磁带存储:有 \(n\) 个磁带,每个片段有两个参数:时长 \(t_i\) 和频率 \(a_i\)。以某种顺序把片段排在磁带里,每个片段的花费为(播放完这个片段的时刻)乘以(该片段的频率)
求最小花费和。
因为两个片段交换,对之后没有影响。 所以可以考虑一个顺序中,如果 \(x,x+1\) 片段换位置后花费的变化。设 \(x\) 之前的片段时长总和为 \(S\)。
换前:\((S+t_x)a_x+(S+t_x+t_{x+1})a_{x+1}\)
换后:\((S+t_{x+1})a_{x+1}+(S+t_x+t_{x+1})a_x\)
两个做差,得到:换之前比换之后好的条件是 \(t_x/a_x\le t_y/a_y\)。
按这个排序即可。
商店访问:有 \(n\) 个商店。如果第 \(t\) 时刻到商店 \(i\),需要停留 \(a_it+b_i\) 分钟。问:\(T\) 分钟最多能访问多少个商店。\(1\le n \le 10^5\),\(a_i,b_i\) 为非负整数。
与上题同理。邻项交换法:要求 \(b_i/a_i\) 小的在前面。(如果 \(a_i=0\) 肯定是丢到所有 \(a_i>0\) 的之后再访问)
但是我们并不能排了序直接扫过去,因为上面只能说明 \(b_i/a_i\) 小的一定在前面,不能说明一定就这么连续。
所以排了序之后做 DP:\(f[i][j]\) 表示前 \(i\) 个商店中访问其中 \(j\) 个的最短用时。
则 \(f[i][j]=\min(f[i-1][j],f[i-1][j-1]\cdot(1+a_i)+b_i).\)
但是这是 \(O(n^2)\) 的,优化。
如果 \(a_i,b_i>0\),发现一个性质:如果是在 \(t_0\) 时刻进入商店 \(i\),那出来时就是 \(t_0+t_0a_i+b_i\ge 2t_0\),说明每进入一个商店时间至少翻倍。那么 DP 的第二维就不需要开到 \(n\),只需要 \(\log T\),时间复杂度优化到 \(n\log T\)。
但题目的 \(a_i\) 是非负的。这也没关系——\(a_i=0\) 的一定是丢到最后访问,而不同的 \(a_i=0\) 之间一定是按照 \(b_i\) 从小到大访问。
安装 app:有 \(n\) 个可安装 APP,第 \(i\) 个安装时需要空间 \(d_i\),安装完后会占据 \(s_i\) 空间。初始空间为 \(S\),最多能安装多少个 APP?(\(1\le n \le 2000\))
两个 APP 相邻的交换对后面没影响。
如果 \(i\) 在 \(j\) 前,我们肯定希望在安装这两个软件的过程中,任何时刻所需空间的最大值最小,这样我们能尽量保证两个软件都能安装。
如果 \(i\) 在 \(j\) 之前安装,安装过程中所需空间最大值为 \(\max(d_i,s_i+\max(d_j,s_j))\)。
(安装 \(i\) 所需空间 \(d_i\),安装完 \(i\) 已经固定占据了 \(s_i\),再安装 \(j\) 时需要空间 \(s_i+d_j\),安装完了需要空间 \(s_i+s_j\)。这些一起取 \(\max\))
同理 \(j\) 在 \(i\) 前安装:\(\max(d_j,s_j+\max(d_i,s_i))\)。
要 \(i\) 先更好,那么 \(\max(d_i,s_i+\max(d_j,s_j))<\max(d_j,s_j+\max(d_i,s_i))\)
那么有 \((d_i<d_j \&\&s_i+\max(d_j,s_j)<d_j)\) 或 \((d_i<s_j+\max(d_i,s_i)\&\&s_i+\max(d_j,s_j)<s_j+\max(d_i,s_i))\)。
但是第一种情况是不可能的,因为 \(s_i+\max(d_j,s_j)>d_j\)。
所以只有第二种,而 \(d_i<s_j+\max(d_i,s_i)\) 恒成立。
因此只需要 \(s_i+\max(d_j,s_j)<s_j+\max(d_i,s_i)\) 即可。
即按照 \(s_i-\max(d_i,s_i)\) 从小到大排序即可。
树的访问:给出一棵树带点权 \(\{a_n\}\),求一个欧拉序,使得 \(\max\{a_u+t_u\}\) 最小,\(t_u\) 表示第一次访问 \(u\) 的时刻。\(1\le n \le 10^5\)。
两个儿子先后访问对之后没影响。(所需时间都是两个子树之和)
\(f[i]\) 表示 \(i\) 的子树里 \(\max\{a_u+t_u\}\) 的最小值。
\(d[u]\) 表示 \(u\) 的子树里走一遍欧拉序所需总时间(欧拉序长度)。
\(d[u]=1+\displaystyle \sum_{v\in sons[u]}(d[v]+1).\)
比如树 1-2,2-3,2-4,1-5 的欧拉序就是 123242151。(每条边过一次,根结点多过一次)
设两个儿子 \(v_i,v_j\)。走它们之前先走了 \(d_0\) 个结点。
如果先走 \(v_i\),此时 \(v_i,v_j\) 贡献的最大值为\(\max(d_0+f[v_i], d_0+d[v_i]+1+f[v_j])\)。
如果先走 \(v_j\) 也是同理:
\(\max(d_0+f[v_j], d_0+d[v_j]+1+f[v_i])\)。
两个 \(\max\) 有大小关系,\(\max\) 里面的数也有大小关系。
要让 \(v_i\) 先的更小。
则 \(d_0+f[v_i]<d[v_i]+1+f[v_j],d_0+d[v_i]+1+f[v_j]<d_0+d[v_i]+1+f[v_j]\)。
而 \(d_0+f[v_i]<d_0+d[v_j]+1+f[v_i]\) 恒成立。
因此只需 \(d_0+d[v_i]+1+f[v_j]<d_0+d[v_j]+1+f[v_i]\) 即可。
得出 \(d[v_i]-f[v_i]<d[v_j]-f[v_j]\),按这个排序就行。
打怪兽
共 \(n\) 个怪兽,打第 \(i\) 个怪兽会先掉 \(a_i\) 点血,后回 \(b_i\) 点血,每个怪兽只能打一次。血量初始 \(h_0\),要保证血量始终非负。最多能打多少怪兽?
交换相邻两个怪兽打完后剩余的血量一样。
看 \(i,j\) 谁放在前面:哪种方案对初始血量的要求更低?
若 \(i\) 在前:\(\max(a_i,a_i-b_i+a_j)\)。
若 \(j\) 在前:\(\max(a_j,a_j-b_j+a_i)\)。
要让前一个 \(\max\) 更小。下列两个条件中成立一个。
-
\(a_i\le a_j\) 且 \(a_i-b_i+a_j\le a_j\)。
-
\(a_i\le a_j-b_j+a_i\) 且 \(a_i-b_i+a_j\le a_j-b_j+a_i.\)
等价于:
-
\(a_i\le a_j\) 且 \(a_i\le b_i\)。
-
\(b_j\le a_j\) 且 \(b_j\le b_i\)。
但是这条件看着不太好弄啊?既要和 \(j\) 比,又要和 \(i\) 比。我们可以分类,不同类按照不同的比较方法。
把怪物分两类:A 类 \(a_i\le b_i\),B 类 \(a_i>b_i\)。
显然应该先打 A 类怪:打完血还更多了。
对于 A 类内部,按照 \(a_i\le a_j\),即 \(a_i\) 从小到大排序。
对于 B 类内部,按照 \(b_j\le b_i\),即 \(b_i\) 从大到小排序。
这个时候可以搞 DP 了。因为从前往后 DP 不好讨论,所以从后往前 DP。
\(f[i][j]\) 表示 \(i\sim n\) 中打 \(j\) 个怪,所需血量最小值。
\(f[i][j]=\min(f[i+1][j],\max(a_i,a_i-b_i+f[i+1][j-1]))\)。
格式化硬盘:有 \(n\) 块硬盘。第 \(i\) 块硬盘容量 \(a_i\) 且已经装满了数据。如果格式化它会有 \(b_i\) 的空间。
两个相邻硬盘交换后对后面没影响。
现在我们要找一个顺序格式化所有硬盘,且不损坏数据。(硬盘格式化后的空间可以用来复制数据)至少需要多少额外空间?
还是考虑 \(i,j\) 哪个先。考虑这个过程中哪种对空间的要求更小。
\(i\) 先:\(\max(a_i,a_i-b_i+a_j)\)。
\(j\) 先:\(\max(a_j,a_j-b_j+a_i)\)。
这不就和上题一样了吗?不过这里是要打所有怪,求初始血量最小是多少。
可以二分初始血量,然后扫一遍看看行不行。
(重点) 括号序列:给出 \(n\) 个括号序列,每个序列都可以删除一些字符,然后可以把这些括号序列按任意顺序拼接为一个大括号序列。求最后形成的最长合法括号序列的长度。
(等价问题:先按照一个顺序拼好,在连接好的字符串里面挑一些删掉)
而一个括号序列中的最长合法子序列,是一个经典贪心问题,用栈可以解决。那现在唯一的问题就是怎么排序。
设 \(a\) 为最后未匹配右括号数量,\(b\) 为未匹配左括号数量。
我们发现,\(a-b\) 是一定的:等于所有右括号数减去所有左括号数。因为每有一对匹配,左括号右括号是一起少了 \(1\)。
最后我们要让 \(a+b\) 最小,而 \(a-b\) 又一定,那我们只需要 \(a\) 最小就行了。
而我们可以把右括号抽象为 \(-1\) 血,左括号为 \(+1\) 血。要使得 \(a\) 最小,也就是要未匹配右括号最少,也就是在开头加上一些左括号使得合法,加上的数量要最少。
这就变成了 “打怪兽”、“格式化硬盘” 的模型。(前面几题)
agc048b
有 \(n\) 个位置。(\(2\mid n\))每个位置可以填 (,),[,]。如果填小括号,得分 \(a_i\);填中括号,得分 \(b_i\)。求最后填成一个合法括号序列,最大得分。
假设在 \(x_1\sim x_k\) 填中括号。\(x_{2i-1}\) 配 \(x_{2i}\)。考虑到 \(x_{2i-1}\) 与 \(x_{2i+1}\) 之间距离必为偶数,合法序列长度必为偶数。得出结论:\(x_{2i-1},x_{2i}\) 奇偶性相反。
所以 \(x_1\sim x_k\) 中奇偶各半。
引理:若指定 \(k\) 个位置,奇偶各半。存在一种合法序列,使得 \(x_1\sim x_k\) 为中括号。
引理证明:一定有一对相邻的 \(x\) 一奇一偶,这一对前面的填 [,后面的填 ]。因为一奇一偶,中间相隔偶数,那么中间全部 () 交替就行。然后这一段就算填完了,删除这一段,递归处理下一对奇偶相邻的 …… 如此往复,得证。
接下来怎么做?
