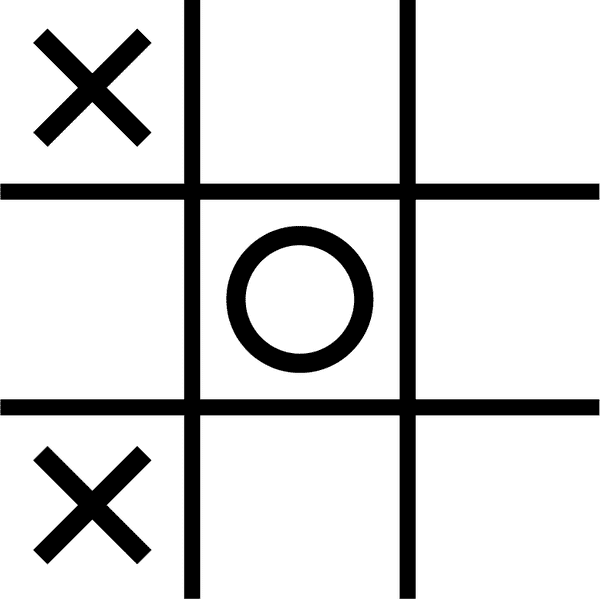
5 7 23 61 = ?
将每个数字乘以相应位置并不像你们中的一些人可能想的那样简单;因为涉及到乘法和加法。计算左上角的值将是 91 x 1 + 82 x 33 + 13 x 7 = 2888。现在对新矩阵的每个索引重复八次这样的计算。计算这种简单乘法的 JavaScript 并不完全琐碎。
张量具有数学上的好处。我不必编写任何代码来执行以前的计算。虽然编写自定义代码不会很复杂,但会是非优化和冗余的。有用的、可扩展的数学运算是内置的。TensorFlow.js 使线性代数对于张量等结构变得易于访问和优化。我可以用以下代码快速得到以前矩阵的答案:
const mat1 = [
[91, 82, 13],
[15, 23, 62],
[25, 66, 63]
]
const mat2 = [
[1, 23, 83],
[33, 12, 5],
[7, 23, 61]
]
tf.matMul(mat1, mat2).print()
在第二章中,毒性检测器下载了用于每个分类计算的大量数字。在毫秒内处理这些大量计算的行为是张量背后的力量。虽然我们将继续扩展张量计算的好处,但 TensorFlow.js 的整个原因是这样一个大量计算的复杂性是框架的领域,而不是程序员的领域。
推荐张量
凭借你迄今学到的技能,你可以构建一个简单的示例,展示 TensorFlow.js 如何处理真实场景的计算。以下示例被选择为张量的力量的一个例证,它欢迎精英和数学避免者。
注意
这一部分可能是你会接触到的最深的数学内容。如果你想深入了解支持机器学习的线性代数和微积分,我推荐一个由斯坦福大学提供、由吴恩达教授的免费在线课程。
让我们用一些张量数据构建一些真实的东西。你将进行一系列简单的计算,以确定一些用户的偏好。这些系统通常被称为推荐引擎。你可能熟悉推荐引擎,因为它们建议你应该购买什么,下一部电影你应该看什么等等。这些算法是数字产品巨头如 YouTube、亚马逊和 Netflix 的核心。推荐引擎在任何销售任何东西的业务中都非常受欢迎,可能可以单独填写一本书。我们将实现一个简单的“基于内容”的推荐系统。发挥你的想象力,因为在生产系统中,这些张量要大得多。
在高层次上,你将做以下事情:
-
要求用户对乐队进行评分,从1到10。
-
任何未知的乐队得到0。
-
乐队和音乐风格将是我们的“特色”。
-
使用矩阵点积来确定每个用户喜欢的风格!
让我们开始创建一个推荐系统!这个小数据集将作为你所需的示例。正如你所注意到的,你在代码中混合了 JavaScript 数组和张量。将标签保留在 JavaScript 中,将计算推入张量是非常常见的。这不仅使张量专注于数字;还有国际化张量结果的好处。标签是这个操作中唯一依赖语言的部分。你会看到这个主题在本书中的几个示例和实际机器学习的真实世界中持续存在。
以下是数据:
const users = ['Gant', 'Todd', 'Jed', 'Justin'] // ①
const bands = [ // ②
'Nirvana',
'Nine Inch Nails',
'Backstreet Boys',
'N Sync',
'Night Club',
'Apashe',
'STP'
]
const features = [ // ③
'Grunge',
'Rock',
'Industrial',
'Boy Band',
'Dance',
'Techno'
]
// User votes // ④
const user_votes = tf.tensor([
[10, 9, 1, 1, 8, 7, 8],
[6, 8, 2, 2, 0, 10, 0],
[0, 2, 10, 9, 3, 7, 0],
[7, 4, 2, 3, 6, 5, 5]
])
// Music Styles 5
const band_feats = tf.tensor([
[1, 1, 0, 0, 0, 0],
[1, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 1],
[0, 0, 1, 0, 0, 1],
[1, 1, 0, 0, 0, 0]
])
①
这四个名称标签只是简单地存储在一个普通的 JavaScript 数组中。
②
你已经要求我们的用户对七支乐队进行评分。
③
一些简单的音乐流派可以用来描述我们的七支乐队,同样存储在一个 JavaScript 数组中。
④
这是我们的第一个张量,一个二级描述,每个用户的投票从1到10,其中“我不认识这支乐队”为0。
⑤
这个张量也是一个二维张量,用于识别与每个给定乐队匹配的流派。每行索引代表了可以分类为真/假的流派的编码。
现在你已经拥有了张量中所需的所有数据。快速回顾一下,你可以看到信息的组织方式。通过阅读user_votes变量,你可以看到每个用户的投票。例如,你可以看到用户0,对应 Gant,给 Nirvana 评了10分,Apashe 评了7分,而 Jed 给了 Backstreet Boys10分。
band_feats变量将每个乐队映射到它们满足的流派。例如,索引1处的第二个乐队是 Nine Inch Nails,对 Grunge 和工业音乐风格有积极评分。为了简单起见,你使用了每种流派的二进制1和0,但在这里也可以使用一种标准化的数字比例。换句话说,[1, 1, 0, 0, 0, 0]代表了 Grunge 和 Rock 对于第 0 个乐队,也就是 Nirvana。
接下来,你将根据他们的投票计算每个用户最喜欢的流派:
// User's favorite styles
