TensorFlow.js 学习手册(三)
译者:飞龙
第五章:介绍模型
“他从哪里弄来那些美妙的玩具?”
—杰克·尼科尔森(蝙蝠侠)
现在您已经进入大联盟。在第二章中,您访问了一个完全训练好的模型,但您根本不需要了解张量。在这里的第五章,您将能够利用您的张量技能直接与您的模型一起工作,没有训练轮。
最后,您将开始利用大多数机器学习的大脑。模型可能看起来像黑匣子。通常,它们期望特定的张量形状输入,并输出特定的张量形状。例如,假设您已经训练了一个狗或猫分类器。输入可能是一个 32 x 32 的 3D RGB 张量,输出可能是一个从零到一的单个张量值,表示预测。即使您不了解这种设备的内部工作原理,至少使用具有定义结构的模型应该是简单的。
我们将:
-
利用训练好的模型来预测各种答案
-
识别我们现有张量操作技能的好处
-
了解谷歌的 TFHub.dev 托管
-
了解对象定位
-
学习如何叠加边界框以识别图像的某些方面
本章将教您直接访问模型。您不会依赖于可爱的包装库来照顾。如果愿意,您甚至可以围绕现有的 TensorFlow.js 模型编写自己的包装库。掌握了本章的技能,您可以开始将突破性的机器学习模型应用于任何网站。
加载模型
我们知道我们需要将模型加载到内存中,最好是加载到像张量这样的 GPU 加速内存中,但是从哪里加载?作为一种祝福和诅咒,答案是“任何地方!”在软件中加载文件是很常见的,因此在 TensorFlow.js 中有各种答案。
为了加剧这个问题,TensorFlow.js 支持两种不同的模型格式。幸运的是,这些选项的组合并不复杂。您只需要知道需要哪种类型的模型以及从哪里访问它。
目前,TensorFlow.js 中有两种模型类型,每种类型都有其自己的优缺点。最简单且最可扩展的模型称为层模型。这种模型格式允许您检查、修改甚至拆解模型以进行调整。该格式非常适合重新调整和调整。另一种模型格式是图模型。图模型通常更加优化和计算效率更高。使用图模型的成本是模型更加“黑匣子”,由于其优化,更难以检查或修改。
模型类型很简单。如果要加载层模型,您需要使用方法loadLayersModel,如果要加载 GraphDef 模型,则需要使用方法loadGraphModel。这两种模型类型各有利弊,但这超出了本章的范围。关键是加载所需模型类型几乎没有复杂性;只是一个问题是哪种类型,然后使用相应的方法。最重要的方面是第一个参数,即模型数据的位置。
提示
在本书结束时,您将对层模型和图模型类型之间的关键差异有相当扎实的理解。每次引入一个模型时,请注意使用了哪种模型。
本节解释了模型位置的多样性选项以及将它们绑定在一起的简单统一 URI 语法。
通过公共 URL 加载模型
使用公共 URL 加载模型是在 TensorFlow.js 中访问模型的最常见方法。正如您在第二章中记得的那样,当您加载毒性检测模型时,您从公共网络下载了文件的几个片段,每个片段大小为 4 MB,可以缓存。模型知道要下载文件的位置。这是通过单个 URL 到单个文件完成的。最初请求的模型文件是一个简单的 JavaScript 对象表示(JSON)文件,随后的文件是从该 JSON 文件中识别出的神经网络的权重。
从 URL 加载 TensorFlow.js 模型需要主动托管相邻的模型文件(相同的相对文件夹)。这意味着一旦您为模型的 JSON 文件提供路径,它通常会引用同一目录级别的连续文件中的权重。期望的结构如下:
Site
├─── Example Folder
├─── index.html
├─── Model Folder
│ ├─── model.json
│ └─── group1-shard1of3
│ └─── group1-shard2of3
│ └─── group1-shard3of3
...
移动或拒绝访问这些额外文件将导致您的模型无法使用并出现错误。根据服务器环境的安全性和配置,这可能是一个难点。因此,您应始终验证每个文件是否具有适当的 URL 访问权限。
注意
到目前为止,我们已经介绍了三种运行 TensorFlow.js 的主要方法。它们是简单的 200 OK!托管、使用 Parcel 打包的 NPM 和使用 Node.js 托管的服务器。在我们告诉您如何为这些情况正确加载模型之前,您能否确定哪种方法会出现问题?
200 OK!Chrome 的 Web 服务器示例不会出现问题,因为文件夹中的所有内容都是无优化或安全性地托管的。Parcel 为我们提供了一些功能,如转换、错误日志记录、HMR 和捆绑。有了这些功能,我们的 JSON 和权重文件不会被传递到分发文件夹,也就是dist文件夹,除非进行一些调整。
在 Parcel.js 2.0 中(在撰写本文时尚未正式发布),您将有更多选项用于静态文件,但目前,有一个简单的解决方案适用于我们将使用的 Parcel 1.x。您可以安装一个名为parcel-plugin-static-files-copy的插件,以允许本地静态托管模型文件。本书相关存储库中使用的代码利用了这个插件。
该插件通过有效地使放置在static目录中的任何文件从根 URL 公开访问。例如,放置在static/model中的model.json文件将可以作为localhost:1234/model/model.json访问。
无论您使用哪种 Web 解决方案,都需要验证模型文件的安全性和捆绑是否适合您。对于未受保护的公共文件夹,只需将所有文件上传到像 Amazon Web Services(AWS)和 Simple Storage Service(S3)这样的服务即可。您需要使整个存储桶公开,或者每个相邻文件都必须明确公开。验证您可以访问 JSON 和 BIN 文件是很重要的。缺少或受限制的模型片段的错误消息令人困惑。您会看到一个404,但错误会继续到第二个更加难以理解的错误,就像图 5-1 中所示的那样。
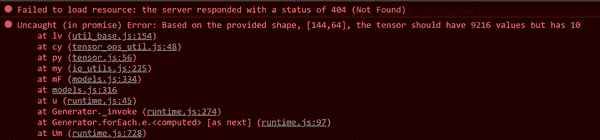
图 5-1. 错误:JSON 可用但没有 bin 文件
提示
Create React App 是一个用于简单 React 网站的流行工具。如果您使用 Create React App,public文件夹中的文件将默认从根 URL 访问。将public视为我们 Parcel 解决方案的static文件夹。两者都非常有效,并已经为模型托管进行了测试。
从其他位置加载模型
模型不必位于公共 URL 中。TensorFlow 有方法允许您从本地浏览器存储、IndexedDB 存储以及在 Node.js 中,本地文件系统访问模型文件。
其中一个重要的好处是,您可以从公共 URL 加载的模型在本地缓存,以便您的应用程序可以脱机准备。其他原因包括速度、安全性,或者仅仅是因为您可以。
浏览器文件
本地浏览器存储和 IndexedDB 存储是两种用于保存指定页面的文件的 Web API。与存储小数据片段(如单个变量)的 cookie 不同,Window.localStorage和 IndexedDB API 是客户端存储,能够处理文件等其他重要结构化数据跨浏览器会话。
公共 URL 具有http和https方案;但是,这些方法在 URI 中使用不同的方案。要从本地存储加载模型,您将使用localstorage://model-name URI,要从 IndexedDB 加载模型,您将使用indexeddb://model-name URI。
除了提供的方法外,您可以存储和检索 TensorFlow.js 模型的位置没有限制。归根结底,您只需要数据,因此您可以使用任何自定义的IOHandler加载模型。例如,甚至已经有将模型完全转换为 JSON 文件的概念验证工作,权重已编码,因此您可以根据需要从任何位置调用require,甚至通过捆绑器。
文件系统文件
要访问文件系统中的文件,您需要使用一个具有权限获取所需文件的 Node.js 服务器。浏览器被沙箱化,目前无法使用此功能。
幸运的是,这与以前的 API 类似。使用file:方案来标识给定文件的路径,就像这样:file://path/to/model.json。就像在浏览器示例中一样,辅助文件必须位于同一文件夹中并且可访问。
我们第一个使用的模型
现在您熟悉了将模型加载到内存的机制,您可以在项目中使用模型。当您在第二章中使用毒性模型时,这对您进行了自动化,但是现在,您熟悉了张量和模型访问,可以处理一个模型,而无需所有保护包代码。
您需要一个简单的模型用于第一个示例。正如您所记得的,您在第三章中将井字棋棋盘编码为练习。让我们从您现有知识的基础上构建,不仅编码一个井字棋比赛,还将该信息传递到训练模型进行分析。训练模型将预测并返回最佳下一步的答案。
本节的目标是询问 AI 模型推荐哪些移动,这些移动在图 5-2 中有所说明。
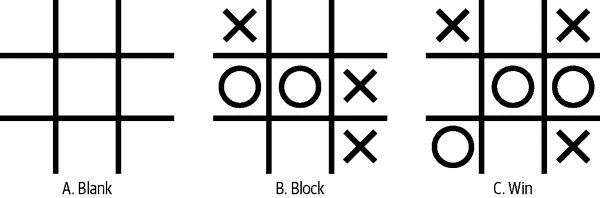
图 5-2。三个游戏状态
这些游戏中的每一个处于不同的情况:
情景 A
这是空白的,允许 AI 进行第一步。
情景 B
现在轮到 O 走棋了,我们期望 AI 通过在右上角的方格中下棋来阻止潜在的失败。
情景 C
现在轮到 X 走棋了,我们期望 AI 在顶部中间移动并取得胜利!
