条形图同步
www.backtrader.com/blog/posts/2015-10-04-bar-synchronization/bar-synchronization/
文献和/或行业中缺乏标准公式并不是问题,因为问题实际上可以总结为:
- 条形图同步
工单 #23 提出了一些关于backtrader是否可以计算相对成交量指标的疑问。
请求者需要比较特定时刻的成交量与前一个交易日相同时刻的成交量。包括:
- 一些未知长度的预市数据
有这样的要求会使大多数指标构建的基本原则无效:
- 有一个固定的用于向后查看的周期
此外,考虑到比较是在盘内进行的,还必须考虑其他因素:
-
一些“盘内”瞬间可能会缺失(无论是分钟还是秒)
数据源缺失每日条形图的可能性很小,但缺失分钟或秒条形图并不罕见。
主要原因是可能根本没有进行任何交易。或者在交易所谈判中可能出现问题,实际上阻止了条形图被记录。
考虑到前述所有要点,对指标开发得出一些结论:
-
这里的周期不是指一个周期,而是一个缓冲区,以确保有足够的条形图使指标尽快生效
-
一些条形图可能会缺失
-
主要问题是同步
幸运的是,有一个关键可以帮助解决同步问题:
- 比较的条形图是“盘内”的,因此计算已经看到的天数和给定时刻已经看到的“条形图”数量可以实现同步
前一天的值保存在字典中,因为如前所述的“向后查看”期限是未知的。
一些早期的想法可以被抛弃,比如实现一个DataFilter数据源,因为这实际上会使数据源与系统的其他部分不同步,通过删除预市数据。同步问题也会存在。
探索的一个想法是创建一个DataFiller,通过使用最后的收盘价填补缺失的分钟/秒,并将成交量设置为 0。
通过实践发现,有必要在backtrader中识别一些额外需求,比如一个time2num函数(日期 2 数字和数字 2 日期系列的补充),以及将成为lines的额外方法:
-
从浮点表示的日期中提取“日”和“时间”部分
被称为“dt”和“tm”
与此同时,RelativeVolumeByBar 指标的代码如下所示。在指标内部进行“period”/“buffer” 计算不是首选模式,但在这种情况下它能够达到目的。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import collections
import datetime
import math
import backtrader as bt
def time2num(tm):
"""
Convert :mod:`time` to the to the preserving hours, minutes, seconds
and microseconds. Return value is a :func:`float`.
"""
HOURS_PER_DAY = 24.0
MINUTES_PER_HOUR = 60.0
SECONDS_PER_MINUTE = 60.0
MUSECONDS_PER_SECOND = 1e6
MINUTES_PER_DAY = MINUTES_PER_HOUR * HOURS_PER_DAY
SECONDS_PER_DAY = SECONDS_PER_MINUTE * MINUTES_PER_DAY
MUSECONDS_PER_DAY = MUSECONDS_PER_SECOND * SECONDS_PER_DAY
tm_num = (tm.hour / HOURS_PER_DAY +
tm.minute / MINUTES_PER_DAY +
tm.second / SECONDS_PER_DAY +
tm.microsecond / MUSECONDS_PER_DAY)
return tm_num
def dtime_dt(dt):
return math.trunc(dt)
def dtime_tm(dt):
return math.modf(dt)[0]
class RelativeVolumeByBar(bt.Indicator):
alias = ('RVBB',)
lines = ('rvbb',)
params = (
('prestart', datetime.time(8, 00)),
('start', datetime.time(9, 10)),
('end', datetime.time(17, 15)),
)
def _plotlabel(self):
plabels = []
for name, value in self.params._getitems():
plabels.append('%s: %s' % (name, value.strftime('%H:%M')))
return plabels
def __init__(self):
# Inform the platform about the minimum period needs
minbuffer = self._calcbuffer()
self.addminperiod(minbuffer)
# Structures/variable to keep synchronization
self.pvol = dict()
self.vcount = collections.defaultdict(int)
self.days = 0
self.dtlast = 0
# Keep the start/end times in numeric format for comparison
self.start = time2num(self.p.start)
self.end = time2num(self.p.end)
# Done after calc to ensure coop inheritance and composition work
super(RelativeVolumeByBar, self).__init__()
def _barisvalid(self, tm):
return self.start <= tm <= self.end
def _daycount(self):
dt = dtime_dt(self.data.datetime[0])
if dt > self.dtlast:
self.days += 1
self.dtlast = dt
def prenext(self):
self._daycount()
tm = dtime_tm(self.data.datetime[0])
if self._barisvalid(tm):
self.pvol[tm] = self.data.volume[0]
self.vcount[tm] += 1
def next(self):
self._daycount()
tm = dtime_tm(self.data.datetime[0])
if not self._barisvalid(tm):
return
# Record the "minute/second" of this day has been seen
self.vcount[tm] += 1
# Get the bar's volume
vol = self.data.volume[0]
# If number of days is right, we saw the same "minute/second" last day
if self.vcount[tm] == self.days:
self.lines.rvbb[0] = vol / self.pvol[tm]
# Synchronize the days and volume count for next cycle
self.vcount[tm] = self.days
# Record the volume for this bar for next cycle
self.pvol[tm] = vol
def _calcbuffer(self):
# Period calculation
minend = self.p.end.hour * 60 + self.p.end.minute
# minstart = session_start.hour * 60 + session_start.minute
# use prestart to account for market_data
minstart = self.p.prestart.hour * 60 + self.p.prestart.minute
