【CVPR2022】LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
1、研究动机
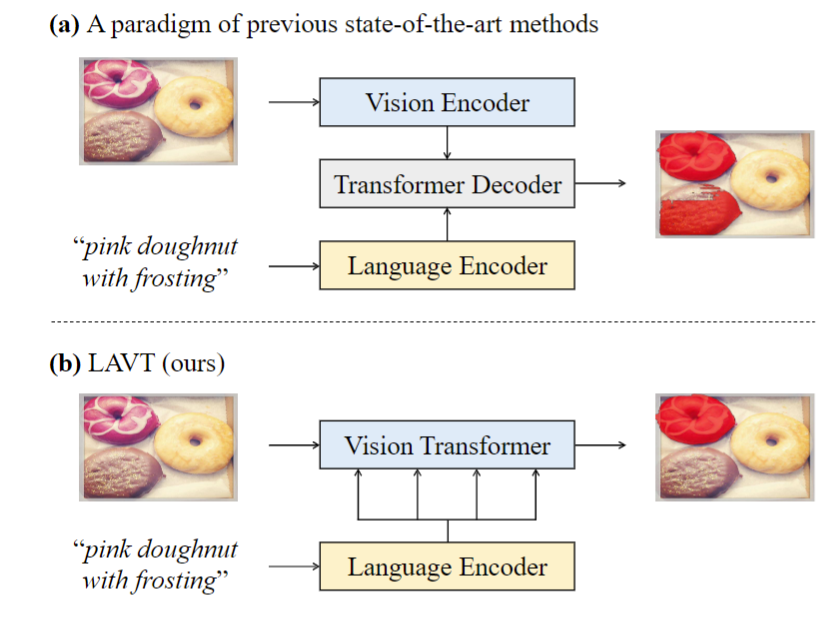
当前的多模态模型大多是从不同的编码器网络中独立地提取视觉和语言特征,然后将它们融合在一起以使用跨模态解码器进行预测。具体来说,融合策略包括循环交互、跨模态注意力、多模态图推理、语言结构引导的上下文建模等。最近的进展通过使用跨模态 Transformer解码器(如下图a所示)来学习更有效的跨模态对齐(cross-modal alignment),提高了性能。
在现有方法中,Transformer 的潜力仍然未被充分挖掘。具体来说,跨模态交互仅在特征编码之后发生,跨模态解码器仅负责对齐视觉和语言特征。因此,以前的方法未能有效地利用编码器中的特征来挖掘有用的多模态上下文。为了解决这个问题,一个解决方案是在视觉编码过程中联合嵌入语言和视觉特征。因此,作者提出了一个Language-Aware Vision Transformer(LAVT)网络,其中视觉特征与语言特征一起编码,在每个空间位置“感知”它们的相关语言上下文。如上图(b)所示,LAVT充分利用了Transformer骨干网络中的多阶段设计,形成了一种分层的语言感知视觉编码方案。
2、主要方法
