Prometheus配置Alertmanager(钉钉告警)
简介
- Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,例如邮件、微信、钉钉、Slack 等常用沟通工具,而且很容易做到告警信息进行去重,降噪,分组等,是一款很好用的告警通知系统。
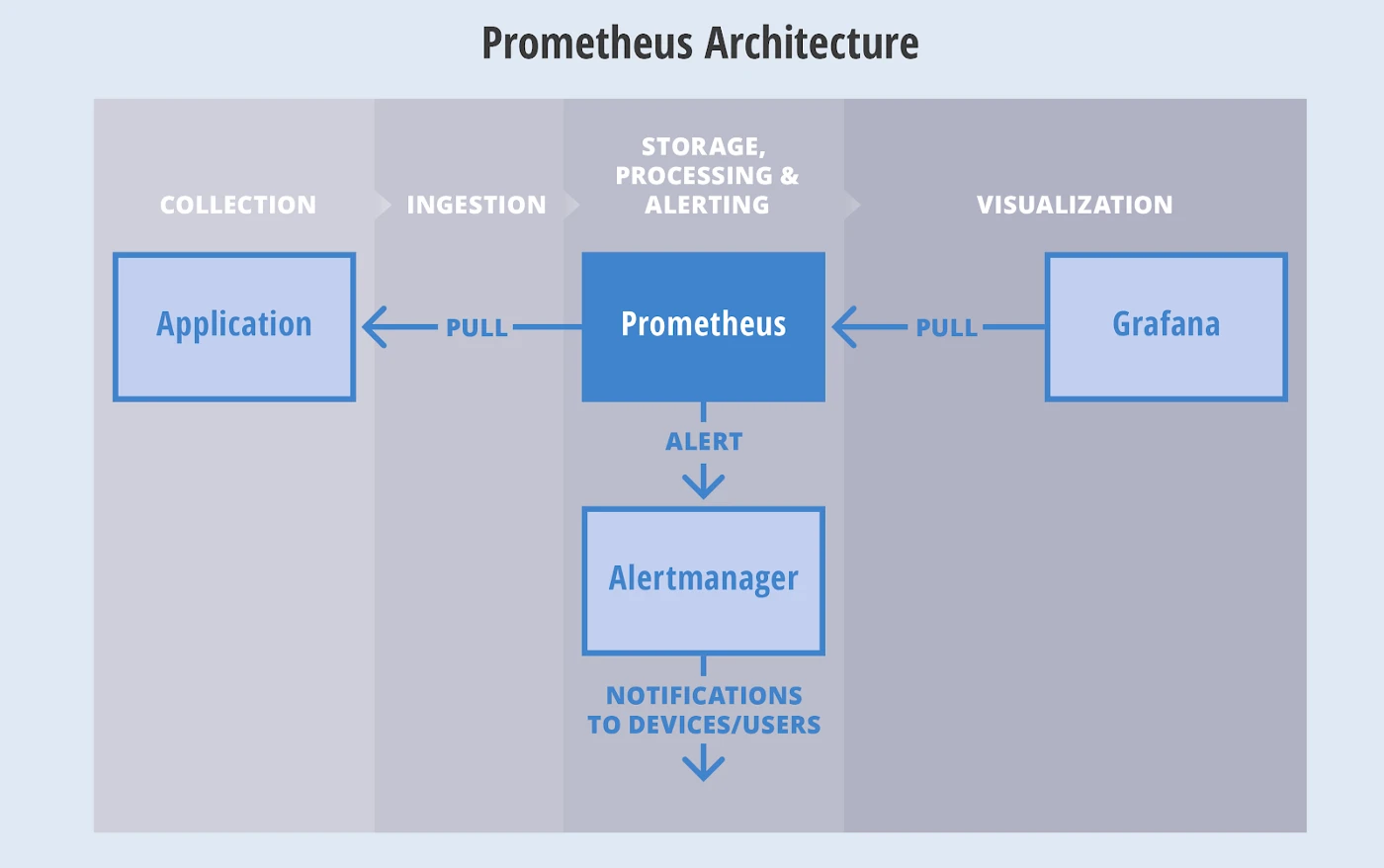
- 下图是Alertmanager与Prometheus的基本架构
一,二进制部署 Alertmanager
本文选择的安装版本为0.24.0
- 根据服务器情况选择安装目录,上传安装包。
cd /prometheus
#解压
tar -xvzf alertmanager-0.24.0.linux-amd64.tar.gz
mv alertmanager-0.24.0.linux-amd64 alertmanager
cd alertmanager

- 进行系统service编写
创建alertmanager.service配置文件
cd /usr/lib/systemd/system
vim alertmanager.service
alertmanager.service文件填入如下内容后保存:wq
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/prometheus/alertmanager/alertmanager --config.file=/prometheus/alertmanager/alertmanager.yml --storage.path=/prometheus/alertmanager/data/
[Install]
WantedBy=multi-user.target
- 查看配置文件
cat alertmanager.service

- 刷新服务配置并启动服务
systemctl daemon-reload
systemctl start alertmanager.service
- 查看服务运行状态
systemctl status alertmanager.service

- 设置开机自启动
systemctl enable alertmanager.service

访问系统