minbuffer = minend - minstart
tframe = self.data._timeframe
tcomp = self.data._compression
if tframe == bt.TimeFrame.Seconds:
minbuffer = (minperiod * 60)
minbuffer = (minbuffer // tcomp) + tcomp
return minbuffer
通过脚本调用,可以如下使用:
$ ./relative-volume.py --help
usage: relative-volume.py [-h] [--data DATA] [--prestart PRESTART]
[--start START] [--end END] [--fromdate FROMDATE]
[--todate TODATE] [--writer] [--wrcsv] [--plot]
[--numfigs NUMFIGS]
MultiData Strategy
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--prestart PRESTART Start time for the Session Filter
--start START Start time for the Session Filter
--end END, -te END End time for the Session Filter
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--writer, -w Add a writer to cerebro
--wrcsv, -wc Enable CSV Output in the writer
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
测试调用:
$ ./relative-volume.py --plot
生成此图表:
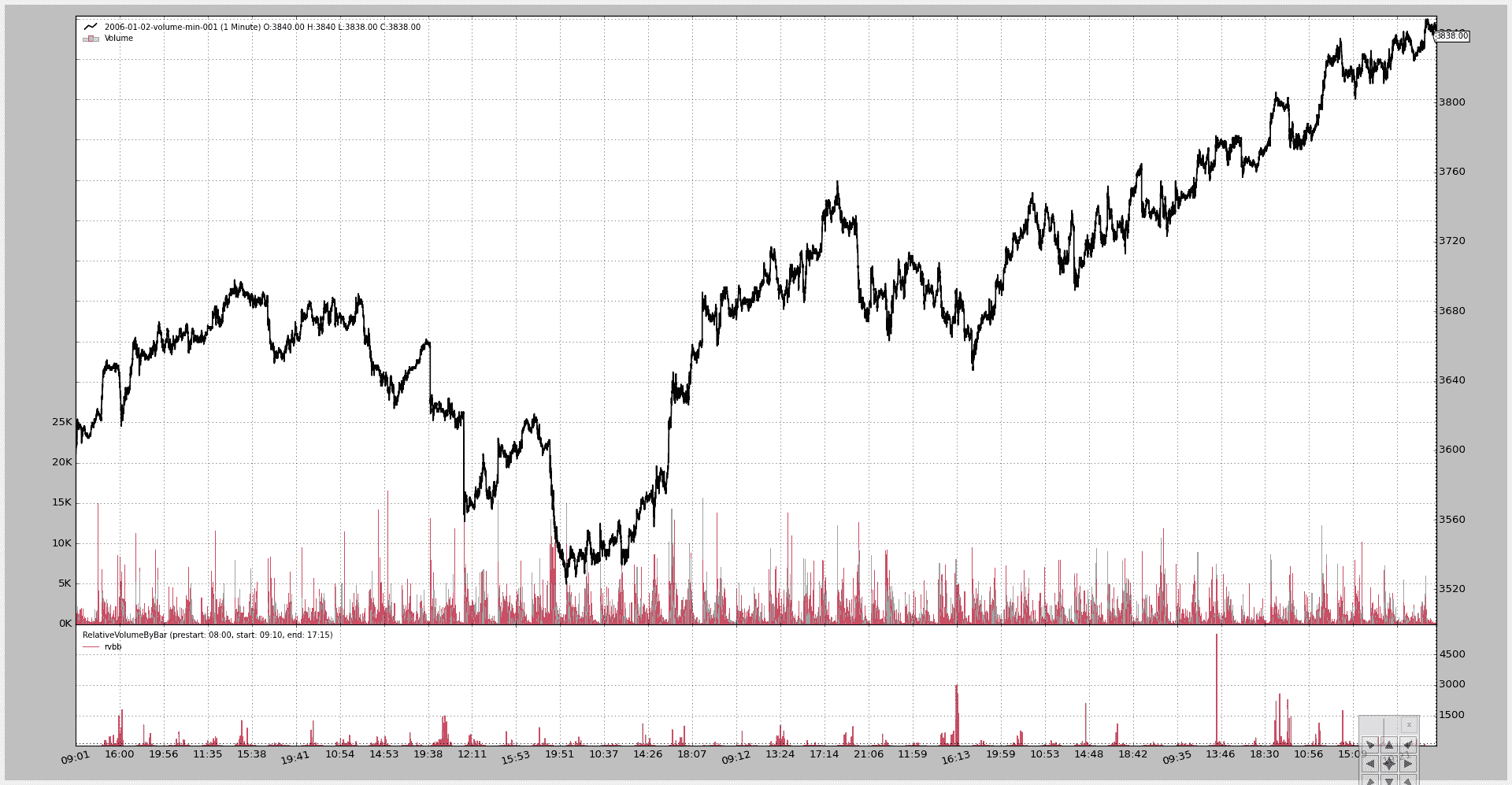
脚本代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
from relvolbybar import RelativeVolumeByBar
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.VChartCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate,
)
# Add the 1st data to cerebro
cerebro.adddata(data)
# Add an empty strategy
cerebro.addstrategy(bt.Strategy)
# Get the session times to pass them to the indicator
prestart = datetime.datetime.strptime(args.prestart, '%H:%M')
start = datetime.datetime.strptime(args.start, '%H:%M')
end = datetime.datetime.strptime(args.end, '%H:%M')
# Add the Relative volume indicator
cerebro.addindicator(RelativeVolumeByBar,
prestart=prestart, start=start, end=end)
# Add a writer with CSV
if args.writer:
cerebro.addwriter(bt.WriterFile, csv=args.wrcsv)
# And run it
cerebro.run(stdstats=False)
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=True)
def parse_args():
parser = argparse.ArgumentParser(description='MultiData Strategy')
parser.add_argument('--data', '-d',
default='../../datas/2006-01-02-volume-min-001.txt',
help='data to add to the system')
parser.add_argument('--prestart',
default='08:00',
help='Start time for the Session Filter')
parser.add_argument('--start',
default='09:15',
help='Start time for the Session Filter')
parser.add_argument('--end', '-te',
default='17:15',
help='End time for the Session Filter')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--writer', '-w', action='store_true',
help='Add a writer to cerebro')
parser.add_argument('--wrcsv', '-wc', action='store_true',
help='Enable CSV Output in the writer')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
Tick 数据和重新取样
原文:
www.backtrader.com/blog/posts/2015-09-25-tickdata-resample/resample-tickdata/
backtrader 已经能够从分钟数据进行重新取样。接受 tick 数据并不是问题,只需将 4 个常用字段(open、high、low、close)设置为 tick 值即可。
但是将要重新取样的 tick 数据传递给产生了相同的数据。从 1.1.11.88 版本开始不再是这样。现在
-
TimeFrame(backtrader.TimeFrame)已经扩展,包含了“Ticks”、“MicroSeconds”和“Seconds”的常量和名称。
-
重新取样可以管理这 3 个前述的时间框架并将其取样。
注意
因为 tick 数据是最低可能的时间框架,它实际上可以被“压缩”(n bars to 1 bar),但不能从最小的时间框架进行取样。
新版本包含了一个小的tickdata.csv样本,添加到了源数据中,以及一个新的样本脚本resample-tickdata.py来进行测试。
注意
更新了脚本以使用新的Cerebro.resampledata方法,避免了手动实例化backtrader.DataResampler的需要
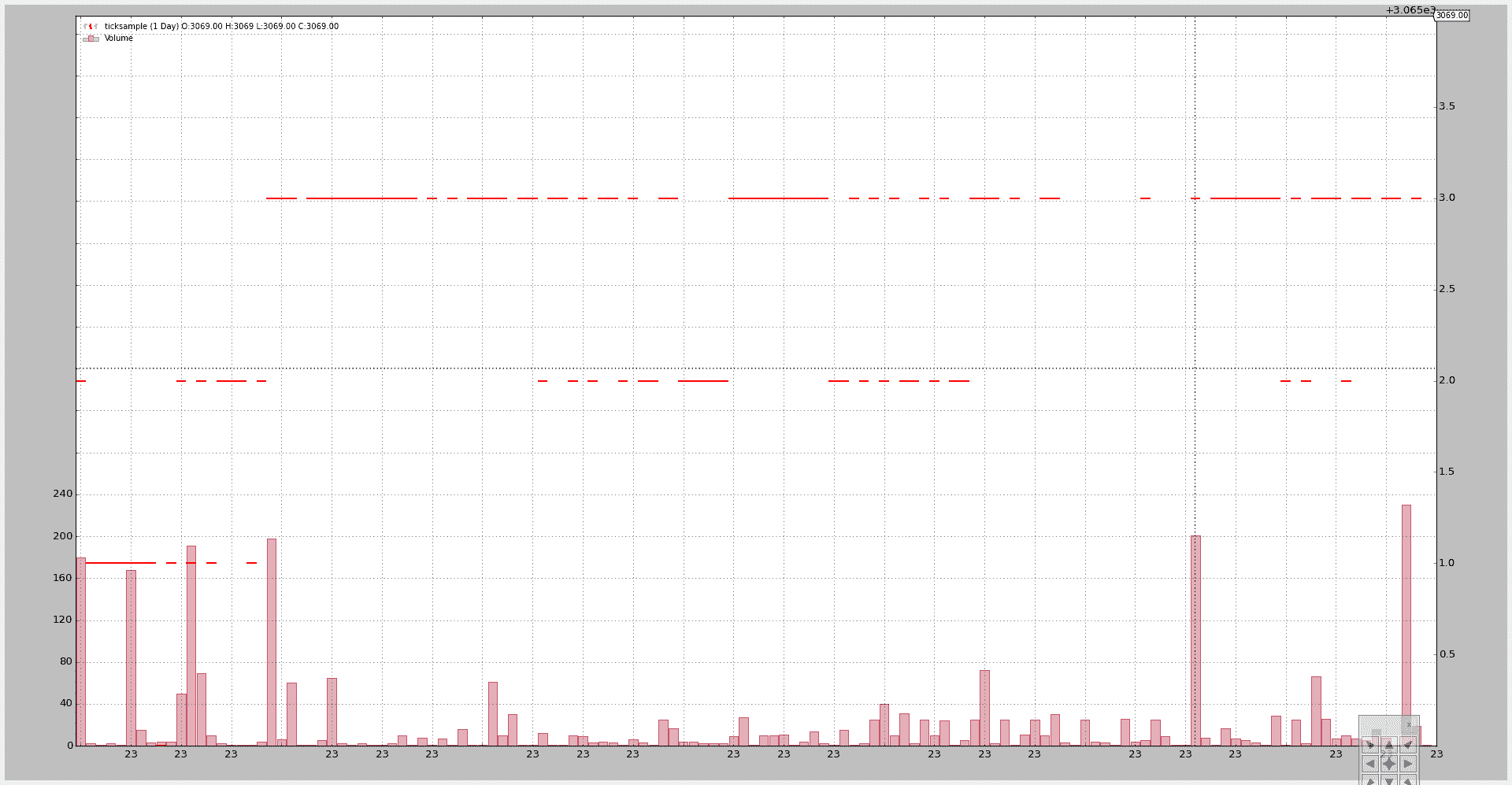
默认执行不会触及数据:
$ ./resample-tickdata.py
生成这个图表:
将 3 个 tick 压缩为 1 个:
$ ./resample-tickdata.py --timeframe ticks --compression 3
生成这个图表:
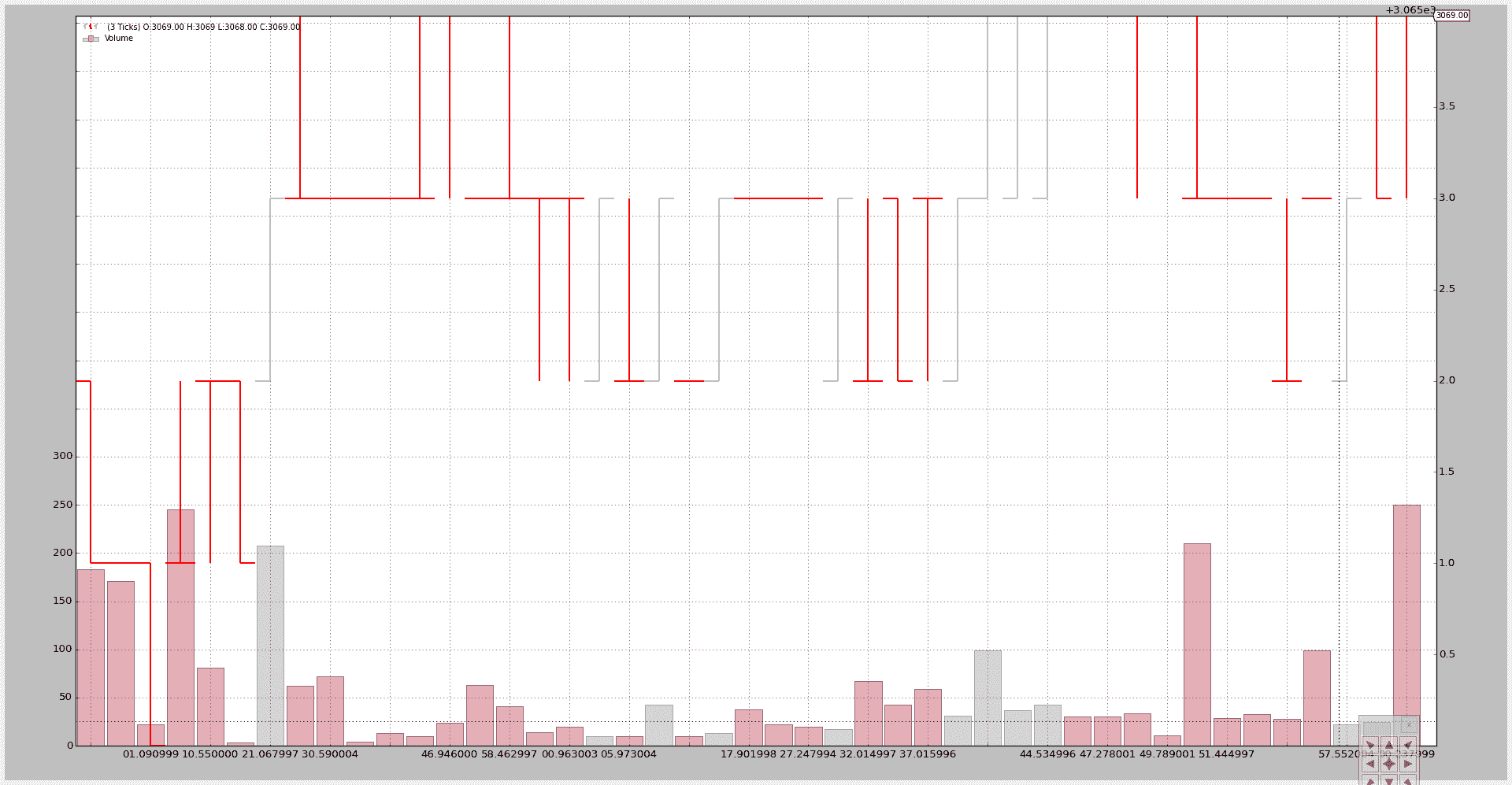
压缩后,我们不再有单个的“ticks”,而是“bars”。
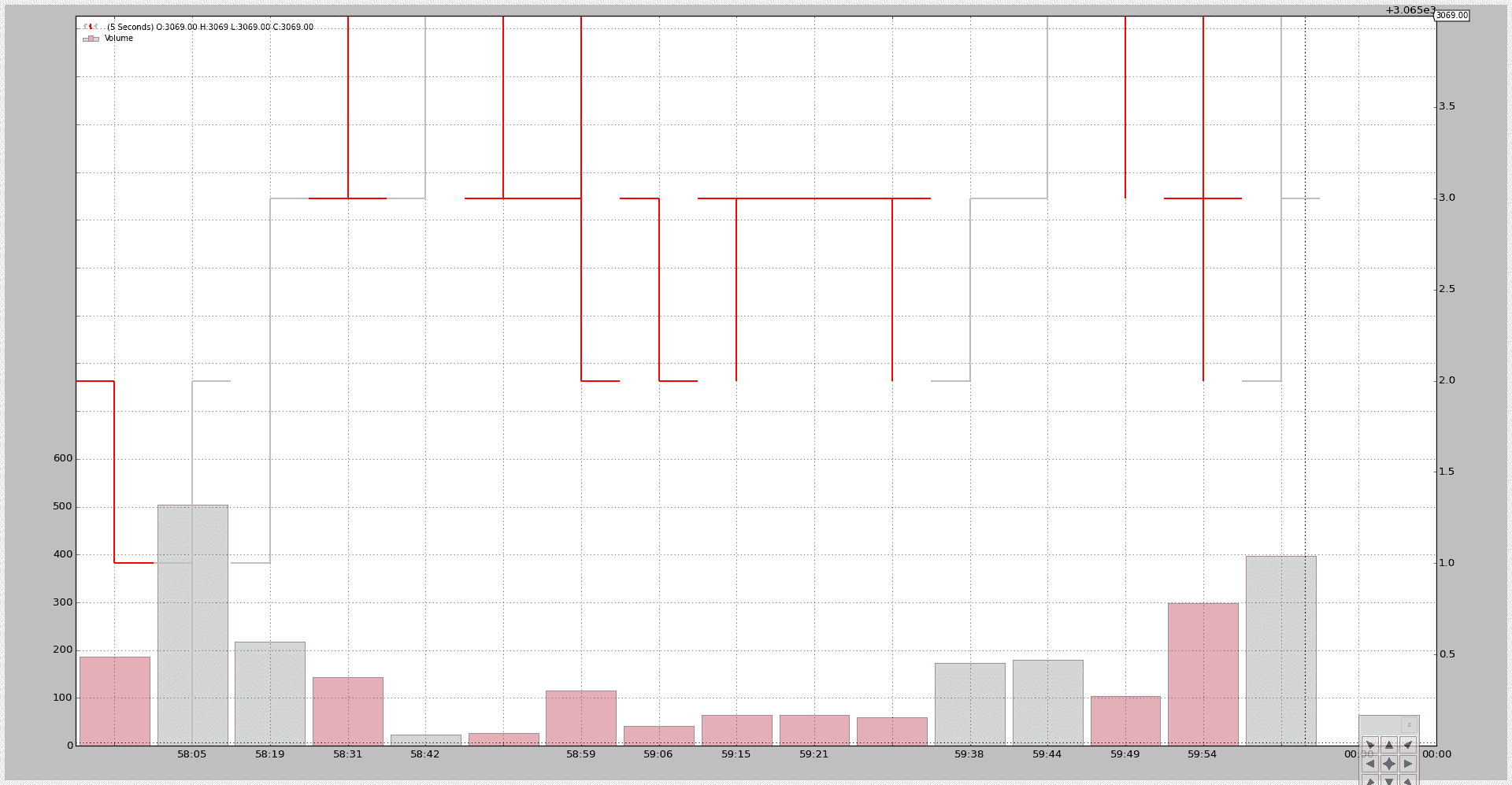
现在压缩到秒和 5 个 bar 的压缩:
$ ./resample-tickdata.py --timeframe seconds --compression 5
通过一个新的图表:
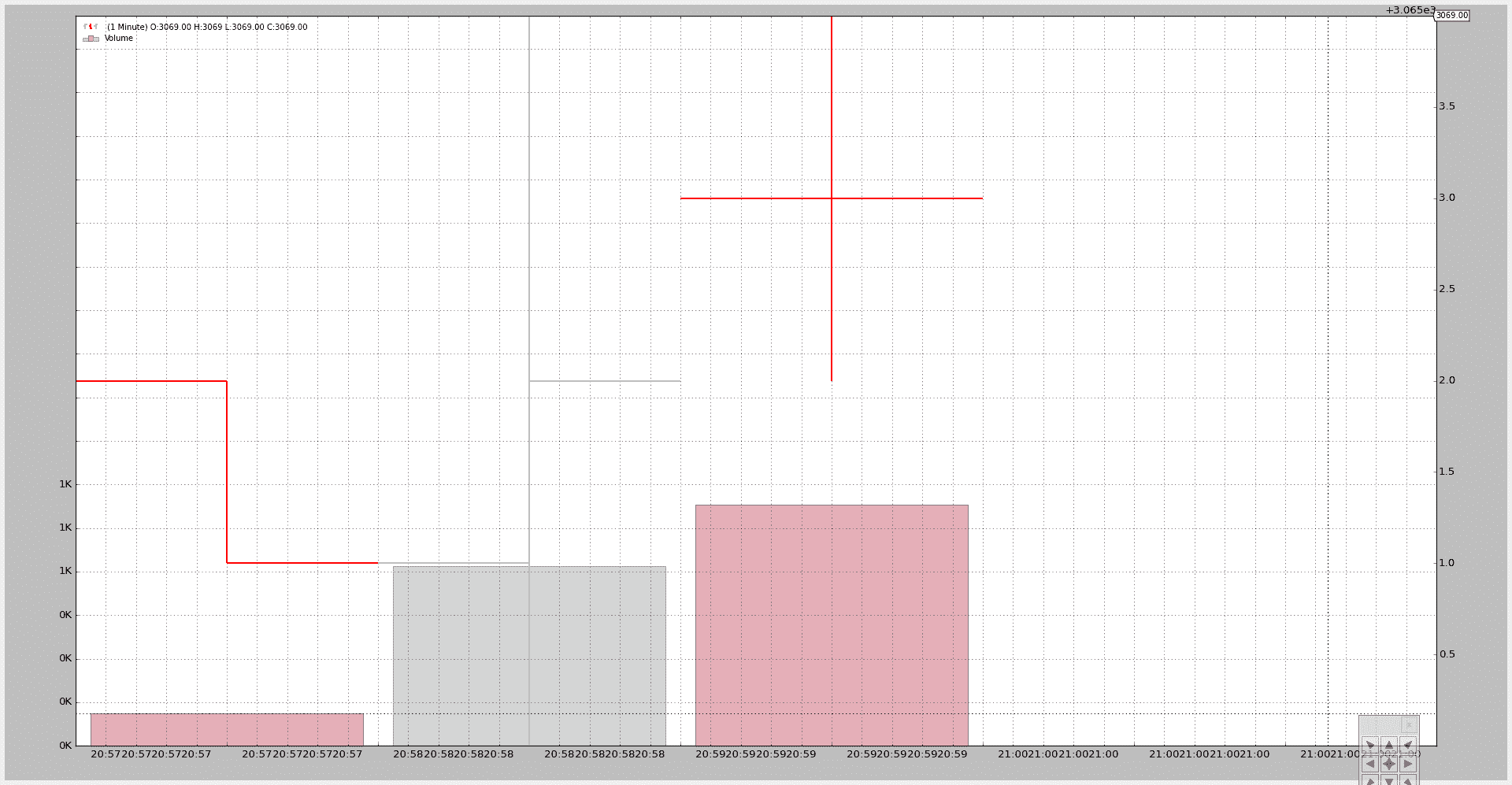
最后转换为分钟。样本数据包含来自 4 个不同分钟的 tick 数据(文件中的最后一个 tick 是第 4 分钟的唯一一个 tick):
