通过显式和隐式的Occupancy预测来做3D检测,用Occupancy弥补了深度图的局限性。设计了3D几何分支和特征传播分支,预测depth-occupancy权重来实现3D检测,由于点级Occupancy的构建依赖于bbox,使整个感知模型与检测任务强相关。
Abstract
传构建BEV表示的方法是基于显式预测的深度分布,将2D图像特征映射到视锥空间内。受限于深度分布的局限性(无内部空间和整体几何结构,只有可见表面),得到的3D表征太稀疏。为此,本文提出BEV-IO(3D 检测),通过实例Occupancy信息来增强BEV感知。其核心是新设计的实例Occ预测(IOP)模块,旨在推断每个instance在视锥空间内point-level的占据状态。为了保证高效训练的同时保持表征的灵活性,组合显式和隐式监督来训练。基于预测的Occ信息,设计一种几何感知的特征传播机制(GFP),该机制基于视锥体内每条ray上的Occupancy分布来执行自注意力,以确保实例级的特征一致性。结合IOP和GFP,BEV-IO能够通过更全面的BEV表征得到高信息量的3D场景结构。实验表明,BEV-IO在增加可忽略参数降低计算成本的情况下达到sota性能。
1. Introduction
BEV方法在3D检测中广泛应用,相比于基于激光雷达的方法,基于摄像头的方法具有更高的成本效益,并在自动驾驶和机器人等实际应用中显示出强大的潜力。基于摄像头的方法主要分为两个流派,其区别在于它们是否显式估计场景的深度分布。
视觉3D检测相比LiDAR成本低,基于视觉的3D检测方法根据其是否显式估计场景深度分布分为两个流派:
- 隐式方法:使用 BEV query 和注意力机制来从多视图中隐式地获取BEV特征,从而避免深度估计。但是缺乏深度信息,在 corner case 易过拟合。(BEVFormer,BEVFormer v2)
- 显式方法:将2D图像特征用估计的深度提升到视锥空间,再投射到BEV空间,明确利用深度生成BEV。BEVDepth,BEVDet)
显式方法必须构建BEV特征,涉及两个关键方面:如何将2D特征映射到BEV空间和要映射哪些特征。前者的关键在于精确的3D几何感知。LSS第一个提出2D-BEV映射过程,但由于缺少深度真值,只能通过BEV的bbox隐式学习深度信息,且关注区域的目标深度,导致整体场景的深度较差。还有利用稀疏深度真值来监督深度估计,显著提高深度估计的准确性。但是这些方法面临两个主要问题:
- 深度信息的不完整性:只能表征可见物体表面,无法获取内部空间和整体几何结构,导致BEV空间下的3D表征稀疏。(如下图1(a))
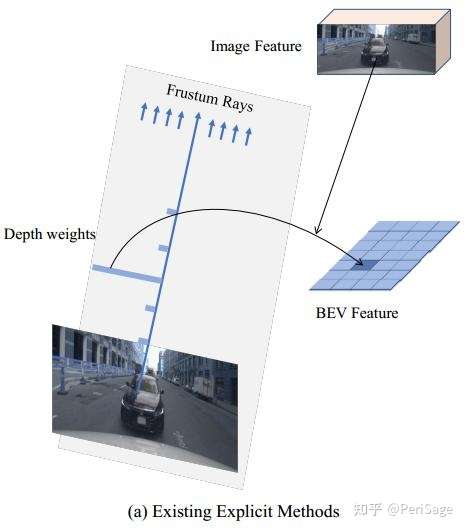 图1 (a) 现有基于BEV方法使用估计的深度权重将图像特征提升到BEV空间,其中深度权重仅有可见表面的特征。
图1 (a) 现有基于BEV方法使用估计的深度权重将图像特征提升到BEV空间,其中深度权重仅有可见表面的特征。
稀疏性:很多 instance 相对小且远,LiDAR点很稀疏。
总的说来,显式方法在BEV特征构建中面临的问题,即深度估计的准确性和表示的稀疏性。
针对上述问题,本文提出BEV-IO,一种基于 instance Occupancy 信息的3D检测新范式。用 Occupancy 表示三维点被物体占用的概率,相比于深度,更能捕捉到场景的全面三维空间几何信息。其核心是利用 instance occupancy 预测,通过更完整更准确地将特征提升到BEV空间来辅助显式BEV检测方法。(见图1(b))