- 访问系统 http://服务器ip:9093,注意防火墙或安全组开放端口
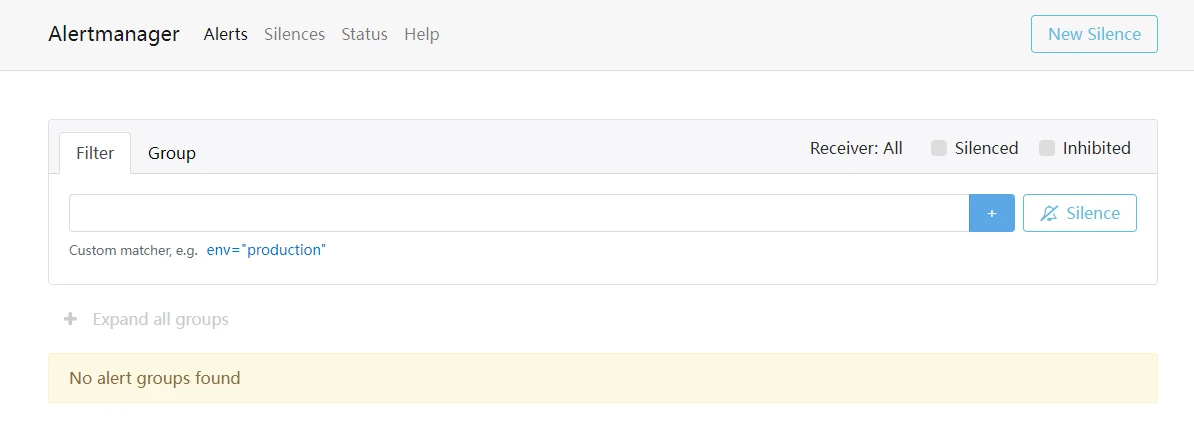
- 若看到如上界面则说明alertmanager部署成功
二,配置钉钉机器人
-
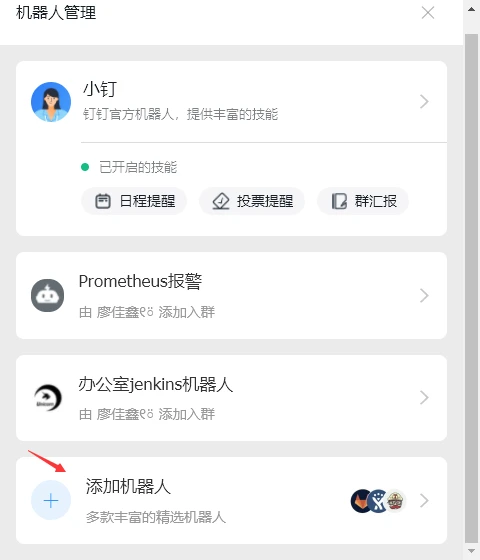
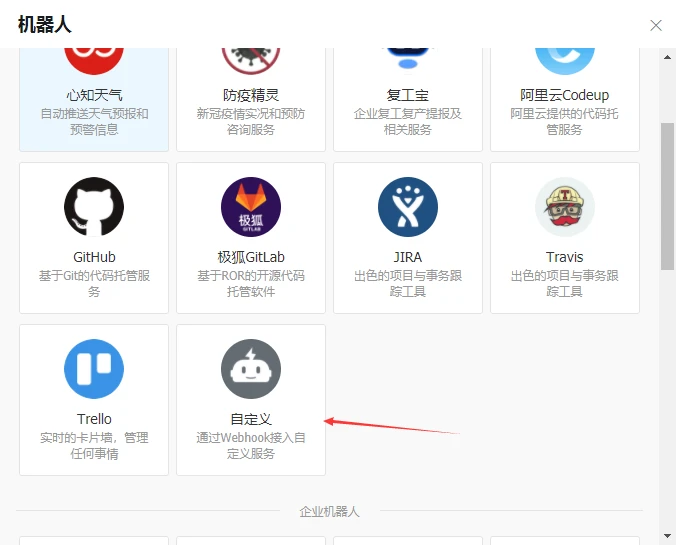
打开钉钉的智能群助手,点击添加机器人
-
选择自定义机器人
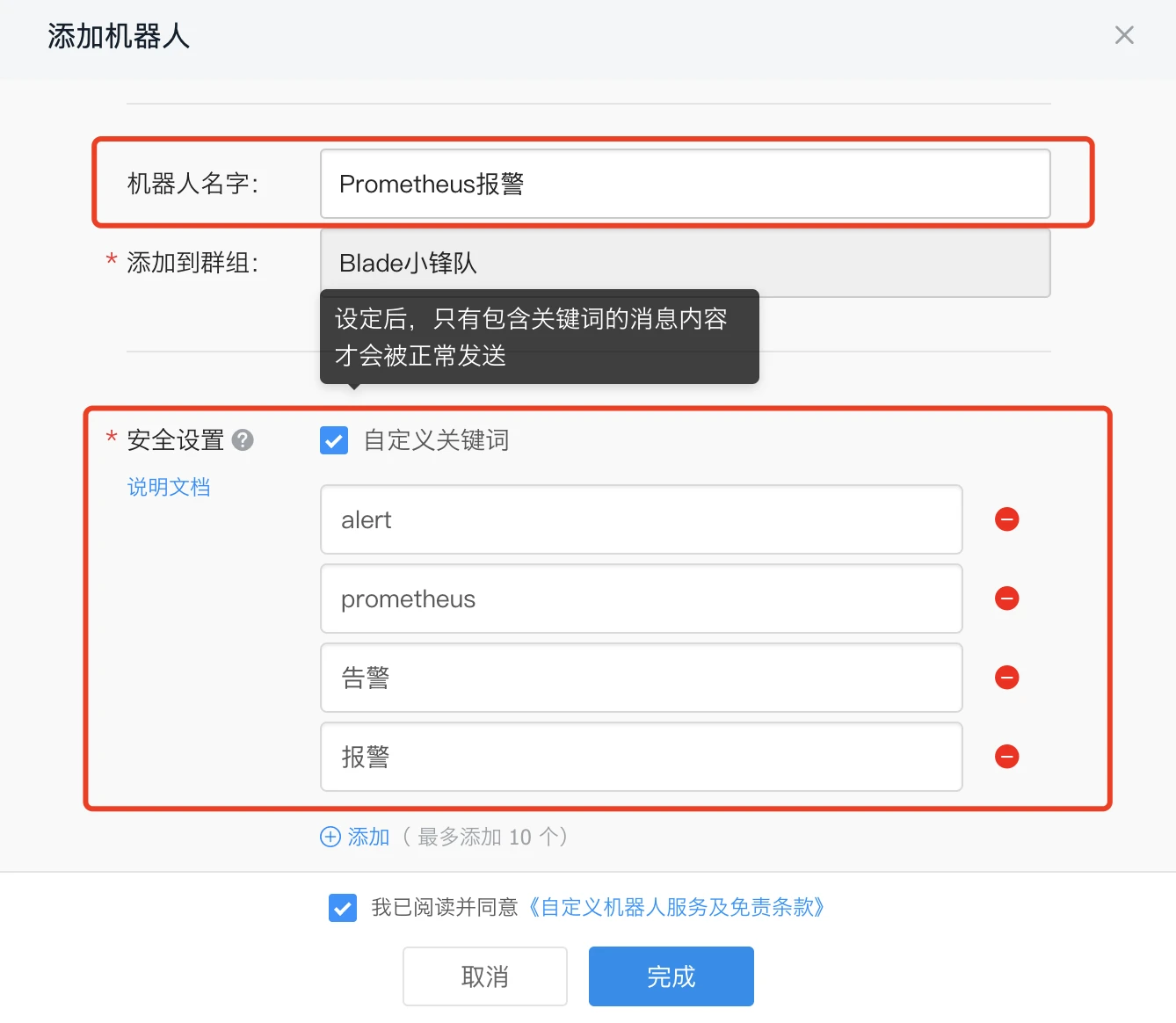
-
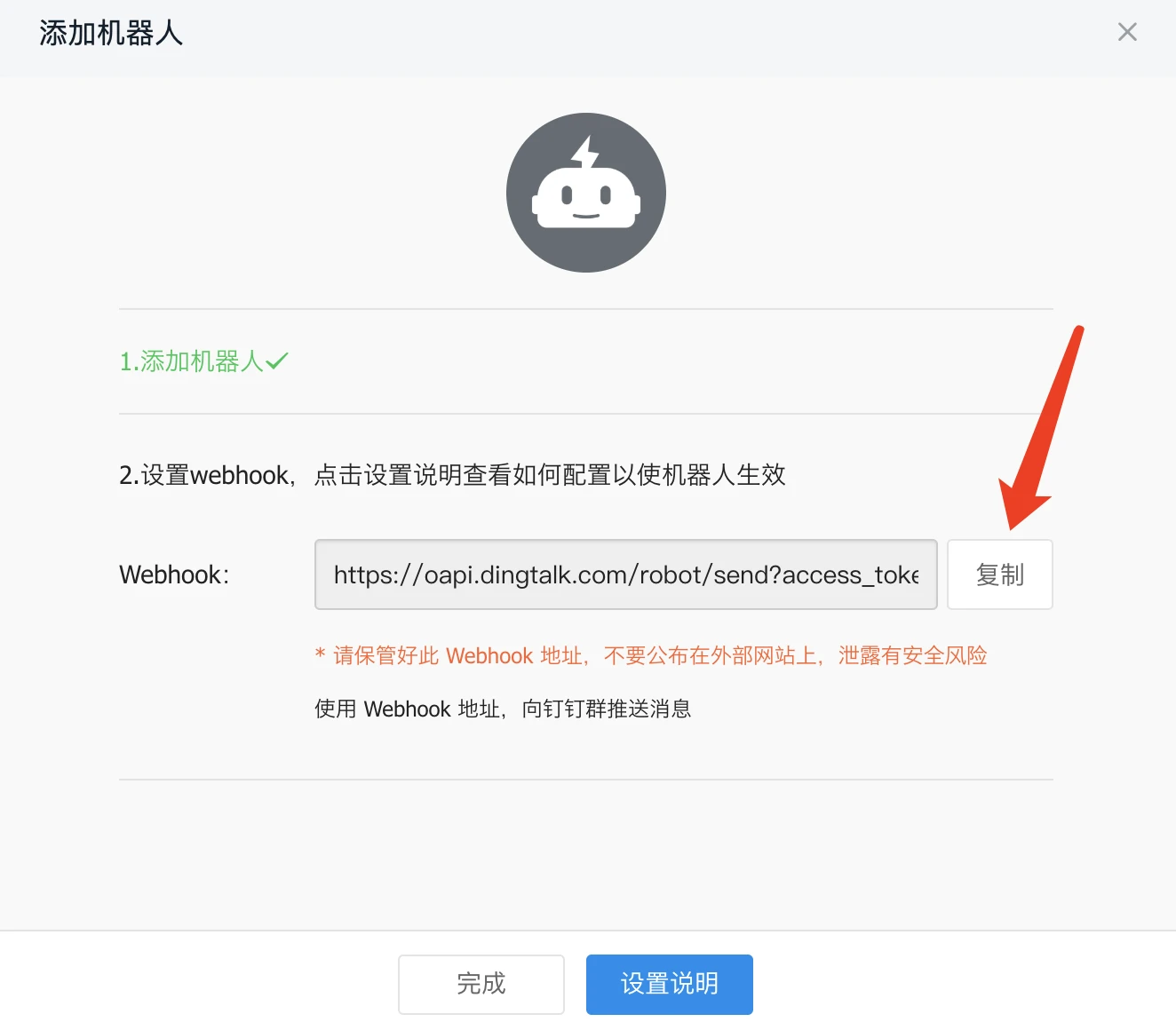
复制webhook地址后点击保存
三,安装钉钉服务(不推荐Docker安装,新版本的安装文档已经很久没更新)
1,二进制安装
- 下载地址:https://github.com/timonwong/prometheus-webhook-dingtalk/releases
- 本次安装版本为
2.1.0
- 根据服务器情况选择安装目录,上传安装包。
- 部署包下载完毕,开始安装
cd /prometheus
tar -xvzf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 webhook_dingtalk
cd webhook_dingtalk

- 编写配置文件(复制之后切记删除#的所有注释,否则启动服务时会报错),将上述获取的钉钉webhook地址填写到如下文件
vim dingtalk.yml
timeout: 5s
targets:
webhook_robot:
# 钉钉机器人创建后的webhook地址
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
webhook_mention_all:
# 钉钉机器人创建后的webhook地址
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# 提醒全员
mention:
all: true
- 进行系统service编写
创建webhook_dingtalk配置文件
cd /usr/lib/systemd/system
