译者:飞龙
六、性能分析,调试和测试
分析,调试和测试是开发过程的组成部分。 您可能熟悉单元测试的概念。 单元测试是程序员编写的用于测试其代码的自动测试。 例如,这些测试可以单独测试函数或函数的一部分。 每次测试仅测试一小部分代码。 这样做的好处是提高了对代码质量的信心,可重复进行的测试,以及副作用,使代码更清晰,更正确。 单元测试还促进了协作编辑,因为通常没有人会自己理解复杂项目中的所有代码,因此,单元测试可防止贡献者破坏现有代码。 Python 对单元测试有很好的支持。 NumPy 添加了numpy.testing包,以帮助 NumPy 对单元测试进行编码。
本章的主题包括:
- 断言
- 性能分析
- 调试
- 单元测试
断言函数
NumPy 测试包具有许多工具函数,用于测试前提条件是否为真。 下表列出了 NumPy 断言函数:
| 函数 | 描述 |
|---|---|
assert_almost_equal |
如果两个数字在指定精度上不相等,则此引发异常 |
assert_approx_equal |
如果两个数字在一定重要性上不相等,则会引发异常 |
assert_array_almost_equal |
如果两个数组在指定精度上不相等,则会引发异常 |
assert_array_equal |
如果两个数组不相等,则此引发异常 |
assert_array_less |
如果两个数组的形状不同,并且第一个数组的元素严格小于第二个数组的元素,则会引发异常 |
assert_equal |
如果两个对象不相等,则此引发异常 |
assert_raises |
如果使用定义的参数调用的可调用函数未引发指定的异常,则此操作失败 |
assert_warns |
如果未引发指定的警告,则会失败 |
assert_string_equal |
断言两个字符串相等 |
assert_almost_equal函数
由于浮点点号的性质及其在计算机中的表示方式,我们不能像整数一样总是声明相等性。 让我们使用assert_almost_equal函数检查它们是否相等:
-
使用较低精度调用函数(最多七位小数):
print "Decimal 6", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=7)注意
请注意,不会引发异常,如以下结果所示:
Decimal 6 None -
使用较高精度调用函数(最多八位小数):
print "Decimal 7", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=8)结果是:
Decimal 7 Traceback (most recent call last): … raise AssertionError(msg) AssertionError: Arrays are not almost equal ACTUAL: 0.123456789 DESIRED: 0.12345678
大约相等的数组
在本节中,我们将介绍另一个断言函数。 如果两个数字不等于一定数量的有效数字,则assert_approx_equal函数会引发异常。 函数结果是由以下条件触发的异常:
abs(actual - expected) >= 10**-(significant - 1)
让我们从上一教程中获得数字,然后让assert_approx_equal函数对其起作用:
-
使用低重要性调用函数:
print "Significance 8", np.testing.assert_approx_ equal(0.123456789, 0.123456780, significant=8)结果是:
Significance 8 None -
使用高重要性调用函数:
print "Significance 9", np.testing.assert_approx_equal(0.123456789, 0.123456780, significant=9)引发异常:
Significance 9 Traceback (most recent call last): ... raise AssertionError(msg) AssertionError: Items are not equal to 9 significant digits: ACTUAL: 0.123456789 DESIRED: 0.12345678
assert_array_almost_equal函数
有时我们需要检查两个数组是否几乎相等。 如果两个数组的指定精度不相等,assert_array_almost_equal函数将引发异常。 该函数检查两个数组的形状是否相同。 然后,将数组的值按元素进行如下比较:
|expected - actual| < 0.5 10-decimal
让我们通过向每个数组添加零来使用上一教程中的值形成数组:
-
以较低的精度调用该函数:
print "Decimal 8", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=8)结果是:
Decimal 8 None -
以较高的精度调用该函数:
print "Decimal 9", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=9)引发异常:
Decimal 9 Traceback (most recent call last): … assert_array_compare raise AssertionError(msg) AssertionError: Arrays are not almost equal (mismatch 50.0%) x: array([ 0\. , 0.12345679]) y: array([ 0\. , 0.12345678])
使用 IPython 分析程序