把所有奇数位置和偶数位置分开成两个数组。分别按照 \(b_i-a_i\) 排序。
然后枚举有多少对位置填中括号。如果枚举了 \(k\) 对,一定是奇数位置的前 \(k\) 个配偶数位置的前 \(k\) 个。(排好序了)
那先排个序,然后扫一遍就行了。
博弈取物:
\(n\) 个物品。第 \(i\) 个物品先手拿到了能获得 \(a_i\) 价值,后手拿到了能获得 \(b_i\) 价值。
先手目标是让自己的价值减去对方价值最大。
后手一定优先选 \(b_i\) 大的,相同再选 \(a_i\) 大的。
求最后先手和后手拿到了什么物品。
后手拿物品的顺序是既定的,唯一的问题就是先手。
把物品按照后手拿物品的顺序排序,考虑先手拿到的物品集合需要满足什么条件。
条件①:先手在前 \(i\) 个里最多选 \(ceil(\dfrac{i}{2})\) 个;也就是后手至少选 \(floor(\dfrac{i}{2})\) 个。
(因为交替,后手一定优先选前面的)
考虑满足 ① 的情况下,先手 - 后手最多多少分?
假设一开始物品全都在先手手里,是后手不停从先手手里拿物品。(并且要满足 ①)
后手每拿走一个物品 \(i\),(先手 - 后手)就会损失 \(a_i+b_i\)。我们要让 \(a_i+b_i\) 尽量小。
到这一步,我们知道先手一定会优先选 \(a_i+b_i\) 尽量小的给后手。
总结一下:
-
先把所有物品按照 \(b_i\) 从大到小排序,\(b_i\) 相同按照 \(a_i\) 从大到小排序。我们之后所有操作的 “前 \(i\) 个” 全部基于这个顺序。
-
物品从头到尾扫一遍,扫到第 \(i\) 个数时,判断后手此时是否已经拿够了 \(floor(\dfrac{i}{2})\) 个。如果没拿够,先手一定会从所有还没给后手的物品中选出 \(a_i+b_i\) 最小的给后手。
-
\(a_i+b_i\) 最小的用堆维护就行。
拓展:如果先手后手的目标都是让(自己价值 - 对手价值)最大,怎么做?
假设物品都在先手手里,先手一定会先锁定 \(a_i+b_i\) 最大的。后手为了让先手损失最大,一定会拿 \(a_i+b_i\) 次大的 …… 最终两个人一定按照 \(a_i+b_i\) 从大到小轮流拿。
可以发现交换两个相邻的字符串,对于前面和后面都没有影响。
因此对于两个字符串 \(s1,s2\),如果 \(s1+s2<s2+s1\),\(s1\) 就排在 \(s2\) 前面。
邻项交换法知,按照 \(t_i/d_i\) 从大到小排序是最优的。
邻项交换法,\(s_i+w_i\) 越小越上面。
先用贪心得知 \(w+s\) 越小的越在上面。
然后 \(dp[i][j]\) 表示前 \(i\) 个盒子且总重量为 \(j\) 的最大价值。
三元组构造(BZ2943):给定三个数 \(p,q,n\),要求构造一些个三元组,满足一下条件:
-
第 \(i\) 个三元组为 \((i,i+p,i+p+q)\) 或 \((i,i+q,i+p+q)\)。
-
三元组的元素 \(\le n+p+q\)。
-
所有三元组不可有重复元素。
-
数 \(1\sim n\) 至少出现一次。
一个粗略的想法是:找到最小的还没出现过的 \(x\),取三元组 \((x,x+?,x+p+q)\),注意因为是从小到大枚举的,所以 \(x+p+q\) 保证不会重复。唯一的问题是中间的取 \(x+p\) 还是 \(x+q\)。
那我们优先取 \(x+p\),如果 \(x+p\) 重复了就取 \(x+q\),对吗?
不对,手玩一个数据 n=5, p=3, q=2 就不对了。
但是,我们如果令 \(p\le q\),这个想法貌似就对了!下面就严格证明一下。
假设已经按照上面的贪心标准选了一些三元组 \((x_i,y_i,z_i)\)。\(r\) 是目前最小的还没选的数。
首先,\(r+p+q\) 显然不会出现在之前的任意三元组中,因为从小到大。
如果 \(r+p\) 还没选,那就选 \((r,r+p,r+p+q)\)。
如果 \(r+p\) 选了,下面证明 \(r+q\) 不出现在任何三元组中。
-
\(r+q=y_i\),也就是 \(r+q=x_i+p\) 或 \(x_i+q\)。
如果 \(r+q=x_i+q\),有 \(r=x_i\),与 \(r\) 还没选矛盾。
如果 \(r+q=x_i+p\),由于 \(r\) 还没选,所以 \(r>x_i\),又 \(p\le q\),得知 \(r+q>x_i+p\),矛盾。
-
\(r+q=z_i\),也就是 \(r+q=x_i+p+q\)。
则 \(r=x_i+p\),这说明 \(x_i+p\) 还没选。但按照我们的贪心策略,一定是优先选 \(x_i+p\) 的。矛盾。
综上所述,当 \(p\le q\) 时,优先选 \(x+p\),然后选 \(x+q\) 是可行的。
区间移位
贪心:覆盖到点 \(A\) 时,每次从所有移动后能到 \(A\) 的区间里挑右端点最小的。
证明用调整法,让右端点小的去覆盖一定不差。
那就可以用堆来维护。
镜子(BZ1380)
一个 \(n\times m\) 的矩形,里面有一些镜子,每个格子只能放一个镜子,每个镜子都是从格子的右上角到左下角摆放。
有一些光从左边和下面进入,给出它们从右边和上面出去的位置,求镜子的摆放方式。(保证光线出口各不相同)
首先如果一束光从同一个位置出去,这一行(列)肯定不能有镜子,可以把这一行(列)删去。
发现一个性质:一束光的出口必然比这束光的入口更右上,这是因为镜子是一个格子的右上-左下对角线。
更有趣的性质:上面这个条件不仅是必要条件,还是充分的。也就是说,只要满足上面的性质,就一定有解。(*)
首先 \(1\times m\) 和 \(n\times 1\) 型的显然满足 (*)。
下面证明当 \(n,m\ge 2\) 时也满足 (*)。
考虑第 \(m\) 列的光线。它的出口显然是在矩形的右侧。假设它从第 \(x\) 行出去。
这时,我们在第 \(1\sim x\) 行第 \(m\) 列的格子里都放上镜子。
这样第 \(m\) 列的光线是可以通过第 \(x\) 行第 \(m\) 列的镜子从第 \(x\) 行出去的。而从第 \(m\) 列出去、从第 \(1\sim x-1\) 出去的光线,可以递归地看作从 \(1\sim x\) 行出去,\(x+1\sim n\) 行的出口不变。
其实就是第 \(x\) 行的出口被第 \(m\) 列的光线用了,然后我们放满镜子,第 \(m\) 列的出口和第 \(1\sim x-1\) 行的出口整体向下移了一格。
这样就形成了一个 \(n\times (m-1)\) 的问题,最后能递归成 \(n\times 1\) 的问题,而这个问题我们已知满足(*)。
因此性质(*)成立。(我们也可以按照上面的递归方法构造)
但是这里再提出一种新的构造方法:贪心。
首先第 \(m\) 列如果要从第 \(x\) 行出去,只在第 \(x\) 行第 \(m\) 列放一个镜子。
然后其他的光线出去的时候都 “尽量往右走”。比如第 \(m-1\) 列的光线要从 \(y\) 出去其实有不同的走法:走到第 \(y\) 行然后出去;走到第 \(x\) 行,往右走一格,借助之前放的镜子再往上走一格,再出去;……
但是我们贪心地让它尽量借助其他镜子往右。(当然,不能干扰其他光线)例如如果 \(y<x\),我们在第 \(x\) 行第 \(m-1\) 列放一个镜子,这样第 \(m-1\) 列的光线就会借助第 \(m\) 列的镜子从第 \(m-1\) 列往右再往上。然后再从想出去的地方出去。
正确性:尽量往右走,可以减小对其他镜子的干扰。(感性理解一下)其实我觉得还不如上面证明(*)的时候用的方法好
工序安排
有 \(n\) 个原件。一个原件经 A 类机器加工后变为半成品,半成品经 B 类加工后变为成品。
A 类有 \(m_A\) 台,B 类有 \(m_B\) 台。每台机器的加工时间都不同。问:①全部加工为半成品最快?②全部加工为成品最快?(\(1\le n \le 1000,1\le m_A,m_B\le 30\))
第一问很简单,可以二分(也可枚举),然后看每台机器可以加工多少半成品。
第二问在第一问的基础上:有 \(n\) 个半成品,加工好的时间分别为 \(a_1\le \dots\le a_n\),如何安排 B 类机器,
最短时间变成成品。
不妨假设所有 B 都是同时结束的:因为如果不同时结束,我们可以把先结束的机器开始时间后移,也不会影响最终答案。(重点)
设第 \(T\) 时刻所有机器结束。第 \(i\) 台机器加工一个的时间为 \(b_i\)。那第一台机器加工最后一个零件时要求零件在 \(T-b_1\) 之前是半成品,第一台机器加工倒数第二个需要 \(T-2b_1\) 之前是半成品…… 第二台机器等也同理。