让我们看看 AI 推荐什么,通过对这三种状态进行编码并打印模型的输出。
加载、编码和询问模型
您将使用简单的 URL 来加载模型。这个模型将是一个 Layers 模型。这意味着您将使用tf.loadLayersModel和路径到本地托管模型文件来加载。在本例中,模型文件将托管在model/ttt_model.json。
注意
本示例的训练井字棋模型可以在本书的相关GitHub中访问。JSON 文件大小为 2 KB,权重文件(ttt_model.weights.bin)大小为 22 KB。对于一个井字棋求解器来说,这 24 KB 的负载并不算太大!
为了转录游戏棋盘状态,编码会有一点差异。你需要告诉 AI 它是为哪个团队在玩。你还需要一个可以对 X 和 O 无动于衷的 AI。因为情景 B 是在询问 AI 关于 O 而不是 X 的建议,我们需要一个灵活的编码系统。不要让 X 总是代表 1,将 AI 分配为 1,对手分配为-1。这样我们可以让 AI 处于玩 X 或 O 的情况。表 5-1 显示了查找每种可能值的情况。
表 5-1. 网格到数字的转换
| 棋盘值 | 张量值 | |
|---|---|---|
| AI | 1 | |
| 对手 | -1 | |
| 空 | 0 |
所有三个游戏需要被编码,然后堆叠成一个单一的张量传递给 AI 模型。然后模型提供三个答案,每种情况一个。
这是完整的过程:
-
加载模型。
-
编码三个单独的游戏状态。
-
将状态堆叠成一个单一的张量。
-
要求模型打印结果。
将输入堆叠到模型是一种常见的做法,可以让你的模型处理加速内存中的任意数量的预测。
堆叠增加了结果的维度。在 1D 张量上执行这个操作会创建一个 2D 张量,依此类推。在这种情况下,你有三个用 1D 张量表示的棋盘状态,所以堆叠它们将创建一个[3, 9]的二阶张量。大多数模型支持对它们的输入进行堆叠或批处理,输出将类似地堆叠,并与输入索引匹配的答案。
这段代码可以在 GitHub 仓库的chapter5/simple/simple-ttt-model找到,看起来是这样的:
tf.ready().then(() => { // ①
const modelPath = "model/ttt_model.json" // ②
tf.tidy(() => {
tf.loadLayersModel(modelPath).then(model => { // ③
// Three board states
const emptyBoard = tf.zeros([9]) // ④
const betterBlockMe = tf.tensor([-1, 0, 0, 1, 1, -1, 0, 0, -1]) // ⑤
const goForTheKill = tf.tensor([1, 0, 1, 0, -1, -1, -1, 0, 1]) // ⑥
// Stack states into a shape [3, 9]
const matches = tf.stack([emptyBoard, betterBlockMe, goForTheKill]) // ⑦
const result = model.predict(matches) // ⑧
// Log the results
result.reshape([3, 3, 3]).print() // ⑨
})
})
})
①
使用tf.ready,当 TensorFlow.js 准备好时解析。不需要 DOM 访问。
②
虽然模型是两个文件,但只需要识别 JSON 文件。它了解并加载任何额外的模型文件。
③
loadLayersModel模型解析为完全加载的模型。
④
一个空棋盘是九个零,代表情景 A。
⑤
编码为 X 等于-1代表情景 B。
⑥
编码为 X 等于1代表情景 C。
⑦
使用tf.stack将三个 1D 张量组合成一个 2D 张量。
⑧
使用.predict来要求模型识别最佳的下一步。
⑨
原始输出将被形状化为[3, 9],但这是一个很好的情况,通过重新塑造输出使其更易读。打印结果在三个 3 x 3 的网格中,这样我们可以像游戏棋盘一样阅读它们。
警告
当使用loadLayersModel甚至loadGraphModel时,TensorFlow.js 库依赖于fetch web API 的存在。如果在 Node.js 中使用这种方法,你需要使用像node-fetch这样的包来填充fetch。
前述代码成功地将三场比赛转换为 AI 模型期望的张量格式,并通过模型的predict()方法运行这些值进行分析。结果将打印到控制台,并看起来像我们在图 5-3 中看到的样子。
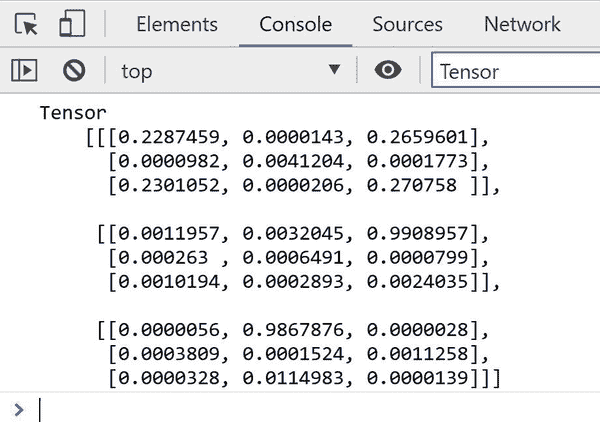
图 5-3. 我们代码生成的结果为[3, 3, 3]形状的张量
这个神奇的方法是模型的predict()函数。该函数让模型知道为给定的输入生成输出预测。
解释结果
对于一些人来说,这个结果张量完全有意义,对于其他人,你可能需要一点上下文。结果再次是下一步最佳移动的概率。最高的数字获胜。
为了得到一个正确的概率,答案需要相加得到 100%,而它们确实相加得到了。让我们看看在这里显示的空井字棋板结果在情景 1 中:
[
[0.2287459, 0.0000143, 0.2659601],
[0.0000982, 0.0041204, 0.0001773],
[0.2301052, 0.0000206, 0.270758 ]
],
如果你像我这样傻乎乎地把这九个值输入到你的计算器(TI-84 Plus CE 永远是我的最爱!),它们会相加得到数字 1。这意味着每个对应的值都是该位置的百分比投票。我们可以看到四个角都有一个显著(接近 25%)的结果。这是有道理的,因为在井字棋中,从一个角开始是最好的策略,其次是中间,它有次高的价值。
因为底部右侧有 27%的投票,这将是 AI 最有可能的移动。让我们看看 AI 在另一个情景中的表现。如果你还记得,在图 5-2 的情景 B 中,AI 需要移动到右上角来阻止。AI 的结果张量在情景 2 中显示:
[
[0.0011957, 0.0032045, 0.9908957],
[0.000263 , 0.0006491, 0.0000799],
[0.0010194, 0.0002893, 0.0024035],
],
顶部右侧的值为 99%,所以模型正确地阻止了给定的威胁。机器学习模型的一个有趣之处是其他移动仍然有值,包括已经被占据的空格。
最后一个情景是一个编码的张量,用来查看模型是否能够获胜井字棋。预测批次的结果在情景 3 中显示:
[
[0.0000056, 0.9867876, 0.0000028],
[0.0003809, 0.0001524, 0.0011258],
[0.0000328, 0.0114983, 0.0000139]
],
结果是 99%(四舍五入)确定顶部中间是最佳移动,这是正确的。其他移动甚至都不接近。所有三个预测结果似乎不仅是有效的移动,而且是给定状态下的正确移动。
你已经成功地加载并与一个模型进行交互,让它提供结果。凭借你刚刚获得的技能,你可以编写自己的井字棋游戏应用。我想互联网上对井字棋游戏的需求不会很大,但如果提供了相同结构的训练模型,你可以使用 AI 制作各种游戏!