正如我们大多数人在编程课上所学的那样,过早的优化是万恶之源。 但是,一旦进入了软件开发的最后阶段,很可能是代码的某些部分不必要地变慢了,或者使用了比严格需要的更多的内存。 我们可以通过分析过程找到这些问题。 分析涉及度量指标,例如一段代码(如函数或一条语句)的执行时间。
IPython 是交互式 Python 环境,还带有与标准 Python shell 相似的 shell。 在 IPython 中,我们可以使用timeit来分析小的代码片段。 我们还可以分析更大的脚本。 我们将展示两种方法。
-
计时一段代码:
在
pylab模式下启动 IPythonipython -pylab -
创建一个包含 1,000 个介于 0 到 1,000 之间的整数值的数组。
In [1]: a = arange(1000)现在是时候搜索数组中所有内容 42 的答案了。
In [2]: %timeit searchsorted(a, 42) 100000 loops, best of 3: 7.58 us per loop -
分析脚本:
我们将分析这个小脚本,该脚本会反转包含随机值的大小可变的矩阵:
import numpy def invert(n): a = numpy.matrix(numpy.random.rand(n, n)) return a.I sizes = 2 ** numpy.arange(0, 12)对于
n个大小:invert(n)我们可以按以下方式计时:
In [1]: %run -t invert_matrix.py IPython CPU timings (estimated): User : 6.08 s. System : 0.52 s. Wall time: 19.26 s.然后,我们可以使用
p选项来分析脚本。In [2]: %run -p invert_matrix.py 852 function calls in 6.597 CPU seconds Ordered by: internal time ncalls tottime percall cumtime percall filename:lineno(function) 12 3.228 0.269 3.228 0.269 {numpy.linalg.lapack_lite.dgesv} 24 2.967 0.124 2.967 0.124 {numpy.core.multiarray._fastCopyAndTranspose} 12 0.156 0.013 0.156 0.013 {method 'rand' of 'mtrand.RandomState' objects} 12 0.087 0.007 0.087 0.007 {method 'copy' of 'numpy.ndarray' objects} 12 0.069 0.006 0.069 0.006 {method 'astype' of 'numpy.ndarray' objects} 12 0.025 0.002 6.304 0.525 linalg.py:404(inv) 12 0.024 0.002 6.328 0.527 defmatrix.py:808(getI) 1 0.017 0.017 6.596 6.596 invert_matrix.py:1(<module>) 24 0.014 0.001 0.014 0.001 {numpy.core.multiarray.zeros} 12 0.009 0.001 6.580 0.548 invert_matrix.py:3(invert) 12 0.000 0.000 6.264 0.522 linalg.py:244(solve) 12 0.000 0.000 0.014 0.001 numeric.py:1875(identity) 1 0.000 0.000 6.597 6.597 {execfile} 36 0.000 0.000 0.000 0.000 defmatrix.py:279(__array_finalize__) 12 0.000 0.000 2.967 0.247 linalg.py:139(_fastCopyAndTranspose) 24 0.000 0.000 0.087 0.004 defmatrix.py:233(__new__) 12 0.000 0.000 0.000 0.000 linalg.py:99(_commonType) 24 0.000 0.000 0.000 0.000 {method '__array_prepare__' of 'numpy.ndarray' objects} 36 0.000 0.000 0.000 0.000 linalg.py:66(_makearray) 36 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array} 12 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects} 12 0.000 0.000 0.000 0.000 linalg.py:127(_to_native_byte_order) 1 0.000 0.000 6.597 6.597 interactiveshell.py:2270(safe_execfile)列标题的解释与标准 Python 分析器的解释相同:
标头 描述 ncalls这是调用数量。 tottime这是在给定函数上花费的总时间(不包括在调用子函数上花费的时间)。 percall这是 tottime除以ncalls的商。cumtime这是此函数和所有子函数(从调用到退出)花费的总时间。 即使对于递归函数,此数字也是准确的。 percall(第二个)这是 cumtime除以原始调用的商。
使用 IPython 进行调试
调试是的其中一项,我们通过适当的单元测试来避免这些调试。 调试可能需要很长时间,而且很可能您没有时间。 因此,重要的是要系统地了解您的工具。 找到问题并实现修复后,应该进行单元测试。 这样,至少您不必再次经历调试的折磨。
