原文:Advanced Deep Learning with TensorFlow 2 and Keras
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、使用 Keras 入门高级深度学习
在第一章中,我们将介绍在本书中将使用的三个深度学习人工神经网络。 这些网络是 MLP,CNN 和 RNN(在第 2 节中定义和描述),它们是本书涵盖的所选高级深度学习主题的构建块,例如自回归网络(自编码器,GAN 和 VAE),深度强化学习 ,对象检测和分割以及使用互信息的无监督学习。
在本章中,我们将一起讨论如何使用 Keras 库实现基于 MLP,CNN 和 RNN 的模型。 更具体地说,我们将使用名为tf.keras的 TensorFlow Keras 库。 我们将首先探讨为什么tf.keras是我们的理想选择。 接下来,我们将深入研究三个深度学习网络中的实现细节。
本章将:
- 确定为什么
tf.keras库是进行高级深度学习的绝佳选择 - 介绍 MLP,CNN 和 RNN –高级深度学习模型的核心构建模块,我们将在本书中使用它们
- 提供有关如何使用
tf.keras实现基于 MLP,CNN 和 RNN 的模型的示例 - 在此过程中,开始引入重要的深度学习概念,包括优化,正则化和损失函数
在本章结束时,我们将使用tf.keras实现基本的深度学习网络。 在下一章中,我们将介绍基于这些基础的高级深度学习主题。 让我们通过讨论 Keras 及其作为深度学习库的功能来开始本章。
1. Keras 为什么是完美的深度学习库?
Keras [1]是一个受欢迎的深度学习库,在撰写本文时有 370,000 个开发人员在使用它-这个数字每年以大约 35% 的速度增长。 超过 800 位贡献者积极维护它。 我们将在本书中使用的一些示例已添加到 Keras GitHub 官方存储库中。
谷歌的 TensorFlow 是一个流行的开源深度学习库,它使用 Keras 作为其库的高级 API。 通常称为tf.keras。 在本书中,我们将交替使用 Keras 和tf.keras一词。
tf.keras作为深度学习库是一种流行的选择,因为它已高度集成到 TensorFlow 中,TensorFlow 因其可靠性而在生产部署中广为人知。 TensorFlow 还提供了各种工具,用于生产部署和维护,调试和可视化以及在嵌入式设备和浏览器上运行模型。 在技术行业中,Google,Netflix,Uber 和 NVIDIA 使用 Keras。
我们选择tf.keras作为本书的首选工具,因为它是致力于加速深度学习模型实现的库。 这使得 Keras 非常适合我们想要实用且动手的时候,例如,当我们探索本书中的高级深度学习概念时。 由于 Keras 旨在加速深度学习模型的开发,训练和验证,因此在有人可以最大限度地利用库之前,必须学习该领域的关键概念。
在tf.keras库中,各层之间就像乐高积木一样相互连接,从而形成了一个干净且易于理解的模型。 模型训练非常简单,只需要数据,大量训练和监控指标即可。
最终结果是,与其他深度学习库(例如 PyTorch)相比,大多数深度学习模型可以用更少的代码行来实现。 通过使用 Keras,我们将通过节省代码实现时间来提高生产率,而这些时间可以用于执行更关键的任务,例如制定更好的深度学习算法。
同样,Keras 是快速实现深度学习模型的理想选择,就像我们将在本书中使用的那样。 使用顺序模型 API,只需几行代码即可构建典型模型。 但是,不要被它的简单性所误导。
Keras 还可以使用其函数式 API 以及用于动态图的Model和Layer类来构建更高级和复杂的模型,可以对其进行定制以满足独特的需求。 函数式 API 支持构建类似图的模型,层重用以及创建行为类似于 Python 函数的模型。 同时,Model和Layer类提供了用于实现罕见或实验性深度学习模型和层的框架。
安装 Keras 和 TensorFlow
Keras 不是独立的深度学习库。 如您在“图 1.1.1”中所看到的,它建立在另一个深度学习库或后端的之上。 这可能是 Google 的 TensorFlow,MILA 的 Theano,微软的 CNTK 或 Apache MXNet。 但是,与本书的上一版不同,我们将使用 TensorFlow 2.0(tf2或简称为tf)提供的 Keras(更好地称为tf.keras),以利用 tf2 所提供的有用工具。 tf.keras也被认为是 TensorFlow 的事实上的前端,它在生产环境中表现出了公认的可靠性。 此外,在不久的将来,将不再提供 Keras 对 TensorFlow 以外的后端的支持。
从 Keras 迁移到tf.keras通常就像更改一样简单:
from keras... import ...
至
from tensorflow.keras... import ...
本书中的代码示例全部以 Python 3 编写,以支持 Python 2 于 2020 年结束。
在硬件上,Keras 在 CPU,GPU 和 Google 的 TPU 上运行。 在本书中,我们将在 CPU 和 NVIDIA GPU(特别是 GTX 1060,GTX 1080Ti,RTX 2080Ti,V100 和 Quadro RTX 8000)上进行测试:
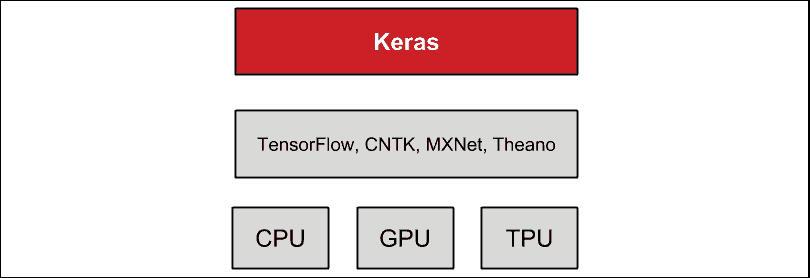
图 1.1.1:Keras 是位于其他深度学习框架之上的高级库。 CPU,GPU 和 TPU 支持 Keras。
在继续进行本书的其余部分之前,我们需要确保正确安装了tf2。 有多种执行安装的方法。 一个示例是通过使用pip3安装tf2:
$ sudo pip3 install tensorflow
如果我们具有支持已正确安装驱动的 NVIDIA GPU,以及 NVIDIA CUDA 工具包和 cuDNN 深度神经网络库,则强烈建议您安装启用 GPU 的版本,因为它可以加快训练和预测的速度:
$ sudo pip3 install tensorflow-gpu
无需安装 Keras,因为它已经是tf2中的包。 如果您不愿意在系统范围内安装库,强烈建议使用 Anaconda 之类的环境。 除了具有隔离环境之外,Anaconda 发行版还安装了用于数据科学的常用第三方包,这些包对于深度学习是必不可少的。
本书中提供的示例将需要其他包,例如pydot,pydot_ng,vizgraph,python3-tk和matplotlib。 在继续本章之前,我们需要安装这些包。
如果安装了tf2及其依赖项,则以下内容不会产生任何错误:
$ python3
>>> import tensorflow as tf
>>> print(tf.__version__)
2.0.0
>>> from tensorflow.keras import backend as K
>>> print(K.epsilon())
1e-07
本书没有涵盖完整的 Keras API。 我们将仅介绍解释本书中选定的高级深度学习主题所需的材料。 有关更多信息,请查阅 Keras 官方文档,该文档在这里或这里。
在随后的部分中,将讨论 MLP,CNN 和 RNN 的详细信息。 这些网络将用于使用tf.keras构建简单的分类器。
2. MLP,CNN 和 RNN
我们已经提到,我们将使用三个深度学习网络,它们是:
- MLP:多层感知器
- CNN:卷积神经网络
- RNN:循环神经网络
这些是我们将在本书中使用的三个网络。 稍后,您会发现它们经常结合在一起以利用每个网络的优势。
在本章中,我们将更详细地讨论这些构建块。 在以下各节中,将介绍 MLP 以及其他重要主题,例如损失函数,优化器和正则化器。 接下来,我们将介绍 CNN 和 RNN。
MLP,CNN 和 RNN 之间的区别
MLP 是全连接(FC)网络。 在某些文献中,您经常会发现将该称为或深度前馈网络或前馈神经网络。 在本书中,我们将使用术语 MLP。 从已知目标应用的角度了解此网络将有助于我们深入了解高级深度学习模型设计的根本原因。
MLP 在简单的逻辑和线性回归问题中很常见。 但是,MLP 对于处理顺序和多维数据模式不是最佳的。 通过设计,MLP 难以记住顺序数据中的模式,并且需要大量参数来处理多维数据。
对于顺序数据输入,RNN 很受欢迎,因为内部设计允许网络发现数据历史记录中的依存关系,这对预测很有用。 对于诸如图像和视频之类的多维数据,CNN 擅长提取用于分类,分割,生成和其他下游任务的特征映射。 在某些情况下,一维卷积形式的 CNN 也用于具有顺序输入数据的网络。 但是,在大多数深度学习模型中,将 MLP 和 CNN 或 RNN 结合起来可以充分利用每个网络。
MLP,CNN 和 RNN 并不完整整个深度网络。 需要识别目标或损失函数,优化器,和调节器。 目标是减少训练期间的损失函数值,因为这样的减少是模型正在学习的一个很好的指标。
为了使值最小化,模型使用了优化器。 这是一种算法,它确定在每个训练步骤中应如何调整权重和偏差。 经过训练的模型不仅必须对训练数据起作用,而且还必须对训练环境之外的数据起作用。 正则化器的作用是确保训练后的模型能够推广到新数据。
现在,让我们进入这三个网络–我们将从谈论 MLP 网络开始。
3. 多层感知器(MLP)
我们将要看的这三个网络中的第一个是 MLP 网络。 让我们假设目标是创建一个神经网络,用于基于手写数字识别数字。 例如,当网络的输入是手写数字 8 的图像时,相应的预测也必须是数字 8。这是分类器网络的经典工作,可以使用逻辑回归进行训练。 为了训练和验证分类器网络,必须有足够大的手写数字数据集。 国家标准技术混合研究院数据集,简称 MNIST [2],通常被视为 Hello World 深度学习数据集。 它是用于手写数字分类的合适数据集。
在我们讨论 MLP 分类器模型之前,必须了解 MNIST 数据集。 本书中的大量示例都使用 MNIST 数据集。 MNIST 用于来解释并验证许多深度学习理论,因为它包含的 70,000 个样本很小,但是的信息足够丰富:

图 1.3.1:来自 MNIST 数据集的示例图像。 每个灰度图像为28×28像素。
在下面的中,我们将简要介绍 MNIST。
MNIST 数据集
MNIST 是从 0 到 9 的手写数字的集合。它具有 60,000 张图像的训练集和 10,000 张测试图像,这些图像被分为相应的类别或标签。 在某些文献中,术语目标或基本事实也用于指标签。
在上图中,可以看到 MNIST 数字的样本图像,每个样本的大小为28 x 28像素(灰度)。 为了在 Keras 中使用 MNIST 数据集,提供了一个 API,用于下载并自动提取图像和标签。“列表 1.3.1”演示了如何仅在一行中加载 MNIST 数据集,从而使我们既可以计算训练和测试标签,又可以绘制 25 个随机数字图像。
“列表 1.3.1”:mnist-sampler-1.3.1.py
import numpy as np
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# load dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# count the number of unique train labels
unique, counts = np.unique(y_train, return_counts=True)
print("Train labels: ", dict(zip(unique, counts)))
# count the number of unique test labels
unique, counts = np.unique(y_test, return_counts=True)
print("Test labels: ", dict(zip(unique, counts)))
# sample 25 mnist digits from train dataset
indexes = np.random.randint(0, x_train.shape[0], size=25)
images = x_train[indexes]
labels = y_train[indexes]
# plot the 25 mnist digits
plt.figure(figsize=(5,5))
for i in range(len(indexes)):
plt.subplot(5, 5, i + 1)
image = images[i]
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.savefig("mnist-samples.png")
plt.show()
plt.close('all')
mnist.load_data()方法很方便,因为不需要分别加载所有 70,000 张图像和标签并将它们存储在数组中。 执行以下命令:
python3 mnist-sampler-1.3.1.py
在命令行上,该代码示例打印训练和测试数据集中的标签分布:
Train labels:{0: 5923, 1: 6742, 2: 5958, 3: 6131, 4: 5842, 5: 5421, 6: 5918, 7: 6265, 8: 5851, 9: 5949}
Test labels:{0: 980, 1: 1135, 2: 1032, 3: 1010, 4: 982, 5: 892, 6: 958, 7: 1028, 8: 974, 9: 1009}
之后,代码将绘制 25 个随机数字,如先前在“图 1.3.1”中所示。
在讨论 MLP 分类器模型之前,必须记住,虽然 MNIST 数据由二维张量组成,但应根据输入层的类型对它进行重塑。 以下“图 1.3.2”显示了如何为 MLP,CNN 和 RNN 输入层重塑3×3灰度图像:

图 1.3.2:根据输入层的类型,对与 MNIST 数据相似的输入图像进行重塑。 为简单起见,显示了3×3灰度图像的重塑。
在以下各节中,将介绍 MNIST 的 MLP 分类器模型。 我们将演示如何使用tf.keras有效地构建,训练和验证模型。
MNIST 数字分类器模型
“图 1.3.3”中显示的建议的 MLP 模型可用于 MNIST 数字分类。 当单元或感知器暴露在外时,MLP 模型是一个全连接网络,如图“图 1.3.4”所示。 我们还将展示如何根据第n个单元的权重w[i]和偏置b[n]的输入来计算感知器的输出。 相应的tf.keras实现在“列表 1.3.2”中进行了说明:

图 1.3.3:MLP MNIST 数字分类器模型

图 1.3.4:图 1.3.3 中的 MLP MNIST 数字分类器由全连接层组成。 为简单起见,未显示激活层和退出层。 还详细显示了一个单元或感知器。
“列表 1.3.2”:mlp-mnist-1.3.2.py
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.datasets import mnist
# load mnist dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# compute the number of labels
num_labels = len(np.unique(y_train))
# convert to one-hot vector
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# image dimensions (assumed square)
image_size = x_train.shape[1]
input_size = image_size * image_size
# resize and normalize
x_train = np.reshape(x_train, [-1, input_size])
x_train = x_train.astype('float32') / 255
x_test = np.reshape(x_test, [-1, input_size])
x_test = x_test.astype('float32') / 255
# network parameters
batch_size = 128
hidden_units = 256
dropout = 0.45
# model is a 3-layer MLP with ReLU and dropout after each layer
model = Sequential()
model.add(Dense(hidden_units, input_dim=input_size))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(hidden_units))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(num_labels))
# this is the output for one-hot vector
model.add(Activation('softmax'))
model.summary()
plot_model(model, to_file='mlp-mnist.png', show_shapes=True)
# loss function for one-hot vector
# use of adam optimizer
# accuracy is good metric for classification tasks
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train the network
model.fit(x_train, y_train, epochs=20, batch_size=batch_size)
# validate the model on test dataset to determine generalization
_, acc = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))
在讨论模型实现之前,数据必须具有正确的形状和格式。 加载 MNIST 数据集后,标签的数量计算为:
# compute the number of labels
num_labels = len(np.unique(y_train))
硬编码num_labels = 10也可以选择。 但是,让计算机完成工作始终是一个好习惯。 该代码假定y_train的标签为 0 到 9。
此时,标签为数字格式,即从 0 到 9。标签的这种稀疏标量表示形式不适用于按类别输出概率的神经网络预测层。 一种更合适的格式称为one-hot vector,这是一个十维向量,除数字类的索引外,所有元素均为 0。 例如,如果标签为 2,则等效one-hot vector为[0,0,1,0,0,0,0,0,0,0]。 第一个标签的索引为 0。
以下各行将每个标签转换为one-hot vector:
# convert to one-hot vector
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
在深度学习中,数据存储在张量中。 张量一词适用于标量(0D 张量),向量(1D 张量),矩阵(二维张量)和多维张量。
从这一点出发,除非标量,向量或矩阵使解释更清楚,否则将使用术语张量。
如下所示的其余代码将计算图像尺寸,第一密集层的input_size值,并将每个像素值从 0 缩放到 255,范围从 0.0 缩放到 1.0。 尽管可以直接使用原始像素值,但最好对输入数据进行规范化,以避免产生可能会使训练变得困难的较大梯度值。 网络的输出也被标准化。 训练后,可以通过将输出张量乘以 255 来将所有内容恢复为整数像素值。
提出的模型基于 MLP 层。 因此,输入应为一维张量。 这样,将x_train和x_test分别重塑为[60,000,28 * 28]和[10,000,28 * 28]。 在 NumPy 中,大小为 -1 表示让库计算正确的尺寸。 在x_train的情况下为 60,000。
# image dimensions (assumed square) 400
image_size = x_train.shape[1]
input_size = image_size * image_size
# resize and normalize
x_train = np.reshape(x_train, [-1, input_size])
x_train = x_train.astype('float32') / 255
x_test = np.reshape(x_test, [-1, input_size])
x_test = x_test.astype('float32') / 255
在准备好数据集之后,以下内容将重点介绍使用 Keras 的顺序 API 构建 MLP 分类器模型。
使用 MLP 和 Keras 构建模型
数据准备之后,接下来是构建模型。 所提出的模型由三个 MLP 层组成。 在 Keras 中,将 MLP 层称为密集,它表示紧密连接的层。 第一和第二个 MLP 层本质上是相同的,每个都有 256 个单元,然后是整流线性单元(ReLU)激活和退出。 由于 128、512 和 1,024 个单元的表现指标较低,因此选择 256 个单元。 在 128 个单元的情况下,网络收敛迅速,但测试精度较低。 512 或 1,024 的额外单元数量不会显着提高测试精度。
单元数是超参数。 它控制网络的容量。 容量是网络可以近似的函数复杂性的度量。 例如,对于多项式,度是超参数。 随着程度的增加,函数的能力也随之增加。
如以下代码行所示,使用 Keras 的顺序 API 实现分类器模型。 如果模型需要一个输入和一个输出(由一系列层处理),这就足够了。 为了简单起见,我们现在将使用它。 但是,在“第 2 章”,“深度神经网络”中,将引入 Keras 的函数式 API 来实现高级深度学习模型,该模型需要更复杂的结构(例如多个输入和输出)。
# model is a 3-layer MLP with ReLU and dropout after each layer model = Sequential()
model.add(Dense(hidden_units, input_dim=input_size))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(hidden_units))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(num_labels))
# this is the output for one-hot vector model.add(Activation('softmax'))
由于Dense层是线性运算,因此Dense层的序列只能近似线性函数。 问题是 MNIST 数字分类本质上是非线性过程。 在Dense层之间插入relu激活将使 MLP 网络能够对非线性映射建模。 relu或 ReLU 是一个简单的非线性函数。 这很像一个过滤器,它允许正输入不变地通过,同时将其他所有值都钳位为零。 数学上,relu用以下公式表示,见“图 1.3.5”:


图 1.3.5:ReLU 函数图。 ReLU 函数在神经网络中引入了非线性。
还可以使用其他非线性函数,例如elu,selu,softplus,sigmoid和tanh。 但是,relu是最常用的函数,由于其简单性,在计算上是有效的。 Sigmoid 和 tanh 函数在输出层中用作激活函数,稍后将描述。“表 1.3.1”显示了每个激活函数的方程式:
relu |
relu(x) = max(0, x) |
1.3.1 |
|---|---|---|
softplus |
softplus(x) = log(1 + exp(x)) |
1.3.2 |
elu |
 其中 其中a≥0并且是可调超参数 |
1.3.3 |
selu |
selu(x) = k×elu(x, a)其中k = 1.0507009873554804934193193349852946和a = 1.6732632423543772848170429916717 |
1.3.4 |
sigmoid |
 |
1.3.5 |
tanh |
 |
1.3.6 |
表 1.3.1:常见非线性激活函数的定义
尽管我们已完成 MLP 分类器模型的关键层,但我们尚未解决泛化问题或模型超出训练数据集的能力。 为了解决这个问题,我们将在下一节介绍正则化。
正则化
神经网络倾向于记住其训练数据,特别是如果它包含的容量超过。 在这种情况下,当经受测试数据时,网络将发生灾难性的故障。 这是网络无法推广的经典情况。 为了避免这种趋势,模型使用了正则化层或函数。 常见的正则化层是Dropout。
丢弃的想法很简单。 给定丢弃率(此处将其设置为dropout = 0.45),丢弃层会从参与下一层的单元中随机删除这一部分。 例如,如果第一层具有 256 个单元,则在应用dropout = 0.45之后,只有(1-0.45) * 256个单元,来自第 1 层的 140 个单元参与第 2 层。
丢弃层使神经网络对于无法预见的输入数据具有鲁棒性,因为即使缺少某些单元,训练后的神经网络也可以正确预测。 值得注意的是,输出层中没有使用丢弃,它仅在训练期间处于活动状态。 此外,在预测期间不存在丢弃现象。
除了诸如丢弃之类的正则化之外,还可以使用其他正则化器。 在 Keras 中,可以按层对偏置,权重和激活输出进行正则化。 l1和l2通过添加罚函数来支持较小的参数值。 l1和l2都使用绝对值(l1)或平方(l2)之和的分数来执行惩罚。 换句话说,惩罚函数迫使优化器找到较小的参数值。 参数值小的神经网络对来自输入数据的噪声的存在更加不敏感。
例如,带有fraction=0.001的l2权重正则器可以实现为:
from tensorflow.keras.regularizers import l2
model.add(Dense(hidden_units,
kernel_regularizer=l2(0.001),
input_dim=input_size))
如果使用l1或l2正则化,则不添加任何附加层。 正则化在内部施加在Dense层中。 对于建议的模型,丢弃仍然具有比l2更好的表现。
我们的模型几乎已经完成。 下一节将重点介绍输出层和损失函数。
输出激活和损失函数
输出的层具有 10 个单元,其后是softmax激活层。 这 10 个单元对应于 10 个可能的标签,类或类别。 可以用数学方式表示softmax激活,如以下等式所示:
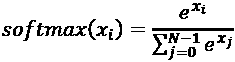 (Equation 1.3.7)
(Equation 1.3.7)
该方程适用于所有N = 10输出,x[i]对于i = 0, 1, ..., 9作最终预测。 softmax的概念非常简单。 通过对预测进行归一化,将输出压缩为概率。 在此,每个预测输出都是该索引是给定输入图像的正确标签的概率。 所有输出的所有概率之和为 1.0。 例如,当softmax层生成预测时,它将是一个 10 维一维张量,看起来像以下输出:
[3.57351579e-11 7.08998016e-08
2.30154569e-07 6.35787558e-07
5.57471187e-11 4.15353840e-09
3.55973775e-16 9.99995947e-01
1.29531730e-09 3.06023480e-06]
预测输出张量建议输入图像的索引具有最高概率,因此将为 7。 numpy.argmax()方法可用于确定具有最高值的元素的索引。
输出激活层还有其他选择,例如linear,sigmoid或tanh。 linear激活是一种恒等函数。 它将其输入复制到其输出。 sigmoid函数更具体地是,称为逻辑 Sigmoid。 如果预测张量的元素将独立地映射在 0.0 和 1.0 之间,则将使用此方法。 与softmax中不同,预测张量的所有元素的总和不限于 1.0。 例如,sigmoid用作情感预测(从 0.0 到 1.0、0.0 不好,1.0 很好)或图像生成(0.0 映射到像素级别 0 和 1.0 映射到像素 255)的最后一层 。
tanh函数将其输入映射在 -1.0 到 1.0 的范围内。 如果输出可以同时以正值和负值摆幅,则这一点很重要。 tanh函数在循环神经网络的内部层中更普遍使用,但也已用作输出层激活。 如果在输出激活中使用 tanh 代替sigmoid,则必须适当缩放使用的数据。 例如,不是使用x = x / 255缩放[0.0, 1.0]范围内的每个灰度像素,而是使用x = (x - 127.5) / 127.5将其分配在[-1.0, 1.0]范围内。
下图“图 1.3.6”显示了sigmoid和tanh函数。 数学上,Sigmoid 可以用以下公式表示:
 (Equation 1.3.5)
(Equation 1.3.5)

图 1.3.6:Sigmoid 和正切图
预测张量距单热地面真值向量有多远称为损失。 损失函数的一种类型是mean_squared_error(MSE),或者是目标或标签与预测之间差异的平方的平均值。 在当前示例中,我们使用categorical_crossentropy。 它是目标或标签乘积与每个类别的预测对数之和的负数。 Keras 中还有其他损失函数,例如mean_absolute_error和binary_crossentropy。“表 1.3.2”总结了的常见损失函数。
| 损失函数 | 公式 |
|---|---|
mean_squared_error |
 |
mean_absolute_error |
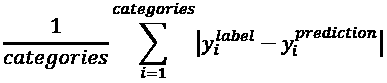 |
categorical_crossentropy |
 |
binary_crossentropy |
 |
表 1.3.2:常见损失函数汇总。 类别是指标签和预测中的类别数(例如:MNIST 为 10)。 所示的损失方程式仅适用于一个输出。 平均损失值是整个批量的平均值。
损失函数的选择不是任意的,而应作为模型正在学习的标准。 对于按类别进行分类,在softmax激活层之后,categorical_crossentropy或mean_squared_error是一个不错的选择。 binary_crossentropy损失函数通常在sigmoid激活层之后使用,而mean_squared_error是tanh输出的选项。
在下一部分中,我们将讨论优化算法以最小化我们在此处讨论的损失函数。
优化
通过优化,目标是使损失函数最小化。 这个想法是,如果将损失减少到可接受的水平,则该模型将间接学习将输入映射到输出的函数。 表现指标用于确定模型是否了解了基础数据分布。 Keras 中的默认指标是损失。 在训练,验证和测试期间,还可以包括其他指标,例如准确率。 准确率是基于地面真实性的正确预测的百分比或分数。 在深度学习中,还有许多其他表现指标。 但是,它取决于模型的目标应用。 在文献中,报告了测试数据集上训练后的模型的表现指标,用于与其他深度学习模型进行比较。
在 Keras 中,优化器有个选择。 最常用的优化器是随机梯度下降(SGD),自适应矩(Adam)和均方根传播(RMSprop)。 每个优化器均具有可调参数,例如学习率,动量和衰减。 Adam 和 RMSprop 是具有自适应学习率的 SGD 的变体。 在提出的分类器网络中,使用了 Adam,因为它具有最高的测试精度。
SGD 被认为是最基本的优化程序。 它是演算中梯度下降的简单版本。 在梯度下降(GD)中,追踪下坡函数的曲线可找到最小值,就像在山谷中下坡直至到达底部一样。
GD 算法如图 1.3.7 所示。 假设x是被调整以找到y的最小值(例如,损失函数)的参数(例如,权重)。 从x = -0.5的任意点开始。 梯度dy/dx = -2.0。 GD 算法强加x然后更新为x = -0.5 - ε(-2.0)。 x的新值等于旧值,再加上ε缩放的梯度的相反值。 小数字ε是指学习率。 如果ε = 0.01,则x的新值为 -0.48。 GD 是迭代执行的。 在每一步,y都将接近其最小值。 在x = 0.5时,dy/dx = 0。 GD 已找到y = -1.25的绝对最小值。 梯度建议不要进一步改变x。
学习率的选择至关重要。 大的ε值可能找不到最小值,因为搜索只会在最小值附近来回摆动。 一方面,在找到最小值之前,较大的ε值可能需要进行大量迭代。 在有多个最小值的情况下,搜索可能会陷入局部最小值。

图 1.3.7:GD 类似于在函数曲线上向下走直到到达最低点。 在此图中,全局最小值为x = 0.5。
多个极小值的示例可以在“图 1.3.8”中看到。 如果由于某种原因从图的左侧开始搜索并且学习率很小,则 GD 很可能会发现x = -1.51是最小值 。 GD 无法在x = 1.66时找到全局最小值。 具有足够值的学习率将使 GD 可以克服x = 0.0的问题。
在深度学习实践中,通常建议从更高的学习率开始(例如,从 0.1 到 0.001),并随着损失接近最小值而逐渐降低学习率。