提示
大多数模型都会有一些相关的文档,帮助你识别正确的输入和输出,但 Layers 模型有一些属性,如果需要帮助,你可以访问这些属性。期望的输入形状可以在model.input.shape中看到,输出可以在model.outputShape中看到。这些属性在 Graph 模型上不存在。
清理棋盘后
在这个例子中,TensorFlow.js 模型被包装在一个tidy中,并且在代码完成后会自动释放内存。在大多数情况下,你不会这么快完成你的模型。重要的是要注意,你必须像处理张量一样调用.dispose()来处理模型。模型被加速处理方式相同,因此它们有相同的清理成本。
重新加载网页通常会清除张量,但长时间运行的 Node.js 服务器将不得不监视和验证张量和模型是否被处理。
我们的第一个 TensorFlow Hub 模型
现在你已经正确地编码、加载和处理了少量数据通过一个自定义模型,你应该花一点时间挑战自己。在这一部分,你将加载一个规模更大的模型从 TensorFlow Hub,并处理一张图片。井字棋是九个值的输入,而大多数图片是包含数千个值的张量。
你将要加载的模型是目前最大和最令人印象深刻的模型之一,Inception v3。Inception 模型是一个令人印象深刻的网络,最初在 2015 年创建。这第三个版本已经训练了数十万张图片。这个模型有 91.02 MB,可以对 1,001 种不同的对象进行分类。来自第二章的 Chapter Challenge 中的 MobileNet-wrapped NPM 包很棒,但不像你即将使用的模型那样强大。
探索 TFHub
Google 已经开始免费托管像 Inception v3 这样的模型在其自己的 CDN 上。对于这种大型模型大小的情况,拥有一个可靠且令人印象深刻的版本化 CDN 对于像我们经常为 JavaScript 做的模型非常有用。您可以在 https://tfhub.dev 上访问数百个经过训练并准备就绪的 TensorFlow 和 TensorFlow.js 模型。TensorFlow.js 有一种特殊的方式来识别您的模型是否托管在 TFHub 上;我们只需在确定了模型 URL 后,在配置中添加 { fromTFHub: true }。
当您浏览 TFHub 时,您可以看到各种发布者和每个模型的解释。这些解释很关键,因为正如我们已经确定的那样,模型对于输入和输出的期望是非常具体的。您可以在 与 Inception v3 相关的 TFHub 页面 上了解更多信息。这个模型是由 Google 构建的,提供的版本经过了广泛的训练。如果您渴望获取更多信息,不妨浏览一下 关于该模型的发表论文。
在 TFHub 页面上,您可以获得使用模型的这两个关键见解。首先,预期的输入图片尺寸应为 299 x 299,值应为 0-1,并且应该像我们在之前的井字棋示例中一样进行批处理。其次,模型返回的结果是一个具有 1,001 个值的单维张量,最大的值最有可能(类似于井字棋返回的九个值)。这可能听起来有点混乱,但该页面使用了一些基于统计的术语来表达这一点:
输出是一批 logits 向量。Logits 中的索引是原始训练中分类的 num_classes = 1001 个类。
返回一个数值结果是有用的,但是像往常一样,我们需要将其映射回一个有用的标签。在井字棋中,我们将索引映射到棋盘上的位置,而在这种情况下,我们将值的索引映射到相应的标签,这些标签遵循相同的索引。TFHub 页面 分享了一个 TXT 文件,其中包含了所有必要标签的正确顺序,您将使用这些标签创建一个数组来解释预测结果。
连接 Inception v3
现在您知道 Inception v3 模型可以对照片进行分类,并且您已经了解了输入和输出规范。这就像是井字棋问题的一个更大版本。然而,会有新的障碍。例如,打印 1,001 个数字并不会提供有用的信息。您需要使用 topk 将巨大的张量解析回一个有用的上下文中。
以下代码可在 GitHub 仓库的 chapter5/simple/simple-tfhub 文件夹中找到。该代码依赖于一个具有 id mystery 的神秘图片。理想情况下,AI 可以为我们解决这个谜题:
tf.ready().then(() => {
const modelPath =
"https://tfhub.dev/google/tfjs-model/imagenet/inception_v3/classification/3/default/1"; // ①
tf.tidy(() => {
tf.loadGraphModel(modelPath, { fromTFHub: true }).then((model) => { // ②
const mysteryImage = document.getElementById("mystery");
const myTensor = tf.browser.fromPixels(mysteryImage);
// Inception v3 expects an image resized to 299x299
const readyfied = tf.image
.resizeBilinear(myTensor, [299, 299], true) // ③
.div(255) // ④
.reshape([1, 299, 299, 3]); // ⑤
const result = model.predict(readyfied); // ⑥
result.print(); // ⑦
const { values, indices } = tf.topk(result, 3); // ⑧
indices.print(); // ⑨
// Let's hear those winners
const winners = indices.dataSync();
console.log(` 10
First place ${INCEPTION_CLASSES[winners[0]]},
Second place ${INCEPTION_CLASSES[winners[1]]},
Third place ${INCEPTION_CLASSES[winners[2]]}
`);
});
});
});
①
这是 Inception 模型的 TFHub 的 URL。
②
加载图模型并将 fromTFHub 设置为 true。
③
图片被调整为 299 x 299。
④
将 fromPixels 的结果转换为介于 0 和 1 之间的值(对数据进行归一化)。
⑤
将 3D 张量转换为单批次 4D 张量,就像模型期望的那样。
⑥
对图片进行预测。
⑦
打印内容太多被截断了。
⑧
恢复前三个值作为我们的猜测。
⑨
打印前三个预测索引。
⑩
将索引映射到它们的标签并打印出来。INCEPTION_CLASSES 是一个标签数组,映射到模型输出。
在本章的相关代码中,您会发现三幅图片,您可以将其设置为本节中的神秘图片。Inception v3 令人印象深刻地正确识别了所有三幅图片。查看 图 5-4 中捕获的结果。

图 5-4. Inception v3 图像的分类结果
从照片中可以看出,Inception 的第一个选择是“磁带播放器”,我认为这非常准确。其次,它看到了一个“磁带播放器”,老实说我不知道这和“磁带播放器”有什么不同,但我不是超级模型。最后,第三高的值是“收音机”,这就是我会说的。
你通常不需要像这样的大型模型,但随着新模型被添加到 TFHub,你知道你有选择。偶尔浏览现有模型。你会看到很多关于图像分类的模型。对图像进行分类是 AI 入门中比较令人印象深刻的任务之一,但为什么要止步于此呢?
我们的第一个叠加模型
到目前为止,你一直在处理简单的输出模型。井字棋识别你的下一步,Inception 对照片进行分类,为了全面,你将在电影中展示 AI 的经典视觉效果,即在照片中识别物体的边界框。AI 不是对整个照片进行分类,而是在照片中突出显示特定的边界框,就像图 5-5 中那样。

图 5-5. 边界框叠加
通常,模型的边界框输出相当复杂,因为它处理各种类别和重叠框。通常,模型会让你使用一些数学方法来正确清理结果。与其处理这些,不如专注于在 TensorFlow.js 中绘制预测输出中的单个矩形。有时这被称为对象定位。
这个最终练习的模型将是一个宠物脸部检测器。该模型将尽力为我们提供一个边界坐标集,指示它认为宠物脸部位于何处。通常不难说服人们看可爱的狗和猫,但这个模型可能有各种应用。一旦你有了宠物脸部的位置,你可以使用这些数据来训练额外的模型,比如识别宠物或检查它们可爱的鼻子是否需要 boop。你懂的...科学!
定位模型
这个模型是在一个名为Oxford-IIIT 宠物数据集上训练的。这个小巧的、大约 2MB 的模型期望一个 256 x 256 的Float32输入 RGB 宠物图像,并输出四个数字来识别围绕宠物脸部的边界框。1D 张量中的四个数字是左上角点和右下角点。
这些点表示为 0 到 1 之间的值,作为图像的百分比。你可以使用模型结果信息定义一个矩形,如图 5-6 所示。
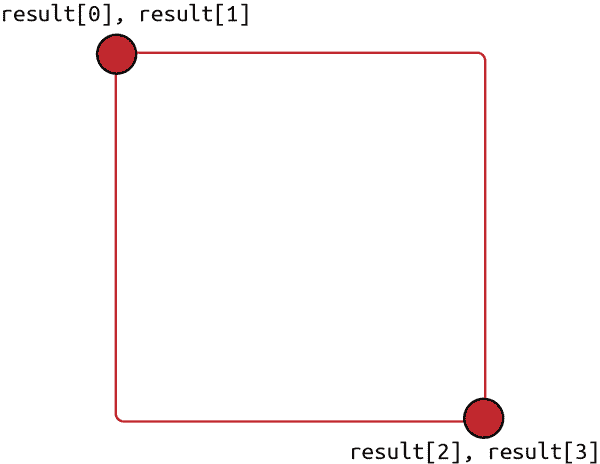
图 5-6. 四个值变成两个点