vim webhook_dingtalk.service
- webhook_dingtalk.service 文件填入如下内容后保存
:wq
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/prometheus/webhook_dingtalk/prometheus-webhook-dingtalk --config.file=/prometheus/webhook_dingtalk/dingtalk.yml --web.listen-address=:8060
[Install]
WantedBy=multi-user.target
- 查看配置文件
cat webhook_dingtalk.service

- 刷新服务配置并启动服务
systemctl daemon-reload
systemctl start webhook_dingtalk.service
- 查看服务运行状态
systemctl status webhook_dingtalk.service

- 设置开机自启动
systemctl enable webhook_dingtalk.service
- 我们记下
urls=http://localhost:8060/dingtalk/webhook_robot/send这一段值,接下来的配置会用上
配置Alertmanager
-
打开
/prometheus/alertmanager/alertmanager.yml,修改为如下内容global: # 在没有报警的情况下声明为已解决的时间 resolve_timeout: 5m route: # 接收到告警后到自定义分组 group_by: ["alertname"] # 分组创建后初始化等待时长 group_wait: 10s # 告警信息发送之前的等待时长 group_interval: 30s # 重复报警的间隔时长 repeat_interval: 5m # 默认消息接收 receiver: "dingtalk" receivers: # 钉钉 - name: 'dingtalk' webhook_configs: # prometheus-webhook-dingtalk服务的地址 - url: http://1xx.xx.xx.7:8060/dingtalk/webhook_robot/send send_resolved: true -
