TensorFlow.js 学习手册(六)
译者:飞龙
第十一章:迁移学习
“向他人的错误学习。你活不到足够长的时间来犯所有的错误。”
—埃莉诺·罗斯福
拥有大量数据、经过实战检验的模型结构和处理能力可能是具有挑战性的。能不能简单点?在第七章中,您可以使用 Teachable Machine 将训练好的模型的特质转移到新模型中,这是非常有用的。事实上,这是机器学习世界中的一个常见技巧。虽然 Teachable Machine 隐藏了具体细节,只提供了一个模型,但您可以理解这个技巧的原理,并将其应用于各种酷炫的任务。在本章中,我们将揭示这个过程背后的魔法。虽然我们将简单地以 MobileNet 为例,但这可以应用于各种模型。
迁移学习是指将训练好的模型重新用于第二个相关任务。
使用迁移学习为您的机器学习解决方案带来一些可重复的好处。大多数项目出于以下原因利用一定程度的迁移学习:
-
重复使用经过实战检验的模型结构
-
更快地获得解决方案
-
通过较少的数据获得解决方案
在本章中,您将学习几种迁移学习策略。您将专注于 MobileNet 作为一个基本示例,可以以各种方式重复使用来识别各种新类别。
我们将:
-
回顾迁移学习的工作原理
-
看看如何重复使用特征向量
-
将模型切割成层并重构新模型
-
了解 KNN 和延迟分类
完成本章后,您将能够将长时间训练并具有大量数据的模型应用于您自己的需求,即使只有较小的数据集。
迁移学习是如何工作的?
一个经过不同数据训练的模型如何突然对您的新数据起作用?听起来像奇迹,但这在人类中每天都发生。
您花了多年时间识别动物,可能看过数百只骆驼、天竺鼠和海狸的卡通、动物园和广告。现在我将向您展示一种您可能很少见到甚至从未见过的动物。图 11-1 中的动物被称为水豚(Hydrochoerus hydrochaeris)。

图 11-1。水豚
对于你们中的一些人,这可能是第一次(或者是少数几次)看到水豚的照片。现在,看看图 11-2 中的阵容。你能找到水豚吗?

图 11-2。哪一个是水豚?
一张单独的照片的训练集足以让您做出选择,因为您一生中一直在区分动物。即使是新的颜色、角度和照片尺寸,您的大脑可能也能绝对确定地检测到动物 C 是另一只水豚。您多年的经验学习到的特征帮助您做出了明智的决定。同样地,具有丰富经验的强大模型可以被教导从少量新数据中学习新事物。
迁移学习神经网络
让我们暂时回到 MobileNet。MobileNet 模型经过训练,可以识别区分一千种物品之间的特征。这意味着有卷积来检测毛发、金属、圆形物体、耳朵以及各种关键的差异特征。所有这些特征在被压缩和简化之前都被吸收到一个神经网络中,各种特征的组合形成了分类。
MobileNet 模型可以识别不同品种的狗,甚至可以区分马耳他犬和西藏犬。如果您要制作一个“狗还是猫”分类器,那么在您更简单的模型中,大多数这些高级特征是可以重复使用的。
先前学习的卷积滤波器在识别全新分类的关键特征方面非常有用,就像我们在图 11-2 中的水豚示例一样。关键是将模型的特征识别部分提取出来,并将自己的神经网络应用于卷积输出,如图 11-3 所示。
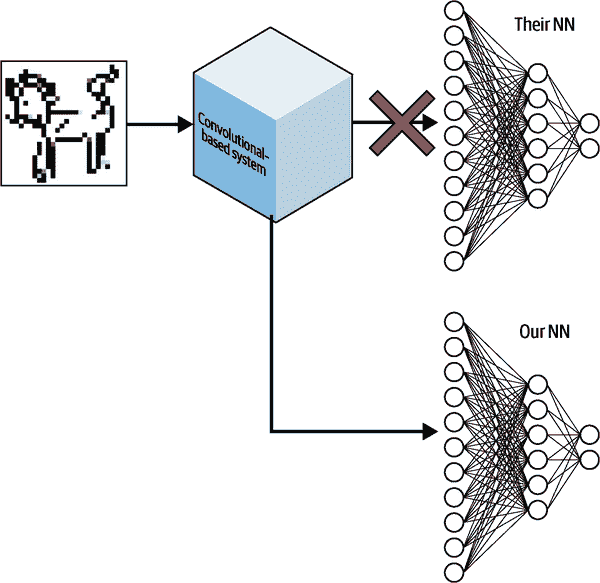
图 11-3。CNN 迁移学习
那么如何分离和重新组合先前训练模型的这些部分呢?您有很多选择。再次,我们将学习更多关于图和层模型的知识。
简单的 MobileNet 迁移学习
幸运的是,TensorFlow Hub已经有一个与任何神经网络断开连接的 MobileNet 模型。它为您提供了一半的模型用于迁移学习。一半的模型意味着它还没有被绑定到最终的 softmax 层来进行分类。这使我们可以让 MobileNet 推导出图像的特征,然后为我们提供张量,然后我们可以将这些张量传递给我们自己训练的网络进行分类。
TFHub 将这些模型称为图像特征向量模型。您可以缩小搜索范围,只显示这些模型,或者通过查看问题域标签来识别它们,如图 11-4 所示。

图 11-4。图像特征向量的问题域标签
您可能会注意到 MobileNet 的小变化,并想知道差异是什么。一旦您了解了一些诡计术语,每个模型描述都会变得非常可读。
例如,我们将使用示例 11-1。
示例 11-1。图像特征向量模型之一
imagenet/mobilenet_v2_130_224/feature_vector
imagenet
这个模型是在 ImageNet 数据集上训练的。
mobilenet_v2
该模型的架构是 MobileNet v2。
130
该模型的深度乘数为 1.30。这会产生更多的特征。如果您想加快速度,可以选择“05”,这将减少一半以下的特征输出并提高速度。这是一个微调选项,当您准备好修改速度与深度时可以使用。
224
该模型的预期输入尺寸为 224 x 224 像素的图像。
feature_vector
我们已经从标签中了解到,但这个模型输出的张量是为了作为图像特征的第二个模型来解释。
现在我们有一个经过训练的模型,可以识别图像中的特征,我们将通过 MobileNet 图像特征向量模型运行我们的训练数据,然后在输出上训练一个模型。换句话说,训练图像将变成一个特征向量,我们将训练一个模型来解释该特征向量。
这种策略的好处是实现起来很简单。主要缺点是当您准备使用新训练的模型时,您将不得不加载两个模型(一个用于生成特征,一个用于解释)。创造性地,可能有一些情况下“特征化”图像然后通过多个神经网络运行可能非常有用。无论如何,让我们看看它的实际效果。
TensorFlow Hub 检查,对手!
