上一篇关于Prometheus的文章中说到了Prometheus是如何实现进程监控。在实际的线上环境中,当系统进程出现异常后需要实时通知到值班运维人员,去检查系统是否还正常运转。下面我们就介绍下基于Prometheus如何实现监控报警通知。
Prometheus的报警通知,是利用其组件AlertManager,Alertmanager接收Prometheus等客户端发来的警报,之后通过分组,删除重复等处理,并将它们通过路由发送给正确的接收器。告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Wechat, Email, Webhook等告警方式, 其中Webhook可以接入钉钉等聊天工具。
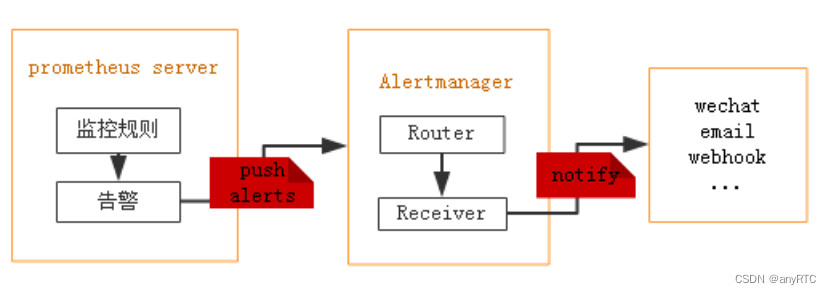
报警流程
- Prometheus配置监控规则
- 监控对象触发阈值
- 阈值超出持续时间
- 推送告警到Alertmanager
- Alertmanager处理告警信息
1)分组(group):类似告警合并为一个通知。
2)静默(silences):不通知,系统升级时使用。
3)抑制(inhibition): 只通知一次,相同内容不再通知。 - Alertmanager发送通知到媒体,邮箱,钉钉,企业微信等接收到通知
安装部署AlertManager
部署alertermanager
下载二进制文件
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
tar zxvf alertmanager-0.24.0.linux-amd64.tar.gz
mv alertmanager-0.24.0.linux-amd64 /apps/alertmanager
创建alertermanager服务
vim /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
[Service]
User=root
Type=simple
#不能有单引号和双引号
ExecStart=/home/prometheus/alertmanager/alertmanager/alertmanager --config.file=/home/prometheus/alertmanager/alertmanager/alertmanager.yml --storage.path=/home/prometheus/alertmanager/alertmanager/data --web.listen-address=:19093 --cluster.listen-address=0.0.0.0:19094 --web.external-url=http://192.168.1.108:19093
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动服务:
systemctl daemon-reload
systemctl enable --now alertmanager