在prometheus安装文件夹根目录增加
alert_rules.yml配置文件,内容如下groups: - name: alert_rules rules: - alert: CpuUsageAlertWarning expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.60 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} CPU usage high" description: "{{ $labels.instance }} CPU usage above 60% (current value: {{ $value }})" - alert: CpuUsageAlertSerious #expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.85 expr: (100 - (avg by (instance) (irate(node_cpu_seconds_total{job=~".*",mode="idle"}[5m])) * 100)) > 85 for: 3m labels: level: serious annotations: summary: "Instance {{ $labels.instance }} CPU usage high" description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})" - alert: MemUsageAlertWarning expr: avg by(instance) ((1 - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes) * 100) > 70 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} MEM usage high" description: "{{$labels.instance}}: MEM usage is above 70% (current value is: {{ $value }})" - alert: MemUsageAlertSerious expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.90 for: 3m labels: level: serious annotations: summary: "Instance {{ $labels.instance }} MEM usage high" description: "{{ $labels.instance }} MEM usage above 90% (current value: {{ $value }})" - alert: DiskUsageAlertWarning expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 80 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Disk usage high" description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }})" - alert: DiskUsageAlertSerious expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 90 for: 3m labels: level: serious annotations: summary: "Instance {{ $labels.instance }} Disk usage high" description: "{{$labels.instance}}: Disk usage is above 90% (current value is: {{ $value }})" - alert: NodeFileDescriptorUsage expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 60 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} File Descriptor usage