我们将使用 MobileNet 进行迁移学习,以识别像图 11-5 中所示的国际象棋棋子。

图 11-5。简单的国际象棋棋子分类器
您只会有每个国际象棋棋子的几张图像。通常这是不够的,但通过迁移学习的魔力,您将得到一个高效的模型。
加载国际象棋图像
为了这个练习,我已经编译了一个包含 150 张图像的集合,并将它们加载到 CSV 文件中以便快速使用。在大多数情况下,我不建议这样做,因为这对于处理和磁盘空间是低效的,但它可以作为一种简单的向量,用于一些快速的浏览器训练。现在加载这些图像的代码是微不足道的。
注意
你可以访问象棋图像和将它们转换为 CSV 文件的代码在chapter11/extra/node-make-csvs文件夹中。
文件 chess_labels.csv 和 chess_images.csv 可以在与本课程相关的chess_data.zip文件中找到。解压这个文件并使用 Danfo.js 加载内容。
许多浏览器可能会在同时读取所有 150 个图像时出现问题,所以我限制了演示只处理 130 个图像。与并发数据限制作斗争是机器学习中常见的问题。
注意
一旦图像被提取特征,它所占用的空间就会少得多。随意尝试批量创建特征,但这超出了本章的范围。
图像已经是 224 x 224,所以你可以用以下代码加载它们:
console.log("Loading huge CSV - this will take a while");
const numImages = 130; // between 1 and 150 // Get Y values const labels = await dfd.read_csv("chess_labels.csv", numImages); // ①
const Y = labels.tensor; // ②
// Get X values (Chess images) const chessImages = await dfd.read_csv("chess_images.csv", numImages);
const chessTensor = chessImages.tensor.reshape([
labels.shape[0], 224, 224, 3, // ③
]);
console.log("Finished loading CSVs", chessTensor.shape, Y.shape);
①
read_csv的第二个参数限制了行数到指定的数字。
②
然后将 DataFrames 转换为张量。
③
图像被展平以变成序列化,但现在被重新塑造成一个四维的 RGB 图像批次。
经过一段时间,这段代码会打印出 130 个准备好的图像和编码的 X 和 Y 形状:
Finished loading CSVs (4) [130, 224, 224, 3] (2) [130, 6]
如果你的计算机无法处理 130 个图像,你可以降低numImages变量,仍然可以继续。然而,CSV 文件的加载时间始终是恒定的,因为整个文件必须被处理。
提示
象棋棋子这样的图像非常适合进行图像增强,因为扭曲棋子永远不会导致一个棋子被误认为是另一个。如果你需要更多的图像,你可以镜像整个集合,有效地将你的数据翻倍。存在整个库来镜像、倾斜和扭曲图像,这样你就可以创建更多数据。
加载特征模型
你可以像加载 TensorFlow Hub 中的任何模型一样加载特征模型。你可以通过模型进行预测,结果将是numImages个预测。代码看起来像示例 11-2。
示例 11-2. 加载和使用特征向量模型
// Load feature model
const tfhubURL =
"https://oreil.ly/P2t2k";
const featureModel = await tf.loadGraphModel(tfhubURL, {
fromTFHub: true,
});
const featureX = featureModel.predict(chessTensor);
// Push data through feature detection
console.log(`Features stack ${featureX.shape}`);
控制台日志的输出是
Features stack 130,1664
每个 130 个图像已经变成了一组 1,664 个浮点值,这些值对图像的特征敏感。如果你改变模型以使用不同的深度,特征的数量也会改变。1,664 这个数字是 MobileNet 1.30 深度版本独有的。
如前所述,1,664 个Float32特征集比每个图像的224*224*3 = 150,528个Float32输入要小得多。这将加快训练速度,并对计算机内存更友好。
创建你自己的神经网络
现在你有了一组特征,你可以创建一个新的完全未经训练的模型,将这 1,664 个特征与你的标签相匹配。
示例 11-3. 一个包含 64 层的小模型,最后一层是 6
// Create NN const transferModel = tf.sequential({
layers: [ // ①
tf.layers.dense({
inputShape: [featureX.shape[1]], // ②
units: 64,
activation: "relu",
}),
tf.layers.dense({ units: 6, activation: "softmax" }),
],
});
①
这个 Layers 模型使用了一个与你习惯的略有不同的语法。而不是调用.add,所有的层都被呈现在初始配置的数组中。这种语法对于像这样的小模型很好。
②
模型的inputShape被动态设置为1,664,以防你想通过更新模型 URL 来改变模型的深度乘数。
训练结果
在训练代码中没有什么新的。模型基于特征输出进行训练。由于特征输出与原始图像张量相比非常小,训练速度非常快。
transferModel.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: ["accuracy"],
});
await transferModel.fit(featureX, Y, {
validationSplit: 0.2,
epochs: 20,
callbacks: { onEpochEnd: console.log },
});
几个周期后,模型的准确率就会非常出色。查看图 11-6。
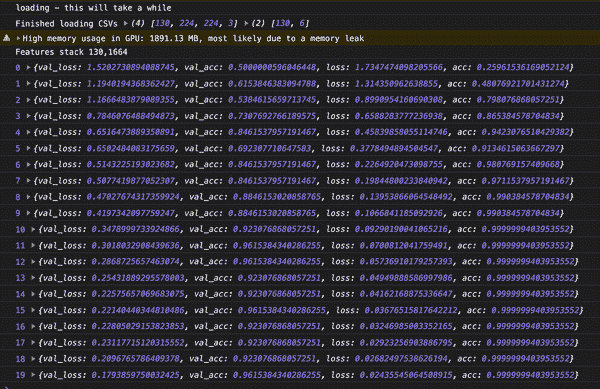
图 11-6. 从 50%到 96%的验证准确率在 20 个周期内
在 TensorFlow Hub 上使用现有模型进行迁移学习可以减轻架构方面的困扰,并为你带来高准确性。但这并不是你实现迁移学习的唯一方式。
利用 Layers 模型进行迁移学习
之前的方法存在一些明显和不那么明显的限制。首先,特征模型无法进行训练。你所有的训练都是在一个消耗图模型特征的新模型上进行的,但卷积层和大小是固定的。你可以使用卷积网络模型的小变体,但无法更新或微调它。
之前来自 TensorFlow Hub 的模型是一个图模型。图模型被优化用于速度,并且无法修改或训练。另一方面,Layers 模型则适用于修改,因此你可以将它们重新连接以进行迁移学习。
此外,在之前的示例中,每次需要对图像进行分类时,实际上都在处理两个模型。你需要加载两个 JSON 模型,并将图像通过特征模型和新模型以对图像进行分类。这并不是世界末日,但通过组合 Layers 模型可以实现单一模型。