在所有的 \(T-kb_i\) 中选出 \(n\) 个最大的。(减的最少的)
我们就在这些时刻给机器加工。
设这 \(n\) 个时刻为 \(T-B_1,T-B_2,\dots,T-B_n\),不妨 \(B_1\le B_2\le \dots \le B_n\)。
而假设半成品完成时刻为 \(A_1,A_2,\dots,A_n\),恰好按这个顺序分配给上面的 \(n\) 个时刻。(\(A_{1\sim n}\) 是 \(a_{1\sim n}\) 的排列,\(A_1\) 时刻加工完毕的半成品在 \(T-B_1\) 时刻开始加工为成品)
这说明:\(T\ge A_i+B_i\),我们已经假设了 \(B_i\) 单调不减,要使得 \(T\) 最小,我们的 \(A_i\) 应当按单调不增排列。
读书(CSES1631):有 \(n\) 本书,读第 \(i\) 本需要 \(a_i\) 时间。有两个人,都要读完所有书,一本书不能两人同时读。问两人读完所需最短时间。
不妨 \(a_1\le a_2\le\dots\le a_n,S=\sum a_i\)。
答案就是 \(\max(S,2a_n)\)。
如果最后一本书的时间 \(\ge\) 之前所有书,答案是 \(2a_n\);否则当一个人读书时,总有一本书是空闲的。
巧克力
有 \(n\) 块巧克力和 \(m\) 个盒子,每个都有属性:长宽。一个盒子只能放一个巧克力,放巧克力必须盒子的长宽 \(\ge\) 巧克力的长宽。
问能不能把所有巧克力放入盒子。
把盒子也视为巧克力,第一关键字长,第二关键字宽,降序排序。然后遍历,如果遍历到一块巧克力,从之前的所有盒子里挑一个宽最小的但是能装下的盒子(长是降序一定都可以)装它。
这个贪心的关键点在于一个盒子只能装一块巧克力。也就是说不管盒子里装的是哪一块巧克力,贡献都只有 \(1\)。既然如此,我们在所有可装的盒子里挑最小的,就能给后面留包容性最大的。
贪心,如果最大值大于国王最大值,就直接比。
如果最大值小于国王最大值,就用最小值和国王最大值比。
如果相等,看最小值:
如果最小值大于国王最小值,直接比;
否则用最小值和国王最大值比。
HUR-Warehouse Store
反悔式贪心
来一批就尽量满足一批,如果无法满足,看看所有已满足的客户中所需商品最多的客户是否比这个客户多。如果是,就用这个客户替换掉,可以让库存变多。
乌鸦喝水
我们只需要每个水缸还能喝多少次。把所有水缸按照次数从小到大排序,相同的按序号从大到小排序。
性质:能喝次数比 \(k\) 大的水缸一定比能喝 \(k\) 次的水缸更晚干枯。
我们次数从小到大枚举水缸,定义一个位置变量 \(pos\)。
注意区分三个东西:当前水缸(这个枚举的),当前位置。
先判断当前水缸剩余次数够不够从当前位置走到第 \(n\) 个水缸。(这里的是看原来的顺序)也就是从当前位置到原来第 \(n\) 个水缸 没干枯的水缸数 是否大于 当前水缸的能喝次数。(因为要求能喝必须喝)这个查询可以用树状数组做。
-
如果能走到第 \(n\) 个水缸,就一直从第 \(1\) 个到第 \(n\) 个不停转圈,每次转一圈就减去 \(1\sim n\) 的能喝水缸个数。一直转到当前水缸的能喝次数不够再转一圈。
如果此时发现转圈的圈数大于 \(m\) 了,就退出遍历水缸并输出答案。
否则此时就是当前位置为第一个水缸,无法走到第 \(n\) 个水缸。当前水缸剩余次数在循环中维护。进入下一种情况。
-
不能走到第 \(n\) 个水缸,用二分找出还能走到哪个水缸。让这个水缸作为下一次的水缸位置。
Free Goodies
先取的人每次取价值最大的,后取的人每次取能让自己最后的价值最大的。求最后两个人取到多少价值。
不如假设是 Jan 先取,如果是 Pet 先取就让他取了 p 最大的变成 Jan 先取。
先按照 \(p_i\) 从大到小排序,然后进行 DP:\(dp[i][j]\) 表示 Jan 在前 \(i\) 个中选 \(j\) 个的最大价值和。(其实 Jan 选物品的顺序并不满足什么贪心原则,所以排序只是为了满足 Pat 的贪心)
注意 \(j\le [\dfrac{i+1}{2}]\),因为 Pat 一定是优先取第一个没取的。
在求 DP 数组的同时同步更新一个数组 \(cst[i][j]\) 表示 Jan 在前 \(i\) 个取 \(j\) 个要最大价值时取走的物品 \(p_i\) 的总和,以便快速求出最后 Petra 的快乐值。
课程复习:
有 \(n\) 个课程,第 \(i\) 个课程需要每 \(d_i\) 天复习一次。(这里指 \(1\sim d_i\) 需要一次,\(d_i+1\sim2d_i\) 需要一次 ……)
设计 \(L\) 天的复习方案,\(L=lcm(d_1,d_2,\dots,d_n)\)。
问:①证明 \(\sum \frac{L}{d_i}\le L \iff\sum \dfrac{1}{d_i} \le 1\) 是问题有解的充要条件。(提示:integer flow theorem)
②有解时,用贪心构造一组解。
①:(这是一段残缺的证明)
假设第 \(i\) 个课程一共会复习 \(k_i\) 次,我们把第 \(i\) 个课程的第 \(j\) 次复习抽象成一个结点 \((i,j)\)。把 \(L\) 天抽象为 \(L\) 个结点 \(1\sim L\)。\((i,j)\) 向 \(d_i(j-1)+1\sim d_i\times j\) 连边,表示这次复习要在这些天中选一个。
这样整个图形成一个二分图。记所有 \((i,j)\) 为左半边,\(1\sim L\) 为右半边。
建立源点 \(S\) 连接左半边,汇点 \(T\) 连接右半边,构建网络流模型。把图里所有边边权设为 \(1\)。
有解 \(\iff\) 有一种可行流流满了 \(S\) 的所有边。
②:贪心构造:每次选紧迫度最小的完成,然后让它的紧迫度加上它的 \(d\),初始所有紧迫度为各自的 \(d\)。
思路:找一个界,证明所有解都 \(\ge\) 这个界,然后构造一组解答案为这个界。
正解:\(\displaystyle \sum_{i=1}^{n-1} \max(a_i,a_{i+1})=A\) 是答案,下面证明有解。
每次找到最小的数,和左右两边较小的合并,答案为 \(A\)。
而因为每对相邻元素都必然会合并一次,所以答案 \(\ge A\)。
BANK:
有 \(n\) 个投资项目,每个项目用两个四元组描述。第 \(i\) 个项目的四元组为 \((c_{ia},c_{ib},c_{ic},c_{id}),(a_{ia},a_{ib},a_{ic},a_{id})\)。
有四种货币 \(a,b,c,d\) 对应上面的四元组。如果当前手上持有的四种货币分别大于等于 \((c_{ia},c_{ib},c_{ic},c_{id})\),就可以做第 \(i\) 个投资。可以收回本金并且四种货币获得 \((a_{ia},a_{ib},a_{ic},a_{id})\) 的净收入。
银行希望初始持有极小的资金做成所有投资(投资过程中可以收入),即任何一种货币减少,都会使得无法做完所有投资。
\(1\le n\le 8000\),但要求算法 \(O(n\log n)\)。
解:
先考虑只有一种货币(一维)的情况。
把所有货币按照所需本金从小到大排序,如果当前投资需要的本金大于自己当前持有钱,就在开始时加上缺的部分。最后扫完了初始本金也就加好了。
再考虑二维的情况:
发现:最后两种货币的数量必然为 \((a_0,?)\)。\(a_0\) 是如果只考虑第一维,第一维货币的初始本金最小数量。
然后同理,三维答案为 \((a_0,b_0,?)\),四维答案为 \((a_0,b_0,c_0,?)\)。
但此时还有一个问题:已知 \(a_0,b_0,c_0\),如何求 \(d_0\)?其实和一维差不多。
令 \((S_a,S_b,S_c,S_d)\) 为当前现金,初始为 \((a_0,b_0,c_0,0)\),然后不断增加第四维。
我们要在所有没选的投资集合 \(B\) 中找出所有 \(c_{ia}\le S_a,c_{ib}\le S_b,c_{ic}\le S_c\) 的投资构成集合 \(B_3\)。
然后再在 \(B_3\) 中找出 \(c_{id}\) 最小的,如果 \(c_{id}\le S_d\),就投资这个项目,将此项目踢出集合并更新四维持有本金。
如果最小的 \(c_{id}>S_d\),那初始本金至少追加 \(c_{id}-S_d\) 的钱。然后再按上面的情况处理。
等处理完了,\(d_0\) 自然也就加出来了。
现在的问题又变成了:如何快速找出满足要求的项目?