systemctl status alertmanager
访问 192.168.1.108:19093 为alertmanager管理页面:
Alertmanager配置
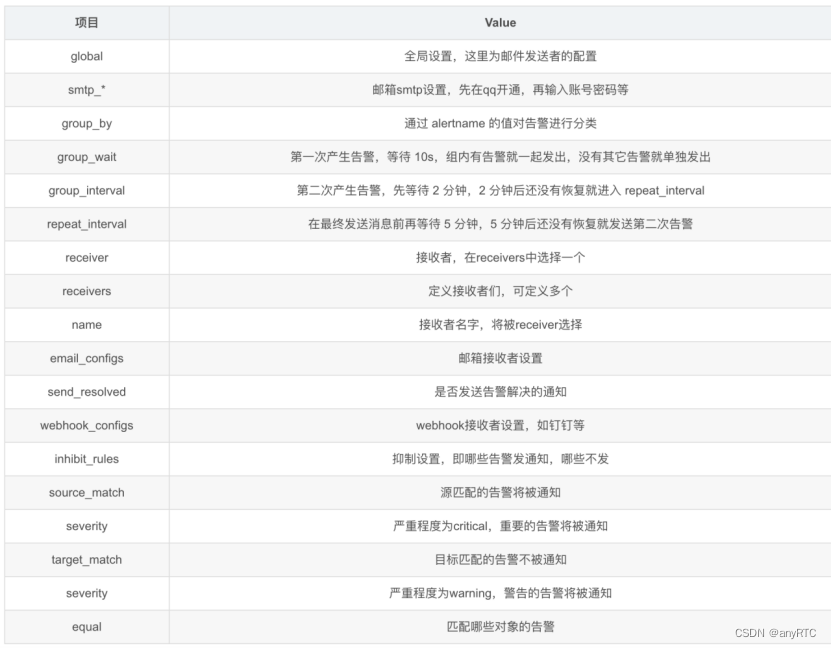
配置文件详解,以邮箱告警为例:
vim /home/prometheus/alertmanager/alertmanager/alertmanager.yml
#邮件发送者
global:
resolve_timeout: 30s
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '809xxx59@qq.com'
smtp_auth_username: '80xxx4859@qq.com'
smtp_auth_password: 'xxxxxxxxvpobcee'
smtp_hello: '@qq.com'
smtp_require_tls: false
templates:
- '/home/prometheus/alertmanager/alertmanager/tmpl/email.tmpl' #增加templates配置
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 5m
receiver: 'email'
routes:
- receiver: dingtalk-webhook
group_wait: 10s
- receiver: email
group_wait: 10s
receivers:
- name: 'email'
email_configs:
- to: 'niuming@dync.cc'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
项目 Value
Prometheus规则
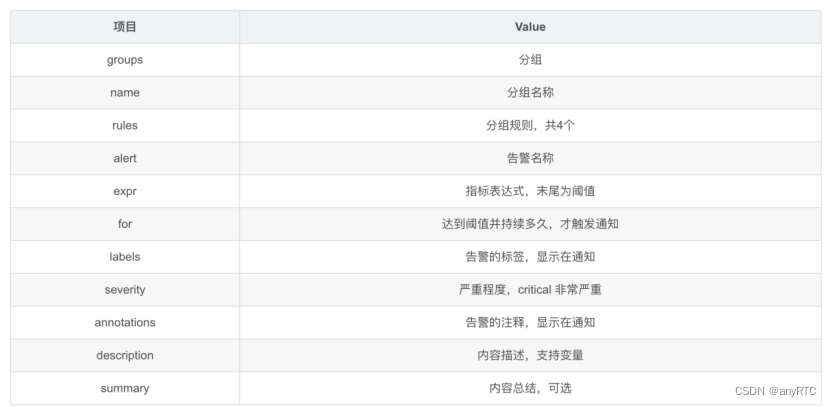
新建规则文件,配置分组信息,告警阈值和时间,告警标签和注释等。
指标表达式采用PromQL语句,多数指标单位为bytes字节,需要转换成KMG,例如2M=210241024。
Prometheus规则文件,对于邮箱,钉钉或企业微信,该文件通用:
vim /home/prometheus/prometheus/rule/qtalk_auth.yaml
groups:
- name: qtalk_auth 程异常退出
rules:
- alert: 应用进程 qtalk_auth 异常退出 # 告警名称
expr: (namedprocess_namegroup_num_procs{groupname="map[:qtalk_auth]"}) == 0
for: 30s # 满足告警条件持续时间多久后,才会发送告警
labels: #标签项
severity: error
ip: 192.168.1.108
annotations: # 解析项,详细解释告警信息
summary: "进程异常报警 Alert {{ $labels.instance }} ,异常停止超过30秒."