让我们再次解决同样的国际象棋问题,但这次使用 Layers 版本的 MobileNet,这样我们可以检查差异。
在 MobileNet 上修剪层
在这个练习中,你将使用一个设置为 Layers 模型的 MobileNet v1.0 版本。这是 Teachable Machine 使用的模型,虽然对于小型探索性项目来说已经足够了,但你会注意到它不如深度为 1.30 的 MobileNet v2 准确。你已经熟悉了使用向导转换模型的方法,就像你在第七章中学到的那样,所以在需要时你可以创建一个更大、更新的 Layers 模型。准确性是一个重要的指标,但在寻找迁移模型时,它远非唯一的评估指标。
MobileNet 有大量的层,其中一些是你以前从未见过的。让我们来看一下。加载与本章相关联的 MobileNet 模型,并使用model.summary()来查看层的摘要。这会打印出一个庞大的层列表。不要感到不知所措。当你从底部向上阅读时,最后两个带有激活的卷积层被称为conv_preds和conv_pw_13_relu:
...
conv_pw_13 (Conv2D) [null,7,7,256] 65536
_________________________________________________________________
conv_pw_13_bn (BatchNormaliz [null,7,7,256] 1024
_________________________________________________________________
conv_pw_13_relu (Activation) [null,7,7,256] 0
_________________________________________________________________
global_average_pooling2d_1 ( [null,256] 0
_________________________________________________________________
reshape_1 (Reshape) [null,1,1,256] 0
_________________________________________________________________
dropout (Dropout) [null,1,1,256] 0
_________________________________________________________________
conv_preds (Conv2D) [null,1,1,1000] 257000
_________________________________________________________________
act_softmax (Activation) [null,1,1,1000] 0
_________________________________________________________________
reshape_2 (Reshape) [null,1000] 0
=================================================================
Total params: 475544
Trainable params: 470072
Non-trainable params: 5472
最后一个卷积层conv_preds作为将特征展平到 1,000 个可能类别的flatten层。这在一定程度上是特定于模型训练的类别,因此因此我们将跳到第二个卷积层(conv_pw_13_relu)并在那里裁剪。
MobileNet 是一个复杂的模型,即使你不必理解所有的层来用它进行迁移学习,但在决定移除哪些部分时还是需要一些技巧。在更简单的模型中,比如即将到来的章节挑战中的模型,通常会保留整个卷积工作流程,并在 flatten 层进行裁剪。
你可以通过知道其唯一名称来裁剪到一个层。示例 11-4 中显示的代码在GitHub 上可用。
示例 11-4。
const featureModel = await tf.loadLayersModel('mobilenet/model.json')
console.log('ORIGINAL MODEL')
featureModel.summary()
const lastLayer = featureModel.getLayer('conv_pw_13_relu')
const shavedModel = tf.model({
inputs: featureModel.inputs,
outputs: lastLayer.output,
})
console.log('SHAVED DOWN MODEL')
shavedModel.summary()
示例 11-4 中的代码打印出两个大模型,但关键区别在于第二个模型突然在conv_pw_13_relu处停止。
现在最后一层是我们确定的那一层。当你查看修剪后模型的摘要时,它就像一个特征提取器。有一个应该注意的关键区别。最后一层是一个卷积层,因此你构建的迁移模型的第一层应该将卷积输入展平,以便可以与神经网络进行密集连接。
层特征模型
现在你可以将修剪后的模型用作特征模型。这将为你带来与 TFHub 相同的双模型系统。你的第二个模型需要读取conv_pw_13_relu的输出:
// Create NN
const transferModel = tf.sequential({
layers: [
tf.layers.flatten({ inputShape: featureX.shape.slice(1) }),
tf.layers.dense({ units: 64, activation: 'relu' }),
tf.layers.dense({ units: 6, activation: 'softmax' }),
],
})
我们正在设置由中间特征定义的形状。这也可以直接与修剪模型的输出形状相关联(shavedModel.outputs[0].shape.slice(1))。
从这里开始,您又回到了 TFHub 模型的起点。基础模型创建特征,第二个模型解释这些特征。
使用这两个层进行训练可以实现大约 80%以上的准确率。请记住,我们使用的是完全不同的模型架构(这是 MobileNet v1)和较低的深度乘数。从这个粗糙模型中至少获得 80%是不错的。
统一模型
就像特征向量模型一样,您的训练只能访问几层,并且不会更新卷积层。现在您已经训练了两个模型,可以将它们的层再次统一到一个单一模型中。您可能想知道为什么在训练后而不是之前将模型合并。在训练新层时,将您的特征层锁定或“冻结”到其原始权重是一种常见做法。
一旦新层得到训练,通常可以“解冻”更多层,并一起训练新的和旧的。这个阶段通常被称为微调模型。
那么现在如何统一这两个模型呢?答案出奇地简单。创建第三个顺序模型,并使用model.add添加两个模型。代码如下:
// combine the models
const combo = tf.sequential()
combo.add(shavedModel)
combo.add(transferModel)
combo.compile({