LAVT的总体框架如下图所示,红框中的四阶段的 Transformer 编码器,每个阶段包括 Transformer编码层 \(\phi_i\) 、多模态融合单元 \(\theta_i\) 和可学习的门控单元 \(\psi_i\) 。首先,Transformer 层 \(\phi_i\) 输出视觉特征 \(V_i\),然后通过多模态融合模块 \(\theta_i\) 与语言特征 \(L\) 相结合生成一组多模态特征 \(F_i\),然后\(F_i\) 中的每个元素由可学习的门控单元\(\psi_i\) 加权,然后逐个元素添加到 \(V_i\) 以产生一组嵌入语言信息的增强视觉特征,表示为\(E_i\)。
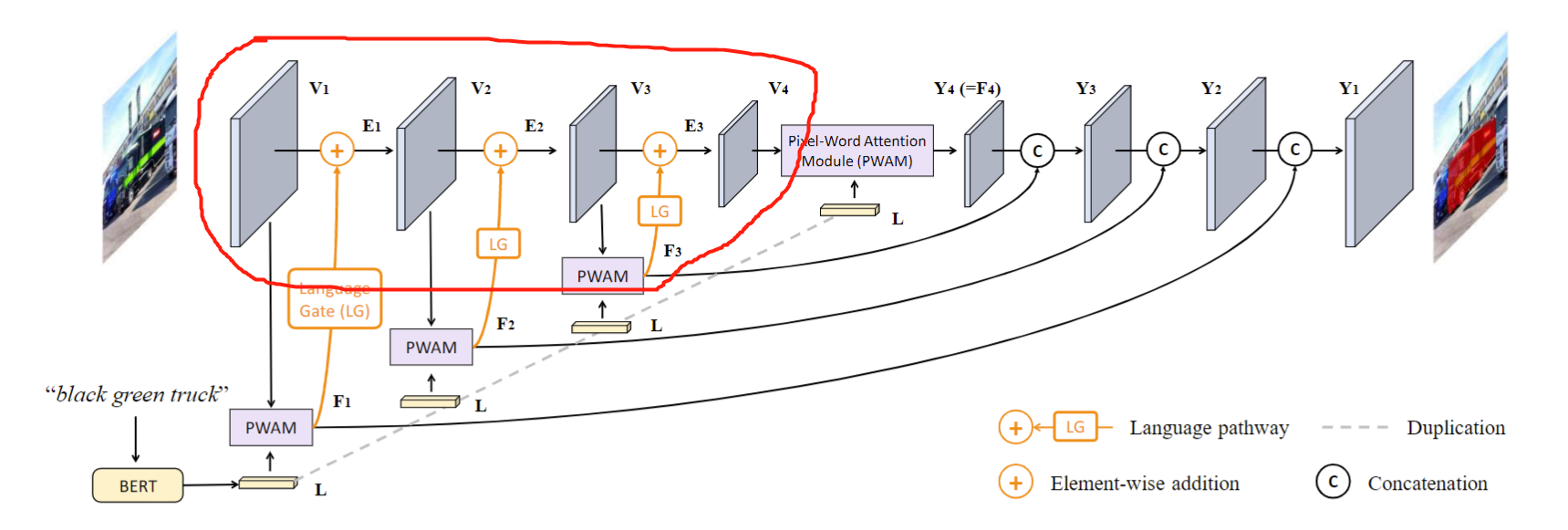
在多模态融合模块中,关键的是 PWAM (pixel-word attention module)。该模块细节如下图所示,个人感觉有些类似于 attention ,只不过 K 和 V 来自语言,Q来自于视觉。语言特征实现缩放的点积注意力。

在每个阶段,作者将PWAM的输出 \(F_i\) 与 Transformer输出的 \(V_i\) 合并,为了防止 \(F_i\) 压倒 \(V_i\) 中的视觉特征,并允许语言特征自适应的流向 Transformer 的下一阶段,作者设计了一个 language gate,结构如下图所示。结构非常简单,由两层卷积组成。

网络剩下的部分就是组合多阶段特征图,进行最终的分割。
3、实验与分析