代码的开头将与之前的代码类似。你将首先将图像转换为张量,然后通过模型运行。以下代码可以在 GitHub 仓库的chapter5/simple/simple-object-localization中找到。
const petImage = document.getElementById("pet");
const myTensor = tf.browser.fromPixels(petImage);
// Model expects 256x256 0-1 value 3D tensor
const readyfied = tf.image
.resizeNearestNeighbor(myTensor, [256, 256], true)
.div(255)
.reshape([1, 256, 256, 3]);
const result = model.predict(readyfied);
// Model returns top left and bottom right
result.print();
标记检测
现在你可以将结果坐标绘制为图像上的矩形。在 TensorFlow.js 中绘制检测是一个常见的任务。在图像上绘制张量结果的基本方法需要你将图像放在一个容器中,然后在图像上方放置一个绝对位置的画布。现在当你在画布上绘制时,你将在图像上绘制。¹ 从侧面看,布局将类似于图 5-7。
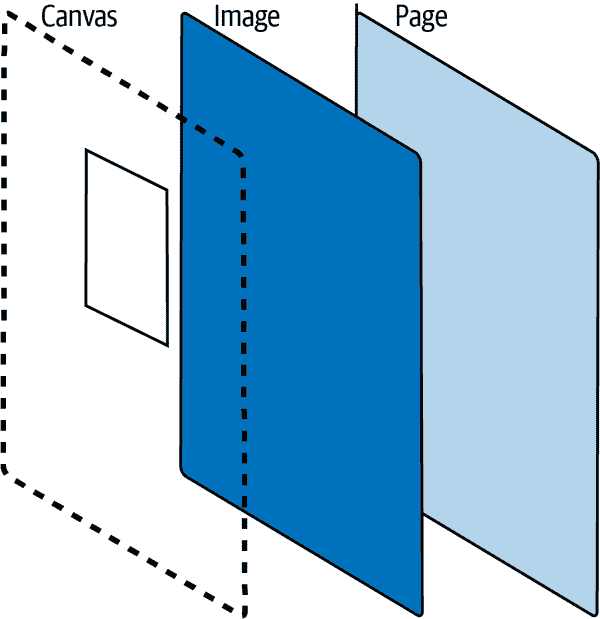
图 5-7. 画布的堆叠视图
对于这节课,CSS 已经直接嵌入到 HTML 中以方便。图像和画布布局如下:
<div style="position: relative; height: 80vh"> <!-- ① -->
<img id="pet" src="/dog1.jpg" height="100%" />
<canvas
id="detection"
style="position: absolute; left: 0;"
><canvas/> <!-- ② -->
</div>
①
包含的div是相对定位的,并且锁定在页面高度的 80%处。
②
画布以绝对位置放置在图像上。
对于简单的矩形,您可以使用画布上下文的strokeRect方法。strokeRect方法不像模型返回的那样需要两个点。它需要一个起点,然后是宽度和高度。要将模型点转换为宽度和高度,您只需减去每个顶点以获得距离。图 5-8 显示了这种计算的可视化表示。
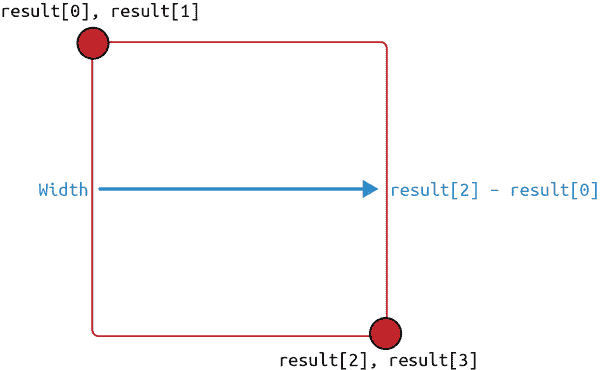
图 5-8。宽度和高度是 X 和 Y 之间的差异计算
使用起点、覆盖矩形的宽度和高度,您可以用几行代码在画布上按比例绘制它。记住,张量输出是一个百分比,需要在每个维度上进行缩放。
// Draw box on canvas
const detection = document.getElementById("detection");
const imgWidth = petImage.width;
const imgHeight = petImage.height;
detection.width = imgWidth; // ①
detection.height = imgHeight;
const box = result.dataSync(); // ②
const startX = box[0] * imgWidth; // ③
const startY = box[1] * imgHeight;
const width = (box[2] - box[0]) * imgWidth; // ④
const height = (box[3] - box[1]) * imgHeight;
const ctx = detection.getContext("2d");
ctx.strokeStyle = "#0F0";
ctx.lineWidth = 4;
ctx.strokeRect(startX, startY, width, height); // ⑤
①
使检测画布与其所覆盖的图像大小相同。
②
获取边界框结果。
③
将起点 X 和 Y 缩放回图像。
④
通过从 X[1]减去 X[2]来找到框的宽度,然后通过图像宽度进行缩放。Y[1]和 Y[2]也是如此。
⑤
现在使用画布的 2D 上下文来绘制所需的矩形。
结果是在给定点处完美放置的边界框。自己看看图 5-9。
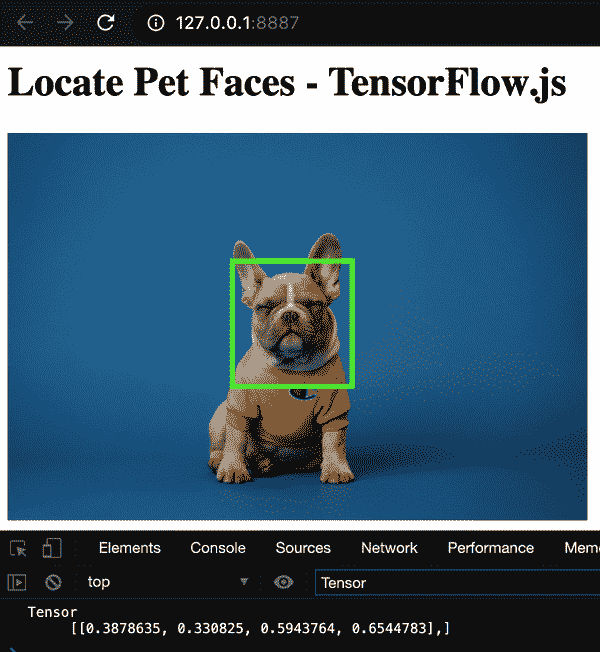
图 5-9。宠物脸部定位
在运行此项目时的一个误解可能是您经历的检测和绘制很慢。这是错误的。很明显,当页面加载时,边界框出现之前会有延迟;然而,您正在经历的延迟包括加载模型并将其加载到某种加速内存中(有时称为模型预热)。尽管这有点超出了本章的目标,但如果您调用model.predict并再次绘制,您会在微秒内看到结果。您在本节中创建的画布+TensorFlow.js 结构可以轻松支持桌面计算机上每秒 60 帧以上。
具有大量边界框和标签的模型使用类似的strokeRect调用来勾画识别对象的位置。有各种各样的模型,它们各自识别图像的各个方面。在 TensorFlow.js 世界中,修改画布以在图像上绘制信息的实践非常有用。
章节回顾
了解模型的输入和输出是关键。在本章中,您最终看到了数据的全部过程。您转换了输入,将其传递给经过训练的模型,并解释了结果。模型可以接受各种各样的输入并提供同样广泛的输出。现在,无论模型需要什么,您都有一些令人印象深刻的经验可以借鉴。
章节挑战:可爱的脸
想象一下,我们的宠物脸部定位是更大过程中的第一步。假设您正在识别宠物脸部,然后将宠物脸部传递给另一个模型,该模型将寻找舌头以查看宠物是否发热和喘气。通常会像这样在管道中组织多个模型,每个模型都调整到自己特定的目的。
根据上一段代码中宠物脸部的位置,编写额外的代码来提取宠物的脸并为需要 96 x 96 图像输入的模型做准备。您的答案将是一个批量裁剪,如图 5-10。

图 5-10。目标[1, 96, 96, 3]张量,只包含脸部
尽管这个练习是为了裁剪宠物的脸以供第二个模型使用,但它也可以很容易地成为一个“宠物匿名化器”,需要您模糊宠物的脸。浏览器中的人工智能应用是无限的。
你可以在附录 B 中找到这个挑战的答案。
复习问题
让我们回顾一下你在本章编写的代码中学到的教训。花点时间回答以下问题:
-
在 TensorFlow.js 中可以加载哪些类型的模型?
-
你需要知道一个模型被分成了多少个碎片吗?
-
除了公共 URL 之外,还有哪些地方可以加载模型?
-
loadLayersModel返回什么? -
如何清除已加载模型的内存?
-
Inception v3 模型的预期输入形状是什么?
-
使用哪个画布上下文方法可以绘制一个空矩形?
-
从 TFHub 加载模型时,你必须向加载方法传递哪个参数?
这些问题的解决方案可以在附录 A 中找到。
¹ 你不一定要使用画布;如果你愿意,你可以移动一个 DOM 对象,但是画布提供了简单和复杂的动画,速度很快。
第六章:高级模型和 UI
“做到之前总是看似不可能。”
—纳尔逊·曼德拉
您已经有了理解模型的基线。您已经消化和利用了模型,甚至在叠加中显示了结果。看起来可能无限制。但是,您已经看到模型往往以各种复杂的方式返回信息。对于井字棋模型,您只想要一个移动,但它仍然返回所有九个可能的框,留下了一些清理工作,然后您才能利用模型的输出。随着模型变得更加复杂,这个问题可能会加剧。在本章中,我们将选择一个广泛和复杂的模型类型进行对象检测,并通过 UI 和概念来全面了解可能遇到的任务。
让我们回顾一下您当前的工作流程。首先,您选择一个模型。确定它是一个 Layers 模型还是 Graph 模型。即使您没有这些信息,您也可以通过尝试以某种方式加载它来弄清楚。
接下来,您需要确定模型的输入和输出,不仅是形状,还有数据实际代表的内容。您批处理数据,对模型调用predict,然后输出就可以了,对吗?
不幸的是,您还应该知道一些其他内容。一些最新和最伟大的模型与您所期望的有显著差异。在许多方面,它们要优越得多,但在其他方面,它们更加繁琐。不要担心,因为您已经在上一章中建立了张量和画布叠加的坚实基础。通过一点点指导,您可以处理这个新的高级模型世界。
我们将:
-
深入了解理论如何挑战您的张量技能
-
了解高级模型特性
-
学习许多新的图像和机器学习术语
-
确定绘制多个框以进行对象检测的最佳方法
-
学习如何在画布上为检测绘制标签
当您完成本章时,您将对实现高级 TensorFlow.js 模型的理论要求有深刻的理解。本章作为对您今天可以使用的最强大模型之一的认知演练,伴随着大量的学习。这不会很难,但请做好学习准备,并不要回避复杂性。如果您遵循本章中解释的逻辑,您将对机器学习的核心理论和实践有深刻的理解和掌握。
再谈 MobileNet
当您在TFHub.dev上浏览时,您可能已经看到我们的老朋友 MobileNet 以许多不同的风格和版本被提及。一个版本有一个简单的名字,ssd_mobilenet_v2,用于图像对象检测(请参见图 6-1 中的突出显示部分)。
多么令人兴奋!看起来您可以从之前的 TensorFlow Hub 示例中获取代码,并将模型更改为查看一组边界框及其相关类,对吗?