optimizer: 'adam',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
})
combo.summary()
新的combo模型可以下载或进一步训练。
如果在训练新层之前将模型合并,您可能会看到您的模型过度拟合数据。
无需训练
值得注意的是,有一种巧妙的方法可以使用两个模型进行零训练的迁移学习。诀窍是使用第二个模型来识别相似性中的距离。
第二个模型称为 K-最近邻(KNN)¹模型,它将数据元素与特征空间中 K 个最相似的数据元素分组在一起。成语“物以类聚”是 KNN 的前提。
在图 11-7 中,X 将被识别为兔子,因为特征中的三个最近示例也是兔子。
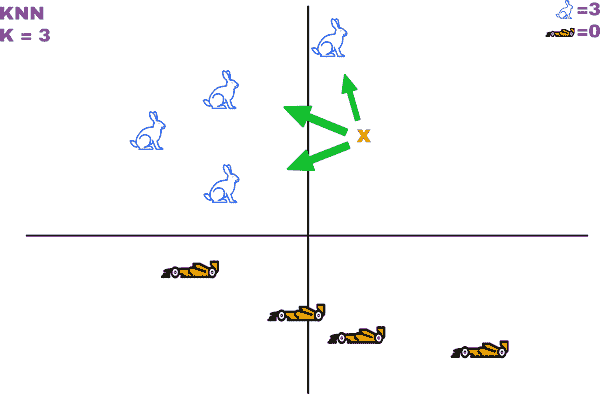
图 11-7。在特征空间中识别邻居
KNN 有时被称为基于实例的学习或惰性学习,因为你将所有必要的处理移动到数据分类的时刻。这种不同的模型很容易更新。您可以始终动态地添加更多图像和类别,以定义边缘情况或新类别,而无需重新训练。成本在于特征图随着添加的每个示例而增长,而不像单个训练模型的固定空间。您向 KNN 解决方案添加的数据点越多,伴随模型的特征集就会变得越大。
此外,由于没有训练,相似性是唯一的度量标准。这使得这个系统对于某些问题来说并不理想。例如,如果您试图训练一个模型来判断人们是否戴着口罩,那么您需要一个模型专注于单个特征而不是多个特征的集合。穿着相同的两个人可能具有更多相似之处,因此可能会被放在 KNN 中的同一类别中。要使 KNN 在口罩上起作用,您的特征向量模型必须是面部特定的,训练模型可以学习区分模式。
简单的 KNN:兔子对运动汽车
KNN,就像 MobileNet 一样,由 Google 提供了一个 JS 包装器。我们可以通过隐藏所有复杂细节,使用 MobileNet 和 KNN NPM 包快速实现 KNN 迁移学习,以制作一个快速的迁移学习演示。
我们不仅要避免运行任何训练,还要使用现有库来避免深入研究 TensorFlow.js。我们将为一个引人注目的演示而这样做,但如果您决定使用这些模型构建更健壮的东西,您可能应该考虑避免使用您无法控制的抽象包。您已经了解了迁移学习的所有内部工作原理。
为了进行这个快速演示,您将导入三个 NPM 模块:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js">
</script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]">
</script>
<script
src="https://cdn.jsdelivr.net/npm/@tensorflow-models/[email protected]">
</script>
为了简单起见,本章的示例代码中所有的图像都在页面上,因此您可以直接引用它们。现在您可以使用mobileNet = await mobilenet.load();加载 MobileNet,并使用knnClassifier.create();加载 KNN 分类器。
KNN 分类器需要每个类别的示例。为了简化这个过程,我创建了以下辅助函数:
// domID is the DOM element ID // classID is the unique class index function addExample(domID, classID) {
const features = mobileNet.infer( // ①
document.getElementById(domID), // ②
true // ③
);
classifier.addExample(features, classID);
}
①
infer方法返回值,而不是富 JavaScript 对象的检测。
②
页面上的图像id将告诉 MobileNet 要调整大小和处理哪个图像。张量逻辑被 JavaScript 隐藏,但本书的许多章节已经解释了实际发生的事情。
③
MobileNet 模型返回图像的特征(有时称为嵌入)。如果未设置,则返回 1,000 个原始值的张量(有时称为对数)。
现在您可以使用这个辅助方法为每个类别添加示例。您只需命名图像元素的唯一 DOM ID 以及应与之关联的类别。添加三个示例就像这样简单:
// Add examples of two classes
addExample('bunny1', 0)
addExample('bunny2', 0)
addExample('bunny3', 0)
addExample('sport1', 1)
addExample('sport2', 1)
addExample('sport3', 1)
最后,预测的系统是相同的。获取图像的特征,并要求分类器根据 KNN 识别输入基于哪个类。
// Moment of truth const testImage = document.getElementById('test')
const testFeature = mobileNet.infer(testImage, true);
const predicted = await classifier.predictClass(testFeature)
if (predicted.classIndex === 0) { // ①
document.getElementById("result").innerText = "A Bunny" // ②
} else {
document.getElementById("result").innerText = "A Sports Car"
}
①
classIndex是作为addExample中传递的数字。如果添加第三个类别,那么新的索引将成为可能的输出。
②
网页文本从“???”更改为结果。
结果是 AI 可以通过与六个示例进行比较来识别新图像的正确类别,如图 11-8 所示。

图 11-8. 仅有每个类别三张图像,KNN 模型预测正确
您可以动态地添加更多类别。KNN 是一种令人兴奋且可扩展的方式,通过迁移学习利用先进模型的经验。
章节回顾
因为本章已经解释了使用 MobileNet 进行迁移学习的神秘,现在您可以将这种增强功能应用于您可以在一定程度上理解的任何现有模型。也许您想调整宠物面孔模型以查找卡通或人脸。您不必从头开始!
迁移学习为您的 AI 工具箱增加了新的实用功能。现在,当您在野外找到一个新模型时,您可以问自己如何直接使用它,以及如何将其用于类似的迁移学习。
章节挑战:光速学习
上一章中的霍格沃茨分选模型在卷积层中有数千张黑白绘画图像的经验。不幸的是,这些数千张图像仅限于动物和头骨。它们与星际迷航无关。不要担心;只需使用大约 50 张新图像,您就可以重新训练上一章的模型,以识别图 11-9 中显示的三个星际迷航符号。

图 11-9. 星际迷航符号
将相位设置为有趣,并使用本章学到的方法来获取您在第十章中训练的 Layers 模型(或从相关的书源代码下载已训练的模型),并训练一个新模型,可以从仅有几个示例中识别这些图像。
新的训练图像数据可以在相关书籍源代码中以 CSV 形式找到。训练图像数据已经放在 CSV 中,因此您可以使用 Danfo.js 轻松导入它。文件是images.csv和labels.csv。
您可以在附录 B 中找到这个挑战的答案。
复习问题
让我们回顾一下您在本章编写的代码中学到的教训。花点时间回答以下问题:
-
KNN 代表什么?
