to keep for close
)
# replaying = True
def __init__(self, data):
self.lastdt = None
def __call__(self, data):
# Make a copy of the new bar and remove it from stream
datadt = data.datetime.date() # keep the date
if self.lastdt == datadt:
return False # skip bars that come again in the filter
self.lastdt = datadt # keep ref to last seen bar
# Make a copy of current data for ohlbar
ohlbar = [data.lines[i][0] for i in range(data.size())]
closebar = ohlbar[:] # Make a copy for the close
# replace close price with o-h-l average
ohlprice = ohlbar[data.Open] + ohlbar[data.High] + ohlbar[data.Low]
ohlbar[data.Close] = ohlprice / 3.0
vol = ohlbar[data.Volume] # adjust volume
ohlbar[data.Volume] = vohl = int(vol * (1.0 - self.p.closevol))
oi = ohlbar[data.OpenInterest] # adjust open interst
ohlbar[data.OpenInterest] = 0
# Adjust times
dt = datetime.datetime.combine(datadt, data.p.sessionstart)
ohlbar[data.DateTime] = data.date2num(dt)
# Ajust closebar to generate a single tick -> close price
closebar[data.Open] = cprice = closebar[data.Close]
closebar[data.High] = cprice
closebar[data.Low] = cprice
closebar[data.Volume] = vol - vohl
ohlbar[data.OpenInterest] = oi
# Adjust times
dt = datetime.datetime.combine(datadt, data.p.sessionend)
closebar[data.DateTime] = data.date2num(dt)
# Update stream
data.backwards(force=True) # remove the copied bar from stream
data._add2stack(ohlbar) # add ohlbar to stack
# Add 2nd part to stash to delay processing to next round
data._add2stack(closebar, stash=True)
return False # initial tick can be further processed from stack
Filters Reference
SessionFilter
class backtrader.filters.SessionFilter(data)
此类可以作为过滤器应用于数据源,并将过滤掉超出常规会话时间的盘中 bar(即:盘前/盘后市场数据)
这是一个“非简单”的过滤器,必须管理数据的堆栈(在初始化和 call 期间传递)
它不需要“last”方法,因为它没有需要传递的内容
SessionFilterSimple
class backtrader.filters.SessionFilterSimple(data)
此类可以作为过滤器应用于数据源,并将过滤掉超出常规会话时间的盘中 bar(即:盘前/盘后市场数据)
这是一个“简单”过滤器,不必管理数据的堆栈(在初始化和 call 期间传递)
它不需要“last”方法,因为它没有需要传递的内容
Bar 管理将由 SimpleFilterWrapper 类完成,该类在 DataBase.addfilter_simple 调用时添加
SessionFilller
class backtrader.filters.SessionFiller(data)
声明会话开始/结束时间内的数据源的 Bar Filler。
填充 bar 是使用声明的 Data Source timeframe 和 compression 构建的(用于计算中间缺失的时间)
参数:
-
fill_price (def: None):
如果传递了 None,则将使用前一个 bar 的收盘价。例如,要得到一个 bar,该 bar 需要时间,但不会在图表中显示... 使用 float(‘Nan’)
-
fill_vol (def: float(‘NaN’)):
用于填充缺失的 volume 的值
-
fill_oi (def: float(‘NaN’)):
用于填充缺失的持仓量的值
-
skip_first_fill (def: True):
在看到第一个有效 bar 时,不要从 sessionstart 填充到该 bar
CalendarDays
class backtrader.filters.CalendarDays(data)
在交易日中添加缺失的日历天的 Bar Filler
参数:
-
fill_price (def: None):
0:用于填充 0 或 None 的给定值:使用最后已知的收盘价 -1:使用最后一个 bar 的中点(High-Low 平均值)
-
fill_vol (def: float(‘NaN’)):
用于填充缺失的 volume 的值
-