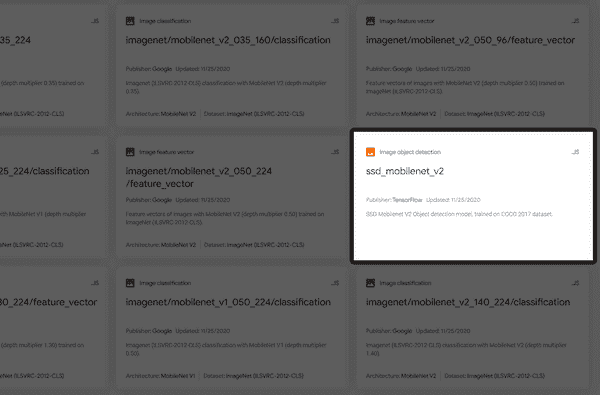
图 6-1. 用于对象检测的 MobileNet
这样做后,您立即收到一个失败消息,要求您使用model.executeAsync而不是model.predict(请参见图 6-2)。
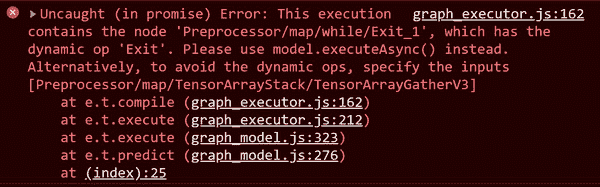
图 6-2. 预测不起作用
那么出了什么问题?到目前为止,您可能有一大堆问题。
-
模型想要的
executeAsync是什么? -
为什么这个 MobileNet 模型用于对象检测?
-
为什么这个模型规范不关心输入大小?
-
“SSD”在机器学习中的名称中代表什么?
警告
在 Parcel 中,您可能会收到关于regeneratorRuntime未定义的错误。这是由于 Babel polyfill 中的弃用。如果您遇到此错误,您可以添加core-js和regenerator-runtime包并在主文件中导入它们。如果您遇到此问题,请参见本章的相关GitHub 代码。
这是一个需要更多信息、理论和历史来理解的高级模型的完美例子。现在也是学习一些我们为方便起见而保留的概念的好时机。通过本章的学习,您将准备好处理一些新术语、最佳实践和复杂模型的特性。
SSD MobileNet
到目前为止,书中已经提到了两种模型的名称,但没有详细说明。MobileNet 和 Inception 是由谷歌 AI 团队创建的已发布的模型架构。在下一章中,您将设计自己的模型,但可以肯定地说,它们不会像这两个知名模型那样先进。每个模型都有一组特定的优点和缺点。准确性并不总是模型的唯一度量标准。
MobileNet 是一种用于低延迟、低功耗模型的特定架构。这使得它非常适合设备和网络。尽管基于 Inception 的模型更准确,但 MobileNet 的速度和尺寸使其成为边缘设备上分类和对象检测的标准工具。
查看由谷歌发布的性能和延迟图表,比较设备上的模型版本。您可以看到,尽管 Inception v2 的大小是 MobileNetV2 的几倍,需要更多计算才能进行单个预测,但 MobileNetV2 速度更快,虽然准确性不如 Inception,但仍然接近。MobileNetV3 甚至有望在尺寸略微增加的情况下更准确。这些模型的核心研究和进展使它们成为经过良好测试的资源,具有已知的权衡。正是因为这些原因,您会看到相同的模型架构在新问题中反复使用。
前面提到的这两种架构都是由谷歌用数百万张图片进行训练的。MobileNet 和 Inception 可以识别的经典 1,001 类来自一个名为ImageNet的知名数据集。因此,在云中的许多计算机上进行长时间训练后,这些模型被调整为立即使用。虽然这些模型是分类模型,但它们也可以被重新用于检测对象。
就像建筑物一样,模型可以稍作修改以处理不同的目标。例如,一个剧院可以从最初用于举办现场表演的目的进行修改,以便支持 3D 特色电影。是的,需要进行一些小的更改,但整体架构是可以重复使用的。对于从分类到对象检测重新用途的模型也是如此。
有几种不同的方法可以进行对象检测。一种方法称为基于区域的卷积神经网络(R-CNN)。不要将 R-CNN 与 RNN 混淆,它们是完全不同的,是机器学习中的真实事物。基于区域的卷积神经网络听起来可能像《哈利波特》中的咒语,但实际上只是通过查看图像的补丁来检测对象的一种流行方法,使用滑动窗口(即重复采样图像的较小部分,直到覆盖整个图像)。R-CNN 通常速度较慢,但非常准确。慢速方面与网站和移动设备不兼容。
检测对象的第二种流行方法是使用另一个时髦词汇,“完全卷积”方法(有关卷积的更多信息,请参阅第十章)。这些方法没有深度神经网络,这就是为什么它们避免需要特定的输入尺寸。没错,您不需要为完全卷积方法调整图像大小,而且它们也很快。
这就是 SSD MobileNet 中的“SSD”之所以重要的地方。它代表单次检测器。是的,您和我可能一直在想固态驱动器,但命名事物可能很困难,所以我们将数据科学放过。SSD 模型类型被设计为完全卷积模型,一次性识别图像的特征。这种“单次检测”使 SSD 比 R-CNN 快得多。不深入细节,SSD 模型有两个主要组件,一个骨干模型,它了解如何识别对象,以及一个SSD 头部,用于定位对象。在这种情况下,骨干是快速友好的 MobileNet。
结合 MobileNet 和 SSD 需要一点魔法,称为控制流,它允许您在模型中有条件地运行操作。这就是使predict方法从简单变得需要异步调用executeAsync的原因。当模型实现控制流时,同步的predict方法将无法工作。
条件逻辑通常由本地语言处理,但这会显著减慢速度。虽然大多数 TensorFlow.js 可以通过利用 GPU 或 Web Assembly(WASM)后端进行优化,但 JavaScript 中的条件语句需要卸载优化张量并重新加载它们。SSD MobileNet 模型为您隐藏了这个头疼的问题,只需使用控制流操作的低成本。虽然实现控制流超出了本书的范围,但使用这些高级功能的模型并不是。
由于这个模型的现代性,它不是为处理图像批次而设置的。这意味着输入的唯一限制不是图像大小,而是批量大小。但是,它确实期望一个批量为 1,因此一个 1,024×768 的 RGB 图像将以[1, 768, 1024, 3]的形式输入到该模型中,其中1是批量的堆栈大小,768是图像高度,1024是图像宽度,3是每个像素的 RGB 值。
深入了解您将处理的输入和输出类型非常重要。值得注意的是,模型的输出边界框遵循输入的经典高度和宽度架构,与宠物面部检测器不同。这意味着边界框将是[y1, x1, y2, x2]而不是[x1, y1, x2, y2]。如果不注意到这些小问题,可能会非常令人沮丧。您的边界框看起来会完全错乱。每当您实现一个新模型时,重要的是您从所有可用的文档中验证规范。
在深入代码之前还有一个注意事项。根据我的经验,生产中的目标检测很少用于识别成千上万种不同的类别,就像您在 MobileNet 和 Inception 中看到的那样。这样做有很多很好的理由,因此目标检测通常在少数类别上进行测试和训练。人们用于目标检测训练的一个常见组标记数据是Microsoft Common Objects in Context(COCO)数据集。这个 SSD MobileNet 使用了该数据集来教会模型看到 80 种不同的类别。虽然 80 种类别比 1,001 种可能的类别要少很多,但仍然是一个令人印象深刻的集合。
现在您对 SSD MobileNet 的了解比大多数使用它的人更多。您知道它是一个使用控制流将 MobileNet 速度与 80 个类别的 SSD 结果联系起来的目标检测模型。这些知识将帮助您以后解释模型的结果。
边界框输出
现在您了解了模型,可以获得结果。在这个模型中,executeAsync返回的值是两个张量堆栈的普通 JavaScript 数组。第一个张量堆栈是检测到的内容,第二个张量堆栈是每个检测的边界框堆栈,换句话说,分数和它们的框。
阅读模型输出
你可以通过几行代码查看图像的结果。以下代码就是这样做的,也可以在本章的源代码中找到:
tf.ready().then(() => {
const modelPath =
"https://tfhub.dev/tensorflow/tfjs-model/ssd_mobilenet_v2/1/default/1"; // '// ①
tf.tidy(() => {
tf.loadGraphModel(modelPath, { fromTFHub: true }).then((model) => {
const mysteryImage = document.getElementById("mystery");
const myTensor = tf.browser.fromPixels(mysteryImage);
// SSD Mobilenet batch of 1
const singleBatch = tf.expandDims(myTensor, 0); // ②
model.executeAsync(singleBatch).then((result) => {
console.log("First", result[0].shape); // ③
result[0].print();
console.log("Second", result[1].shape); // ④
result[1].print();
});
});
});
});
①
这是 JavaScript 模型的 TFHub URL。
②
输入在秩上扩展为一个批次,形状为[1, 高度, 宽度, 3]。
③
得到的张量是[1, 1917, 90],其中返回了 1,917 个检测结果,每行中的 90 个概率值加起来为 1。