作者在 PyTorch中实现本文的方法,并使用 HuggingFace 的 Transformer 库中的 BERT 实现。LAVT 中的 Transformer 层使用 Swin Transformer在 ImageNet22K上预训练的分类权重进行初始化。本文的语言编码器是基础 BERT 模型,具有 12 层,隐藏大小为 768,并使用官方预训练的权重进行初始化。
本文模型中的其余权重是随机初始化的。模型使用交叉熵损失进行优化。作者采用 AdamW优化器,权重衰减为 0.01,初始学习率为 0.00005。作者用batch大小为 32 的 40 个 epoch 训练本文的模型。在一个 epoch 中对每个对象(同时为它随机采样一个引用表达式)仅迭代一次。图像被调整为 480×480,并且没有应用数据增强技术。在推理过程中,沿分数图的通道维度的 argmax 用作预测。
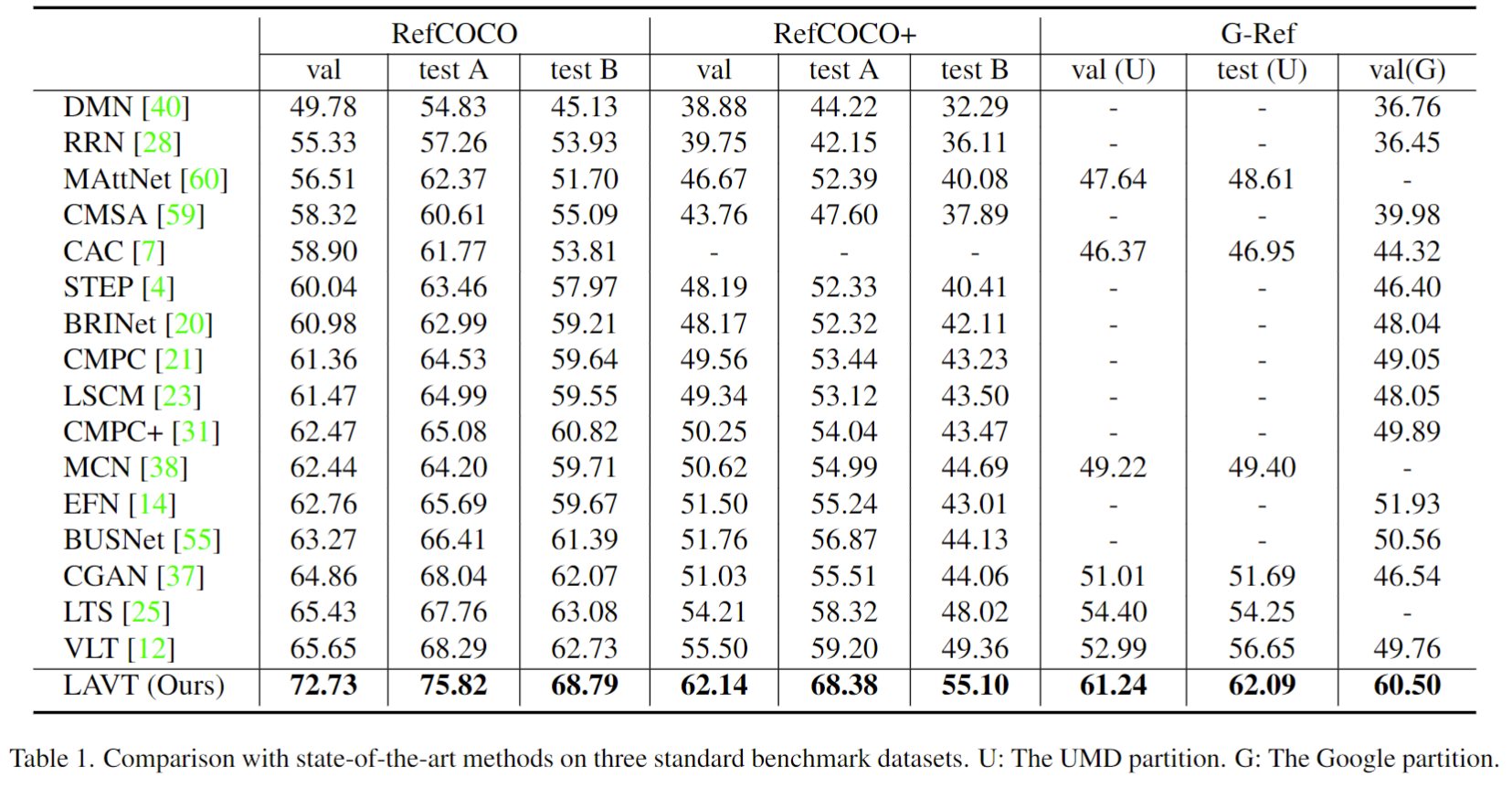
LAVT在三个公开数据集上均取得最优性能。
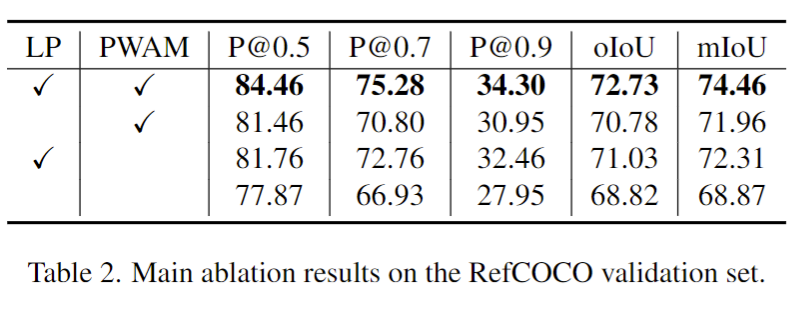
消融实验可以看出,作者提的的两个模块对于提升性能都是有效的。
此外,作者还比较了在 language gate 中使用不同激活函数的影响,归一化函数对于实验结果的影响等。
作者还做了很多实验,可以参考作者论文,这里不过多介绍。
标签:模态,Transformer,Referring,Language,特征,视觉,LAVT,语言 From: https://www.cnblogs.com/gaopursuit/p/16626474.html