TensorFlow.js 学习手册(七)
译者:飞龙
结语
“那么为什么要尝试预测未来,如果这是如此困难,几乎不可能呢?因为做出预测是一种在我们看到自己朝着危险方向漂移时发出警告的方式。因为预测是指出更安全、更明智的途径的有用方式。最重要的是,我们的明天是我们今天的孩子。”
—Octavia E. Butler
构建和撰写这样一个鼓舞人心的框架是一种绝对的乐趣。我简直无法相信我已经在为这本书写后记了,我想您可能对阅读完这本书的感觉也是如此。此刻,我们在这本书中的探索已经结束。然而,您在 TensorFlow.js 中的冒险现在已经开始。
在这本书中,您涵盖了许多机器学习的基础和视觉方面。如果您对机器学习不熟悉,现在您可以深入了解更高级的模型架构,如声音、文本和生成模型。虽然您已经掌握了 TensorFlow.js 的许多基础知识,但还有许多团队与您一起探索着整个可能性的宇宙。
从这里,您可以订阅频道和信息,帮助您成长,连接您所需的人,并将您带入令人惊叹的 TensorFlow.js 项目,您可以在其中构建令人惊叹的产品。
社交
要了解 TensorFlow.js 的最新动态,我强烈建议您进行社交连接。Twitter 标签#MadeWithTFJS经常用于标记 TensorFlow.js 中的新颖和独特的创作。Google 的 TensorFlow.js 社区领导者Jason Mayes在他的展示和讲解活动中帮助推广这个标签,这些活动都在 TensorFlow YouTube 频道上展示。
我强烈建议您在这个频道上与所有过去的演讲者社交,包括本人。社交是一个很好的方式,可以提问,看见想法,并获得进入更多社区的途径。
如果您更喜欢阅读而不是写作,那么连接到 TensorFlow.js 的时代精神仍然很重要。我在https://ai-fyi.com管理一个通讯,我将始终发布 TensorFlow.js 及更多发现的最新和最伟大的内容。
更多书籍
如果您是书籍爱好者,并正在寻找下一个机器学习冒险,那就不要再找了。
*Laurence Maroney(O’Reilly)的《面向程序员的人工智能和机器学习》是一本书,将帮助您将您的 TensorFlow 思维应用到一个新的可能性世界。您将学习如何在各种平台上处理 TensorFlow,以及将您的知识推进到计算机视觉以外的领域。
*Aurélien Géron(O’Reilly)的《使用 Scikit-Learn、Keras 和 TensorFlow 进行实践机器学习》是一个更基础的方法,可以帮助您加强机器学习知识的概念和工具。
*Shanqing Cai 等人(Manning)的《使用 JavaScript 进行深度学习》是有关 TensorFlow.js 和机器学习概念的权威信息来源。
其他选择
在线活动正在飞速增长。搜索您感兴趣的话题的活动,并确保查看 O’Reilly 提供的在线活动。
在线课程是互动培训和认证的绝佳机会。查看 O’Reilly Media 提供的在线课程以及许多作者创建的课程。
如果您正在寻找在 TensorFlow.js 中演讲或咨询,我建议您联系我,我将尽力帮助您联系。
更多 TensorFlow.js 代码
那里有越来越多的优秀 TensorFlow.js 项目。如果您正在寻找灵感,这里有一堆我创建的资源和项目:
-
Tic-Tac-Toe: https://www.tensorflowtictactoe.co
-
Enjoying the Show: https://enjoyingthe.show
-
AI Sorting Hat: https://aisortinghat.com
-
NSFWJS: https://nsfwjs.com
-
Nic or Not: https://nicornot.com
-
Add Masks: https://spooky-masks.netlify.app
-
Rock Paper Scissors: https://rps-tfjs.netlify.app
-
Bad Poetry: https://irbeat.netlify.app
-
Dogs and Cats Dataset: https://dogs-n-cats.netlify.app
-
Tensor Playground: https://www.tensorplayground.com
-
FizzBuzz: https://codesandbox.io/s/fizzbuzz-5sog8
-