$ ./resample-tickdata.py --timeframe minutes
使用 4 个 bar(顶部可以看到最终价格为 3069)。第 4 个 bar 是一个单点,因为这一分钟文件中只有一个 tick。
脚本用法:
$ ./resample-tickdata.py --help
usage: resample-tickdata.py [-h] [--dataname DATANAME]
[--timeframe {ticks,microseconds,seconds,minutes,daily,weekly,monthly}]
[--compression COMPRESSION]
Resampling script down to tick data
optional arguments:
-h, --help show this help message and exit
--dataname DATANAME File Data to Load
--timeframe {ticks,microseconds,seconds,minutes,daily,weekly,monthly}
Timeframe to resample to
--compression COMPRESSION
Compress n bars into 1
以及代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
# Add a strategy
cerebro.addstrategy(bt.Strategy)
# Load the Data
datapath = args.dataname or '../../datas/ticksample.csv'
data = btfeeds.GenericCSVData(
dataname=datapath,
dtformat='%Y-%m-%dT%H:%M:%S.%f',
timeframe=bt.TimeFrame.Ticks,
)
# Handy dictionary for the argument timeframe conversion
tframes = dict(
ticks=bt.TimeFrame.Ticks,
microseconds=bt.TimeFrame.MicroSeconds,
seconds=bt.TimeFrame.Seconds,
minutes=bt.TimeFrame.Minutes,
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Resample the data
data = cerebro.resampledata(data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# add a writer
cerebro.addwriter(bt.WriterFile, csv=True)
# Run over everything
cerebro.run()
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Resampling script down to tick data')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--timeframe', default='ticks', required=False,
choices=['ticks', 'microseconds', 'seconds',
'minutes', 'daily', 'weekly', 'monthly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help=('Compress n bars into 1'))
return parser.parse_args()
if __name__ == '__main__':
runstrat()
在同一轴线上绘图。
原文:
www.backtrader.com/blog/posts/2015-09-21-plotting-same-axis/plotting-same-axis/
根据博客上的评论稍微增加了一点(幸运的是只是几行代码)来进行绘图。
- 能够在任何其他指标上绘制任何指标。
一个潜在的用例:
-
节省宝贵的屏幕空间,将一些指标绘制在一起,有更多的空间来欣赏 OHLC 柱状图。
示例:将 Stochastic 和 RSI 绘图合并。
当然,有些事情必须考虑进去:
-
如果指标的缩放差异太大,一些指标可能不可见。
示例:一个围绕 0.0 加/减 0.5 波动的 MACD 绘制在一个横跨 0-100 范围的 Stochastic 上。
第一个实现在提交的开发分支上是 …14252c6
一个示例脚本(见下面的完整代码)让我们看到了效果。
注意
因为示例策略什么都不做,标准观察者被移除了,除非通过命令行开关激活。
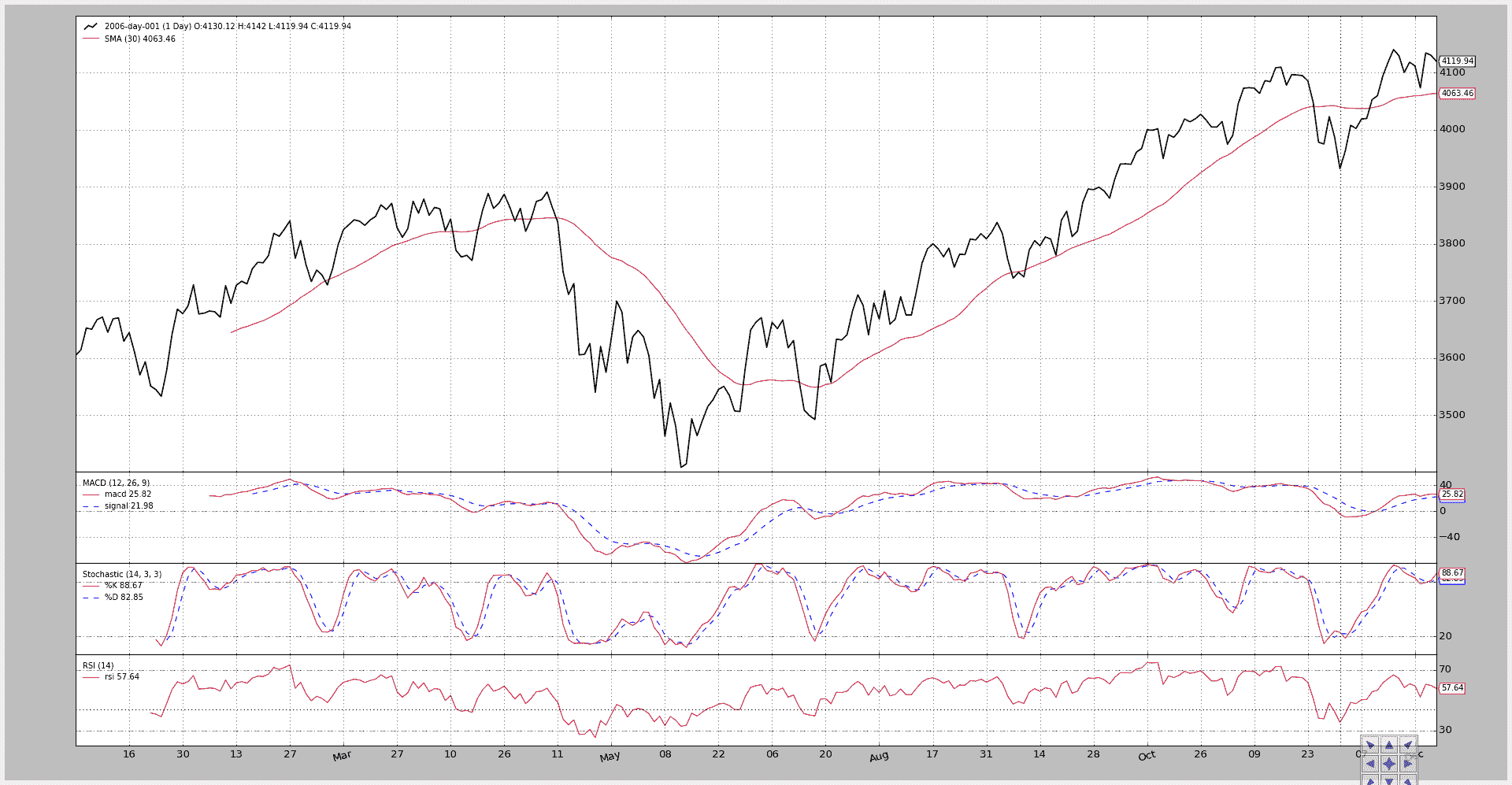
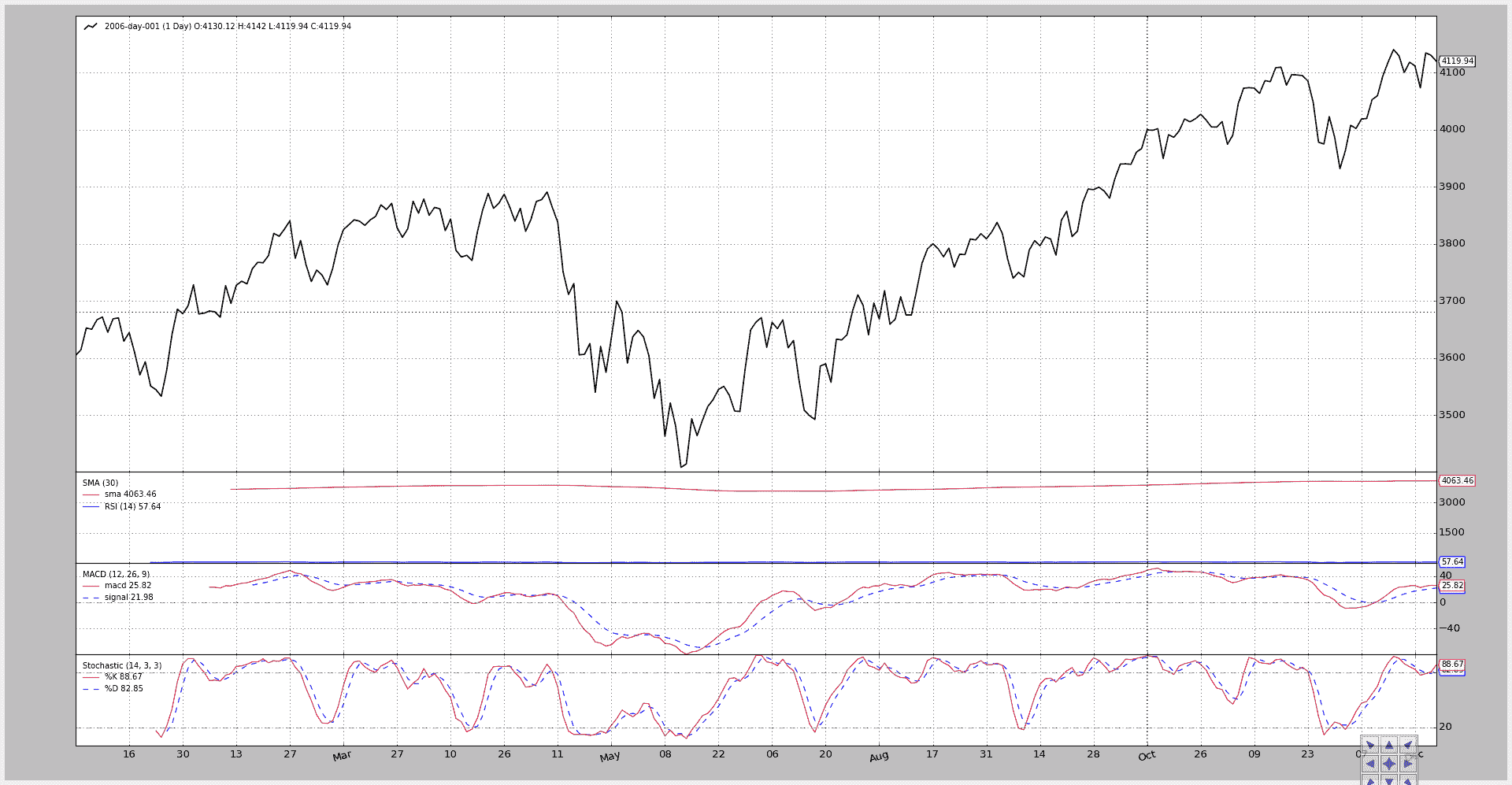
首先,脚本在没有任何开关的情况下运行。
-
简单移动平均线绘制在数据上。
-
MACD、Stochastic 和 RSI 分别绘制在各自的轴线/子图上。
执行:
$ ./plot-same-axis.py
和图表。
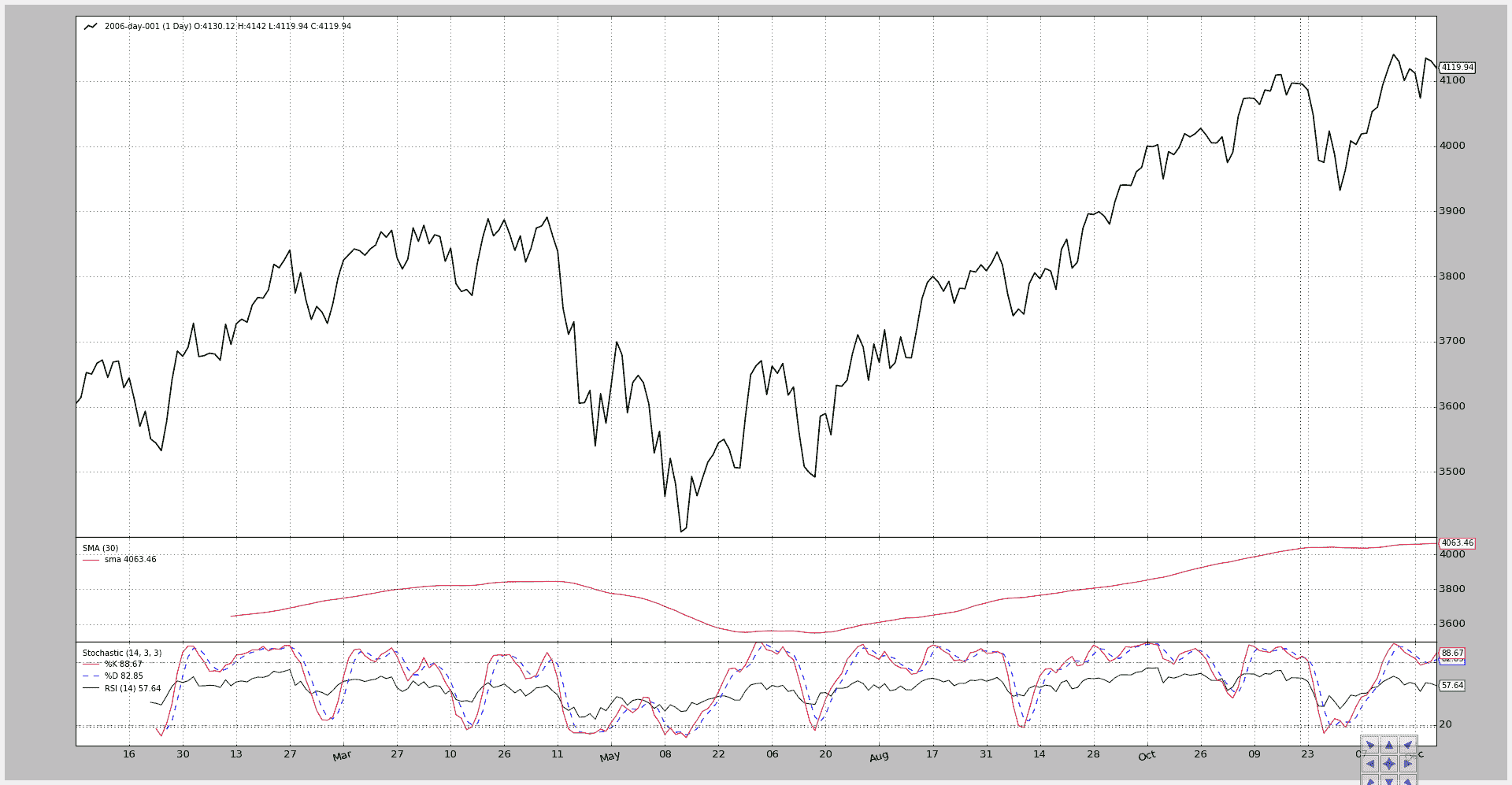
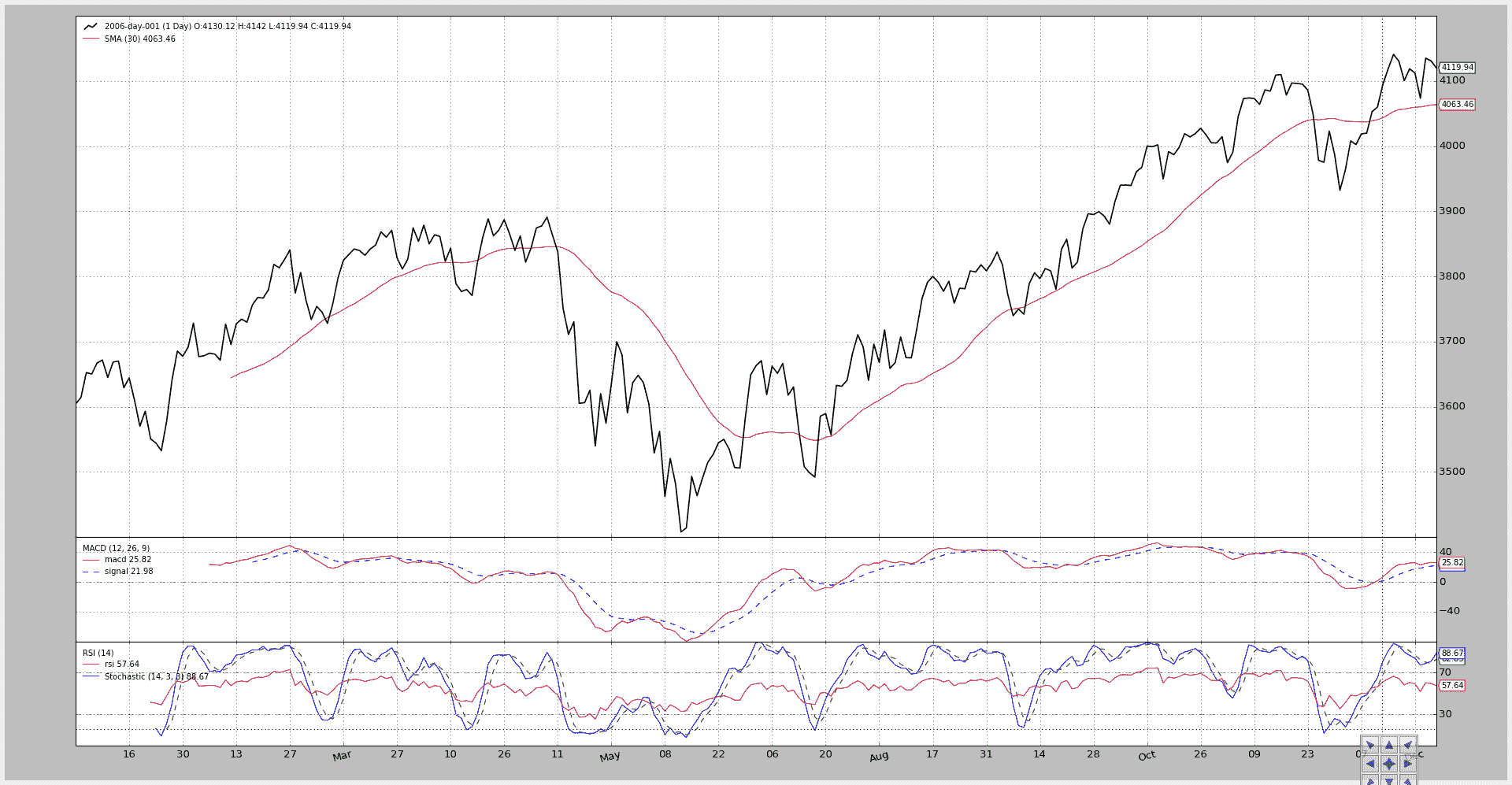
第二次执行改变了全景:
-
简单移动平均线移动到了一个子图上。
-
MACD 被隐藏了。
-
RSI 绘制在 Stochastic 之上(y 轴范围兼容:0-100)。
这通过将指标的
plotinfo.plotmaster值设置为要绘制到的其他指标来实现。在这种情况下,由于
__init__中的局部变量被命名为stoc代表 Stochastic 和rsi代表 RSI,看起来像是:rsi.plotinfo.plotmaster = stoc`
执行:
$ ./plot-same-axis.py --smasubplot --nomacdplot --rsioverstoc
图表。
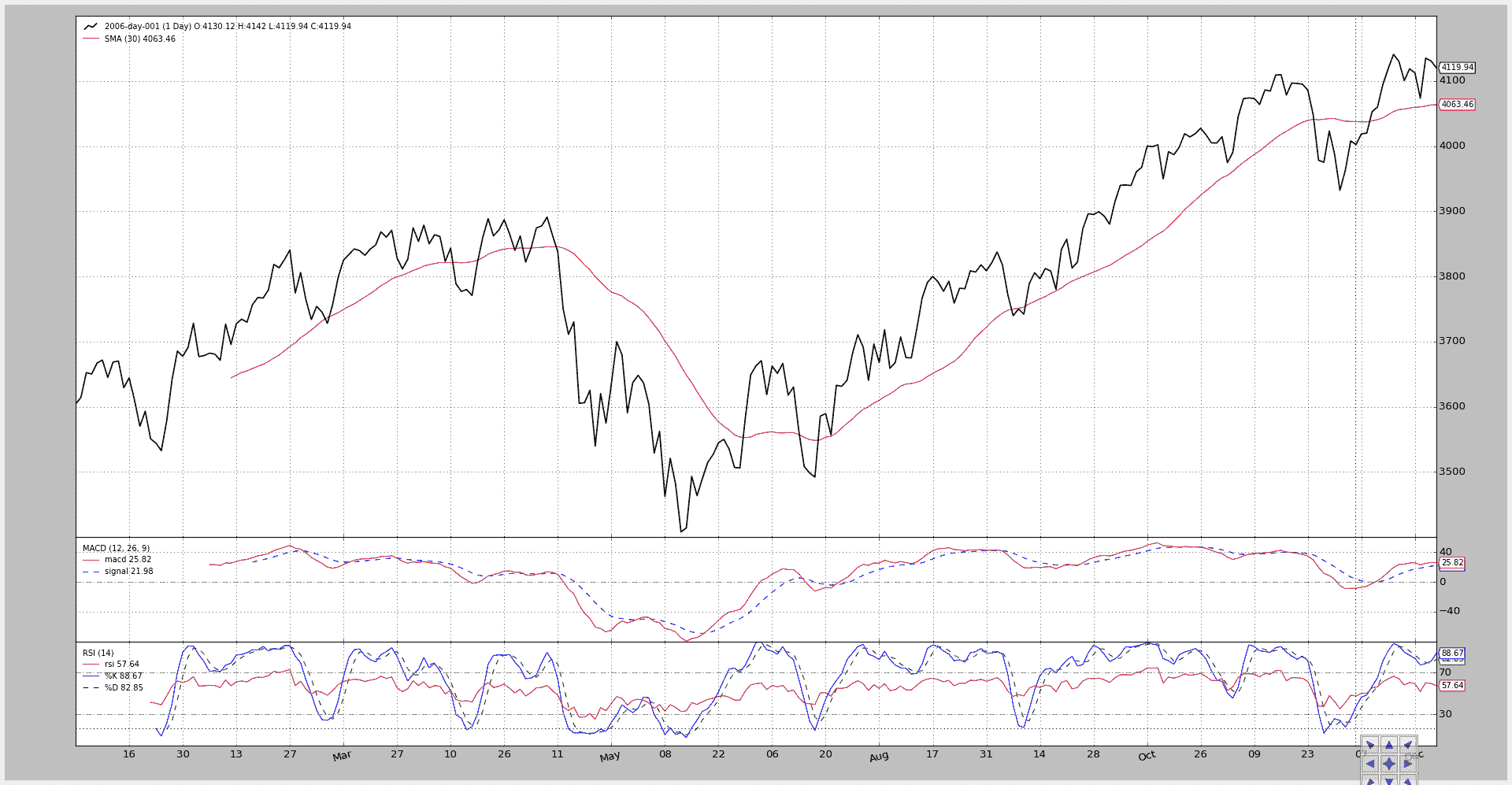
为了检查尺度的不兼容性,让我们尝试在 SMA 上绘制 RSI:
$ ./plot-same-axis.py --rsiovermacd
图表。
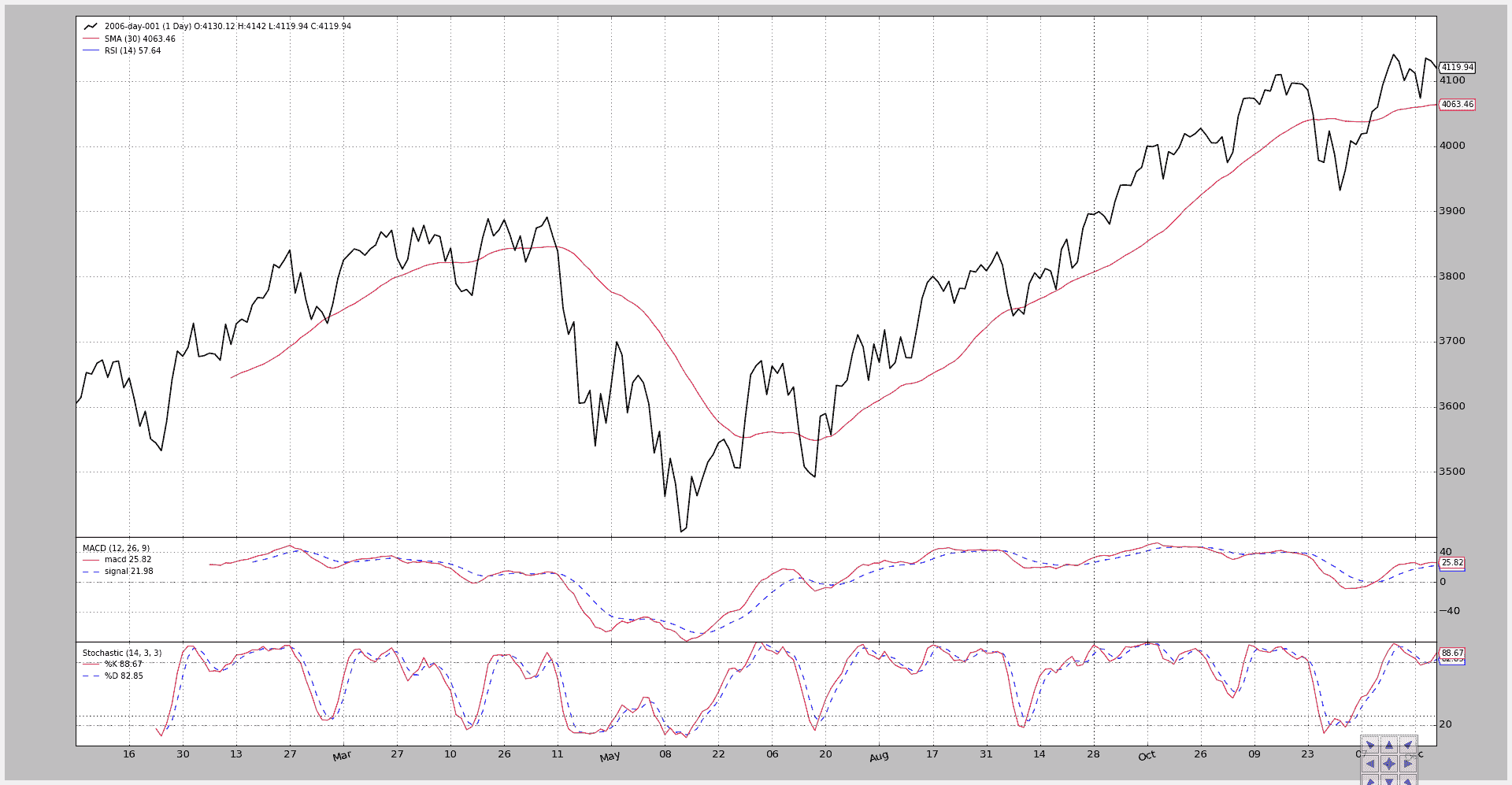
RSI 标签显示出数据和 SMA,但是尺度在 3400-4200 范围内,因此……RSI 没有任何迹象。
进一步的徒劳尝试是将 SMA 放在一个子图上,然后再次在 SMA 上绘制 RSI。
$ ./plot-same-axis.py –rsiovermacd –smasubplot
图表。
标签清晰,但是除了 SMA 图中底部的一条淡蓝线外,RSI 的所有东西都消失了。
注意
添加了在另一个指标上绘制的多行指标。
沿着另一个方向,让我们在另一个指标上绘制多行指标。让我们将 Stochastic 绘制在 RSI 上:
$ ./plot-same-axis.py --stocrsi
它有效。Stochastic标签显示出来了,K%和D%这两条线也是如此。但是这些线没有“名称”,因为我们得到了指标的名称。
在代码中,当前的设置将是:
stoc.plotinfo.plotmaster = rsi
要显示随机线的名称而不是名称,我们还需要:
stoc.plotinfo.plotlinelabels = True
这已经被参数化,新的执行结果显示如下:
$ ./plot-same-axis.py --stocrsi --stocrsilabels
现在图表显示了随机线的名称在 RSI 线的名称下方。
脚本用法:
$ ./plot-same-axis.py --help
usage: plot-same-axis.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--stdstats] [--smasubplot]
[--nomacdplot]