const user_feats = tf.matMul(user_votes, band_feats)
// Print the answers
user_feats.print()
现在user_feats包含用户在每个乐队的特征上的点积。我们打印的结果将如下所示:
Tensor
[[27, 18, 24, 2 , 1 , 15],
[14, 6 , 18, 4 , 2 , 10],
[2 , 0 , 12, 20, 10, 10],
[16, 12, 15, 5 , 2 , 11]]
这个张量显示了每个用户特征(在本例中是流派)的价值。用户0,对应 Gant,其最高价值在索引0处为27,这意味着他们在调查数据中最喜欢的流派是 Grunge。这些数据看起来相当不错。使用这个张量,你可以确定每个用户的喜好。
虽然数据以张量形式存在,但你可以使用一个叫做topk的方法来帮助我们识别每个用户的前k个值。要获取前k个张量或者仅仅通过识别它们的索引来确定前k个值的位置,你可以调用带有所需张量和大小的函数topk。在这个练习中,你将把k设置为完整特征集大小。
最后,让我们把这些数据带回 JavaScript。编写这段代码可以这样写:
// Let's make them pretty
const top_user_features = tf.topk(user_feats, features.length)
// Back to JavaScript
const top_genres = top_user_features.indices.arraySync() // ①
// print the results
users.map((u, i) => {
const rankedCategories = top_genres[i].map(v => features[v]) // ②
console.log(u, rankedCategories)
})
①
你将索引张量返回到一个二维 JavaScript 数组以获取结果。
②
你正在将索引映射回音乐流派。
结果日志如下所示:
Gant
[
"Grunge",
"Industrial",
"Rock",
"Techno",
"Boy Band",
"Dance"
]
Todd
[
"Industrial",
"Grunge",
"Techno",
"Rock",
"Boy Band",
"Dance"
]
Jed
[
"Boy Band",
"Industrial",
"Dance",
"Techno",
"Grunge",
"Rock"
]
Justin
[
"Grunge",
"Industrial",
"Rock",
"Techno",
"Boy Band",
"Dance"
]
在结果中,你可以看到 Todd 应该多听工业音乐,而 Jed 应该加强对男孩乐队的了解。两者都会对他们的推荐感到满意。
你刚刚做了什么?
你成功地将数据加载到张量中,这样做是有意义的,然后你对整个集合应用了数学计算,而不是对每个人进行迭代式的处理。一旦你得到了答案,你对整个集合进行了排序,并将数据带回 JavaScript 进行推荐!
你还能做更多吗?
你可以做很多事情。从这里开始,你甚至可以使用每个用户投票中的 0 来确定用户从未听过的乐队,并按照最喜欢的流派顺序推荐给他们!有一种非常酷的数学方法可以做到这一点,但这有点超出了我们第一个张量练习的范围。不过,恭喜你实现了在线销售中最受欢迎和流行的功能之一!
章节回顾
在本章中,你不仅仅是浅尝辄止地了解了张量。你深入了解了 TensorFlow.js 的基本结构,并掌握了根本。你正在掌握在 JavaScript 中应用机器学习的方法。张量是一个贯穿所有机器学习框架和基础知识的概念。
章节挑战:你有何特别之处?
现在你不再是一个张量新手,你可以像专业人士一样管理张量,让我们尝试一个小练习来巩固你的技能。在撰写本文时,JavaScript 没有内置的方法来清除数组中的重复项。虽然其他语言如 Ruby 已经有了uniq方法超过十年,JavaScript 开发人员要么手动编写解决方案,要么导入像 Lodash 这样的流行库。为了好玩,让我们使用 TensorFlow.js 来解决唯一值的问题。作为一个学到的教训的练习,思考一下这个问题:
给定这个美国电话号码数组,删除重复项。
// Clean up the duplicates
const callMeMaybe = tf.tensor([8367677, 4209111, 4209111, 8675309, 8367677])
确保您的答案是一个 JavaScript 数组。如果您在这个练习中遇到困难,可以查阅TensorFlow.js 在线文档。搜索关键术语的文档将指引您正确方向。
您可以在附录 B 中找到这个挑战的答案。
复习问题
让我们回顾一下您在本章编写的代码中学到的教训。花点时间回答以下问题:
-
我们为什么要使用张量?
-
以下哪一个不是张量数据类型?
-
Int32
-
Float32
-
对象
-
布尔值
-
六维张量的秩是多少?
-
方法dataSync的返回数组的维数是多少?
-
当您将一个三维张量传递给tf.tensor1d时会发生什么?
-
在张量形状方面,rank和size之间有什么区别?
-
张量tf.tensor([1])的数据类型是什么?
-
张量的输入数组维度总是结果张量维度吗?
-
如何确定内存中张量的数量?
-
tf.tidy能处理异步函数吗?
-
如何在tf.tidy内部创建的张量?
-
我可以用console.log看到张量的值吗?
-
tf.topk方法是做什么的?
-
张量是为批量还是迭代计算进行优化的?
-
推荐引擎是什么?