Blight Cam: https://blightcam.netlify.app
-
RGB to Color Blind: https://youtu.be/X55m9eS5UFU
-
No Trump Social: https://notrumpsocial.com
-
E-course: https://oreil.ly/6Liof
谢谢
感谢您,读者。您是这本书存在的原因。请与我分享喜欢的时刻,这样我们可以一起享受。您可以在 Twitter 上找到我,用户名为@GantLaborde,或者访问我的网站GantLaborde.com。

附录 A. 章节复习答案
第一章:AI 是魔术
-
机器学习是 AI 的一个子集,专注于从数据中学习以提高性能的系统。
-
您可以建议获得结果的最佳方法是收集一组带标签的数据,这样您可以执行监督或半监督训练,或者您可以提供无监督或基于强化的方法。
-
强化学习最适合将机器学习应用于游戏。
-
不,机器学习是人工智能的一个子集。
-
不,模型包含结构和数字,但通常比它看到的训练数据小得多。
-
数据通常被分成训练集和测试集,有些人使用验证集。训练数据集始终是最大的。
第二章:介绍 TensorFlow.js
-
不,TensorFlow 直接与 Python 一起工作。您需要 TensorFlow.js 在浏览器中运行 AI。
-
是的,TensorFlow.js 通过 WebGL 可以访问浏览器 GPU,如果加载
tensorflow/tfjs-node-gpu,则可以通过 CUDA 访问服务器 GPU。 -
不,TensorFlow.js 原始版和 Node.js 版本都不需要 CUDA。
-
您将获得该库的最新版本,其中可能包含对您网站的破坏性更改。
-
分类器返回一个违规数组及其真实可能性的百分比。
-
阈值是可以传递给模型的
load调用的可选参数。 -
不,毒性模型代码需要模型的网络权重,并且在调用
load时会从 TFHub 下载此文件。 -
我们不直接进行任何张量操作;库处理所有 JavaScript 原语到张量的转换和反向转换。
第三章:介绍张量
-
张量使我们能够以优化的速度处理大量数据和计算,这对于机器学习至关重要。
-
没有对象数据类型。
-
一个六阶张量将是六阶的。
-
dataSync和data都会产生一维类型数组。 -
您将收到一个错误。
-
张量的
size是其形状的乘积,其中rank是张量的形状长度。- 例如,张量
tf.tensor([[1,2], [1,2], [1,2]])的形状是[3,2],大小为 6,秩为 2。
- 例如,张量
-
数据类型将是
float32。 -
不,第二个参数是张量的首选形状,不必与输入匹配。
-
使用
tf.memory().numTensors。 -
不,
tidy必须传递一个普通函数。 -
您可以通过使用
tf.keep或从封装函数返回张量来保留在tidy内部创建的张量。 -
这些值在传统的
console.log中不可见,但如果用户使用.print,它们将被记录。 -
topk函数找到最后一个维度上k个最大条目的值和索引。 -
张量被优化用于批量操作。
-
有时被称为推荐系统,它是一种寻求预测用户偏好的过滤系统。
第四章:图像张量
-
对于值
0-255,可以使用int32。 -
tf.tensor([[1, 0, 0],[1, 0, 0]],[[1, 0, 0],[1, 0, 0]]) -
一个 50 x 100 的灰度图像,其中 20%是白色。
-
错误。3D 张量应该具有大小为 4 的 RGBA 通道,但形状将是三阶的,即
[?, ?, 4]。 -
错误。输出将在输入约束内随机化。
-
您可以使用
tf.browser.fromPixels。 -
您将设置值为
9。 -
您可以使用
tf.reverse并提供高度轴,如tf.reverse(myImageTensor, 0)。 -
对于四阶张量进行批处理会更快。
-
结果形状将是
[20, 20, 3]。
第五章:介绍模型
-
您可以在 TensorFlow.js 中加载图形和层模型,它们对应的加载方法是
tf.loadGraphModel和tf.loadLayersModel。 -
不,JSON 文件知道相应的分片,并且只要有访问权限,它们将被加载。
-
您可以从 IndexedDB、本地存储、本地文件系统以及任何其他方式加载模型,以便将它们加载到内存中供 JavaScript 项目使用。
-
函数
loadLayersModel返回一个解析为模型的 promise。 -