[--rsioverstoc | --rsioversma | --stocrsi]
[--stocrsilabels] [--numfigs NUMFIGS]
Plotting Example
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--stdstats, -st Show standard observers
--smasubplot, -ss Put SMA on own subplot/axis
--nomacdplot, -nm Hide the indicator from the plot
--rsioverstoc, -ros Plot the RSI indicator on the Stochastic axis
--rsioversma, -rom Plot the RSI indicator on the SMA axis
--stocrsi, -strsi Plot the Stochastic indicator on the RSI axis
--stocrsilabels Plot line names instead of indicator name
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
以及代码。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class PlotStrategy(bt.Strategy):
'''
The strategy does nothing but create indicators for plotting purposes
'''
params = dict(
smasubplot=False, # default for Moving averages
nomacdplot=False,
rsioverstoc=False,
rsioversma=False,
stocrsi=False,
stocrsilabels=False,
)
def __init__(self):
sma = btind.SMA(subplot=self.params.smasubplot)
macd = btind.MACD()
# In SMA we passed plot directly as kwarg, here the plotinfo.plot
# attribute is changed - same effect
macd.plotinfo.plot = not self.params.nomacdplot
# Let's put rsi on stochastic/sma or the other way round
stoc = btind.Stochastic()
rsi = btind.RSI()
if self.params.stocrsi:
stoc.plotinfo.plotmaster = rsi
stoc.plotinfo.plotlinelabels = self.p.stocrsilabels
elif self.params.rsioverstoc:
rsi.plotinfo.plotmaster = stoc
elif self.params.rsioversma:
rsi.plotinfo.plotmaster = sma
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data)
# Add the strategy
cerebro.addstrategy(PlotStrategy,
smasubplot=args.smasubplot,
nomacdplot=args.nomacdplot,
rsioverstoc=args.rsioverstoc,
rsioversma=args.rsioversma,
stocrsi=args.stocrsi,
stocrsilabels=args.stocrsilabels)
# And run it
cerebro.run(stdstats=args.stdstats)
# Plot
cerebro.plot(numfigs=args.numfigs, volume=False)
def parse_args():
parser = argparse.ArgumentParser(description='Plotting Example')
parser.add_argument('--data', '-d',
default='../../datas/2006-day-001.txt',
help='data to add to the system')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--stdstats', '-st', action='store_true',
help='Show standard observers')
parser.add_argument('--smasubplot', '-ss', action='store_true',
help='Put SMA on own subplot/axis')
parser.add_argument('--nomacdplot', '-nm', action='store_true',
help='Hide the indicator from the plot')
group = parser.add_mutually_exclusive_group(required=False)
group.add_argument('--rsioverstoc', '-ros', action='store_true',
help='Plot the RSI indicator on the Stochastic axis')
group.add_argument('--rsioversma', '-rom', action='store_true',
help='Plot the RSI indicator on the SMA axis')
group.add_argument('--stocrsi', '-strsi', action='store_true',
help='Plot the Stochastic indicator on the RSI axis')
parser.add_argument('--stocrsilabels', action='store_true',
help='Plot line names instead of indicator name')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
Writers - 写下来
原文:
www.backtrader.com/blog/posts/2015-09-14-write-it-down/write-it-down/
随着 1.1.7.88 版本的发布,backtrader 增加了一个新的功能:writers
这可能是早该做的事情,应该一直都有,并且在问题#14的讨论中也应该促进了发展。
迟做总比不做好。
Writer实现试图与backtrader环境中的其他对象保持一致
-
添加到 Cerebro
-
提供最合理的默认值
-
不要强迫用户做太多事情
当然,更重要的是理解写手实际上写了什么。 这就是:
-
CSV 输出
- `datas` added to the system (can be switched off) - `strategies` (a Strategy can have named lines) - `indicators` inside the strategies (only 1st level) - `observers` inside the strategies (only 1st level) Which `indicators` and `observers` output data to the CSV stream is controlled by the attribute: `csv` in each instance The defaults are: - Observers have `csv = True` - Indicators have `csv = False` The value can be overriden for any instance created inside a strategy`