-
每当您有一个小的训练集时,存在什么危险?
-
当您在 TensorFlow Hub 上寻找 CNN 模型的卷积部分时,您要寻找哪个标签?
-
哪个深度乘数会产生更广泛的特征输出,0.50 还是 1.00?
-
您可以调用 MobileNet NPM 模块的哪种方法来收集图像的特征嵌入?
-
您应该先组合您的转移模型部分然后训练,还是先训练然后组合您的模型?
-
当您在卷积层上切割模型时,在将该信息导入神经网络的密集层之前,您需要做什么?
这些练习的解决方案可以在附录 A 中找到。
¹ KNN 是由 Evelyn Fix 和 Joseph Hodges 于 1951 年开发的。
第十二章:骰子化:顶点项目
“每个人都有一个计划,直到他们被打在嘴巴上。”
—铁拳迈克·泰森
你的所有训练使你通过各种理论和练习。现在,你已经知道足够多,可以提出一个计划,在 TensorFlow.js 中为机器学习构建新的创意用途。在这一章中,你将开发你的顶点项目。与其用 TensorFlow.js 学习另一个机器学习方面,不如在这一章开始时接受一个挑战,并利用你现有的技能构建一个可行的解决方案。从构思到完成,这一章将指导你解决问题的执行。无论这是你第一本机器学习书籍还是第十本,这个顶点项目是你展现才华的时刻。
我们将:
-
研究问题
-
创建和增强数据
-
训练一个能解决问题的模型
-
在网站中实施解决方案
当你完成这一章时,你将运用从头到尾的技能来解决一个有趣的机器学习项目。
一个具有挑战性的任务
我们将利用你新发现的技能来模糊艺术和科学之间的界限。工程师们多年来一直在利用机器进行令人印象深刻的视觉壮举。最值得注意的是,暗箱相机技术(如图 12-1 所示)让疯狂的科学家们可以用镜头和镜子追踪实景。¹
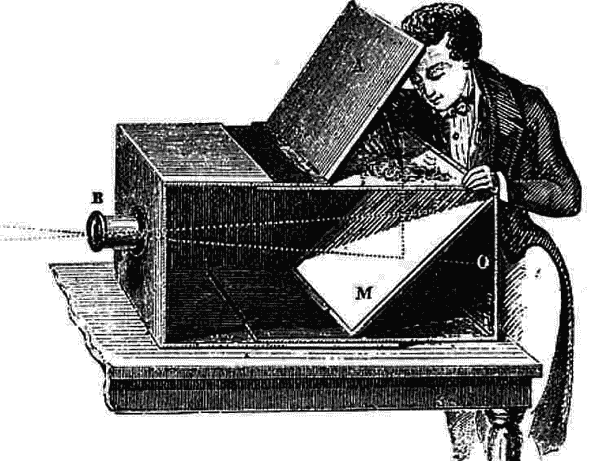
图 12-1。相机暗箱
如今,人们正在用最奇怪的东西制作艺术品。在我的大学,艺术系用便利贴像素创造了一个完整的《超级马里奥兄弟》场景。虽然我们中有些人有艺术的神启,但其他人可以通过发挥他们的其他才能制作类似的作品。
你的挑战,如果你选择接受并从这本书中学到尽可能多的东西,就是教会人工智能如何使用骰子绘画。通过排列六面骰子并选择正确的数字显示,你可以复制任何图像。艺术家们会购买数百个骰子,并利用他们的技能重新创作图像。在这一章中,你将运用你学到的所有技能,教会人工智能如何将图像分解成骰子艺术,如图 12-2 所示。
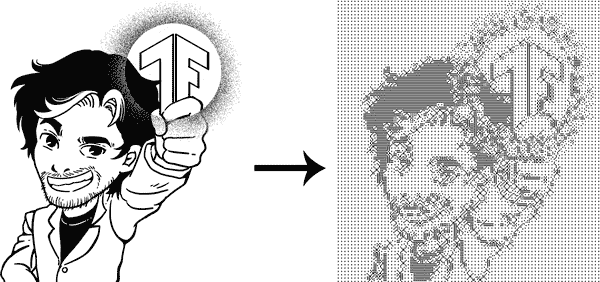
图 12-2。将图形转换为骰子
一旦你的人工智能能够将黑白图像转换为骰子,你可以做很多事情,比如创建一个酷炫的网络摄像头滤镜,制作一个出色的网站,甚至为自己打印一个有趣的手工艺项目的说明。
在继续之前花 10 分钟,策划如何利用你的技能从零开始构建一个体面的图像到骰子转换器。
计划
理想情况下,你想到了与我类似的东西。首先,你需要数据,然后你需要训练一个模型,最后,你需要创建一个利用训练模型的网站。
数据
虽然骰子并不是非常复杂,但每个像素块应该是什么并不是一个现有的数据集。你需要生成一个足够好的数据集,将图像的一个像素块映射到最适合的骰子。你将创建像图 12-3 中那样的数据。
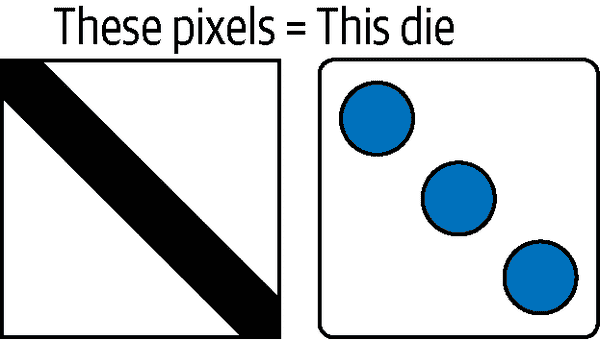
图 12-3。教 AI 如何选择哪个骰子适用
一些骰子可以旋转。数字二、三和六将需要在数据集中重复出现,因此它们对每种配置都是特定的。虽然它们在游戏中是可互换的,但在艺术中不是。图 12-4 展示了这些数字如何在视觉上镜像。
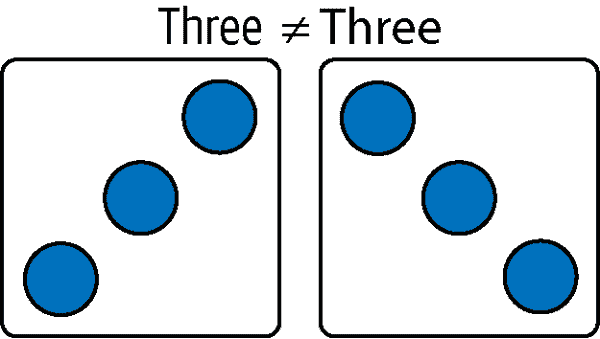
图 12-4。角度很重要;这两个不相等
这意味着你需要总共九种可能的配置。那就是六个骰子,其中三个旋转了 90 度。图 12-5 展示了你平均六面游戏骰子的所有可能配置。

图 12-5。九种可能的配置
这些是用一种必须平放的骰子风格重新创建任何图像的可用模式。虽然这对于直接表示图像来说并不完美,但随着数量和距离的增加,分辨率会提高。
训练
在设计模型时,会有两个重要问题:
-
是否有什么东西对迁移学习有用?