fill_oi (def: float(‘NaN’)):
用于填充缺失的持仓量的值
BarReplayer_Open
class backtrader.filters.BarReplayer_Open(data)
此过滤器将一个 bar 拆分为两部分:
-
Open:将使用 bar 的开盘价提供一个初始价格 bar,在该 bar 中,四个组件(OHLC)相等该初始 bar 的 volume/openinterest 字段为 0
-
OHLC:原始 bar 包含原始的volume/openinterest
拆分模拟了一次回放,无需使用 replay 过滤器。
DaySplitter_Close
class backtrader.filters.DaySplitter_Close(data)
将每日 bar 拆分为两部分,模拟用于重放数据的 2 个 tick:
-
第一个 tick:
OHLXClose将被替换为Open、High和Low的 平均值此 tick 使用会话开放时间
和
-
第二个 tick:
CCCCClose价格将用于价格的四个组成部分会话结束时间用于此点
体积将根据以下参数分配给 2 个点:
closevol(默认:0.5)该值表示从 0.0 到 1.0 的绝对比例,应分配给收盘点。其余将分配给OHLX点。
此过滤器意在与 cerebro.replaydata 一同使用
平均趋势烛(HeikinAshi)
类 backtrader.filters.HeikinAshi(data)
此过滤器重新构建开盘价、最高价、最低价、收盘价以绘制平均趋势烛
参见:
* [`en.wikipedia.org/wiki/Candlestick_chart#Heikin_Ashi_candlesticks`](https://en.wikipedia.org/wiki/Candlestick_chart#Heikin_Ashi_candlesticks)
* [`stockcharts.com/school/doku.php?id=chart_school:chart_analysis:heikin_ashi`](http://stockcharts.com/school/doku.php?id=chart_school:chart_analysis:heikin_ashi)
砖形图(Renko)
类 backtrader.filters.Renko(data)
修改数据流以绘制砖形图(或砖块)
参数:
-
hilo(默认:False)使用最高价和最低价而不是收盘价来决定是否需要新砖 -
size(默认:None)每个砖的考虑大小 -
autosize(默认:20.0)如果size为None,则将用于自动计算砖的大小(简单地将当前价格除以给定值) -
dynamic(默认:False)如果True并使用autosize,则移至新砖时将重新计算砖的大小。这当然会消除砖的完美对齐。 -
align(默认:1.0)用于对齐砖的价格边界的因子。例如,如果价格为3563.25,而align为10.0,则得到的对齐价格将为3560。计算方式:-
3563.25 / 10.0 = 356.325
-
四舍五入并去除小数 -> 356
-
356 * 10.0 -> 3560
-
参见:
* [`stockcharts.com/school/doku.php?id=chart_school:chart_analysis:renko`](http://stockcharts.com/school/doku.php?id=chart_school:chart_analysis:renko)
雅虎数据源注意事项
2017 年 5 月,雅虎停止了用于历史数据下载的现有 csv 格式的 API。
一个新的 API(此处命名为 v7)迅速被标准化并已实施。
这也带来了实际 CSV 下载格式的更改。
使用 v7 API/格式
从版本 1.9.49.116 开始,这是默认行为。只需简单选择
-
YahooFinanceData用于在线下载 -
YahooFinanceCSVData用于离线下载的文件
使用传统的 API/格式
要使用旧的 API/格式
-
将在线雅虎数据源实例化为:
data = bt.feeds.YahooFinanceData( ... version='', ... )`离线雅虎数据源为:
data = bt.feeds.YahooFinanceCSVData( ... version='', ... )`可能在线服务会回来(该服务没有任何公告地停止了… 也有可能会回来)
或者
-
仅对在更改发生之前下载的离线文件,也可以进行以下操作:
data = bt.feeds.YahooLegacyCSV( ... ... )`新的
YahooLegacyCSV简单地使用version=''进行自动化。
Pandas 数据源示例
注意
必须安装 pandas 及其依赖项
支持 Pandas Dataframes 似乎是许多人关注的问题,他们依赖于已经可用的用于不同数据源(包括 CSV)的解析代码以及 Pandas 提供的其他功能。
数据源的重要声明。
注意
这些只是声明。不要盲目复制此代码。请参见下面示例中的实际用法
class PandasData(feed.DataBase):
'''
The ``dataname`` parameter inherited from ``feed.DataBase`` is the pandas
DataFrame
'''
params = (
# Possible values for datetime (must always be present)
# None : datetime is the "index" in the Pandas Dataframe
# -1 : autodetect position or case-wise equal name
# >= 0 : numeric index to the colum in the pandas dataframe
# string : column name (as index) in the pandas dataframe
('datetime', None),