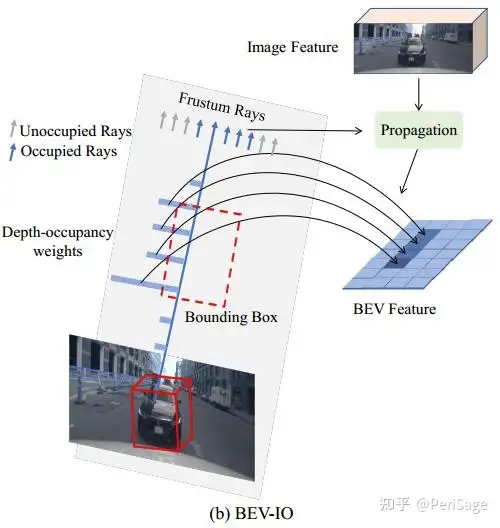 图1 (b) 在深度权重上引入Occupancy权重来获取更完整精确的BEV表征,此外,提出用Occupancy线索传播图像特征来获取几何感知的图像特征。
图1 (b) 在深度权重上引入Occupancy权重来获取更完整精确的BEV表征,此外,提出用Occupancy线索传播图像特征来获取几何感知的图像特征。
为此,提出 instance occupancy prediction(IOP)模块,结合了了显式和隐式训练方式。显式训练方式利用3Dbbox注释作为强监督信号,隐式训练策略则针对最终检测性能以端到端方式优化Occupancy预测,从而实现更灵活的训练。融合上述两种策略,IOP能够填补对象内部结构,且受稀疏深度影响较小,从而得到更面向实例的全面的BEV表征。
针对第二个“要映射哪些特征”的问题,现有方法只利用2D图像特征,忽略了3D几何和图像领域之间的交互关系,而BEVFusion系列工作表,几何和图像特征的融合对BEV检测至关重要。因此,本文不使用复杂的3D encoders来提取几何特征,而是设计一种geometry-aware feature propagation(GFP)机制作为替代方案,利用几何线索来传播图像上下文特征。
对于第二个问题(要映射哪些特征):设计了一种几何感知特征传播(GFP)机制作为替代方案,利用几何线索传播图像上下文特征,沿着每条输入射线进行占用分布自注意力来图像特征传递,并融入占用的几何结构信息,以更好地捕捉物体的内部空间结构。基于同一对象实例中的特征点具有类似的占用状态,本文通过沿每条ray的Occupancy分布执行self-attention来传播图像特征,在考虑Occupancy几何结构信息的同时,保证了每个instance的特征一致性。
本文的方法通过GFP机制融合IOP模块,与大多数BEV的3D检测框架兼容,主要贡献有以下几点:
- 分析了面向深度的特征提升过程的缺点,提出了新的实例占用预测(IOP)模块来增强BEV特征表征的完整性和准确性。
- 提出几何感知的特征传播机制(GFP)来进一步增强带有instance occupancy 线索的图像特征。
- 只增加0.2% 的参数和0.24%的GFLOPS,BEV-IO在流行BEV检测框架下实现了显著的改进。
2. Related Work
- Multi-view 3D Object Detection
- Occupancy Prediction: MonoScene,OccDepth,VoxFormer,TPVFormer,MonoScene
不同于voxel-level方法,BEV-IO在 point-level 操作,使其更有效,更易与适用 frustum-based 的场景。
3 Method
3.1 Explicit BEV Detection Revisit
将六视图
输入预训练的图像编码器,输出图像特征 ,其中,H,W,和C分别为特征图的高度,宽度和维度(channel)。不同于隐式方法,显式方法需要估计每个视图的深度视锥(depth frustum) ,其中深度视锥 为当前视图视锥中沿每条ray的不同手工设定的深度区间(depth bins)的概率, 为深度区间(depth bins)的个数。通过使用深度视锥对图像特征加权(外积运算)可以得到图像特征视锥:
多视角的图像特征视锥被提升到3D空间,并通过体素池化操作映射到BEV空间。
其中,K为相机内参,Proj为从图像到3D空间测投影操作,VoxelPooling为体素池化过程,最后得到的BEV特征输入到指定任务的检测头中以获取最终的检测结果(类别,位置,尺寸和速度)。
3.2 Overview of BEV-IO