一旦回测阶段结束,Writers为Cerebro实例添加一个新的部分,并添加以下子部分:
-
系统中
datas的属性(名称、压缩、时间框架) -
系统中
strategies的属性(行、参数)-
策略中
indicators的属性(行、参数) -
策略中
observers的属性(行、参数) -
具有以下特性的分析器
-
参数
-
分析
-
在考虑所有这些的同时,一个例子可能是展示writers的功能(或弱点)的最简单方法。
但是在了解如何将它们添加到 cerebro 之前。
-
使用
writer参数到cerebro:cerebro = bt.Cerebro(writer=True)`这创建了一个默认实例。
-
具体添加:
cerebro = bt.Cerebro() cerebro.addwriter(bt.WriterFile, csv=False)`添加(现在是唯一的作者)一个
WriterFile类到作者列表中,稍后用csv=False实例化(输出中不会生成 csv 流。
具有多空策略的长期示例(请参阅下面的完整代码),使用 Close-SMA 交叉作为信号进行执行:
$ ./writer-test.py
图表:
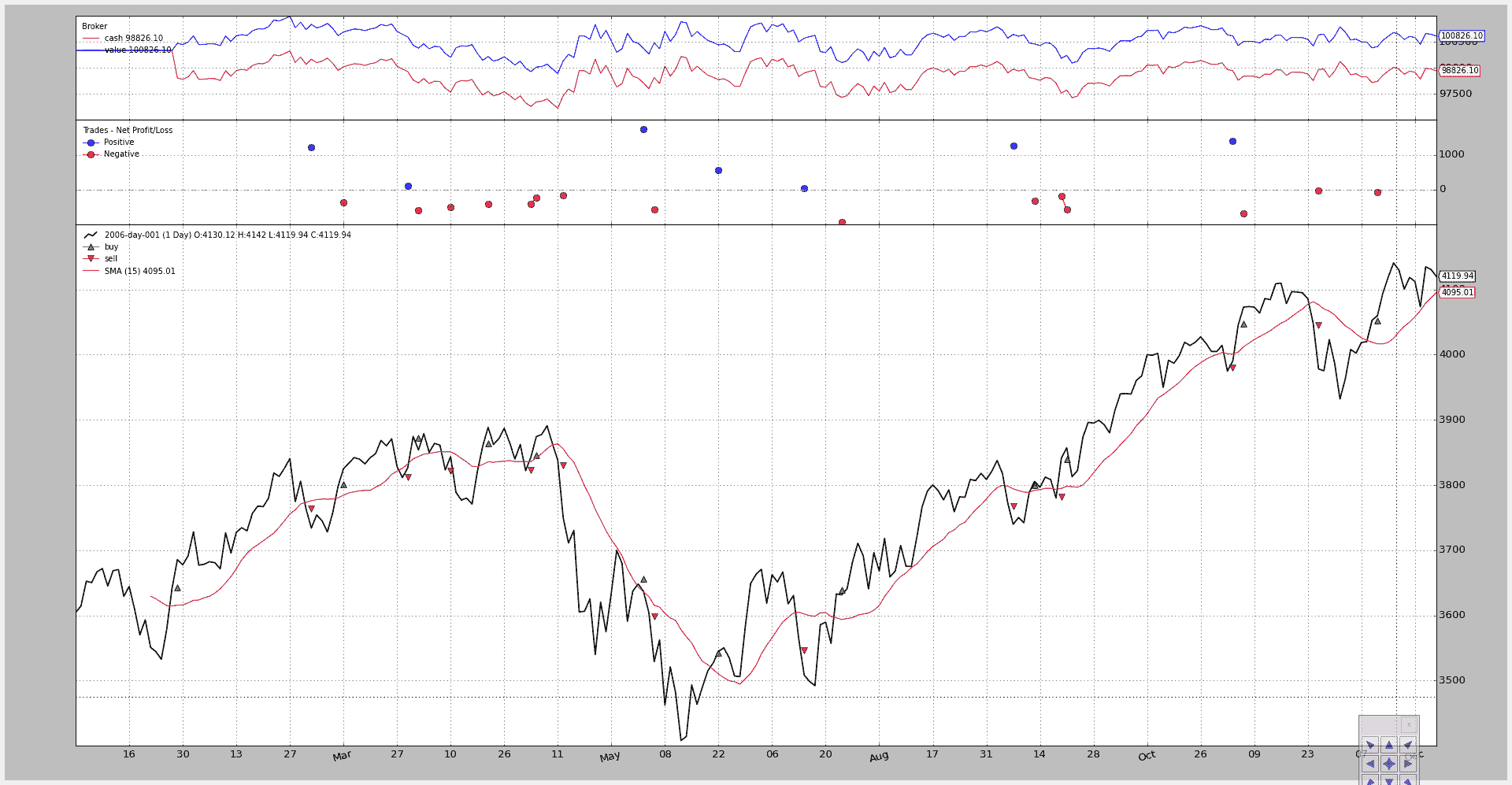
具有以下输出:
===============================================================================
Cerebro:
-----------------------------------------------------------------------------
- Datas:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- Data0:
- Name: 2006-day-001
- Timeframe: Days
- Compression: 1
-----------------------------------------------------------------------------
- Strategies:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- LongShortStrategy:
*************************************************************************
- Params:
- csvcross: False
- printout: False
- onlylong: False
- stake: 1
- period: 15
*************************************************************************
- Indicators:
.......................................................................
- SMA:
- Lines: sma
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Params:
- period: 15
.......................................................................
- CrossOver:
- Lines: crossover
- Params: None
*************************************************************************
- Observers:
.......................................................................
- Broker:
- Lines: cash, value
- Params: None
.......................................................................
- BuySell:
- Lines: buy, sell
- Params: None
.......................................................................
- Trades:
- Lines: pnlplus, pnlminus
- Params: None
*************************************************************************
- Analyzers:
.......................................................................
- Value:
- Begin: 100000
- End: 100826.1
.......................................................................
- SQN:
- Params: None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Analysis:
- sqn: 0.05
- trades: 22
运行后,我们有了一个完整的摘要,显示系统的设置以及分析器的意见。 在这种情况下,分析器是
-
Value是策略内部的一个虚拟分析器,它收集了组合的起始值和结束值 -
SQN(或 SystemQualityNumber)由 Van K. Tharp 定义(增加到backtrader1.1.7.88,告诉我们它已经看到了 22 笔交易,并且计算了sqn为 0.05。这实际上相当低。 我们本可以通过观察完整一年后的微薄利润来发现这一点(幸运的是,系统不会亏损)
测试脚本允许我们调整策略以变为仅多头:
$ ./writer-test.py --onlylong --plot
图表:
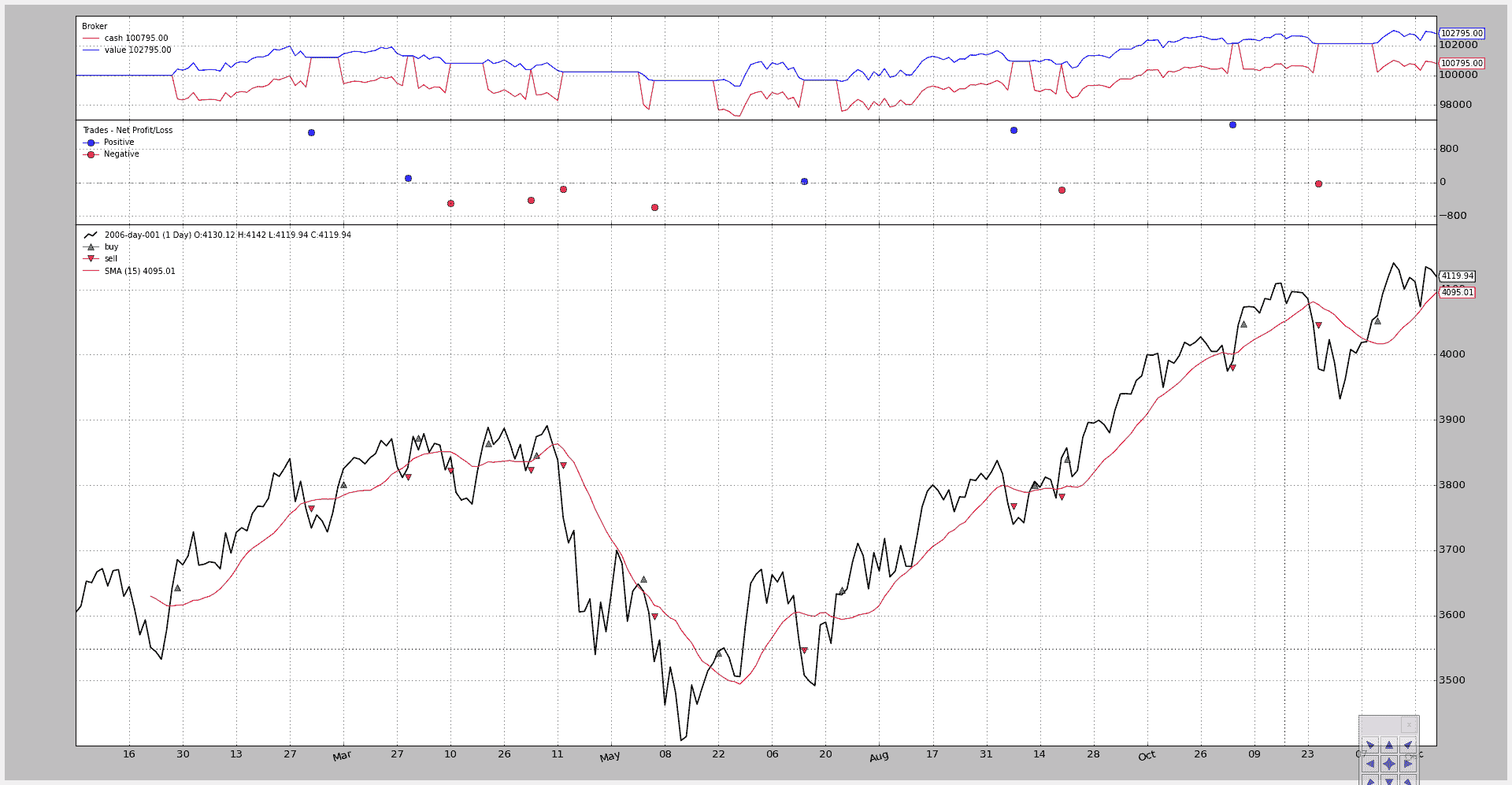
现在的输出是:
===============================================================================
Cerebro:
-----------------------------------------------------------------------------
- Datas:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- Data0:
- Name: 2006-day-001
- Timeframe: Days
- Compression: 1
-----------------------------------------------------------------------------
- Strategies:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- LongShortStrategy:
*************************************************************************
- Params:
- csvcross: False
- printout: False
- onlylong: True
- stake: 1
- period: 15
*************************************************************************
- Indicators:
.......................................................................