可以使用
.dispose清除模型。 -
Inception v3 模型期望一个四维批次,大小为 299 x 299 的 3D RGB 像素,值在 0 到 1 之间。
-
您可以使用 2D 上下文的
strokeRect方法在画布上绘制边界框。 -
第二个参数应该是一个配置对象,带有
fromTFHub: true。
第六章:高级模型和 UI
-
SSD 代表“单次检测器”,指的是用于目标检测的完全卷积方法。
-
您可以在这些模型上使用
executeAsync。 -
SSD MobileNet 模型识别 80 个类别,但每个检测的张量输出形状为 90。
-
非极大值抑制(NMS)和软 NMS 用于利用 IoU 去重检测。
-
大型同步的 TensorFlow.js 调用可能会记录 UI。通常期望您使用异步或甚至将 TensorFlow.js 后端转换为 CPU,以避免引起 UI 问题。
-
画布上下文
measureText(label).width测量标签宽度。 -
将
globalCompositeOperation设置为source-over将覆盖现有内容。这是绘制到画布的默认设置。
第七章:模型制作资源
-
虽然数据量很大,但评估数据的质量和有效特征很重要。一旦数据经过清理并删除了不重要的特征,您可以将其分解为训练、测试和验证集。
-
模型过度拟合训练数据,显示出高方差。您应该评估模型在测试集上的表现,并确保它正确学习以便泛化。
-
该网站是 Teachable Machine,网址为https://teachablemachine.withgoogle.com。
-
模型是根据您的特定数据进行训练的,可能不会很好地泛化。您应该使数据集多样化,以避免出现严重偏差。
-
ImageNet 是用于训练 MobileNet 的数据集。
第八章:训练模型
-
本章的训练数据具有一个秩为一且大小为一的输入,输出为秩为一且大小为一。章节挑战要求输入为五个秩为一的输出为四个数字的秩为一张量。
-
您可以使用
model.summary()查看 Layers 模型的层和可训练参数。 -
激活函数创建非线性预测。
-
第一个指定的层标识出其所需的
inputShape。 -
sgd是一种用于学习的优化方法,代表随机梯度下降。
-
一个时期是通过整个训练数据集进行训练的一次迭代。
-
描述的模型有一个隐藏层(参见图 A-1)。
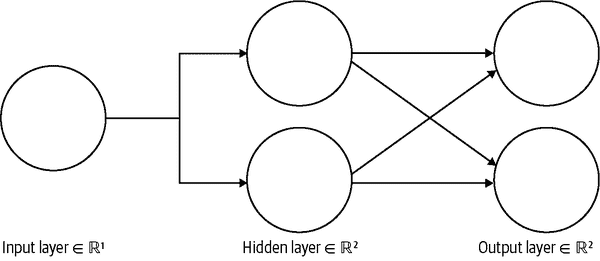
图 A-1。一个隐藏层
第九章:分类模型和数据分析
-
您将在最后一层使用 softmax,带有三个单元,因为这三个手势是互斥的。
-
您将在最后一层使用一个带有 sigmoid 的单个节点/单元。
-
您可以通过键入
$ dnotebook来运行 Dnotebook。 -
您可以使用 Danfo.js 的
concat将它们组合,并将它们列在df_list属性中作为数组。 -
您将使用 Danfo.js 的
get_dummies方法。 -
您可以使用
dfd.MinMaxScaler()来缩放您的模型。
第十章:图像训练
-
卷积层有许多可训练的滤波器。
-
卷积窗口大小为
kernelSize。 -
为了保持卷积结果的大小不变,您需要通过将层的
padding属性设置为'same'来填充卷积。 -
错误。卷积层可以处理多维输入。在将它们连接到密集神经网络之前,您必须展平一组卷积的输出。
-
一个 3 x 3 的步幅为三的卷积会将每个维度减少三分之一。因此,结果图像将变为更小的 27 x 27。
-
不,你需要知道 12 以外存在多少可能的值,这样函数才能添加所需的零。
第十一章:迁移学习
-
KNN 代表 K-最近邻算法。
-
即使使用迁移学习,小数据集也容易过拟合或具有高方差。
-
图像特征向量标记模型是经过训练的卷积。
-
1.00 将比 0.50 具有 2 倍的特征。
-
将第二个参数设置为
true的.infer方法将返回嵌入。 -
你已经添加到已经训练模型的初始层训练得非常差,你应该确保在训练新层时不要修改已经训练好的层。一切就绪后,你可以结合并进行“微调”训练。
-
你应该将输入数据展平,以便后续网络的密集层能够正确处理。
第十二章:Dicify:毕业项目
-
你可以使用
tf.split将张量沿着给定轴分割成相等的子张量。 -
这个过程被称为数据增强。
-
科学家们多年来一直在研究这个问题,虽然尚未确定来源,但它已被普遍接受为科学事实。
附录 B. 章节挑战答案
第二章:卡车警报!