我们将调试一些错误的代码,这些代码试图越界访问数组元素:
import numpy
a = numpy.arange(7)
print a[8]
继续执行以下步骤:
-
在 IPython 中运行错误的脚本。
启动
ipythonShell。 发出以下命令,在 IPython 中运行错误的脚本:In [1]: %run buggy.py --------------------------------------------------------------------------- IndexError Traceback (most recent call last) .../site-packages/IPython/utils/py3compat.pyc in execfile(fname, *where) 173 else: 174 filename = fname --> 175 __builtin__.execfile(filename, *where) .../buggy.py in <module>() 2 3 a = numpy.arange(7) ----> 4 print a[8] IndexError: index out of bounds -
启动调试器。
现在我们的程序崩溃了,我们可以启动调试器了。 这将在发生错误的行上设置一个断点:
In [2]: %debug > .../buggy.py(4)<module>() 2 3 a = numpy.arange(7) ----> 4 print a[8] -
列出代码。
我们可以使用
list命令列出代码或使用缩写l。ipdb> list 1 import numpy 2 3 a = numpy.arange(7) ----> 4 print a[8] -
在当前行求值代码。
现在,我们可以在当前行求值任意代码。
ipdb> len(a) 7 ipdb> print a [0 1 2 3 4 5 6] -
查看调用栈。
我们可以使用
bt命令查看调用栈:ipdb> bt .../py3compat.py(175)execfile() 171 if isinstance(fname, unicode): 172 filename = fname.encode(sys.getfilesystemencoding()) 173 else: 174 filename = fname --> 175 __builtin__.execfile(filename, *where) > .../buggy.py(4)<module>() 0 print a[8]向上移动调用栈:
ipdb> u > .../site-packages/IPython/utils/py3compat.py(175)execfile() 173 else: 174 filename = fname --> 175 __builtin__.execfile(filename, *where)下移调用栈:
ipdb> d > .../buggy.py(4)<module>() 2 3 a = numpy.arange(7) ----> 4 print a[8]
执行单元测试
单元测试是自动化测试,用于测试一小段代码,通常是一个函数或方法。 Python 具有用于单元测试的 PyUnit API 。 作为 NumPy 的用户,我们可以使用之前在操作中看到的断言函数。
我们将为一个简单的阶乘函数编写测试。 测试将检查所谓的“快乐路径”(正常情况,并且预计将始终通过)和异常情况:
-
我们首先编写阶乘函数:
def factorial(n): if n == 0: return 1 if n < 0: raise ValueError, "Unexpected negative value" return np.arange(1, n+1).cumprod()该代码使用了我们已经看到的
arange和cumprod函数来创建数组和计算累积乘积,但是我们对边界条件进行了一些检查。 -
现在我们将编写单元测试。 让我们写一个包含单元测试的类。 它从
unittest模块扩展了TestCase类,这是标准 Python 的一部分。 我们测试使用以下命令调用阶乘函数:-
正数,正确的方式
-
边界条件为零
-
负数,应导致错误
class FactorialTest(unittest.TestCase): def test_factorial(self): #Test for the factorial of 3 that should pass. self.assertEqual(6, factorial(3)[-1]) np.testing.assert_equal(np.array([1, 2, 6]), factorial(3)) def test_zero(self): #Test for the factorial of 0 that should pass. self.assertEqual(1, factorial(0)) def test_negative(self): #Test for the factorial of negative numbers that should fail. # It should throw a ValueError, but we expect IndexError self.assertRaises(IndexError, factorial(-10))正如您在以下输出中看到的那样,我们将其中一项测试失败:
$ python unit_test.py .E. ====================================================================== ERROR: test_negative (__main__.FactorialTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "unit_test.py", line 26, in test_negative self.assertRaises(IndexError, factorial(-10)) File "unit_test.py", line 9, in factorial raise ValueError, "Unexpected negative value" ValueError: Unexpected negative value ---------------------------------------------------------------------- Ran 3 tests in 0.003s FAILED (errors=1)我们为
factorial函数代码做了一些快乐的路径测试。 我们让边界条件测试故意失败(请参见unit_test.py),如下所示:import numpy as np import unittest def factorial(n): if n == 0: return 1 if n < 0: raise ValueError, "Unexpected negative value" return np.arange(1, n+1).cumprod() class FactorialTest(unittest.TestCase): def test_factorial(self): #Test for the factorial of 3 that should pass. self.assertEqual(6, factorial(3)[-1]) np.testing.assert_equal(np.array([1, 2, 6]), factorial(3)) def test_zero(self): #Test for the factorial of 0 that should pass. self.assertEqual(1, factorial(0)) def test_negative(self): #Test for the factorial of negative numbers that should fail. # It should throw a ValueError, but we expect IndexError self.assertRaises(IndexError, factorial(-10)) if __name__ == '__main__': unittest.main()
-
nose测试装饰器
nose是一个 Python 框架,它使(单元)测试更加容易。 鼻子可以帮助您组织测试。 根据nose文档:
任何与testMatch正则表达式匹配的 python 源文件,目录或包(默认情况下:(?:^|[b_.-])[Tt]est))都将作为测试被收集。
鼻子广泛使用装饰器。 Python 装饰器是指示有关方法或函数的注解。 numpy.testing模块具有许多装饰器:
| 装饰器 | 描述 |
|---|---|
numpy.testing.decorators.deprecated |
这是运行测试时过滤器的过时警告 |
numpy.testing.decorators.knownfailureif |
这会根据条件引发KnownFailureTest异常。 |
numpy.testing.decorators.setastest |
该将函数标记为测试或非测试。 |
numpy.testing.decorators.skipif |
这会根据条件引发SkipTest异常。 |
numpy.testing.decorators.slow |
这将测试函数或方法标记为缓慢。 |
此外,我们可以调用decorate_methods函数,以将修饰符应用于与正则表达式或字符串匹配的类的方法。
我们将直接将 setastest装饰器应用于测试函数。 然后,我们将相同的装饰器应用于禁用它的方法。 另外,我们将跳过其中一项测试,并通过另一项测试。 首先,如果您还没有安装 nose,请按以下步骤安装:
-
使用安装工具安装
nose,如下所示:easy_install nose或点子:
pip install nose -
直接应用装饰器,如下所示:
我们将一个函数作为测试,将另一个函数作为非测试:
@setastest(False) def test_false(): pass @setastest(True) def test_true(): pass -
跳过测试如下:
我们可以使用
skipif装饰器跳过测试。 让我们使用一个总是导致测试被跳过的条件:@skipif(True) def test_skip(): pass -
使用
knownfailureif装饰器的失败测试如下:添加一个始终通过的测试函数。 然后使用
knownfailureif装饰器对其进行装饰,以使测试始终失败:@knownfailureif(True) def test_alwaysfail(): pass -
定义测试类,如下所示:
我们将使用通常应由鼻子执行的方法来定义一些测试类:
class TestClass(): def test_true2(self): pass class TestClass2(): def test_false2(self): pass -
禁用测试方法如下:
让我们从上一步中禁用第二种测试方法:
decorate_methods(TestClass2, setastest(False), 'test_false2') -
运行测试,如下所示:
我们可以使用以下命令运行测试:
nosetests -v decorator_setastest.py decorator_setastest.TestClass.test_true2 ... ok decorator_setastest.test_true ... ok decorator_test.test_skip ... SKIP: Skipping test: test_skipTest skipped due to test condition decorator_test.test_alwaysfail ... ERROR ====================================================================== ERROR: decorator_test.test_alwaysfail ---------------------------------------------------------------------- Traceback (most recent call last): File "…/nose/case.py", line 197, in runTest self.test(*self.arg) File …/numpy/testing/decorators.py", line 213, in knownfailer raise KnownFailureTest(msg) KnownFailureTest: Test skipped due to known failure ---------------------------------------------------------------------- Ran 4 tests in 0.001s FAILED (SKIP=1, errors=1) -
我们将某些函数和方法修饰为未经测试,以便
nose忽略它们。 我们跳过了一项测试,也没有通过另一项测试。 我们通过直接应用装饰器并使用以下decorate_methods函数(请参见decorator_test.py)来做到这一点:from numpy.testing.decorators import setastest from numpy.testing.decorators import skipif from numpy.testing.decorators import knownfailureif from numpy.testing import decorate_methods @setastest(False) def test_false(): pass @setastest(True) def test_true(): pass @skipif(True) def test_skip(): pass @knownfailureif(True) def test_alwaysfail(): pass class TestClass(): def test_true2(self): pass class TestClass2(): def test_false2(self): pass decorate_methods(TestClass2, setastest(False), 'test_false2')
总结
在本章中,我们了解了测试和 NumPy 测试工具。 我们介绍了单元测试,断言函数,性能分析和调试。 单元测试是一种标准做法,因为它应该为您提供质量更好的代码,并且回归风险低。 NumPy 提供断言函数来帮助您进行单元测试。 在本章中,我们介绍了其中一些函数。 无论您的单元测试有多好,在某个时候,您都必须进行性能分析和调试,因此在这方面给出了指针。
下一章的主题是科学的 Python 生态系统以及 NumPy 如何融入其中。
七、Python 科学生态系统
SciPy 是在 NumPy 之上构建的。 它增加了功能,例如数值积分,优化,统计和特殊功能。 从历史上看,NumPy 是 SciPy 的一部分,但后来被分离以供其他 Python 库使用。 当这些结合在一起时,就定义了用于科学和数值分析的通用栈。 当然,栈本身并不是固定的。 但是,每个人都同意 NumPy 是一切的中心。 本章中的示例应使您对科学 Python 生态系统的功能有所了解。
在本章中,我们将介绍以下主题:
- 数值积分
- 插值
- 将 Cython 与 NumPy 结合使用
- 使用 scikit-learn 进行聚类
- 检测角点
- 比较 NumPy 与 Blaze
数值积分
数值积分是使用数值方法而不是分析方法的积分。 SciPy 具有数值集成包scipy.integrate,在 NumPy 中没有等效的包。 quad函数可以在两个点之间集成一个变量函数。 这些点可以是无穷大。
注意
quad函数在引擎盖下使用了久经考验的 QUADPACK Fortran 库。
高斯积分与error函数相关,但没有限制。 它求值为pi的平方根。 让我们用quad函数计算高斯积分,如以下代码行所示:
print "Gaussian integral", np.sqrt(np.pi),integrate.quad(lambda x: np.exp(-x**2), -np.inf, np.inf)
返回值是结果,其错误将是:
Gaussian integral 1.77245385091 (1.7724538509055159, 1.4202636780944923e-08)
插值
插值根据观察结果预测范围内的值。 例如,我们可以在两个变量x和y之间建立关系,并且有一组观察到的x-y对。 在这种情况下,我们可以尝试在给定x值范围内的情况下预测y值。 该范围将从已经观察到的最低x值开始,到已经观察到的最高x值结束。 scipy.interpolate函数根据实验数据对函数进行插值。 interp1d类可以创建线性或三次插值函数。 默认情况下,会构造线性插值函数,但是如果设置了kind参数,则会创建三次插值函数。 interp2d类的工作方式相同,但是是二维的。
我们将使用sinc函数创建数据点,然后向其中添加一些随机噪声。 之后,我们将进行线性和三次插值并绘制结果,如下所示:
-
创建数据点并添加噪声,如下所示:
x = np.linspace(-18, 18, 36) noise = 0.1 * np.random.random(len(x)) signal = np.sinc(x) + noise -