- SMA:
- Lines: sma
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Params:
- period: 15
.......................................................................
- CrossOver:
- Lines: crossover
- Params: None
*************************************************************************
- Observers:
.......................................................................
- Broker:
- Lines: cash, value
- Params: None
.......................................................................
- BuySell:
- Lines: buy, sell
- Params: None
.......................................................................
- Trades:
- Lines: pnlplus, pnlminus
- Params: None
*************************************************************************
- Analyzers:
.......................................................................
- Value:
- Begin: 100000
- End: 102795.0
.......................................................................
- SQN:
- Params: None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Analysis:
- sqn: 0.91
- trades: 11
“params”对策略的更改可见(onlylong 已转为 True),分析器讲述了一个不同的故事:
-
结束值从 100826.1 提高到 102795.0
-
SQN 看到的交易从 22 减少到 11
-
SQN 分数从 0.05 增长到 0.91,好得多得多
但是仍然看不到 CSV 输出。 让我们运行脚本来打开它:
$ ./writer-test.py --onlylong --writercsv
带有更新的输出:
===============================================================================
Id,2006-day-001,len,datetime,open,high,low,close,volume,openinterest,LongShortStrategy,len,Broker,len,cash,value,Buy
Sell,len,buy,sell,Trades,len,pnlplus,pnlminus
1,2006-day-001,1,2006-01-02 23:59:59+00:00,3578.73,3605.95,3578.73,3604.33,0.0,0.0,LongShortStrategy,1,Broker,1,1000
00.0,100000.0,BuySell,1,,,Trades,1,,
2,2006-day-001,2,2006-01-03 23:59:59+00:00,3604.08,3638.42,3601.84,3614.34,0.0,0.0,LongShortStrategy,2,Broker,2,1000
00.0,100000.0,BuySell,2,,,Trades,2,,
...
...
...
255,2006-day-001,255,2006-12-29 23:59:59+00:00,4130.12,4142.01,4119.94,4119.94,0.0,0.0,LongShortStrategy,255,Broker,255,100795.0,102795.0,BuySell,255,,,Trades,255,,
===============================================================================
Cerebro:
-----------------------------------------------------------------------------
...
...
我们可以跳过大部分的 CSV 流和已经看过的摘要。CSV 流已经打印出以下内容
-
一个部分线分隔符在开头
-
一个标题行
-
相应的数据
注意每个对象的“长度”是如何被打印出来的。虽然在这种情况下它并没有提供太多信息,但如果使用了多时间框数据或者数据被重播,它将提供信息。
writer 的默认设置如下:
-
没有指标被打印出来(既没有简单移动平均线也没有交叉点)
-
观察者被打印出来
让我们运行脚本并附加一个参数,将 CrossOver 指示器添加到 CSV 流中:
$ ./writer-test.py --onlylong --writercsv --csvcross
输出:
===============================================================================
Id,2006-day-001,len,datetime,open,high,low,close,volume,openinterest,LongShortStrategy,len,CrossOver,len,crossover,B
roker,len,cash,value,BuySell,len,buy,sell,Trades,len,pnlplus,pnlminus
1,2006-day-001,1,2006-01-02 23:59:59+00:00,3578.73,3605.95,3578.73,3604.33,0.0,0.0,LongShortStrategy,1,CrossOver,1,,
Broker,1,100000.0,100000.0,BuySell,1,,,Trades,1,,
...
...
这展示了写入器的一些功能。该类的进一步文档仍然是一个待办事项。
与此同时是执行可能性和用于示例的代码。
用法:
$ ./writer-test.py --help
usage: writer-test.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--period PERIOD] [--onlylong]
[--writercsv] [--csvcross] [--cash CASH] [--comm COMM]
[--mult MULT] [--margin MARGIN] [--stake STAKE] [--plot]
[--numfigs NUMFIGS]
MultiData Strategy
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--period PERIOD Period to apply to the Simple Moving Average
--onlylong, -ol Do only long operations
--writercsv, -wcsv Tell the writer to produce a csv stream
--csvcross Output the CrossOver signals to CSV
--cash CASH Starting Cash
--comm COMM Commission for operation
--mult MULT Multiplier for futures
--margin MARGIN Margin for each future
--stake STAKE Stake to apply in each operation
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
和测试脚本。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
from backtrader.analyzers import SQN
class LongShortStrategy(bt.Strategy):
'''This strategy buys/sells upong the close price crossing
upwards/downwards a Simple Moving Average.
It can be a long-only strategy by setting the param "onlylong" to True
'''
params = dict(
period=15,
stake=1,
printout=False,
onlylong=False,
csvcross=False,
)
def start(self):
pass
def stop(self):
pass
def log(self, txt, dt=None):
if self.p.printout:
dt = dt or self.data.datetime[0]
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
# To control operation entries
self.orderid = None
# Create SMA on 2nd data
sma = btind.MovAv.SMA(self.data, period=self.p.period)
# Create a CrossOver Signal from close an moving average
self.signal = btind.CrossOver(self.data.close, sma)
self.signal.csv = self.p.csvcross
def next(self):
if self.orderid:
return # if an order is active, no new orders are allowed
if self.signal > 0.0: # cross upwards
if self.position:
self.log('CLOSE SHORT , %.2f' % self.data.close[0])
self.close()
self.log('BUY CREATE , %.2f' % self.data.close[0])
self.buy(size=self.p.stake)
elif self.signal < 0.0:
if self.position:
self.log('CLOSE LONG , %.2f' % self.data.close[0])
self.close()
if not self.p.onlylong:
self.log('SELL CREATE , %.2f' % self.data.close[0])
self.sell(size=self.p.stake)
def notify_order(self, order):
if order.status in [bt.Order.Submitted, bt.Order.Accepted]:
return # Await further notifications
if order.status == order.Completed:
if order.isbuy():
buytxt = 'BUY COMPLETE, %.2f' % order.executed.price
self.log(buytxt, order.executed.dt)
else:
selltxt = 'SELL COMPLETE, %.2f' % order.executed.price
self.log(selltxt, order.executed.dt)
elif order.status in [order.Expired, order.Canceled, order.Margin]:
self.log('%s ,' % order.Status[order.status])
pass # Simply log
# Allow new orders
self.orderid = None
def notify_trade(self, trade):
if trade.isclosed:
self.log('TRADE PROFIT, GROSS %.2f, NET %.2f' %
(trade.pnl, trade.pnlcomm))
elif trade.justopened:
self.log('TRADE OPENED, SIZE %2d' % trade.size)
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data)
# Add the strategy
cerebro.addstrategy(LongShortStrategy,
period=args.period,
onlylong=args.onlylong,
csvcross=args.csvcross,
stake=args.stake)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcash(args.cash)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcommission(commission=args.comm,
mult=args.mult,
margin=args.margin)
cerebro.addanalyzer(SQN)
cerebro.addwriter(bt.WriterFile, csv=args.writercsv, rounding=2)
# And run it
cerebro.run()
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=False, zdown=False)
def parse_args():
parser = argparse.ArgumentParser(description='MultiData Strategy')
parser.add_argument('--data', '-d',
default='../../datas/2006-day-001.txt',
help='data to add to the system')
parser.add_argument('--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--period', default=15, type=int,
help='Period to apply to the Simple Moving Average')
parser.add_argument('--onlylong', '-ol', action='store_true',
help='Do only long operations')
parser.add_argument('--writercsv', '-wcsv', action='store_true',
help='Tell the writer to produce a csv stream')
parser.add_argument('--csvcross', action='store_true',
help='Output the CrossOver signals to CSV')
parser.add_argument('--cash', default=100000, type=int,
help='Starting Cash')
parser.add_argument('--comm', default=2, type=float,
help='Commission for operation')
parser.add_argument('--mult', default=10, type=int,
help='Multiplier for futures')
parser.add_argument('--margin', default=2000.0, type=float,
help='Margin for each future')
parser.add_argument('--stake', default=1, type=int,
help='Stake to apply in each operation')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
多数据策略
原文:
www.backtrader.com/blog/posts/2015-09-03-multidata-strategy/multidata-strategy/
因为世界上没有任何事物是孤立存在的,很可能购买某项资产的触发因素实际上是另一项资产。
使用不同的分析技术可能会发现两个不同数据之间的相关性。
backtrader 支持同时使用不同数据源,因此在大多数情况下可能会用于此目的。
让我们假设已经发现了以下公司之间的相关性:
-
Oracle -
Yahoo
人们可以想象,当雅虎公司运营良好时,该公司会从 Oracle 购买更多服务器、更多数据库和更多专业服务,从而推动股价上涨。
因此,经过深入分析后制定了一项策略:
-
如果
Yahoo的收盘价超过简单移动平均线(周期 15) -
买入
Oracle
退出头寸:
- 使用收盘价的下穿
订单执行类型:
- 市场
总结一下使用backtrader设置所需的内容:
-
创建一个
cerebro -
加载数据源 1(Oracle)并将其添加到 cerebro
-
加载数据源 2(Yahoo)并将其添加到 cerebro
-
加载我们设计的策略
策略的详细信息:
-
在数据源 2(Yahoo)上创建一个简单移动平均线
-
使用雅虎��收盘价和移动平均��创建一个 CrossOver 指标
然后按照上述描述在数据源 1(Oracle)上执行买入/卖出订单。
下面的脚本使用以下默认值:
-
Oracle(数据源 1)
-
雅虎(数据源 2)
-
现金:10000(系统默认值)
-
股份:10 股
-
佣金:每轮 0.5%(表示为 0.005)
-
周期:15 个交易日
-
周期:2003 年、2004 年和 2005 年
该脚本可以接受参数以修改上述设置,如帮助文本中所示:
$ ./multidata-strategy.py --help
usage: multidata-strategy.py [-h] [--data0 DATA0] [--data1 DATA1]
[--fromdate FROMDATE] [--todate TODATE]
[--period PERIOD] [--cash CASH]
[--commperc COMMPERC] [--stake STAKE] [--plot]
[--numfigs NUMFIGS]
MultiData Strategy
optional arguments:
-h, --help show this help message and exit
--data0 DATA0, -d0 DATA0
1st data into the system
--data1 DATA1, -d1 DATA1
2nd data into the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--period PERIOD Period to apply to the Simple Moving Average
--cash CASH Starting Cash
--commperc COMMPERC Percentage commission for operation (0.005 is 0.5%
--stake STAKE Stake to apply in each operation
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
标准执行结果:
$ ./multidata-strategy.py
2003-02-11T23:59:59+00:00, BUY CREATE , 9.14
2003-02-12T23:59:59+00:00, BUY COMPLETE, 11.14
2003-02-12T23:59:59+00:00, SELL CREATE , 9.09
2003-02-13T23:59:59+00:00, SELL COMPLETE, 10.90
2003-02-14T23:59:59+00:00, BUY CREATE , 9.45
2003-02-18T23:59:59+00:00, BUY COMPLETE, 11.22
2003-03-06T23:59:59+00:00, SELL CREATE , 9.72
2003-03-07T23:59:59+00:00, SELL COMPLETE, 10.32
...
...