# Possible values below:
# None : column not present
# -1 : autodetect position or case-wise equal name
# >= 0 : numeric index to the colum in the pandas dataframe
# string : column name (as index) in the pandas dataframe
('open', -1),
('high', -1),
('low', -1),
('close', -1),
('volume', -1),
('openinterest', -1),
)
上述从 PandasData 类中摘录的片段显示了键:
-
实例化期间传递给类的
dataname参数保存了 Pandas Dataframe此参数从基类
feed.DataBase继承 -
新参数使用
DataSeries中常规字段的名称,并遵循以下约定-
datetime(默认值:无) -
None:datetime 是 Pandas Dataframe 中的“索引”
-
-1:自动检测位置或大小写相等的名称
-
= 0:对应 pandas 数据帧中的列的数字索引
-
string:pandas 数据帧中的列名(作为索引)
-
open,high,low,high,close,volume,openinterest(默认值:全部为 -1) -
None:列不存在
-
-1:自动检测位置或大小写相等的名称
-
= 0:对应 pandas 数据帧中的列的数字索引
-
string:pandas 数据帧中的列名(作为索引)
-
一个小示例应该能够加载标准的 2006 示例,已由 Pandas 解析,而不是直接由 backtrader 解析
运行示例以使用 CSV 数据中的现有“标题”:
$ ./panda-test.py
--------------------------------------------------
Open High Low Close Volume OpenInterest
Date
2006-01-02 3578.73 3605.95 3578.73 3604.33 0 0
2006-01-03 3604.08 3638.42 3601.84 3614.34 0 0
2006-01-04 3615.23 3652.46 3615.23 3652.46 0 0
相同但告诉脚本跳过标题:
$ ./panda-test.py --noheaders
--------------------------------------------------
1 2 3 4 5 6
0
2006-01-02 3578.73 3605.95 3578.73 3604.33 0 0
2006-01-03 3604.08 3638.42 3601.84 3614.34 0 0
2006-01-04 3615.23 3652.46 3615.23 3652.46 0 0
第 2 次运行使用的是 tells pandas.read_csv:
-
跳过第一行输入(将
skiprows关键字参数设置为 1) -
不查找标题行(将
header关键字参数设置为 None)
backtrader 对 Pandas 的支持尝试自动检测是否使用了列名,否则使用数字索引,并相应地采取行动,尝试提供最佳匹配。
下图是对成功的致敬。Pandas Dataframe 已正确加载(在两种情况下)
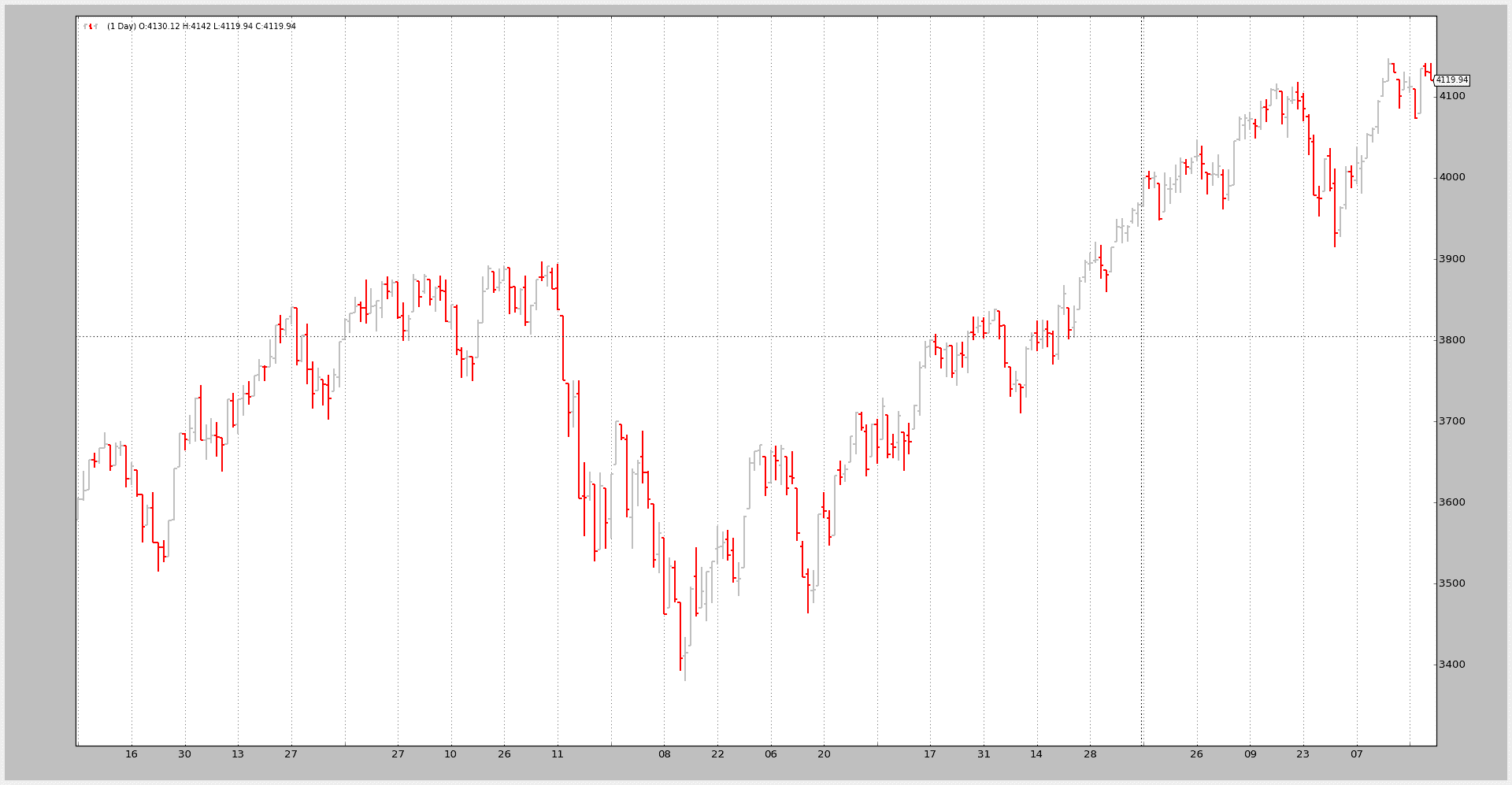
测试的示例代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import pandas
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Get a pandas dataframe
datapath = ('../../datas/2006-day-001.txt')
# Simulate the header row isn't there if noheaders requested
skiprows = 1 if args.noheaders else 0
header = None if args.noheaders else 0
dataframe = pandas.read_csv(datapath,
skiprows=skiprows,
header=header,
parse_dates=True,
index_col=0)
if not args.noprint:
print('--------------------------------------------------')
print(dataframe)
print('--------------------------------------------------')
# Pass it to the backtrader datafeed and add it to the cerebro
data = bt.feeds.PandasData(dataname=dataframe)
cerebro.adddata(data)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--noheaders', action='store_true', default=False,
required=False,
help='Do not use header rows')
parser.add_argument('--noprint', action='store_true', default=False,
help='Print the dataframe')
return parser.parse_args()
if __name__ == '__main__':
runstrat()
数据源参考
AbstractDataBase
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
BacktraderCSVData
解析用于测试的自定义 CSV 数据。
特定参数:
dataname:要解析的文件名或类似文件的对象
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
CSVDataBase
实现 CSV 数据源的类的基类
该类负责打开文件,读取行并对其进行标记
子类只需要覆盖:
- _loadline(tokens)
_loadline的返回值(True/False)将是由此基类覆盖的_load的返回值
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
Chainer
链接数据的类
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
DataClone
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
DataFiller
此类将使用来自基础数据源的以下信息位填充源数据中的间隙
-
时间框架和压缩以确定输出条的维度
-
sessionstart 和 sessionend
如果数据源在 10:31 和 10:34 之间缺少���,且时间框架为分钟,则输出将使用最后一条条的收盘价(10:31)填充 10:32 和 10:33 分钟的条
条可能会缺失,因为其他原因
参数:
* `fill_price` (def: None): if None (or evaluates to False),the
closing price will be used, else the passed value (which can be
for example ‘NaN’ to have a missing bar in terms of evaluation but
present in terms of time
* `fill_vol` (def: NaN): used to fill the volume of missing bars
* `fill_oi` (def: NaN): used to fill the openinterest of missing bars
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* fill_price (None)
* fill_vol (nan)
* fill_oi (nan)
DataFilter
此类从给定数据源中过滤条。除了 DataBase 的标准参数外,它还接受一个funcfilter参数,该参数可以是任何可调用对象
逻辑:
-
funcfilter将与基础数据源一起调用它可以是任何可调用对象
-
返回值
True:将使用当前数据源的条形值 -
返回值
False:将丢弃当前数据源的条形值
-
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* funcfilter (None)
GenericCSVData
根据参数定义的顺序和字段存在性解析 CSV 文件
特定参数(或特定含义):
-
dataname:要解析的文件名或类似文件的对象 -
行参数(日期时间,开盘价,最高价...)采用数值
-1 的值表示 CSV 源中该字段的缺失
-
如果
time存在(参数 time >=0),则源包含分开的日期和时间字段,这些字段将被组合 -
nullvalue如果应该存在的值缺失(CSV 字段为空),将使用的值
-
dtformat:用于解析日期时间 CSV 字段的格式。有关格式,请参阅 python strptime/strftime 文档。如果指定了数值,则将按以下方式解释
-
1:值是int类型的 Unix 时间戳,表示自 1970 年 1 月 1 日起的秒数 -
2:值是float类型的 Unix 时间戳
如果传递了可调用对象
- 它将接受一个字符串并返回一个 datetime.datetime 的 python 实例
-
-
tmformat:如果“存在”,则用于解析时间 CSV 字段的格式(“时间”CSV 字段的默认值是不存在)
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* nullvalue (nan)
* dtformat (%Y-%m-%d %H:%M:%S)
* tmformat (%H:%M:%S)
* datetime (0)
* time (-1)
* open (1)
* high (2)
* low (3)
* close (4)
* volume (5)
* openinterest (6)
IBData
交互经纪人数据源。
支持参数dataname中的以下合同规范:
-
TICKER # 股票类型和 SMART 交易所
-
TICKER-STK # 股票和 SMART 交易所
-
TICKER-STK-EXCHANGE # 股票
-
TICKER-STK-EXCHANGE-CURRENCY # 股票
-
TICKER-CFD # 差价合约和 SMART 交易所
-
TICKER-CFD-EXCHANGE # 差价合约
-
TICKER-CDF-EXCHANGE-CURRENCY # 股票
-
TICKER-IND-EXCHANGE # 指数
-
TICKER-IND-EXCHANGE-CURRENCY # 指数
-
TICKER-YYYYMM-EXCHANGE # 期货
-
TICKER-YYYYMM-EXCHANGE-CURRENCY # 期货
-
TICKER-YYYYMM-EXCHANGE-CURRENCY-MULT # 期货
-
TICKER-FUT-EXCHANGE-CURRENCY-YYYYMM-MULT # 期货
-
TICKER-YYYYMM-EXCHANGE-CURRENCY-STRIKE-RIGHT # 期权
-
TICKER-YYYYMM-EXCHANGE-CURRENCY-STRIKE-RIGHT-MULT # 期权
-
TICKER-FOP-EXCHANGE-CURRENCY-YYYYMM-STRIKE-RIGHT # 期权
-
TICKER-FOP-EXCHANGE-CURRENCY-YYYYMM-STRIKE-RIGHT-MULT # 期权
-