创建一个线性插值函数,然后将其应用于具有五倍数据点的输入数组:
interpolated = interpolate.interp1d(x, signal) x2 = np.linspace(-18, 18, 180) y = interpolated(x2) -
执行与上一步相同的操作,但使用三次插值:
cubic = interpolate.interp1d(x, signal, kind="cubic") y2 = cubic(x2) -
用 Matplotlib 绘制结果,如下所示:
plt.plot(x, signal, 'o', label="data") plt.plot(x2, y, '-', label="linear") plt.plot(x2, y2, '--', lw=2, label="cubic") plt.legend() plt.show()下图是数据,线性和三次插值的图形:
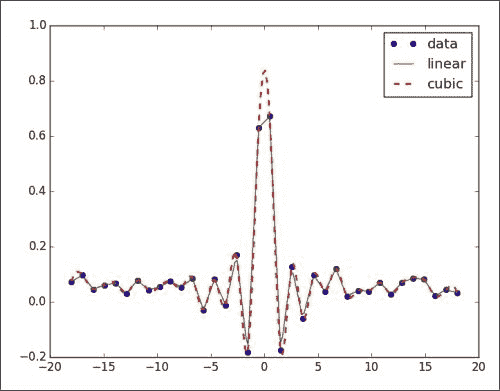
我们通过sinc函数创建了一个数据集,并添加了噪声。 然后,我们使用scipy.interpolate模块的interp1d类进行了线性和三次插值(请参见本书代码包包Chapter07文件夹中的sincinterp.py文件):
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
x = np.linspace(-18, 18, 36)
noise = 0.1 * np.random.random(len(x))
signal = np.sinc(x) + noise
interpolated = interpolate.interp1d(x, signal)
x2 = np.linspace(-18, 18, 180)
y = interpolated(x2)
cubic = interpolate.interp1d(x, signal, kind="cubic")
y2 = cubic(x2)
plt.plot(x, signal, 'o', label="data")
plt.plot(x2, y, '-', label="linear")
plt.plot(x2, y2, '--', lw=2, label="cubic")
plt.legend()
plt.show()
将 Cython 与 NumPy 结合使用
Cython 是一种相对较年轻的基于 Python 的编程语言。 不同之处在于,使用 Python,我们可以选择为代码中的变量声明静态类型。 Cython 是一种生成 CPython 扩展模块的编译语言。 除了提供性能增强外,Cython 的主要用途是将现有的 C/C++ 软件与 Python 接口。
我们可以像整合 Cython 和 Python 代码一样,整合 Cython 和 NumPy 代码。 让我们看一个示例,该示例分析股票的上涨天数(接近前一天)的比率。 我们将对二项式比例置信度应用公式。 这表明该比率有多重要。
-
编写
.pyx文件。.pyx文件包含 Cython 代码。 基本上,Cython 代码是标准 Python 代码,并为变量添加了可选的静态类型声明。 让我们编写一个.pyx文件,其中包含一个函数,该函数计算上升天数的比率及其相关的置信度。 首先,该函数计算价格之间的差异。 然后,我们计算正差的数量,从而得出上升天数的比率。 最后,我们在引言中的维基百科页面上应用公式来增强置信度,如下所示。import numpy def pos_confidence(numbers): diffs = numpy.diff(numbers) n = float(len(diffs)) p = len(diffs[diffs > 0])/n confidence = numpy.sqrt(p * (1 - p)/ n) return (p, confidence) -
编写
setup.py文件。我们将使用以下
setup.py文件:from distutils.core import setup from distutils.extension import Extension from Cython.Distutils import build_ext ext_modules = [Extension("binomial_proportion", ["binomial_proportion.pyx"])] setup( name = 'Binomial proportion app', cmdclass = {'build_ext': build_ext}, ext_modules = ext_modules ) -
现在,使用 Cython 模块。
我们可以使用以下命令进行构建:
python setup.py build_ext --inplace构建完成后,我们可以通过导入使用上一步中的 Cython 模块。 我们将编写一个 Python 程序,使用 Matplotlib 下载股价数据。 然后,我们将置信函数应用于收盘价。
from matplotlib.finance import quotes_historical_yahoo from datetime import date import numpy import sys from binomial_proportion import pos_confidence #1\. Get close prices. today = date.today() start = (today.year - 1, today.month, today.day) quotes = quotes_historical_yahoo(sys.argv[1], start, today) close = numpy.array([q[4] for q in quotes]) print pos_confidence(close)AAPL程序的输出如下:(0.56746031746031744, 0.031209043355655924)