我们令 \(B_2\) 为所有满足 \(c_{ia}\le S_a,c_{ib}\le S_b,c_{ib}>S_c\) 的项目集合,令 \(B_1\) 为所有满足 \(c_{ia}\le S_a\) 之后条件不满足的项目集合,令 \(B_0\) 为四个条件都不满足的集合。
那 \(B\) 就分成了四个集合 \(B_0,B_1,B_2,B_3\),每个集合用最小堆维护,从一个集合进入另一个集合。\(B_0\) 中按照 \(c_{ia}\) 从小到大,\(B_1\) 按照 \(c_{ib}\),\(B_2,B_3\) 类似。
01比例:
给出一个 01串,找一个子串,使其中 1 的占比最接近实数 \(r\in[0,1]\)。
令 \(S_i\) 为前 \(i\) 个 \(1\) 的个数。二分答案 \(d\) 表示 \(1\) 的占比在 \([r-d,r+d]\) 中。
则 \(r-d\le \dfrac{S_i-S_j}{i-j}\le r+d\)。
\(\iff (r-d)i-S_i\le (r-d)j-S_j,(r+d)i-S_i\ge (r+d)j-S_j\)。
令 \(A_i=(r-d)i-S_i,B_i=S_i-(r+d)i\)。
化简为 \(A_i\le A_j,B_i\le B_j\),即:找出 \(i>j\) 使 \(A_i\le A_j,B_i\le B_j\)。
这个玩意需要满足三个大小关系,找三维偏序 \(O(n\log n)\),加上二分,整体复杂度 \(O(n\log n\log limit)\)。
P7840
建立一个表格,第 \(i\) 行第 \(j\) 列为 \(v_j\times (2i-1)\),这样我们发现第 \(j\) 列的前 \(x\) 行的和就是 \(v_j\times x^2\)。
题目等价于在表格中选 \((2n-2)\) 个数,和最小。要求第一行所有数必须选。
这不就是这题吗?用 \(n\) 个最小堆做。
Sail:
有 \(n\) 个旗杆高度不一,第 \(i\) 个旗杆高 \(h_i\)。每一个高度可以挂一个旗。
对于每一个高度,这个高度下最靠右的旗损失为 \(0\),第二靠右的损失为 \(1\),以此类推。
要求在第 \(i\) 个旗杆上挂 \(k_i\) 个旗,求最小损失之和。\(1\le n\le 10^5\)。
首先发现旗杆可以按高度排序,因为每一行(高度)上旗数量不变。现在 \(h_1\le ...\le h_n\)。
从低到高依次考虑每个旗杆的放置方式,设 \(S_1\sim S_H\) 为当前每个高度上的旗数量。则答案为 \(\sum \dfrac{S_i(S_i-1)}{2}\)。
贪心:从 \(S\) 最小的 \(k_i\) 个位置放旗子。
证明:假设第 \(w\) 个旗杆上没有在最小位置放旗子,设本应该在 \(x\) 的旗到了 \(y\) 上。
考虑之后的旗杆在 \(x,y\) 这两行:(注意因为排了序,每个旗杆都包含这两行,才能用)
如果有旗杆 \(y\) 上没放,\(x\) 上放了,让第 \(w\) 根旗杆的这两行与这根旗杆交换,第 \(w\) 根旗杆还是最优的,往后看;
否则以后的旗杆在这两行必为都放、都不放或者 \(y\) 放 \(x\) 不放。
如果都放或者都不放,不管;如果是 \(y\) 放 \(x\) 不放,让第 \(w\) 根旗杆变成 \(x\) 放 \(y\) 不放,可以让 \(x,y\) 行的数量更接近,损失更小。
证毕。
那我们每次要找出最小的 \(k\) 个位置让它们 \(+1\)。
我们希望每次增加后每行的数量能保持单调不增。(有序好处理)
那我们先利用有序的条件,\(O(1)\) 找出第 \(h-k\) 大的位置,设这个位置上的数为 \(x\)。然后计算一共有多少个 \(x\) 在前 \(h-k\) 大中。
(例如 \(h-k=5\),数列为 \(4,4,4,3,3,3,2,1\),第 \(h-k\) 大的数一共要有 \(2\) 个 \(3\) 在前 \(5\) 个中)
注意,我们不是增加这 \(h-k\) 个,我们是增加 \(k\) 个数。因此,我们看如果增加后 \(k\) 个,会不会导致数列变得不单调不增。如果会,一定是有一些 \(x\) 被增加了导致的。
那我们把这些 \(x\) 移到 \(x\) 的区间的开头增加。还是上面的例子,如果增加后面的,数列就会变成 \(4,4,4,3,3,4,3,2\) 不单调不增。
原因是有一个 \(3\) 在 \(3\) 的区间的末尾,但是加了 \(1\),我们把这个移到前面去加,数列就变成了 \(4,4,4,4,4,3,3,3,2\) 单调不增。
找到第 \(h-k\) 大的数所在区间有多少个会增加,可以二分它所在区间的右端点。
而找好增加的区间后,只需要用线段树维护就行了。二分也在线段树上二分。
答案就每个高度查询一下,\(S(S-1)/2\) 求和。
LEXICO GRAPHIC 定理(只是开阔一下眼界):
给定 \(n\),表示一个二分图。
左半边每个点表示 从 \(1\sim 2n-1\) 中选 \(n-1\) 个元素组成的集合中的一个。
右半边是选 \(n\) 个。
如果一个点包含另一个点代表的集合,就连边。
求一个二分图完备匹配。
贪心构造:按照字典序枚举左半边的所有点,在所有没匹配的右半边点中,找代表集合字典序最小的点匹配。
LEXICODE:
找长度为 \(n\) 的 01 串尽量多,使得任意两个串至少有 \(d\) 个位置不相同。
贪心构造:按照字典序从小到大看左右长度为 \(n\) 的 01 串,如果当前串不冲突就选。
CF1682C
考虑出现次数 \(\ge 2\) 的数,显然我们可以把它们放到 \(a\) 和 \(a'\) 中,让 \(LIS(a),LIS(a')\) 一起加一。若有 \(cnt\) 种次数 \(\ge2\) 的数,贡献为 \(cnt\)。
对于剩下的数,为了使 \(\max()\) 最大,显然应该平均分配。若有 \(cnt2\) 种次数 \(\ge2\) 的数,贡献为 \([\dfrac{cnt2}{2}]\)。
用 map 存次数即可。
CF1304D
猜一个界,然后构造。
先做最短 LIS。LIS 最短肯定是所有连续 < 段的长度的最小值。
考虑构造一组解使得答案为这个。
先令初始数组为 \(n,n-1,\dots,1\),对于每一个连续 < 段,翻转在数组的对应段。这样就得出了构造。
受这个构造的启发,我们令初始数组为 \(1,2,\dots,n\),对于每一个连续 > 段,翻转对应数组。这样可以使 LIS 最长。
一次切割的代价:(与自己方向不同的已经切了的个数 + 1)乘自己原本的代价。
一个非常裸的想法:每次挑代价最大的切,而事实上这也是正确的想法。
考虑同一种方向的切,谁先切都一样。
而对于不同方向的切,后切的会多花费一个初始代价,那么初始代价大的应该先切。
很显然的贪心,按照巧克力价格从小到大满足,直到没钱。
注意数据范围 \(10^{18}\),不能一个一个减,要除。
乘积:给定 \(m,n(m\le n)\) 和数组 \(c_i(0\le i \le 9)\),要求构造出一个 \(m\) 位正整数 \(A\) 和 \(n\) 位正整数 \(B\),允许有前导零。要求这两个数中 \(i(0\le i\le 9)\) 的个数和不能超过 \(c_i\),使得 \(A\times B\) 最小。
先考虑 \(c_0=0\) 时,\(A=\overline{a_1a_2...a_m},B=\overline{b_1...b_n}\)。
我们可以先在 \(A\) 后面补 \(0\),使得 \(A,B\) 对齐,最后减去一个 \(B\) 乘以 \(10\) 的若干次方即可。
此时 \(A=\overline{a_1a_2...a_ma_{m+1}...a_n},a_{m+1}\sim a_n=0\)。
首先我们发现 \(a_1\le a_2\le\dots\le a_m\) 和 \(b_1\le b_2\le\dots\le b_n\)。这是显然的。
然后我们有贪心构造法:假设我们可以使用的数构成集合 \(S\),则 \(a_1\) 是最小数,\(b_1\) 是次小数,\(a_2\) 是次次小数,以此类推。
为什么正确呢?我们先证明 \(a_i\le b_i(i=1\sim n)\),再进一步证明贪心的正确性。
假设在 \(A,B\) 的一个位上切一刀,把 \(A,B\) 分成了 \(A_1,A_2,B_1,B_2\),且 \(A_2\) 包含所有补充的 \(0\)。
我们假设最优解中 \(A_1\le B_1\) 时 \(A_2>B_2\),令 \(A\) 的 \(A_1\) 部分和 \(B_1\) 交换。调整前是 \(A_1\cdot B_1\cdot 10^l\cdot 10^l+(A_2\cdot B_2)+(A_1B_2+A_2B_1)\cdot 10^l\),调整后 \(A_1B_1\cdot10^l\cdot10^l+A_2B_1+(B_1B_2+A_1A_2)\cdot10^l\)。\(l\) 是 \(A_2\) 的位数,也是 \(B_2\) 的位数。
发现调整后变小了。矛盾,又因为 \(n,m\) 的对称性,可以假设 \(a_1\le b_1\),所以 \(a_i\le b_i\)。接下来就是证明贪心正确性了。
假设 \(a\le b\le c\le ...\le f\le ...\) 是可以填的数。
我们在 \(A\) 的一个位上填了 \(e\),但是没有在 \(B\) 的对应位上填 \(f\),而是填到了 \(A\) 的后面。(不可能填到 \(B\) 的其他地方因为 \(a_i\le b_i\))
假设 \(e\) 的对应位上 \(B\) 填了 \(x\),我们再用调整法,把 \(f\) 和这个 \(x\) 交换,得知答案更优。
贪心结论得证。
注意:这仅仅是 \(c_0=0\) 的情况,那 \(c_0>0\) 呢?