CUR1.CUR2-CASH-IDEALPRO # 外汇
-
TICKER-YYYYMMDD-EXCHANGE-CURRENCY-STRIKE-RIGHT # 期权
-
TICKER-YYYYMMDD-EXCHANGE-CURRENCY-STRIKE-RIGHT-MULT # 期权
-
TICKER-OPT-EXCHANGE-CURRENCY-YYYYMMDD-STRIKE-RIGHT # 期权
-
TICKER-OPT-EXCHANGE-CURRENCY-YYYYMMDD-STRIKE-RIGHT-MULT # 期权
参数:
-
sectype(默认值:STK)如果在
dataname规范中未提供,应用的默认值为security type -
exchange(默认值:SMART)如果在
dataname规范中未提供,应用的默认值为exchange -
currency(默认值:'')如果在
dataname规范中未提供,应用的默认值为currency -
historical(默认值:False)如果设置为
True,数据源将在首次下载数据后停止。标准数据源参数
fromdate和todate将被用作参考。如果请求的持续时间大于 IB 根据所选数据的时间框架/压缩允许的持续时间,则数据源将进行多次请求。
-
what(默认值:None)如果为
None,则将为历史数据请求使用不同资产类型的默认值:-
对于现金资产‘BID’
-
对于任何其他‘交易’
如果希望使用其他值,请查阅 IB API 文档
-
-
rtbar(默认值:False)如果设置为
True,则使用 Interactive Brokers 提供的5 秒实时数据条作为最小跳动。根据文档,它们对应实时值(一旦被 IB 收集和整理)如果为
False,则将使用基于接收到的跳动的RTVolume价格。在CASH资产的情况下(例如 EUR.JPY),将始终使用RTVolume,并从中获取bid价格(根据散布在互联网上的文献,这是 IB 的行业事实标准)即使设置为
True,如果数据被重新采样/保持到低于 Seconds/5 的时间框架/压缩,将不会使用实时条,因为 IB 不会在该水平以下提供它们 -
qcheck(默认值:0.5)以秒为单位的时间,如果未收到数据,则唤醒以正确重新采样/回放数据包并将通知传递给链路上游的机会
-
backfill_start(默认值:True)在开始时执行回填。将在单个请求中获取最大可能的历史数据。
-
backfill(默认值:True)在断开/重新连接周期后执行回填。间隙持续时间将用于下载尽可能少的数据量
-
backfill_from(默认值:None)可以传递一个额外的数据源来进行初始层次的回填。一旦数据源耗尽并且如果需要,将从 IB 进行回填。理想情况下,这是为了从已存储的源(如磁盘上的文件)回填,但不限于此。
-
latethrough(默认:False)如果数据源被重新采样/回放,一些 ticks 可能会因为已经交付的重新采样/回放的 bar 而来得太晚。如果这是
True,那些 ticks 将无论如何都会被放过。检查 Resampler 文档以查看如何考虑这些 ticks。
如果在
IBStore实例中设置timeoffset为False,并且 TWS 服务器时间与本地计算机时间不同步,则可能会发生这种情况。 -
tradename(默认:None)对某些特定情况(如CFD,其中价格由一种资产提供,交易发生在另一种资产上)很有用-
SPY-STK-SMART-USD -> SP500 ETF(将被指定为
dataname) -
SPY-CFD-SMART-USD -> 这是对应的 CFD,它提供的不是价格跟踪,而是在这种情况下将是交易资产(指定为
tradename)
-
参数中的默认值是为了允许类似 \TICKER这样的东西,其中参数sectype(默认:STK)和 exchange(默认:SMART`)被应用。
一些资产如 AAPL 需要包括 currency 的完整规范(默认:‘’),而像 TWTR 这样的其他资产可以直接传递。
-
AAPL-STK-SMART-USD是 dataname 的完整规范。或者:
IBData作为IBData(dataname='AAPL', currency='USD'),它使用默认值(STK和SMART)并覆盖货币为USD
Lines:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.5)
* calendar (None)
* sectype (STK)
* exchange (SMART)
* currency ()
* rtbar (False)
* historical (False)
* what (None)
* useRTH (False)
* backfill_start (True)
* backfill (True)
* backfill_from (None)
* latethrough (False)
* tradename (None)
InfluxDB
Lines:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* host (127.0.0.1)
* port (8086)
* username (None)
* password (None)
* database (None)
* startdate (None)
* high (high_p)
* low (low_p)
* open (open_p)
* close (close_p)
* volume (volume)
* ointerest (oi)
MT4CSVData
解析 Metatrader4 历史中心的 CSV 导出文件。
特定参数(或特定含义):
-
dataname:要解析的文件名或文件对象 -
使用 GenericCSVData 并简单修改参数
Lines:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* nullvalue (nan)
* dtformat (%Y.%m.%d)
* tmformat (%H:%M)
* datetime (0)
* time (1)
* open (2)