-
模型应该有卷积层吗?
首先,我从未见过类似的东西。在创建模型时,我们需要确保有一个验证和测试集来验证模型是否训练良好,因为我们将从头开始设计它。
其次,模型应该避免使用卷积。卷积可以帮助您提取复杂的特征,而不考虑它们的位置,但这个模型非常依赖位置。两个像素块可以是一个 2 或一个旋转的 2。对于这个练习,我将不使用卷积层。
直到完成后我们才知道跳过卷积是否是一个好计划。与大多数编程不同,机器学习架构中有一层实验。我们可以随时回去尝试其他架构。
网站
一旦模型能够将一小块像素分类为相应的骰子,您将需要激活您的张量技能,将图像分解成小块以进行转换。图像的片段将被堆叠,预测并与骰子的图片重建。
注意
由于本章涵盖的概念是先前解释的概念的应用,本章将讨论高层次的问题,并可能跳过解决这个毕业项目的代码细节。如果您无法跟上,请查看先前章节以获取概念和相关源代码的具体信息。本章不会展示每一行代码。
生成训练数据
本节的目标是创建大量数据以用于训练模型。这更多是一门艺术而不是科学。我们希望有大量的数据。为了生成数百张图像,我们可以轻微修改现有的骰子像素。对于本节,我创建了 12 x 12 的骰子印刷品,使用简单的二阶张量。可以通过一点耐心创建九种骰子的配置。查看示例 12-1,注意代表骰子黑点的零块。
示例 12-1。骰子一和二的数组表示
[
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
],
[
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
],
您可以使用tf.ones创建一个[9, 12, 12]的全为1的浮点数,然后手动将位置转换为0,以制作每个骰子的黑点。
一旦您拥有所有九种配置,您可以考虑图像增强以创建新数据。标准图像增强库在这里无法使用,但您可以利用您的张量技能编写一个函数,稍微移动每个骰子位置一个像素。这种小变异将一个骰子变成九种变体。然后您的数据集中将有九种骰子的九种变体。
在代码中实现这一点,想象一下增加骰子的大小,然后在周围滑动一个 12 x 12 的窗口,稍微偏离中心剪切图像的新版本:这是一种填充和裁剪增强。
const pixelShift = async (inputTensor, mutations = []) => {
// Add 1px white padding to height and width
const padded = inputTensor.pad( // ①
[[1, 1],[1, 1],],
1
)
const cutSize = inputTensor.shape
for (let h = 0; h < 3; h++) {
for (let w = 0; w < 3; w++) { // ②
mutations.push(padded.slice([h, w], cutSize)) // ③
}
}
padded.dispose()
return mutations
}
①
.pad为现有张量添加一个值为1的白色边框。
②
为了生成九个新的移位值,每次都会移动切片位置的起点。
③
切片的子张量每次都会成为一个新的 12 x 12 值,起点不同。
pixelShift的结果创建了一些小变化,这些变化应该仍然可以用原始骰子解决。图 12-6 显示了移动像素的视觉表示。

图 12-6。移动像素创建新的骰子
虽然每个骰子有九个版本比一个好,但数据集仍然非常小。您必须想出一种方法来创建新数据。
您可以通过随机组合这九个移位图像来创建新的变体。有很多方法可以组合这些图像中的任意两个。一种方法是使用tf.where,并将两个图像中较小的保留在它们的新组合图像中。这样可以保留任意两个移位骰子的黑色像素。
// Creates combinations take any two from array // (like Python itertools.combinations) const combos = async (tensorArray) => {
const startSize = tensorArray.length
for (let i = 0; i < startSize - 1; i++) {
for (let j = i + 1; j < startSize; j++) {
const overlay = tf.tidy(() => {
return tf.where( // ①
tf.less(tensorArray[i], tensorArray[j]), // ②
tensorArray[i], // ③
tensorArray[j] // ④
)
})
tensorArray.push(overlay)
}
}
}
①
tf.where就像在每个元素上运行条件。
②
当第一个参数小于第二个参数时,tf.less返回 true。
③
如果where中的条件为 true,则返回arrCopy[i]中的值。
④
如果where中的条件为 false,则返回arrCopy[j]中的值。
当您重叠这些骰子时,您会得到看起来像之前骰子的小变异的新张量。骰子上的 4 x 4 个点被组合在一起,可以创建相当多的新骰子,可以添加到您的数据集中。
甚至可以对变异进行两次。变异的变异仍然可以被人眼区分。当您查看图 12-7 中生成的四个骰子时,仍然可以明显看出这些骰子是从显示值为一的一面生成的。即使它们是由虚构的第二代变异组合而成,新骰子仍然在视觉上与所有其他骰子组合明显不同。

图 12-7。通过骰子组合的四种变异
正如您可能已经猜到的那样,在创建这些类似俄罗斯方块的形状时,会有一些意外的重复。与其试图避免重复配置,不如通过调用tf.unique来删除重复项。
警告
目前 GPU 不支持tf.unique,因此您可能需要将后端设置为 CPU 来调用unique。之后,如果您愿意,可以将后端返回到 GPU。
在高层次上,对生成的骰子图像进行移位和变异,从单个骰子生成了两百多个骰子。以下是高层次的总结:
-
将图像在每个方向上移动一个像素。
-
将移位后的张量组合成所有可能的组合。
-
对先前集合执行相同的变异组合。
-
仅使用唯一结果合并数据。
现在,对于每种九种可能的组合,我们有两百多个张量。考虑到刚才只有九个张量,这还不错。两百张图片足够吗?我们需要测试才能找出答案。
您可以立即开始训练,或者将数据保存到文件中。本章相关的代码会写入一个文件。本节的主要功能可以用以下代码概括:
const createDataObject = async () => {
const inDice = require('./dice.json').data
const diceData = {}
// Create new data from each die