其实差不多:有 \(0\) 的时候,优先往位数小的高位填。
首先每个 \(a_i-=i\),就变成了求一个非严格单调递增的序列。(变成《算法竞赛进阶指南》P267 的 “making the grade”(POJ3666),详情自行翻书查阅,书上写了 \(O(n^2)\) 的DP方法)
观察:\(\{b\}\) 中所有数都是 \(a\) 中的数。更进一步,\(\{b\}\) 中每一段数,全部等于 \(a\) 中对应段的中位数。
引理:
假设 \(a_1\sim a_n\) 的对应最优 \(b\) 是 \((u,u,...,u)\),\(a_{n+1}\sim a_{n+m}\) 的对应最优 \(b\) 是 \((v,v,...,v)\)。
-
当 \(u\le v\) 时,\(a_1\sim a_{n+m}\) 对应的最优 \(b\) 是 \((u,...,u,v,...,v)\),因为 \(u\le v\) 可以直接接上去。
-
当 \(u>v\) 时,对应的最优 \(b\) 是 \((w,w,...,w)\),其中 \(w\) 是 \(a_1\sim a_{n+m}\) 的中位数。
暂时不提引理证明,先考虑有了引理怎么求答案。
首先初始 \(b\) 设为 \(a_1\),然后向后遍历整个 \(a\)。每次遍历到 \(a_i\) 时,判断 \(a_i\) 和 \(b_{i-1}\) 的大小:如果 \(b_{i-1}\le a_i\),直接令 \(b_i=a_i\);否则求出 \(a_{i-1}\) 所在段加上 \(a_i\) 的中位数 \(w\),将 \(a_{i-1}\) 所在段的所有 \(b\) 以及 \(b_i\) 赋值为 \(w\),再将 \(a_{i-1}\) 所在段加上 \(a_i\)。
这里的 “所在段” 其实就对应上面引理中的 \(a_1\sim a_n\) 和 \(a_{n+1}\sim a_{n+m}\) 两段。初始每个数的所在段只有它自己一个数。每发生一次 \(u>v\) 时,就必有一些 \(b\) 要变成相等的数。(全部赋值为 \(a_1\sim a_{n+m}\) 的中位数)这个时候,我们把这些相等的 \(b\) 弄成一个段。
给个例子:1 4 3 2 5 7 6。规定中位数是删掉一半最大的数(个数下取整)后留下的最大数。
首先 \(b_1\) 设为 \(1\),同时开始遍历。
遍历到 \(a_2=4\),发现 \(a_2>b_1\),因此 \(b_2=a_2=4\)。
遍历到 \(a_3=3\),发现 \(a_3<b_2\),这个时候 \(a_2\) 的所在段只有 \(a_2\) 自己。于是求出 \(a_2,a_3\) 的中位数 \(3\),令 \(b_2=b_3=3\) 且 \(a_2,a_3\) 变成一段。
遍历到 \(a_4=2\),发现 \(a_4<b_3\),\(a_3\) 所在段包含了 \(a_2,a_3\),因此求出 \(a_{2\sim 4}\) 的中位数 \(3\),令 \(b_2=b_3=b_4=3\),且 \(a_2\sim a_4\) 变成一段。
遍历到 \(a_5\) 和 \(a_6\),都可以直接接上,因此 \(b_5=5,b_6=7\)。
遍历到 \(a_7\),\(a_7<b_6\),因此求出 \(a_6,a_7\) 的中位数 \(6\),令 \(b_6=b_7=6\) 且 \(a_6,a_7\) 成一段。
结束,最后得出 \(b_i=1,3,3,3,5,6,6\)。
如何快速求出两个段合并后的中位数?我们需要一个支持删除(删除一半数)、求根(查找最大值)、合并(两个段合并)的数据结构,这是可并堆,可以用左偏树实现,也许也能用Treap,FHQ-Treap实现。
每段我们都只保留小的一半,每次合并我们也同样只需要保留两段中各自小的一半。因为这两个小的一半合并后就形成了整体的小的一半,不可能有大的合并后反而变到小的一半。
如果原序列中奶牛 \(i\) 要去位置 \(j\),则从 \(i\) 向 \(j\) 连边。连完后先考虑如果只处理图上的一个环,花费最小是多少。
找环上花费最小的点交换。
例如 6 <= 7 <= 9 <= 8 <= 6,交换 6,7,7 到了想要的位置,图变成 6 <= 9 <= 8 <= 6,再交换 6,8,以此类推,直到环上每个点就位。
显然这种花费已经最小了。但是这是不使用环外点交换的最小。
如果可以用环外的点帮忙,上面的方法就不对了。
而如果用环外的点,我们肯定是用全局最小值帮忙,让它和环内最小值交换,然后让环内其他点归位,再把它和环内最小值换回来。
这两种方法取 \(\min\) 即可。
反向考虑,是一些儿子合并到父亲身上。父结点显然是排在最前面,要注意的就是儿子的顺序。
假设第 \(i\) 个子树有 \(i_0\) 个 \(0\),\(i_1\) 个 \(1\)。第 \(j\) 个子树有 \(j_0\) 个 \(0\),\(j_1\) 个 \(1\)。
则第 \(i\) 个子树排在第 \(j\) 个子树前面,会诞生 \(i_1\times j_0\) 个逆序对。第 \(j\) 个在前,会诞生 \(i_0\times j_1\) 个逆序对。
所以若 \(i_1j_0<i_0j_1\iff i_1/i_0<j_1/j_0\),第 \(i\) 个就应该排前面。分母为 \(0\) 无穷大。
在实现上:每次找一个非根结点 \(u\),\(u_1/u_0\) 最小。分母为 \(0\) 无穷大。然后让它和它的父结点合并,同时让父结点记录:此时的父结点两种结点个数都要累加 \(u\) 的。
重点:可以考虑中间的一步,子结点与父结点合并。
树上排序:给出一棵树,每个结点有两个参数 \((a_i,b_i)\)。现将每个结点排序,要求父结点必须在子结点左侧,使得 \(\displaystyle \sum_{i<j}a_{p_i}\times b_{p_j}\) 最小。
结论:若 \(u\) 为剩下的结点中 \(\dfrac{a_u}{b_u}\) 最小的结点,则 \(u\) 排在 \(fa_u\) 后面。
否则 \(u\) 和前一个结点交换,总和变小。
Escape:给出一棵树,初始血量 \(hp=0\),在根结点。第一次进入结点 \(i\) 时,\(hp+=v_i\),\(v_i\) 可能正可能负。找一种方法,从根走到 \(t\),途中血量都非负。(如果死在 \(t\) 不算到达)
给 \(t\) 加一个 \(v=+\infty\) 的儿子,题目转化为 “走完所有节点”。(如果死在 \(t\) 算,直接把 \(v_t\) 改成 \(+\infty\))
法一:
若一个结点 \(v_u>0\),可以视为先损失 \(0\) 血,再加上 \(v_u\) 血;\(v_u<0\),可以视为先损失 \(-v_u\) 血,再加上 \(0\) 血。
这转化为了 “打怪兽” 那题,在贪心合集一里面。但是要求父结点在子结点前打。如果没有父结点在前这个限制,记这种排序为 “打怪兽” 序。
我们可以不断取出非根结点 \(u\),\(u\) 是剩下结点中 “打怪兽” 序中最早出现的。然后让它和父结点合并为一个结点。\((a_u,b_u),(a_{pr},b_{pr})\) 可以合并为 \((a',b')\)。(合并结点这个事有点像上面的 01 on tree)
法二:
其实每次挑权值最大的点和父结点合并即可。
分裂(BZ2064):
初始有 \(n\) 个区域,面积为 \(s_1,\dots ,s_n\)。
有两种操作,第一种可以把任意两块区域合并为一块,新区域面积为两块区域面积之和;第二种可以把一块区域分成两块,新区域面积之和等于旧区域。
目标状态有 \(n_2\) 块区域,面积为 \(s_1',\dots,s_{n2}'\),问至少要多少次操作?(不要求顺序对应,例如变成 3 1 2 目标 1 2 3 也算达成目标)
\(1\le n,n_2\le 10\)。
解:
在最终方案中,若目标状态中 \(s_{i1}'\sim s_{ik}'\) 都包含了 \(s_w\) 分裂出来的区域,则 \(w\) 和 \(i1\sim ik\) 连一条边,边权为 \(s_w\) 向 \(s_{ix}'\) 贡献的面积。