这些练习的解决方案可以在附录 A 中找到。
第四章:图像张量
“但是那些不敢抓住荆棘的人
永远不应该渴望玫瑰。”
— 安妮·勃朗特
在上一章中,你创建并销毁了简单的张量。然而,我们的数据很小。正如你可能猜到的,打印张量只能带你走到这么远,而且在这么多维度上。你需要学会如何处理更常见的大张量。当然,在图像世界中这是真实的!这是一个令人兴奋的章节,因为你将开始处理真实数据,我们将能够立即看到你的张量操作的效果。
我们还将利用一些现有的最佳实践。正如你回忆的,在上一章中,你将一个井字棋游戏转换为张量。在这个简单的 3 x 3 网格的练习中,你确定了一种转换游戏状态的方法,但另一个人可能会想出完全不同的策略。我们需要确定一些常见的做法和行业诀窍,这样你就不必每次都重新发明轮子。
我们将:
-
识别张量是什么使其成为图像张量
-
手动构建一些图像
-
使用填充方法创建大张量
-
将现有图像转换为张量,然后再转换回来
-
以有用的方式操作图像张量
当你完成本章时,你将能够自信地处理真实世界的图像数据,而这些知识很多都适用于一般张量的管理。
视觉张量
你可能会假设当图像转换为张量时,得到的张量将是二阶的。如果你忘记了二阶张量是什么样子,请查看第三章。很容易将一个 2D 图像想象成一个 2D 张量,只是像素颜色通常不能存储为单个数字。二阶张量仅适用于灰度图像。彩色像素的最常见做法是将其表示为三个独立的值。那些从小就接触颜料的人被教导使用红色、黄色和蓝色,但我们这些书呆子更喜欢红色、绿色、蓝色(RGB)系统。
注意
RGB 系统是艺术模仿生活的另一个例子。人眼使用 RGB,这是基于“加法”颜色系统——一种发射光的系统,就像计算机屏幕一样。你的美术老师可能用黄色覆盖绿色来帮助淡化随着添加更多而变暗的颜料的颜色,这是一种“减法”颜色系统,就像纸上的颜料一样。
一个像素通常是由红色、绿色和蓝色的有序量来着色,这些量在一个字节内。这个0-255值数组看起来像[255, 255, 255]对于整数,对于大多数寻求相同三个值的十六进制版本的网站来说,看起来像#FFFFFF。当我们的张量是数据类型int32时,这是使用的解释方法。当我们的张量是float32时,假定值在0-1范围内。因此,一个整数[255, 255, 255]代表纯白,但在浮点形式中等价的是[1, 1, 1]。这也意味着[1, 1, 1]在float32张量中是纯白的,并且在int32张量中被解释为接近黑色。
根据张量数据类型的不同,从一个像素编码为[1, 1, 1],你会得到两种颜色极端,如图 4-1 所示。
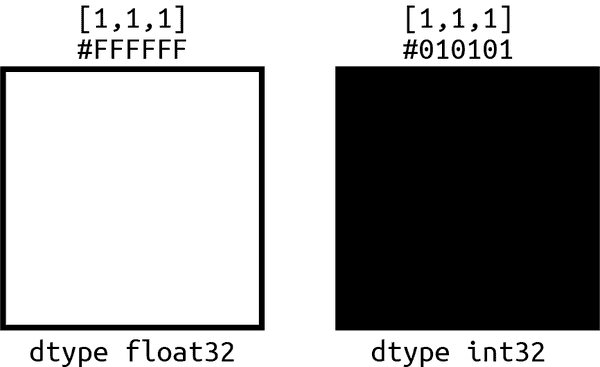
图 4-1。相同数据的显著颜色差异
这意味着要存储图像,你将需要一个三维张量。你需要将每个三值像素存储在给定的宽度和高度上。就像你在井字棋问题中看到的那样,你将不得不确定最佳的格式来做到这一点。在 TensorFlow 和 TensorFlow.js 中,将 RGB 值存储在张量的最后一个维度是一种常见做法。也习惯性地将值沿着高度、宽度,然后颜色维度进行存储。这对于图像来说可能看起来有点奇怪,但引用行然后列是矩阵的经典组织参考顺序。
警告
大多数人会按照宽度乘以高度来提及图像尺寸。一个 1024 x 768 的图像宽度为1024px,高度为768px,但正如我们刚刚所述,TensorFlow 图像张量首先存储高度,这可能有点令人困惑。同样的图像将是一个[768, 1024, 3]张量。这经常会让对视觉张量新手的开发人员感到困惑。
因此,如果你想要制作一个 4 x 3 的像素棋盘,你可以手动创建一个形状为[3, 4, 3]的 3D 数组。
代码将会是以下简单的形式:
const checky = tf.tensor([
[
[1, 1, 1],
[0, 0, 0],
[1, 1, 1],
[0, 0, 0]
],
[
[0, 0, 0],
[1, 1, 1],
[0, 0, 0],
[1, 1, 1]
],
[
[1, 1, 1],
[0, 0, 0],
[1, 1, 1],
[0, 0, 0]
],
])
一个 4 x 3 像素的图像可能会很小,但如果我们放大几百倍,我们将能够看到我们刚刚创建的像素。生成的图像看起来会像图 4-2。

图 4-2。4 x 3 的 TensorFlow.js 棋盘图像
你不仅限于 RGB,正如你可能期望的那样;在张量的 RGB 维度中添加第四个值将添加一个 alpha 通道。就像在 Web 颜色中一样,#FFFFFF00将是白色的零不透明度,具有红色、绿色、蓝色、alpha(RGBA)值为[1, 1, 1, 0]的张量像素也将是类似透明的。一个带有透明度的 1024 x 768 图像将存储在一个形状为[768, 1024, 4]的张量中。
作为前述两个系统的推论,如果最终通道只有一个值而不是三个或四个,生成的图像将是灰度的。
我们之前的黑白棋盘图案示例可以通过使用最后的知识大大简化。现在我们可以用张量构建相同的图像,代码如下:
const checkySmalls = tf.tensor([
[[1],[0],[1],[0]],
[[0],[1],[0],[1]],
[[1],[0],[1],[0]]
])
是的,如果你简单地去掉那些内部括号并将其移动到一个简单的 2D 张量中,那也是可以的!