* high (3)
* low (4)
* close (5)
* volume (6)
* openinterest (-1)
OandaData
Oanda 数据源。
参数:
-
qcheck(默认:0.5)在未收到数据时唤醒的时间,以便充分重新采样/回放数据包并将通知传递给上游链。
-
historical(默认:False)如果设置为
True,数据源在完成首次数据下载后将停止。标准数据源参数
fromdate和todate将作为参考。如果所请求的持续时间大于 IB 根据数据所选的时间框架/压缩允许的持续时间,则数据源将发出多个请求。
-
backfill_start(默认:True)在开始时执行回填。将在单个请求中获取最大可能的历史数据。
-
backfill(默认:True)在断开/重新连接周期后执行回填。将使用间隙持续时间来下载可能的最小数据量
-
backfill_from(默认:None)可以传递附加数据源来执行初始层的补充。一旦数据源耗尽并且如果需要,将从 IB 进行补充。这最理想地用于从已存储的源(如磁盘上的文件)进行补充,但不限于此。
-
bidask(默认:True)如果为
True,则历史/补偿请求将从服务器请求买入/卖出价格如果为
False,则将请求midpoint -
useask(默认:False)如果为
True,则将使用bidask价格的ask部分,而不是默认使用bid -
includeFirst(默认:True)通过直接将参数直接设置为 Oanda API 调用来影响历史/补偿请求的第 1 个栏条的交付
-
reconnect(默认:True)当网络连接中断时重新连接
-
reconnections(默认:-1)重新连接尝试次数:
-1表示永远 -
reconntimeout(默认:5.0)重新连接尝试之间等待的秒数
此数据源仅支持与 OANDA API 开发人员指南中的定义相符的timeframe和compression的此映射:
(TimeFrame.Seconds, 5): 'S5',
(TimeFrame.Seconds, 10): 'S10',
(TimeFrame.Seconds, 15): 'S15',
(TimeFrame.Seconds, 30): 'S30',
(TimeFrame.Minutes, 1): 'M1',
(TimeFrame.Minutes, 2): 'M3',
(TimeFrame.Minutes, 3): 'M3',
(TimeFrame.Minutes, 4): 'M4',
(TimeFrame.Minutes, 5): 'M5',
(TimeFrame.Minutes, 10): 'M10',
(TimeFrame.Minutes, 15): 'M15',
(TimeFrame.Minutes, 30): 'M30',
(TimeFrame.Minutes, 60): 'H1',
(TimeFrame.Minutes, 120): 'H2',
(TimeFrame.Minutes, 180): 'H3',
(TimeFrame.Minutes, 240): 'H4',
(TimeFrame.Minutes, 360): 'H6',
(TimeFrame.Minutes, 480): 'H8',
(TimeFrame.Days, 1): 'D',
(TimeFrame.Weeks, 1): 'W',
(TimeFrame.Months, 1): 'M',
任何其他组合都将被拒绝
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.5)
* calendar (None)
* historical (False)
* backfill_start (True)
* backfill (True)
* backfill_from (None)
* bidask (True)
* useask (False)
* includeFirst (True)
* reconnect (True)
* reconnections (-1)
* reconntimeout (5.0)
PandasData
使用 Pandas DataFrame 作为数据源,使用列名的索引(可以是“数字”)
这意味着所有与行相关的参数都必须具有数值作为元组的索引
参数:
nocase(默认 True)不区分列名大小写的匹配
注:
-
dataname参数是一个 Pandas DataFrame -
可用于日期时间的值
-
None:索引包含日期时间
-
-1:无索引,自动检测列
-
= 0 或字符串:具体的列标识符
-
-
对于其他行参数
-
None:列不存在
-
-1:自动检测
-
= 0 或字符串:具体的列标识符
-
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* nocase (True)
* datetime (None)
* open (-1)
* high (-1)
* low (-1)
* close (-1)
* volume (-1)
* openinterest (-1)
PandasDirectData
使用 Pandas DataFrame 作为数据源,直接迭代“itertuples”返回的元组。
这意味着所有与行相关的参数都必须具有数值作为元组的索引
注:
-
dataname参数是一个 Pandas DataFrame -
数据行中任何参数的负值表示它不存在于 DataFrame 中
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* datetime (0)
* open (1)
* high (2)
* low (3)
* close (4)
* volume (5)
* openinterest (6)
Quandl
对给定时间范围内的数据执行从 Quandl 服务器的直接下载。
特定参数(或特定含义):
-
dataname要下载的股票代码(例如‘YHOO’)
-
baseurl服务器 URL。未来可能有人决定开放与 Quandl 兼容的服务。
-
proxies一个字典,指示下载要经过的代理,如{‘http’: ‘