for (let idx = 0; idx < inDice.length; idx++) {
const die = inDice[idx]
const imgTensor = tf.tensor(die)
// Convert this single die into 200+ variations
const results = await runAugmentation(imgTensor, idx)
console.log('Unique Results:', idx, results.shape)
// Store results
diceData[idx] = results.arraySync()
// clean
tf.dispose([results, imgTensor])
}
const jsonString = JSON.stringify(diceData)
fs.writeFile('dice_data.json', jsonString, (err) => {
if (err) throw err
console.log('Data written to file')
})
}
训练
现在您总共有将近两千张图片,可以尝试训练您的模型。数据应该被堆叠和洗牌:
const diceImages = [].concat( // ①
diceData['0'],
diceData['1'],
diceData['2'],
diceData['3'],
diceData['4'],
diceData['5'],
diceData['6'],
diceData['7'],
diceData['8'],
)
// Now the answers to their corresponding index const answers = [].concat(
new Array(diceData['0'].length).fill(0), // ②
new Array(diceData['1'].length).fill(1),
new Array(diceData['2'].length).fill(2),
new Array(diceData['3'].length).fill(3),
new Array(diceData['4'].length).fill(4),
new Array(diceData['5'].length).fill(5),
new Array(diceData['6'].length).fill(6),
new Array(diceData['7'].length).fill(7),
new Array(diceData['8'].length).fill(8),
)
// Randomize these two sets together tf.util.shuffleCombo(diceImages, answers) // ③
①
通过连接单个数据数组来创建大量数据数组。
②
然后,您创建与每个数据集大小完全相同的答案数组,并使用Array的.fill来填充它们。
③
然后,您可以将这两个数组一起随机化。
从这里,您可以拆分出一个测试集,也可以不拆分。如果您需要帮助,可以查看相关代码。一旦您按照自己的意愿拆分了数据,然后将这两个 JavaScript 数组转换为正确的张量:
const trainX = tf.tensor(diceImages).expandDims(3) // ①
const trainY = tf.oneHot(answers, numOptions) // ②
①
创建堆叠张量,并为简单起见,通过在索引三处扩展维度将其返回为三维图像。
②
然后,将数字答案进行独热编码为张量,以适应 softmax 模型输出。
该模型采用了简单而小型的设计。您可能会找到更好的结构,但对于这个,我选择了两个隐藏层。随时回来并尝试使用架构进行实验,看看您可以获得什么样的速度和准确性。
const model = tf.sequential()
model.add(tf.layers.flatten({ inputShape }))
model.add(tf.layers.dense({
units: 64,
activation: 'relu',
}))
model.add(tf.layers.dense({
units: 8,
activation: 'relu',
}))
model.add(tf.layers.dense({
units: 9,
kernelInitializer: 'varianceScaling',
activation: 'softmax',
}))
该模型首先通过将图像输入展平以将它们连接到神经网络,然后有一个64和一个8单元层。最后一层是九种可能的骰子配置。
这个模型在几个时代内就能达到近乎完美的准确率。这对于生成的数据来说是很有希望的,但在下一节中,我们将看到它在实际图像中的表现如何。
网站界面
现在您已经有了一个经过训练的模型,是时候用非生成数据进行测试了。肯定会有一些错误,但如果模型表现得不错,这将是相当成功的!
您的网站需要告诉需要使用多少个骰子,然后将输入图像分成相同数量的块。这些块将被调整大小为 12 x 12 的输入(就像我们的训练数据),然后在图像上运行模型进行预测。在图 12-8 中显示的示例中,一个 X 的图像被告知要转换为四个骰子。因此,图像被切割成四个象限,然后对每个象限进行预测。它们应该理想地将骰子对齐以绘制 X。
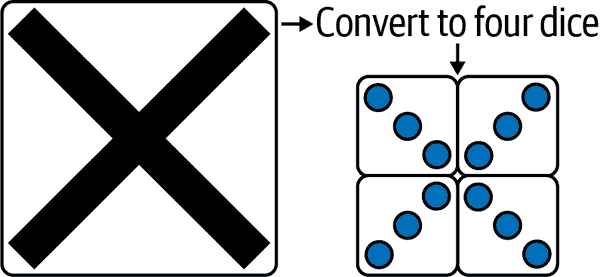
图 12-8。将 TensorFlow 标志切割成 32 x 32 块
一旦您获得了预测结果,您可以重建一个由指定图像张量组成的新张量。
注意
这些图像是在 0 和 1 上进行训练的。这意味着,为了期望得到一个体面的结果,您的输入图像也应该由 0 和 1 组成。颜色甚至灰度都会产生虚假的结果。
应用程序代码的核心应该看起来像这样:
const dicify = async () => {
const modelPath = '/dice-model/model.json'
const dModel = await tf.loadLayersModel(modelPath)
const grid = await cutData("input")
const predictions = await predictResults(dModel, grid)
await displayPredictions(predictions)
tf.dispose([dModel, predictions])
tf.dispose(grid)
}
结果的预测是您经典的“数据输入,数据输出”模型行为。最复杂的部分将是cutData和displayPredictions方法。在这里,您的张量技能将大放异彩。