使用 scikit-learn 聚类股票
Scikit-learn 是用于机器学习的开源软件。 聚类是类型的机器学习算法,旨在基于相似度对项目进行分组。
注意
存在大量的锡克奇人。 这些都是开源的科学 Python 项目。 有关 scikits 的列表,请参考这里。
群集是不受监督的,这意味着您不必创建学习示例。 该算法根据某种距离度量将项目放入适当的存储桶中,以便彼此靠近的项目最终位于同一存储桶中。 在此示例中,我们将使用道琼斯工业(DJI)指数中的股票对数收益。
注意
存在无数的聚类算法,并且由于这是一个快速发展的领域,因此每年都会发明新的算法。 由于本书的紧急性,我们无法一一列举。 有兴趣的读者可以看看这里。
首先,我们将从 Yahoo 财经下载这些股票的 EOD 价格数据。 其次,我们将计算平方亲和矩阵。 最后,我们将股票分类为AffinityPropagation。 与其他聚类算法相比,亲和力传播不需要聚类数作为参数。 该算法依赖于所谓的亲和力矩阵。 这是一个包含数据点亲和力的矩阵,可以将其解释为距离。
-
我们将使用 DJI 指数的股票代码下载 2013 年的价格数据。 在此示例中,我们仅对收盘价感兴趣。 代码如下:
# 2012 to 2013 start = datetime.datetime(2012, 01, 01) end = datetime.datetime(2013, 01, 01) #Dow Jones symbols symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"] for symbol in symbols: try : quotes.append(finance.quotes_historical_yahoo_ochl(symbol, start, end, asobject=True)) except urllib2.HTTPError: print symbol, "not found" close = np.array([q.close for q in quotes]).astype(np.float) -
使用对数收益率作为指标来计算不同股票之间的相似性。 代码如下:
logreturns = np.diff(np.log(close)) print logreturns.shape logreturns_norms = np.sum(logreturns ** 2, axis=1) S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T) -
给
AffinityPropagation类上一步的结果。 此类使用适当的群集编号标记数据点或本例中的库存。 代码如下:aff_pro = sklearn.cluster.AffinityPropagation().fit(S) labels = aff_pro.labels_ for i in xrange(len(labels)): print '%s in Cluster %d' % (symbols[i], labels[i])
以下是完整的群集程序:
import datetime
import numpy as np
import sklearn.cluster
from matplotlib import finance
import urllib2
##1\. Download price data
## 2012 to 2013
start = datetime.datetime(2012, 01, 01)
end = datetime.datetime(2013, 01, 01)
##Dow Jones symbols
symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"]
quotes = []
对于符号内的符号,代码如下:
try :
quotes.append(finance.quotes_historical_yahoo_ochl(symbol, start, end, asobject=True))
except urllib2.HTTPError:
print symbol, "not found"
close = np.array([q.close for q in quotes]).astype(np.float)
print close.shape
##2\. Calculate affinity matrix
logreturns = np.diff(np.log(close))
print logreturns.shape
logreturns_norms = np.sum(logreturns ** 2, axis=1)
S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T)
##3\. Cluster using affinity propagation
aff_pro = sklearn.cluster.AffinityPropagation().fit(S)
labels = aff_pro.labels_
for i in xrange(len(labels)):
print '%s in Cluster %d' % (symbols[i], labels[i])
每个股票的集群编号输出如下:
AA in Cluster 2
AXP in Cluster 0
BA in Cluster 0
BAC in Cluster 1
CAT in Cluster 2
CSCO in Cluster 3
CVX in Cluster 8
DD in Cluster 0
DIS in Cluster 6
GE in Cluster 8
HD in Cluster 0
HPQ in Cluster 4