若图已经连好了,则操作次数为图中每个点的(度数减一)之和。(画张图手玩一下)
那如何建图呢?我们要一张图,边权之和等于总面积之和(称这个条件为合法),且总边数最小。(度数和 => 总边数)
观察到如果合法图中有环,一定不优。
证明:如果有环,因为图是二分图,所以必是偶环。考虑环中边权最小的边 \(a\),设这条边连接 \(x,y\)。则删去 \(a\),让 \(x\) 连着的另一条边(环上每个点应该有两条边)边权加 \(a\);若 \(x\) 的这条边又连接了 \(x,z\),让 \(z\) 的另一条边边权减 \(a\);然后不停加减循环。
因为 \(a\) 边权最小,所以调整后每条边边权非负,而且至少少了一条边。
推论:最优解是森林。
而我们发现森林中树越多,总边数就越少。所以我们要找尽可能多的树,且每棵树都是合法的。(合法:边权和等于点权和)
注意到一棵树合法有一个必要条件:上部分点权和 = 下部分点权和。
结论:把图分成尽量多个子集,要求每个子集上下部分点权和相等。假设能分成 \(k\) 个子集。同时设图中最多能找出 \(k'\) 个合法树,则 \(k=k'\)。
证明:首先 \(k\ge k'\) 是很显然的,因为每一棵树都满足上下部分点权和相等。
接下来就是证明每一个上下点权和相等的子集,都能构造出一棵树。这可以贪心构造。
假设子集上面 \(p\) 个结点,下面 \(q\) 个结点。
让下面第一个点和上面第一个点连边。
如果下面第一个结点点权比上面第一个大,让下面第一个的点权减去上面第一个。然后处理上面 \(p-1\) 个,下面 \(q\) 个。
下面第一个点权小也类似处理。总之最后能建出一棵树。得证。
有了这个结论,我们就可以做状压 DP 了。
反悔贪心
记结束时间为 \(ddl_i\)。
按照 \(ddl\) 从小到大排序,能选则选。如果选不了了尝试用这个任务替换掉以前选的任务中价值最小的那个。
正确性证明:
假设贪心算法依次会删除(替换)掉 \(d_1,d_2,\dots,d_k\) 这些任务。
要证明:存在最优解,没有选 \(d_1,d_2,\dots,d_k\)。
假设存在最优解 \(OPT\),没有选 \(d_1,d_2,\dots,d_{i-1}\) 但选中 \(d_i\)。尝试调整得到另一个不差的解,未选 \(d_1\sim d_i\)。
设贪心算法枚举到任务 \(a\) 的时候删除了 \(d_i\),且任务 \(ddl_a\) 为 \(t\)。
定义 \(S=\{1,\dots, a\}-\{d_1\sim d_{i-1}\}\)。
则 \(|S|=t+1\),且 \(d_i\) 是 \(S\) 中价值最低的,因为 \(d_i\) 被删掉了。 (可能 \(d_i=a\))
此时考虑 \(OPT\) 中属于 \(1\sim a\) 的元素,共 \(t\) 个,且都是 \(S\) 中的元素。而 \(|S|=t+1\),所以存在一个元素 \(b\ne d_i\) 没选进 \(OPT\) 中。让 \(b\) 替换 \(d_i\),可以使价值更大。
同时:若 \(ddl_b=t\),显然成立,因为时间要求更松了。
当 \(ddl_b<t\),反证法,假设加入 \(b\) 后无法安排。
这代表 \(OPT\) 中 \(ddl_b\) 之前有超过 \(ddl_b\) 个任务。因为 \(ddl_b<t\),所以所有 \(ddl<t\) 的任务都在 \(S-\{a\}\) 中,而我们知道 \(S-\{a\}\) 有解,所以它的子集有解,矛盾。所以调整法不会产生矛盾。
再根据归纳法,存在最优解删掉 \(d_1\sim d_k\)。
证毕。
这题和上题相反,价值为 \(1\),时间不为 \(1\)。
同样反悔贪心,按照结束时间排序,尽量选,如果选不了了尝试替换花时间最多的任务。
\(n\) 天,每天股价已知,每天只能买一次或者卖一次或者啥也不干。手上能持有的股票无限,求最大收益。
贪心:
定义两个集合 \(s1, s2\),\(s1\) 包含那些买入的且还没有卖过的股票,\(s2\) 包含那些卖过的股票。
到某天 \(i\),当日股票价格 \(c_i\)。考虑 \(s1,s2\) 中最小的元素 \(a\)。
-
\(a\in s1\),获得价值 \(c_i-a\),\(a\) 从 \(s1\) 中删除,加入 \(s2\)。
-
\(a\in s2\),获得价值 \(c_i-a\),\(a\) 加入 \(s1\),从 \(s2\) 中删除,且 \(c_i\) 加入 \(s2\)。还要让 \(a\) 加入 \(s1\) 是因为 \(c_i\) 是和 \(a\) 之前买入的股票构成一对了,股票 \(a\) 就解放了。
当然,获得价值的前提是 \(c_i\ge a\),\(c_i<a\) 就不加价值。
同时这题还能费用流。
抽象出 \(n\) 个点 \(v_1\sim v_n\) 代表 \(n\) 天,\(v_i\) 向 \(v_{i+1}\) 连有向边,容量为 \(+\infty\),费用为 \(0\)。
从源点 \(S\) 向 \(v_1\sim v_n\) 连有向边,\(S\rightarrow v_i\) 的容量为 \(1\),费用为 \(-c_i\)。
从 \(v_1\sim v_n\) 向汇点 \(T\) 连有向边,\(v_i\rightarrow T\) 的容量为 \(1\),费用为 \(c_i\)。
题目等价于在这张图上跑最大费用流(不限制流量)。假设我们考虑了 \(v_1\sim v_{n-1}\) 个点,则加入 \(v_n\) 后会多出三条边:\(v_{n-1}\rightarrow v_n,S\rightarrow v_n,v_n\rightarrow T\)。
此时应当会出现增广路,增广路类型只有两种:
-
\(S\rightarrow v_i\rightarrow v_{i+1}\rightarrow \dots\rightarrow v_n\rightarrow T\)。对应着上面贪心的第一种情况。
-
\(T\rightarrow v_i\rightarrow \dots\rightarrow v_n\rightarrow T\),即之前从 \(v_i\) 有流向 \(T\) (第 \(i\) 天卖出了股票),现在反悔了,选择在第 \(n\) 天卖,对应上面贪心的第二种情况。
我们的贪心算法就是模拟了这种费用流的解法,所以贪心正确。
贪心模拟费用流的关键,在于每次的增广路变化情况不多。用堆、集合可以模拟。
这里讲贪心做法。
我们把手续费在买入的时候算,也就是说,如果我们在第 \(i\) 天买入,需要花费 \(price[i]+fee\)。
我们定义 \(buy:\) 在最大化收益的前提下,买入一支股票的最低价。 显然一开始 \(buy=price[0]+fee\)。
接下来我们枚举 \(i:1\sim price.size()-1\),对第 \(i\) 天的股票考虑:
-
如果 \(price[i]+fee<buy\),说明我们在这天买入的价格比我们之前的最低价更低。于是 \(buy\leftarrow price[i]+fee\)。
-
如果 \(price[i]\in [buy-fee,buy]\),说明这天的股票既不更便宜,也不产生利润,于是我们啥也不干。
-
如果 \(price[i]>buy\),说明我们如果在这天卖出,可以获得 \(price[i]-buy\) 的利润,那么我们就卖出。
但是这里有一个问题:我们如果现在就卖出,可能后面会遇到利润更高的选项,并非全局最优。我们考虑一个反悔的操作,在我们第 \(i\) 天卖出的同时,我们令 \(buy\leftarrow price[i]\)。让我们考虑这个操作会有什么影响:
-
如果先在后面遇到 \(j,price[j]>price[i]\),按照我们上面的贪心策略,我们会卖出股票(虽然这支股票是我们虚构的),并获得 \(price[j]-price[i]\) 的利润。我们发现,之前在第 \(i\) 天卖出的利润是 \(price[i]-buy\),这两天的利润加起来就是 \(price[j]-buy\),恰好等于我们在第 \(i\) 天不卖但是在第 \(j\) 天卖的利润!
