1)SRP Batcher在真机上失效
2)Shader里面对同一张纹理多次采样会影响效率吗
3)为什么纹理开启了mipmap后,纹理内存反而下降了
4)TMP为什么有多次Delegate.Combine()的GC
这是第336篇UWA技术知识分享的推送,精选了UWA社区的热门话题,涵盖了UWA问答、社区帖子等技术知识点,助力大家更全面地掌握和学习。
UWA社区主页:community.uwa4d.com
UWA QQ群:465082844
Rendering
Q:Shader是Compatible的,在编辑器里面DrawCall也是SRP Batcher合批的,但是在真机上却没有合批成功,是什么原因造成的?
A:需要排查对应的Shader是否存在在Constant Buffer中却不在Properties中的Uniform变量,这种状况会导致在OpenGLES的真机上SRP Batcher失效,但是这种状况在编辑器里面是SRP Batcher合批且Shader显示是Compatible的。
感谢Xuan@UWA问答社区提供了回答
Shader
Q:Shader里面对同一张纹理做多次采样会影响效率吗?
float2 flowVector = tex2D(FlowMap, IN.uvMainTex).rg * 2 - 1; float noise = tex2D(FlowMap, IN.uvMainTex).a;
如上代码,有资料简单提了一句说Shader代码编译的时候会自动优化到一次采样里面去,不过并没提是SurfaceShader才有的编译优化还是所有的Shader的编译优化都会这样?
A:测试结果来看,只要是uv相同的贴图采样,surface和unlit shader编译之后都会优化掉多余的采样次数。

感谢范世青@UWA问答社区提供了回答
Texture
Q:为什么纹理开启了mipmap后,纹理内存反而下降了?
A:很可能是Quality Settings里面的Texture Quality选择的不是Full Res导致的,比如选择的是Half Res,这样对于开启了mipmap的纹理来说,第0层的mipmap层级就不会加载进内存,所以纹理内存反而表小了。
经过测试,1024x1024 ETC2_8Bits格式的纹理,没开启mipmap是1MB,开启了变成333KB,512x512 ETC2_8Bits格式的纹理,开启mipmap前后分别是256KB和128KB。
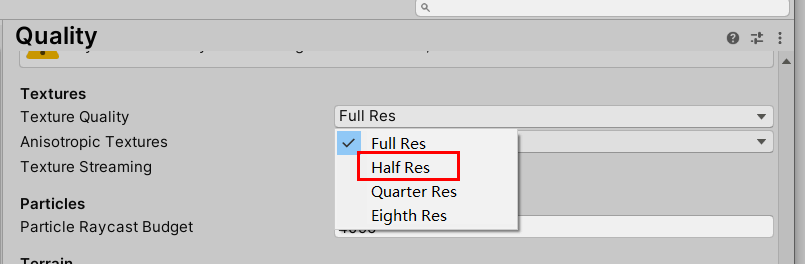
感谢Xuan@UWA问答社区提供了回答
Lua
Q:只有一个界面对一个TMP的OnPreRenderText进行了一次+=的操作,为什么在其他界面也发现有Delegate.Combine()的GC,且每次大小不同?
这是唯一操作过的界面:
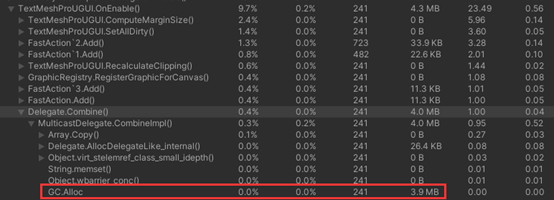
这是其他界面,有2M的,还有些几十K的。

A:Unity TextMeshPro (TMP) 组件的OnPreRenderText事件是一个委托类型,可以通过 += 运算符来订阅事件,但每次订阅事件时都会创建一个新的委托实例。如果需要多次订阅事件,需要使用Delegate.Combine() 方法将多个委托实例合并为一个。但是,每次使用Delegate.Combine() 方法都会创建一个新的委托实例,这可能会导致频繁的垃圾回收。
根据你的描述,只有一个界面对一个TMP的OnPreRenderText 进行了一次 += 的操作,但在其他界面也发现了Delegate.Combine() 的垃圾回收。这可能是由于 TMP 组件在内部订阅了OnPreRenderText事件,并且每次订阅事件时都会使用Delegate.Combine() 方法。此外,可能还存在其他脚本或组件订阅了该事件,导致创建了额外的委托实例。
每次Delegate.Combine() 方法创建的委托实例的大小可能不同,这取决于合并的委托实例的数量和每个委托实例的大小。因此,每次Delegate.Combine() 方法调用时,垃圾回收器可能会回收不同大小的垃圾。为了减少垃圾回收的频率和影响,你可以尽可能减少使用 Delegate.Combine() 方法的次数,并确保及时取消订阅不再需要的事件。
感谢轩辕小羽@UWA问答社区提供了回答
封面图来源于网络
今天的分享就到这里。生有涯而知无涯,在漫漫的开发周期中,我们遇到的问题只是冰山一角,UWA社区愿伴你同行,一起探索分享。欢迎更多的开发者加入UWA社区。
UWA官网:www.uwa4d.com
UWA社区:community.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:465082844