图 1.3.8:具有 2 个最小值的函数图,x = -1.51和x = 1.66。 还显示了该函数的导数。
GD 通常不用于深度神经网络,因为遇到数百万个要训练的参数很常见。 执行完整的 GD 在计算上效率低下。 而是使用 SGD。 在 SGD 中,选择一小批样本以计算下降的近似值。 参数(例如权重和偏差)可通过以下公式进行调整:

在该等式中,θ和g = 1/m ᐁ[θ] ΣL分别是损失函数的参数和梯度张量。g由损失函数的偏导数计算得出。 出于 GPU 优化的目的,建议最小批量大小为 2 的幂。 在建议的网络中,batch_size = 128。
“公式 1.3.8”计算最后一层参数更新。 那么,我们如何调整前几层的参数呢? 在这种情况下,应用微分链规则将导数传播到较低层并相应地计算梯度。 该算法在深度学习中称为反向传播。 反向传播的详细信息超出了本书的范围。 但是,可以在这里找到很好的在线参考。
由于优化是基于微分的,因此得出损失函数的重要标准是它必须平滑或可微。 当引入新的损失函数时,这是要牢记的重要约束。
给定训练数据集,损失函数的选择,优化器和正则化器,现在可以通过调用fit()函数来训练模型:
# loss function for one-hot vector
# use of adam optimizer
# accuracy is a good metric for classification tasks model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
# train the network
model.fit(x_train, y_train, epochs=20, batch_size=batch_size)
这是 Keras 的另一个有用函数。 通过仅提供x和y数据,要训练的周期数和批量大小,fit()完成了其余工作。 在其他深度学习框架中,这转化为多项任务,例如以适当的格式准备输入和输出数据,加载,监视等等。 尽管所有这些都必须在for循环内完成,但在 Keras 中,一切都只需要一行即可完成。
在fit()函数中,一个周期是整个训练数据的完整采样。 batch_size参数是每个训练步骤要处理的输入数量的样本大小。 为了完成一个周期,fit()将处理等于训练数据集大小的步数除以批量大小再加上 1,以补偿任何小数部分。
训练模型后,我们现在可以评估其表现。
表现评估
至此,MNIST 数字分类器的模型现已完成。 表现评估将是的下一个关键步骤,以确定提议的训练模型是否已提出令人满意的解决方案。 将模型训练 20 个时间段就足以获得可比较的表现指标。
下表“表 1.3.3”列出了不同的网络配置和相应的表现指标。 在“层”下,显示第 1 到第 3 层的单元数。对于每个优化器,将使用tf.keras中的默认参数。 可以观察到改变正则化器,优化器和每层单元数的效果。“表 1.3.3”中的另一个重要观察结果是,更大的网络不一定会转化为更好的表现。
在训练和测试数据集的准确率方面,增加此网络的深度不会显示任何其他好处。 另一方面,较少的单元(例如 128)也可能会降低测试和训练的准确率。 删除正则器后,将在99.93%处获得最佳的训练精度,并且每层使用 256 个单元。 但是,由于网络过拟合,测试精度在98.0%时要低得多。
最高的测试精度是使用 Adam 优化器和98.5%处的Dropout(0.45)。 从技术上讲,鉴于其训练精度为99.39%,仍然存在某种程度的过拟合。 对于256-512-256,Dropout(0.45)和 SGD,在98.2%时,训练和测试精度均相同。 同时去除正则化和 ReLU 层会导致其表现最差。 通常,我们会发现Dropout层比l2具有更好的表现。
下表演示了调整期间典型的深度神经网络表现:
| 层 | 正则化函数 | 优化器 | ReLU | 训练准确率(%) | 测试准确率(%) |
|---|---|---|---|---|---|
| 256-256-256 | 没有 | SGD | 没有 | 93.65 | 92.5 |
| 256-256-256 | L2(0.001) | SGD | 是 | 99.35 | 98.0 |
| 256-256-256 | L2(0.01) | SGD | 是 | 96.90 | 96.7 |
| 256-256-256 | 没有 | SGD | 是 | 99.93 | 98.0 |
| 256-256-256 | 丢弃(0.4) | SGD | 是 | 98.23 | 98.1 |
| 256-256-256 | 丢弃(0.45) | SGD | 是 | 98.07 | 98.1 |
| 256-256-256 | 丢弃(0.5) | SGD | 是 | 97.68 | 98.1 |
| 256-256-256 | 丢弃(0.6) | SGD | 是 | 97.11 | 97.9 |
| 256-512-256 | 丢弃(0.45) | SGD | 是 | 98.21 | 98.2 |
| 512-512-512 | 丢弃(0.2) | SGD | 是 | 99.45 | 98.3 |
| 512-512-512 | 丢弃(0.4) | SGD | 是 | 98.95 | 98.3 |
| 512-1024-512 | 丢弃(0.45) | SGD | 是 | 98.90 | 98.2 |
| 1024-1024-1024 | 丢弃(0.4) | SGD | 是 | 99.37 | 98.3 |
| 256-256-256 | 丢弃(0.6) | Adam | 是 | 98.64 | 98.2 |
| 256-256-256 | 丢弃(0.55) | Adam | 是 | 99.02 | 98.3 |
| 256-256-256 | 丢弃(0.45) | Adam | 是 | 99.39 | 98.5 |
| 256-256-256 | 丢弃(0.45) | RMSprop | 是 | 98.75 | 98.1 |
| 128-128-128 | 丢弃(0.45) | Adam | 是 | 98.70 | 97.7 |
表 1.3.3 不同的 MLP 网络配置和表现指标
示例指示需要改进网络架构。 在下一节讨论了 MLP 分类器模型摘要之后,我们将介绍另一个 MNIST 分类器。 下一个模型基于 CNN,并证明了测试准确率的显着提高。
模型摘要
使用 Keras 库为我们提供了一种快速的机制,可以通过调用以下方法来仔细检查模型描述:
model.summary()
下面的“列表 1.3.3”显示了所建议网络的模型摘要。 它总共需要 269,322 个参数。 考虑到我们具有对 MNIST 数字进行分类的简单任务,这一点非常重要。 MLP 的参数效率不高。 可以通过关注如何计算感知器的输出,从“图 1.3.4”计算参数的数量。 从输入到密集层:784 × 256 + 256 = 200,960。 从第一密集层到第二密集层:256 × 256 + 256 = 65,792。 从第二个密集层到输出层:10 × 256 + 10 = 2,570。 总数是269,322。
“列表 1.3.3”:MLP MNIST 数字分类器模型的摘要:
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 256) 200960
activation_1 (Activation) (None, 256) 0
dropout_1 (Dropout) (None, 256) 0
dense_2 (Dense) (None, 256) 65792
activation_2 (Activation) (None, 256) 0
dropout_2 (Dropout) (None, 256) 0
dense_3 (Dense) (None, 10) 2750
activation_3 (Activation) (None, 10) 0
=================================================================
Total params: 269,322
Trainable params: 269,322
Non-trainable params: 0
验证网络的另一种方法是通过调用:
plot_model(model, to_file='mlp-mnist.png', show_shapes=True)
“图 1.3.9”显示了该图。 您会发现这类似于summary()的结果,但是以图形方式显示了每个层的互连和 I/O。
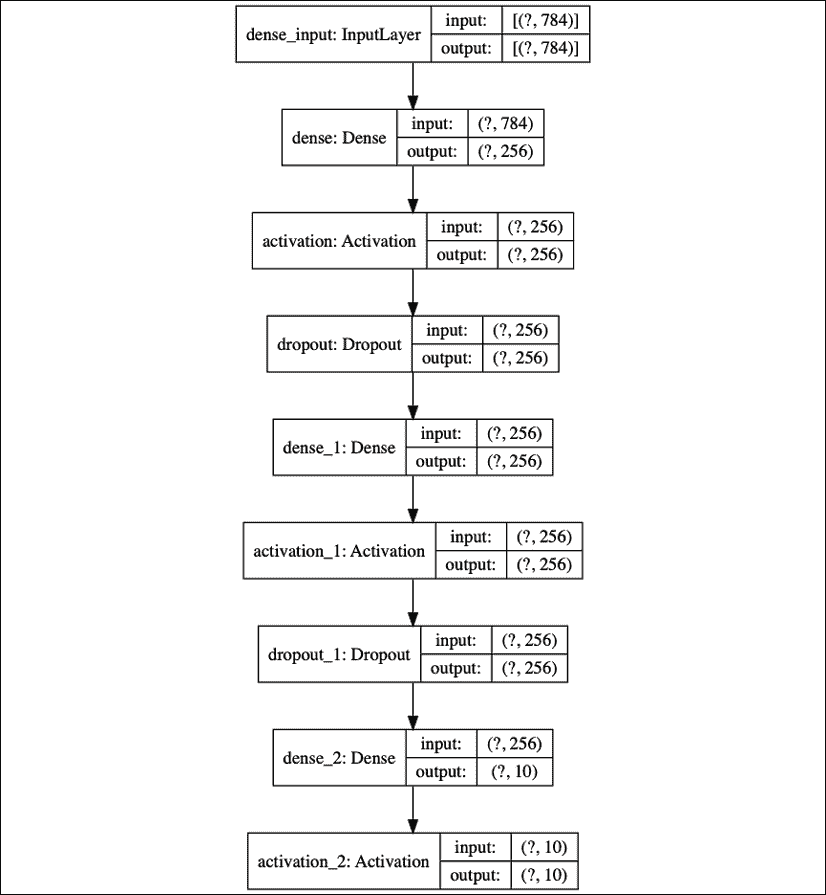
图 1.3.9:MLP MNIST 数字分类器的图形描述
在总结了我们模型的之后,到此结束了我们对 MLP 的讨论。 在下一部分中,我们将基于 CNN 构建 MNIST 数字分类器模型。
4. 卷积神经网络(CNN)
现在,我们将进入第二个人工神经网络 CNN。 在本节中,我们将解决相同的 MNIST 数字分类问题,但这一次使用 CNN。
“图 1.4.1”显示了我们将用于 MNIST 数字分类的 CNN 模型,而其实现在“列表 1.4.1”中进行了说明。 实现 CNN 模型将需要对先前模型进行一些更改。 现在,输入张量不再具有输入向量,而具有新尺寸(height,width,channels)或(image_size,image_size,1)=(28,28 ,1)用于 MNIST 灰度图像。 需要调整训练和测试图像的大小以符合此输入形状要求。

图 1.4.1:用于 MNIST 数字分类的 CNN 模型
实现上图:
“列表 1.4.1”:cnn-mnist-1.4.1.py
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.datasets import mnist
# load mnist dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# compute the number of labels
num_labels = len(np.unique(y_train))
# convert to one-hot vector
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# input image dimensions
image_size = x_train.shape[1]
# resize and normalize
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
# image is processed as is (square grayscale)
input_shape = (image_size, image_size, 1)
batch_size = 128
kernel_size = 3
pool_size = 2
filters = 64
dropout = 0.2
# model is a stack of CNN-ReLU-MaxPooling
model = Sequential()
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu'))
model.add(MaxPooling2D(pool_size))
model.add(Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu'))
model.add(Flatten())
# dropout added as regularizer
model.add(Dropout(dropout))
# output layer is 10-dim one-hot vector
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.summary()
plot_model(model, to_file='cnn-mnist.png', show_shapes=True)
# loss function for one-hot vector
# use of adam optimizer
# accuracy is good metric for classification tasks
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train the network
model.fit(x_train, y_train, epochs=10, batch_size=batch_size)
_, acc = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))
的主要更改是Conv2D层的使用。 ReLU激活函数已经是Conv2D的参数。 当模型中包含batch normalization层时,可以将ReLU函数作为Activation层使用。 Batch normalization用于深层 CNN,因此可以利用较大的学习率而不会引起训练过程中的不稳定。
卷积
如果在 MLP 模型中,单元数量表示密集层,则核表示 CNN 操作。 如图“图 1.4.2”所示,可以将核可视化为矩形补丁或窗口,该补丁或窗口从左到右,从上到下在整个图像中滑动。 此操作称为卷积。 它将输入图像转换成特征映射,该特征映射表示核从输入图像中学到的内容。 然后将特征映射转换为后续层中的另一个特征映射,依此类推。 每个Conv2D生成的特征映射的数量由filters参数控制。

图 1.4.2:3×3 核与 MNIST 数字图像卷积。
在步骤t[n]和t[n + 1]中显示了卷积,其中核向右移动了 1 个像素 。
卷积中涉及的计算显示在“图 1.4.3”中:
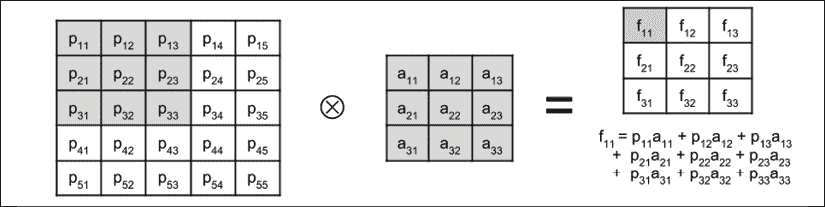
图 1.4.3:卷积运算显示如何计算特征映射的一个元素
为简单起见,显示了应用了3×3核的3×3输入图像(或输入特征映射)。 卷积后显示结果特征映射。 特征映射中一个元素的值被加阴影。 您会注意到,结果特征映射小于原始输入图像的,这是因为卷积仅在有效元素上执行。 核不能超出映像的边界。 如果输入的尺寸应与输出特征映射相同,则Conv2D接受选项padding='same'。 输入在其边界周围填充零,以在卷积后保持尺寸不变。
池化操作
最后的更改是添加了MaxPooling2D层以及参数pool_size=2。 MaxPooling2D压缩每个特征映射。 每个大小为pool_size × pool_size的补丁都减少为 1 个特征映射点。 该值等于补丁中的最大特征点值。 下图显示了MaxPooling2D的两个补丁:

图 1.4.4:MaxPooling2D操作。 为简单起见,输入特征映射为4×4,结果为2×2特征映射。
MaxPooling2D的意义在于特征映射尺寸的减小,这转化为感受野尺寸的增加。 例如,在MaxPooling2D(2)之后,2×2 核现在大约与4×4补丁卷积。 CNN 学会了针对不同接收场大小的一组新的特征映射。
还有其他合并和压缩方式。 例如,要使MaxPooling2D(2)的尺寸减少 50%,AveragePooling2D(2)会取一个补丁的平均值而不是找到最大值。 交叉卷积Conv2D(strides=2,…)在卷积过程中将跳过每两个像素,并且仍具有相同的 50% 缩小效果。 每种还原技术的有效性都有细微的差异。
在Conv2D和MaxPooling2D中,pool_size和kernel都可以是非正方形的。 在这些情况下,必须同时指定行和列的大小。 例如,pool_ size = (1, 2)和kernel = (3, 5)。
最后一个MaxPooling2D操作的输出是一堆特征映射。 Flatten的作用是,将特征映射的栈转换为适用于Dropout或Dense层的向量格式,类似于 MLP 模型输出层。
在下一部分中,我们将评估经过训练的 MNIST CNN 分类器模型的表现。
表现评估和模型摘要
如“列表 1.4.2”中所示,“列表 1.4.1”中的 CNN 模型在 80,226 处需要较少数量的参数,而使用 MLP 层时需要 269,322 个参数。 conv2d_1层具有 640 个参数,因为每个核具有3×3 = 9个参数,并且 64 个特征映射中的每一个都有一个核,一个偏置参数。 其他卷积层的参数数量可以类似的方式计算。
“列表 1.4.2”:CNN MNIST 数字分类器的摘要
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 64) 640
max_pooling2d_1 (MaxPooiling2) (None, 13, 13, 64) 0
conv2d_2 (Conv2D) (None, 11, 11, 64) 36928
max_pooling2d_2 (MaxPooiling2) (None, 5.5, 5, 64) 0
conv2d_3 (Conv2D) (None, 3.3, 3, 64) 36928
flatten_1 (Flatten) (None, 576) 0
dropout_1 (Dropout) (None, 576) 0
dense_1 (Dense) (None, 10) 5770
activation_1 (Activation) (None, 10) 0
===================================================================
Total params: 80,266
Trainable params: 80,266
Non-trainable params: 0
“图 1.4.5”:显示了 CNN MNIST 数字分类器的图形表示形式。
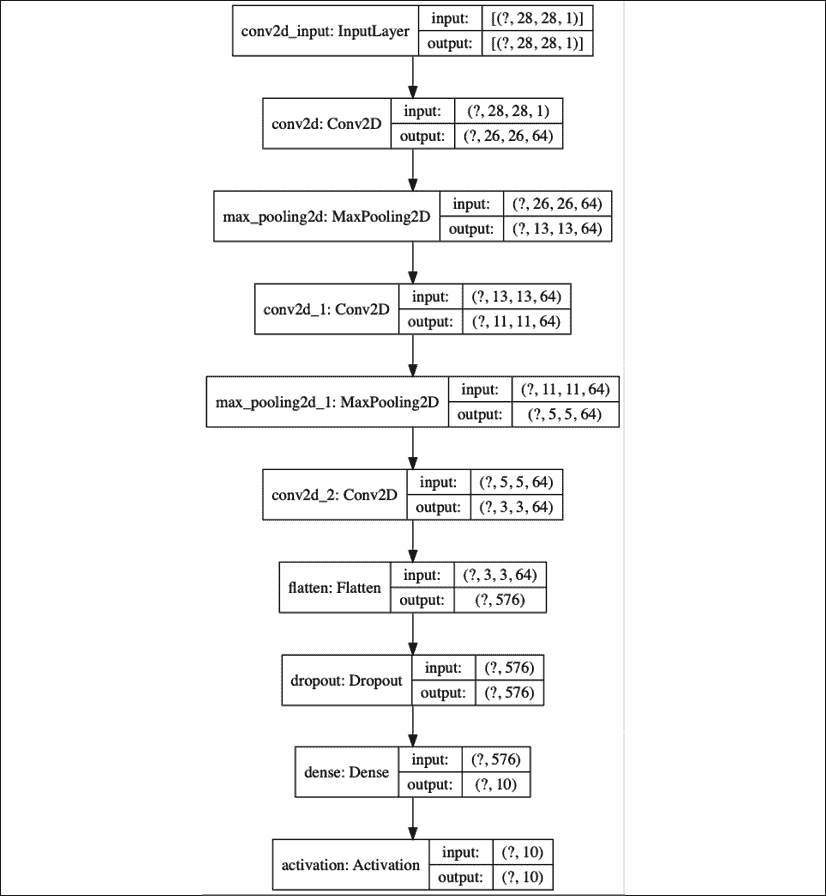
图 1.4.5:CNN MNIST 数字分类器的图形描述
“表 1.4.1”显示了 99.4% 的最大测试准确率,这对于使用带有dropout=0.2的 Adam 优化器的每层具有 64 个特征映射的 3 层网络可以实现。 CNN 比 MLP 具有更高的参数效率,并且具有更高的准确率。 同样,CNN 也适合从顺序数据,图像和视频中学习表示形式。
| 层 | 优化器 | 正则化函数 | 训练准确率(%) | 测试准确率(%) |
| --- | --- | --- | --- | --- | --- |
| 64-64-64 | SGD | 丢弃(0.2) | 97.76 | 98.50 |
| 64-64-64 | RMSprop | 丢弃(0.2) | 99.11 | 99.00 |
| 64-64-64 | Adam | 丢弃(0.2) | 99.75 | 99.40 |
| 64-64-64 | Adam | 丢弃(0.4) | 99.64 | 99.30 |
表 1.4.1:CNN MNIST 数字分类器的不同 CNN 网络配置和表现指标。
看了 CNN 并评估了训练好的模型之后,让我们看一下我们将在本章中讨论的最终核心网络:RNN。
5. 循环神经网络(RNN)
现在,我们来看一下三个人工神经网络中的最后一个,即 RNN。
RNN 是网络的序列,适用于学习顺序数据的表示形式,例如自然语言处理(NLP)中的文本或仪器中的传感器数据流 。 尽管每个 MNIST 数据样本本质上都不是顺序的,但不难想象每个图像都可以解释为像素行或列的序列。 因此,基于 RNN 的模型可以将每个 MNIST 图像作为 28 个元素的输入向量序列进行处理,时间步长等于 28。下面的清单在“图 1.5.1”中显示了 RNN 模型的代码:

图 1.5.1:用于 MNIST 数字分类的 RNN 模型
“列表 1.5.1”:rnn-mnist-1.5.1.py
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, SimpleRNN
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.datasets import mnist
# load mnist dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# compute the number of labels
num_labels = len(np.unique(y_train))
# convert to one-hot vector
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# resize and normalize
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1, image_size, image_size])
x_test = np.reshape(x_test,[-1, image_size, image_size])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
input_shape = (image_size, image_size)
batch_size = 128
units = 256
dropout = 0.2
# model is RNN with 256 units, input is 28-dim vector 28 timesteps
model = Sequential()
model.add(SimpleRNN(units=units,
dropout=dropout,
input_shape=input_shape))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.summary()
plot_model(model, to_file='rnn-mnist.png', show_shapes=True)
# loss function for one-hot vector
# use of sgd optimizer
# accuracy is good metric for classification tasks
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# train the network
model.fit(x_train, y_train, epochs=20, batch_size=batch_size)
_, acc = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))
RNN 分类器与之前的两个模型之间有两个主要区别。 首先是input_shape = (image_size, image_size),它实际上是input_ shape = (timesteps, input_dim)或时间步长的input_dim维向量序列。 其次是使用SimpleRNN层以units=256表示 RNN 单元。 units变量代表输出单元的数量。 如果 CNN 是通过输入特征映射上的核卷积来表征的,则 RNN 输出不仅是当前输入的函数,而且是先前输出或隐藏状态的函数。 由于前一个输出也是前一个输入的函数,因此当前输出也是前一个输出和输入的函数,依此类推。 Keras 中的SimpleRNN层是真实 RNN 的简化版本。 以下等式描述了SimpleRNN的输出:
 (Equation 1.5.1)
(Equation 1.5.1)
在此等式中,b是偏差,而W和U被称为循环核(先前输出的权重)和核(当前输入的权重) ), 分别。 下标t用于指示序列中的位置。 对于具有units=256的SimpleRNN层,参数总数为256 + 256×256 + 256×28 = 72,960,对应于b,W和个贡献。
下图显示了用于分类任务的SimpleRNN和 RNN 的图。 使SimpleRNN比 RNN 更简单的是缺少输出值o[t] = Vh[t] + c在计算softmax函数之前:

图 1.5.2:SimpleRNN和 RNN 图
与 MLP 或 CNN 相比,RNN 最初可能较难理解。 在 MLP 中,感知器是基本单元。 一旦了解了感知器的概念,MLP 就是感知器的网络。 在 CNN 中,核是一个补丁或窗口,可在特征映射中滑动以生成另一个特征映射。 在 RNN 中,最重要的是自环的概念。 实际上只有一个单元。
出现多个单元的错觉是因为每个时间步都有一个单元,但实际上,除非网络展开,否则它只是重复使用的同一单元。 RNN 的基础神经网络在单元之间共享。
“列表 1.5.2”中的摘要指示使用SimpleRNN需要较少数量的参数。
“列表 1.5.2”:RNN MNIST 数字分类器的摘要
Layer (type) Output Shape Param #
=================================================================
simple_rnn_1 (SimpleRNN) (None, 256) 72960
dense_1 (Dense) (None, 10) 2570
activation_1 (Activation) (None, 10) 36928
=================================================================
Total params: 75,530
Trainable params: 75,530
Non-trainable params: 0
“图 1.5.3”显示了 RNN MNIST 数字分类器的图形描述。 该模型非常简洁:
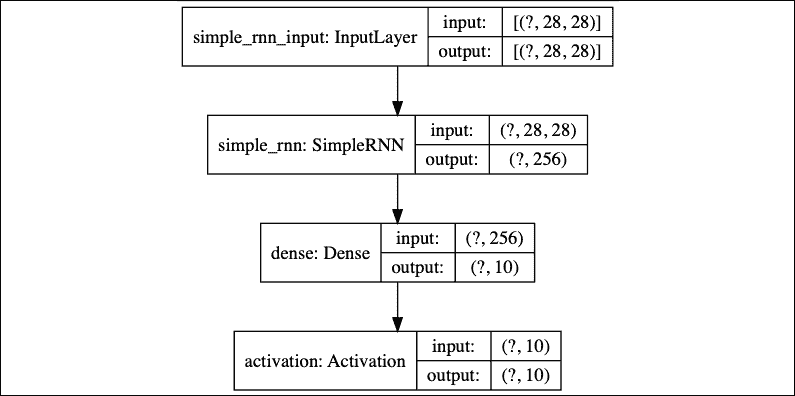
图 1.5.3:RNN MNIST 数字分类器图形说明
“表 1.5.1”显示 SimpleRNN 在所呈现的网络中具有最低的准确率:
| 层 | 优化器 | 正则化函数 | 训练准确率(%) | 测试准确率(%) |
| --- | --- | --- | --- | --- | --- |
| 256 | SGD | 丢弃(0.2) | 97.26 | 98.00 |
| 256 | RMSprop | 丢弃(0.2) | 96.72 | 97.60 |
| 256 | Adam | 丢弃(0.2) | 96.79 | 97.40 |
| 512 | SGD | 丢弃(0.2) | 97.88 | 98.30 |
表 1.5.1:不同的SimpleRNN网络配置和表现指标
在许多深度神经网络中,更常使用 RNN 家族的其他成员。 例如,机器翻译和问答问题都使用了长短期记忆(LSTM)。 LSTM 解决了长期依赖或记住与当前输出相关的过去信息的问题。
与 RNN 或SimpleRNN不同,LSTM 单元的内部结构更为复杂。“图 1.5.4”显示了 LSTM 的示意图。 LSTM 不仅使用当前输入和过去的输出或隐藏状态,还引入了一个单元状态s[t],该状态将信息从一个单元传送到另一个单元。 单元状态之间的信息流由三个门控制f[t],i[t]和q[t]。 这三个门的作用是确定应保留或替换哪些信息,以及过去对当前单元状态或输出有贡献的信息量以及过去和当前的输入。 我们不会在本书中讨论 LSTM 单元内部结构的细节。 但是,可以在这个页面上找到 LSTM 的直观指南。
LSTM()层可以用作SimpleRNN()的嵌入式替代。 如果 LSTM 对于手头的任务过于苛刻,则可以使用更简单的版本,称为门控循环单元(GRU)。 GRU 通过将单元状态和隐藏状态组合在一起来简化 LSTM。 GRU 还将门数量减少了一个。 GRU()函数也可以用作SimpleRNN()的直接替代品。
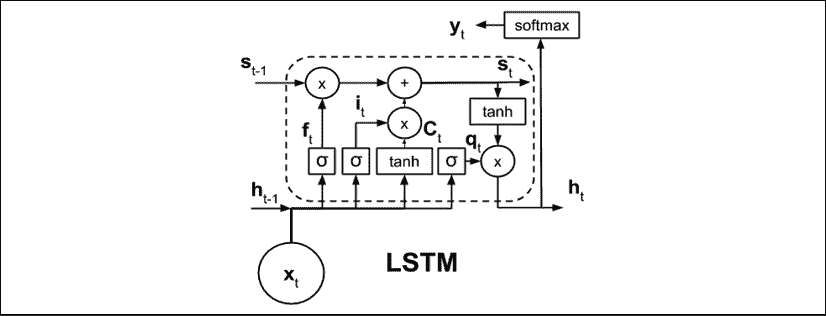
图 1.5.4:LSTM 图。为了清楚起见,未显示参数。
还有许多其他方法可以配置 RNN。 一种方法是制作双向 RNN 模型。 默认情况下,从当前输出仅受过去状态和当前输入影响的意义上讲,RNN 是单向的。
在双向 RNN 中,未来状态还可以通过允许信息向后流动来影响当前状态和过去状态。 根据收到的新信息,根据需要更新过去的输出。 可以通过调用包装器函数使 RNN 双向。 例如,双向 LSTM 的实现是Bidirectional(LSTM())。
对于所有类型的 RNN,增加单元数量也将增加容量。 但是,增加容量的另一种方法是堆叠 RNN 层。 尽管应注意,但作为一般经验法则,只有在需要时才应增加模型的容量。 容量过大可能会导致过拟合,结果可能导致训练时间延长和预测期间的表现降低。
6. 总结
本章概述了三种深度学习模型(MLP,RNN,CNN),并介绍了 TensorFlow 2 tf.keras,这是一个用于快速开发,训练和测试适合于生产环境的深度学习模型的库。 还讨论了 Keras 的顺序 API。 在下一章中,将介绍函数式 API,这将使我们能够构建更复杂的模型,专门用于高级深度神经网络。
本章还回顾了深度学习的重要概念,例如优化,正则化和损失函数。 为了便于理解,这些概念是在 MNIST 数字分类的背景下提出的。
还讨论了使用人工神经网络(特别是 MLP,CNN 和 RNN)进行 MNIST 数字分类的不同解决方案,它们是深度神经网络的重要组成部分,并讨论了它们的表现指标。
了解了深度学习概念以及如何将 Keras 用作工具之后,我们现在可以分析高级深度学习模型。 在下一章讨论了函数式 API 之后,我们将继续执行流行的深度学习模型。 随后的章节将讨论选定的高级主题,例如自回归模型(自编码器,GAN,VAE),深度强化学习,对象检测和分段以及使用互信息的无监督学习。 随附的 Keras 代码实现将在理解这些主题方面发挥重要作用。
7. 参考
Chollet, François. Keras (2015). https://github.com/keras-team/keras.LeCun, Yann, Corinna Cortes, and C. J. Burges. MNIST handwritten digit database. AT&T Labs [Online]. Available: http://yann.lecun.com/exdb/mnist2 (2010).
二、深度神经网络
在本章中,我们将研究深度神经网络。 这些网络在更具挑战性的数据集,如 ImageNet,CIFAR10 和 CIFAR100。 为简洁起见,我们仅关注两个网络: ResNet [2] [4]和 DenseNet [5]。 尽管我们会更加详细,但重要的是花一点时间介绍这些网络。
ResNet 引入了残差学习的概念,使残障学习能够通过解决深度卷积网络中消失的梯度问题(在第 2 节中讨论)来构建非常深的网络。
DenseNet 允许每个卷积直接访问输入和较低层的特征映射,从而进一步改进了 ResNet。 通过利用瓶颈和过渡层,还可以在深层网络中将参数的数量保持为较低。
但是,为什么这些是两个模型,而不是其他? 好吧,自从引入它们以来,已经有无数的模型,例如 ResNeXt [6]和 WideResNet [7],它们受到这两个网络使用的技术的启发。 同样,在了解 ResNet 和 DenseNet 的情况下,我们将能够使用他们的设计指南来构建我们自己的模型。 通过使用迁移学习,这也将使我们能够将预训练的 ResNet 和 DenseNet 模型用于我们自己的目的,例如对象检测和分割。 仅出于这些原因,以及与 Keras 的兼容性,这两个模型非常适合探索和补充本书的高级深度学习范围。
尽管本章的重点是深度神经网络; 在本章中,我们将讨论 Keras 的重要功能,称为函数式 API。 该 API 充当在tf.keras中构建网络的替代方法,使我们能够构建更复杂的网络,而这是顺序模型 API 无法实现的。 我们之所以专注于此 API 的原因是,它将成为构建诸如本章重点介绍的两个之类的深度网络的非常有用的工具。 建议您先完成“第 1 章”,“Keras 的高级深度学习介绍”,然后再继续本章,因为我们将参考在本章中探讨的入门级代码和概念,我们将它们带入了更高的层次。
本章的目的是介绍:
- Keras 中的函数式 API,以及探索运行该 API 的网络示例
tf.keras中的深度残差网络(ResNet 版本 1 和 2)实现tf.keras中密集连接卷积网络(DenseNet)的实现- 探索两种流行的深度学习模型,即 ResNet 和 DenseNet
让我们开始讨论函数式 API。
1. 函数式 API
在我们首先在“第 1 章”,“Keras 高级深度学习入门”的顺序模型 API 中,一层堆叠在另一层之上。 通常,将通过其输入和输出层访问模型。 我们还了解到,如果我们发现自己想要在网络中间添加辅助输入,或者甚至想在最后一层之前提取辅助输出,则没有简单的机制。
这种模式也有缺点。 例如,它不支持类似图的模型或行为类似于 Python 函数的模型。 此外,在两个模型之间共享层也很困难。函数式 API 解决了这些局限性,这就是为什么它对于想要使用深度学习模型的任何人来说都是至关重要的工具的原因。
函数式 API 遵循以下两个概念:
- 层是接受张量作为参数的实例。 一层的输出是另一个张量。 为了构建模型,层实例是通过输入和输出张量彼此链接的对象。 这与在顺序模型中堆叠多个层有类似的最终结果。 但是,使用层实例会使模型更容易具有辅助或多个输入和输出,因为每个层的输入/输出将易于访问。
- 模型是一个或多个输入张量和输出张量之间的函数。 在模型输入和输出之间,张量是通过层输入和输出张量彼此链接的层实例。 因此,模型是一个或多个输入层和一个或多个输出层的函数。 该模型实例将数据从输入流到输出流的形式的计算图形式化。
在完成函数式 API 模型的构建之后,训练和评估将由顺序模型中使用的相同函数执行。 为了说明,在函数式 API 中,二维卷积层Conv2D带有 32 个过滤器,并且x作为层输入张量,y作为层输出张量可以写为:
y = Conv2D(32)(x)
我们也可以堆叠多层来构建模型。 例如,我们可以使用函数式 API 重写 MNIST cnn-mnist-1.4.1.py上的卷积神经网络(CNN),如下所示:
“列表 2.1.1”:cnn-functional-2.1.1.py
import numpy as np
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# load MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# from sparse label to categorical
num_labels = len(np.unique(y_train))
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# reshape and normalize input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
input_shape = (image_size, image_size, 1)
batch_size = 128
kernel_size = 3
filters = 64
dropout = 0.3
# use functional API to build cnn layers
inputs = Input(shape=input_shape)
y = Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu')(inputs)
y = MaxPooling2D()(y)
y = Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu')(y)
y = MaxPooling2D()(y)
y = Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu')(y)
# image to vector before connecting to dense layer
y = Flatten()(y)
# dropout regularization
y = Dropout(dropout)(y)
outputs = Dense(num_labels, activation='softmax')(y)
# build the model by supplying inputs/outputs
model = Model(inputs=inputs, outputs=outputs)
# network model in text
model.summary()
# classifier loss, Adam optimizer, classifier accuracy
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train the model with input images and labels
model.fit(x_train,
y_train,
validation_data=(x_test, y_test),
epochs=20,
batch_size=batch_size)
# model accuracy on test dataset
score = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * score[1]))
默认情况下,使用pool_size=2作为参数,因此MaxPooling2D已被删除。
在前面的清单中,每一层都是张量的函数。 每一层生成一个张量作为输出,该张量成为下一层的输入。 要创建此模型,我们可以调用Model()并提供inputs和outputs张量,或者提供张量列表。 其他一切保持不变。
类似于顺序模型,也可以使用fit()和evaluate()函数来训练和评估相同的列表。 实际上,Sequential类是Model类的子类。 我们需要记住,我们在fit()函数中插入了validation_data参数,以查看训练期间验证准确率的进度。 在 20 个周期内,准确率范围从 99.3% 到 99.4%。
创建两输入一输出模型
现在,我们将做一些令人兴奋的事情,创建一个具有两个输入和一个输出的高级模型。 在开始之前,重要的是要知道序列模型 API 是为仅构建 1 输入和 1 输出模型而设计的。
假设发明了一种用于 MNIST 数字分类的新模型,它称为 Y 网络,如图“图 2.1.1”所示。 Y 网络在左 CNN 分支和右 CNN 分支两次使用相同的输入。 网络使用concatenate层合并结果。 合并操作concatenate类似于沿连接轴堆叠两个相同形状的张量以形成一个张量。 例如,沿着最后一个轴连接两个形状为(3, 3, 16)的张量将导致一个形状为(3, 3, 32)的张量。
concatenate层之后的所有其他内容将与上一章的 CNN MNIST 分类器模型相同:Flatten,然后是Dropout,然后是Dense:

图 2.1.1:Y 网络接受两次相同的输入,但是在卷积网络的两个分支中处理输入。 分支的输出使用连接层进行合并。最后一层的预测将类似于上一章的 CNN MNIST 分类器模型。
为了提高“列表 2.1.1”中模型的表现,我们可以提出一些更改。 首先,Y 网络的分支将过滤器数量加倍,以补偿MaxPooling2D()之后特征映射尺寸的减半。 例如,如果第一个卷积的输出为(28, 28, 32),则在最大池化之后,新形状为(14, 14, 32)。 下一个卷积的过滤器大小为 64,输出尺寸为(14, 14, 64)。
其次,尽管两个分支的核大小相同,但右分支使用 2 的扩展率。“图 2.1.2”显示了不同的扩展率对大小为 3 的核的影响。 这个想法是,通过使用扩张率增加核的有效接受域大小,CNN 将使正确的分支能够学习不同的特征映射。 使用大于 1 的扩张速率是一种计算有效的近似方法,可以增加接收场的大小。 这是近似值,因为该核实际上不是成熟的核。 这是有效的,因为我们使用与膨胀率等于 1 相同的操作数。
要了解接受域的概念,请注意,当核计算特征映射的每个点时,其输入是前一层特征映射中的补丁,该补丁也取决于其前一层特征映射。 如果我们继续将此依赖关系一直跟踪到输入图像,则核将依赖于称为接收场的图像补丁。
我们将使用选项padding='same'来确保使用扩张的 CNN 时不会出现负张量。 通过使用padding='same',我们将使输入的尺寸与输出特征映射相同。 这是通过用零填充输入以确保输出的大小相同来实现的。

图 2.1.2:通过从 1 增加膨胀率,有效的核接受域大小也增加了
“列表 2.1.2”的cnn-y-network-2.1.2.py显示了使用函数式 API 的 Y 网络的实现。 两个分支由两个for循环创建。 两个分支期望输入形状相同。 两个for循环将创建两个Conv2D-Dropout-MaxPooling2D的三层栈。 虽然我们使用concatenate层组合了左右分支的输出,但我们还可以利用tf.keras的其他合并函数,例如add,dot和multiply。 合并函数的选择并非纯粹是任意的,而必须基于合理的模型设计决策。
在 Y 网络中,concatenate不会丢弃特征映射的任何部分。 取而代之的是,我们让Dense层确定如何处理连接的特征映射。
“列表 2.1.2”:cnn-y-network-2.1.2.py
import numpy as np
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.utils import plot_model
# load MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# from sparse label to categorical
num_labels = len(np.unique(y_train))
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# reshape and normalize input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
input_shape = (image_size, image_size, 1)
batch_size = 32
kernel_size = 3
dropout = 0.4
n_filters = 32
# left branch of Y network
left_inputs = Input(shape=input_shape)
x = left_inputs
filters = n_filters
# 3 layers of Conv2D-Dropout-MaxPooling2D
# number of filters doubles after each layer (32-64-128)
for i in range(3):
x = Conv2D(filters=filters,
kernel_size=kernel_size,
padding='same',
activation='relu')(x)
x = Dropout(dropout)(x)
x = MaxPooling2D()(x)
filters *= 2
# right branch of Y network
right_inputs = Input(shape=input_shape)
y = right_inputs
filters = n_filters
# 3 layers of Conv2D-Dropout-MaxPooling2Do
# number of filters doubles after each layer (32-64-128)
for i in range(3):
y = Conv2D(filters=filters,
kernel_size=kernel_size,
padding='same',
activation='relu',
dilation_rate=2)(y)
y = Dropout(dropout)(y)
y = MaxPooling2D()(y)
filters *= 2
# merge left and right branches outputs
y = concatenate([x, y])
# feature maps to vector before connecting to Dense
y = Flatten()(y)
y = Dropout(dropout)(y)
outputs = Dense(num_labels, activation='softmax')(y)
# build the model in functional API
model = Model([left_inputs, right_inputs], outputs)
# verify the model using graph
plot_model(model, to_file='cnn-y-network.png', show_shapes=True)
# verify the model using layer text description
model.summary()
# classifier loss, Adam optimizer, classifier accuracy
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# train the model with input images and labels
model.fit([x_train, x_train],
y_train,
validation_data=([x_test, x_test], y_test),
epochs=20,
batch_size=batch_size)
# model accuracy on test dataset
score = model.evaluate([x_test, x_test],
y_test,
batch_size=batch_size,
verbose=0)
print("\nTest accuracy: %.1f%%" % (100.0 * score[1]))
退后一步,我们可以注意到 Y 网络期望有两个输入用于训练和验证。 输入是相同的,因此提供了[x_train, x_train]。
在 20 个周期的过程中,Y 网络的准确率为 99.4% 至 99.5%。 与 3 叠 CNN 相比,这是一个微小的改进,CNN 的精度在 99.3% 到 99.4% 之间。 但是,这是以更高的复杂度和两倍以上的参数数量为代价的。
下图“图 2.1.3”显示了 Keras 理解并由plot_model()函数生成的 Y 网络的架构:
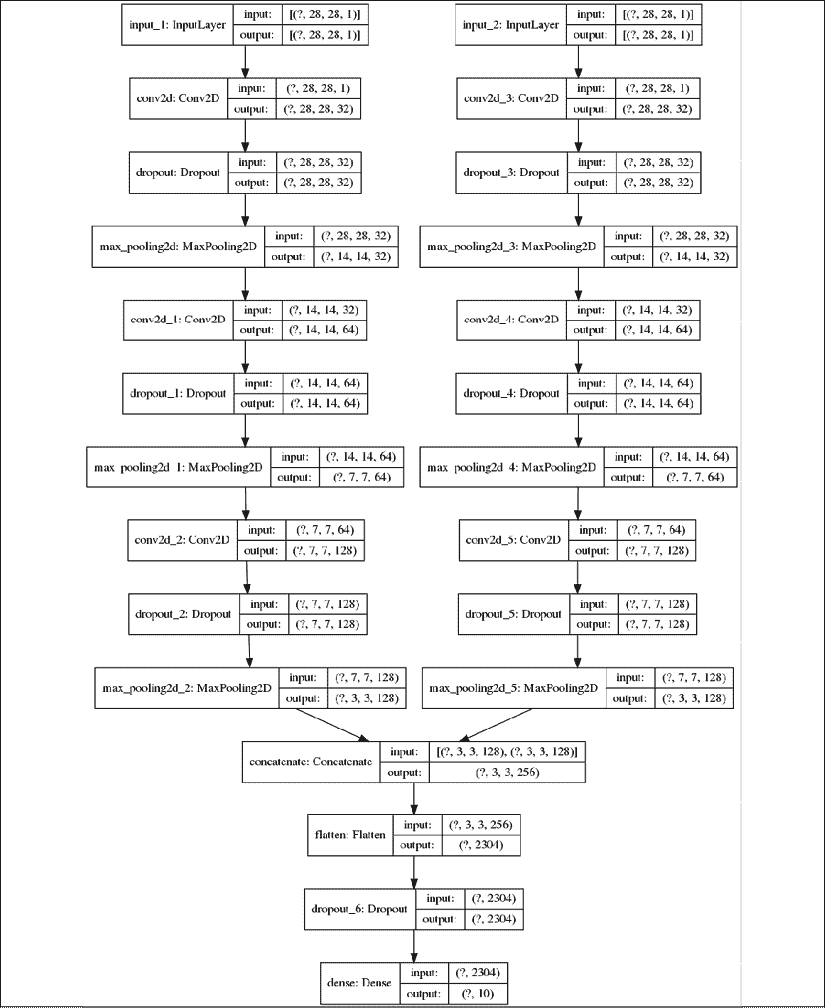
图 2.1.3:清单 2.1.2 中实现的 CNN Y 网络
总结我们对函数式 API 的了解。 我们应该花时间记住本章的重点是构建深度神经网络,特别是 ResNet 和 DenseNet。 因此,我们只讨论构建它们所需的函数式 API 材料,因为涵盖整个的 API 将超出本书的范围。 话虽如此,让我们继续讨论 ResNet。
有关函数式 API 的其他信息,请阅读这里。
2. 深度残差网络(ResNet)
深度网络的一个主要优点是,它们具有从输入图和特征映射学习不同级别表示的能力。 在分类,分割,检测和许多其他计算机视觉问题中,学习不同的特征映射通常可以提高性能。
但是,您会发现训练深层网络并不容易,因为在反向传播过程中,梯度可能会随着浅层中的深度消失(或爆炸)。“图 2.2.1”说明了梯度消失的问题。 通过从输出层向所有先前层的反向传播来更新网络参数。 由于反向传播是基于链法则的,因此当梯度到达浅层时,梯度会逐渐减小。 这是由于小数的乘法,尤其是对于小损失函数和参数值。
乘法运算的数量将与网络深度成正比。 还要注意的是,如果梯度降低,则不会适当更新参数。
因此,网络将无法提高其表现。

图 2.2.1:深层网络中的一个常见问题是,在反向传播过程中,梯度在到达浅层时会消失。
为了减轻深度网络中梯度的降级,ResNet 引入了深度残差学习框架的概念。 让我们分析一个块:深度网络的一小部分。
“图 2.2.2”显示了典型 CNN 块和 ResNet 残差块之间的比较。 ResNet 的想法是,为了防止梯度降级,我们将让信息通过快捷连接流到浅层。

图 2.2.2:典型 CNN 中的块与 ResNet 中的块之间的比较。 为了防止反向传播期间梯度的降低,引入了快捷连接。
接下来,我们将在中讨论两个模块之间的差异,以了解更多详细信息。“图 2.2.3”显示了另一个常用的深层网络 VGG [3]和 ResNet 的 CNN 块的更多详细信息。 我们将层特征映射表示为x。 层l的特征映射为x[l]。 在 CNN 层中的操作是 Conv2D 批量规范化(BN)- ReLU。
假设我们以H() = Conv2D-Batch Normalization(BN)-ReLU的形式表示这组操作; 然后:
x[l-1] = H(x[l-2])(公式 2.2.1)
x[l] = H(x[l-1])(方程式 2.2.2)
换句话说,通过H() =Conv2D-Batch Normalization(BN)-ReLU将l-2层上的特征映射转换为x[l-1]。 应用相同的操作集将x[l-1]转换为x[l]。 换句话说,如果我们有一个 18 层的 VGG,则在将输入图像转换为第 18 个层特征映射之前,有 18 个H()操作。
一般而言,我们可以观察到l层输出特征映射仅直接受先前的特征映射影响。 同时,对于 ResNet:
x[l-1] = H(x[l-2])(公式 2.2.3)
x[l] = ReLU(F(x[l-1]) + x[l-2])(公式 2.2.4)

图 2.2.3:普通 CNN 块和残差块的详细层操作
F(x[l-1])由Conv2D-BN制成,这也被称为残差映射。 +符号是快捷方式连接和F(x[l-1])输出之间的张量元素加法。 快捷连接不会增加额外的参数,也不会增加计算复杂度。
可以通过add()合并函数在tf.keras中实现添加操作。 但是,F(x[l-1])和x[l-2]应该具有相同的尺寸。
如果尺寸不同,例如,当更改特征映射尺寸时,我们应该在x[l-2]上进行线性投影以匹配尺寸F([l-1])的含量。 在原始论文中,当特征映射的大小减半时,情况的线性投影是通过Conv2D和 1 strides=2核完成的。
在“第 1 章”,“Keras 高级深度学习”,我们讨论了stride > 1等效于在卷积期间跳过像素。 例如,如果strides=2,则在卷积过程中滑动核时,可以跳过其他每个像素。
前面的“公式 2.2.3”和“公式 2.2.4”都对 ResNet 残余块操作进行建模。 他们暗示,如果可以训练较深的层具有较少的误差,则没有理由为什么较浅的层应具有较高的误差。
知道 ResNet 的基本构建块后,我们就可以设计一个深度残差网络来进行图像分类。 但是,这一次,我们将处理更具挑战性的数据集。
在我们的示例中,我们将考虑 CIFAR10,它是原始论文所基于的数据集之一。 在此示例中,tf.keras提供了一个 API,可以方便地访问 CIFAR10 数据集,如下所示:
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
与 MNIST 一样,CIFAR10 数据集也有 10 个类别。 数据集是对应于飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船和卡车的小型(32×32)RGB 真实世界图像的集合。 10 个类别中的每个类别。“图 2.2.4”显示了来自 CIFAR10 的示例图像。
在数据集中,有 50,000 个标记的训练图像和 10,000 个标记的测试图像用于验证:

图 2.2.4:来自 CIFAR10 数据集的样本图像。 完整的数据集包含 50,000 张标签的训练图像和 10,000 张标签的测试图像以进行验证。
对于 CIFAR10 数据,可以使用“表 2.2.1”中所示的不同网络架构来构建 ResNet。“表 2.2.1”表示我们有三组残差块。 每组具有对应于n个残余块的2n层。32×32的额外层是输入图像的第一层。
| 层 | 输出大小 | 过滤器尺寸 | 操作 |
|---|---|---|---|
| 卷积 | 32 × 32 |
16 | 3 x 3 Conv2D |
| 残差块(1) | 32 × 32 |
 |
|
| 过渡层(1) | 32 × 32 |
{1 x 1 Conv2D, stride = 2} |
|
16 × 16 |
|||
| 残差块(2) | 16 × 16 |
32 |  |
| 过渡层(2) | 16 × 16 |
||
8 × 8 |
|||
| 残差块(3) | 8 × 8 |
64 |  |
| 平均池化 | 1 × 1 |
表 2.2.1:ResNet 网络架构配置
核大小为 3,不同大小的两个特征映射之间的过渡除外,该过渡实现了线性映射。 例如,核大小为 1 的Conv2D和strides=2。 为了与 DenseNet 保持一致,当我们连接两个大小不同的剩余块时,我们将使用项Transition层。
ResNet 使用kernel_initializer='he_normal'以便在进行反向传播时帮助收敛[1]。 最后一层由AveragePooling2D-Flatten-Dense制成。 在这一点上值得注意的是 ResNet 不使用丢弃。 似乎add 合并操作和1 x 1卷积具有自正则化效果。“图 2.2.5”显示了 CIFAR10 数据集的 ResNet 模型架构,如“表 2.2.1”中所述。
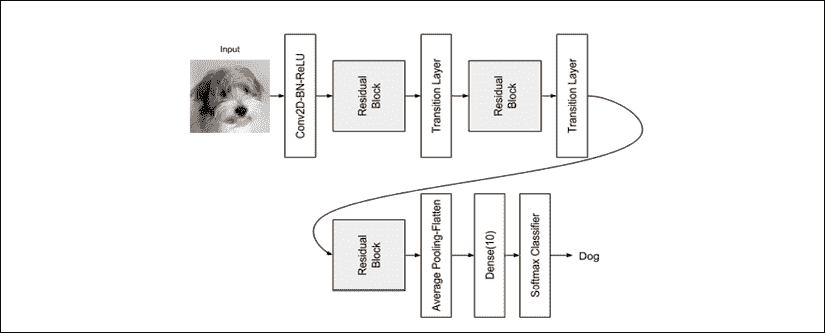
图 2.2.5:用于 CIFAR10 数据集分类的 ResNet 的模型架构
以下代码段显示了tf.keras中的部分 ResNet 实现。 该代码已添加到 Keras GitHub 存储库中。 从“表 2.2.2”(稍后显示)中,我们还可以看到,通过修改n的值,我们可以增加网络的深度。
例如,对于n = 18,我们已经拥有 ResNet110,这是一个具有 110 层的深度网络。 要构建 ResNet20,我们使用n = 3:
n = 3
# model version
# orig paper: version = 1 (ResNet v1),
# improved ResNet: version = 2 (ResNet v2)
version = 1
# computed depth from supplied model parameter n
if version == 1:
depth = n * 6 + 2
elif version == 2:
depth = n * 9 + 2
if version == 2:
model = resnet_v2(input_shape=input_shape, depth=depth)
else:
model = resnet_v1(input_shape=input_shape, depth=depth)
resnet_v1()方法是 ResNet 的模型构建器。 它使用工具函数resnet_layer(),来帮助构建Conv2D-BN-ReLU的栈。
它将称为版本 1,正如我们将在下一节中看到的那样,提出了一种改进的 ResNet,该版本称为 ResNet 版本 2 或 v2。 通过 ResNet,ResNet v2 改进了残差块设计,从而提高了表现。
以下清单显示了resnet-cifar10-2.2.1.py的部分代码,它是 ResNet v1 的tf.keras模型实现。
“列表 2.2.1”:resnet-cifar10-2.2.1.py
def resnet_v1(input_shape, depth, num_classes=10):
"""ResNet Version 1 Model builder [a]
Stacks of 2 x (3 x 3) Conv2D-BN-ReLU
Last ReLU is after the shortcut connection.
At the beginning of each stage, the feature map size is halved
(downsampled) by a convolutional layer with strides=2, while
the number of filters is doubled. Within each stage,
the layers have the same number filters and the
same number of filters.
Features maps sizes:
stage 0: 32x32, 16
stage 1: 16x16, 32
stage 2: 8x8, 64
The Number of parameters is approx the same as Table 6 of [a]:
ResNet20 0.27M
ResNet32 0.46M
ResNet44 0.66M
ResNet56 0.85M
ResNet110 1.7M
Arguments:
input_shape (tensor): shape of input image tensor
depth (int): number of core convolutional layers
num_classes (int): number of classes (CIFAR10 has 10)
Returns:
model (Model): Keras model instance
"""
if (depth - 2) % 6 != 0:
raise ValueError('depth should be 6n+2 (eg 20, 32, in [a])')
# Start model definition.
num_filters = 16
num_res_blocks = int((depth - 2) / 6)
inputs = Input(shape=input_shape)
x = resnet_layer(inputs=inputs)
# instantiate the stack of residual units
for stack in range(3):
for res_block in range(num_res_blocks):
strides = 1
# first layer but not first stack
if stack > 0 and res_block == 0:
strides = 2 # downsample
y = resnet_layer(inputs=x,
num_filters=num_filters,
strides=strides)
y = resnet_layer(inputs=y,
num_filters=num_filters,
activation=None)
# first layer but not first stack
if stack > 0 and res_block == 0:
# linear projection residual shortcut
# connection to match changed dims
x = resnet_layer(inputs=x,
num_filters=num_filters,
kernel_size=1,
strides=strides,
activation=None,
batch_normalization=False)
x = add([x, y])
x = Activation('relu')(x)
num_filters *= 2
# add classifier on top.
# v1 does not use BN after last shortcut connection-ReLU
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
# instantiate model.
model = Model(inputs=inputs, outputs=outputs)
return model
ResNet 在n的各种值上的表现显示在“表 2.2.2”中。
| 层 | n |
CIFAR10 的准确率百分比(原始论文) | CIFAR10 的准确率百分比(本书) |
|---|---|---|---|
| ResNet20 | 3 | 91.25 | 92.16 |
| ResNet32 | 5 | 92.49 | 92.46 |
| ResNet44 | 7 | 92.83 | 92.50 |
| ResNet56 | 9 | 93.03 | 92.71 |
| ResNet110 | 18 | 93.57 | 92.65 |
表 2.2.2:针对不同的 n 值,使用 CIFAR10 验证的 ResNet 架构
与 ResNet 的原始实现有一些细微的差异。 特别是,我们不使用 SGD,而是使用 Adam。 这是因为 ResNet 更容易与 Adam 融合。 我们还将使用学习率调度器lr_schedule(),以便将lr的减少量从默认的1e-3缩短为 80、120、160 和 180 个周期。 在训练期间的每个周期之后,都会将lr_schedule()函数作为回调变量的一部分进行调用。
每当验证准确率方面取得进展时,另一个回调将保存检查点。 训练深层网络时,保存模型或权重检查点是一个好习惯。 这是因为训练深度网络需要大量时间。
当您想使用网络时,您只需要做的就是重新加载检查点,然后恢复经过训练的模型。 这可以通过调用tf.keras load_model()来完成。 包含lr_reducer()函数。 如果指标在排定的减少之前已稳定在上,则如果在patience = 5周期之后验证损失没有改善,则此回调将以参数中提供的某个因子来降低学习率。
调用model.fit()方法时,会提供回调变量。 与原始论文相似,tf.keras实现使用数据扩充ImageDataGenerator()来提供其他训练数据作为正则化方案的一部分。 随着训练数据数量的增加,概括性将会提高。
例如,简单的数据扩充就是翻转一条狗的照片,如图“图 2.2.6”(horizontal_flip = True)所示。 如果它是狗的图像,则翻转的图像仍然是狗的图像。 您还可以执行其他变换,例如缩放,旋转,变白等等,并且标签将保持不变:

图 2.2.6:一个简单的数据扩充就是翻转原始图像
准确复制原始论文的实现通常很困难。 在本书中,我们使用了不同的优化器和数据扩充。 这可能会导致本书中所实现的tf.keras ResNet 和原始模型中的表现略有不同。
在 ResNet [4]的第二篇论文发布之后,本节中介绍的原始模型为,称为 ResNet v1。 改进的 ResNet 通常称为 ResNet v2,我们将在下一部分讨论。
3. ResNet v2
ResNet v2 的改进主要体现在残块中各层的排列中,如图“图 2.3.1”所示。
ResNet v2 的主要变化是:
- 使用
1 x 1 – 3 x 3 – 1 × 1的栈BN-ReLU-Conv2D - 批量标准化和 ReLU 激活先于二维卷积

图 2.3.1:ResNet v1 和 ResNet v2 之间的剩余块比较
ResNet v2 也以与resnet-cifar10-2.2.1.py相同的代码实现,如“列表 2.2.1”所示:
“列表 2.2.1”:resnet-cifar10-2.2.1.py
def resnet_v2(input_shape, depth, num_classes=10):
"""ResNet Version 2 Model builder [b]
Stacks of (1 x 1)-(3 x 3)-(1 x 1) BN-ReLU-Conv2D or
also known as bottleneck layer.
First shortcut connection per layer is 1 x 1 Conv2D.
Second and onwards shortcut connection is identity.
At the beginning of each stage,
the feature map size is halved (downsampled)
by a convolutional layer with strides=2,
while the number of filter maps is
doubled. Within each stage, the layers have
the same number filters and the same filter map sizes.
Features maps sizes:
conv1 : 32x32, 16
stage 0: 32x32, 64
stage 1: 16x16, 128
stage 2: 8x8, 256
Arguments:
input_shape (tensor): shape of input image tensor
depth (int): number of core convolutional layers
num_classes (int): number of classes (CIFAR10 has 10)
Returns:
model (Model): Keras model instance
"""
if (depth - 2) % 9 != 0:
raise ValueError('depth should be 9n+2 (eg 110 in [b])')
# start model definition.
num_filters_in = 16
num_res_blocks = int((depth - 2) / 9)
inputs = Input(shape=input_shape)
# v2 performs Conv2D with BN-ReLU
# on input before splitting into 2 paths
x = resnet_layer(inputs=inputs,
num_filters=num_filters_in,
conv_first=True)
# instantiate the stack of residual units
for stage in range(3):
for res_block in range(num_res_blocks):
activation = 'relu'
batch_normalization = True
strides = 1
if stage == 0:
num_filters_out = num_filters_in * 4
# first layer and first stage
if res_block == 0:
activation = None
batch_normalization = False
else:
num_filters_out = num_filters_in * 2
# first layer but not first stage
if res_block == 0:
# downsample
strides = 2
# bottleneck residual unit
y = resnet_layer(inputs=x,
num_filters=num_filters_in,
kernel_size=1,
strides=strides,
activation=activation,
batch_normalization=batch_normalization,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_in,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_out,
kernel_size=1,
conv_first=False)
if res_block == 0:
# linear projection residual shortcut connection
# to match changed dims
x = resnet_layer(inputs=x,
num_filters=num_filters_out,
kernel_size=1,
strides=strides,
activation=None,
batch_normalization=False)
x = add([x, y])
num_filters_in = num_filters_out
# add classifier on top.
# v2 has BN-ReLU before Pooling
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
# instantiate model.
model = Model(inputs=inputs, outputs=outputs)
return model
下面的代码显示了 ResNet v2 的模型构建器。 例如,要构建 ResNet110 v2,我们将使用n = 12和version = 2:
n = 12
# model version
# orig paper: version = 1 (ResNet v1),
# improved ResNet: version = 2 (ResNet v2)
version = 2
# computed depth from supplied model parameter n
if version == 1:
depth = n * 6 + 2
elif version == 2:
depth = n * 9 + 2
if version == 2:
model = resnet_v2(input_shape=input_shape, depth=depth)
else:
model = resnet_v1(input_shape=input_shape, depth=depth)
ResNet v2 的准确率显示在下面的“表 2.3.1”中:
| 层 | n |
CIFAR10 的准确率百分比(原始论文) | CIFAR10 的准确率百分比(本书) |
|---|---|---|---|
| ResNet56 | 9 | 不适用 | 93.01 |
| ResNet110 | 18 | 93.63 | 93.15 |
表 2.3.1:在 CIFAR10 数据集上验证的 ResNet v2 架构
在 Keras 应用包中,已实现某些 ResNet v1 和 v2 模型(例如:50、101、152)。 这些是替代的实现方式,其中预训练的权重不清楚,可以轻松地重新用于迁移学习。 本书中使用的模型在层数方面提供了灵活性。
我们已经完成了对最常用的深度神经网络之一 ResNet v1 和 v2 的讨论。 在以下部分中,将介绍另一种流行的深度神经网络架构 DenseNet。
4. 紧密连接的卷积网络(DenseNet)
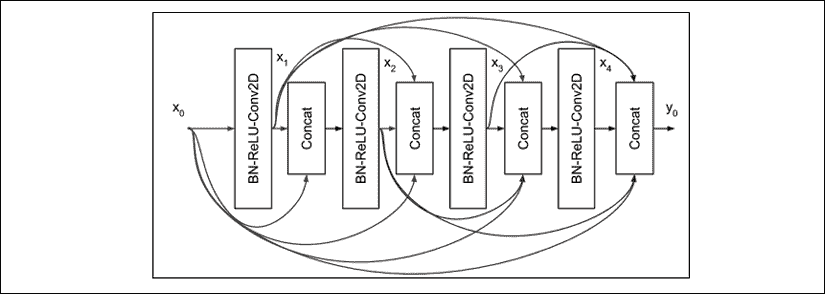
图 2.4.1:DenseNet 中的一个 4 层Dense块,每层的输入均由所有先前的特征映射组成。
DenseNet 使用另一种方法攻击梯度消失的问题。 代替使用快捷方式连接,所有先前的特征映射都将成为下一层的输入。 上图显示了一个Dense块中密集互连的示例。
为简单起见,在此图中,我们仅显示四层。 注意,层l的输入是所有先前特征映射的连接。 如果用操作H表示BN-ReLU-Conv2D(x),则层l的输出为:
x[l] = H(x[0], x[1], x[2], x[l-1])(公式 2.4.1)
Conv2D使用大小为 3 的核。每层生成的特征映射的数量称为增长率k。 通常,在 Huang 等人的论文“密集连接卷积网络”中,也使用k = 12,但是k = 24 [5]。 因此,如果特征映射x[0]的数量为k[0],则“图 2.4.1”中,4 层Dense块的末尾的特征映射总数为4 x k + k[0]。
DenseNet 建议在Dense块之前加上BN-ReLU-Conv2D,以及许多是增长率两倍的特征映射k[0]= 2 xk。 在Dense块的末尾,特征映射的总数将为4 x 12 + 2 x 12 = 72。
在输出层,DenseNet 建议我们在具有softmax层的Dense()之前执行平均池化。 如果未使用数据扩充,则必须在Dense块Conv2D之后跟随一个丢弃层。
随着网络的深入,将出现两个新问题。 首先,由于每一层都贡献了k特征映射,因此l层的输入数量为(l – 1) x k + k[0]。 特征映射可以在深层中快速增长,从而减慢了计算速度。 例如,对于 101 层网络,对于k = 12,这将是1200 + 24 = 1224。
其次,类似于 ResNet,随着网络的不断深入,特征映射的大小将减小,从而增加核的接收域大小。 如果 DenseNet 在合并操作中使用连接,则必须协调大小上的差异。
为了防止特征映射的数量增加到计算效率低的程度,DenseNet 引入了Bottleneck层,如图“图 2.4.2”所示。 这个想法是,在每次连接之后,现在应用1 x 1卷积,其过滤器大小等于4k。 这种降维技术阻止了Conv2D(3)处理的特征映射的数量快速增加。

图 2.4.2:DenseNet 的 Dense 块中的一层,带有和不带有瓶颈层 BN-ReLU-Conv2D(1)。 为了清楚起见,我们将核大小作为 Conv2D 的参数。
然后Bottleneck层将 DenseNet 层修改为BN-ReLU-Conv2D(1)-BN- ReLU-Conv2D(3),而不仅仅是BN-ReLU-Conv2D(3)。 为了清楚起见,我们将核大小作为Conv2D的参数。 在瓶颈层,每个Conv2D(3)仅处理 4 个k特征映射,而不是(l – 1) x k + k[0]的,对于层l。 例如,对于 101 层网络,最后一个Conv2D(3)的输入仍然是k = 12而不是先前计算的 1224 的 48 个特征映射。
为了解决特征映射大小不匹配的问题,DenseNet 将深度网络划分为多个 Dense 块,这些块通过过渡层连接在一起,如图“图 2.4.3”所示。 在每个Dense块中,特征映射的大小(即宽度和高度)将保持不变。
过渡层的作用是在两个Dense块之间从一个特征映射大小过渡到较小的特征映射大小。 尺寸通常减少一半。 这是通过平均池化层完成的。 例如,默认值为pool_size=2的AveragePooling2D会将大小从(64, 64, 256)减小为(32, 32, 256)。 过渡层的输入是前一个Dense块中最后一个连接层的输出。
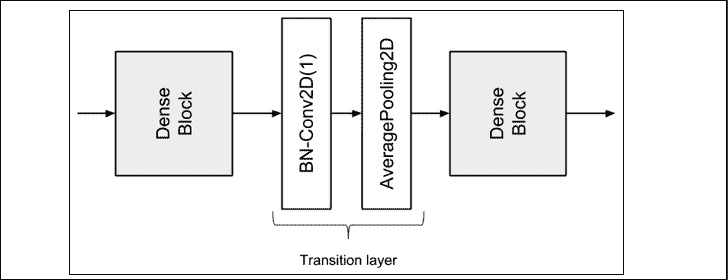
图 2.4.3:两个密集块之间的过渡层
但是,在将特征映射传递到平均池之前,使用Conv2D(1)将其数量减少某个压缩因子0 < θ < 1。DenseNet 在实验中使用θ = 0.5。 例如,如果先前Dense块的最后连接的输出是(64, 64, 512),则在Conv2D(1)之后,特征映射的新尺寸将是(64, 64, 256)。 当压缩和降维放在一起时,过渡层由BN-Conv2D(1)-AveragePooling2D层组成。 实际上,批量归一化在卷积层之前。
现在,我们已经涵盖了 DenseNet 的重要概念。 接下来,我们将为tf.keras中的 CIFAR10 数据集构建并验证 DenseNet-BC。
为 CIFAR10 构建 100 层 DenseNet-BC
现在,我们将要为 CIFAR10 数据集构建一个具有 100 层的 DenseNet-BC(瓶颈压缩), 我们在上面讨论过。
“表 2.4.1”显示了模型配置,而“图 2.4.4”显示了模型架构。 清单为我们展示了具有 100 层的 DenseNet-BC 的部分 Keras 实现。 我们需要注意的是,我们使用RMSprop,因为在使用 DenseNet 时,它的收敛性优于 SGD 或 Adam。
| 层 | 输出大小 | DenseNet-100 BC |
|---|---|---|
| 卷积 | 32 x 32 |
3 x 3 Conv2D |
| 密集块(1) | 32 x 32 |
 |
| 过渡层(1) | 32 x 32 |
 |
16 x 16 |
||
| 密集块(2) | 16 x 16 |
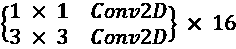 |
| 过渡层(2) | 16 x 16 |
 |
8 x 8 |
||
| 密集块(3) | 8 x 8 |
|
| 平均池化 | 1 x 1 |
8 x 8 AveragePooling2D |
| 分类层 | Flatten-Dense(10)-softmax |
表 2.4.1:100 层的 DenseNet-BC 用于 CIFAR10 分类
将从配置移至架构:
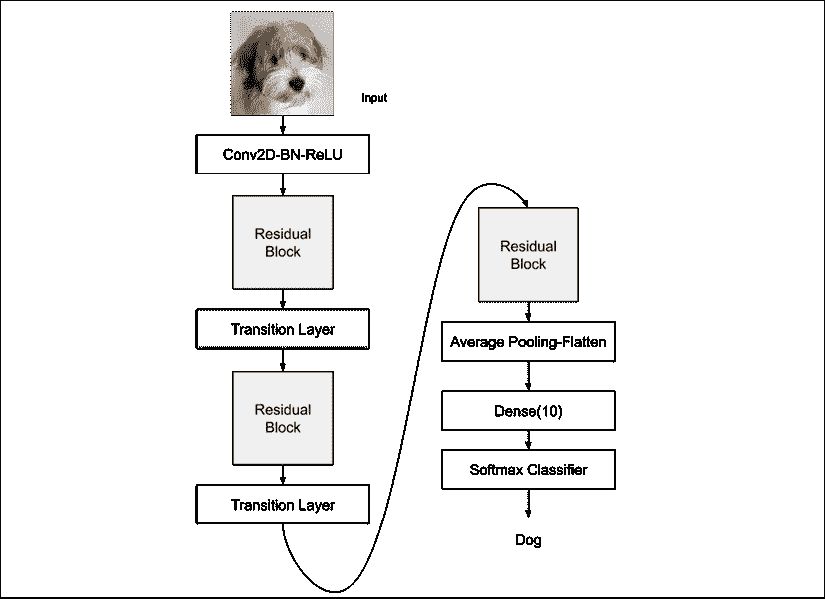
图 2.4.4:用于 CIFAR10 分类的 100 个层的 DenseNet-BC 模型架构
下面“列表 2.4.1”是具有 100 层的 DenseNet-BC 的部分 Keras 实现,如“表 2.4.1”所示。
“列表 2.4.1”:densenet-cifar10-2.4.1.py
# start model definition
# densenet CNNs (composite function) are made of BN-ReLU-Conv2D
inputs = Input(shape=input_shape)
x = BatchNormalization()(inputs)
x = Activation('relu')(x)
x = Conv2D(num_filters_bef_dense_block,
kernel_size=3,
padding='same',
kernel_initializer='he_normal')(x)
x = concatenate([inputs, x])
# stack of dense blocks bridged by transition layers
for i in range(num_dense_blocks):
# a dense block is a stack of bottleneck layers
for j in range(num_bottleneck_layers):
y = BatchNormalization()(x)
y = Activation('relu')(y)
y = Conv2D(4 * growth_rate,
kernel_size=1,
padding='same',
kernel_initializer='he_normal')(y)
if not data_augmentation:
y = Dropout(0.2)(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = Conv2D(growth_rate,
kernel_size=3,
padding='same',
kernel_initializer='he_normal')(y)
if not data_augmentation:
y = Dropout(0.2)(y)
x = concatenate([x, y])
# no transition layer after the last dense block
if i == num_dense_blocks - 1:
continue
# transition layer compresses num of feature maps and # reduces the size by 2
num_filters_bef_dense_block += num_bottleneck_layers * growth_rate
num_filters_bef_dense_block = int(num_filters_bef_dense_block * compression_factor)
y = BatchNormalization()(x)
y = Conv2D(num_filters_bef_dense_block,
kernel_size=1,
padding='same',
kernel_initializer='he_normal')(y)
if not data_augmentation:
y = Dropout(0.2)(y)
x = AveragePooling2D()(y)
# add classifier on top
# after average pooling, size of feature map is 1 x 1
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
kernel_initializer='he_normal',
activation='softmax')(y)
# instantiate and compile model
# orig paper uses SGD but RMSprop works better for DenseNet
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(1e-3),
metrics=['accuracy'])
model.summary()
训练 DenseNet 的tf.keras实现 200 个周期,可以达到 93.74% 的准确率,而本文中报道的是 95.49%。 使用数据扩充。 我们在 ResNet v1 / v2 中为 DenseNet 使用了相同的回调函数。
对于更深的层,必须使用 Python 代码上的表来更改growth_rate和depth变量。 但是,如本文所述,以深度 190 或 250 训练网络将需要大量时间。 为了给我们一个训练时间的想法,每个周期在 1060Ti GPU 上运行大约一个小时。 与 ResNet 相似,Keras 应用包具有针对 DenseNet 121 及更高版本的预训练模型。
DenseNet 完成了我们对深度神经网络的讨论。 与 ResNet 一起,这两个网络已成为许多下游任务中不可或缺的特征提取器网络。
5. 总结
在本章中,我们介绍了函数式 API 作为使用tf.keras构建复杂的深度神经网络模型的高级方法。 我们还演示了如何使用函数式 API 来构建多输入单输出 Y 网络。 与单分支 CNN 网络相比,该网络具有更高的准确率。 在本书的其余部分中,我们将发现在构建更复杂和更高级的模型时必不可少的函数式 API。 例如,在下一章中,函数式 API 将使我们能够构建模块化编码器,解码器和自编码器。
我们还花费了大量时间探索两个重要的深度网络 ResNet 和 DenseNet。 这两个网络不仅用于分类,而且还用于其他领域,例如分段,检测,跟踪,生成和视觉语义理解。 在“第 11 章”,“对象检测”和“第 12 章”,“语义分割”中,我们将使用 ResNet 进行对象检测和分割。 我们需要记住,与仅仅遵循原始实现相比,更仔细地了解 ResNet 和 DenseNet 中的模型设计决策至关重要。 这样,我们就可以将 ResNet 和 DenseNet 的关键概念用于我们的目的。
6. 参考
Kaiming He et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. Proceedings of the IEEE international conference on computer vision, 2015 (https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/He_Delving_Deep_into_ICCV_2015_paper.pdfspm=5176.100239.blogcont55892.28.pm8zm1&file=He_Delving_Deep_into_ICCV_2015_paper.pdf).Kaiming He et al. Deep Residual Learning for Image Recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016a (http://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf).Karen Simonyan and Andrew Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR, 2015 (https://arxiv.org/pdf/1409.1556/).Kaiming He et al. Identity Mappings in Deep Residual Networks. European Conference on Computer Vision. Springer International Publishing, 2016b (https://arxiv.org/pdf/1603.05027.pdf).Gao Huang et al. Densely Connected Convolutional Networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 2017 (http://openaccess.thecvf.com/content_cvpr_2017/papers/Huang_Densely_Connected_Convolutional_CVPR_2017_paper.pdf).Saining Xie et al. Aggregated Residual Transformations for Deep Neural Networks. Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017 (http://openaccess.thecvf.com/content_cvpr_2017/papers/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.pdf).Zagoruyko, Sergey, and Nikos Komodakis. "Wide residual networks." arXiv preprint arXiv:1605.07146 (2016).
三、自编码器
在上一章“第 2 章”,“深度神经网络”中,我们介绍了深度神经网络的概念。 现在,我们将继续研究自编码器,它是一种神经网络架构,试图找到给定输入数据的压缩表示形式。
与前面的章节相似,输入数据可以采用多种形式,包括语音,文本,图像或视频。 自编码器将尝试查找表示形式或一段代码,以便对输入数据执行有用的转换。 例如,当对自编码器进行降噪处理时,神经网络将尝试找到可用于将噪声数据转换为干净数据的代码。 嘈杂的数据可以是带有静态噪声的录音形式,然后将其转换为清晰的声音。 自编码器将自动从数据中自动学习代码,而无需人工标记。 这样,自编码器可以在无监督学习算法下分类为。
在本书的后续章节中,我们将研究生成对抗网络(GAN)和变分自编码器(VAE) 也是无监督学习算法的代表形式。 这与我们在前几章中讨论过的监督学习算法相反,后者需要人工标注。
总之,本章介绍:
- 自编码器的原理
- 如何使用
tf.keras实现自编码器 - 去噪和着色自编码器的实际应用
让我们从了解自编码器是什么以及自编码器的原理开始。
1. 自编码器的原理
自编码器以最简单的形式通过尝试将输入复制到输出中来学习表示形式或代码。 但是,使用自编码器并不像将输入复制到输出那样简单。 否则,神经网络将无法发现输入分布中的隐藏结构。
自编码器将输入分布编码为低维张量,通常采用向量形式。 这将近似通常称为潜在表示,代码或向量的隐藏结构。 该处理构成编码部分。 然后,潜在向量将由解码器部分解码,以恢复原始输入。
由于潜向量是输入分布的低维压缩表示,因此应该期望解码器恢复的输出只能近似输入。 输入和输出之间的差异可以通过损失函数来衡量。
但是为什么我们要使用自编码器? 简而言之,自编码器在原始形式或更复杂的神经网络的一部分中都有实际应用。
它们是了解深度学习的高级主题的关键工具,因为它们为我们提供了适合密度估计的低维数据表示。 此外,可以有效地对其进行处理以对输入数据执行结构化操作。 常见的操作包括去噪,着色,特征级算术,检测,跟踪和分割,仅举几例。
在本节中,我们将介绍自编码器的原理。 我们将使用前几章介绍的带有 MNIST 数据集的自编码器。
首先,我们需要意识到自编码器具有两个运算符,它们是:
- 编码器:这会将输入
x转换为低维潜向量z = f(x)。 由于潜向量是低维的,编码器被迫仅学习输入数据的最重要特征。 例如,在 MNIST 数字的情况下,要学习的重要特征可能包括书写风格,倾斜角度,笔触圆度,厚度等。 从本质上讲,这些是代表数字 0 至 9 所需的最重要的信息位。 - 解码器:这尝试从潜在向量
g(z) = x中恢复输入。
尽管潜向量的维数较小,但它的大小足以使解码器恢复输入数据。
解码器的目标是使x_tilde尽可能接近x。 通常,编码器和解码器都是非线性函数。z的尺寸是可以表示的重要特征数量的度量。 该维数通常比输入维数小得多,以提高效率,并为了限制潜在代码仅学习输入分布的最显着属性[1]。
当潜码的维数明显大于x时,自编码器倾向于记忆输入。
合适的损失函数L(x, x_tilde)衡量输入x与输出(即)恢复后的输入x_tilde的相异程度。 如下式所示,均方误差(MSE)是此类损失函数的一个示例:
 (Equation 3.1.1)
(Equation 3.1.1)
在此示例中,m是输出尺寸(例如,在 MNIST 中,m = width × height × channels = 28 × 28 × 1 = 784)。x[i]和x_tilde[i]分别是x和x_tilde的元素。 由于损失函数是输入和输出之间差异的量度,因此我们可以使用替代的重建损失函数,例如二进制交叉熵或结构相似性指数(SSIM)。
与其他神经网络类似,自编码器会在训练过程中尝试使此误差或损失函数尽可能小。“图 3.1.1”显示了一个自编码器。 编码器是将输入x压缩为低维潜向量z的函数。 该潜向量代表输入分布的重要特征。 然后,解码器尝试以x_tilde的形式从潜向量中恢复原始输入。

图 3.1.1:自编码器的框图
为了将自编码器置于上下文中,x可以是尺寸为28×28×1 = 784的 MNIST 数字。编码器将输入转换为低维的z,可以是 16 维潜在向量。 解码器将尝试从z中以x_tilde的形式恢复输入。
在视觉上,每个 MNIST 数字x看起来都类似于x_tilde。“图 3.1.2”向我们演示了此自编码过程。