快速图像张量
我知道有一大群人在你的门口排队逐个像素地手绘图像,所以你可能会惊讶地发现有些人觉得写一些小的 1 和 0 很烦人。当然,你可以使用Array.prototype.fill创建数组,然后使用它来填充数组以创建可观的 3D 张量构造器,但值得注意的是,TensorFlow.js 已经内置了这个功能。
创建具有预填充值的大张量是一个常见的需求。实际上,如果你继续从第三章的推荐系统中工作,你将需要利用这些确切的功能。
现在,你可以使用tf.ones、tf.zeros和tf.fill方法手动创建大张量。tf.ones和tf.zeros都接受一个形状作为参数,然后构造该形状,每个值都等于1或0。因此,代码tf.zeros([768, 1024, 1])将创建一个 1024 x 768 的黑色图像。可选的第二个参数将是生成的张量的数据类型。
提示
通常,你可以通过使用tf.zeros创建一个空图像,通过模型预先分配内存。结果会立即被丢弃,后续调用会快得多。这通常被称为模型预热,当开发人员在等待网络摄像头或网络数据时寻找要分配的内容时,你可能会看到这种加速技巧。
正如你所想象的,tf.fill接受一个形状,然后第二个参数是用来填充该形状的值。你可能会想要将一个张量作为第二个参数传递,从而提高生成的张量的秩,但重要的是要注意这样做是行不通的。关于什么有效和无效的对比,请参见表 4-1。
表 4-1。填充参数:标量与向量
| 这有效 |
|
这无效 |
tf.fill([2, 2], 1) |
|
tf.fill([2, 2], [1, 1, 1]) |
你的第二个参数必须是一个单一值,用来填充你给定形状的张量。这个非张量值通常被称为标量。总之,代码tf.fill([200, 200, 4], 0.5)将创建一个 200 x 200 的灰色半透明正方形,如图 4-3 所示。

图 4-3. 带背景的 Alpha 通道图像张量
如果您对不能用优雅的颜色填充张量感到失望,那么我有一个惊喜给您!我们下一个创建大张量的方法不仅可以让您用张量填充,还可以让您用图案填充。
让我们回到您之前制作的 4 x 3 的方格图像。您手工编码了 12 个像素值。如果您想制作一个 200 x 200 的方格图像,那将是 40,000 个像素值用于简单的灰度。相反,我们将使用.tile方法来扩展一个简单的 2 x 2 张量。
// 2 x 2 checker pattern
const lil = tf.tensor([ // ①
[[1], [0]],
[[0], [1]]
]);
// tile it
const big = lil.tile([100, 100, 1]) // ②
①
方格图案是一个二维的黑白张量。这可以是任何优雅的图案或颜色。
②
瓷砖大小为 100 x 100,因为重复的图案是 2 x 2,这导致了一个 200 x 200 的图像张量。
对于人眼来说,方格像素很难看清楚。不放大的情况下,方格图案可能看起来灰色。就像印刷点组成杂志的多种颜色一样,一旦放大,您就可以清楚地看到方格图案,就像在图 4-4 中一样。

图 4-4. 10 倍放大的 200 x 200 方格张量
最后,如果所有这些方法对您的口味来说都太结构化,您可以释放混乱!虽然 JavaScript 没有内置方法来生成随机值数组,但 TensorFlow.js 有各种各样的方法可以精确地做到这一点。
简单起见,我最喜欢的是.randomUniform。这个张量方法接受一个形状,还可以选择一个最小值、最大值和数据类型。
如果您想构建一个 200 x 200 的灰度颜色的随机静态图像,您可以使用tf.randomUniform([200, 200, 1])或者tf.randomUniform([200, 200, 1], 0, 255, 'int32')。这两者将产生相同的(尽可能相同的)结果。
图 4-5 显示了一些示例输出。

图 4-5. 200 x 200 随机值填充的张量
JPG、PNG 和 GIF,哦我的天啊!
好的,甘特!您已经谈论了一段时间的图像,但我们看不到它们;我们只看到张量。张量如何变成实际可见的图像?而对于机器学习来说,现有的图像如何变成张量?
正如您可能已经直觉到的那样,这将根据 JavaScript 运行的位置(特别是客户端和服务器)而有很大不同。要在浏览器上将图像解码为张量,然后再转换回来,您将受到浏览器内置功能的限制和赋予的力量。相反,在运行 Node.js 的服务器上的图像将不受限制,但缺乏易于的视觉反馈。
不要害怕!在本节中,您将涵盖这两个选项,这样您就可以自信地将 TensorFlow.js 应用于图像,无论媒介如何。
我们将详细审查以下常见情况:
-
浏览器:张量到图像
-
浏览器:图像到张量
-
Node.js:张量到图像
-
Node.js:图像到张量
浏览器:张量到图像
为了可视化、修改和保存图像,您将利用 HTML 元素和画布。让我们从给我们一种可视化我们学到的所有图形课程的方法开始。我们将在浏览器中将一个张量渲染到画布上。
首先,创建一个 400 x 400 的随机噪声张量,然后在浏览器中将张量转换为图像。为了实现这一点,您将使用tf.browser.toPixels。该方法将张量作为第一个参数,可选地为第二个参数提供一个画布以绘制。它返回一个在渲染完成时解析的 Promise。
注意
乍一看,将 canvas 作为可选参数是相当令人困惑的。值得注意的是,promise 将以Uint8ClampedArray的形式解析为张量作为参数,因此这是一个很好的方式来创建一个“准备好的 canvas”值,即使您没有特定的 canvas 在脑海中。随着OffscreenCanvas 的概念从实验模式转变为实际支持的 Web API,它可能会减少实用性。
要设置我们的第一个画布渲染,您需要在我们的 HTML 中有一个带有 ID 的画布,以便您可以引用它。对于那些熟悉 HTML 加载顺序复杂性的人来说,您需要在尝试从 JavaScript 中访问它之前使画布存在之前(或者遵循您网站的任何最佳实践,比如检查文档准备就绪状态):
<canvas id="randomness"></canvas>
现在您可以通过 ID 访问此画布,并将其传递给我们的browser.toPixels方法。
const bigMess = tf.randomUniform([400, 400, 3]); // ①
const myCanvas = document.getElementById("randomness"); // ②
tf.browser.toPixels(bigMess, myCanvas).then(() => { // ③
// It's not bad practice to clean up and make sure we got everything
bigMess.dispose();
console.log("Make sure we cleaned up", tf.memory().numTensors);
});
①
创建一个 RGB 400 x 400 图像张量
②
在文档对象模型(DOM)中获取对我们画布的引用
③
使用我们的张量和画布调用browser.toPixels
如果此代码在异步函数中运行,您可以简单地等待browser.toPixels调用,然后清理。如果不使用 promise 或异步功能,dispose几乎肯定会赢得可能的竞争条件并导致错误。
浏览器:图像到张量
正如您可能已经猜到的,browser.toPixels有一个名为browser.fromPixels的对应方法。此方法将获取图像并将其转换为张量。对于我们来说,browser.fromPixels的输入非常动态。您可以传入各种元素,从 JavaScript ImageData 到 Image 对象,再到 HTML 元素如<img>、<canvas>,甚至<video>。这使得将任何图像编码为张量变得非常简单。
作为第二个参数,您甚至可以确定您想要的图像通道数(1、3、4),因此您可以优化您关心的数据。例如,如果您要识别手写,那么就没有真正需要 RGB。您可以立即从我们的张量转换中获得灰度张量!