-
如果先遇到 \(j,price[j]+fee<price[i]\),我们就可以顺势把手上的股票换成 \(j\)。
因为如果我们用 第 \(x(x<i)\) 天 卖出 \(price[i]\),用 第 \(j(i<j<k)\) 卖出更高价 \(price[k]\),总利润就是 \(price[i]-price[x]-fee+price[k]-price[j]-fee\);
而如果我们留着 \(price[x]+fee\) 卖出 \(price[k]\),总利润就是 \(price[k]-price[x]-fee\)。因为我们的前提:\(price[j]+fee<price[i]\),所以 \(price[i]-price[j]-fee\) 一定正,所以一定是第一种选择更好。
-
种树:有 \(n\) 个坑。第 \(i\) 个坑种树的价值是 \(c_i\),相邻坑不能同时种。可以种 \(k\) 颗树,求最大价值。
模拟费用流,建图类似这样: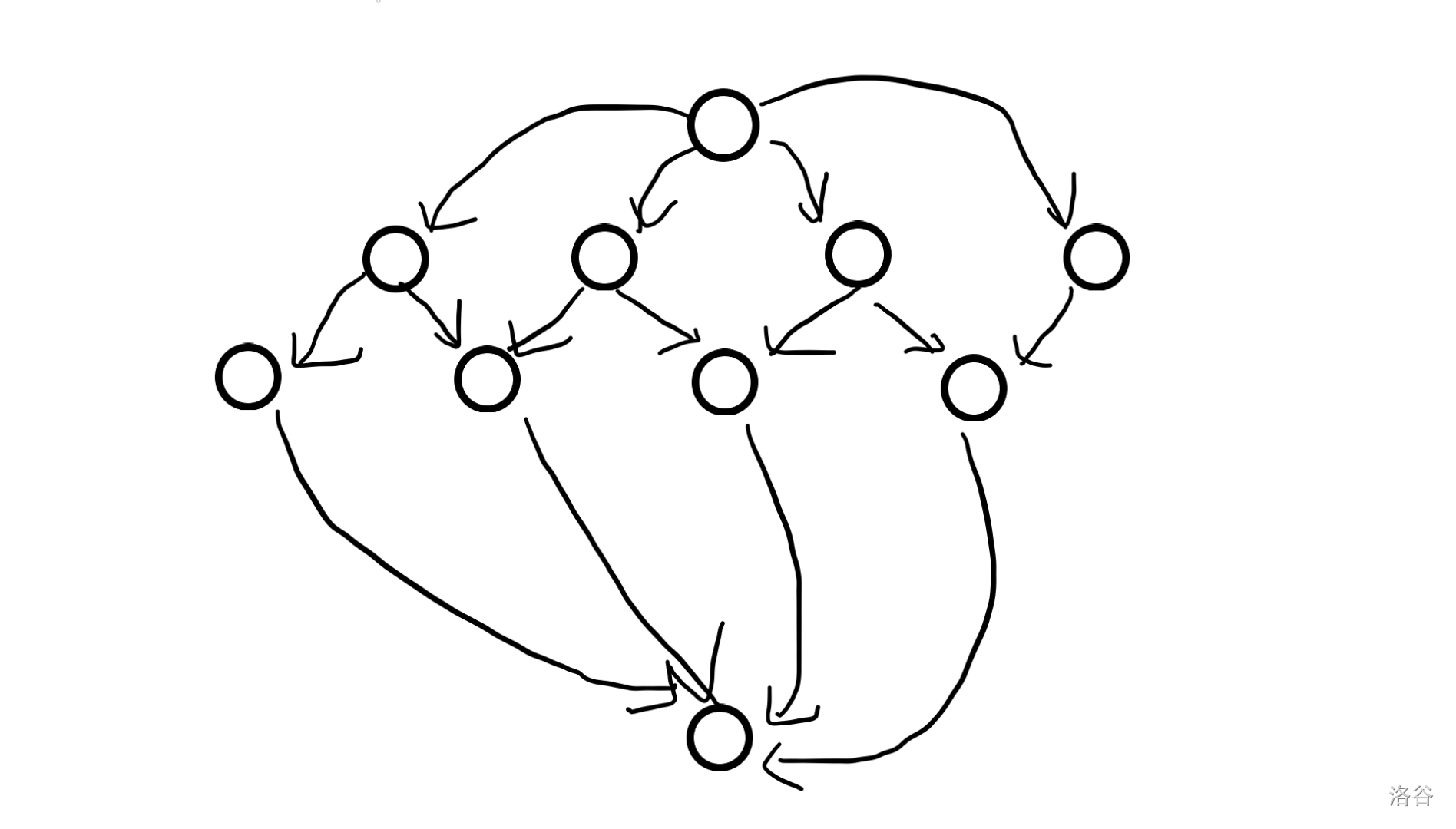
中间两层结点之间有 \(7\) 条边,表示 \(n=7\) 的情况。相邻两条边,例如 \(1,2\) 总流入量为 \(1\),\(2,3\) 总流出量为 \(1\),也不可能出现相邻两条边同时流的情况,对应相邻两个坑不能同时种树。
在上面的图里找增广路的时候,我们发现增广路上每条边的流量有特征:源点流出和汇点流入的边流量都是 \(0\),其余边 \(0,1\) 不断交替且 \(0\) 开头 \(0\) 结尾:例如 0 1 0 1 0 就是一种可能的情况。
对应到原问题里,初始每个坑位都是 \(0\)。种了树就会变 \(1\)。一个区间如果开头结尾为 \(0\)、\(0,1\) 交替且区间左边一个和右边一个都是 \(0\),这就对应一个增广路。
可见一开始每个坑位都对应一个区间,也对应一个增广路。
而更新一条增广路,会使路径上的 \(0\) 变 \(1\),\(1\) 变 \(0\);对应到原问题里就是区间内 \(0\) 变 \(1\),\(1\) 变 \(0\)。
发现将区间翻转后,因为规定了一个区间左边一个右边一个为 \(0\),且开头结尾为 \(0\),所以反转后刚好和左右拼成一个更大的区间。
那我们可以用链表来维护这些区间。同时搞一个堆,这个堆用来每次找最大价值的区间。一个区间的价值定义为其中 \(1\) 的价值减去 \(0\) 的价值。
每次挑出一个价值最大的且未被标记为不可选的区间 \(d\),统计其价值,同时通过链表找到它相邻的两个区间 \(d_1,d_2\),将 \(d,d_1,d_2\) 合并为一个大区间,价值为 \(v_{d_1}+v_{d_2}-v_d\),然后把原本的 \(d_1,d_2\) 标记为不可选。
一直挑,挑到够了 \(k\) 个就结束。
建成最小费用流模型。
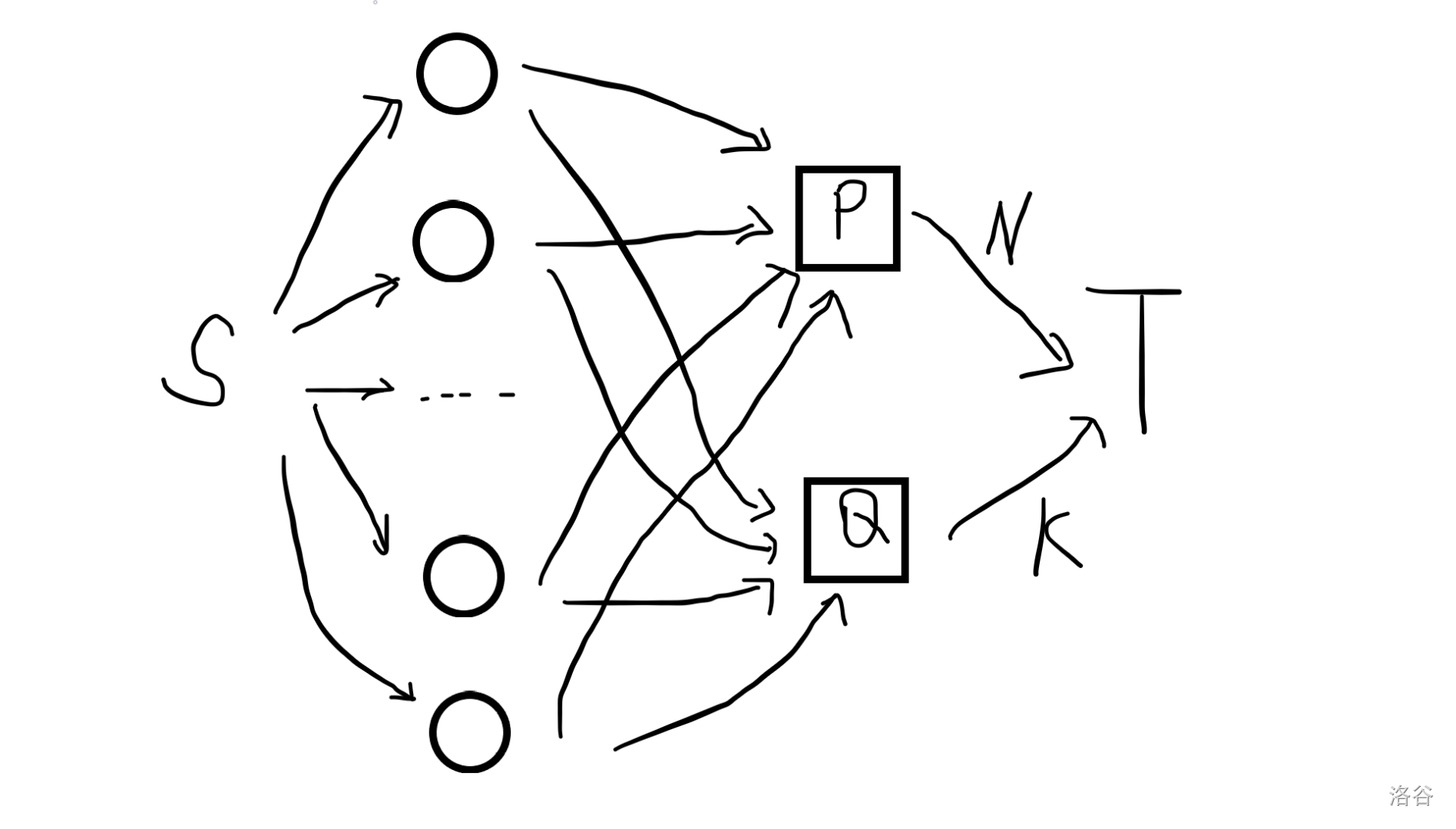
圆形点共 \(n\) 个表示 \(n\) 头牛。
走点 \(P\) 表示用普通价格买,\(P\rightarrow T\) 容量为 \(n\)。(有多少要多少)
走 \(Q\) 表示优惠券,因为只能有 \(k\) 张优惠券,所以容量为 \(k\)。
题目限定了总费用上界,其实可以转化为 “流量为 \(j\) 的最小费用流”。
问题等价于在这张图上找最小费用流。
这题可以模拟费用流,如何模拟,主要考虑增广路长啥样。
显然当 \(j\le k\) 时,都会走优惠券,然后挑优惠券价格最小的 \(k\) 个。
那现在就看 \(j>k\) 的情况。
增广路有两种情况:
-
\(S\rightarrow v_i\rightarrow P\rightarrow T\)。
-
\(S\rightarrow v_i\rightarrow Q\rightarrow v_j\rightarrow P\rightarrow T\)。即 \(v_i\) 想走优惠券,把某个 \(v_j\) 的优惠券撤回了,让 \(v_j\) 正常价购买。
现在要找出上面两种增广路中费用较小的,然后应用那条增广路。
-
形如 1 的增广路费用最小就是剩下所有没买的牛中不用优惠券价格最低的。
搞一个小根堆,记录所有没买的牛中 \(p\) 最小的。
-
形如 2 的增广路费用最小就是 (\(c_i\;+\) 所有走了优惠券的牛中 \(p-c\) 最小的)。
搞一个小根堆,记录所有用优惠券买的牛中 \(p-c\) 最小的。
这样就用贪心模拟了费用流。
其实和上一题 cow coupons 类似,只不过右边不再是 \(p,q\) 两个点而是 \(p,q,r\) 三个点。这样搞增广路的种类太多了,对应的也需要很多堆来维护,不好搞。
但是我们可以先让所有人给出金币,然后让每个人的银币数量变成 \(B-A\),铜币数量变成 \(C-A\),这个时候就可以回到上面的模型,\(p\) 到 \(T\) 的容量不再是 \(n\) 而是 \(y\),\(q\) 到 \(T\) 的容量是 \(z\)。
这样增广路的种类只有四种:
-
\(S\rightarrow v_i\rightarrow P\rightarrow T\)。
-
\(S\rightarrow v_i\rightarrow Q\rightarrow T\)。
-
\(S\rightarrow v_i\rightarrow P\rightarrow v_j\rightarrow Q\rightarrow T\)。
-
\(S\rightarrow v_i\rightarrow Q\rightarrow v_j\rightarrow P\rightarrow T\)。
弄四个堆,每次找出四种增广路中费用最大的选了。
取硬币问题:有 \(n\) 堆硬币,每堆硬币有上下两个,每个硬币有自己的价值。要取下面的硬币必须先取它上面的。一共可以取 \(k\) 个硬币,问最大价值。
观察:一定不会有两堆硬币都只取了上面的一个,否则把一次机会用来取价值更大的下层硬币,价值更大。
所以最终的方案一定是取了 \([k/2]\) 堆的两个硬币,如果 \(k\%2=1\) 就有一个额外的上层硬币。
要么是取出两个硬币和最大的 \([k/2]\) 堆,再加上剩下的上层最大的;要么取出两个硬币和最大的 \([k/2]+1\) 堆,再减去选了的下层最小的。
线段树模拟费用流。
和 Buy low sell high 相似。
网络流构图是类似的,费用变了一下。\(S\rightarrow v_i\) 的费用是 \(a_i\)。
要求的是流量为 \(k\) 的最小费用流。
差别主要在于固定流量这个条件。
给出一个观察:
我们把 \(S\rightarrow v_i\) 的边视作左括号,\(v_i\rightarrow T\) 的边视作右括号。
依次考虑 \(i:1\sim n\),先看看 \(S\rightarrow v_i\) 是否有流(第 \(i\) 天是否加工半成品),如果有,在当前括号序列末尾加入一个 (;再看看 \(v_i\rightarrow T\) 是否有流,如果是,在当前括号序列末尾加入一个 )。