④
张量的形状为[1, 1917, 4],为 1,917 个检测提供了边界框。
图 6-3 显示了模型的输出。
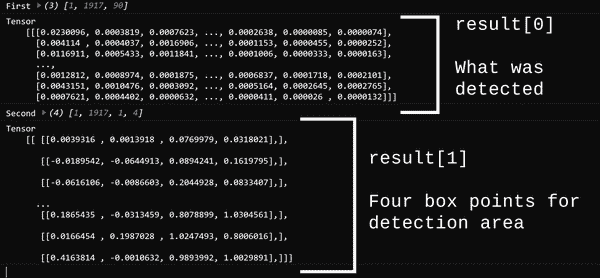
图 6-3。前一段代码的输出
注
你可能会惊讶地看到 90 个值而不是 80 个可能的类别。仍然只有 80 个可能的类别。该模型中的十个结果索引未被使用。
虽然看起来你已经完成了,但还有一些警告信号。正如你可能想象的那样,绘制 1,917 个边界框不会有用或有效,但是尝试一下看看。
显示所有输出
是时候编写代码来绘制多个边界框了。直觉告诉我们,1,917 个检测结果太多了。现在是时候编写一些代码来验证一下了。由于代码变得有点过于依赖 promise,现在是时候切换到 async/await 了。这将阻止代码进一步缩进,并提高可读性。如果你不熟悉在 promise 和 async/await 之间切换,请查看 JavaScript 的相关部分。
绘制模型检测的完整代码可以在书籍源代码文件too_many.html中找到。这段代码使用了与上一章节中对象定位部分描述的相同技术,但参数顺序已调整以适应模型的预期输出。
const results = await model.executeAsync(readyfied);
const boxes = await results[1].squeeze().array();
// Prep Canvas
const detection = document.getElementById("detection");
const ctx = detection.getContext("2d");
const imgWidth = mysteryImage.width;
const imgHeight = mysteryImage.height;
detection.width = imgWidth;
detection.height = imgHeight;
boxes.forEach((box, idx) => {
ctx.strokeStyle = "#0F0";
ctx.lineWidth = 1;
const startY = box[0] * imgHeight;
const startX = box[1] * imgWidth;
const height = (box[2] - box[0]) * imgHeight;
const width = (box[3] - box[1]) * imgWidth;
ctx.strokeRect(startX, startY, width, height);
});
无论模型的置信度如何,绘制每个检测并不困难,但结果输出完全无法使用,如图 6-4 所示。

图 6-4。1,917 个边界框,使图像无用
在图 6-4 中看到的混乱表明有大量的检测结果,但没有清晰度。你能猜到是什么导致了这种噪音吗?导致你看到的噪音有两个因素。
检测清理
对结果边界框的第一个批评是没有质量或数量检查。代码没有检查检测值的概率或过滤最有信心的值。你可能不知道,模型可能只有 0.001%的确信度,那么微小的检测就不值得绘制边界框。清理的第一步是设置检测分数的最小阈值和最大边界框数量。
其次,在仔细检查后,绘制的边界框似乎一遍又一遍地检测到相同的对象,只是略有变化。稍后将对此进行验证。最好是当它们识别出相同类别时,它们的重叠应该受到限制。如果两个重叠的框都检测到一个人,只保留检测分数最高的那个。
模型在照片中找到了东西(或没有找到),现在轮到你来进行清理了。
质量检查
你需要最高排名的预测。你可以通过抑制低于给定分数的任何边界框来实现这一点。通过一次调用topk来识别整个检测系列中的最高分数,如下所示:
const prominentDetection = tf.topk(results[0]);
// Print it to be sure
prominentDetection.indices.print()
prominentDetection.values.print()
对所有检测结果调用topk将返回一个仅包含最佳结果的数组,因为k默认为1。每个检测的索引对应于类别,值是检测的置信度。输出看起来会像图 6-5。

图 6-5。topk调用适用于整个批次
如果显著检测低于给定阈值,您可以拒绝绘制框。然后,您可以限制绘制的框,仅绘制前 N 个预测。我们将把这个练习的代码留给章节挑战,因为它无法解决第二个问题。仅仅进行质量检查会导致在最强预测周围出现一堆框,而不是单个预测。结果框看起来就像您的检测系统喝了太多咖啡(参见图 6-6)。
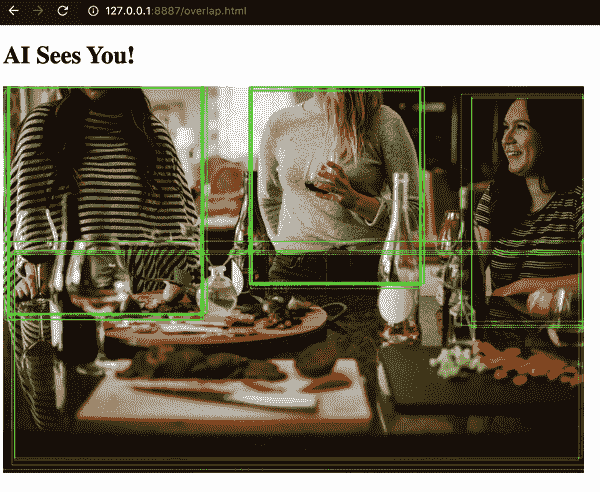
图 6-6。绘制前 20 个预测会产生模糊的边框
幸运的是,有一种内置的方法来解决这些模糊的框,并为您的晚餐派对提供一些新术语。
IoUs 和 NMS
直到现在,您可能认为 IoUs 只是由 Lloyd Christmas 支持的一种获得批准的法定货币,但在目标检测和训练领域,它们代表交集与并集。交集与并集是用于识别对象检测器准确性和重叠的评估指标。准确性部分对于训练非常重要,而重叠部分对于清理重叠输出非常重要。
IoU 是用于确定两个框在重叠中共享多少面积的公式。如果框完全重叠,IoU 为 1,而它们的适合程度越低,数字就越接近零。标题“IoU”来自于这个计算公式。框的交集面积除以框的并集面积,如图 6-7 所示。
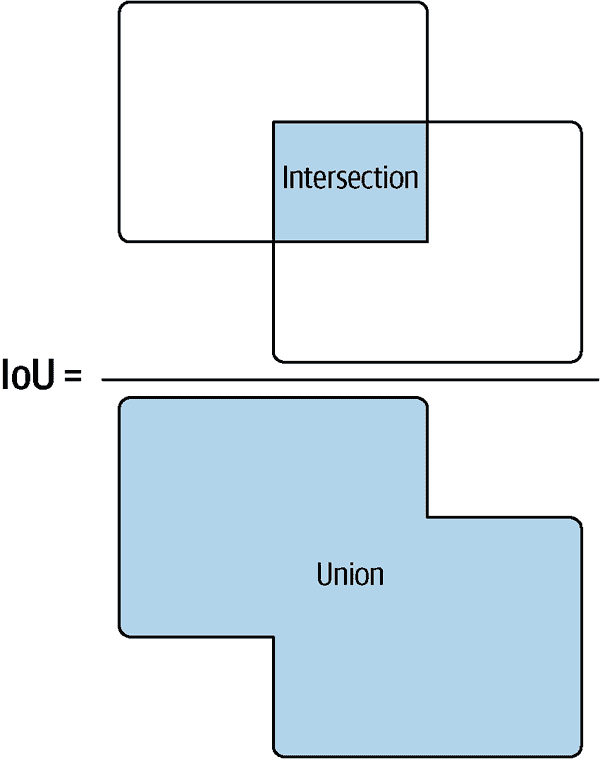
图 6-7。交集与并集
现在您有一个快速的公式来检查边界框的相似性。使用 IoU 公式,您可以执行一种称为非极大值抑制(NMS)的算法来消除重复。NMS 会自动获取得分最高的框,并拒绝任何 IoU 超过指定水平的相似框。图 6-8 展示了一个包含三个得分框的简单示例。
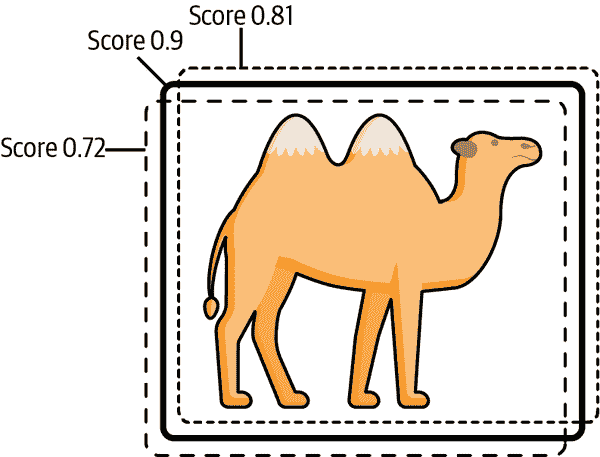
图 6-8。只有最大值存活;其他得分较低的框被移除
如果将 NMS 的 IoU 设置为 0.5,则任何与得分更高的框共享 50%面积的框将被删除。这对于消除与同一对象重叠的框非常有效。但是,对于彼此重叠并应该有两个边界框的两个对象可能会出现问题。这对于具有不幸角度的真实对象是一个问题,因为它们的边界框将相互抵消,您只会得到两个实际对象的一个检测。对于这种情况,您可以启用一个名为Soft-NMS的 NMS 的高级版本,它将降低重叠框的分数而不是删除它们。如果它们在被降低后的分数仍然足够高,检测结果将存活并获得自己的边界框,即使 IoU 非常高。图 6-9 使用 Soft-NMS 正确识别了与极高交集的两个对象。
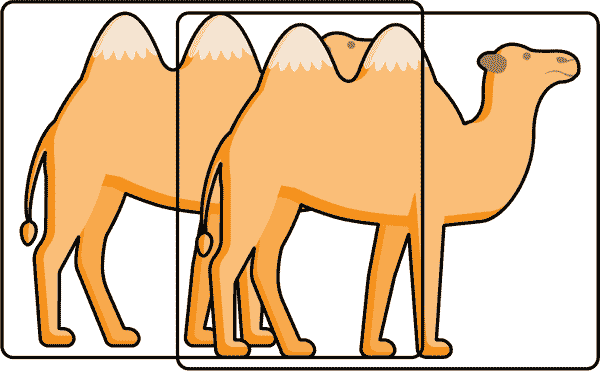
图 6-9。即使是真实世界中重叠的对象也可以使用 Soft-NMS 进行检测
Soft-NMS 最好的部分是它内置在 TensorFlow.js 中。我建议您为所有目标检测需求使用这个 TensorFlow.js 函数。在这个练习中,您将使用内置的方法,名为tf.image.nonMaxSuppressionWithScoreAsync。TensorFlow.js 内置了许多 NMS 算法,但tf.image.nonMaxSuppressionWithScoreAsync具有两个优点,使其非常适合使用:
-
WithScore提供 Soft-NMS 支持。 -
Async可以阻止 GPU 锁定 UI 线程。
在使用非异步高级方法时要小心,因为它们可能会锁定整个 UI。如果出于任何原因想要移除 Soft-NMS 方面,可以将最后一个参数(Soft-NMS Sigma)设置为零,然后您就得到了传统的 NMS。
const nmsDetections = await tf.image.nonMaxSuppressionWithScoreAsync(
justBoxes, // shape [numBoxes, 4]
justValues, // shape [numBoxes]
maxBoxes, // Stop making boxes when this number is hit
iouThreshold, // Allowed overlap value 0 to 1
detectionThreshold, // Minimum detection score allowed
1 // 0 is normal NMS, 1 is max Soft-NMS
);
只需几行代码,您就可以将 SSD 结果澄清为几个清晰的检测结果。
结果将是一个具有两个属性的对象。selectedIndices属性将是一个张量,其中包含通过筛选的框的索引,selectedScores将是它们对应的分数。您可以循环遍历所选结果并绘制边界框。