要设置我们的图像到张量转换,您将探索两种最常见的输入。您将转换一个 DOM 元素,也将转换一个内存元素。内存元素将通过 URL 加载图像。
警告
如果到目前为止您一直在本地打开.html文件,那么这里将停止工作。您需要实际使用像 200 OK!这样的 Web 服务器或其他提到的托管解决方案来访问通过 URL 加载的图像。如果遇到困难,请参阅第二章。
要从 DOM 加载图像,您只需要在 DOM 上引用该项。在与本书相关的源代码中,我设置了一个示例来访问两个图像。跟随的最简单方法是阅读GitHub 上的第四章。
让我们用一个简单的img标签和id设置我们的 DOM 图像:
<img id="gant" src="/gant.jpg" />
是的,那是我决定使用的一张奇怪的图片。我有可爱的狗,但它们很害羞,拒绝签署发布协议成为我书中的模特。作为一个爱狗人士可能会很“艰难”。现在您有了一张图片,让我们写一个简单的 JavaScript 来引用所需的图像元素。
提示
在尝试访问图像元素之前,请确保document已经加载完成。否则,您可能会收到类似“源宽度为 0”的神秘消息。这在没有 JavaScript 前端框架的实现中最常见。在没有任何东西等待 DOM 加载事件的情况下,我建议在尝试访问 DOM 之前订阅window的加载事件。
在img放置并 DOM 加载完成后,您可以调用browser.fromPixels获取结果:
// Simply read from the DOM
const gantImage = document.getElementById('gant') // ①
const gantTensor = tf.browser.fromPixels(gantImage) // ②
console.log( // ③
`Successful conversion from DOM to a ${gantTensor.shape} tensor`
)
①
获取对img标签的引用。
②
从图像创建张量。
③
记录证明我们现在有了一个张量!这将打印以下内容:
Successful conversion from DOM to a 372,500,3 tensor
警告
如果您遇到类似于 Failed to execute 'getImageData' on 'CanvasRenderingContext2D': The canvas has been tainted by cross-origin data. 的错误,这意味着您正在尝试从另一个服务器加载图像而不是本地。出于安全原因,浏览器会防止这种情况发生。查看下一个示例以加载外部图像。
完美!但是如果我们的图像不在页面的元素中怎么办?只要服务器允许跨域加载 (Access-Control-Allow-Origin "*"),您就可以动态加载和处理外部图像。这就是 JavaScript 图像对象示例 的用武之地。我们可以这样将图像转换为张量:
// Now load an image object in JavaScript
const cake = new Image() // ①
cake.crossOrigin = 'anonymous' // ②
cake.src = '/cake.jpg' // ③
cake.onload = () => { // ④
const cakeTensor = tf.browser.fromPixels(cake) // ⑤
console.log( // ⑥
`Successful conversion from Image() to a ${cakeTensor.shape} tensor`
)
}
①
创建一个新的 Image web API 对象。
②
这在这里是不必要的,因为文件在服务器上,但通常需要设置此选项以访问外部 URL。
③
给出图像的路径。
④
等待图像完全加载到对象中,然后再尝试将其转换为张量。
⑤
将图像转换为张量。
⑥
打印我们的张量形状以确保一切按计划进行。这将打印以下内容:从 Image() 成功转换为 578,500,3 张量。
通过结合两种先前的方法,您可以创建一个单页面,其中显示一个图像元素并将两个张量的值打印到控制台(参见 图 4-6)。

图 4-6. 两个图像变成张量的控制台日志
通过图像的日志,您可以看到它们都是 500 像素宽的 RGB 图像。如果修改第二个参数,您可以轻松地将这些图像中的任何一个转换为灰度或 RGBA。您将在本章后面修改我们的图像张量。
Node:张量到图像
在 Node.js 中,没有用于渲染的画布,只有安静高效地写文件。您将使用 tfjs-node 保存一个随机的 400 x 400 RGB。虽然图像张量是逐像素的值,但典型的图像格式要小得多。JPG 和 PNG 具有各种压缩技术、头部、特性等。生成的文件内部看起来与我们漂亮的 3D 图像张量完全不同。
一旦张量转换为它们的编码文件格式,您将使用 Node.js 文件系统库 (fs) 将文件写出。现在您已经有了一个计划,让我们探索保存张量到 JPG 和 PNG 的功能和设置。
编写 JPG
要将张量编码为 JPG,您将使用一个名为 node.encodeJpeg 的方法。此方法接受图像的 Int32 表示和一些选项,并返回一个包含结果数据的 promise。
您可能注意到的第一个问题是,输入张量 必须 是具有值 0-255 的 Int32 编码,而浏览器可以处理浮点和整数值。也许这是一个优秀的开源贡献者的绝佳机会!?