myproxy.com’}或{‘http’: ‘127.0.0.1:8080’} -
buffered如果为 True,则在解析开始前,整个套接字连接将在本地缓冲。
-
reverseQuandl 以降序返回值(最新的先)。如果这是
True(默认值),请求将告诉 Quandl 以升序(从旧到新)格式返回 -
adjclose是否使用股息/拆分调整后的收盘价,并根据其调整所有值。
-
apikey在可能需要时的 apikey 标识
-
dataset标识要查询的数据集的字符串。默认为
WIKI
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* reverse (True)
* adjclose (True)
* round (False)
* decimals (2)
* baseurl ([`www.quandl.com/api/v3/datasets`](https://www.quandl.com/api/v3/datasets))
* proxies ({})
* buffered (True)
* apikey (None)
* dataset (WIKI)
QuandlCSV
解析预先下载的 Quandl CSV 数据源(或者如果它们符合 Quandl 格式则是本地生成的)
特定参数:
-
dataname:要解析的文件名或类似文件的对象 -
reverse(默认值:False)假定本地存储的文件已在下载过程中进行了反转
-
adjclose(默认值:True)是否使用股息/拆分调整后的收盘价,并根据其调整所有值。
-
round(默认值:False)是否在调整收盘价后将值四舍五入到特定小数位数
-
decimals(默认值:2)要四舍五入的小数位数
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* reverse (False)
* adjclose (True)
* round (False)
* decimals (2)
RollOver
当满足条件时转到下一个未来的类
参数:
-
checkdate(默认值:None)这必须是一个可调用对象,具有以下签名:
checkdate(dt, d):`在哪里:
-
dt是一个datetime.datetime对象 -
d是当前活动期货的当前数据源
期望返回值:
True:只要可调用返回此值,就可以切换到下一个未来
-
如果商品在三月的第三个星期五到期,checkdate 可能会在到期周的整个周返回 True。
* `False`: the expiration cannot take place
-
checkcondition(默认值:None)注意:仅当
checkdate返回True时才会调用此函数如果为
None,则会在内部评估为True(执行滚动)否则,这必须是一个可调用对象,具有以下签名:
checkcondition(d0, d1)`在哪里:
-
d0是当前活动期货的当前数据源 -
d1是下一个到期的数据源
期望返回值:
True:切换到下一个未来
-
跟随 checkdate 的示例,这可能表示仅当 d0 中的 volume 已经小于 d1 中的 volume 时,才能发生滚动
* `False`: the expiration cannot take place
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* checkdate (None)
* checkcondition (None)
SierraChartCSVData
解析 SierraChart 导出的 CSV 文件。
特定参数(或特定含义):
-
dataname:要解析的文件名或类似文件的对象 -
使用 GenericCSVData 并简单修改日期格式(dtformat)为
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* nullvalue (nan)
* dtformat (%Y/%m/%d)
* tmformat (%H:%M:%S)
* datetime (0)
* time (-1)
* open (1)
* high (2)
* low (3)
* close (4)
* volume (5)
* openinterest (6)
VCData
VisualChart 数据源。
参数:
-
qcheck(默认值:0.5)唤醒重新采样器/重播器检查当前柱状图是否可交付的默认超时时间仅当在数据中插入了重新采样/重播过滤器时才使用该值
-
historical(默认值:False)如果没有提供todate参数(在基类中定义),则设置为True将强制进行历史下载如果提供了
todate,则会实现相同的效果 -
milliseconds(默认值:True)由 Visual Chart 构造的柱状图如下所示:HH:MM:59.999000如果此参数为
True,则会添加一毫秒到此时间,使其看起来像这样:HH::MM + 1:00.000000 -
tradename(默认:None)连续期货不能交易,但非常适合数据跟踪。如果提供了此参数,则它将是当前期货的名称,这将是交易资产。例如:-
001ES -> ES 迷你连续作为
dataname提供 -
ESU16 -> ES 迷你 2016-09. 如果在
tradename中提供,它将是交易资产。
-
-
usetimezones(默认:True)对于大多数市场,Visual Chart提供的时间偏移信息允许将日期时间转换为市场时间(backtrader表示的选择)一些市场是特殊的(
096),需要特殊的内部覆盖和时区支持,以显示用户期望的市场时间。如果将此参数设置为
True,将尝试导入pytz以使用时区(默认)禁用它将删除时区使用(如果负载过大可能有所帮助)
行数:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.5)
* calendar (None)
* historical (False)
* millisecond (True)
* tradename (None)
* usetimezones (True)