图 3.1.2:带有 MNIST 数字输入和输出的自编码器。 潜在向量为 16 角
我们可以看到,虽然解码后的数字 7 并不完全相同,但仍然足够接近。
由于编码器和解码器都是非线性函数,因此我们可以使用神经网络来实现两者。 例如,在 MNIST 数据集中,自编码器可以由 MLP 或 CNN 实现。 通过最小化通过反向传播的损失函数,可以训练自编码器。 与其他神经网络类似,反向传播的要求是损失函数必须是可微的。
如果将输入视为分布,则可以将编码器解释为分布的编码器,p(z | x),将解码器解释为分布的解码器p(x | z)。 自编码器的损失函数表示为:
 (Equation 3.1.2)
(Equation 3.1.2)
损失函数只是意味着我们要在给定潜在向量分布的情况下最大程度地恢复输入分布的机会。 如果假设解码器的输出分布为为高斯,则损失函数归结为 MSE,因为:
 (Equation 3.1.3)
(Equation 3.1.3)
在此示例中,N(x[i]; x_tilde[i], σ²表示平均值为x_tilde[i]且方差为σ²的高斯分布。 假设恒定方差。 假定解码器输出x_tilde[i]是独立的。m是输出尺寸。
了解自编码器背后的原理将有助于我们执行代码。 在下一节中,我们将研究如何使用tf.keras函数式 API 来构建编码器,解码器和自编码器。
2. 使用 Keras 构建自编码器
现在,我们要使用进行一些令人兴奋的事情,使用tf.keras库构建一个自编码器。 为了简单起见,我们将使用 MNIST 数据集作为第一组示例。 然后,自编码器将根据输入数据生成潜向量,并使用解码器恢复输入。 在该第一示例中,潜向量是 16 维。
首先,我们将通过构建编码器来实现自编码器。
“列表 3.2.1”显示了将 MNIST 数字压缩为 16 维潜在向量的编码器。 编码器是两个Conv2D的栈。 最后阶段是具有 16 个单元的Dense层,以生成潜向量。
“列表 3.2.1”:autoencoder-mnist-3.2.1.py
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.layers import Conv2D, Flatten
from tensorflow.keras.layers import Reshape, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import plot_model
from tensorflow.keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
# load MNIST dataset
(x_train, _), (x_test, _) = mnist.load_data()
# reshape to (28, 28, 1) and normalize input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train, [-1, image_size, image_size, 1])
x_test = np.reshape(x_test, [-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# network parameters
input_shape = (image_size, image_size, 1)
batch_size = 32
kernel_size = 3
latent_dim = 16
# encoder/decoder number of CNN layers and filters per layer
layer_filters = [32, 64]
# build the autoencoder model
# first build the encoder model
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
# stack of Conv2D(32)-Conv2D(64)
for filters in layer_filters:
x = Conv2D(filters=filters,
kernel_size=kernel_size,
activation='relu',
strides=2,
padding='same')(x)
# shape info needed to build decoder model
# so we don't do hand computation
# the input to the decoder's first
# Conv2DTranspose will have this shape
# shape is (7, 7, 64) which is processed by
# the decoder back to (28, 28, 1)
shape = K.int_shape(x)
# generate latent vector
x = Flatten()(x)
latent = Dense(latent_dim, name='latent_vector')(x)
# instantiate encoder model
encoder = Model(inputs,
latent,
name='encoder')
encoder.summary()
plot_model(encoder,
to_file='encoder.png',
show_shapes=True)
# build the decoder model
latent_inputs = Input(shape=(latent_dim,), name='decoder_input')
# use the shape (7, 7, 64) that was earlier saved
x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs)
# from vector to suitable shape for transposed conv
x = Reshape((shape[1], shape[2], shape[3]))(x)
# stack of Conv2DTranspose(64)-Conv2DTranspose(32)
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
activation='relu',
strides=2,
padding='same')(x)
# reconstruct the input
outputs = Conv2DTranspose(filters=1,
kernel_size=kernel_size,
activation='sigmoid',
padding='same',
name='decoder_output')(x)
# instantiate decoder model
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
plot_model(decoder, to_file='decoder.png', show_shapes=True)
# autoencoder = encoder + decoder
# instantiate autoencoder model
autoencoder = Model(inputs,
decoder(encoder(inputs)),
name='autoencoder')
autoencoder.summary()
plot_model(autoencoder,
to_file='autoencoder.png',
show_shapes=True)
# Mean Square Error (MSE) loss function, Adam optimizer
autoencoder.compile(loss='mse', optimizer='adam')
# train the autoencoder
autoencoder.fit(x_train,
x_train,
validation_data=(x_test, x_test),
epochs=1,
batch_size=batch_size)
# predict the autoencoder output from test data
x_decoded = autoencoder.predict(x_test)
# display the 1st 8 test input and decoded images
imgs = np.concatenate([x_test[:8], x_decoded[:8]])
imgs = imgs.reshape((4, 4, image_size, image_size))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure()
plt.axis('off')
plt.title('Input: 1st 2 rows, Decoded: last 2 rows')
plt.imshow(imgs, interpolation='none', cmap='gray')
plt.savefig('input_and_decoded.png')
plt.show()
“图 3.2.1”显示了plot_model()生成的架构模型图,与encoder.summary()生成的文本版本相同。 保存最后一个Conv2D的输出形状以计算解码器输入层的尺寸,以便轻松重建 MNIST 图像:shape = K.int_shape(x)。
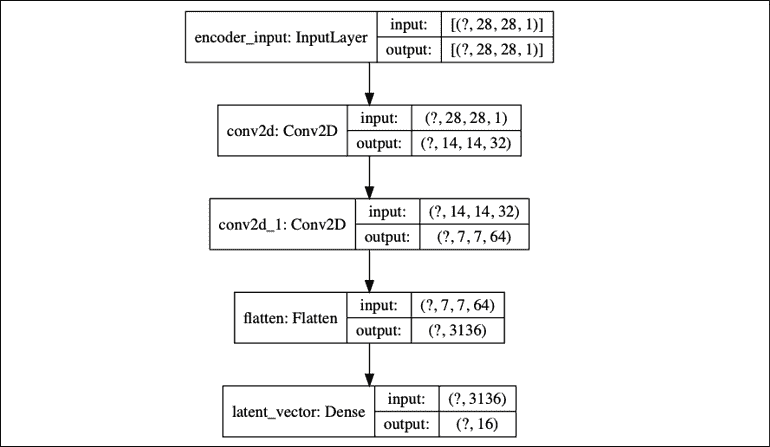
图 3.2.1:编码器模型由Conv2D(32) - Conv2D(64) - Dense(16)组成,以生成低维潜向量
列表 3.2.1 中的解码器对潜在向量进行解压缩,以恢复 MNIST 数字。 解码器输入级是Dense层,它将接受潜在向量。 单元的数量等于从编码器保存的Conv2D输出尺寸的乘积。 这样做是为了便于我们调整Dense层Dense层的输出大小,以最终恢复原始 MNIST 图像尺寸。
解码器由三个Conv2DTranspose的栈组成。 在我们的案例中,我们将使用转置的 CNN(有时称为反卷积),它是解码器中常用的。 我们可以将转置的 CNN(Conv2DTranspose)想象成 CNN 的逆过程。
在一个简单的示例中,如果 CNN 将图像转换为特征映射,则转置的 CNN 将生成给定特征映射的图像。“图 3.2.2”显示了解码器模型:
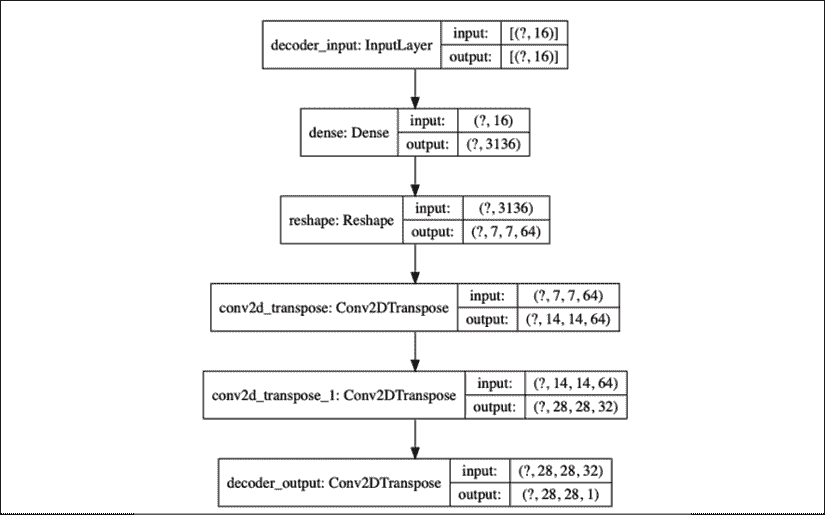
图 3.2.2:解码器模型由Dense(16) - Conv2DTranspose(64) - Conv2DTranspose(32) - Conv2DTranspose(1)组成。 输入是经过解码以恢复原始输入的潜向量
通过将编码器和解码器连接在一起,我们可以构建自编码器。“图 3.2.3”说明了自编码器的模型图:

图 3.2.3:通过将编码器模型和解码器模型结合在一起来构建自编码器模型。 此自编码器有 178 k 个参数
编码器的张量输出也是解码器的输入,该解码器生成自编码器的输出。 在此示例中,我们将使用 MSE 损失函数和 Adam 优化器。 在训练期间,输入与输出x_train相同。 我们应该注意,在我们的示例中,只有几层足以将验证损失在一个周期内驱动到 0.01。 对于更复杂的数据集,我们可能需要更深的编码器和解码器,以及更多的训练时间。
在对自编码器进行了一个周期的验证损失为 0.01 的训练之后,我们能够验证它是否可以对以前从未见过的 MNIST 数据进行编码和解码。“图 3.2.4”向我们展示了来自测试数据和相应解码图像的八个样本:

图 3.2.4:根据测试数据预测自编码器。 前两行是原始输入测试数据。 最后两行是预测数据
除了图像中的轻微模糊之外,我们能够轻松识别出自编码器能够以良好的质量恢复输入。 随着我们训练更多的周期,结果将有所改善。
在这一点上,我们可能想知道:我们如何可视化空间中的潜在向量? 一种简单的可视化方法是强制自编码器使用 2 维潜在向量来学习 MNIST 数字特征。 从那里,我们可以将该潜在向量投影到二维空间上,以查看 MNIST 潜在向量的分布方式。“图 3.2.5”和“图 3.2.6”显示了 MNIST 数字的分布与潜在代码尺寸的关系。
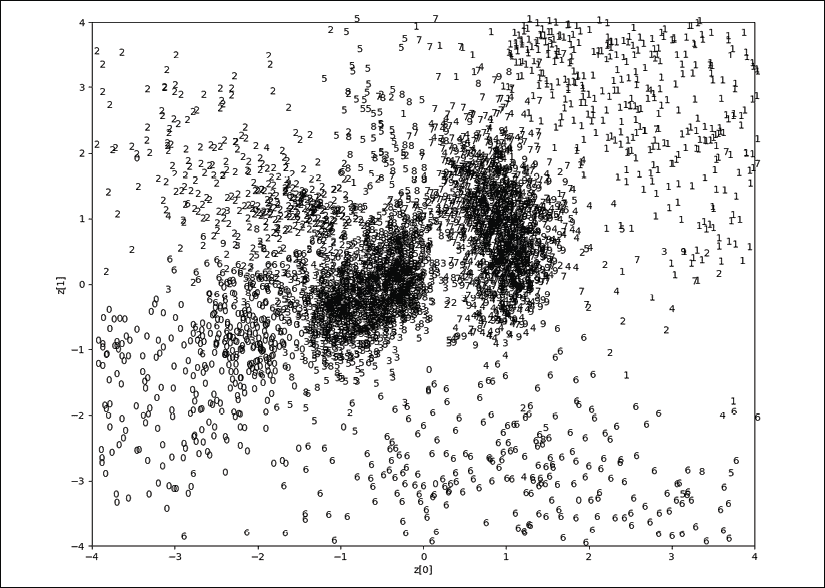
图 3.2.5:MNIST 数字分布与潜在代码尺寸z[0]和z[1]的关系。 原始照片可以在本书的 GitHub 存储库中找到。
在“图 3.2.5”中,我们可以看到特定数字的潜向量聚集在空间的某个区域上。 例如,数字 0 在左下象限中,而数字 1 在右上象限中。 这种群集在图中得到了反映。 实际上,同一图显示了导航或从潜在空间生成新数字的结果,如图“图 3.2.5”所示。
例如,从中心开始,向右上象限改变 2 维潜向量的值,这表明数字从 9 变为 1。这是可以预期的,因为从“图 3.2.5”开始,我们可以看到数字 9 群集的潜在代码值在中心附近,数字 1 群集的潜在代码值在右上象限。
对于“图 3.2.5”和“图 3.2.6”,我们仅研究了每个潜在向量维在 -4.0 和 +4.0 之间的区域:

图 3.2.6:导航 2 维潜在向量空间时生成的数字
从“图 3.2.5”中可以看出,潜在代码分布不是连续的。 理想情况下,应该看起来像一个圆圈,其中到处都有有效值。 由于这种不连续性,因此如果解码潜伏向量,则几乎不会产生任何可识别的数字。
“图 3.2.5”和“图 3.2.6”经过 20 个训练周期后生成。 通过设置latent_dim = 2修改了autoencoder-mnist-3.2.1.py代码。 plot_ results()函数将 MNIST 数字绘制为 2 维潜在向量的函数。 为了方便起见,该程序另存为autoencoder-2dim-mnist-3.2.2.py,其部分代码显示在“列表 3.2.2”中。 其余代码实际上类似于“列表 3.2.1”,在此不再显示。
“列表 3.2.2”:autoencoder-2dim-mnist-3.2.2.py
def plot_results(models,
data,
batch_size=32,
model_name="autoencoder_2dim"):
"""Plots 2-dim latent values as scatter plot of digits
then, plot MNIST digits as function of 2-dim latent vector
Arguments:
models (list): encoder and decoder models
data (list): test data and label
batch_size (int): prediction batch size
model_name (string): which model is using this function
"""
encoder, decoder = models
x_test, y_test = data
xmin = ymin = -4
xmax = ymax = +4
os.makedirs(model_name, exist_ok=True)
filename = os.path.join(model_name, "latent_2dim.png")
# display a 2D plot of the digit classes in the latent space
z = encoder.predict(x_test,
batch_size=batch_size)
plt.figure(figsize=(12, 10))
# axes x and y ranges
axes = plt.gca()
axes.set_xlim([xmin,xmax])
axes.set_ylim([ymin,ymax])
# subsample to reduce density of points on the plot
z = z[0::2]
y_test = y_test[0::2]
plt.scatter(z[:, 0], z[:, 1], marker="")
for i, digit in enumerate(y_test):
axes.annotate(digit, (z[i, 0], z[i, 1]))
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.savefig(filename)
plt.show()
filename = os.path.join(model_name, "digits_over_latent.png")
# display a 30x30 2D manifold of the digits
n = 30
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# linearly spaced coordinates corresponding to the 2D plot
# of digit classes in the latent space
grid_x = np.linspace(xmin, xmax, n)
grid_y = np.linspace(ymin, ymax, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z = np.array([[xi, yi]])
x_decoded = decoder.predict(z)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
start_range = digit_size // 2
end_range = n * digit_size + start_range + 1
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap='Greys_r')
plt.savefig(filename)
plt.show()
这样就完成了和自编码器的检查。 接下来的章节将重点介绍其实际应用。 我们将从去噪自编码器开始。
3. 去噪自编码器(DAE)
现在,我们将构建具有实际应用的自编码器。 首先,让我们画一幅画,然后想象 MNIST 的数字图像被噪声破坏了,从而使人类更难以阅读。 我们能够构建一个去噪自编码器(DAE),以消除这些图像中的噪声。“图 3.3.1”向我们展示了三组 MNIST 数字。 每组的顶部行(例如,MNIST 数字 7、2、1、9、0、6、3、4 和 9)是原始图像。 中间的行显示了 DAE 的输入,这些输入是被噪声破坏的原始图像。 作为人类,我们发现很难读取损坏的 MNIST 数字。 最后一行显示 DAE 的输出。

图 3.3.1:原始 MNIST 数字(顶部行),损坏的原始图像(中间行)和去噪图像(最后一行)
如图“图 3.3.2”所示,去噪自编码器的结构实际上与我们在上一节中介绍的 MNIST 的自编码器相同。

图 3.3.2:去噪自编码器的输入是损坏的图像。 输出是干净或去噪的图像。 假定潜向量为 16 维
“图 3.3.2”中的输入定义为:
x = x_ori + noise(公式 3.3.1)
在该公式中,x_ori表示被噪声破坏的原始 MNIST 图像。 编码器的目的是发现如何产生潜向量z,这将使解码器能够恢复诸如 MSE,如下所示:x_ori通过最小化相异损失函数:
 (Equation 3.3.2)
(Equation 3.3.2)
在此示例中,m是输出尺寸(例如,在 MNIST 中,m = width × height × channels = 28 × 28 × 1 = 784)。 x_ori[i]和x_tilde[i]分别是x_ori和x_tilde的元素。
为了实现 DAE,我们将需要对上一节中介绍的自编码器进行一些更改。 首先,训练输入数据应损坏的 MNIST 数字。 训练输出数据是原始的原始 MNIST 数字相同。 这就像告诉自编码器应校正的图像是什么,或要求它找出在图像损坏的情况下如何消除噪声。 最后,我们必须在损坏的 MNIST 测试数据上验证自编码器。
“图 3.3.2"左侧所示的 MNIST 数字 7 是实际损坏的图像输入。 右边的是经过训练的降噪自编码器的干净图像输出。
“列表 3.3.1”:denoising-autoencoder-mnist-3.3.1.py
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.layers import Conv2D, Flatten
from tensorflow.keras.layers import Reshape, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
np.random.seed(1337)
# load MNIST dataset
(x_train, _), (x_test, _) = mnist.load_data()
# reshape to (28, 28, 1) and normalize input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train, [-1, image_size, image_size, 1])
x_test = np.reshape(x_test, [-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# generate corrupted MNIST images by adding noise with normal dist
# centered at 0.5 and std=0.5
noise = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape)
x_train_noisy = x_train + noise
noise = np.random.normal(loc=0.5, scale=0.5, size=x_test.shape)
x_test_noisy = x_test + noise
# adding noise may exceed normalized pixel values>1.0 or <0.0
# clip pixel values >1.0 to 1.0 and <0.0 to 0.0
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# network parameters
input_shape = (image_size, image_size, 1)
batch_size = 32
kernel_size = 3
latent_dim = 16
# encoder/decoder number of CNN layers and filters per layer
layer_filters = [32, 64]
# build the autoencoder model
# first build the encoder model
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
# stack of Conv2D(32)-Conv2D(64)
for filters in layer_filters:
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
# shape info needed to build decoder model so we don't do hand computation
# the input to the decoder's first Conv2DTranspose will have this shape
# shape is (7, 7, 64) which can be processed by the decoder back to (28, 28, 1)
shape = K.int_shape(x)
# generate the latent vector
x = Flatten()(x)
latent = Dense(latent_dim, name='latent_vector')(x)
# instantiate encoder model
encoder = Model(inputs, latent, name='encoder')
encoder.summary()
# build the decoder model
latent_inputs = Input(shape=(latent_dim,), name='decoder_input')
# use the shape (7, 7, 64) that was earlier saved
x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs)
# from vector to suitable shape for transposed conv
x = Reshape((shape[1], shape[2], shape[3]))(x)
# stack of Conv2DTranspose(64)-Conv2DTranspose(32)
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
# reconstruct the denoised input
outputs = Conv2DTranspose(filters=1,
kernel_size=kernel_size,
padding='same',
activation='sigmoid',
name='decoder_output')(x)
# instantiate decoder model
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
# autoencoder = encoder + decoder
# instantiate autoencoder model
autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder')
autoencoder.summary()
# Mean Square Error (MSE) loss function, Adam optimizer
autoencoder.compile(loss='mse', optimizer='adam')
# train the autoencoder
autoencoder.fit(x_train_noisy,
x_train,
validation_data=(x_test_noisy, x_test),
epochs=10,
batch_size=batch_size)
# predict the autoencoder output from corrupted test images
x_decoded = autoencoder.predict(x_test_noisy)
# 3 sets of images with 9 MNIST digits
# 1st rows - original images
# 2nd rows - images corrupted by noise
# 3rd rows - denoised images
rows, cols = 3, 9
num = rows * cols
imgs = np.concatenate([x_test[:num], x_test_noisy[:num], x_decoded[:num]])
imgs = imgs.reshape((rows * 3, cols, image_size, image_size))
imgs = np.vstack(np.split(imgs, rows, axis=1))
imgs = imgs.reshape((rows * 3, -1, image_size, image_size))
imgs = np.vstack([np.hstack(i) for i in imgs])
imgs = (imgs * 255).astype(np.uint8)
plt.figure()
plt.axis('off')
plt.title('Original images: top rows, '
'Corrupted Input: middle rows, '
'Denoised Input: third rows')
plt.imshow(imgs, interpolation='none', cmap='gray')
Image.fromarray(imgs).save('corrupted_and_denoised.png')
plt.show()
“列表 3.3.1”显示了去噪自编码器,该编码器已添加到官方 Keras GitHub 存储库中。 使用相同的 MNIST 数据集,我们可以通过添加随机噪声来模拟损坏的图像。 添加的噪声是高斯分布,平均值为μ = 0.5,标准差为σ = 0.5。 由于添加随机噪声可能会将像素数据推入小于 0 或大于 1 的无效值,因此像素值会被裁剪为[0.1, 1.0]范围。
其他所有内容实际上都与上一节中的自编码器相同。 我们将使用相同的 MSE 损失函数和 Adam 优化器。 但是,训练的周期数已增加到 10。这是为了进行足够的参数优化。
“图 3.3.3”显示了 DAE 在某种程度上的鲁棒性,因为噪声级别从σ = 0.5增至σ = 0.75和σ = 1.0。 在σ = 0.75处,DAE 仍能够恢复原始图像。 但是,在σ = 1.0处,一些数字,例如第二和第三组中的 4 和 5,将无法正确恢复。

图 3.3.3:降噪自编码器的表现随着噪声水平的提高而增加
我们已经完成去噪自编码器的讨论和实现。 尽管此概念已在 MNIST 数字上进行了演示,但该思想也适用于其他信号。 在下一节中,我们将介绍自编码器的另一种实际应用,称为着色自编码器。
4. 自动着色自编码器
现在,我们将致力于自编码器的另一个实际应用。 在这种情况下,我们将想象一下,我们有一张灰度照片,并且想要构建一个可以自动为其添加颜色的工具。 我们要复制人类的能力,以识别海洋和天空为蓝色,草地和树木为绿色,云层为白色,依此类推。
如图“图 3.4.1”所示,如果给我们前景的稻田,背景的火山和顶部的天空的灰度照片(左),我们可以添加适当的颜色(右)。

图 3.4.1:为 Mayon 火山的灰度照片添加颜色。 着色网络应通过向灰度照片添加颜色来复制人类的能力。 左照片是灰度的。 正确的照片是彩色的。 原始彩色照片可以在本书的 GitHub 存储库中找到。
对于自编码器,一种简单的自动着色算法似乎是一个合适的问题。 如果我们可以使用足够数量的灰度照片作为输入并使用相应的彩色照片作为输出来训练自编码器,则可能会在正确应用颜色时发现隐藏的结构。 大致上,这是去噪的反向过程。 问题是,自编码器能否在原始灰度图像上添加颜色(良好的噪点)?
“列表 3.4.1”显示了着色自编码器网络。 着色自编码器网络是我们用于 MNIST 数据集的降噪自编码器的修改版本。 首先,我们需要一个彩色照片的灰度数据集。 我们之前使用过的 CIFAR10 数据库进行了 50,000 次训练和 10,000 次测试,可以将32×32 RGB 照片转换为灰度图像。 如下清单所示,我们可以使用rgb2gray()函数在 R,G 和 B 分量上应用权重,以从彩色转换为灰度:
“列表 3.4.1”:colorization-autoencoder-cifar10-3.4.1.py
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.layers import Conv2D, Flatten
from tensorflow.keras.layers import Reshape, Conv2DTranspose
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ReduceLROnPlateau
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import plot_model
from tensorflow.keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
import os
def rgb2gray(rgb):
"""Convert from color image (RGB) to grayscale.
Source: opencv.org
grayscale = 0.299*red + 0.587*green + 0.114*blue
Argument:
rgb (tensor): rgb image
Return:
(tensor): grayscale image
"""
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
# load the CIFAR10 data
(x_train, _), (x_test, _) = cifar10.load_data()
# input image dimensions
# we assume data format "channels_last"
img_rows = x_train.shape[1]
img_cols = x_train.shape[2]
channels = x_train.shape[3]
# create saved_images folder
imgs_dir = 'saved_images'
save_dir = os.path.join(os.getcwd(), imgs_dir)
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
# display the 1st 100 input images (color and gray)
imgs = x_test[:100]
imgs = imgs.reshape((10, 10, img_rows, img_cols, channels))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure()
plt.axis('off')
plt.title('Test color images (Ground Truth)')
plt.imshow(imgs, interpolation='none')
plt.savefig('%s/test_color.png' % imgs_dir)
plt.show()
# convert color train and test images to gray
x_train_gray = rgb2gray(x_train)
x_test_gray = rgb2gray(x_test)
# display grayscale version of test images
imgs = x_test_gray[:100]
imgs = imgs.reshape((10, 10, img_rows, img_cols))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure()
plt.axis('off')
plt.title('Test gray images (Input)')
plt.imshow(imgs, interpolation='none', cmap='gray')
plt.savefig('%s/test_gray.png' % imgs_dir)
plt.show()
# normalize output train and test color images
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# normalize input train and test grayscale images
x_train_gray = x_train_gray.astype('float32') / 255
x_test_gray = x_test_gray.astype('float32') / 255
# reshape images to row x col x channel for CNN output/validation
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, channels)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, channels)
# reshape images to row x col x channel for CNN input
x_train_gray = x_train_gray.reshape(x_train_gray.shape[0], img_rows, img_cols, 1)
x_test_gray = x_test_gray.reshape(x_test_gray.shape[0], img_rows, img_cols, 1)
# network parameters
input_shape = (img_rows, img_cols, 1)
batch_size = 32
kernel_size = 3
latent_dim = 256
# encoder/decoder number of CNN layers and filters per layer
layer_filters = [64, 128, 256]
# build the autoencoder model
# first build the encoder model
inputs = Input(shape=input_shape, name='encoder_input')
x = inputs
# stack of Conv2D(64)-Conv2D(128)-Conv2D(256)
for filters in layer_filters:
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
# shape info needed to build decoder model so we don't do hand computation
# the input to the decoder's first Conv2DTranspose will have this shape
# shape is (4, 4, 256) which is processed by the decoder back to (32, 32, 3)
shape = K.int_shape(x)
# generate a latent vector
x = Flatten()(x)
latent = Dense(latent_dim, name='latent_vector')(x)
# instantiate encoder model
encoder = Model(inputs, latent, name='encoder')
encoder.summary()
# build the decoder model
latent_inputs = Input(shape=(latent_dim,), name='decoder_input')
x = Dense(shape[1]*shape[2]*shape[3])(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
# stack of Conv2DTranspose(256)-Conv2DTranspose(128)-Conv2DTranspose(64)
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=2,
activation='relu',
padding='same')(x)
outputs = Conv2DTranspose(filters=channels,
kernel_size=kernel_size,
activation='sigmoid',
padding='same',
name='decoder_output')(x)
# instantiate decoder model
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
# autoencoder = encoder + decoder
# instantiate autoencoder model
autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder')
autoencoder.summary()
# prepare model saving directory.
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'colorized_ae_model.{epoch:03d}.h5'
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
filepath = os.path.join(save_dir, model_name)
# reduce learning rate by sqrt(0.1) if the loss does not improve in 5 epochs
lr_reducer = ReduceLROnPlateau(factor=np.sqrt(0.1),
cooldown=0,
patience=5,
verbose=1,
min_lr=0.5e-6)
# save weights for future use (e.g. reload parameters w/o training)
checkpoint = ModelCheckpoint(filepath=filepath,
monitor='val_loss',
verbose=1,
save_best_only=True)
# Mean Square Error (MSE) loss function, Adam optimizer
autoencoder.compile(loss='mse', optimizer='adam')
# called every epoch
callbacks = [lr_reducer, checkpoint]
# train the autoencoder
autoencoder.fit(x_train_gray,
x_train,
validation_data=(x_test_gray, x_test),
epochs=30,
batch_size=batch_size,
callbacks=callbacks)
# predict the autoencoder output from test data
x_decoded = autoencoder.predict(x_test_gray)
# display the 1st 100 colorized images
imgs = x_decoded[:100]
imgs = imgs.reshape((10, 10, img_rows, img_cols, channels))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure()
plt.axis('off')
plt.title('Colorized test images (Predicted)')
plt.imshow(imgs, interpolation='none')
plt.savefig('%s/colorized.png' % imgs_dir)
plt.show()
通过添加更多卷积和转置卷积,我们提高了自编码器的容量。 我们还将每个 CNN 块的过滤器数量增加了一倍。 潜向量现在为 256 维,以增加其可以表示的显着属性的数量,如自编码器部分所述。 最后,输出过滤器的大小已增加到三倍,或等于预期的彩色输出的 RGB 中的通道数。
现在使用灰度作为输入,原始 RGB 图像作为输出来训练着色自编码器。 训练将花费更多的时间,并在验证损失没有改善的情况下使用学习率降低器来缩小学习率。 通过告诉tf.keras fit()函数中的 callbacks 参数调用lr_reducer()函数,可以轻松完成此操作。
“图 3.4.2”演示了来自 CIFAR10 测试数据集的灰度图像的着色。

图 3.4.2:使用自编码器将灰度自动转换为彩色图像。 CIFAR10 测试灰度输入图像(左)和预测的彩色图像(右)。 原始彩色照片可以在本书的 GitHub 存储库中找到,网址为 https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Keras/blob/master/chapter3-autoencoders/README.md
“图 3.4.3”将基本事实与着色自编码器预测进行了比较:

图 3.4.3:地面真彩色图像与预测彩色图像的并排比较。 原始彩色照片可以在本书的 GitHub 存储库中找到,网址为 https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Keras/blob/master/chapter3-autoencoders/README.md
自编码器执行可接受的着色作业。 预计大海或天空为蓝色,动物的阴影为棕色,云为白色,依此类推。
有一些明显的错误预测,例如红色车辆变成蓝色或蓝色车辆变成红色,偶尔的绿色领域被误认为是蓝天,而黑暗或金色的天空被转换为蓝天。
这是关于自编码器的最后一部分。 在以下各章中,我们将重新讨论以一种或另一种形式进行编码和解码的概念。 表示学习的概念在深度学习中非常基础。
5. 总结
在本章中,我们已经介绍了自编码器,它们是将输入数据压缩为低维表示形式的神经网络,以便有效地执行结构转换,例如降噪和着色。 我们为 GAN 和 VAE 的更高级主题奠定了基础,我们将在后面的章节中介绍它们。 我们已经演示了如何从两个构建模块模型(编码器和解码器)实现自编码器。 我们还学习了如何提取输入分布的隐藏结构是 AI 的常见任务之一。
一旦学习了潜在代码,就可以对原始输入分布执行许多结构操作。 为了更好地了解输入分布,可以使用低级嵌入(类似于本章内容)或通过更复杂的降维技术(例如 t-SNE 或 PCA)来可视化潜在向量形式的隐藏结构。
除了去噪和着色外,自编码器还用于将输入分布转换为低维潜向量,可以针对其他任务(例如,分割,检测,跟踪,重建和视觉理解)进一步对其进行处理。 在“第 8 章”,“变分自编码器(VAE)”中,我们将讨论 VAE,它们在结构上与自编码器相同,但具有可解释的潜在代码,这些代码可以产生连续的潜在向量投影,因此有所不同。
在下一章中,我们将着手介绍 AI 最近最重要的突破之一,即 GAN。 在下一章中,我们将学习 GAN 的核心优势,即其综合看起来真实的数据的能力。
6. 参考
Ian Goodfellow et al.: Deep Learning. Vol. 1. Cambridge: MIT press, 2016 (http://www.deeplearningbook.org/).
四、生成对抗网络(GAN)
在本章中,我们将研究生成对抗网络(GAN)[1]。 GAN 属于生成模型家族。 但是,与自编码器不同,生成模型能够在给定任意编码的情况下创建新的有意义的输出。
在本章中,将讨论 GAN 的工作原理。 我们还将使用tf.keras回顾几个早期 GAN 的实现,而在本章的后面,我们将演示实现稳定训练所需的技术。 本章的范围涵盖了 GAN 实现的两个流行示例,深度卷积 GAN(DCGAN)[2]和条件 GAN(CGAN)[3]。
总之,本章的目标是:
- GAN 的原理简介
- GAN 的早期工作实现之一的简介,称为 DCGAN
- 改进的 DCGAN,称为 CGAN,它使用条件
- 在
tf.keras中实现 DCGAN 和 CGAN
让我们从 GAN 的概述开始。
1. GAN 概述
在进入 GAN 的更高级概念之前,让我们开始研究 GAN,并介绍它们背后的基本概念。 GAN 非常强大。 通过执行潜在空间插值,他们可以生成不是真实人的新人脸这一事实证明了这一简单的陈述。
可以在以下 YouTube 视频中看到 GAN 的高级功能:
展示如何利用 GAN 产生逼真的面部的视频演示了它们的功能。 这个主题比我们之前看过的任何内容都先进得多。 例如,上面的视频演示了自编码器无法轻松完成的事情,我们在“第 3 章”,“自编码器”中介绍了这些内容。
GAN 可以通过训练两个相互竞争(且相互配合)的网络(称为生成器和判别器(有时称为评论家)。 生成器的作用是继续弄清楚如何生成伪造数据或信号(包括音频和图像),使伪造者蒙上阴影。 同时,判别器被训练以区分假信号和真实信号。 随着训练的进行,判别器将不再能够看到合成生成的数据与真实数据之间的差异。 从那里,可以丢弃判别器,然后可以使用生成器来创建从未见过的新的真实数据。
GAN 的基本概念很简单。 但是,我们将发现的一件事是,最具挑战性的问题是我们如何实现对生成器-判别器网络的稳定训练? 为了使两个网络都能同时学习,生成器和判别器之间必须存在健康的竞争。 由于损失函数是根据判别器的输出计算得出的,因此其参数会快速更新。 当判别器收敛速度更快时,生成器不再为其参数接收到足够的梯度更新,并且无法收敛。 除了难以训练之外,GAN 还可能遭受部分或全部模态崩溃的影响,这种情况下,生成器针对不同的潜在编码生成几乎相似的输出。
GAN 的原理
如图“图 4.1.1”所示,GAN 类似于伪造者(生成器)-警察(判别器)场景。 在学院里,警察被教导如何确定美钞是真钞还是假钞。 来自银行的真实美钞样本和来自伪造者的伪钞样本被用来训练警察。 但是,伪造者会不时地假装他印制了真实的美元钞票。 最初,警方不会上当,并且会告诉造假者这笔钱是假的。 考虑到此反馈,造假者再次磨练他的技能,并尝试制作新的假美元钞票。 如预期的那样,警察将能够发现这笔钱是伪造的,并说明为什么美元钞票是伪造的:
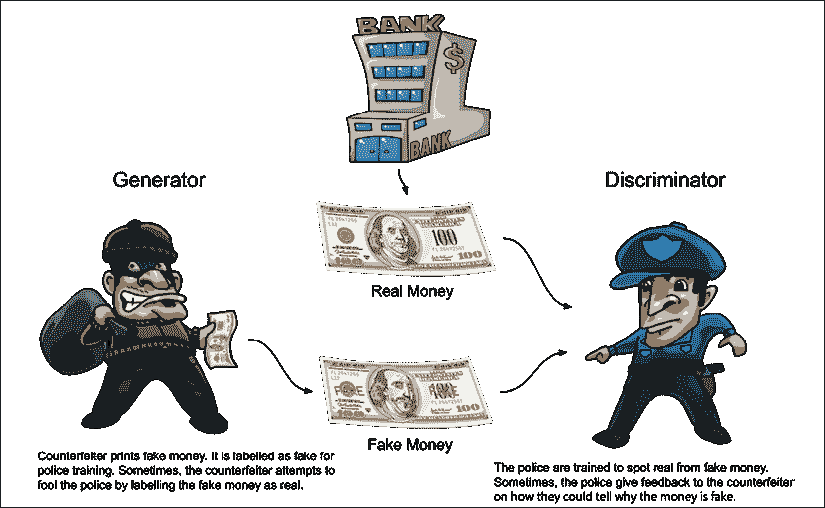
图 4.1.1:GAN 的生成器和判别器类似于伪造者和警察。 造假者的目的是欺骗警察,使他们相信美元钞票是真实的
此过程无限期地继续,但是到了造假者已经掌握了伪造货币的程度,以至于伪造品与真实货币几乎无法区分-甚至对于最受执业的警察也是如此。 然后,伪造者可以无限次打印美元钞票,而不会被警方抓获,因为它们不再可识别为伪造的。
如图“图 4.1.2”所示,GAN 由两个网络组成,一个生成器和一个判别器:
图 4.1.2:GAN 由两个网络组成,一个生成器和一个判别器。 判别器经过训练,可以区分真实信号和虚假信号或数据。 生成器的工作是生成伪造的信号或数据,这些伪造的信号或数据最终会欺骗判别器
生成器的输入是噪声,输出是合成数据。 同时,判别器的输入将是实数据或合成数据。 真实数据来自真实的采样数据,而虚假数据来自生成器。 所有有效数据均标记为 1.0(即 100% 为真实概率),而所有合成数据均标记为 0.0(即 0% 为真实概率)。 由于标记过程是自动化的,因此 GAN 仍被认为是深度学习中无监督学习方法的一部分。
判别器的目标是从此提供的数据集中学习如何区分真实数据与伪数据。 在 GAN 训练的这一部分中,仅判别器参数将被更新。 像典型的二元分类器一样,判别器经过训练,可以在 0.0 到 1.0 的范围内预测置信度值,以了解给定输入数据与真实数据的接近程度。 但是,这只是故事的一半。
生成器将以固定的时间间隔假装其输出是真实数据,并要求 GAN 将其标记为 1.0。 然后,当将伪造数据提供给判别器时,自然会将其分类为伪造,标签接近 0.0。
优化器根据显示的标签(即 1.0)计算生成器参数更新。 在对新数据进行训练时,它还会考虑自己的预测。 换句话说,判别器对其预测有一些疑问,因此,GAN 将其考虑在内。 这次,GAN 将让梯度从判别器的最后一层向下向下传播到生成器的第一层。 但是,在大多数实践中,在训练的此阶段,判别器参数会暂时冻结。 生成器将使用梯度来更新其参数并提高其合成伪数据的能力。
总体而言,整个过程类似于两个网络相互竞争,同时仍在合作。 当 GAN 训练收敛时,最终结果是生成器,可以合成看似真实的数据。 判别器认为该合成数据是真实数据或带有接近 1.0 的标签,这意味着该判别器可以被丢弃。 生成器部分将有助于从任意噪声输入中产生有意义的输出。
下面的“图 4.1.3”中概述了该过程:

图 4.1.3:训练判别器类似于使用二进制交叉熵损失训练二分类器网络。 伪数据由生成器提供,而真实数据来自真实样本
如上图所示,可以通过最小化以下等式中的损失函数来训练判别器:
 (Equation 4.1.1)
(Equation 4.1.1)
该方程只是标准的二进制交叉熵代价函数。 损失是正确识别真实数据1 - D(g(z))的期望值与 1.0 正确识别合成数据1 - D(g(z))的期望值之和。 日志不会更改本地最小值的位置。
训练过程中将两个小批数据提供给判别器:
-
x,来自采样数据的实数据(换言之,x ~ p_data),标签为 1.0 -
x' = g(z),来自生成器的带有标签 0.0 的伪造数据
为了使的损失函数最小,将通过反向传播通过正确识别真实数据D(x)和合成数据1 - D(g(z))来更新判别器参数θ^(D)。 正确识别真实数据等同于D(x) -> 1.0,而正确分类伪造数据则与D(g(z)) -> 0.0或1 - D(g(z)) -> 1.0相同。 在此等式中,z是生成器用来合成新信号的任意编码或噪声向量。 两者都有助于最小化损失函数。
为了训练生成器,GAN 将判别器和生成器损失的总和视为零和博弈。 生成器损失函数只是判别器损失函数的负数:
 (Equation 4.1.2)
(Equation 4.1.2)
然后可以将其更恰当地重写为值函数:
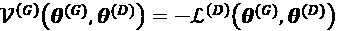 (Equation 4.1.3)
(Equation 4.1.3)
从生成器的角度来看,应将“公式 4.1.3”最小化。 从判别器的角度来看,值函数应最大化。 因此,生成器训练准则可以写成极大极小问题:
 (Equation 4.1.4)
(Equation 4.1.4)
有时,我们会假装合成数据是带有标签 1.0 的真实数据,以此来欺骗判别器。 通过最大化θ^(D),优化器将梯度更新发送到判别器参数,以将该合成数据视为真实数据。 同时,通过将θ^(G)的相关性减至最小,优化器将在上训练生成器的参数,从而欺骗识别器。 但是,实际上,判别器对将合成数据分类为伪造的预测很有信心,并且不会更新 GAN 参数。 此外,梯度更新很小,并且在传播到生成器层时已大大减小。 结果,生成器无法收敛。

图 4.1.4:训练生成器就像使用二进制交叉熵损失函数训练网络一样。 来自生成器的虚假数据显示为真实数据
解决方案是按以下形式重新构造生成器的损失函数:
 (Equation 4.1.5)
(Equation 4.1.5)
损失函数只是通过训练生成器,最大程度地提高了判别器认为合成数据是真实数据的机会。 新公式不再是零和,而是纯粹由启发式驱动的。“图 4.1.4”显示了训练过程中的生成器。 在此图中,仅在训练整个对抗网络时才更新生成器参数。 这是因为梯度从判别器向下传递到生成器。 但是,实际上,判别器权重仅在对抗训练期间临时冻结。
在深度学习中,可以使用合适的神经网络架构来实现生成器和判别器。 如果数据或信号是图像,则生成器和判别器网络都将使用 CNN。 对于诸如音频之类的一维序列,两个网络通常都是循环的(RNN,LSTM 或 GRU)。
在本节中,我们了解到 GAN 的原理很简单。 我们还了解了如何通过熟悉的网络层实现 GAN。 GAN 与其他网络的区别在于众所周知,它们很难训练。 只需稍作更改,就可以使网络变得不稳定。 在以下部分中,我们将研究使用深度 CNN 的 GAN 早期成功实现之一。 它称为 DCGAN [3]。
2. 在 Keras 中实现 DCGAN
“图 4.2.1”显示 DCGAN,其中用于生成伪造的 MNIST 图像:

图 4.2.1:DCGAN 模型
DCGAN 实现以下设计原则:
- 使用
stride > 1和卷积代替MaxPooling2D或UpSampling2D。 通过stride > 1,CNN 可以学习如何调整特征映射的大小。 - 避免使用
Dense层。 在所有层中使用 CNN。Dense层仅用作生成器的第一层以接受z向量。 调整Dense层的输出大小,并成为后续 CNN 层的输入。 - 使用批量归一化(BN),通过将每一层的输入归一化以使均值和单位方差为零,来稳定学习。 生成器输出层和判别器输入层中没有 BN。 在此处要介绍的实现示例中,没有在标识符中使用批量归一化。
- 整流线性单元(ReLU)在生成器的所有层中均使用,但在输出层中则使用
tanh激活。 在此处要介绍的实现示例中,在生成器的输出中使用sigmoid代替tanh,因为通常会导致对 MNIST 数字进行更稳定的训练。 - 在判别器的所有层中使用 Leaky ReLU。 与 ReLU 不同,Leaky ReLU 不会在输入小于零时将所有输出清零,而是生成一个等于
alpha x input的小梯度。 在以下示例中,alpha = 0.2。
生成器学习从 100 维输入向量([-1.0,1.0]范围内具有均匀分布的 100 维随机噪声)生成伪图像。 判别器将真实图像与伪图像分类,但是在训练对抗网络时无意中指导生成器如何生成真实图像。 在我们的 DCGAN 实现中使用的核大小为 5。这是为了允许它增加卷积的接收场大小和表达能力。
生成器接受由 -1.0 到 1.0 范围内的均匀分布生成的 100 维z向量。 生成器的第一层是7 x 7 x 128 = 6,272单元的密集层。 基于输出图像的预期最终尺寸(28 x 28 x 1,28 是 7 的倍数)和第一个Conv2DTranspose的过滤器数量(等于 128)来计算单元数量。
我们可以将转置的 CNN(Conv2DTranspose)想象成 CNN 的逆过程。 在一个简单的示例中,如果 CNN 将图像转换为特征映射,则转置的 CNN 将生成给定特征映射的图像。 因此,转置的 CNN 在上一章的解码器中和本章的生成器中使用。
在对strides = 2进行两个Conv2DTranspose之后,特征映射的大小将为28 x 28 x n_filter。 每个Conv2DTranspose之前都有批量规范化和 ReLU。 最后一层具有 Sigmoid 激活,可生成28 x 28 x 1假 MNIST 图像。 将每个像素标准化为与[0, 255]灰度级相对应的[0.0, 1.0]。 下面的“列表 4.2.1”显示了tf.keras中生成器网络的实现。 定义了一个函数来生成生成器模型。 由于整个代码的长度,我们将列表限制为正在讨论的特定行。
“列表 4.2.1”:dcgan-mnist-4.2.1.py
def build_generator(inputs, image_size):
"""Build a Generator Model
Stack of BN-ReLU-Conv2DTranpose to generate fake images
Output activation is sigmoid instead of tanh in [1].
Sigmoid converges easily.
Arguments:
inputs (Layer): Input layer of the generator
the z-vector)
image_size (tensor): Target size of one side
(assuming square image)
Returns:
generator (Model): Generator Model
"""
image_resize = image_size // 4
# network parameters
kernel_size = 5
layer_filters = [128, 64, 32, 1]
x = Dense(image_resize * image_resize * layer_filters[0])(inputs)
x = Reshape((image_resize, image_resize, layer_filters[0]))(x)
for filters in layer_filters:
# first two convolution layers use strides = 2
# the last two use strides = 1
if filters > layer_filters[-2]:
strides = 2
else:
strides = 1
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = Activation('sigmoid')(x)
generator = Model(inputs, x, name='generator')
return generator
判别器与相似,是许多基于 CNN 的分类器。 输入是28 x 28 x 1MNIST 图像,分类为真实(1.0)或伪(0.0)。 有四个 CNN 层。 除了最后的卷积,每个Conv2D都使用strides = 2将特征映射下采样两个。 然后每个Conv2D之前都有一个泄漏的 ReLU 层。 最终的过滤器大小为 256,而初始的过滤器大小为 32,并使每个卷积层加倍。 最终的过滤器大小 128 也适用。 但是,我们会发现生成的图像在 256 的情况下看起来更好。最终输出层被展平,并且在通过 Sigmoid 激活层缩放后,单个单元Dense层在 0.0 到 1.0 之间生成预测。 输出被建模为伯努利分布。 因此,使用了二进制交叉熵损失函数。
建立生成器和判别器模型后,通过将生成器和判别器网络连接起来,建立对抗模型。 鉴别网络和对抗网络都使用 RMSprop 优化器。 判别器的学习率是2e-4,而对抗网络的学习率是1e-4。 判别器的 RMSprop 衰减率为6e-8,对抗网络的 RMSprop 衰减率为3e-8。
将对手的学习率设置为判别器的一半将使训练更加稳定。 您会从“图 4.1.3”和“图 4.1.4”中回忆起,GAN 训练包含两个部分:判别器训练和生成器训练,这是冻结判别器权重的对抗训练。
“列表 4.2.2”显示了tf.keras中判别器的实现。 定义一个函数来建立鉴别模型。
“列表 4.2.2”:dcgan-mnist-4.2.1.py
def build_discriminator(inputs):
"""Build a Discriminator Model
Stack of LeakyReLU-Conv2D to discriminate real from fake.
The network does not converge with BN so it is not used here
unlike in [1] or original paper.
Arguments:
inputs (Layer): Input layer of the discriminator (the image)
Returns:
discriminator (Model): Discriminator Model
"""
kernel_size = 5
layer_filters = [32, 64, 128, 256]
x = inputs
for filters in layer_filters:
# first 3 convolution layers use strides = 2
# last one uses strides = 1
if filters == layer_filters[-1]:
strides = 1
else:
strides = 2
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = Flatten()(x)
x = Dense(1)(x)
x = Activation('sigmoid')(x)
discriminator = Model(inputs, x, name='discriminator')
return discriminator
在“列表 4.2.3”中,我们将说明如何构建 GAN 模型。 首先,建立鉴别模型,然后实例化生成器模型。 对抗性模型只是生成器和判别器组合在一起。 在许多 GAN 中,批大小为 64 似乎是最常见的。 网络参数显示在“列表 4.2.3”中。
“列表 4.2.3”:dcgan-mnist-4.2.1.py
建立 DCGAN 模型并调用训练例程的函数:
def build_and_train_models():
# load MNIST dataset
(x_train, _), (_, _) = mnist.load_data()
# reshape data for CNN as (28, 28, 1) and normalize
image_size = x_train.shape[1]
x_train = np.reshape(x_train, [-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
model_name = "dcgan_mnist"
# network parameters
# the latent or z vector is 100-dim
latent_size = 100
batch_size = 64
train_steps = 40000
lr = 2e-4
decay = 6e-8
input_shape = (image_size, image_size, 1)
# build discriminator model
inputs = Input(shape=input_shape, name='discriminator_input')
discriminator = build_discriminator(inputs)
# [1] or original paper uses Adam,
# but discriminator converges easily with RMSprop
optimizer = RMSprop(lr=lr, decay=decay)
discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
discriminator.summary()
# build generator model
input_shape = (latent_size, )
inputs = Input(shape=input_shape, name='z_input')
generator = build_generator(inputs, image_size)
generator.summary()
# build adversarial model
optimizer = RMSprop(lr=lr * 0.5, decay=decay * 0.5)
# freeze the weights of discriminator during adversarial training
discriminator.trainable = False
# adversarial = generator + discriminator
adversarial = Model(inputs,
discriminator(generator(inputs)),
name=model_name)
adversarial.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
adversarial.summary()
# train discriminator and adversarial networks
models = (generator, discriminator, adversarial)
params = (batch_size, latent_size, train_steps, model_name)
train(models, x_train, params)
从“列表 4.2.1”和“列表 4.2.2”中可以看出,DCGAN 模型很简单。 使它们难以构建的原因是,网络中的较小更改设计很容易破坏训练收敛。 例如,如果在判别器中使用批量归一化,或者如果生成器中的strides = 2传输到后面的 CNN 层,则 DCGAN 将无法收敛。
“列表 4.2.4”显示了专用于训练判别器和对抗网络的函数。 由于自定义训练,将不使用常规的fit()函数。 取而代之的是,调用train_on_batch()对给定的数据批量运行单个梯度更新。 然后通过对抗网络训练生成器。 训练首先从数据集中随机选择一批真实图像。 这被标记为实数(1.0)。 然后,生成器将生成一批伪图像。 这被标记为假(0.0)。 这两个批量是连接在一起的,用于训练判别器。
完成此操作后,生成器将生成一批新的伪图像,并将其标记为真实(1.0)。 这批将用于训练对抗网络。 交替训练这两个网络约 40,000 步。 定期将基于特定噪声向量生成的 MNIST 数字保存在文件系统中。 在最后的训练步骤中,网络已收敛。 生成器模型也保存在文件中,因此我们可以轻松地将训练后的模型重新用于未来的 MNIST 数字生成。 但是,仅保存生成器模型,因为这是该 DCGAN 在生成新 MNIST 数字时的有用部分。 例如,我们可以通过执行以下操作来生成新的和随机的 MNIST 数字:
python3 dcgan-mnist-4.2.1.py --generator=dcgan_mnist.h5
“列表 4.2.4”:dcgan-mnist-4.2.1.py
训练判别器和对抗网络的函数:
def train(models, x_train, params):
"""Train the Discriminator and Adversarial Networks
Alternately train Discriminator and Adversarial networks by batch.
Discriminator is trained first with properly real and fake images.
Adversarial is trained next with fake images pretending to be real
Generate sample images per save_interval.
Arguments:
models (list): Generator, Discriminator, Adversarial models
x_train (tensor): Train images
params (list) : Networks parameters
"""
# the GAN component models
generator, discriminator, adversarial = models
# network parameters
batch_size, latent_size, train_steps, model_name = params
# the generator image is saved every 500 steps
save_interval = 500
# noise vector to see how the generator output evolves during training
noise_input = np.random.uniform(-1.0, 1.0, size=[16, latent_size])
# number of elements in train dataset
train_size = x_train.shape[0]
for i in range(train_steps):
# train the discriminator for 1 batch
# 1 batch of real (label=1.0) and fake images (label=0.0)
# randomly pick real images from dataset
rand_indexes = np.random.randint(0, train_size, size=batch_size)
real_images = x_train[rand_indexes]
# generate fake images from noise using generator
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# generate fake images
fake_images = generator.predict(noise)
# real + fake images = 1 batch of train data
x = np.concatenate((real_images, fake_images))
# label real and fake images
# real images label is 1.0
y = np.ones([2 * batch_size, 1])
# fake images label is 0.0
y[batch_size:, :] = 0.0
# train discriminator network, log the loss and accuracy
loss, acc = discriminator.train_on_batch(x, y)
log = "%d: [discriminator loss: %f, acc: %f]" % (i, loss, acc)
# train the adversarial network for 1 batch
# 1 batch of fake images with label=1.0
# since the discriminator weights
# are frozen in adversarial network
# only the generator is trained
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# label fake images as real or 1.0
y = np.ones([batch_size, 1])
# train the adversarial network
# note that unlike in discriminator training,
# we do not save the fake images in a variable
# the fake images go to the discriminator input of the adversarial
# for classification
# log the loss and accuracy
loss, acc = adversarial.train_on_batch(noise, y)
log = "%s [adversarial loss: %f, acc: %f]" % (log, loss, acc)
print(log)
if (i + 1) % save_interval == 0:
# plot generator images on a periodic basis
plot_images(generator,
noise_input=noise_input,
show=False,
step=(i + 1),
model_name=model_name)
# save the model after training the generator
# the trained generator can be reloaded for
# future MNIST digit generation
generator.save(model_name + ".h5")
“图 4.2.2”显示了生成器伪造图像根据训练步骤的演变。 生成器已经以 5,000 步的速度生成了可识别的图像。 非常像拥有一个知道如何绘制数字的智能体。 值得注意的是,某些数字从一种可识别的形式(例如,最后一行的第二列中的 8)变为另一种形式(例如,0)。 当训练收敛时,判别器损失接近 0.5,而对抗性损失接近 1.0,如下所示:
39997: [discriminator loss: 0.423329, acc: 0.796875] [adversarial loss:
0.819355, acc: 0.484375]
39998: [discriminator loss: 0.471747, acc: 0.773438] [adversarial loss:
1.570030, acc: 0.203125]
39999: [discriminator loss: 0.532917, acc: 0.742188] [adversarial loss:
0.824350, acc: 0.453125]
我们可以看到以下结果:

图 4.2.2:DCGAN 生成器在不同训练步骤生成的伪造图像
在本节中,由 DCGAN 生成的伪造图像是随机的。
生成器无法控制哪个特定数字。 没有机制可以请求生成器提供特定的数字。 这个问题可以通过称为 CGAN [4]的 GAN 变体来解决,我们将在下一部分中进行讨论。
3. Conditional GAN
使用与上一节相同的 GAN ,会对生成器和判别器输入都施加一个条件。 条件是数字的一键向量形式。 这与要生成的图像(生成器)或分类为真实或伪造的图像(判别器)相关。 CGAN 模型显示在“图 4.3.1”中。
CGAN 与 DCGAN 相似,除了附加的单热向量输入。 对于生成器,单热标签在Dense层之前与潜向量连接在一起。 对于判别器,添加了新的Dense层。 新层用于处理单热向量并对其进行整形,以使其适合于与后续 CNN 层的另一个输入连接。

图 4.3.1:CGAN 模型与 DCGAN 相似,只不过是单热向量,用于调节生成器和判别器的输出
生成器学习从 100 维输入向量和指定位数生成伪图像。 判别器基于真实和伪图像及其对应的标签将真实图像与伪图像分类。
CGAN 的基础仍然与原始 GAN 原理相同,区别在于判别器和生成器的输入均以“一热”标签y为条件。
通过在“公式 4.1.1”和“公式 4.1.5”中合并此条件,判别器和生成器的损失函数在“公式 4.3.1”和“公式 4.3.2”中显示,分别为:
 (Equation 4.3.1)
(Equation 4.3.1)
 (Equation 4.3.2)
(Equation 4.3.2)
给定“图 4.3.2”,将损失函数写为:
 (Equation 4.3.3)
(Equation 4.3.3)
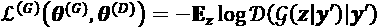 (Equation 4.3.4)
(Equation 4.3.4)
判别器的新损失函数旨在最大程度地减少预测来自数据集的真实图像和来自生成器的假图像(给定单热点标签)的误差。“图 4.3.2”显示了如何训练判别器。