提示
任何具有值 0-1 的 Float32 张量都可以通过将其乘以 255 然后转换为 int32 的代码来转换为新的张量,例如:myTensor.mul(255).asType('int32')。
从张量中写入 JPG,就像在*GitHub 的第四章节中的 chapter4/node/node-encode中发现的那样,可以简单地这样做:
const bigMess = tf.randomUniform([400, 400, 3], 0, 255); // ①
tf.node.encodeJpeg(bigMess).then((f) => { // ②
fs.writeFileSync("simple.jpg", f); // ③
console.log("Basic JPG 'simple.jpg' written");
});
①
创建一个 400 x 400 的图像张量,其中包含随机的 RGB 像素。
②
使用张量输入调用 node.encodeJpeg。
③
生成的数据将使用文件系统库写入。
因为您要写入的文件是 JPG,您可以启用各种配置选项。让我们再写入另一张图片,并在此过程中修改默认设置:
const bigMess = tf.randomUniform([400, 400, 3], 0, 255);
tf.node
.encodeJpeg(
bigMess,
"rgb", // ①
90, // ②
true, // ③
true, // ④
true, // ⑤
"cm", // ⑥
250, // ⑦
250, // ⑧
"Generated by TFJS Node!" // ⑨
)
.then((f) => {
fs.writeFileSync("advanced.jpg", f);
console.log("Full featured JPG 'advanced.jpg' written");
});
①
format:您可以使用grayscale或rgb覆盖默认的颜色通道,而不是匹配输入张量。
②
quality:调整 JPG 的质量。较低的数字会降低质量,通常是为了减小文件大小。
③
progressive:JPG 具有从上到下加载或逐渐清晰的渐进加载能力。将其设置为 true 可以启用渐进加载格式。
④
optimizeSize:花费一些额外的周期来优化图像大小,而不会修改质量。
⑤
chromaDownsampling:这是一个技巧,其中照明比颜色更重要。它修改了数据的原始分布,使其对人眼更清晰。
⑥
densityUnit:选择每英寸或每厘米的像素;一些奇怪的人反对公制系统。
⑦
xDensity:设置 x 轴上的像素密度单位。
⑧
yDensity:设置 y 轴上的像素密度单位。
⑨
xmpMetadata:这是一个非可见的消息,存储在图像元数据中。通常,这是为许可和寻宝活动保留的。
根据您写入 JPG 的原因,您可以充分配置或忽略这些选项来自 Node.js!图 4-7 显示了您刚刚创建的两个 JPG 文件的文件大小差异。
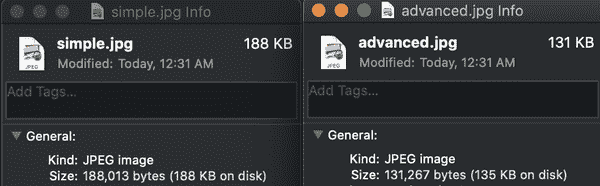
图 4-7. 我们两个示例的文件大小
写入 PNG
写入 PNG 的功能明显比 JPG 有限得多。正如您可能猜到的那样,我们将有一个友好的方法来帮助我们,它被称为node.encodePng。就像我们的朋友 JPG 一样,该方法期望我们的张量的整数表示,值范围在0-255之间。
我们可以轻松地写入 PNG 如下:
const bigMess = tf.randomUniform([400, 400, 3], 0, 255);
tf.node.encodePng(bigMess).then((f) => {
fs.writeFileSync("simple.png", f);
console.log("Basic PNG 'simple.png' written");
});
PNG 参数并不那么先进。您只有一个新参数,而且它是一个神秘的参数!node.encodePng的第二个参数是一个压缩设置。该值可以在-1和9之间任意取值。默认值为1,表示轻微压缩,而9表示最大压缩。
提示
您可能认为-1表示无压缩,但通过实验,0表示无压缩。实际上,-1激活了最大压缩。因此,-1 和 9 实际上是相同的。
由于 PNG 在压缩随机性方面表现糟糕,您可以将第二个参数设置为9,得到与默认设置大小相近的文件:
tf.node.encodePng(bigMess, 9).then((f) => {
fs.writeFileSync("advanced.png", f);
console.log("Full featured PNG 'advanced.png' written");
});
如果您想看到实际的文件大小差异,请尝试打印一些易于压缩的内容,比如tf.zeros。无论如何,您现在可以轻松地从张量生成 PNG 文件。
注意
如果您的张量使用了 alpha 通道,您不能使用 JPG 等格式;您将不得不保存为 PNG 以保留这些数据。
Node:图像到张量
Node.js 是一个出色的工具,用于训练机器学习模型,因为它具有直接的文件访问和解码图像的速度。在 Node.js 上将图像解码为张量与编码过程非常相似。
Node 提供了解码 BMP、JPG、PNG 甚至 GIF 文件格式的功能。但是,正如您可能期望的那样,还有一个通用的node.decodeImage方法,能够自动进行简单的识别查找和转换。您现在将使用decodeImage,并留下decodeBMP等待您需要时查看。
对于图像的最简单解码是直接将文件传递给命令。为此,您可以使用标准的 Node.js 库fs和path。
这个示例代码依赖于一个名为cake.jpg的文件进行加载和解码为张量。此演示中使用的代码和图像资源可在 GitHub 的第四章chapter4/node/node-decode中找到。
import * as tf from '@tensorflow/tfjs-node'
import * as fs from 'fs'
import * as path from 'path'
const FILE_PATH = 'files'
const cakeImagePath = path.join(FILE_PATH, 'cake.jpg')
const cakeImage = fs.readFileSync(cakeImagePath) // ①
tf.tidy(() => {
const cakeTensor = tf.node.decodeImage(cakeImage) // ②
console.log(`Success: local file to a ${cakeTensor.shape} tensor`)
const cakeBWTensor = tf.node.decodeImage(cakeImage, 1) // ③
console.log(`Success: local file to a ${cakeBWTensor.shape} tensor`)
})
①
您使用文件系统库将指定的文件加载到内存中。
②
您将图像解码为与导入图像的颜色通道数量相匹配的张量。
③
您将此图像解码为灰度张量。
正如我们之前提到的,解码过程还允许解码 GIF 文件。一个明显的问题是,“GIF 的哪一帧?”为此,您可以选择所有帧或动画 GIF 的第一帧。node.decodeImage方法有一个标志,允许您确定您的偏好。
注意
物理学家经常争论第四维是时间还是不是时间。不管关于 4D 闵可夫斯基时空是否是现实的争论,对于动画 GIF 来说,这是一个已被证明的现实!为了表示动画 GIF,您使用一个四阶张量。
这个示例代码解码了一个动画 GIF。您将要使用的示例 GIF 是一个 500 x 372 的动画 GIF,有 20 帧:
const gantCakeTensor = tf.node.decodeImage(gantCake, 3, 'int32', true)
console.log(`Success: local file to a ${gantCakeTensor.shape} tensor`)
对于node.decodeImage参数,您提供图像数据,接着是三个颜色通道,作为一个int32结果张量,最后一个参数是true。
传递true让方法知道展开动画 GIF 并返回一个 4D 张量,而false会将其剪裁为 3D。
我们的结果张量形状,正如您可能期望的那样,是[20, 372, 500, 3]。
常见的图像修改
将图像导入张量进行训练是强大的,但很少是直接的。当图像用于机器学习时,它们通常有一些常见的修改。
常见的修改包括:
-
被镜像以进行数据增强
-
调整大小以符合预期的输入大小
-
裁剪出脸部或其他所需部分
您将在机器学习中执行许多这些操作,并且您将在接下来的两章中看到这些技能被使用。第十二章的毕业项目将大量依赖这项技能。让我们花点时间来实现一些这些日常操作,以完善您对图像张量的舒适度。
镜像图像张量
如果您正在尝试训练一个识别猫的模型,您可以通过镜像您现有的猫照片来使数据集翻倍。微调训练图像以增加数据集是一种常见做法。
