前言 目前,大多数现有的基于transformer的视觉模型只是借用了自然语言处理的思想,忽略了语言和图像之间的关键差异,特别是空间扁平像素特征的巨大序列长度。这阻碍了在像素特征和对象查询之间交叉注意的学习。
在本文中,作者重新思考像素和对象查询之间的关系,并提出将交叉注意学习重新定义为一个聚类过程。受传统k-means聚类算法的启发,开发了一种用于分割任务的k-means Mask Xformer (kMaX-DeepLab),它不仅改进了最先进的技术,而且具有简单优雅的设计。
kMaX-DeepLab在COCO val set和Cityscapes val set 上实现了新的SOTA的性能,无需测试时间增强或外部数据集。
QQ交流群: 444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
QQ交流群: 444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。

论文:https://arxiv.org/pdf/2207.04044.pdf
代码:https://github.com/google-research/deeplab2
创新思路
基于transformer的端到端框架已经成功地应用于多种计算机视觉任务,尤其是交叉注意模块的transformer解码器。然而,幕后的工作机制仍不清楚。交叉注意起源于自然语言处理社区,最初是为语言问题设计的,如神经机器翻译,其中输入序列和输出序列共享相似的短长度。
当涉及到某些视觉问题时,这种隐含的假设就会产生问题,即在对象查询和空间扁平像素特征之间执行交叉注意。具体来说,通常使用少量的对象查询(如128次查询),而输入图像可以包含数千个像素,用于检测和分割的视觉任务。
每次对象查询在交叉注意学习过程中都需要学习在丰富的像素中突出最具区别性的特征,这导致训练收敛缓慢,性能较差。
在这项工作中,作者观察到交叉注意方案实际上与传统的k-means聚类具有很强的相似性,将对象查询视为具有可学习嵌入向量的聚类中心。
因此,提出了新的k-means Mask Xformer (kMaX-DeepLab),它重新考虑像素特征和对象查询之间的关系,并从k-means聚类的角度重新设计交叉注意。
方法
基于掩码 transformer 的分割框架
transformer已经有效地部署到分割任务中。在不损失一般性的情况下,在下面的问题公式中考虑全视域分割,它可以很容易地推广到其他分割任务。全景分割的目的是将图像I分割为一组不重叠且有关联语义标签的掩码:
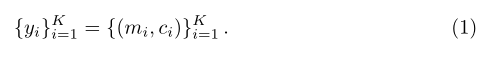
从DETR和MaX-DeepLab开始,全视域分割的方法转移到一个新的端到端范式,其中预测直接匹配ground truth的格式与N个掩码及其语义类:
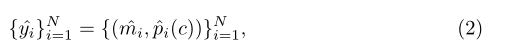
基于N个对象查询,预测N个掩码,通过一个transformer解码器从像素特征中聚合信息,由自我注意和交叉注意模块组成。通过多个transformer解码器更新的对象查询被用作掩码嵌入向量,该向量将与像素特征相乘,得到由N个掩码组成的最终预测Z:
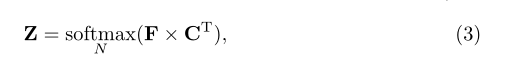
交叉注意与 k-means 聚类的关系
虽然基于transformer的分割框架成功地以端到端方式连接对象查询和掩码预测,但关键问题是如何将对象查询从可学习的嵌入转换为有意义的掩码嵌入向量。
Cross-attention
交叉注意模块用于聚合关联像素特征以更新对象查询。