图 4.3.2:训练 CGAN 判别器类似于训练 GAN 判别器。 唯一的区别是,所生成的伪造品和数据集的真实图像均以其相应的“一键通”标签作为条件。
生成器的新损失函数可最大程度地减少对以指定的一幅热标签为条件的伪造图像进行鉴别的正确预测。 生成器学习如何在给定单热向量的情况下生成特定的 MNIST 数字,该数字可能使判别器蒙蔽。“图 4.3.3”显示了如何训练生成器。

图 4.3.3:通过对抗网络训练 CGAN 生成器类似于训练 GAN 生成器。 唯一的区别是,生成的伪造图像以“一热”标签为条件
“列表 4.3.1”突出显示了判别器模型中所需的微小更改。 该代码使用Dense层处理单热点向量,并将其与输入图像连接在一起。 修改了Model实例以用于图像和一键输入向量。
“列表 4.3.1”:cgan-mnist-4.3.1.py
突出显示了 DCGAN 中所做的更改:
def build_discriminator(inputs, labels, image_size):
"""Build a Discriminator Model
Inputs are concatenated after Dense layer.
Stack of LeakyReLU-Conv2D to discriminate real from fake.
The network does not converge with BN so it is not used here
unlike in DCGAN paper.
Arguments:
inputs (Layer): Input layer of the discriminator (the image)
labels (Layer): Input layer for one-hot vector to condition
the inputs
image_size: Target size of one side (assuming square image)
Returns:
discriminator (Model): Discriminator Model
"""
kernel_size = 5
layer_filters = [32, 64, 128, 256]
x = inputs
y = Dense(image_size * image_size)(labels)
y = Reshape((image_size, image_size, 1))(y)
x = concatenate([x, y])
for filters in layer_filters:
# first 3 convolution layers use strides = 2
# last one uses strides = 1
if filters == layer_filters[-1]:
strides = 1
else:
strides = 2
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = Flatten()(x)
x = Dense(1)(x)
x = Activation('sigmoid')(x)
# input is conditioned by labels
discriminator = Model([inputs, labels], x, name='discriminator')
return discriminator
以下“列表 4.3.2”突出显示了代码更改,以在生成器生成器函数中合并条件化单热标签。 对于z向量和单热向量输入,修改了Model实例。
“列表 4.3.2”:cgan-mnist-4.3.1.py
突出显示了 DCGAN 中所做的更改:
def build_generator(inputs, labels, image_size):
"""Build a Generator Model
Inputs are concatenated before Dense layer.
Stack of BN-ReLU-Conv2DTranpose to generate fake images.
Output activation is sigmoid instead of tanh in orig DCGAN.
Sigmoid converges easily.
Arguments:
inputs (Layer): Input layer of the generator (the z-vector)
labels (Layer): Input layer for one-hot vector to condition the inputs
image_size: Target size of one side (assuming square image)
Returns:
generator (Model): Generator Model
"""
image_resize = image_size // 4
# network parameters
kernel_size = 5
layer_filters = [128, 64, 32, 1]
x = concatenate([inputs, labels], axis=1)
x = Dense(image_resize * image_resize * layer_filters[0])(x)
x = Reshape((image_resize, image_resize, layer_filters[0]))(x)
for filters in layer_filters:
# first two convolution layers use strides = 2
# the last two use strides = 1
if filters > layer_filters[-2]:
strides = 2
else:
strides = 1
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = Activation('sigmoid')(x)
# input is conditioned by labels
generator = Model([inputs, labels], x, name='generator')
return generator
“列表 4.3.3”突出显示了在train()函数中所做的更改,以适应判别器和生成器的条件一热向量。 首先对 CGAN 判别器进行训练,以一批真实和伪造的数据为条件,这些数据以其各自的热门标签为条件。 然后,在给定单热标签条件假冒数据为假的情况下,通过训练对抗网络来更新生成器参数。 与 DCGAN 相似,在对抗训练中,判别器权重被冻结。
“列表 4.3.3”:cgan-mnist-4.3.1.py
着重介绍了 DCGAN 中所做的更改:
def train(models, data, params):
"""Train the Discriminator and Adversarial Networks
Alternately train Discriminator and Adversarial networks by batch.
Discriminator is trained first with properly labelled real and fake images.
Adversarial is trained next with fake images pretending to be real.
Discriminator inputs are conditioned by train labels for real images,
and random labels for fake images.
Adversarial inputs are conditioned by random labels.
Generate sample images per save_interval.
Arguments:
models (list): Generator, Discriminator, Adversarial models
data (list): x_train, y_train data
params (list): Network parameters
"""
# the GAN models
generator, discriminator, adversarial = models
# images and labels
x_train, y_train = data
# network parameters
batch_size, latent_size, train_steps, num_labels, model_name = params
# the generator image is saved every 500 steps
save_interval = 500
# noise vector to see how the generator output evolves during training
noise_input = np.random.uniform(-1.0, 1.0, size=[16, latent_size])
# one-hot label the noise will be conditioned to
noise_class = np.eye(num_labels)[np.arange(0, 16) % num_labels]
# number of elements in train dataset
train_size = x_train.shape[0]
print(model_name,
"Labels for generated images: ",
np.argmax(noise_class, axis=1))
for i in range(train_steps):
# train the discriminator for 1 batch
# 1 batch of real (label=1.0) and fake images (label=0.0)
# randomly pick real images from dataset
rand_indexes = np.random.randint(0, train_size, size=batch_size)
real_images = x_train[rand_indexes]
# corresponding one-hot labels of real images
real_labels = y_train[rand_indexes]
# generate fake images from noise using generator
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# assign random one-hot labels
fake_labels = np.eye(num_labels)[np.random.choice(num_labels,batch_size)]
# generate fake images conditioned on fake labels
fake_images = generator.predict([noise, fake_labels])
# real + fake images = 1 batch of train data
x = np.concatenate((real_images, fake_images))
# real + fake one-hot labels = 1 batch of train one-hot labels
labels = np.concatenate((real_labels, fake_labels))
# label real and fake images
# real images label is 1.0
y = np.ones([2 * batch_size, 1])
# fake images label is 0.0
y[batch_size:, :] = 0.0
# train discriminator network, log the loss and accuracy
loss, acc = discriminator.train_on_batch([x, labels], y)
log = "%d: [discriminator loss: %f, acc: %f]" % (i, loss, acc)
# train the adversarial network for 1 batch
# 1 batch of fake images conditioned on fake 1-hot labels
# w/ label=1.0
# since the discriminator weights are frozen in
# adversarial network only the generator is trained
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# assign random one-hot labels
fake_labels = np.eye(num_labels)[np.random.choice(num_labels,batch_size)]
# label fake images as real or 1.0
y = np.ones([batch_size, 1])
# train the adversarial network
# note that unlike in discriminator training,
# we do not save the fake images in a variable
# the fake images go to the discriminator input of the adversarial
# for classification
# log the loss and accuracy
loss, acc = adversarial.train_on_batch([noise, fake_labels], y)
log = "%s [adversarial loss: %f, acc: %f]" % (log, loss, acc)
print(log)
if (i + 1) % save_interval == 0:
# plot generator images on a periodic basis
plot_images(generator,
noise_input=noise_input,
noise_class=noise_class,
show=False,
step=(i + 1),
model_name=model_name)
# save the model after training the generator
# the trained generator can be reloaded for
# future MNIST digit generation
generator.save(model_name + ".h5")
“图 4.3.4”显示了当生成器被调整为产生带有以下标签的数字时生成的 MNIST 数字的演变:
[0 1 2 3
4 5 6 7
8 9 0 1
2 3 4 5]
我们可以看到以下结果:

图 4.3.4:使用标签[0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5]对 CGAN 在不同训练步骤中生成的伪造图像
鼓励您运行经过训练的生成器模型,以查看新的合成 MNIST 数字图像:
python3 cgan-mnist-4.3.1.py --generator=cgan_mnist.h5
或者,也可以请求要生成的特定数字(例如 8):
python3 cgan-mnist-4.3.1.py --generator=cgan_mnist.h5 --digit=8
使用 CGAN,就像有一个智能体,我们可以要求绘制数字,类似于人类如何写数字。 与 DCGAN 相比,CGAN 的主要优势在于我们可以指定希望智能体绘制的数字。
4。结论
本章讨论了 GAN 的一般原理,以便为我们现在要讨论的更高级的主题奠定基础,包括改进的 GAN,解缠的表示 GAN 和跨域 GAN。 我们从了解 GAN 如何由两个网络(称为生成器和判别器)组成的这一章开始。 判别器的作用是区分真实信号和虚假信号。 生成器的目的是欺骗判别器。 生成器通常与判别器结合以形成对抗网络。 生成器是通过训练对抗网络来学习如何生成可欺骗判别器的虚假数据的。
我们还了解了 GAN 的构建方法,但众所周知,其操作起来非常困难。 提出了tf.keras中的两个示例实现。 DCGAN 证明了可以训练 GAN 使用深层 CNN 生成伪造图像。 伪造的图像是 MNIST 数字。 但是,DCGAN 生成器无法控制应绘制的特定数字。 CGAN 通过调节生成器以绘制特定数字来解决此问题。 该病是单热标签的形式。 如果我们要构建可以生成特定类数据的智能体,则 CGAN 很有用。
在下一章中,将介绍 DCGAN 和 CGAN 的改进。 特别是,重点将放在如何稳定 DCGAN 的训练以及如何提高 CGAN 的感知质量上。 这将通过引入新的损失函数和稍有不同的模型架构来完成。
5. 参考
Ian Goodfellow. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv preprint arXiv:1701.00160, 2016 (https://arxiv.org/pdf/1701.00160.pdf).Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint arXiv:1511.06434, 2015 (https://arxiv.org/pdf/1511.06434.pdf).Mehdi Mirza and Simon Osindero. Conditional Generative Adversarial Nets. arXiv preprint arXiv:1411.1784, 2014 (https://arxiv.org/pdf/1411.1784.pdf).Tero Karras et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR, 2018 (https://arxiv.org/pdf/1710.10196.pdf).Tero Karras, , Samuli Laine, and Timo Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.Tero Karras et al. Analyzing and Improving the Image Quality of StyleGAN. 2019 (https://arxiv.org/abs/1912.04958).
五、改进的 GAN
自 2014 年引入生成对抗网络(GAN)以来,其流行度迅速提高。 GAN 已被证明是有用的生成模型,可以合成看起来真实的新数据。 深度学习中的许多研究论文都遵循提出的措施来解决原始 GAN 的困难和局限性。
正如我们在前几章中讨论的那样,众所周知,GAN 很难训练,并且易于崩溃。 模式损失是一种情况,即使损失函数已经被优化,但生成器仍会产生看起来相同的输出。 在 MNIST 数字的情况下,模式折叠时,生成器可能只产生数字 4 和 9,因为看起来很相似。 Wasserstein GAN(WGAN)[2]解决了这些问题,认为只需替换基于 Wasserstein 的 GAN 损失函数就可以稳定的训练和避免模式崩溃,也称为陆地移动距离(EMD)。
但是,稳定性问题并不是 GAN 的唯一问题。 也越来越需要来提高所生成图像的感知质量。 最小二乘 GAN(LSGAN)[3]建议同时解决这两个问题。 基本前提是,在训练过程中,Sigmoid 交叉熵损失会导致梯度消失。 这导致较差的图像质量。 最小二乘损失不会导致梯度消失。 与原始 GAN 生成的图像相比,生成的生成图像具有更高的感知质量。
在上一章中,CGAN 介绍了一种调节生成器输出的方法。 例如,如果要获取数字 8,则可以在生成器的输入中包含条件标签。 受 CGAN 的启发,辅助分类器 GAN(ACGAN)[4]提出了一种改进的条件算法,可产生更好的感知质量和输出多样性。
总之,本章的目的是介绍:
- WGAN 的理论描述
- 对 LSGAN 原理的理解
- 对 ACGAN 原理的理解
- 改进的 GAN 的
tf.keras实现 – WGAN,LSGAN 和 ACGAN
让我们从讨论 WGAN 开始。
1. Wasserstein GAN
如前所述,众所周知,GAN 很难训练。 判别器和生成器这两个网络的相反目标很容易导致训练不稳定。 判别器尝试从真实数据中正确分类伪造数据。 同时,生成器将尽最大努力欺骗判别器。 如果判别器的学习速度比生成器快,则生成器参数将无法优化。 另一方面,如果判别器学习较慢,则梯度可能会在到达生成器之前消失。 在最坏的情况下,如果判别器无法收敛,则生成器将无法获得任何有用的反馈。
WGAN 认为 GAN 固有的不稳定性是由于它的损失函数引起的,该函数基于 Jensen-Shannon(JS)距离。 在 GAN 中,生成器的目的是学习如何将一种源分布(例如噪声)从转换为估计的目标分布(例如 MNIST 数字)。 使用 GAN 的原始公式,损失函数实际上是使目标分布与其估计值之间的距离最小。 问题是,对于某些分布对,没有平滑的路径可以最小化此 JS 距离。 因此,训练将无法收敛。
在以下部分中,我们将研究三个距离函数,并分析什么可以替代更适合 GAN 优化的 JS 距离函数。
距离函数
可以通过检查其损失函数来了解训练 GAN 的稳定性。 为了更好地理解 GAN 损失函数,我们将回顾两个概率分布之间的公共距离或散度函数。
我们关注的是用于真实数据分配的p_data与用于生成器数据分配的p_g之间的距离。 GAN 的目标是制造p_g -> p_data。“表 5.1.1”显示了散度函数。
在大多数个最大似然任务中,我们将使用 Kullback-Leibler(KL)散度,或D[KL]损失函数可以衡量我们的神经网络模型预测与真实分布函数之间的距离。 如“公式 5.1.1”所示,由于D[KL](p_data || p_g) ≠ D[KL](p_g || p_data),所以D[KL]不对称。
JS 或D[JS]是基于D[KL]的差异。 但是,与D[KL]不同,D[JS]是对称的并且是有限的。 在本节中,我们将演示优化 GAN 损失函数等同于优化D[JS]:
| 散度 | 表达式 |
|---|---|
| Kullback-Leibler(KL)“公式 5.1.1” |  |
 |
|
| *詹森·香农(JS)“公式 5.1.2” |  |
| 陆地移动距离(EMD)或 Wasserstein 1 “公式 5.1.3” |  |
其中Π(p_data, p_g)是所有联合分布γ(x, y)的集合,其边际为p_data和p_g。 |
表 5.1.1:两个概率分布函数p_data和p_g之间的散度函数
EMD 背后的想法是,它是d = ||x - y||传输多少质量γ(x, y),为了让概率分布p_data匹配p_g的度量。 γ(x, y)是所有可能的联合分布Π(p_data, p_g)的空间中的联合分布。 γ(x, y)也被称为运输计划,以反映运输质量以匹配两个概率分布的策略。 给定两个概率分布,有许多可能的运输计划。 大致而言, inf表示成本最低的运输计划。
例如,“图 5.1.1”向我们展示了两个简单的离散分布x和y:

图 5.1.1:EMD 是从x传输以匹配目标分布y的质量的加权数量。
在位置i = 1, 2, 3, 4上,x在具有质量m[i], i = 1, 2, 3, 4。同时,位置y[i], i = 1, 2上,y的质量为m[i], i = 1, 2。为了匹配分布y,图中的箭头显示了将每个质量x[i]移动d[i]的最小运输计划。 EMD 计算如下:
 (Equation 5.1.4)
(Equation 5.1.4)
在“图 5.1.1”中,EMD 可解释为移动一堆污物x填充孔y所需的最少工作量。 尽管在此示例中,也可以从图中推导出inf,但在大多数情况下,尤其是在连续分布中,用尽所有可能的运输计划是很棘手的。 我们将在本章中稍后回到这个问题。 同时,我们将向您展示 GAN 损失函数的作用,实际上是如何使 JS 的差异最小化。
GAN 中的距离函数
现在,在上一章的损失函数给定任何生成器的情况下,我们将计算最佳判别器。 我们将回顾上一章中的以下等式:
 (Equation 4.1.1)
(Equation 4.1.1)
除了从噪声分布中采样外,前面的等式也可以表示为从生成器分布中采样:
 (Equation 5.1.5)
(Equation 5.1.5)
找出最小的L^(D):
 (Equation 5.1.6)
(Equation 5.1.6)
 (Equation 5.1.7)
(Equation 5.1.7)
积分内部的项为y -> a log(y) + b log(1 - y)的形式,对于不包括{0, 0}的任何a, b ∈ R^2,在y ∈ [0. 1]的a / (a + b)处都有一个已知的最大值。 由于该积分不会更改此表达式的最大值(或L^(D)的最小值)的位置,因此最佳判别器为:
 (Equation 5.1.8)
(Equation 5.1.8)
因此,给定最佳判别器的损失函数为:
 (Equation 5.1.9)
(Equation 5.1.9)
 (Equation 5.1.10)
(Equation 5.1.10)
 (Equation 5.1.11)
(Equation 5.1.11)
 (Equation 5.1.12)
(Equation 5.1.12)
我们可以从“公式 5.1.12”观察到,最佳判别器的损失函数为常数减去真实分布p_data和任何生成器分布p_g之间的 JS 散度的两倍。 最小化L^(D*)意味着最大化D[JS](p_data || p_g),否则判别器必须正确地将真实数据中的伪造物分类。
同时,我们可以放心地说,最佳生成器是当生成器分布等于真实数据分布时:
 (Equation 5.1.13)
(Equation 5.1.13)
这是有道理的,因为生成器的目的是通过学习真实的数据分布来欺骗判别器。 有效地,我们可以通过最小化D[JS]或通过制作p_g -> p_data来获得最佳生成器。 给定最佳生成器,最佳判别器为D*(x) = 1 / 2和L^(D*) = 2log2 = 0.60。
问题在于,当两个分布没有重叠时,就没有平滑函数可以帮助缩小它们之间的差距。 训练 GAN 不会因梯度下降而收敛。 例如,假设:
p_data = (x, y) where x = 0, y ~ U(0, 1) (Equation 5.1.14)
p_g = (x, y) where x = θ, y ~ U(0, 1) (Equation 5.1.15)
这两个分布显示在“图 5.1.2”中:
图 5.1.2:没有重叠的两个分布的示例。 对于p_g,θ = 0.5
 是均匀分布。 每个距离函数的差异如下:
是均匀分布。 每个距离函数的差异如下:




由于D[JS]是一个常数,因此 GAN 将没有足够的梯度来驱动p_g -> p_data。 我们还会发现D[KL]或反向D[KL]也不起作用。 但是,通过W(p_data, p_g),我们可以拥有平滑函数,以便通过梯度下降获得p_g -> p_data。 为了优化 GAN,EMD 或 Wasserstein 1 似乎是一个更具逻辑性的损失函数,因为在两个分布具有极小或没有重叠的情况下,D[JS]会失败。
为了帮助进一步理解,可以在以下位置找到有关距离函数的精彩讨论。
在下一节中,我们将重点介绍使用 EMD 或 Wasserstein 1 距离函数来开发替代损失函数,以鼓励稳定训练 GAN。
使用 Wasserstein 损失
在使用 EMD 或 Wasserstein 1 之前,还有一个要解决的问题。 耗尽Π(p_data, p_g)的空间来找到γ ~ Π(p_data, p_g)是很棘手的。 提出的解决方案是使用其 Kantorovich-Rubinstein 对偶:
 (Equation 5.1.16)
(Equation 5.1.16)
等效地,EMD sup ||f||_L <= 1是所有 K-Lipschitz 函数上的最高值(大约是最大值):f: x -> R。 K-Lipschitz 函数满足以下约束:
 (Equation 5.1.17)
(Equation 5.1.17)
对于所有x[1], x[2] ∈ R。 K-Lipschitz 函数具有有界导数,并且几乎总是连续可微的(例如,f(x) = |x|具有有界导数并且是连续的,但在x = 0时不可微分)。
“公式 5.1.16”可以通过找到 K-Lipschitz 函数{f[w]}, w ∈ W的族来求解:
 (Equation 5.1.18)
(Equation 5.1.18)
在 GAN 中,可以通过从z-噪声分布采样并用f[w]替换“公式 5.1.18”来重写。 鉴别函数,D[w]:
 (Equation 5.1.19)
(Equation 5.1.19)
我们使用粗体字母突出显示多维样本的一般性。 最后一个问题是如何找到函数族w ∈ W。 所提出的解决方案是在每次梯度更新时进行的。 判别器w的权重被限制在上下限之间(例如,-0.01 和 0.01):
 (Equation 5.1.20)
(Equation 5.1.20)
w的较小值将判别器约束到紧凑的参数空间,从而确保 Lipschitz 连续性。
我们可以使用“公式 5.1.19”作为我们新的 GAN 损失函数的基础。 EMD 或 Wasserstein 1 是生成器旨在最小化的损失函数,以及判别器试图最大化的损失函数(或最小化-W(p_data, p_g):
 (Equation 5.1.21)
(Equation 5.1.21)
 (Equation 5.1.22)
(Equation 5.1.22)
在生成器损失函数中,第一项消失了,因为它没有针对实际数据进行直接优化。
“表 5.1.2”显示了 GAN 和 WGAN 的损失函数之间的差异。 为简洁起见,我们简化了L^(D)和L^(G)的表示法:
| 网络 | 损失函数 | 公式 |
|---|---|---|
| GAN |  |
4.1.1 |
 |
4.1.5 | |
| WGAN |  |
5.1.21 |
 |
5.1.22 | |
 |
5.1.20 |
表 5.1.2:GAN 和 WGAN 的损失函数之间的比较
这些损失函数用于训练 WGAN,如“算法 5.1.1”中所示。
算法 5.1.1 WGAN。 参数的值为α = 0.00005,c = 0.01,m = 64和n_critic = 5。
要求:α,学习率。c是削波参数。m,批量大小。 n_critic,即每个生成器迭代的评论(鉴别)迭代次数。
要求:w[D],初始判别器(discriminator)参数。 θ[D],初始生成器参数:
-
当
θ[D]尚未收敛,执行: -
对于
t = 1, ..., n_critic,执行: -
从真实数据中抽样一批
{x^(i)} ~ p_data, i = 1, ..., m -
从均匀的噪声分布中采样一批
{z^(i)} ~ p_x, i = 1, ..., m -

计算判别器梯度
-

更新判别器参数
-

剪辑判别器权重
-
end for -
从均匀的噪声分布中采样一批
{z^(i)} ~ p_x, i = 1, ..., m -

计算生成器梯度

更新生成器参数
end while
“图 5.1.3”展示了 WGAN 模型实际上与 DCGAN 相同,除了伪造的/真实的数据标签和损失函数:

图 5.1.3:顶部:训练 WGAN 判别器需要来自生成器的虚假数据和来自真实分发的真实数据。 下:训练 WGAN 生成器要求生成器中假冒的真实数据是真实的
与 GAN 相似,WGAN 交替训练判别器和生成器(通过对抗)。 但是,在 WGAN 中,判别器(也称为评论者)在训练生成器进行一次迭代(第 9 至 11 行)之前,先训练n_critic迭代(第 2 至 8 行)。 这与对于判别器和生成器具有相同数量的训练迭代的 GAN 相反。 换句话说,在 GAN 中,n_critic = 1。
训练判别器意味着学习判别器的参数(权重和偏差)。 这需要从真实数据中采样一批(第 3 行),并从伪数据中采样一批(第 4 行),然后将采样数据馈送到判别器网络,然后计算判别器参数的梯度(第 5 行)。 判别器参数使用 RMSProp(第 6 行)进行了优化。 第 5 行和第 6 行都是“公式 5.1.21”的优化。
最后,EM 距离优化中的 Lipschitz 约束是通过裁剪判别器参数(第 7 行)来施加的。 第 7 行是“公式 5.1.20”的实现。 在n_critic迭代判别器训练之后,判别器参数被冻结。 生成器训练通过对一批伪造数据进行采样开始(第 9 行)。 采样的数据被标记为实数(1.0),以致愚弄判别器网络。 在第 10 行中计算生成器梯度,并在第 11 行中使用 RMSProp 对其进行优化。第 10 行和第 11 行执行梯度更新以优化“公式 5.1.22”。
训练生成器后,将解冻判别器参数,并开始另一个n_critic判别器训练迭代。 我们应该注意,在判别器训练期间不需要冻结生成器参数,因为生成器仅涉及数据的制造。 类似于 GAN,可以将判别器训练为一个单独的网络。 但是,训练生成器始终需要判别器通过对抗网络参与,因为损失是根据生成器网络的输出计算得出的。
与 GAN 不同,在 WGAN 中,将实际数据标记为 1.0,而将伪数据标记为 -1.0,作为计算第 5 行中的梯度的一种解决方法。第 5-6 和 10-11 行执行梯度更新以优化“公式 5.1.21”和“5.1.22”。 第 5 行和第 10 行中的每一项均建模为:
 (Equation 5.1.23)
(Equation 5.1.23)
对于真实数据,其中y_label = 1.0,对于假数据,y_label= -1.0。 为了简化符号,我们删除了上标(i)。 对于判别器,当使用实际数据进行训练时,WGAN 增加y_pred = D[w](x)以最小化损失函数。
使用伪造数据进行训练时,WGAN 会降低y_pred = D[w](g(z))以最大程度地减少损失函数。 对于生成器,当在训练过程中将伪数据标记为真实数据时,WGAN 增加y_pred = D[w](g(z))以最小化损失函数。 请注意,y_label除了其符号外,对损失函数没有直接贡献。 在tf.keras中,“公式 5.1.23”实现为:
def wasserstein_loss(y_label, y_pred):
return -K.mean(y_label * y_pred)
本节最重要的部分是用于稳定训练 GAN 的新损失函数。 它基于 EMD 或 Wasserstein1。“算法 5.1.1”形式化了 WGAN 的完整训练算法,包括损失函数。 在下一节中,将介绍tf.keras中训练算法的实现。
使用 Keras 的 WGAN 实现
为了在tf.keras中实现 WGAN,我们可以重用 GAN 的 DCGAN 实现,这是我们在上一一章中介绍的。 DCGAN 构建器和工具函数在lib文件夹的gan.py中作为模块实现。
函数包括:
generator():生成器模型构建器discriminator():判别器模型构建器train():DCGAN 训练师plot_images():通用生成器输出绘图仪test_generator():通用的生成器测试工具
如“列表 5.1.1”所示,我们可以通过简单地调用以下命令来构建一个判别器:
discriminator = gan.discriminator(inputs, activation='linear')
WGAN 使用线性输出激活。 对于生成器,我们执行:
generator = gan.generator(inputs, image_size)
tf.keras中的整体网络模型类似于 DCGAN 的“图 4.2.1”中看到的模型。
“列表 5.1.1”突出显示了 RMSprop 优化器和 Wasserstein 损失函数的使用。 在训练期间使用“算法 5.1.1”中的超参数。
“列表 5.1.1”:wgan-mnist-5.1.2.py
def build_and_train_models():
"""Load the dataset, build WGAN discriminator,
generator, and adversarial models.
Call the WGAN train routine.
"""
# load MNIST dataset
(x_train, _), (_, _) = mnist.load_data()
# reshape data for CNN as (28, 28, 1) and normalize
image_size = x_train.shape[1]
x_train = np.reshape(x_train, [-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
model_name = "wgan_mnist"
# network parameters
# the latent or z vector is 100-dim
latent_size = 100
# hyper parameters from WGAN paper [2]
n_critic = 5
clip_value = 0.01
batch_size = 64
lr = 5e-5
train_steps = 40000
input_shape = (image_size, image_size, 1)
# build discriminator model
inputs = Input(shape=input_shape, name='discriminator_input')
# WGAN uses linear activation in paper [2]
discriminator = gan.discriminator(inputs, activation='linear')
optimizer = RMSprop(lr=lr)
# WGAN discriminator uses wassertein loss
discriminator.compile(loss=wasserstein_loss,
optimizer=optimizer,
metrics=['accuracy'])
discriminator.summary()
# build generator model
input_shape = (latent_size, )
inputs = Input(shape=input_shape, name='z_input')
generator = gan.generator(inputs, image_size)
generator.summary()
# build adversarial model = generator + discriminator
# freeze the weights of discriminator during adversarial training
discriminator.trainable = False
adversarial = Model(inputs,
discriminator(generator(inputs)),
name=model_name)
adversarial.compile(loss=wasserstein_loss,
optimizer=optimizer,
metrics=['accuracy'])
adversarial.summary()
# train discriminator and adversarial networks
models = (generator, discriminator, adversarial)
params = (batch_size,
latent_size,
n_critic,
clip_value,
train_steps,
model_name)
train(models, x_train, params)
“列表 5.1.2”是紧跟“算法 5.1.1”的训练函数。 但是,在判别器的训练中有一个小的调整。 与其在单个合并的真实数据和虚假数据中组合训练权重,不如先训练一批真实数据,然后再训练一批虚假数据。 这种调整将防止梯度消失,因为真实和伪造数据标签中的符号相反,并且由于裁剪而导致的权重较小。
“列表 5.1.2”:wgan-mnist-5.1.2.py
为 WGAN 训练算法:
def train(models, x_train, params):
"""Train the Discriminator and Adversarial Networks
Alternately train Discriminator and Adversarial
networks by batch.
Discriminator is trained first with properly labelled
real and fake images for n_critic times.
Discriminator weights are clipped as a requirement
of Lipschitz constraint.
Generator is trained next (via Adversarial) with
fake images pretending to be real.
Generate sample images per save_interval
Arguments:
models (list): Generator, Discriminator,
Adversarial models
x_train (tensor): Train images
params (list) : Networks parameters
"""
# the GAN models
generator, discriminator, adversarial = models
# network parameters
(batch_size, latent_size, n_critic,
clip_value, train_steps, model_name) = params
# the generator image is saved every 500 steps
save_interval = 500
# noise vector to see how the
# generator output evolves during training
noise_input = np.random.uniform(-1.0,
1.0,
size=[16, latent_size])
# number of elements in train dataset
train_size = x_train.shape[0]
# labels for real data
real_labels = np.ones((batch_size, 1))
for i in range(train_steps):
# train discriminator n_critic times
loss = 0
acc = 0
for _ in range(n_critic):
# train the discriminator for 1 batch
# 1 batch of real (label=1.0) and
# fake images (label=-1.0)
# randomly pick real images from dataset
rand_indexes = np.random.randint(0,
train_size,
size=batch_size)
real_images = x_train[rand_indexes]
# generate fake images from noise using generator
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
fake_images = generator.predict(noise)
# train the discriminator network
# real data label=1, fake data label=-1
# instead of 1 combined batch of real and fake images,
# train with 1 batch of real data first, then 1 batch
# of fake images.
# this tweak prevents the gradient
# from vanishing due to opposite
# signs of real and fake data labels (i.e. +1 and -1) and
# small magnitude of weights due to clipping.
real_loss, real_acc = \
discriminator.train_on_batch(real_images,
real_labels)
fake_loss, fake_acc = \
discriminator.train_on_batch(fake_images,
-real_labels)
# accumulate average loss and accuracy
loss += 0.5 * (real_loss + fake_loss)
acc += 0.5 * (real_acc + fake_acc)
# clip discriminator weights to satisfy Lipschitz constraint
for layer in discriminator.layers:
weights = layer.get_weights()
weights = [np.clip(weight,
-clip_value,
clip_value) for weight in weights]
layer.set_weights(weights)
# average loss and accuracy per n_critic training iterations
loss /= n_critic
acc /= n_critic
log = "%d: [discriminator loss: %f, acc: %f]" % (i, loss, acc)
# train the adversarial network for 1 batch
# 1 batch of fake images with label=1.0
# since the discriminator weights are frozen in
# adversarial network only the generator is trained
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# train the adversarial network
# note that unlike in discriminator training,
# we do not save the fake images in a variable
# the fake images go to the discriminator
# input of the adversarial for classification
# fake images are labelled as real
# log the loss and accuracy
loss, acc = adversarial.train_on_batch(noise, real_labels)
log = "%s [adversarial loss: %f, acc: %f]" % (log, loss, acc)
print(log)
if (i + 1) % save_interval == 0:
# plot generator images on a periodic basis
gan.plot_images(generator,
noise_input=noise_input,
show=False,
step=(i + 1),
model_name=model_name)
# save the model after training the generator
# the trained generator can be reloaded
# for future MNIST digit generation
generator.save(model_name + ".h5")
“图 5.1.4”显示了 MNIST 数据集上 WGAN 输出的演变:

图 5.1.4:WGAN 与训练步骤的示例输出。 在训练和测试期间,WGAN 的任何输出均不会遭受模式崩溃
即使在网络配置更改的情况下,WGAN 也稳定。 例如,当在识别符网络的 ReLU 之前插入批量规范化时,已知 DCGAN 不稳定。 在 WGAN 中,相同的配置是稳定的。
下图“图 5.1.5”向我们展示了 DCGAN 和 WGAN 的输出,并在判别器网络上进行了批量归一化:

图 5.1.5:在判别器网络中的 ReLU 激活之前插入批量归一化时,DCGAN(左)和 WGAN(右)的输出比较
与上一章中的 GAN 训练相似,经过 40,000 个训练步骤,将训练后的模型保存在文件中。 使用训练有素的生成器模型,通过运行以下命令来生成新的合成 MNIST 数字图像:
python3 wgan-mnist-5.1.2.py --generator=wgan_mnist.h5
正如我们所讨论的,原始 GAN 很难训练。 当 GAN 优化的损失函数时,就会出现问题。 实际上是在优化 JS 差异,D[JS]。 当两个分布函数之间几乎没有重叠时,很难优化D[JS]。
WGAN 提出通过使用 EMD 或 Wasserstein 1 损失函数来解决该问题,该函数即使在两个分布之间很少或没有重叠时也具有平滑的微分函数。 但是,WGAN 与生成的图像质量无关。 除了稳定性问题之外,原始 GAN 生成的图像在感知质量方面还有很多改进的地方。 LSGAN 理论上可以同时解决两个问题。 在下一节中,我们将介绍 LSGAN。
2. 最小二乘 GAN(LSGAN)
LSGAN 提出最小二乘损失。“图 5.2.1”演示了为什么在 GAN 中使用 Sigmoid 交叉熵损失会导致生成的数据质量较差:

图 5.2.1:真实样本和虚假样本分布均除以各自的决策边界:Sigmoid 和最小二乘
理想情况下,假样本分布应尽可能接近真实样本的分布。 但是,对于 GAN,一旦伪样本已经位于决策边界的正确一侧,梯度就消失了。
这会阻止生成器具有足够的动机来提高生成的伪数据的质量。 远离决策边界的伪样本将不再试图靠近真实样本的分布。 使用最小二乘损失函数,只要假样本分布与真实样本的分布相距甚远,梯度就不会消失。 即使假样本已经位于决策边界的正确一侧,生成器也将努力改善其对实际密度分布的估计。
“表 5.2.1”显示了 GAN,WGAN 和 LSGAN 之间的损失函数的比较:
| 网络 | 损失函数 | 公式 |
|---|---|---|
| GAN |  |
4.1.1 |
 |
4.1.5 | |
| WGAN | 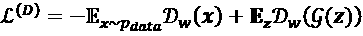 |
5.1.21 |
 |
5.1.22 | |
 |
5.1.20 | |
| LSGAN |  |
5.2.1 |
 |
5.2.2 |
表 5.2.1:GAN,WGAN 和 LSGAN 损失函数之间的比较
最小化“公式 5.2.1”或判别器损失函数意味着实际数据分类与真实标签 1.0 之间的 MSE 应该接近零。 此外,假数据分类和真实标签 0.0 之间的 MSE 应该接近零。
与其他 GAN 相似,对 LSGAN 判别器进行了训练,可以从假数据样本中对真实数据进行分类。 最小化公式 5.2.2 意味着在标签 1.0 的帮助下,使判别器认为生成的假样本数据是真实的。
以上一章中的 DCGAN 代码为基础来实现 LSGAN 仅需进行一些更改。 如“列表 5.2.1”所示,删除了判别器 Sigmoid 激活。 判别器是通过调用以下命令构建的:
discriminator = gan.discriminator(inputs, activation=None)
生成器类似于原始的 DCGAN:
generator = gan.generator(inputs, image_size)
鉴别函数和对抗损失函数都被mse代替。 所有网络参数均与 DCGAN 中的相同。 tf.keras中 LSGAN 的网络模型类似于“图 4.2.1”,除了存在线性激活或无输出激活外。 训练过程类似于 DCGAN 中的训练过程,由工具函数提供:
gan.train(models, x_train, params)
“列表 5.2.1”:lsgan-mnist-5.2.1.py
def build_and_train_models():
"""Load the dataset, build LSGAN discriminator,
generator, and adversarial models.
Call the LSGAN train routine.
"""
# load MNIST dataset
(x_train, _), (_, _) = mnist.load_data()
# reshape data for CNN as (28, 28, 1) and normalize
image_size = x_train.shape[1]
x_train = np.reshape(x_train,
[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
model_name = "lsgan_mnist"
# network parameters
# the latent or z vector is 100-dim
latent_size = 100
input_shape = (image_size, image_size, 1)
batch_size = 64
lr = 2e-4
decay = 6e-8
train_steps = 40000
# build discriminator model
inputs = Input(shape=input_shape, name='discriminator_input')
discriminator = gan.discriminator(inputs, activation=None)
# [1] uses Adam, but discriminator easily
# converges with RMSprop
optimizer = RMSprop(lr=lr, decay=decay)
# LSGAN uses MSE loss [2]
discriminator.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
discriminator.summary()
# build generator model
input_shape = (latent_size, )
inputs = Input(shape=input_shape, name='z_input')
generator = gan.generator(inputs, image_size)
generator.summary()
# build adversarial model = generator + discriminator
optimizer = RMSprop(lr=lr*0.5, decay=decay*0.5)
# freeze the weights of discriminator
# during adversarial training
discriminator.trainable = False
adversarial = Model(inputs,
discriminator(generator(inputs)),
name=model_name)
# LSGAN uses MSE loss [2]
adversarial.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
adversarial.summary()
# train discriminator and adversarial networks
models = (generator, discriminator, adversarial)
params = (batch_size, latent_size, train_steps, model_name)
gan.train(models, x_train, params)
“图 5.2.2”显示了使用 MNIST 数据集对 40,000 个训练步骤进行 LSGAN 训练后生成的样本:

图 5.2.2:LSGAN 的示例输出与训练步骤
与上一章中 DCGAN 中的“图 4.2.1”相比,输出图像的感知质量更好。
使用训练有素的生成器模型,通过运行以下命令来生成新的合成 MNIST 数字图像:
python3 lsgan-mnist-5.2.1.py --generator=lsgan_mnist.h5
在本节中,我们讨论了损失函数的另一种改进。 通过使用 MSE 或 L2,我们解决了训练 GAN 的稳定性和感知质量的双重问题。 在下一节中,提出了相对于 CGAN 的另一项改进,这已在上一章中进行了讨论。
3. 辅助分类器 GAN (ACGAN)
ACGAN 在原理上类似于我们在上一章中讨论的条件 GAN(CGAN)。 我们将比较 CGAN 和 ACGAN。 对于 CGAN 和 ACGAN,生成器输入均为噪声及其标签。 输出是属于输入类标签的伪图像。 对于 CGAN,判别器的输入是图像(假的或真实的)及其标签。 输出是图像真实的概率。 对于 ACGAN,判别器的输入是一幅图像,而输出是该图像是真实的且其类别是标签的概率。
“图 5.3.1”突出显示了生成器训练期间 CGAN 和 ACGAN 之间的区别:

图 5.3.1:CGAN 与 ACGAN 生成器训练。 主要区别是判别器的输入和输出
本质上,在 CGAN 中,我们向网络提供了边信息(标签)。 在 ACGAN 中,我们尝试使用辅助类解码器网络重建辅助信息。 ACGAN 理论认为,强制网络执行其他任务可以提高原始任务的表现。 在这种情况下,附加任务是图像分类。 原始任务是生成伪造图像。
“表 5.3.1”显示了 ACGAN 损失函数与 CGAN 损失函数的比较:
| 网络 | 损失函数 | 编号 |
|---|---|---|
| CGAN |  |
4.3.1 |
 |
4.3.2 | |
| ACGAN |  |
5.3.1 |
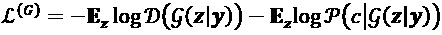 |
5.3.2 |
表 5.3.1:CGAN 和 ACGAN 损失函数之间的比较
ACGAN 损失函数与 CGAN 相同,除了附加的分类器损失函数。 除了从假图片中识别真实图像的原始任务之外,判别器的“公式 5.3.1”还具有对真假图像正确分类的附加任务。 生成器的“公式 5.3.2”意味着,除了尝试用伪造的图像来欺骗判别器(-E[z] log D(g(z | y)))之外,它还要求判别器正确地对那些伪造的图像进行分类(-E[z] log P(c | g(z | y)))。
从 CGAN 代码开始,仅修改判别器和训练函数以实现 ACGAN。 gan.py还提供了判别器和生成器构建器函数。 要查看判别器上所做的更改,清单 5.3.1 显示了构建器函数,其中突出显示了执行图像分类的辅助解码器网络和双输出。
“列表 5.3.1”:gan.py
def discriminator(inputs,
activation='sigmoid',
num_labels=None,
num_codes=None):
"""Build a Discriminator Model
Stack of LeakyReLU-Conv2D to discriminate real from fake
The network does not converge with BN so it is not used here
unlike in [1]
Arguments:
inputs (Layer): Input layer of the discriminator (the image)
activation (string): Name of output activation layer
num_labels (int): Dimension of one-hot labels for ACGAN & InfoGAN
num_codes (int): num_codes-dim Q network as output
if StackedGAN or 2 Q networks if InfoGAN
Returns:
Model: Discriminator Model
"""
kernel_size = 5
layer_filters = [32, 64, 128, 256]
x = inputs
for filters in layer_filters:
# first 3 convolution layers use strides = 2
# last one uses strides = 1
if filters == layer_filters[-1]:
strides = 1
else:
strides = 2
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
x = Flatten()(x)
# default output is probability that the image is real
outputs = Dense(1)(x)
if activation is not None:
print(activation)
outputs = Activation(activation)(outputs)
if num_labels:
# ACGAN and InfoGAN have 2nd output
# 2nd output is 10-dim one-hot vector of label
layer = Dense(layer_filters[-2])(x)
labels = Dense(num_labels)(layer)
labels = Activation('softmax', name='label')(labels)
if num_codes is None:
outputs = [outputs, labels]
else:
# InfoGAN have 3rd and 4th outputs
# 3rd output is 1-dim continous Q of 1st c given x
code1 = Dense(1)(layer)
code1 = Activation('sigmoid', name='code1')(code1)
# 4th output is 1-dim continuous Q of 2nd c given x
code2 = Dense(1)(layer)
code2 = Activation('sigmoid', name='code2')(code2)
outputs = [outputs, labels, code1, code2]
elif num_codes is not None:
# StackedGAN Q0 output
# z0_recon is reconstruction of z0 normal distribution
z0_recon = Dense(num_codes)(x)
z0_recon = Activation('tanh', name='z0')(z0_recon)
outputs = [outputs, z0_recon]
return Model(inputs, outputs, name='discriminator')
然后通过调用以下命令来构建判别器:
discriminator = gan.discriminator(inputs, num_labels=num_labels)
生成器与 WGAN 和 LSGAN 中的生成器相同。 回想一下,在以下“列表 5.3.2”中显示了生成器生成器。 我们应该注意,“列表 5.3.1”和“5.3.2”与上一节中 WGAN 和 LSGAN 使用的生成器函数相同。 重点介绍了适用于 LSGAN 的部件。
“列表 5.3.2”:gan.py
def generator(inputs,
image_size,
activation='sigmoid',
labels=None,
codes=None):
"""Build a Generator Model
Stack of BN-ReLU-Conv2DTranpose to generate fake images.
Output activation is sigmoid instead of tanh in [1].
Sigmoid converges easily.
Arguments:
inputs (Layer): Input layer of the generator (the z-vector)
image_size (int): Target size of one side
(assuming square image)
activation (string): Name of output activation layer
labels (tensor): Input labels
codes (list): 2-dim disentangled codes for InfoGAN
Returns:
Model: Generator Model
"""
image_resize = image_size // 4
# network parameters
kernel_size = 5
layer_filters = [128, 64, 32, 1]
if labels is not None:
if codes is None:
# ACGAN labels
# concatenate z noise vector and one-hot labels
inputs = [inputs, labels]
else:
# infoGAN codes
# concatenate z noise vector,
# one-hot labels and codes 1 & 2
inputs = [inputs, labels] + codes
x = concatenate(inputs, axis=1)
elif codes is not None:
# generator 0 of StackedGAN
inputs = [inputs, codes]
x = concatenate(inputs, axis=1)
else:
# default input is just 100-dim noise (z-code)
x = inputs
x = Dense(image_resize * image_resize * layer_filters[0])(x)
x = Reshape((image_resize, image_resize, layer_filters[0]))(x)
for filters in layer_filters:
# first two convolution layers use strides = 2
# the last two use strides = 1
if filters > layer_filters[-2]:
strides = 2
else:
strides = 1
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2DTranspose(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='same')(x)
if activation is not None:
x = Activation(activation)(x)
# generator output is the synthesized image x
return Model(inputs, x, name='generator')
在 ACGAN 中,生成器实例化为:
generator = gan.generator(inputs, image_size, labels=labels)
“图 5.3.2”显示了tf.keras中 ACGAN 的网络模型:

图 5.3.2:ACGAN 的tf.keras模型
如“列表 5.3.3”所示,对判别器和对抗模型进行了修改,以适应判别器网络中的更改。 现在,我们有两个损失函数。 首先是原始的二进制交叉熵,用于训练判别器来估计输入图像为实的概率。
第二个是图像分类器,用于预测类别标签。 输出是一个 10 维的单热向量。
“列表 5.3.3”:acgan-mnist-5.3.1.py
重点介绍了在判别器和对抗网络中实现的更改:
def build_and_train_models():
"""Load the dataset, build ACGAN discriminator,
generator, and adversarial models.
Call the ACGAN train routine.
"""
# load MNIST dataset
(x_train, y_train), (_, _) = mnist.load_data()
# reshape data for CNN as (28, 28, 1) and normalize
image_size = x_train.shape[1]
x_train = np.reshape(x_train,
[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
# train labels
num_labels = len(np.unique(y_train))
y_train = to_categorical(y_train)
model_name = "acgan_mnist"
# network parameters
latent_size = 100
batch_size = 64
train_steps = 40000
lr = 2e-4
decay = 6e-8
input_shape = (image_size, image_size, 1)
label_shape = (num_labels, )
# build discriminator Model
inputs = Input(shape=input_shape,
name='discriminator_input')
# call discriminator builder
# with 2 outputs, pred source and labels
discriminator = gan.discriminator(inputs,
num_labels=num_labels)
# [1] uses Adam, but discriminator
# easily converges with RMSprop
optimizer = RMSprop(lr=lr, decay=decay)
# 2 loss fuctions: 1) probability image is real
# 2) class label of the image
loss = ['binary_crossentropy', 'categorical_crossentropy']
discriminator.compile(loss=loss,
optimizer=optimizer,
metrics=['accuracy'])
discriminator.summary()
# build generator model
input_shape = (latent_size, )
inputs = Input(shape=input_shape, name='z_input')
labels = Input(shape=label_shape, name='labels')
# call generator builder with input labels
generator = gan.generator(inputs,
image_size,
labels=labels)
generator.summary()
# build adversarial model = generator + discriminator
optimizer = RMSprop(lr=lr*0.5, decay=decay*0.5)
# freeze the weights of discriminator
# during adversarial training
discriminator.trainable = False
adversarial = Model([inputs, labels],
discriminator(generator([inputs, labels])),
name=model_name)
# same 2 loss fuctions: 1) probability image is real
# 2) class label of the image
adversarial.compile(loss=loss,
optimizer=optimizer,
metrics=['accuracy'])
adversarial.summary()
# train discriminator and adversarial networks
models = (generator, discriminator, adversarial)
data = (x_train, y_train)
params = (batch_size, latent_size, \
train_steps, num_labels, model_name)
train(models, data, params)
在“列表 5.3.4”中,我们重点介绍了训练例程中实现的更改。 将与 CGAN 代码进行比较的主要区别在于,必须在鉴别和对抗训练中提供输出标签。
“列表 5.3.4”:acgan-mnist-5.3.1.py
def train(models, data, params):
"""Train the discriminator and adversarial Networks
Alternately train discriminator and adversarial
networks by batch.
Discriminator is trained first with real and fake
images and corresponding one-hot labels.
Adversarial is trained next with fake images pretending
to be real and corresponding one-hot labels.
Generate sample images per save_interval.
# Arguments
models (list): Generator, Discriminator,
Adversarial models
data (list): x_train, y_train data
params (list): Network parameters
"""
# the GAN models
generator, discriminator, adversarial = models
# images and their one-hot labels
x_train, y_train = data
# network parameters
batch_size, latent_size, train_steps, num_labels, model_name \
= params
# the generator image is saved every 500 steps
save_interval = 500
# noise vector to see how the generator
# output evolves during training
noise_input = np.random.uniform(-1.0,
1.0,
size=[16, latent_size])
# class labels are 0, 1, 2, 3, 4, 5,
# 6, 7, 8, 9, 0, 1, 2, 3, 4, 5
# the generator must produce these MNIST digits
noise_label = np.eye(num_labels)[np.arange(0, 16) % num_labels]
# number of elements in train dataset
train_size = x_train.shape[0]
print(model_name,
"Labels for generated images: ",
np.argmax(noise_label, axis=1))
for i in range(train_steps):
# train the discriminator for 1 batch
# 1 batch of real (label=1.0) and fake images (label=0.0)
# randomly pick real images and
# corresponding labels from dataset
rand_indexes = np.random.randint(0,
train_size,
size=batch_size)
real_images = x_train[rand_indexes]
real_labels = y_train[rand_indexes]
# generate fake images from noise using generator
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# randomly pick one-hot labels
fake_labels = np.eye(num_labels)[np.random.choice(num_labels,
batch_size)]
# generate fake images
fake_images = generator.predict([noise, fake_labels])
# real + fake images = 1 batch of train data
x = np.concatenate((real_images, fake_images))
# real + fake labels = 1 batch of train data labels
labels = np.concatenate((real_labels, fake_labels))
# label real and fake images
# real images label is 1.0
y = np.ones([2 * batch_size, 1])
# fake images label is 0.0
y[batch_size:, :] = 0
# train discriminator network, log the loss and accuracy
# ['loss', 'activation_1_loss',
# 'label_loss', 'activation_1_acc', 'label_acc']
metrics = discriminator.train_on_batch(x, [y, labels])
fmt = "%d: [disc loss: %f, srcloss: %f,"
fmt += "lblloss: %f, srcacc: %f, lblacc: %f]"
log = fmt % (i, metrics[0], metrics[1], \
metrics[2], metrics[3], metrics[4])
# train the adversarial network for 1 batch
# 1 batch of fake images with label=1.0 and
# corresponding one-hot label or class
# since the discriminator weights are frozen
# in adversarial network only the generator is trained
# generate noise using uniform distribution
noise = np.random.uniform(-1.0,
1.0,
size=[batch_size, latent_size])
# randomly pick one-hot labels
fake_labels = np.eye(num_labels)[np.random.choice(num_labels,
batch_size)]
# label fake images as real
y = np.ones([batch_size, 1])
# train the adversarial network
# note that unlike in discriminator training,
# we do not save the fake images in a variable
# the fake images go to the discriminator input
# of the adversarial for classification
# log the loss and accuracy
metrics = adversarial.train_on_batch([noise, fake_labels],
[y, fake_labels])
fmt = "%s [advr loss: %f, srcloss: %f,"
fmt += "lblloss: %f, srcacc: %f, lblacc: %f]"
log = fmt % (log, metrics[0], metrics[1],\
metrics[2], metrics[3], metrics[4])
print(log)
if (i + 1) % save_interval == 0:
# plot generator images on a periodic basis
gan.plot_images(generator,
noise_input=noise_input,
noise_label=noise_label,
show=False,
step=(i + 1),
model_name=model_name)
# save the model after training the generator
# the trained generator can be reloaded
# for future MNIST digit generation
generator.save(model_name + ".h5")
可以看出,与其他任务相比,与我们之前讨论的所有 GAN 相比,ACGAN 的表现显着提高。 ACGAN 训练是稳定的,如“图 5.3.3”的 ACGAN 示例输出的以下标签所示:
[0 1 2 3
4 5 6 7
8 9 0 1
2 3 4 5]
与 CGAN 不同,样本输出的外观在训练过程中变化不大。 MNIST 数字图像的感知质量也更好。

图 5.3.3:ACGAN 根据标签的训练步骤生成的示例输出[0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5]
使用训练有素的生成器模型,通过运行以下命令来生成新的合成 MNIST 数字图像:
python3 acgan-mnist-5.3.1.py --generator=acgan_mnist.h5
或者,也可以请求生成要生成的特定数字(例如 3):
python3 acgan-mnist-5.3.1.py --generator=acgan_mnist.h5 --digit=3
“图 5.3.4”显示了 CGAN 和 ACGAN 产生的每个 MNIST 数字的并排比较。 ACGAN 中的数字 2-6 比 CGAN 中的数字质量更好:

图 5.3.4:以数字 0 到 9 为条件的 CGAN 和 ACGAN 输出的并排比较
与 WGAN 和 LSGAN 相似,ACGAN 通过微调的损失函数,对现有 GAN CGAN 进行了改进。 在接下来的章节中,我们将发现新的损失函数,这些函数将使 GAN 能够执行新的有用任务。
4. 总结
在本章中,我们介绍了对原始 GAN 算法的各种改进,这些改进在上一章中首次介绍。 WGAN 提出了一种通过使用 EMD 或 Wasserstein 1 损失来提高训练稳定性的算法。 LSGAN 认为,与最小二乘损失不同,GANs 的原始交叉熵函数倾向于消失梯度。 LSGAN 提出了一种实现稳定训练和高质量输出的算法。 ACGAN 通过要求判别器在确定输入图像是假的还是真实的基础上执行分类任务,来令人信服地提高了 MNIST 数字有条件生成的质量。
在下一章中,我们将研究如何控制生成器输出的属性。 尽管 CGAN 和 ACGAN 可以指示要生成的期望数字,但我们尚未分析可以指定输出属性的 GAN。 例如,我们可能想要控制 MNIST 数字的书写风格,例如圆度,倾斜角度和厚度。 因此,目标是引入具有纠缠表示的 GAN,以控制生成器输出的特定属性。
5. 参考
Ian Goodfellow et al.: Generative Adversarial Nets. Advances in neural information processing systems, 2014 (http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf).Martin Arjovsky, Soumith Chintala, and Léon Bottou: Wasserstein GAN. arXiv preprint, 2017 (https://arxiv.org/pdf/1701.07875.pdf).Xudong Mao et al.: Least Squares Generative Adversarial Networks. 2017 IEEE International Conference on Computer Vision (ICCV). IEEE 2017 (http://openaccess.thecvf.com/content_ICCV_2017/papers/Mao_Least_Squares_Generative_ICCV_2017_paper.pdf).Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional Image Synthesis with Auxiliary Classifier GANs. ICML, 2017 (http://proceedings.mlr.press/v70/odena17a/odena17a.pdf).