整体框架由图像编码器(image encoder),视图转换器(view-transformer) 和检测头 (detection head)三部分组成,其中,图像编码器和检测头与BEVDepth相同。主要是视图转换器,采用双分支结构:3D几何分支和特征传播分支。
- 3D几何分支:一个深度解码器和两个实例Occupancy预测(IOP)解码器组成,给定来自图像编码器的图像特征,深度解码器预测深度权重(与BEVDepth一致),同时IOP解码器则预测视锥空间中的实例Occupancy权重。深度和显式IOP解码器通过gt监督。深度和Occupancy权重融合为depth-occupancy权重,并用来将图像特征提升到视锥空间。
- 特征传播分支:核心为几何感知特征传播模块(GFP)。输入显式的实例Occupancy权重和图像特征,生成几何感知特征。这些特征将被投影到视锥空间,形成BEV特征。
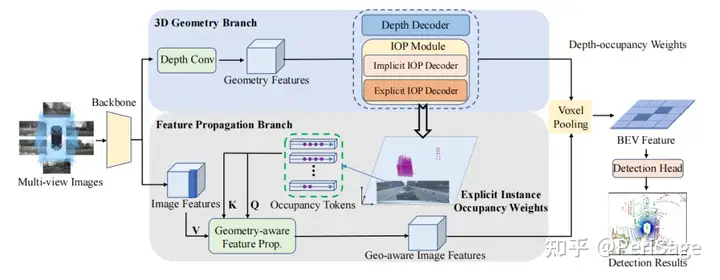 Figure 2: BEV-IO ppl
Figure 2: BEV-IO ppl
整个流程,3D几何分支接收图像backbone提取的图像特征作为输入,用于估计深度和显式/隐式实例Occupancy权重。这些权重被融合起来生成depth-occupancy权重。特征传播分支也以图像特征和显式实例Occupancy权重作为输入,然后通过一个几何感知的传播模块进一步增强图像特征,并融合几何信息。随后,使用depth-occupancy权重将获取到的几何感知特征投影到BEV空间中,最后将BEV 特征经过检测头得到最终结果。
3.3. 3D Geometry Branch
已有的基于深度的特征提升方法在深度不完整时有局限性,本文用点级的实例Occupancy来实现特征提升。如图3所示,3D几何分支不仅包含先前方法中的深度解码器,好包含两个并列的IOP解码器以推理出更全面的场景3D几何。
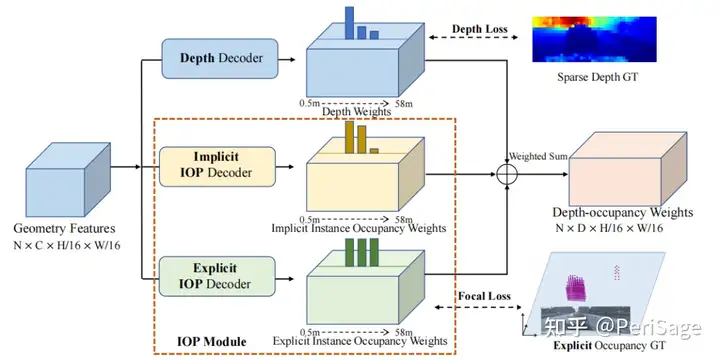 Figure 3: 3D Geometry Branch. 3D几何分支以图像特征作为输入,预测深度、显式实例Occupancy权重和隐式实例Occupancy权重。深度和显式实例Occupancy权重受到GT深度和生成的显式实例Occupancy的监督。隐式实例Occupancy权重学习一种隐式Occupancy表示,depth-occupancy权重是这三种权重的加权和。
Figure 3: 3D Geometry Branch. 3D几何分支以图像特征作为输入,预测深度、显式实例Occupancy权重和隐式实例Occupancy权重。深度和显式实例Occupancy权重受到GT深度和生成的显式实例Occupancy的监督。隐式实例Occupancy权重学习一种隐式Occupancy表示,depth-occupancy权重是这三种权重的加权和。
Depth Decoder:在BEVdepth 的基础上,深度解码器位一组人工设计的深度区间(depth-bins)预测深度权重
,由二值交叉熵损失进行监督:
其中,gt depth在计算损失时转换为one-hot形式。
Implicit IOP Decoder:深度权重仅获取了对象的视觉表面,为了填补物体缺失的内部空间,设计了隐式IOP解码器来估计沿每条ray
的深度区间的占用概率。与真值深度监督的深度解码器相反,在没有显式监督的情况下以端到端的方式训练隐式IOP解码器。因此,该解码器有很强的灵活性,且有可能为图像特征提升生成最右的空间权重,从而得到更精确的3D检测结果。
Explicit IOP Decoder:没有直接和具体的监督,隐式IOP解码器很难训练。因此设计显式IOP解码器来预测显式占用权重