MobileNet 模型可以检测各种不同类型的卡车。您可以通过查看可识别卡车的列表来解决这个问题,或者您可以简单地在给定的类名列表中搜索truck这个词。为简单起见,提供的答案选择了后者。
包含 HTML 和 JavaScript 的整个解决方案在这里:
<!DOCTYPE html>
<html>
<head>
<script
src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js">
</script>
<script
src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]">
</script> <!-- ① -->
<script>
mobilenet.load().then(model => {
const img = document.getElementById('myImage'); <!-- ② -->
// Classify the image
model.classify(img).then(predictions => {
console.log('Predictions: ', predictions);
// Was there a truck?
let foundATruck
predictions.forEach(p => {
foundATruck = foundATruck || p.className.includes("truck") <!-- ③ -->
})
// TRUCK ALERT!
if (foundATruck) alert("TRUCK DETECTED!") <!-- ④ -->
});
});
</script>
</head>
<body>
<h1>Is this a truck?</h1>
<img id="myImage" src="truck.jpg" width="100%"></img>
</body>
</html>
①
从 CDN 加载 MobileNet 模型。
②
通过 ID 访问 DOM 上的图像。由于等待模型加载,DOM 可能已经加载了一段时间。
③
如果在任何预测中检测到truck这个词,将foundATruck设置为 true。
④
真相时刻!只有在foundATruck为 true 时才会弹出警报。
这个带有卡车图像的章节挑战答案可以在本书的GitHub源代码中找到。
第三章:你有什么特别之处?
这个简单的练习是关于查找 TensorFlow.js tf.unique方法。一旦找到这个友好的方法,就很容易构建一个解决方案,就像这样:
const callMeMaybe = tf.tensor([8367677, 4209111, 4209111, 8675309, 8367677])
const uniqueTensor = tf.unique(callMeMaybe).values
const result = uniqueTensor.arraySync()
console.log(`There are ${result.length} unique values`, result)
不要忘记将此代码包装在tf.tidy中以进行自动张量清理!
第四章:混乱排序
一种优雅的解决方案是对randomUniform创建的张量使用topk进行排序。由于randomUniform创建的值在0和1之间,并且topk沿着最后一个轴对值进行排序,您可以使用以下代码完成这个练习:
const rando = tf.randomUniform([400, 400]) // ①
const sorted = tf.topk(rando, 400).values // ②
const answer = sorted.reshape([400, 400, 1]) // ③
①
创建一个 2D 的 400 x 400 张量,其中包含介于0和1之间的随机值。
②
使用topk对最后一个维度(宽度)进行排序,并返回所有 400 个值。
③
可选:将张量重塑为 3D 值。
先前的解决方案非常冗长,可以压缩为一行代码:
tf.topk(tf.randomUniform([400, 400]), 400).values
第五章:可爱的脸
现在,第一个模型已经给出了脸部的坐标,一个张量裁剪将提供这些像素。这几乎与strokeRect完全相同,因为您提供了一个起始位置和所需的大小。然而,我们之前的所有测量对于这个裁剪都不起作用,因为它们是在图像的调整版本上计算的。您需要在原始张量数据上进行类似的计算,以便提取正确的信息。
提示
如果您不想重新计算位置,可以将张量调整大小以匹配petImage的宽度和高度。这将允许您重用相同的startX、startY、width和height变量进行裁剪。
以下代码可能引用原始人脸定位代码中创建的一些变量,特别是原始的fromPixels张量myTensor:
// Same bounding calculations but for the tensor
const tHeight = myTensor.shape[0] // ①
const tWidth = myTensor.shape[1]
const tStartX = box[0] * tWidth
const tStartY = box[1] * tHeight
const cropLength = parseInt((box[2] - box[0]) * tWidth, 0) // ②
const cropHeight = parseInt((box[3] - box[1]) * tHeight, 0)
const startPos = [tStartY, tStartX, 0]
const cropSize = [cropHeight, cropLength, 3]
const cropped = tf.slice(myTensor, startPos, cropSize)