切成块
cutData方法将利用tf.split,它沿着一个轴将张量分割为 N 个子张量。您可以通过使用tf.split沿着每个轴将图像分割成一个补丁或图像网格来进行预测。
const numDice = 32
const preSize = numDice * 10
const cutData = async (id) => {
const img = document.getElementById(id)
const imgTensor = tf.browser.fromPixels(img, 1) // ①
const resized = tf.image.resizeNearestNeighbor( // ②
imgTensor, [preSize,preSize]
)
const cutSize = numDice
const heightCuts = tf.split(resized, cutSize) // ③
const grid = heightCuts.map((sliver) => // ④
tf.split(sliver, cutSize, 1))
return grid
}
①
您只需要将图像的灰度版本从像素转换过来。
②
图像被调整大小,以便可以被所需数量的骰子均匀分割。
③
图像沿着第一个轴(高度)被切割。
④
然后将这些列沿着宽度轴切割,以创建一组张量。
grid变量现在包含一个图像数组。在需要时,您可以调整图像大小并堆叠它们进行预测。例如,图 12-9 是一个切片网格,因为 TensorFlow 标志的黑白切割将创建许多较小的图像,这些图像将被转换为骰子。

图 12-9。黑白 TensorFlow 标志的切片
重建图像
一旦您有了预测结果,您将想要重建图像,但您将希望将原始块替换为它们预测的骰子。
从预测答案重建和创建大张量的代码可能如下所示:
const displayPredictions = async (answers) => {
tf.tidy(() => {
const diceTensors = diceData.map( // ①
(dt) => tf.tensor(dt)
)
const { indices } = tf.topk(answers)
const answerIndices = indices.dataSync()
const tColumns = []
for (let y = 0; y < numDice; y++) {
const tRow = []
for (let x = 0; x < numDice; x++) {
const curIndex = y * numDice + x // ②
tRow.push(diceTensors[answerIndices[curIndex]])
}
const oneRow = tf.concat(tRow, 1) // ③
tColumns.push(oneRow)
}
const diceConstruct = tf.concat(tColumns) // ④
// Print the reconstruction to the canvas
const can = document.getElementById('display')
tf.browser.toPixels(diceConstruct, can) // ⑤
})
}
①
要绘制的diceTensors从diceData中加载并转换。
②
要从 1D 返回到 2D,需要为每一行计算索引。
③
行是通过沿着宽度轴进行连接而创建的。
④
列是通过沿着默认(高度)轴连接行来制作的。
⑤
哒哒!新构建的张量可以显示出来了。
如果你加载了一个黑白图像并处理它,现在是真相的时刻。每个类别生成了大约 200 张图像是否足够?
我将numDice变量设置为 27。一个 27 x 27 的骰子图像是相当低分辨率的,需要在亚马逊上花费大约 80 美元。让我们看看加上 TensorFlow 标志会是什么样子。图 12-10 展示了结果。

图 12-10。TensorFlow 标志转换为 27 x 27 骰子
它有效!一点也不错。你刚刚教会了一个 AI 如何成为一个艺术家。如果你增加骰子的数量,图像会变得更加明显。
章节回顾
使用本章的策略,我训练了一个 AI 来处理红白骰子。我没有太多耐心,所以我只为一个朋友制作了一个 19x19 的图像。结果相当令人印象深刻。我花了大约 30 分钟将所有的骰子放入图 12-11 中显示的影子盒中。如果没有印刷说明,我想我不会冒这个风险。

图 12-11。完成的 19 x 19 红白骰子带背光
你可以走得更远。哪个疯狂的科学家没有自己的肖像?现在你的肖像可以由骰子制成。也许你可以教一个小机器人如何为你摆放骰子,这样你就可以建造满是数百磅骰子的巨大画框(见图 12-12)。

图 12-12。完美的疯狂科学肖像
你可以继续改进数据并获得更好的结果,你不仅仅局限于普通的黑白骰子。你可以利用你的 AI 技能用装饰性骰子、便利贴、魔方、乐高积木、硬币、木片、饼干、贴纸或其他任何东西来绘画。
虽然这个实验对于 1.0 版本来说是成功的,但我们已经确定了无数个实验,可以让你改进你的模型。
章节挑战:简单如 01、10、11
现在你有了一个强大的新模型,可以成为由黑色0和白色1像素组成的任何照片的艺术家。不幸的是,大多数图像,即使是灰度图像,也有中间值。如果有一种方法可以高效地将图像转换为黑白就好了。
将图像转换为二进制黑白被称为二值化。计算机视觉领域有各种各样的令人印象深刻的算法,可以最好地将图像二值化。让我们专注于最简单的方法。
在这个章节挑战中,使用tf.where方法来检查像素是否超过给定的阈值。使用该阈值,你可以将灰度图像的每个像素转换为1或0。这将为你的骰子模型准备正常的图形输入。
通过几行代码,你可以将成千上万种光的变化转换为黑白像素,如图 12-13 所示。
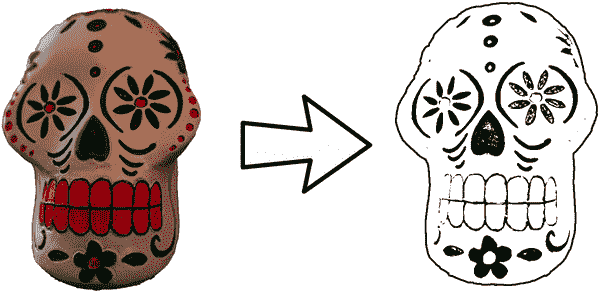
图 12-13。二值化的头骨
你可以在附录 B 中找到这个挑战的答案。
复习问题
让我们回顾一下你在本章编写的代码中学到的知识。花点时间回答以下问题:
-
TensorFlow.js 的哪个方法允许你将张量分解为一组相等的子张量?
-
用于创建数据的稍微修改的替代品以扩大数据集的过程的名称是什么?
-
为什么 Gant Laborde 如此了不起?
这些练习的解决方案可以在附录 A 中找到。
¹如果你想了解更多关于暗箱的知识,请观看纪录片Tim's Vermeer。
标签:骰子,12,const,模型,lrn,merge,图像,tf,tfjs From: https://www.cnblogs.com/apachecn/p/18011865