。由于点级的占用注释成本高且少见,本文从3D bbox的gt中构建Occupancy标签。简单来说,将Occupancy标记建模为视锥体(view-frustum)空间中的二元分类问题:物体bbox内的3D点标记为1,其余为0。由于目标是检测3D bbox,因此上述策略合理且消除人工标注的需要。训练时通过Focal Loss来减轻类别不平衡的影响:
其中,
为二进制占用标签。给定隐式和显式Occupancy权重和深度权重时,最终的depth-occupancy权重如下:
其中, 和
为加权组合的可训练参数,最终的depth-occupancy权重将2D图像特征体素到视锥体((view-frustum))空间。
Point-level Occupancy Ground Truth Generation:本文提出一种简单高效的通过3D bbox来标注点级占用的方法(通过将3D物体边界框划分为盒子的内部和外部来确定点的占用状态)。下面是具体的步骤:
- 对于每个bbox,将3D空间划分为box的内部和外部,
- 对于每个点,通过计算该点和六个box面的表面法向量之间的点积来确定其相对于box的位置(内/外),
- 如果该点在bbox的所有六个面内部(点与边界框的所有面的法向量点积都为正),则为标记为占用。(反之,在外部,即点与边界框的任何一个面的法向量点积为负,标记为未占用,)
伪代码如下:

3.4. Feature Propagation Branch
沿每条ray的instance Occupancy权重编码了几何结构信息。此外,同一对象上的特征点,Occupancy权重相似。基于此设计了 geometry-aware feature propagation (GFP) 模块,利用Occupancy权重的几何信息来增强每个对象区域内的特征一致性。如下图4所示,将每个特征点的显式Occupancy权重作为key和query,其对应的特征特征作为value。通过计算自注意力来实现图像特征的几何感知传播。由于相似的Occupancy权重,图像特征将在相同的实例中传播。所以输出的特征是几何感知的,并被投影到BEV空间,用于后续的检测过程
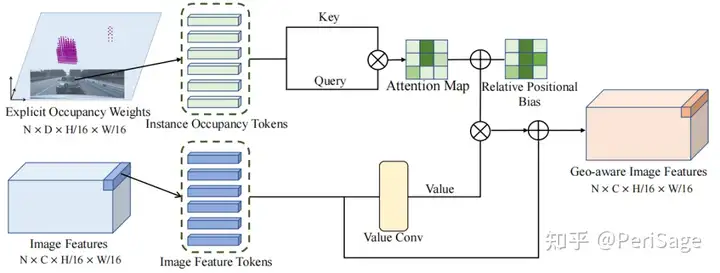 图4 几何感知的特征传播机制(GFP) 输入为显式实例Occupancy和图像特征,GFP将显式Occupancy token标记为键值对,执行自注意力,在图像特征上进行几何感知的特征传播。
图4 几何感知的特征传播机制(GFP) 输入为显式实例Occupancy和图像特征,GFP将显式Occupancy token标记为键值对,执行自注意力,在图像特征上进行几何感知的特征传播。
3.5. Loss Function
总损失是检测损失
、深度损失 和占用损失的加权组合:
λ为预定义的损失权重超参数。
4. Experiment
4.1. Datasets and Metrics and
- 数据集:使用nuScenes数据集(大规模的自动驾驶数据集),包含超过1,000个场景的复杂城市驾驶场景,并标注了10个类别的1.4 million个3D bbox。这些场景涵盖了波士顿和新加坡的不同天气、光照条件和交通情景。
- 数据集划分:数据集官方划分为训练、验证和测试集,比例为700/150/150。
- 评估指标:评估BEV-IO性能时,使用nuScenes数据集官方提供的一系列评估指标。包括nuScenes检测分数(NDS)和平均精度均值(mAP),用于衡量目标检测任务的准确性。此外,还用了平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)和平均属性误差(mAAE),用于评估定位、尺度、方向、速度和属性等方面的误差。