description: "{{$labels.ip}} 进程{{$labels.groupname}} 异常停止!请立即查看!"
检验prometheus报警规则文件,显示SUCCESS:
/home/prometheus/prometheus/promtool check rules rule/qtalk_auth.yml
Checking rule/qtalk_auth.yml
SUCCESS: 1 rules found
Prometheus配置
配置Prometheus文件,alertmanagers服务器的IP和端口,prometheus服务器规则文件的路径:
vim /home/Prometheus/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.108:19093"]
#- alertmanager:["192.168.1.108:19093"]
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rule/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: 'process'
static_configs:
- targets: ['192.168.1.108:9256']
重启Prometheus服务:
systemctl restart prometheus.service
邮箱告警
查看Prometheus
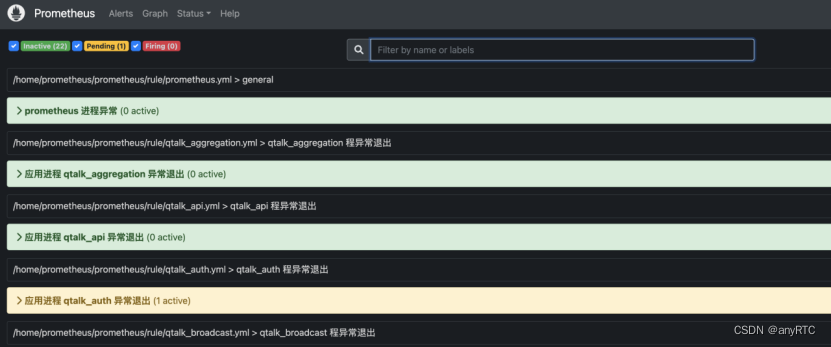
Prometheus首页,Alerts选项,可以查看告警信息:
报警状态分3种:
- inactive:没有异常。
- pending:已触发阈值,但未满足告警持续时间(即 rule 中的 for 字段)。
- firing:已触发阈值且满足条件并发送至 alertmanager。
pending状态,阈值触发了,但再观察30m秒(for: 30s)。

firing状态,30秒过后还超出阈值,则发送至alertmanager。
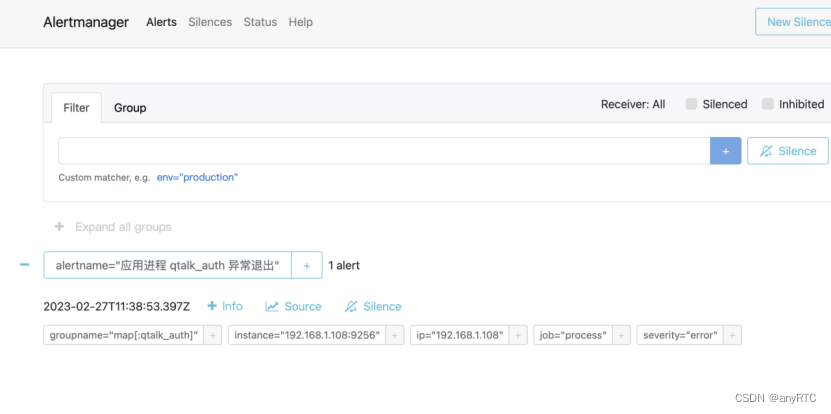
查看Alertmanager
只有在Prometheus中Firing的警告才会传到Alertmanager,进入首页查看。
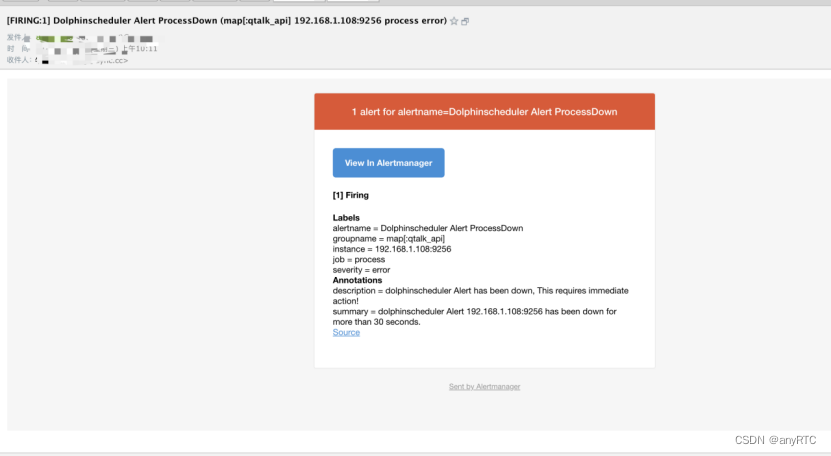
查看邮箱
Prometheus发送告警给alertmanager后,alertmanager根据通知设置,将报警消息通过邮箱发送:
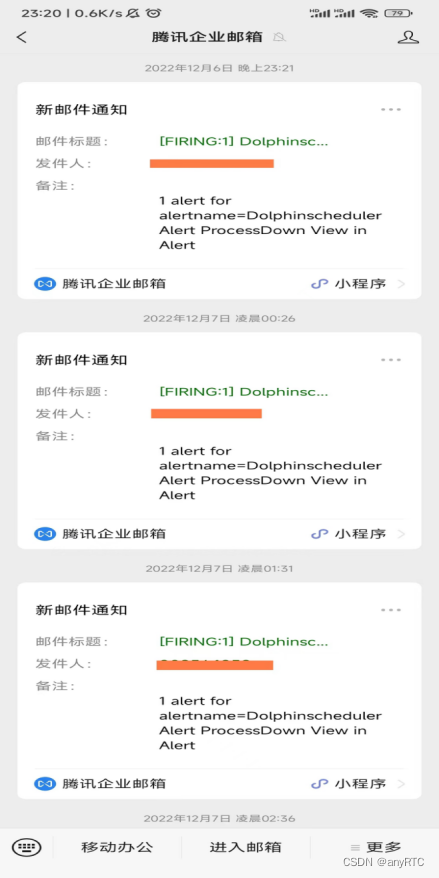
发邮件时,都是根据配置规则中时间间隔进行的邮件推送。(可在配置文件修改)
至此,一个简单的基于Prometheus的系统监控及报警通知的服务都搭建完成,利用这样一套监控通知体系,可以让系统运维人员早早的知道系统健康度,保证系统高可用。
参考文档
prometheus 发送恢复 值_Prometheus-基础系列-(五)-报警体系-2