一个合法解必然对应着一个可行流,而一个可行流对应着一个合法括号序列。(这其实很好理解,卖出必须先买入,对应右括号前必有左括号,然后删去第一次买入卖出,又可以递归证明)
把左括号视作 \(+1\),右括号视作 \(-1\),合法括号序列等价于前缀和始终非负且总和为 \(0\)。在一个位置放左括号相当于让前缀和后面都加一,右括号就是后面都减一。
重新回到费用流的图里面。考虑图里面的一条增广路,要么是 \(S\rightarrow v_i\rightarrow\dots\rightarrow v_j\rightarrow T,j\ge i\)。这个就相当于在 \(i\) 位置添加一个左括号,\(j\) 位置添加一个右括号,前缀和 \([i,j)\) 加一。
要么是 \(S\rightarrow v_j\rightarrow\dots\rightarrow v_i\rightarrow T,j>i\),这个就是走了反向边,在 \(i\) 位置添加一个右括号,\(j\) 位置添加一个左括号,前缀和 \([i,j)\) 减一。因为要求合法括号序列前缀和非负,所以这种情况要求前缀和 \([i,j)\) 为正。
显然 \(S\rightarrow v_i\) 的边不会走反向边。
因为图中边权均为正,所以无论怎么搞都不会出现负环,这和 buy low sell high 不同。
现在的问题就很明确了,每次找出数对 \((i,j)\),使得 \(a_i+b_j\) 最小,同时满足以下条件之一:
-
\(i\le j\)。
-
\(i>j\) 且 前缀和 \([i,j)>0\)。
这可以用线段树维护。不过要搞很多东西。对于一个区间 \(u\),我们要维护以下东西:
-
\(ans1\),表示 \(u\) 中 \(i\le j\) 的数对 \((i,j)\) 中 \(a_i+b_j\) 最小的。
-
\(ans2\),表示 \(u\) 中 \(i>j\) 的数对 \((i,j)\) 中
基础的 \(dp\) 想法:\(dp[i][j]\) 表示前 \(i\) 座山且第 \(i\) 座高度为 \(j\) 的最小操作数。
这个状态数太多了。但是观察到每一座山最后的高度 \(H_i\in S\),\(S=\{h_i+x\cdot d|1\le i\le n,-n\le x\le n\}\)。
证明:
显然 \(h_1,h_n\in S\)。
假设一个最优解 \(OPT\) 中每座山最后的高度是 \(H_1\sim H_n\)。因为 \(1,n\) 不能动,所以 \(H_1,H_n\in S\)。
设 \(H_{x1},H_{x2},\dots,H_{xk}\in S,\;x_1=1,x_k=n\)。考虑 \([x_i+1,x_{i+1}-1]\) 这段。\(OPT\) 中这一段都不属于 \(S\)。
考虑 \(H_{x_i+1}-h_{x_i},H_{x_i+2}-h_{x_i+2},\dots, H_{x_{i+1}-1}-h{x_{i+1}-1}\)。
因为这一段都不属于 \(S\),所以 \(H\ne h\),如果将最后的 \(H_{x_i+1}\sim H_{x_{i+1}-1}\) 整体加一或减一,总有一种方向可以使这一段的 \(h\) 变成 \(H\) 的操作次数变小,也可能不变,但一定不差。
那我们一直这么操作,直到出现这一段里某个 \(H\in S\),以此为分界点把这一段分成两半,然后再递归论证。
但是这个证明似乎有缺陷:整体加减是否会导致开头结尾和 \(H_{x_i},H_{x_{i+1}}\) 的差超过 \(d\) 呢?并不会,因为在那之前,\(H_{x_i+1},H_{x_{i+1}-1}\) 一定会先变成 \(S\) 的元素。
综上,结论得证,状态数量优化到 \(O(n^3)\),可行。
显然只可能相邻的楼房连电缆,问题变为:有一些数,要选 \(k\) 个,相邻的不能选,要求和最小。
这个问题有点像上面的 种树,每次选最小的,然后加入一个权值等于 左边+右边-本身 的数,同时左边、右边、本身合并为一个大结点。
用链表。
显然根结点的各个子树相互独立,每颗子树的答案取 max 即可。
显然我们希望每一次行动,都是所有蚂蚁都往上走。但是有可能多个蚂蚁的目的地都是一个结点,这个时候就会卡住。
什么样的蚂蚁之间会矛盾?初始深度相同的蚂蚁会,而且可以发现一定会。(至少在子树的根那里卡住一次)
这个时候我们就要让一些蚂蚁停留一回合,可以视作深度加一。
在这么把所有初始深度相同的蚂蚁都加好了之后,最大深度就是最终答案。
具体操作:把子树里的所有深度从小到大排序得到数组 \(a\),然后对于 \(i:2\sim n\) 依次使 \(a_i\leftarrow \max(a_{i-1}+1,a_i)\)。于是 \(a_n\) 就是这颗子树的答案。
如果没有要求编码的最长长度最短,就是哈夫曼树的板子题。
普通哈夫曼编码拿一个普通的优先队列就行了。而对于还要求最长长度的哈夫曼编码,优先队列的元素要有二维属性:一维记录出现次数/频率,一维记录目前的长度。
每次取出 \(k\) 个元素合并,第一维相同的取第二维较小的。
给定 \(n\) 个数,每次操作合并两个数,得到它们中较大值 \(+C\),其中 \(C\) 是一个常数。求最后留下来的数最小是多少。
多了一个 \(+C\),现在的贪心方法是什么?
其实贪心方法和普通哈夫曼树一样,都是不断取两个最小的替换为结果。
我们只需要证明:权值最小的两个 \(w_1,w_2\) 一定是在 新 · 哈夫曼树 最低层的两个兄弟。
用调整法,如果更高层的有比最低层还小的,可以调整。新旧两种方案的权值一比较,证毕。
(证明的式子是 \(\max()<\max()\) 型的,类比打怪兽)
贪心:权值最大的父节点被选了之后,它就立刻会在下一个被选。
我们希望可以合并结点,同时合并后的结点可以等价代替原本的两个结点。
比如 \(x,y\) 要合并为一个结点,\(z\) 是另外一个结点。因为 \(x,y\) 是连着的,所以一共两种可能:
-
先 \(x,y\) 后 \(z\),\(x+2y+3z\)。
-
先 \(z\) 后 \(x,y\),\(z+2x+3y\)。
因为我们只关心大小关系。(我们不在乎具体数值,因为如果通过大小关系找出染色顺序,就可以重新倒回去算具体数值)
给 \(x+2y+3z,z+2x+3y\) 都加上 \((z-y)/2\)。
\((x+y)/2+2z,z+2((x+y)/2)\)。
这相当于 \(x,y\) 合并为权值 \((x+y)/2\) 的结点!
所以合并操作就是把 \(x,y\rightarrow (x+y)/2\)。
观光公交:
标签:结点,le,题目,最小,贪心,合集,sim,rightarrow From: https://www.cnblogs.com/FLY-lai/p/18016086