IBM in Cluster 0
INTC in Cluster 0
JNJ in Cluster 6
JPM in Cluster 5
KO in Cluster 6
MCD in Cluster 6
MMM in Cluster 8
MRK in Cluster 6
MSFT in Cluster 0
PFE in Cluster 6
PG in Cluster 6
T in Cluster 6
TRV in Cluster 6
UTX in Cluster 0
VZ in Cluster 6
WMT in Cluster 7
XOM in Cluster 8
检测角点
角点检测是计算机视觉中的标准技术。 Scikits-image(专门用于图像处理的包)提供了 Harris 角点检测器,由于角点检测非常复杂,因此该函数非常好。 显然,我们可以从头开始做,但是这违反了不重新发明轮子的基本原则。 我们将从 scikits-learn 加载示例图像。 对于此示例,这不是绝对必要的。 您可以改用其他任何图像。
注意
有关转角检测的更多信息,请参考这里。
您可能需要在系统上安装 jpeglib 才能加载 scikits-learn 图像,该图像是 JPEG 文件。 如果您使用的是 Windows,请使用安装程序。 否则,下载发行版,解压缩,然后使用以下命令行从顶部文件夹中进行构建:
./configure
make
sudo make install
要检测图像的角,请执行以下步骤:
-
加载样例图像。
Scikits-learn 当前在数据集结构中具有两个样本 JPEG 图像。 我们将仅看第一张图像,如下所示:
dataset = load_sample_images() img = dataset.images[0] -
然后,通过调用
harris函数获取角点的坐标来检测角点:harris_coords = harris(img) print "Harris coords shape", harris_coords.shape y, x = np.transpose(harris_coords)角点检测的代码如下:
from sklearn.datasets import load_sample_images from matplotlib.pyplot import imshow, show, axis, plot import numpy as np from skimage.feature import harris dataset = load_sample_images() img = dataset.images[0] harris_coords = harris(img) print "Harris coords shape", harris_coords.shape y, x = np.transpose(harris_coords) axis('off') imshow(img) plot(x, y, 'ro') show()我们得到一个带有红点的图像,其中的角点检测如下:

比较 NumPy 与 Blaze
由于我们接近本书结尾,因此似乎很适合讨论 NumPy 的未来。 NumPy 的未来是 Blaze,这是新的开源 Python 数字库。 Blaze 应该比 NumPy 更好地处理大数据。 大数据可以通过多种方式定义。 在这里,我们将大数据定义为无法存储在内存中甚至无法在一台机器上的数据。 通常,数据分布在多个服务器之间。 Blaze 还应该能够处理从未存储的大量流数据。
注意
可以在这个页面中找到。
就像 NumPy 一样,Blaze 允许科学家,分析师和工程师快速编写高效的代码。 但是,Blaze 更进一步,它还负责与分配计算以及从各种数据源类型提取和转换数据有关的工作。
Blaze 围绕一般的多维数组和表抽象。 Blaze 中的类表示现实世界中发现的不同数据类型和数据结构。 Blaze 具有通用的计算引擎,可以处理分布在多个服务器上的数据,并将指令发送到专用的低级内核。
Blaze 扩展了 NumPy,以提供自定义数据类型和异构形状。 当然,这允许更大的灵活性和易用性。
Blaze 是围绕数组设计的。 就像 NumPy ndarray一样,Blaze 提供带有额外计算信息的元数据。 元数据定义数据的存储方式(异构),并以多维数组的形式进行索引。 可以在各种硬件上执行计算,包括 CPU 和 GPU 的异构集群。
Blaze 有志成为多个节点集群和分布式计算的 NumPy。 就像 NumPy 一样,其主要思想是着眼于数组和数组操作,同时将凌乱的细节抽象化。
注意
Blaze 具有特殊的 LLVM 编译器。 有关 LLVM 编译器的更多信息,请参见这里。 简而言之,LLVM 是一个开源编译器技术项目。
可以使用 Blaze 数据适配器在不同格式之间转换数据。 Blaze 还管理计算的调度,该调度可以是自动的,也可以由用户配置的,可以延迟计算表达式。
总结
在本章中,我们仅介绍了科学 Python 生态系统的可能性。 我们使用了一些库,即使不是通用栈的一部分,也至少是基础库。 我们使用了 SciPy 提供的插值和数值积分。 演示了 scikit-learn 中数十种算法中的两种。 我们还看到了 Cython 的实际应用,从技术上讲,它是一种编程语言。 最后,我们看了 Blaze,这是一个应该推广和扩展 NumPy 原理的库。 鉴于大数据和云计算等最新发展。 Blaze 和相关项目仍处于孵化阶段,但我们可以期望在不久的将来生产稳定的软件。 您可以参考其中一些项目。
不幸的是,我们到了本书的结尾。 由于本书的格式(即页数),您应该掌握 NumPy 的基本知识,并且可能会需要更多。 但是,请不要担心这还不够。 您可以期待同一作者的《学习 Python 数据分析》,该书将于 2015 年初发布。
标签:函数,NumPy,py,手册,test,数组,np,numpy,0.000 From: https://www.cnblogs.com/apachecn/p/17314350.html