VChartCSVData
解析VisualChart导出的 CSV 文件。
特定参数(或特定含义):
dataname:要解析的文件名或文件类对象
行数:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
VChartData
支持Visual Chart的二进制磁盘文件,包括每日和日内格式。
注意:
-
dataname:文件或打开的类文件对象如果传递了类文件对象,将使用
timeframe参数来确定实际时间范围。否则,将使用文件扩展名(
.fd表示每日,.min表示日内)。
行数:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
VChartFile
支持Visual Chart的二进制磁盘文件,包括每日和日内格式。
注意:
dataname:由 Visual Chart 显示的市场代码。例如:015ES 代表 EuroStoxx 50 连续期货
行数:
* close
* low
* high
* open
* volume
* openinterest
* datetime
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
YahooFinanceCSVData
解析预先下载的 Yahoo CSV 数据源(或者如果它们符合 Yahoo 格式,可以是本地生成的)。
特定参数:
-
dataname:要解析的文件名或文件类对象 -
reverse(默认:False)假设在下载过程中本地存储的文件已经被反转。
-
adjclose(默认:True)是否使用股息/拆分调整后的收盘价,并根据其调整所有值。
-
adjvolume(默认:True)如果
adjclose也为True,还需调整volume。 -
round(默认:True)在调整收盘价后,是否要将值四舍五入到特定的小数位数。
-
roundvolume(默认:0)调整后,将结果体积四舍五入到指定的小数位数。
-
decimals(默认:2)要四舍五入的小数位数
-
swapcloses(默认:False)[2018-11-16] 看起来close和adjusted close的顺序现在已经固定。参数被保留,以防需要再次交换列。
行数:
* close
* low
* high
* open
* volume
* openinterest
* datetime
* adjclose
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* reverse (False)
* adjclose (True)
* adjvolume (True)
* round (True)
* decimals (2)
* roundvolume (False)
* swapcloses (False)
YahooFinanceData
对给定时间范围从 Yahoo 服务器直接下载数据。
特定参数(或特定含义):
-
dataname要下载的股票代码(‘YHOO’用于 Yahoo 自有股票报价)
-
proxies一个字典,指示要通过的代理,如{‘http’: ‘
myproxy.com’}或{‘http’: ‘127.0.0.1:8080’} -
period下载数据的时间范围。传递‘w’表示每周,‘m’表示每月。
-
reverse[2018-11-16] 雅虎在线下载的最新版本按正确顺序返回数据。因此,在线下载的
reverse默认值设置为False。 -
adjclose是否使用股息/拆分调整后的收盘价,并根据其调整所有值。
-
urlhist用于获取下载的
crumb授权 cookie 的雅虎财经历史行情的 URL -
urldown实际下载服务器的 URL
-
retries尝试获取
crumbcookie 并下载数据的次数(每次)
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
* adjclose
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* reverse (False)
* adjclose (True)
* adjvolume (True)
* round (True)
* decimals (2)
* roundvolume (False)
* swapcloses (False)
* proxies ({})
* period (d)
* urlhist ([`finance.yahoo.com/quote`](https://finance.yahoo.com/quote)/{}/history)
* urldown ([`query1.finance.yahoo.com/v7/finance/download`](https://query1.finance.yahoo.com/v7/finance/download))
* retries (3)
YahooLegacyCSV
这旨在加载在 2017 年 5 月雅虎停止原始服务之前下载的文件。
行:
* close
* low
* high
* open
* volume
* openinterest
* datetime
* adjclose
参数:
* dataname (None)
* name ()
* compression (1)
* timeframe (5)
* fromdate (None)
* todate (None)
* sessionstart (None)
* sessionend (None)
* filters ([])
* tz (None)
* tzinput (None)
* qcheck (0.0)
* calendar (None)
* headers (True)
* separator (,)
* reverse (False)
* adjclose (True)
* adjvolume (True)
* round (True)
* decimals (2)
* roundvolume (False)
* swapcloses (False)
* version ()