const chosen = await nmsDetections.selectedIndices.data(); // ①
chosen.forEach((detection) => {
ctx.strokeStyle = "#0F0";
ctx.lineWidth = 4;
const detectedIndex = maxIndices[detection]; // ②
const detectedClass = CLASSES[detectedIndex]; // ③
const detectedScore = scores[detection];
const dBox = boxes[detection];
console.log(detectedClass, detectedScore); // ④
// No negative values for start positions
const startY = dBox[0] > 0 ? dBox[0] * imgHeight : 0; // ⑤
const startX = dBox[1] > 0 ? dBox[1] * imgWidth : 0;
const height = (dBox[2] - dBox[0]) * imgHeight;
const width = (dBox[3] - dBox[1]) * imgWidth;
ctx.strokeRect(startX, startY, width, height);
});
①
从结果中高得分的框的索引创建一个普通的 JavaScript 数组。
②
从先前的topk调用中获取最高得分的索引。
③
将类别作为数组导入以匹配给定的结果索引。这种结构就像上一章中 Inception 示例中的代码一样。
④
记录在画布中被框定的内容,以便验证结果。
⑤
禁止负数,以便框至少从帧开始。否则,一些框将从左上角被切断。
返回的检测数量各不相同,但受限于 NMS 中设置的规格。示例代码导致了五个正确的检测结果,如图 6-10 所示。

图 6-10。干净的 Soft-NMS 检测结果
循环中的控制台日志打印出五个检测结果分别为三个“人”检测、一个“酒杯”和一个“餐桌”。将图 6-11 中的五个日志与图 6-10 中的五个边界框进行比较。
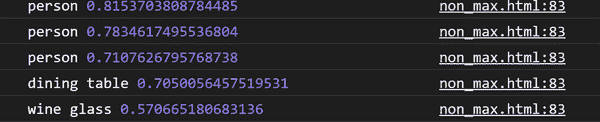
图 6-11。结果日志类别和置信水平
UI 已经取得了很大进展。覆盖层应该能够识别检测和它们的置信度百分比是合理的。普通用户不知道要查看控制台以查看日志。
添加文本覆盖
您可以以各种花式方式向画布添加文本,并使其识别相关的边界框。在此演示中,我们将回顾最简单的方法,并将更美观的布局留给读者作为任务。
可以使用画布 2D 上下文的fillText方法向画布绘制文本。您可以通过重复使用绘制框时使用的X, Y坐标将文本定位在每个框的左上角。
有两个绘制文本时需要注意的问题:
-
文本与背景之间很容易出现低对比度。
-
与同时绘制的框相比,同时绘制的文本可能会被后绘制的框覆盖。
幸运的是,这两个问题都很容易解决。
解决低对比度
创建可读标签的典型方法是绘制一个背景框,然后放置文本。正如您所知,strokeRect创建一个没有填充颜色的框,所以不应该感到意外的是fillRect绘制一个带有填充颜色的框。
矩形应该有多大?一个简单的答案是将矩形绘制到检测框的宽度,但不能保证框足够宽,当框非常宽时,这会在结果中创建大的阻挡条。唯一有效的解决方案是测量文本并相应地绘制框。文本高度可以通过利用上下文font属性来设置,宽度可以通过measureText确定。
最后,您可能需要考虑从绘图位置减去字体高度,以便将文本绘制在框内而不是在框上方,但上下文已经有一个属性可以设置以保持简单。context.textBaseline属性有各种选项。图 6-12 显示了每个可能属性选项的起始点。

图 6-12。将textBaseline设置为top可以保持文本在 X 和 Y 坐标内
现在你知道如何绘制一个填充矩形到适当的大小并将标签放在内部。您可以将这些方法结合在您的forEach循环中,您在其中绘制检测结果。标签绘制在每个检测的左上角,如图 6-13 所示。

图 6-13。标签与每个框一起绘制
重要的是文本在背景框之后绘制,否则框将覆盖文本。对于我们的目的,标签将使用略有不同颜色的绿色绘制,而不是边界框。
// Draw the label background.
ctx.fillStyle = "#0B0";
ctx.font = "16px sans-serif"; // ①
ctx.textBaseline = "top"; // ②
const textHeight = 16;
const textPad = 4; // ③
const label = `${detectedClass} ${Math.round(detectedScore * 100)}%`;
const textWidth = ctx.measureText(label).width;
ctx.fillRect( // ④
startX,
startY,
textWidth + textPad,
textHeight + textPad
);
// Draw the text last to ensure it's on top.
ctx.fillStyle = "#000000"; // ⑤
ctx.fillText(label, startX, startY); // ⑥
①
设置标签使用的字体和大小。
②
设置textBaseline如上所述。
③
添加一点水平填充以在fillRect渲染中使用。
④
使用相同的startX和startY绘制矩形,这与绘制边界框时使用的相同。
⑤
将fillStyle更改为黑色以进行文本渲染。
⑥
最后,绘制文本。这可能也应该略微填充。
现在每个检测都有一个几乎可读的标签。但是,根据您的图像,您可能已经注意到了一些问题,我们现在将解决。
解决绘制顺序
尽管标签是绘制在框的上方,但框是在不同的时间绘制的,可以轻松重叠一些现有标签文本,使它们难以阅读甚至不可能阅读。如您在图 6-14 中所见,由于重叠检测,餐桌百分比很难阅读。

图 6-14。上下文绘制顺序重叠问题
解决这个问题的一种方法是遍历检测结果并绘制框,然后再进行第二次遍历并绘制文本。这将确保文本最后绘制,但代价是需要在两个连续循环中遍历检测结果。
作为替代方案,您可以使用代码处理这个问题。您可以设置上下文globalCompositeOperation来执行各种令人惊奇的操作。一个简单的操作是告诉上下文在现有内容的上方或下方渲染,有效地设置 z 顺序。
strokeRect调用可以设置为globalCompositeOperation为destination-over。这意味着任何存在于目标中的像素将获胜并放置在添加的内容上方。这有效地在任何现有内容下绘制。
然后,在绘制标签时,将globalCompositionOperation返回到其默认行为,即source-over。这会将新的源像素绘制在任何现有绘图上。如果在这两种操作之间来回切换,您可以确保您的标签是最优先的,并在主循环内处理所有内容。
总的来说,绘制边界框、标签框和标签的单个循环如下所示:
chosen.forEach((detection) => {
ctx.strokeStyle = "#0F0";
ctx.lineWidth = 4;
ctx.globalCompositeOperation='destination-over'; // ①
const detectedIndex = maxIndices[detection];
const detectedClass = CLASSES[detectedIndex];
const detectedScore = scores[detection];
const dBox = boxes[detection];
// No negative values for start positions
const startY = dBox[0] > 0 ? dBox[0] * imgHeight : 0;
const startX = dBox[1] > 0 ? dBox[1] * imgWidth : 0;
const height = (dBox[2] - dBox[0]) * imgHeight;
const width = (dBox[3] - dBox[1]) * imgWidth;
ctx.strokeRect(startX, startY, width, height);
// Draw the label background.