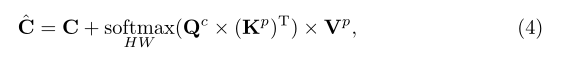
如式(4)所示,在更新对象查询时,对图像分辨率(HW)应用softmax函数,通常在数千像素范围内进行分割任务。
k - means 聚类
在式(4)中,交叉注意计算对象查询和像素之间的亲和力,沿着图像分辨率操作转换为注意图。然后使用注意图来检索关联的像素特征,以更新对象查询。整个过程实际上与经典的k-means聚类算法相似,其工作原理如下:
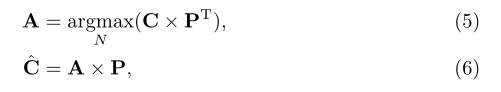
比较式(4)、式(5)和式(6),k-means聚类算法是无参数的,因此查询、键和值都不需要线性投影。集群中心上的更新不是以残留方式进行的。最重要的是,k-means在将亲和度转换为注意图(即检索和更新特征的权重)时,采用了一个集群级的argmax(即沿着集群维度操作的argmax),而不是空间级的softmax。
从聚类的角度来看,图像分割相当于将像素分组到不同的聚类中,其中每个聚类对应一个预测掩码。然而,交叉注意机制也试图将像素分组到不同的对象查询中,相反,它使用了不同于k-means中集群argmax的空间wise softmax操作。
鉴于k-means的成功,假设在像素聚类方面,聚类argmax比空间softmax更适合,因为聚类argmax执行硬分配,并有效地将操作目标从数千个像素减少到只有几个聚类中心,加快训练收敛,从而获得更好的性能。
k-means Mask Transformer
k - means cross-attention
提出的k-means交叉注意以类似于k-means聚类的方式重新定义交叉注意:
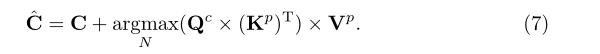
比较Eq.(4)和Eq.(7),空间上的softmax现在被集群上的argmax所取代。如图1所示,通过这种简单而有效的改变,可以将一个典型的transformer解码器转换为kMaX解码器。
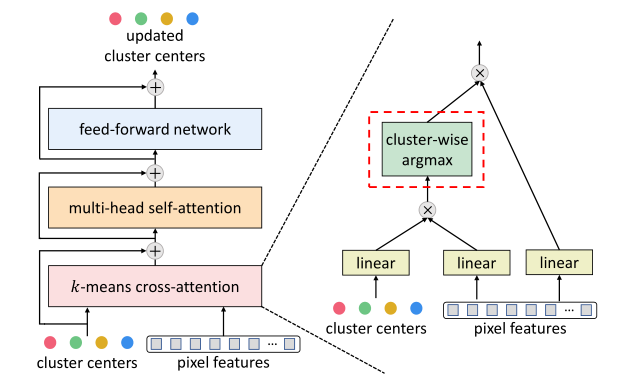
图1:将一个典型的transformer解码器转换为kMaX解码器
与原来的交叉注意不同,本文提出的k-means交叉注意采用了不同的操作(即按簇argmax)来计算注意图,并且不需要多头机制。然而,对于聚类而言,argmax是一种难以聚合像素特征以进行聚类中心更新的赋值方法,它不是一种可微操作,这给训练带来了挑战。
在Eq.(7)中,像素特征和簇中心之间的亲和对数直接对应于分割掩码的softmax对数,因为簇中心旨在将亲和相似的像素聚集在一起,形成预测的分割掩码。这个公式使每个kMaX解码器添加深度监督,以便训练k-means交叉注意模块中的参数。
Meta architecture
图2展示了kMaX- deeplab的元架构,它包含三个主要部分:像素编码器、增强像素解码器和kMaX解码器。像素编码器通过CNN或transformer主干提取像素特征,而增强像素解码器负责恢复特征图分辨率,并通过transformer编码器或轴向注意增强像素特征。
最后,kMaX解码器从k-means聚类的角度将对象查询(即簇中心)转换为掩码嵌入向量。
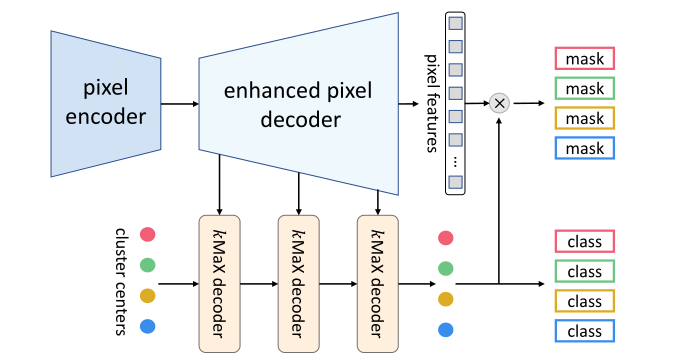
图2 :k-means Mask Transformer元架构
Model instantiation
基于MaX-DeepLab和官方代码库构建kMaX。将整个模型分为两条路径:像素路径和簇路径,分别负责提取像素特征和簇中心。图3详细描述了kMaX-DeepLab的实例化,其中有两个示例主干。