2005-12-22T23:59:59+00:00, BUY CREATE , 40.83
2005-12-23T23:59:59+00:00, BUY COMPLETE, 11.68
2005-12-23T23:59:59+00:00, SELL CREATE , 40.63
2005-12-27T23:59:59+00:00, SELL COMPLETE, 11.63
==================================================
Starting Value - 100000.00
Ending Value - 99959.26
==================================================
经过两年的执行后,该策略:
- 损失了 40.74 货币单位
至于雅虎和 Oracle 之间的相关性
可视化输出(添加--plot以生成图表)
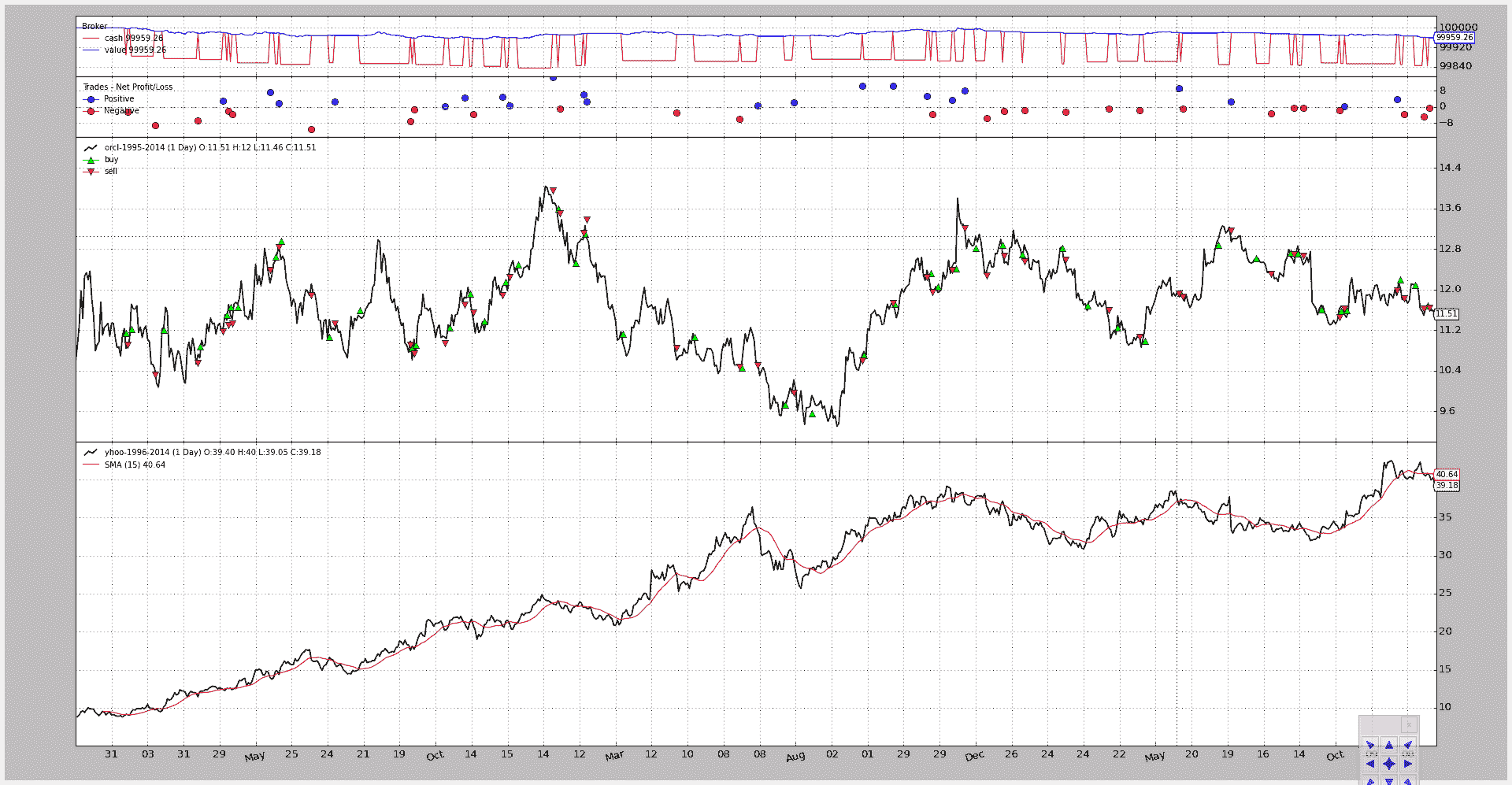
以及脚本(已添加到backtrader源分发的samples/multidata-strategy目录下。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class MultiDataStrategy(bt.Strategy):
'''
This strategy operates on 2 datas. The expectation is that the 2 datas are
correlated and the 2nd data is used to generate signals on the 1st
- Buy/Sell Operationss will be executed on the 1st data
- The signals are generated using a Simple Moving Average on the 2nd data
when the close price crosses upwwards/downwards
The strategy is a long-only strategy
'''
params = dict(
period=15,
stake=10,
printout=True,
)
def log(self, txt, dt=None):
if self.p.printout:
dt = dt or self.data.datetime[0]
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def notify_order(self, order):
if order.status in [bt.Order.Submitted, bt.Order.Accepted]:
return # Await further notifications
if order.status == order.Completed:
if order.isbuy():
buytxt = 'BUY COMPLETE, %.2f' % order.executed.price
self.log(buytxt, order.executed.dt)
else:
selltxt = 'SELL COMPLETE, %.2f' % order.executed.price
self.log(selltxt, order.executed.dt)
elif order.status in [order.Expired, order.Canceled, order.Margin]:
self.log('%s ,' % order.Status[order.status])
pass # Simply log
# Allow new orders
self.orderid = None
def __init__(self):
# To control operation entries
self.orderid = None
# Create SMA on 2nd data
sma = btind.MovAv.SMA(self.data1, period=self.p.period)
# Create a CrossOver Signal from close an moving average
self.signal = btind.CrossOver(self.data1.close, sma)
def next(self):
if self.orderid:
return # if an order is active, no new orders are allowed
if not self.position: # not yet in market
if self.signal > 0.0: # cross upwards
self.log('BUY CREATE , %.2f' % self.data1.close[0])
self.buy(size=self.p.stake)
else: # in the market
if self.signal < 0.0: # crosss downwards
self.log('SELL CREATE , %.2f' % self.data1.close[0])
self.sell(size=self.p.stake)
def stop(self):
print('==================================================')
print('Starting Value - %.2f' % self.broker.startingcash)
print('Ending Value - %.2f' % self.broker.getvalue())
print('==================================================')
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data0 = btfeeds.YahooFinanceCSVData(
dataname=args.data0,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data0)
# Create the 2nd data
data1 = btfeeds.YahooFinanceCSVData(
dataname=args.data1,
fromdate=fromdate,
todate=todate)
# Add the 2nd data to cerebro
cerebro.adddata(data1)
# Add the strategy
cerebro.addstrategy(MultiDataStrategy,
period=args.period,
stake=args.stake)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcash(args.cash)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcommission(commission=args.commperc)
# And run it
cerebro.run()
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=False, zdown=False)
def parse_args():
parser = argparse.ArgumentParser(description='MultiData Strategy')
parser.add_argument('--data0', '-d0',
default='../../datas/orcl-1995-2014.txt',
help='1st data into the system')
parser.add_argument('--data1', '-d1',
default='../../datas/yhoo-1996-2014.txt',
help='2nd data into the system')
parser.add_argument('--fromdate', '-f',
default='2003-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2005-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--period', default=15, type=int,
help='Period to apply to the Simple Moving Average')
parser.add_argument('--cash', default=100000, type=int,
help='Starting Cash')
parser.add_argument('--commperc', default=0.005, type=float,
help='Percentage commission for operation (0.005 is 0.5%%')
parser.add_argument('--stake', default=10, type=int,
help='Stake to apply in each operation')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
实际应用
原文:
www.backtrader.com/blog/posts/2015-08-27-real-world-usage/real-world-usage/
最后,似乎将其扎根于开发 backtrader 是值得的。
在看到上周欧洲市场的情况看起来像世界末日之后,一个朋友问我是否可以查看我们图表软件中的数据,看看下跌范围与以前类似情况的比较如何。
当然我可以,但我说我可以做的不仅仅是看图表,因为我可以迅速:
-
创建一个快速的
LegDown指标来测量下跌的范围。它也可以被命名为HighLowRange或HiLoRange。幸运的是,如果认为有必要,可以通过alias来解决这个问题。 -
创建一个
LegDownAnalyzer,它将收集结果并对其进行排序。
这导致了一个额外的请求:
-
在接下来的 5、10、15、20 天内(交易后…)的跌幅后的复苏。
通过使用
LegUp指标解决,它会将值写回以与相应的LegDown对齐。
这项工作很快就完成了(在我空闲时间的允许范围内),并与请求者共享了结果。但是…只有我看到了潜在问题:
-
改进
bt-run.py中的自动化程式-
多种策略/观察者/分析器以及分开的 kwargs
-
直接将指标注入策略中,每个指标都带有 kwargs
-
单一的绘图参数也接受 kwargs。
-
-
在
AnalyzerAPI 中进行改进,以实现对结果的自动打印功能(结果以dict-like 实例返回),并具有直接的data访问别名。
尽管如此:
-
由于我编写了一个混合声明并额外使用
next来对齐LegDown和LegUp值的实现组合,出现了一个隐晦的错误。这个错误是为了简化传递多个
Lines的单个数据而引入的,以便Indicators可以对每条线进行操作作为单独的数据。
后者将我推向:
-
添加一个与
LineDelay相反的背景对象以“看”到“未来”。实际上这意味着实际值被写入过去的数组位置。
一旦所有这些都就位了,就是重新测试以上请求提出的(小?)挑战,看看如何更轻松地解决以及更快地(在实现时间上)解决的时候了。
最后,执行和结果为从 1998 年至今的 Eurostoxx 50 期货:
bt-run.py \
--csvformat vchartcsv \
--data ../datas/sample/1998-2015-estx50-vchart.txt \
--analyzer legdownup \
--pranalyzer \
--nostdstats \
--plot
====================
== Analyzers
====================
##########
legdownupanalyzer
##########
Date,LegDown,LegUp_5,LegUp_10,LegUp_15,LegUp_20
2008-10-10,901.0,331.0,69.0,336.0,335.0
2001-09-11,889.0,145.0,111.0,239.0,376.0
2008-01-22,844.0,328.0,360.0,302.0,344.0
2001-09-21,813.0,572.0,696.0,816.0,731.0
2002-07-24,799.0,515.0,384.0,373.0,572.0
2008-01-23,789.0,345.0,256.0,319.0,290.0
2001-09-17,769.0,116.0,339.0,405.0,522.0
2008-10-09,768.0,102.0,0.0,120.0,208.0
2001-09-12,764.0,137.0,126.0,169.0,400.0
2002-07-23,759.0,331.0,183.0,285.0,421.0
2008-10-16,758.0,102.0,222.0,310.0,201.0
2008-10-17,740.0,-48.0,219.0,218.0,116.0
2015-08-24,731.0,nan,nan,nan,nan
2002-07-22,729.0,292.0,62.0,262.0,368.0
...
...
...
2001-10-05,-364.0,228.0,143.0,286.0,230.0
1999-01-04,-370.0,219.0,99.0,-7.0,191.0
2000-03-06,-382.0,-60.0,-127.0,-39.0,-161.0
2000-02-14,-393.0,-92.0,90.0,340.0,230.0
2000-02-09,-400.0,-22.0,-46.0,96.0,270.0
1999-01-05,-438.0,3.0,5.0,-107.0,5.0
1999-01-07,-446.0,-196.0,-6.0,-82.0,-50.0
1999-01-06,-536.0,-231.0,-42.0,-174.0,-129.0
2015 年 8 月的下跌在第 13 个位置显示出来。显然是一个不常见的事件,尽管有更大的事件发生过。
针对指向上升的后续腿要做的事情对于统计学家和聪明的数学头脑来说要多得多,而对我来说则要少得多。
关于LegUpDownAnalyzer的实现细节(在末尾看到整个模块代码):
-
它在
__init__中创建指标,就像其他对象一样:Strategies,Indicators通常是常见的嫌疑人这些指标会自动注册到附加了分析器的策略中
-
就像策略一样,
Analyzer有self.datas(一个数据数组)和它的别名:self.data、self.data0、self.data1… -
类似策略:
nexstart和stop钩子(这些在指标中不存在)在这种情况下用于:
-
nextstart: 记录策略的初始起始点 -
stop: 进行最终的计算,因为事情已经完成
-
-
注意:在这种情况下不需要其他方法,如
start、prenext和next -
LegDownUpAnalyzer方法print已经被重写,不再调用pprint方法,而是创建计算的 CSV 打印输出
经过许多讨论,因为我们将 --plot 加入了混合中 … 图表。
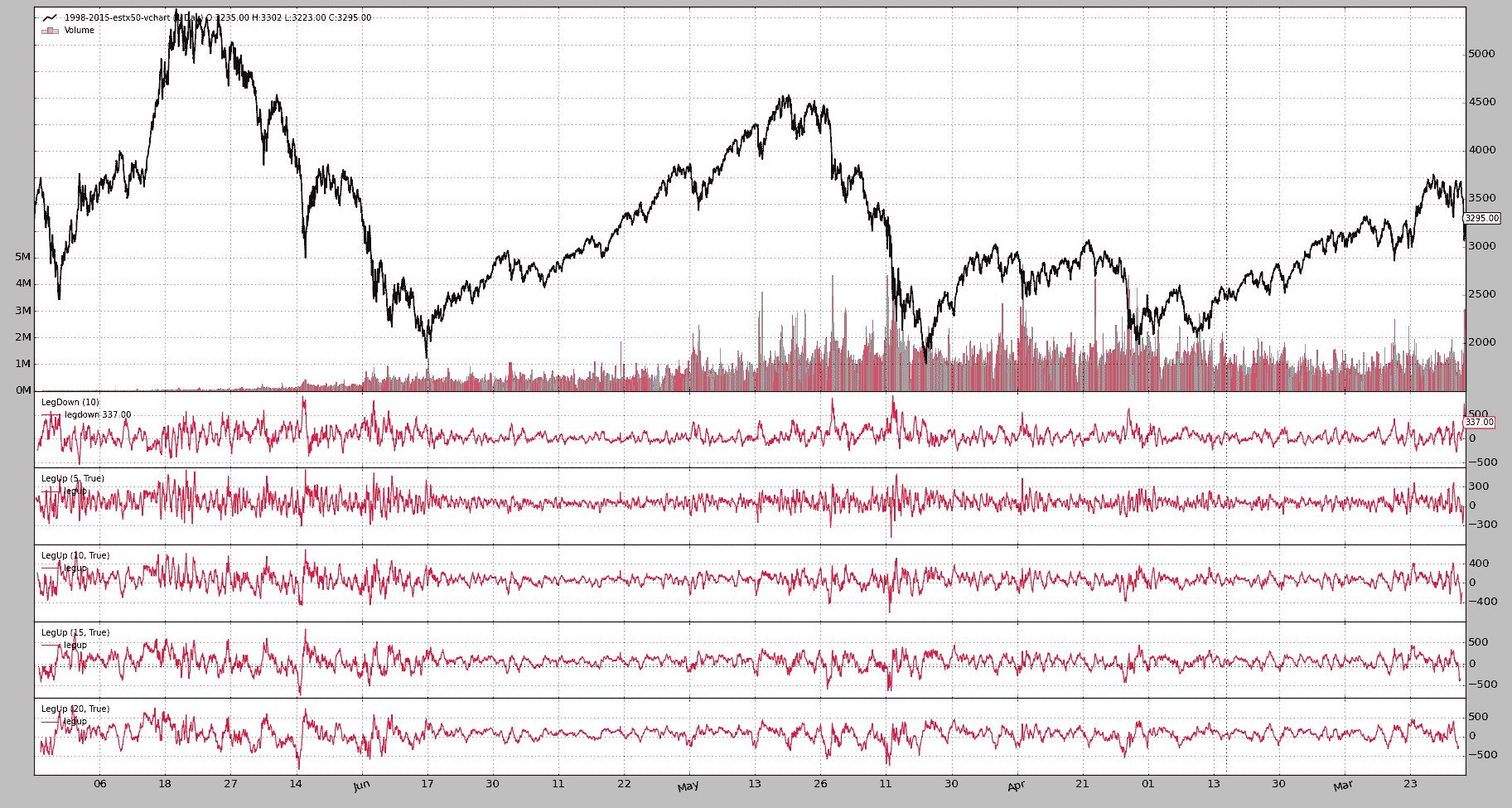
最后是由 bt-run 加载的 legupdown 模块。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import itertools
import operator
import six
from six.moves import map, xrange, zip
import backtrader as bt
import backtrader.indicators as btind
from backtrader.utils import OrderedDict
class LegDown(bt.Indicator):
'''
Calculates what the current legdown has been using:
- Current low
- High from ``period`` bars ago
'''
lines = ('legdown',)
params = (('period', 10),)
def __init__(self):
self.lines.legdown = self.data.high(-self.p.period) - self.data.low
class LegUp(bt.Indicator):
