# PhysDiff: Physics-Guided Human Motion Diffusion Model #paper
1. paper-info
1.1 Metadata
- Author:: [[Ye Yuan]], [[Jiaming Song]], [[Umar Iqbal]], [[Arash Vahdat]], [[Jan Kautz]]
- 作者机构::
- Keywords:: #HM , #Diffusion
- Journal::
- Date:: [[2022-12-05]]
- 状态:: #Done
1.2. Abstract
Denoising diffusion models hold great promise for generating diverse and realistic human motions. However, existing motion diffusion models largely disregard the laws of physics in the diffusion process and often generate physically-implausible motions with pronounced artifacts such as floating, foot sliding, and ground penetration. This seriously impacts the quality of generated motions and limits their real-world application. To address this issue, we present a novel physics-guided motion diffusion model (PhysDiff), which incorporates physical constraints into the diffusion process. Specifically, we propose a physics-based motion projection module that uses motion imitation in a physics simulator to project the denoised motion of a diffusion step to a physically-plausible motion. The projected motion is further used in the next diffusion step to guide the denoising diffusion process. Intuitively, the use of physics in our model iteratively pulls the motion toward a physically-plausible space. Experiments on large-scale human motion datasets show that our approach achieves state-of-the-art motion quality and improves physical plausibility drastically (>78% for all datasets).
2. Introduction
Denoising diffusion models 在最近的生成领域大火,扩散模型对复杂模型有着很好的建模能力,已经在图片生成领域取得了巨大成功。已经有工作将扩散模型用于在Deep learning-based human motion generation领域中。
但是,这些人体动作生成扩散模型有一个缺陷:the underlying law of physics, 如Fig1
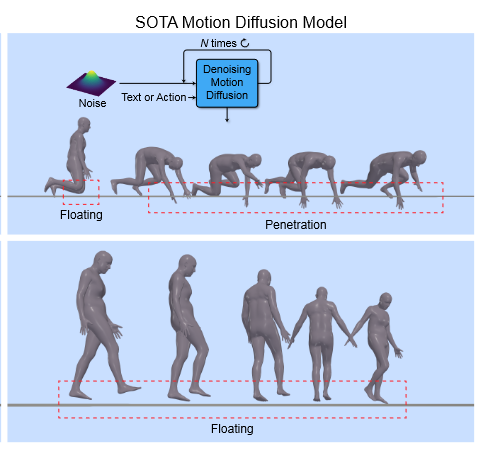
Fig.扩散模型中已存的问题
针对该问题,该作者在论文中提出了一种物理投影方法,该方法在于纠正生成的不合理的动作,于此也可以推理出,该投影方案作用于逆扩散过程的后半段,因为在逆扩散过程的前半程阶段,生成的动作还包含很多噪声,很难纠正。
3. Method

Fig.2 模型结构
Fig2为该网络模型结构,当不看红框内的内容时,该模型为普通的条件扩散模型(classifie-free),在特定的时间步上,会对扩散采样生成的动作进行Physics-Based Motion Projection。该投影过程只发生在逆扩散过程,整体算法流程的伪代码如Fig3
需要特别注意两个问题:
- 如何进行物理约束投影?
- 在逆扩散过程的那个时间点进行投影?

Fig.3 PhysDiff sampling algorithm for motion
3.1 Physics-Based Motion Projection
该投影方案通过强化学习实现,将人体动作\(\hat{x}^{1:H}\)中每一帧看做一个单独的状态,Markov decision process定义为\(M = (S, A, \tau, R, \gamma)\)
\(s^{h}\in S\): 状态,由当前动作的一些物理状态构成(关节角度、速度、位置等)
\(\pi(a^h|s^h)\): motion imitation policy,给定\(s\)的情况下选择一个action \(a^{h}\in A\)
\(\tau(s^{h+1} | s^{h}, a^h)\): 根据\(s^{h}, a^{h}\)生成下一个状态
通过执行\(\pi\) \(H\)次,就能够获得经过物理约束投影的动作\(\hat{x}^{1:H}\)
Rewards

Fig.4 reward 计算方式
其中\(w_{p}, w_{v}, w_{j}, w_{q} ,\alpha_{p}, \alpha_{v},\alpha_{j},\alpha_{q}\)为系数,\(r_p^h\)用于衡量局部关节角度,\(r_v^h\)用于衡量关节速度,\(r_j^h\)用于衡量关节点的3D位置坐标,\(r_q^h\)用于衡量全局关节角度。
States
\(s^h\)由当前动作的一些物理状态构成,并且包含下一时刻的pose \(\tilde{x}^{h+1}\) , 且包含a character attribute vector \(\varphi\)
Actions
作者使用比例微分 (PD) 控制器的目标关节角度作为动作表示。作者还在动作空间中添加残余力以稳定角色并补偿任何动态不匹配。
3.2 投影步数,投影时机,
在逆扩散步长的50-0之间进行投影,Fig5给出了步数对精度的影响。在早期步骤中执行基于物理的投影可以将生成的运动推离数据分布,从而阻碍扩散过程。
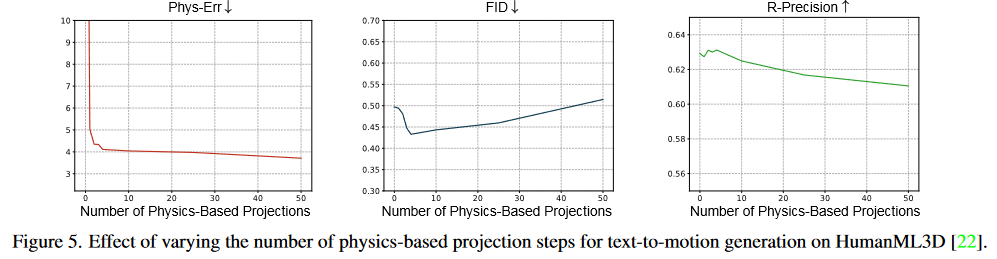
Fig.5 投影数
作者对何时使用投影也进行了实验,最后发现在逆扩散的(0,1,2,3)进行投影效果比较好。
4. 总结
在其他扩散模型中发现问题,(生成的动作存在物理差异),想到对生成的样本进行校正,在没有对逆扩散过程不做出改变的情况下,利用强化学习学习了一种物理约束投影方案。
但该方案并没有解决扩散模型内在的问题,而是利用了另一个模型第结果进行修改。
标签:Diffusion,diffusion,Guided,投影,motion,2022,扩散,physics,模型 From: https://www.cnblogs.com/guixu/p/17249280.html