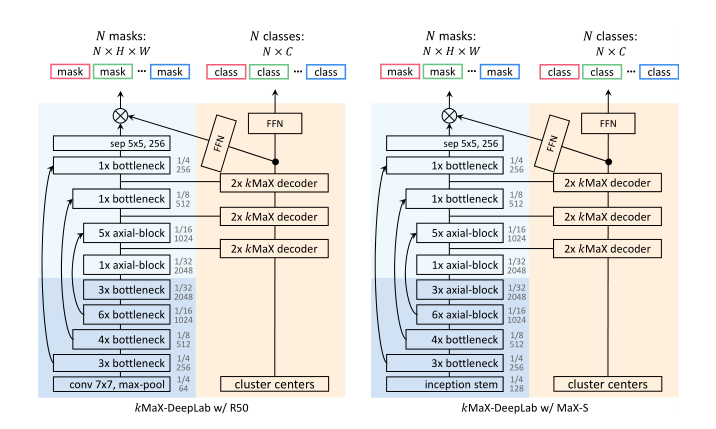
图3:以ResNet-50和MaX-S为骨干的kMaX-DeepLab示意图
Pixel path
Pixel path包括像素编码器和增强像素解码器。像素编码器是imagenet预训练的骨干,如ResNet, MaX-S(即具有轴向注意的ResNet-50)和ConvNeXt。增强像素解码器由几个axial attention块和bottleneck 块组成。
Cluster path
Cluster path共包含6个kMaX解码器,均匀分布在不同空间分辨率的特征图中。具体来说,分别对输出步长32、16和8处的像素特征部署了两个kMaX解码器。
Loss functions
训练损失函数大多遵循MaX-DeepLab。采用相同的PQ-style的损失、辅助语义损失、mask-id交叉熵损失和像素实例识别损失。
实验
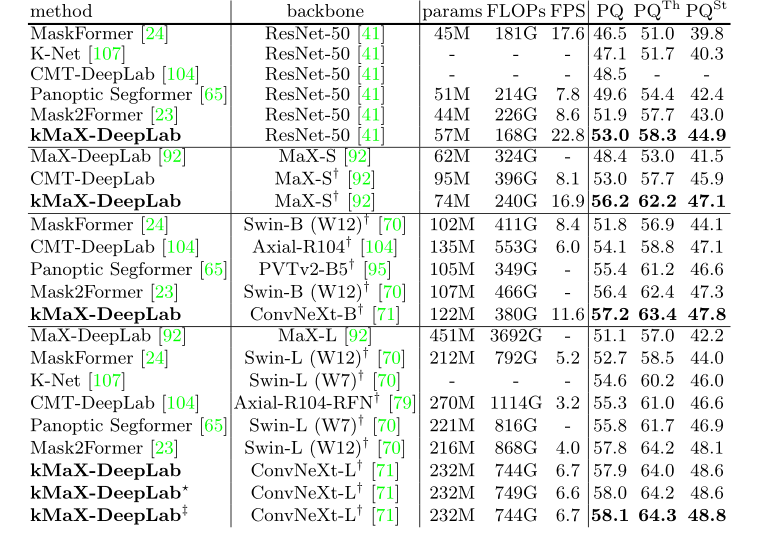
表1:COCO val set results

图4:kMaX- deeplab像素簇分配在每个kMaX解码器阶段的可视化,以及最终的全光预测。
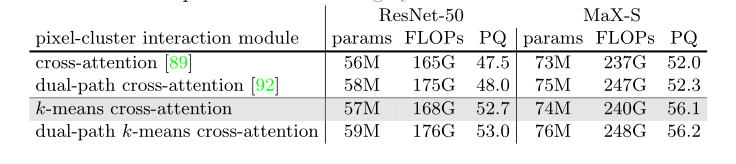
表3:不同方法对像素-簇交互的消融实验

表4:kMaX解码器数量的消融实验
结论
在本文中,提出了一个新的端到端框架,称为k-means Mask Transformer (kMaX-DeepLab),用于分割任务。
kMaX-DeepLab从聚类的角度重新思考像素特征和对象查询之间的关系。因此,它简化了掩码transformer模型,用提出的单头k-means聚类代替了多头交叉注意。
通过建立传统k-means聚类算法和交叉注意之间的联系,为分割任务定制了基于transformer的模型。
搞了个QQ交流群,打算往5000人的规模扩展,还专门找了大佬维护群内交流氛围,大家有啥问题可以直接问,主要用于算法、技术、学习、工作、求职等方面的交流,征稿、公众号或星球招聘、一些福利也会优先往群里发。感兴趣的请搜索群号:444129970
加微信群加知识星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
其它文章
ECCV 2022 | MorphMLP:一种有效的用于视频建模的MLP类架构
CVPR 2022 | BatchFormerV2:新的即插即用的用于学习样本关系的模块
CVPR 2022|RINet:弱监督旋转不变的航空目标检测网络
ECCV 2022 | FPN:You Should Look at All Objects
ECCV 2022 | ScalableViT:重新思考视觉Transformer面向上下文的泛化
ECCV 2022 | RFLA:基于高斯感受野的微小目标检测标签分配
迁移科技-工业机器人3D视觉方向2023校招-C++、算法、方案等岗位
文末赠书 |【经验】深度学习中从基础综述、论文笔记到工程经验、训练技巧
ECCV 2022 | 通往数据高效的Transformer目标检测器
ECCV 2022 Oral | 基于配准的少样本异常检测框架
CVPR 2022 | 网络中批处理归一化估计偏移的深入研究
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
标签:Transformer,解码器,means,Mask,像素,kMaX,聚类,掩码 From: https://www.cnblogs.com/wxkang/p/16653608.html