// Prepare for next model input
const readyFace = tf.image
.resizeBilinear(cropped, [96, 96], true)
.reshape([1, 96, 96, 3]); // ③
①
请注意,张量的顺序是高度然后宽度。它们的格式类似于数学矩阵,而不是图像特定的宽度乘以高度的标准。
②
减去比率可能会留下浮点值;您需要将这些值四舍五入到特定的像素索引。在这种情况下,答案是使用parseInt来去除任何小数。
③
显然,批处理,然后取消批处理,然后重新批处理是低效的。在可能的情况下,您应该将所有操作保持批处理,直到绝对必要。
现在,您已经成功地准备好将狗脸张量传递到下一个模型中,该模型将返回狗在喘气的可能性百分比。
结果模型的输出从未指定,但您可以确保它将是一个两值的一维张量,索引 0 表示不 panting,索引 1 表示 panting,或者是一个一值的一维张量,表示从零到一的 panting 可能性。这两种情况都很容易处理!
第六章:顶级侦探
使用topk的问题在于它仅在特定张量的最终维度上起作用。因此,您可以通过两次调用topk来找到两个维度上的最大值。第二次您可以将结果限制为前三名。
const { indices, values } = tf.topk(t)
const topvals = values.squeeze()
const sorted = tf.topk(topvals, 3)
// prints [3, 4, 2]
sorted.indices.print()
然后,您可以循环遍历结果并从topvals变量中访问前几个值。
第七章:再见,MNIST
通过向导您可以选择所有所需的设置;您应该已经创建了一些有趣的结果。结果应该如下:
-
100 个二进制文件被生成在一个分组中。
-
最终大小约为 1.5 MB。
-
由于大小为 1.5 MB,如果使用默认值,这可以适合单个 4 MB 分片。
第八章:模型架构师
您被要求创建一个符合给定规格的 Layers 模型。该模型的输入形状为五,输出形状为四,中间有几个具有指定激活函数的层。
构建模型的代码应该如下所示:
const model = tf.sequential();
model.add(
tf.layers.dense({
inputShape: 5,
units: 10,
activation: "sigmoid"
})
);
model.add(
tf.layers.dense({
units: 7,
activation: "relu"
})
);
model.add(
tf.layers.dense({
units: 4,
activation: "softmax"
})
);
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy"
});
可训练参数的数量计算为进入一个层的行数 + 该层中的单元数。您可以使用每个层的计算layerUnits[i] * layerUnits[i - 1] + layerUnits[i]来解决这个问题。model.summary()的输出将验证您的数学计算。将您的摘要与示例 B-1 进行比较。
示例 B-1. 模型摘要
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
dense_Dense33 (Dense) [null,10] 60
_________________________________________________________________
dense_Dense34 (Dense) [null,7] 77
_________________________________________________________________
dense_Dense35 (Dense) [null,4] 32
=================================================================
Total params: 169
Trainable params: 169
Non-trainable params: 0
_________________________________________________________________
第九章:船出事了
当然,有很多获取这些信息的方法。这只是其中一种方式。
要提取每个名称的敬语,您可以使用.apply并通过空格分割。这将让您很快得到大部分答案。但是,一些名称中有“von”之类的内容,这会导致额外的空格并稍微破坏您的代码。为此,一个好的技巧是使用正则表达式。我使用了/,\s(.*?)\./,它查找逗号后跟一个空格,然后匹配直到第一个句点。
您可以应用这个方法创建一个新行,按该行分组,然后使用.mean()对幸存者的平均值进行表格化。
mega_df['Name'] = mega_df['Name'].apply((x) => x.split(/,\s(.*?)\./)[1])
grp = mega_df.groupby(['Name'])
table(grp.col(['Survived']).mean())
mega_df['Name']被替换为有用的内容,然后进行分组以进行验证。然后可以轻松地对其进行编码或进行分箱处理以用于您的模型。
图 B-1 显示了在 Dnotebook 中显示的分组代码的结果。
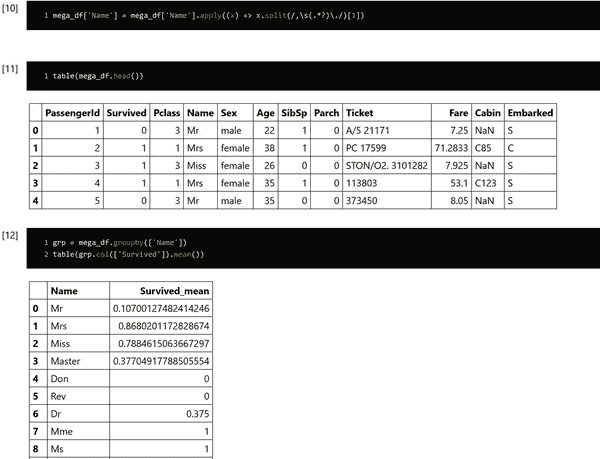
图 B-1. 敬语和生存平均值
第十章:保存魔法
为了保存最高的验证准确性,而不是最后的验证准确性,您可以在时期结束回调中添加一个条件保存。这可以避免您意外地陷入过拟合时期的困扰。
// initialize best at zero
let best = 0
//...