ctx.globalCompositeOperation='source-over'; // ②
ctx.fillStyle = "#0B0";
const textHeight = 16;
const textPad = 4;
const label = `${detectedClass} ${Math.round(detectedScore * 100)}%`;
const textWidth = ctx.measureText(label).width;
ctx.fillRect(
startX,
startY,
textWidth + textPad,
textHeight + textPad
);
// Draw the text last to ensure it's on top.
ctx.fillStyle = "#000000";
ctx.fillText(label, startX, startY);
});
①
在任何现有内容下绘制。
②
在任何现有内容上绘制。
结果是一个动态的人类可读结果,您可以与您的朋友分享(参见图 6-15)。

图 6-15。使用destination-over修复重叠问题
连接到网络摄像头
所有这些速度的好处是什么?正如前面提到的,选择 SSD 而不是 R-CNN,选择 MobileNet 而不是 Inception,以及一次绘制画布而不是两次。当你加载页面时,它看起来相当慢。似乎至少需要四秒才能加载和渲染。
是的,把一切都放在适当的位置需要一点时间,但在内存分配完毕并且模型下载完成后,你会看到一些相当显著的速度。是的,足以在你的网络摄像头上运行实时检测。
加快流程的关键是运行设置代码一次,然后继续运行检测循环。这意味着你需要将这节课的庞大代码库分解;否则,你将得到一个无法使用的界面。为简单起见,你可以按照示例 6-1 中所示分解项目。
示例 6-1。分解代码库
async function doStuff() {
try {
const model = await loadModel() // ①
const mysteryVideo = document.getElementById('mystery') // ②
const camDetails = await setupWebcam(mysteryVideo) // ③
performDetections(model, mysteryVideo, camDetails) // ④
} catch (e) {
console.error(e) // ⑤
}
}
①
加载模型时最长的延迟应该首先发生,且仅发生一次。
②
为了效率,你可以一次捕获视频元素,并将该引用传递到需要的地方。
③
设置网络摄像头应该只发生一次。
④
performDetections方法可以在检测网络摄像头中的内容并绘制框时无限循环。
⑤
不要让所有这些awaits吞没错误。
从图像到视频的转换
从静态图像转换为视频实际上并不复杂,因为将所见内容转换为张量的困难部分由tf.fromPixels处理。tf.fromPixels方法可以读取画布、图像,甚至视频元素。因此,复杂性在于将img标签更改为video标签。
你可以通过更换标签来开始。原始的img标签:
<img id="mystery" src="/dinner.jpg" height="100%" />
变成以下内容:
<video id="mystery" height="100%" autoplay></video>
值得注意的是,视频元素的宽度/高度属性稍微复杂,因为有输入视频的宽度/高度和实际客户端的宽度/高度。因此,所有使用width的计算都需要使用clientWidth,同样,height需要使用clientHeight。如果使用错误的属性,框将不对齐,甚至可能根本不显示。
激活网络摄像头
为了我们的目的,我们只会设置默认的网络摄像头。这对应于示例 6-1 中的第四点。如果你对getUserMedia不熟悉,请花点时间分析视频元素如何连接到网络摄像头。这也是你可以将画布上下文设置移动到适应视频元素的时间。
async function setupWebcam(videoRef) {
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
const webcamStream = await navigator.mediaDevices.getUserMedia({ // ①
audio: false,
video: {
facingMode: 'user',
},
})
if ('srcObject' in videoRef) { // ②
videoRef.srcObject = webcamStream
} else {
videoRef.src = window.URL.createObjectURL(webcamStream)
}
return new Promise((resolve, _) => { // ③
videoRef.onloadedmetadata = () => { // ④
// Prep Canvas
const detection = document.getElementById('detection')
const ctx = detection.getContext('2d')
const imgWidth = videoRef.clientWidth // ⑤
const imgHeight = videoRef.clientHeight
detection.width = imgWidth
detection.height = imgHeight
ctx.font = '16px sans-serif'
ctx.textBaseline = 'top'
resolve([ctx, imgHeight, imgWidth]) // ⑥
}
})
} else {
alert('No webcam - sorry!')
}
}
①
这些是网络摄像头用户媒体配置约束。这里可以应用几个选项,但为简单起见,保持得很简单。
②
这个条件检查是为了支持不支持新的srcObject配置的旧浏览器。根据你的支持需求,这可能会被弃用。
③
在视频加载完成之前无法访问视频,因此该事件被包装在一个 promise 中,以便等待。
④
这是你需要等待的事件,然后才能将视频元素传递给tf.fromPixels。
⑤
在设置画布时,注意使用clientWidth而不是width。
⑥
promise 解析后,你将需要将信息传递给检测和绘制循环。
绘制检测结果
最后,您执行检测和绘图的方式与对图像执行的方式相同。在每次调用的开始时,您需要删除上一次调用的所有检测;否则,您的画布将慢慢填满旧的检测。清除画布很简单;您可以使用clearRect来删除指定坐标的任何内容。传递整个画布的宽度和高度将擦除所有内容。
ctx.clearRect(0, 0, ctx.canvas.width, ctx.canvas.height)
在每次绘制检测结束时,不要在清理中处理模型,因为您需要在每次检测中使用它。然而,其他所有内容都可以和应该被处理。
在示例 6-1 中确定的performDetections函数应该在无限循环中递归调用自身。该函数的循环速度可能比画布绘制速度更快。为了确保不浪费循环,使用浏览器的requestAnimationFrame来限制这一点:
// Loop forever
requestAnimationFrame(() => {
performDetections(model, videoRef, camDetails)
})
就是这样。通过一些逻辑调整,您已经从静态图像转移到了实时速度的视频输入。在我的电脑上,我看到大约每秒 16 帧。在人工智能领域,这已经足够快,可以处理大多数用例。我用它来证明我至少是 97%的人,如图 6-16 所示。

图 6-16。具有 SSD MobileNet 的完全功能网络摄像头
章节回顾
祝贺您挑战了 TensorFlow Hub 上存在的最有用但也最复杂的模型之一。虽然用 JavaScript 隐藏这个模型的复杂性很简单,但您现在熟悉了一些最令人印象深刻的物体检测和澄清概念。机器学习背负着快速解决问题的概念,然后解决后续代码以将 AI 的壮丽属性附加到给定领域。您可以期待任何显著先进模型和领域都需要大量研究。
章节挑战:顶级侦探
NMS 简化了排序和消除检测。假设您想解决识别顶级预测然后将它们从高到低排序的问题,以便您可以创建类似图 6-6 的图形。与其依赖 NMS 来找到您最可行和最高值,您需要自己解决最高值问题。将这个小但类似的分组视为整个检测数据集。想象这个[1, 6, 5]的张量检测集合是您的result[0],您只想要具有最高置信度值的前三个检测。您如何解决这个问题?
const t = tf.tensor([[
[1, 2, 3, 4, 5],
[1.1, 2.1, 3.1, 4.1, 5.1],
[1.2, 2.2, 3.2, 4.2, 5.2],
[1.2, 12.2, 3.2, 4.2, 5.2],
[1.3, 2.3, 3.3, 4.3, 5.3],
[1, 1, 1, 1, 1]
]])
// Get the top-three most confident predictions.
您的最终解决方案应该打印[3, 4, 2],因为索引为 3 的张量具有最大值(12.2),其次是索引为 4(包含 5.3),然后是索引为 2(5.2)。
您可以在附录 B 中找到此挑战的答案。
复习问题
让我们回顾您在本章编写的代码中学到的知识。花点时间回答以下问题:
-
在物体检测机器学习领域,SSD 代表什么?
-
您需要使用哪种方法来预测使用动态控制流操作的模型?
-
SSD MobileNet 预测多少类别和多少值?
-
去重相同对象的检测的方法是什么?
-
使用大型同步 TensorFlow.js 调用的缺点是什么?
-
您应该使用什么方法来识别标签的宽度?
-
globalCompositeOperation会覆盖画布上现有的内容吗?
这些问题的解决方案可以在附录 A 中找到。
标签:const,检测,模型,张量,lrn,merge,tfjs,绘制,加载 From: https://www.cnblogs.com/apachecn/p/18011862