'''
Calculates what the current legup has been using:
- Current high
- Low from ``period`` bars ago
If param ``writeback`` is True the value will be written
backwards ``period`` bars ago
'''
lines = ('legup',)
params = (('period', 10), ('writeback', True),)
def __init__(self):
self.lu = self.data.high - self.data.low(-self.p.period)
self.lines.legup = self.lu(self.p.period * self.p.writeback)
class LegDownUpAnalyzer(bt.Analyzer):
params = (
# If created indicators have to be plotteda along the data
('plotind', True),
# period to consider for a legdown
('ldown', 10),
# periods for the following legups after a legdown
('lups', [5, 10, 15, 20]),
# How to sort: date-asc, date-desc, legdown-asc, legdown-desc
('sort', 'legdown-desc'),
)
sort_options = ['date-asc', 'date-des', 'legdown-desc', 'legdown-asc']
def __init__(self):
# Create the legdown indicator
self.ldown = LegDown(self.data, period=self.p.ldown)
self.ldown.plotinfo.plot = self.p.plotind
# Create the legup indicators indicator - writeback is not touched
# so the values will be written back the selected period and therefore
# be aligned with the end of the legdown
self.lups = list()
for lup in self.p.lups:
legup = LegUp(self.data, period=lup)
legup.plotinfo.plot = self.p.plotind
self.lups.append(legup)
def nextstart(self):
self.start = len(self.data) - 1
def stop(self):
# Calculate start and ending points with values
start = self.start
end = len(self.data)
size = end - start
# Prepare dates (key in the returned dictionary)
dtnumslice = self.strategy.data.datetime.getzero(start, size)
dtslice = map(lambda x: bt.num2date(x).date(), dtnumslice)
keys = dtslice
# Prepare the values, a list for each key item
# leg down
ldown = self.ldown.legdown.getzero(start, size)
# as many legs up as requested
lups = [up.legup.getzero(start, size) for up in self.lups]
# put legs down/up together and interleave (zip)
vals = [ldown] + lups
zvals = zip(*vals)
# Prepare sorting options
if self.p.sort == 'date-asc':
reverse, item = False, 0
elif self.p.sort == 'date-desc':
reverse, item = True, 0
elif self.p.sort == 'legdown-asc':
reverse, item = False, 1
elif self.p.sort == 'legdown-desc':
reverse, item = True, 1
else:
# Default ordering - date-asc
reverse, item = False, 0
# Prepare a sorted array of 2-tuples
keyvals_sorted = sorted(zip(keys, zvals),
reverse=reverse,
key=operator.itemgetter(item))
# Use it to build an ordereddict
self.ret = OrderedDict(keyvals_sorted)
def get_analysis(self):
return self.ret
def print(self, *args, **kwargs):
# Overriden to change default behavior (call pprint)
# provides a CSV printout of the legs down/up
header_items = ['Date', 'LegDown']
header_items.extend(['LegUp_%d' % x for x in self.p.lups])
header_txt = ','.join(header_items)
print(header_txt)
for key, vals in six.iteritems(self.ret):
keytxt = key.strftime('%Y-%m-%d')
txt = ','.join(itertools.chain([keytxt], map(str, vals)))
print(txt)
数据 - 重放
原文:
www.backtrader.com/blog/posts/2015-08-25-data-replay/data-replay/
时间已经过去,针对一个完全形成和关闭的柱状图测试策略是好的,但可以更好。
这就是数据重放的用武之地。如果:
- 策略在时间框架 X(例如:每日)上运行
和
- 较小时间框架 Y(例如:1 分钟)的数据可用
数据重放正如其名称所示:
Replay a daily bar using the 1 minute data
当然,这并不是市场实际发展的方式,但比孤立地查看每日完整和关闭的柱状图要好得多:
If the strategy operates in realtime during the formation of the daily bar,
the approximation of the formation of the bar gives a chance to replicate the
actual behavior of the strategy under real conditions
将数据重放付诸实践遵循backtrader的常规使用模式
-
加载数据源
-
将数据传递给
DataReplayer,这是另一个将在加载的数据源上工作的数据源 -
将新的数据源传递给 cerebro
-
添加一个策略
-
然后运行... 禁用预加载*
注意
当数据被重放时,无法支持预加载,因为每个柱状图实际上是实时构建的。
为了演示,将在每周基础上重放标准的 2006 年日常数据。这意味着:
-
最终将有 52 个柱状图,每周一个
-
Cerebro 将总共调用
prenext和next255 次,这是每日柱状图的原始计数
技巧:
-
当每周柱状图形成时,策略的长度(
len(self))将保持不变。 -
每个新周,长度将增加一
以下是一些示例,但首先是测试脚本的源代码,其中加载数据并传递给重放器...并且使用preload=False来禁用预加载(强制)
dataname=datapath)
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
data_replayed = bt.DataReplayer(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# First add the original data - smaller timeframe
cerebro.adddata(data_replayed)
# Run over everything
cerebro.run(preload=False)
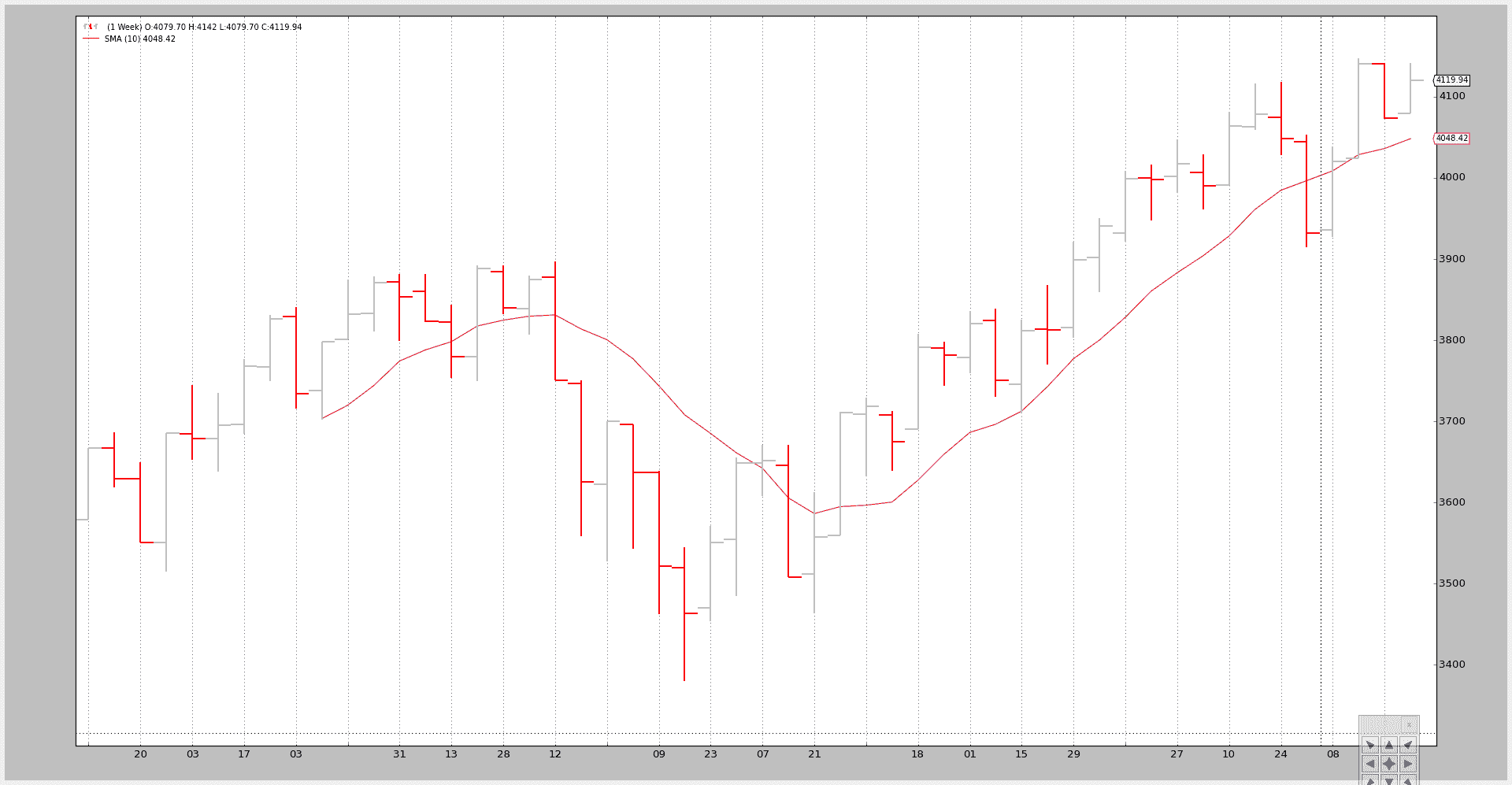
示例 - 将每日重放为每周
脚本的调用:
$ ./data-replay.py --timeframe weekly --compression 1
不幸的是,图表无法向我们展示背景中发生的真实情况,因此让我们看看控制台输出:
prenext len 1 - counter 1
prenext len 1 - counter 2
prenext len 1 - counter 3
prenext len 1 - counter 4
prenext len 1 - counter 5
prenext len 2 - counter 6
...
...
prenext len 9 - counter 44
prenext len 9 - counter 45
---next len 10 - counter 46
---next len 10 - counter 47
---next len 10 - counter 48
---next len 10 - counter 49
---next len 10 - counter 50
---next len 11 - counter 51
---next len 11 - counter 52
---next len 11 - counter 53
...
...
---next len 51 - counter 248
---next len 51 - counter 249
---next len 51 - counter 250
---next len 51 - counter 251
---next len 51 - counter 252
---next len 52 - counter 253
---next len 52 - counter 254
---next len 52 - counter 255
正如我们所看到的,内部的self.counter变量正在跟踪每次调用prenext或next。前者在应用简单移动平均产生值之前调用。后者在简单移动平均产生值时调用。
关键:
- 策略的长度(len(self))每 5 个柱状图(每周 5 个交易日)发生变化
该策略实际上看到:
-
每周柱状图是如何在 5 次快照中发展的。
再次强调,这并不复制市场的实际逐笔(甚至不是分钟、小时)发展,但比实际看到柱状图要好。
可视化输出是周线图表,这是系统正在进行测试的最终结果。
示例 2 - 每日到每日带压缩
当然,“重放”也可以应用于相同的时间框架,但具有压缩。
控制台:
$ ./data-replay.py --timeframe daily --compression 2
prenext len 1 - counter 1
prenext len 1 - counter 2
prenext len 2 - counter 3
prenext len 2 - counter 4
prenext len 3 - counter 5
prenext len 3 - counter 6
prenext len 4 - counter 7
...
...
---next len 125 - counter 250
---next len 126 - counter 251
---next len 126 - counter 252
---next len 127 - counter 253
---next len 127 - counter 254
---next len 128 - counter 255
这次我们得到了预期的一半柱状图,因为请求的压缩因子为 2。
图表:
结论
可以对市场发展进行重建。通常会提供一组较小的时间范围数据,可以用来离散地重播系统运行的时间范围。
测试脚本。
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class SMAStrategy(bt.Strategy):
params = (
('period', 10),
('onlydaily', False),
)
def __init__(self):
self.sma = btind.SMA(self.data, period=self.p.period)
def start(self):
self.counter = 0
def prenext(self):
self.counter += 1
print('prenext len %d - counter %d' % (len(self), self.counter))
def next(self):
self.counter += 1
print('---next len %d - counter %d' % (len(self), self.counter))
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(stdstats=False)
cerebro.addstrategy(
SMAStrategy,
# args for the strategy
period=args.period,
)
# Load the Data
datapath = args.dataname or '../datas/sample/2006-day-001.txt'
data = btfeeds.BacktraderCSVData(
dataname=datapath)
tframes = dict(
daily=bt.TimeFrame.Days,
weekly=bt.TimeFrame.Weeks,
monthly=bt.TimeFrame.Months)
# Handy dictionary for the argument timeframe conversion
# Resample the data
data_replayed = bt.DataReplayer(
dataname=data,
timeframe=tframes[args.timeframe],
compression=args.compression)
# First add the original data - smaller timeframe
cerebro.adddata(data_replayed)
# Run over everything
cerebro.run(preload=False)
# Plot the result
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
description='Pandas test script')
parser.add_argument('--dataname', default='', required=False,
help='File Data to Load')
parser.add_argument('--timeframe', default='weekly', required=False,
choices=['daily', 'weekly', 'monhtly'],
help='Timeframe to resample to')
parser.add_argument('--compression', default=1, required=False, type=int,
help='Compress n bars into 1')
parser.add_argument('--period', default=10, required=False, type=int,
help='Period to apply to indicator')
return parser.parse_args()
if __name__ == '__main__':
runstrat()