high" description: "{{$labels.instance}}: File Descriptor usage is above 60% (current value is: {{ $value }})" - alert: NodeLoad15 expr: avg by (instance) (node_load15{}) > 80 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Load15 usage high" description: "{{$labels.instance}}: Load15 is above 80 (current value is: {{ $value }})" - alert: NodeAgentStatus expr: avg by (instance) (up{}) == 0 for: 2m labels: level: warning annotations: summary: "{{$labels.instance}}: has been down" description: "{{$labels.instance}}: Node_Exporter Agent is down (current value is: {{ $value }})" - alert: NodeProcsBlocked expr: avg by (instance) (node_procs_blocked{}) > 10 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Process Blocked usage high" description: "{{$labels.instance}}: Node Blocked Procs detected! above 10 (current value is: {{ $value }})" - alert: NetworkTransmitRate #expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50 expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40 for: 1m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Network Transmit Rate usage high" description: "{{$labels.instance}}: Node Transmit Rate (Upload) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)" - alert: NetworkReceiveRate #expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50 expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40 for: 1m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Network Receive Rate usage high" description: "{{$labels.instance}}: Node Receive Rate (Download) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)" - alert: DiskReadRate expr: avg by (instance) (floor(irate(node_disk_read_bytes_total{}[2m]) / 1024 )) > 200 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Disk Read Rate usage high" description: "{{$labels.instance}}: Node Disk Read Rate is above 200KB/s (current value is: {{ $value }}KB/s)" - alert: DiskWriteRate expr: avg by (instance) (floor(irate(node_disk_written_bytes_total{}[2m]) / 1024 / 1024 )) > 20 for: 2m labels: level: warning annotations: summary: "Instance {{ $labels.instance }} Disk Write Rate usage high" description: "{{$labels.instance}}: Node Disk Write Rate is above 20MB/s (current value is: {{ $value }}MB/s)" -
修改
prometheys.yml,最上方三个节点改为如下配置global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: # alertmanager服务地址 - targets: ['11x.xx.x.7:9093'] rule_files: - "alert_rules.yml" -
执行
curl -XPOST localhost:9090/-/reload刷新prometheus配置 -
执行
systemctl restart alertmanger.service或docker restart alertmanager刷新alertmanger服务
验证配置
-
打开prometheus服务,可以看到alerts栏出现了很多规则
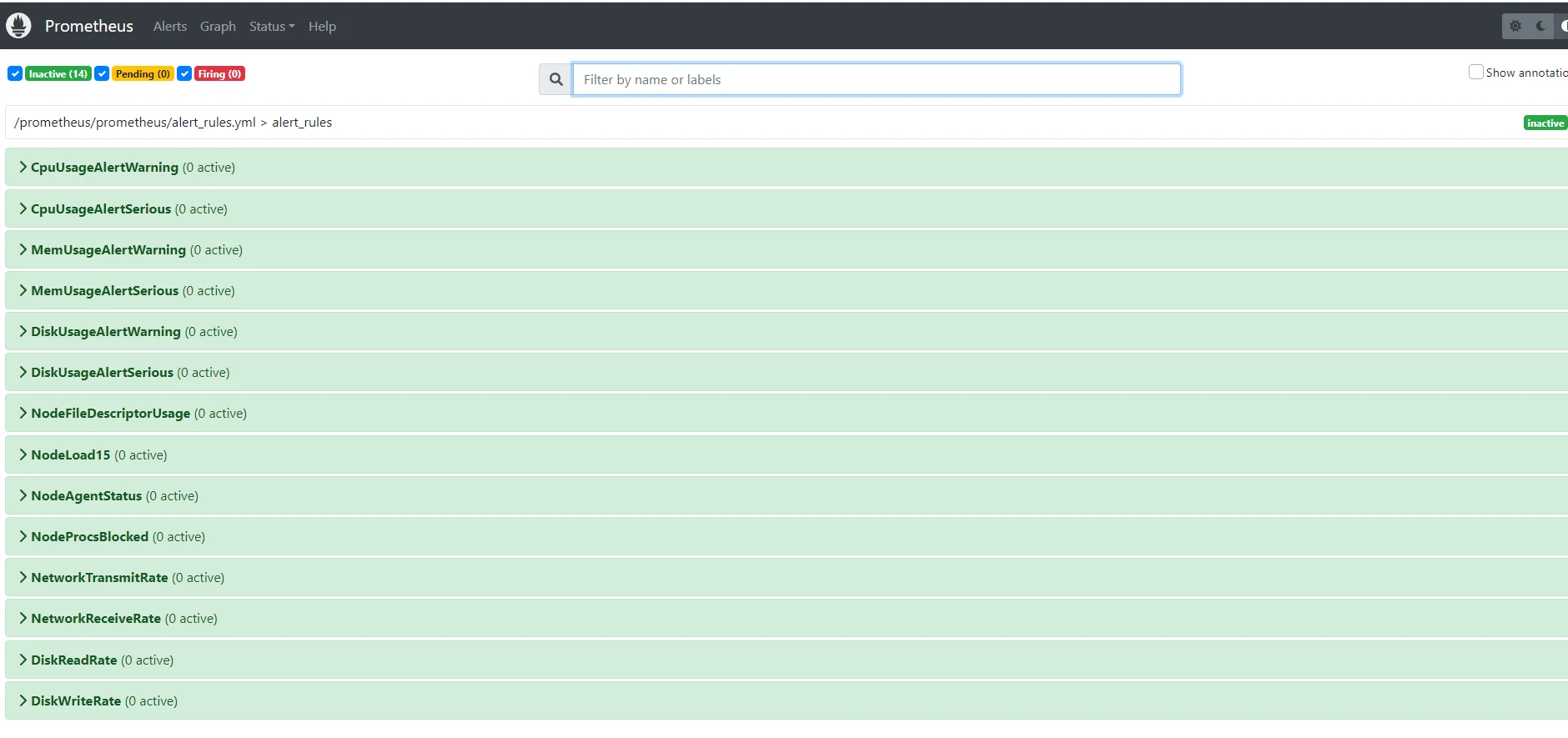
-
此时我们手动关闭一个节点
docker stop mysqld -
刷新prometheus,可以看到有一个节点颜色改变,进入了pending状态

-
稍等片刻,alertmanager.yml 配置为等待5m,颜色变为红色,进入了firing状态
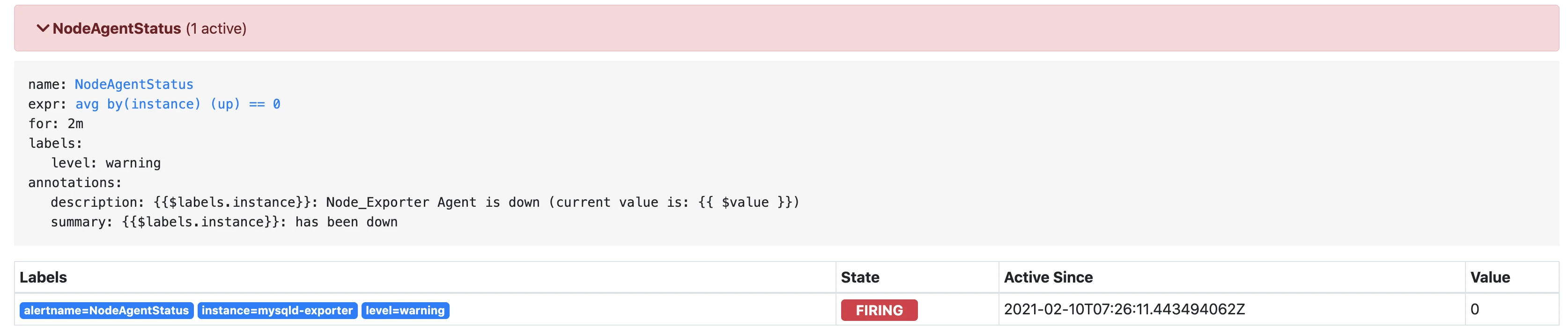
-
查看alertmanager服务,也出现了相关告警节点
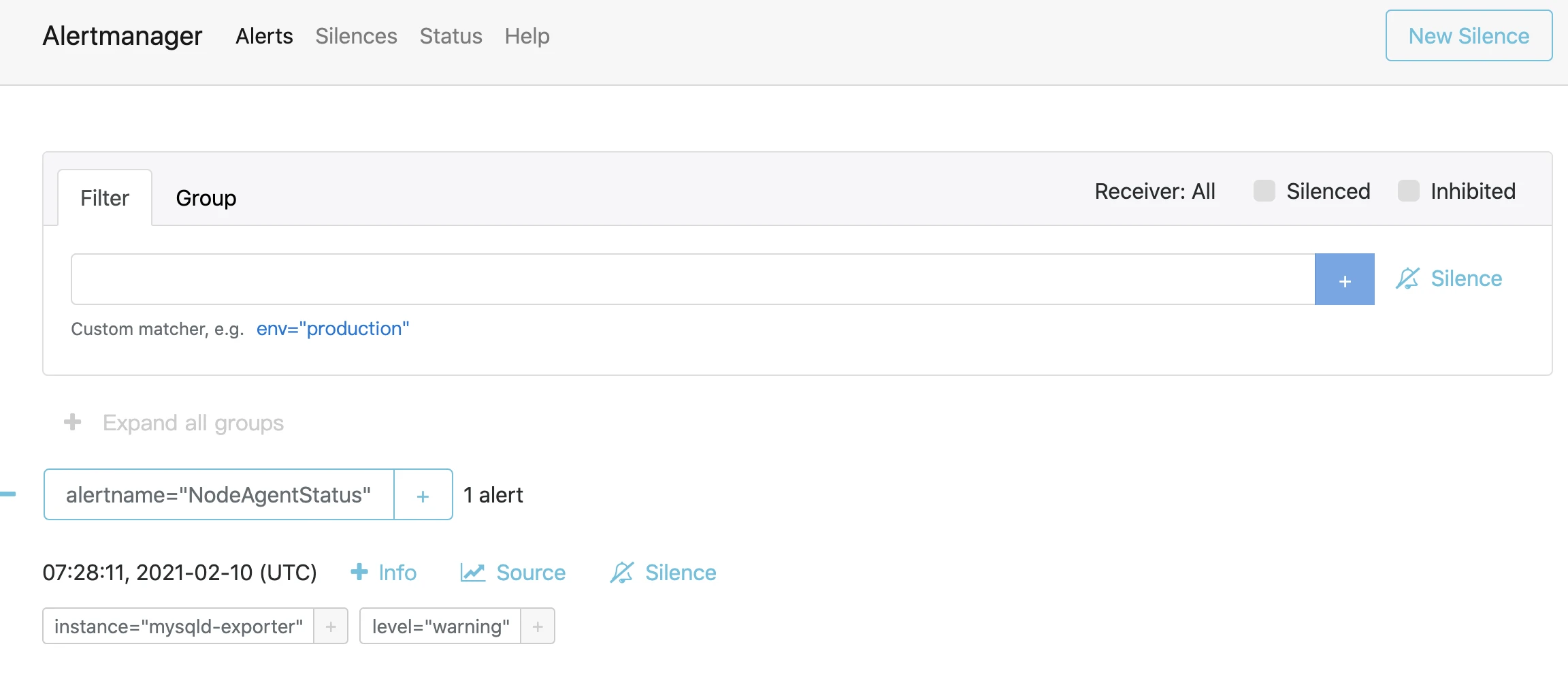
-
此时如果配置无误,会收到钉钉机器人的一条信息
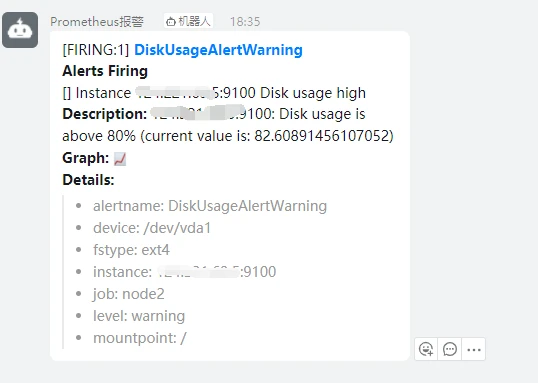
-
这时我们重启mysqld-exporter服务
docker start mysqld -
过了配置的等待时长,若服务没有在期间断开,钉钉机器人会发送一条恢复状态的信息