// In the callback object add the onEpochEnd save condition
onEpochEnd: async (_epoch, logs) => {
if (logs.val_acc > best) {
console.log("SAVING")
model.save(savePath)
best = logs.val_acc
}
}
还有earlyStopping预打包回调,用于监视和防止过拟合。将您的回调设置为callbacks: tf.callbacks.earlyStopping({monitor: 'val_acc'})将在验证准确性回退时停止训练。
第十一章:光速学习
您现在知道很多解决这个问题的方法,但我们将采取快速简单的方式。解决这个问题有四个步骤:
-
加载新的图像数据
-
将基础模型削减为特征模型
-
创建读取特征的新层
-
训练新层
加载新的图像数据:
const dfy = await dfd.read_csv('labels.csv')
const dfx = await dfd.read_csv('images.csv')
const Y = dfy.tensor
const X = dfx.tensor.reshape([dfx.shape[0], 28, 28, 1])
将基础模型削减为特征模型:
const model = await tf.loadLayersModel('sorting_hat/model.json')
const layer = model.getLayer('max_pooling2d_MaxPooling2D3')
const shaved = tf.model({
inputs: model.inputs,
outputs: layer.output
})
// Run data through shaved model to get features
const XFEATURES = shaved.predict(X)
创建读取特征的新层:
transferModel = tf.sequential({
layers: [
tf.layers.flatten({ inputShape: shaved.outputs[0].shape.slice(1) }),
tf.layers.dense({ units: 128, activation: 'relu' }),
tf.layers.dense({ units: 3, activation: 'softmax' }),
],
})
transferModel.compile({
optimizer: 'adam',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
})
训练新层:
await transferModel.fit(XFEATURES, Y, {
epochs: 10,
validationSplit: 0.1,
callbacks: {
onEpochEnd: console.log,
},
})
结果在 10 个时期内训练到了很高的准确性,如图 B-2 所示。
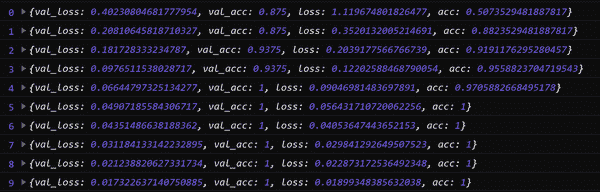
图 B-2. 仅从 150 张图像训练
这个挑战的完整答案可以在本章的相关源代码中找到,这样你就可以查看代码,甚至与结果进行交互。
第十二章:简单如 01, 10, 11
将图像转换为灰度很容易。一旦你这样做了,你可以在图像上使用 tf.where 来用白色或黑色像素替换每个像素。
以下代码将具有 input ID 的图像转换为一个二值化图像,该图像显示在同一页上名为 output 的画布上:
// Simply read from the DOM
const inputImage = document.getElementById('input')
const inTensor = tf.browser.fromPixels(inputImage, 1)
// Binarize
const threshold = 50
const light = tf.onesLike(inTensor).asType('float32')
const dark = tf.zerosLike(inTensor)
const simpleBinarized = tf.where(
tf.less(inTensor, threshold),
dark, // False Case: place zero