要为图像翻转张量数据,您有两个选项。一种是以一种方式修改图像张量的数据,使图像沿宽度轴翻转。另一种方法是使用tf.image.flipLeftRight,这通常用于图像批次。让我们两者都做一下。
要翻转单个图像,您可以使用tf.reverse并指定您只想翻转包含图像宽度像素的轴。正如您已经知道的,这是图像的第二个轴,因此您将传递的索引是1。
在本章的相应源代码中,您显示一幅图像,然后在旁边的画布上镜像该图像。您可以在 GitHub 的simple/simple-image-manipulation/mirror.html中访问此示例。此操作的完整代码如下:
// Simple Tensor Flip
const lemonadeImage = document.getElementById("lemonade");
const lemonadeCanvas = document.getElementById("lemonadeCanvas");
const lemonadeTensor = tf.browser.fromPixels(lemonadeImage);
const flippedLemonadeTensor = tf.reverse(lemonadeTensor, 1) // ①
tf.browser.toPixels(flippedLemonadeTensor, lemonadeCanvas).then(() => {
lemonadeTensor.dispose();
flippedLemonadeTensor.dispose();
})
①
reverse 函数将轴索引1翻转以反转图像。
因为您了解底层数据,将此转换应用于您的图像是微不足道的。您可以尝试沿高度或甚至 RGB 轴翻转。任何数据都可以被反转。
Figure 4-8 显示了在轴1上使用tf.reverse的结果。

图 4-8。tf.reverse 用于轴设置为 1 的 lemonadeTensor
提示
反转和其他数据操作方法并不局限于图像。您可以使用这些方法来增强非视觉数据集,如井字棋和类似的游戏。
我们还应该回顾另一种镜像图像的方法,因为这种方法可以处理一组图像的镜像,并且在处理图像数据时暴露了一些非常重要的概念。毕竟,我们的目标是尽可能依赖张量的优化,并尽量远离 JavaScript 的迭代循环。
第二种镜像图像的方法是使用tf.image.flipLeftRight。这种方法旨在处理一组图像,并且一组 3D 张量基本上是 4D 张量。对于我们的演示,您将取一张图像并将其制作成一组一张的批次。
要扩展单个 3D 图像的维度,您可以使用tf.expandDims,然后当您想要反转它(丢弃不必要的括号)时,您可以使用tf.squeeze。这样,您可以将 3D 图像移动到 4D 以进行批处理,然后再次缩小。对于单个图像来说,这似乎有点愚蠢,但这是一个很好的练习,可以帮助您理解批处理和张量维度变化的概念。
因此,一个 200 x 200 的 RGB 图像起始为[200, 200, 3],然后您扩展它,实质上使其成为一个堆叠。结果形状变为[1, 200, 200, 3]。
您可以使用以下代码在单个图像上执行tf.image.flipLeftRight:
// Batch Tensor Flip
const cakeImage = document.getElementById("cake");
const cakeCanvas = document.getElementById("cakeCanvas");
const flipCake = tf.tidy(() => {
const cakeTensor = tf.expandDims( // ①
tf
.browser.fromPixels(cakeImage) // ②
.asType("float32") // ③
);
return tf
.squeeze(tf.image.flipLeftRight(cakeTensor)) // ④
.asType("int32"); // ⑤
})
tf.browser.toPixels(flipCake, cakeCanvas).then(() => {
flipCake.dispose();
});
①
张量的维度被扩展。
②
将 3D 图像导入为张量。
③
在撰写本节时,image.flipLeftRight期望图像是一个float32张量。这可能会在未来发生变化。
④
翻转图像批次,然后在完成后将其压缩回 3D 张量。
⑤
image.flipLeftRight返回0-255的值,因此您需要确保发送给browser.toPixels的张量是int32,这样它才能正确渲染。
这比我们使用tf.reverse更复杂一些,但每种策略都有其自身的优点和缺点。在可能的情况下,充分利用张量的速度和巨大计算能力是至关重要的。
调整图像张量的大小
许多 AI 模型期望特定的输入图像尺寸。这意味着当您的用户上传 700 x 900 像素的图像时,模型正在寻找一个尺寸为 256 x 256 的张量。调整图像大小是处理图像输入的核心。
注意
调整图像张量的大小以用于输入是大多数模型的常见做法。这意味着任何与期望输入严重不成比例的图像,如全景照片,当调整大小以用于输入时可能表现糟糕。
TensorFlow.js 有两种优秀的方法用于调整图像大小,并且两者都支持图像批处理:image.resizeNearestNeighbor和image.resizeBilinear。我建议您在进行任何视觉调整时使用image.resizeBilinear,并将image.resizeNearestNeighbor保留用于当图像的特定像素值不能被破坏或插值时。速度上有一点小差异,image.resizeNearestNeighbor比image.resizeBilinear快大约 10 倍,但差异仍然以每次调整的毫秒数来衡量。
直白地说,resizeBilinear会模糊,而resizeNearestNeighbor会像素化,当它们需要为新数据进行外推时。让我们使用这两种方法放大图像并进行比较。您可以在simple/simple-image-manipulation/resize.html中查看此示例。
// Simple Tensor Flip
const newSize = [768, 560] // 4x larger // ①
const littleGantImage = document.getElementById("littleGant");
const nnCanvas = document.getElementById("nnCanvas");
const blCanvas = document.getElementById("blCanvas");
const gantTensor = tf.browser.fromPixels(littleGantImage);
const nnResizeTensor = tf.image.resizeNearestNeighbor( // ②
gantTensor,
newSize,
true // ③
)
tf.browser.toPixels(nnResizeTensor, nnCanvas).then(() => {
nnResizeTensor.dispose();
})
const blResizeTensor = tf.image.resizeBilinear( // ④
gantTensor,
newSize,
true // ⑤
)
const blResizeTensorInt = blResizeTensor.asType('int32') // ⑥
tf.browser.toPixels(blResizeTensorInt, blCanvas).then(() => {
blResizeTensor.dispose();
blResizeTensorInt.dispose();
})
// All done with ya
gantTensor.dispose();
①
将图像大小增加 4 倍,以便您可以看到这两者之间的差异。
②
使用最近邻算法调整大小。
③
第三个参数是alignCorners;请始终将其设置为 true。¹
④
使用双线性算法调整大小。
⑤
始终将此设置为true(参见3)。
⑥
截至目前,resizeBilinear返回一个float32,你需要进行转换。
如果你仔细观察图 4-9 中的结果,你会看到最近邻的像素呈现锐利的像素化,而双线性的呈现柔和的模糊效果。
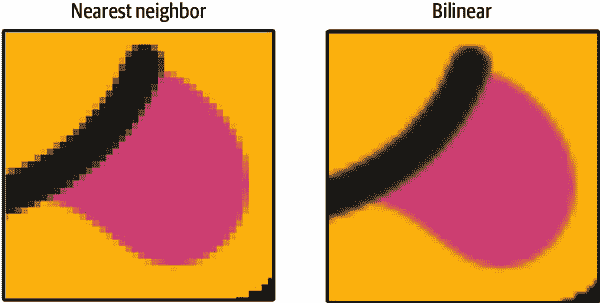
图 4-9. 使用调整大小方法的表情符号(有关图像许可证,请参见附录 C)
警告
使用最近邻算法调整大小可能会被恶意操纵。如果有人知道你最终的图像尺寸,他们可以构建一个看起来只在那个调整大小时不同的邪恶图像。这被称为对抗性预处理。更多信息请参见https://scaling-attacks.net。
如果你想看到鲜明对比,你应该尝试使用两种方法调整本章开头创建的 4 x 3 图像的大小。你能猜到哪种方法会在新尺寸上创建一个棋盘格,哪种方法不会吗?