4.2 Experiment Settings
实验基于BEVDepth进行,引入ResNet50作为图像backbone,图像resize到分辨率为704 × 256,图像和BEV的数据增强从BEVDet引入(包括随机裁剪,随机缩放,随机翻转和随机旋转)。训练时,只将gt的投影深度,检测注释用作监督。使用AdamW优化器,学习率:2e-4,batch_size: 32,损失权重 和
分别为 1.0,3.0和3000.0。为了与其他方法的公平对比,使用了CBGS策略,在消融分析时,为了训练的高效,没有使用该策略。所有实验在8张 NVIDIA-3090 上完成。推理时,输入多视图图像和相机内参,输出物体的类别,位置,尺寸和速度。
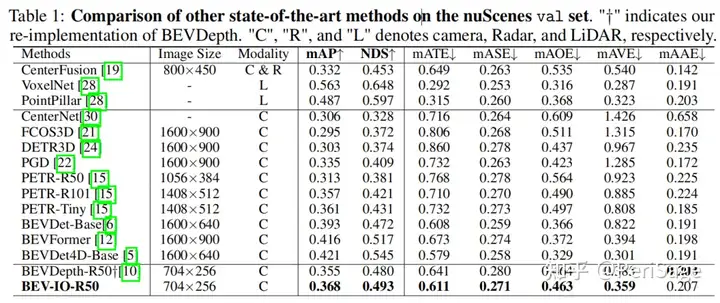
4.3 3D Object Detection Results
在NuScenes val集上与其他基于BEV的方法对比,公平起见,所有方法都使用了CBGS策略进行训练。结果如图1所示,BEV-IO优于BEVDepth方法,而且仅增加了0.15M的参数和0.6 GFLOPS的计算量。
4.4 Ablation Study
消融实验时,不使用CBGS训练策略。首先是BEV-IO所提的三个组件的情况,其中 Im-Occ, Ex-Occ, 和 GFP分别为显式实例 Occupancy 预测,隐式实例Occupancy预测,和几何感知的特征传播。
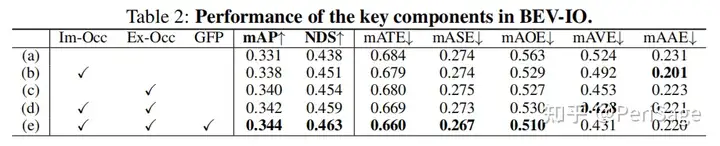
为了验证一个问题:在估计的深度足够准确时,是否仍需要实例Occupancy信息。为此,设计两个实验,(a) 移除深度解码器,直接使用gt深度当作one-hot输入,(b) 此基础上移除实例Occupancy信息。前者表示深度信息足够的情况,后者为在深度信息足够时不使用实例占据信息,两者的对比情况如下,移除实例Occupancy各方面精度均下降。可见,在估计的深度足够准确时,仍需要实例Occupancy信息。

接下来是对各方法参数、计算复杂度的比较,与baseline相比,BEV-IO仅增加0.2%的参数、0.24%的GFLOPs的情况下,其他指标得到了提升:

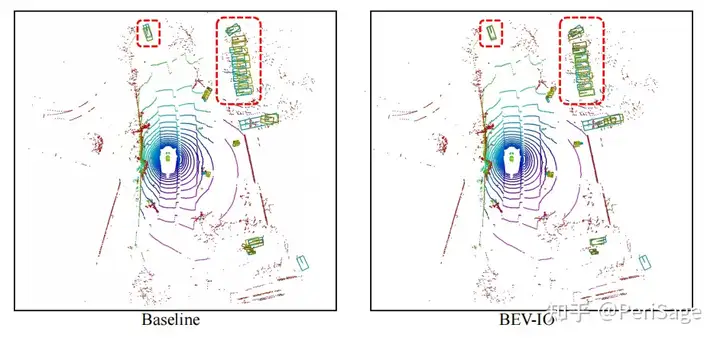
最后是检测结果的可视化,BEV-IO的预测结果和GT重合更接近(黄框:预测框;绿色:GT)
5. Conclusion
本文提出了BEV-IO,利用point-level的实例Occupancy解决深度在获取整个实例时的局限性。设计了实例Occupancy预测(IOP)模块,模该块通过显式和隐式地估计实例点级Occupancy信息来促进更全面的BEV特征表征。此外,引入几何感知的特征传播机制,通过结合几何线索来高效传播图像特征,实验表明,BEV-IO在性能上达到了SOTA,而且只增加了参数增加(0.2%)和计算开销(GFLOPs中的0.24%)(可忽略)。
6. Thought
利用Occupancy来进行3D检测,一定程度上弥补了深度图的局限性,但是,由于在点级的Occupancy预测时,直接用bbox作为区别,使得整个感知模型与3D检测任务强相关,对SSC一类的任务不一定可行。但是depth-occupancy的设计思想还是值得借鉴的。
标签:Eye,Enhancing,特征,显式,Occupancy,深度,BEV,3D From: https://www.cnblogs.com/jimchen1218/p/18022052