light, // True Case: place one
)
// Show results
const myCanvas = document.getElementById('output')
tf.browser.toPixels(simpleBinarized, myCanvas)
本章挑战答案的完全运行示例可以在本章的相关源代码中找到。
有更高级和更健壮的方法来对图像进行二值化。如果你想处理更多的图像,请查看二值化算法。
附录 C. 权利和许可
Unsplash 许可
Unsplash 授予您不可撤销的、非独占的、全球性的版权许可,允许您免费下载、复制、修改、分发、执行和使用 Unsplash 的照片,包括商业用途,无需征得摄影师或 Unsplash 的许可。该许可不包括从 Unsplash 编译照片以复制类似或竞争性服务的权利。
在此许可下的图像:
第二章
图 2-5:Milovan Vudrag 拍摄的照片
第五章
图 5-9:Karsten Winegeart 拍摄的照片
图 5-4:Dave Weatherall 拍摄的照片
第六章
图 6-15:Kelsey Chance 拍摄的照片
第十一章
图 11-2,骆驼:Wolfgang Hasselmann 拍摄的照片
图 11-2,天竺鼠:Jack Catalano 拍摄的照片
图 11-2,水豚:Dušan Veverkolog 拍摄的照片
图 11-8,兔子 1:Satyabrata sm 拍摄的照片
图 11-8,兔子 2:Gary Bendig 拍摄的照片
图 11-8,兔子 3:Gavin Allanwood 拍摄的照片
图 11-8,汽车 1:Sam Pearce-Warrilow 拍摄的照片
图 11-8,汽车 2:Cory Rogers 拍摄的照片
图 11-8,汽车 3:Kevin Bhagat 拍摄的照片
图 11-8,测试兔子:Christopher Paul High 拍摄的照片
第十二章
图 12-12,修改后的 Igor Miske 拍摄的照片
图 12-13:Gant Laborde 拍摄的照片
Apache 许可证 2.0
版权所有 2017 © Google
根据 Apache 许可证第 2.0 版(“许可证”)许可,除非符合许可证的规定,否则您不得使用此文件。您可以在http://www.apache.org/licenses/LICENSE-2.0获取许可证的副本。
除非适用法律要求或书面同意,根据许可证分发的软件是基于“原样”分发的,没有任何明示或暗示的担保或条件。请查看许可证以了解许可证下的权限和限制的具体语言。
在此许可下的图像:
- 图 4-9:维基媒体共享
在此许可下的代码:
-
第二章:毒性模型 NPM
-
第二章:MobileNet 模型 NPM
-
第五章:Inception v3 模型
公共领域
在此许可下的图像:
-
图 3-2:https://oreil.ly/xVmXb
-
图 9-1:https://oreil.ly/ly839
-
图 12-1:https://oreil.ly/e0MCV
WTFPL
根据此许可的数据](http://www.wtfpl.net):
-
第五章:井字游戏模型
-
第五章:宠物面孔模型
-
第十章:分拣帽模型
知识共享署名-相同方式共享 4.0 国际许可协议(CC BY-SA 4.0)
根据此许可的数据](https://creativecommons.org/licenses/by-sa/4.0):
- 第五章:宠物面孔模型是用牛津-IIIT 宠物数据集训练的
在此许可下的图像:
- 图 11-1,水豚:https://oreil.ly/qLh1h
知识共享署名 4.0 国际许可协议(CC BY 4.0)
根据此许可证的数据:
- 第十章:从绘图中排序数据是Google 的 Quick, Draw! 数据集的子集,并在Kaggle上以相同许可证共享。
Gant Laborde 和 O’Reilly
除了在附录 C 中明确标识的图像外,所有其他图像均由 O’Reilly 或作者 Gant Laborde 拥有,用于此出版作品的明确使用。
TensorFlow 和 TensorFlow.js 标志
TensorFlow、TensorFlow 标志和任何相关标记均为 Google Inc. 的商标。
标签:const,模型,张量,js,lrn,merge,tf,TensorFlow,tfjs From: https://www.cnblogs.com/apachecn/p/18011866