裁剪图像张量
在我们最后一轮的基本图像张量任务中,我们将裁剪一幅图像。我想指出,就像我们之前的镜像练习一样,有一种适用于批量裁剪大量图像的版本,称为image.cropAndResize。知道这种方法的存在,你可以利用它来收集和规范化图像的部分用于训练,例如,抓取照片中检测到的所有人脸并将它们调整到相同的输入尺寸以供模型使用。
目前,你只需从 3D 张量中裁剪出一些张量数据的简单示例。如果你想象这在空间中,就像从一个更大的矩形蛋糕中切出一个小矩形薄片。
通过给定切片的起始位置和大小,你可以在任何轴上裁剪出你想要的任何部分。你可以在 GitHub 上的simple/simple-image-manipulation/crop.html找到这个例子。要裁剪单个图像,请使用以下代码:
// Simple Tensor Crop
const startingPoint = [0, 40, 0]; // ①
const newSize = [265, 245, 3]; // ②
const lemonadeImage = document.getElementById("lemonade");
const lemonadeCanvas = document.getElementById("lemonadeCanvas");
const lemonadeTensor = tf.browser.fromPixels(lemonadeImage);
const cropped = tf.slice(lemonadeTensor, startingPoint, newSize) // ③
tf.browser.toPixels(cropped, lemonadeCanvas).then(() => {
cropped.dispose();
})
lemonadeTensor.dispose();
①
从下方0像素开始,向右40像素,并且在红色通道上。
②
获取接下来的265像素高度,245像素宽度,以及所有三个 RGB 值。
③
将所有内容传入tf.slice方法。
结果是原始图像的精确裁剪,你可以在图 4-10 中看到。

图 4-10. 使用tf.slice裁剪单个图像张量
新的图像工具
你刚刚学会了三种最重要的图像操作方法,但这并不意味着你的能力有所限制。新的 AI 模型将需要新的图像张量功能,因此,TensorFlow.js 和辅助库不断添加用于处理和处理图像的方法。现在,你可以更加自如地在单个和批量形式中利用和依赖这些工具。
章节回顾
从可编辑张量中编码和解码图像使你能够进行逐像素的操作,这是很少有人能做到的。当然,你已经学会了为了我们在 AI/ML 中的目标而学习视觉张量,但事实上,如果你愿意,你可以尝试各种疯狂的图像操作想法。如果你愿意,你可以做以下任何一种:
-
铺设一个你自己设计的像素图案
-
从另一幅图像中减去一幅图像以进行艺术设计
-
通过操纵像素值在图像中隐藏一条消息
-
编写分形代码或其他数学可视化
-
去除背景图像颜色,就像绿幕一样
在本章中,你掌握了创建、加载、渲染、修改和保存大型结构化数据张量的能力。处理图像张量不仅简单,而且非常有益。你已经准备好迎接任何挑战。
章节挑战:排序混乱
使用您在本章和之前章节学到的方法,您可以用张量做一些非常令人兴奋和有趣的事情。虽然这个挑战没有我能想到的特定实用性,但它是对您所学内容的有趣探索。作为对所学课程的练习,请思考以下问题:
如何生成一个随机的 400 x 400 灰度张量,然后沿一个轴对随机像素进行排序?
如果您完成了这个挑战,生成的张量图像将会像图 4-11 那样。

图 4-11. 沿宽度轴排序的 400 x 400 随机性
您可以使用本书中学到的方法来解决这个问题。如果遇到困难,请查阅TensorFlow.js 在线文档。在文档中搜索关键词将指引您正确方向。
您可以在附录 B 中找到这个挑战的答案。
复习问题
让我们回顾一下您在本章编写的代码中学到的知识。请花点时间回答以下问题:
-
如果一个图像张量包含值0-255,为了正确渲染它需要什么类型的数据?
-
一个 2 x 2 的红色Float32在张量形式中会是什么样子?
-
tf.fill([100, 50, 1], 0.2)会创建什么样的图像张量?
-
真或假:要保存一个 RGBA 图像,您必须使用一个四阶图像张量。
-
真或假:randomUniform如果给定相同的输入,将会创建相同的输出。
-
在浏览器中将图像转换为张量应该使用什么方法?
-
在 Node.js 中对 PNG 进行编码时,第二个参数应该使用什么数字以获得最大压缩?
-
如果您想要将图像张量上下翻转,您该如何做?
-
哪个更快?
-
循环遍历一组图像并调整它们的大小
-
将一组图像作为四阶张量进行批处理并调整整个张量的大小
-
以下结果的秩和大小是多少:
[.keep-together]#`tf.slice(myTensor, [0,0,0], [20, 20, 3])`?#
这些练习的解决方案可以在附录 A 中找到。
¹ TensorFlow 对alignCorners的实现存在错误,可能会有问题。