作者自己的解读比较精辟(NeurIPS'21) SegFormer: 简单有效的语义分割新思路 - Anonymous的文章 - 知乎 https://zhuanlan.zhihu.com/p/379054782
摘要
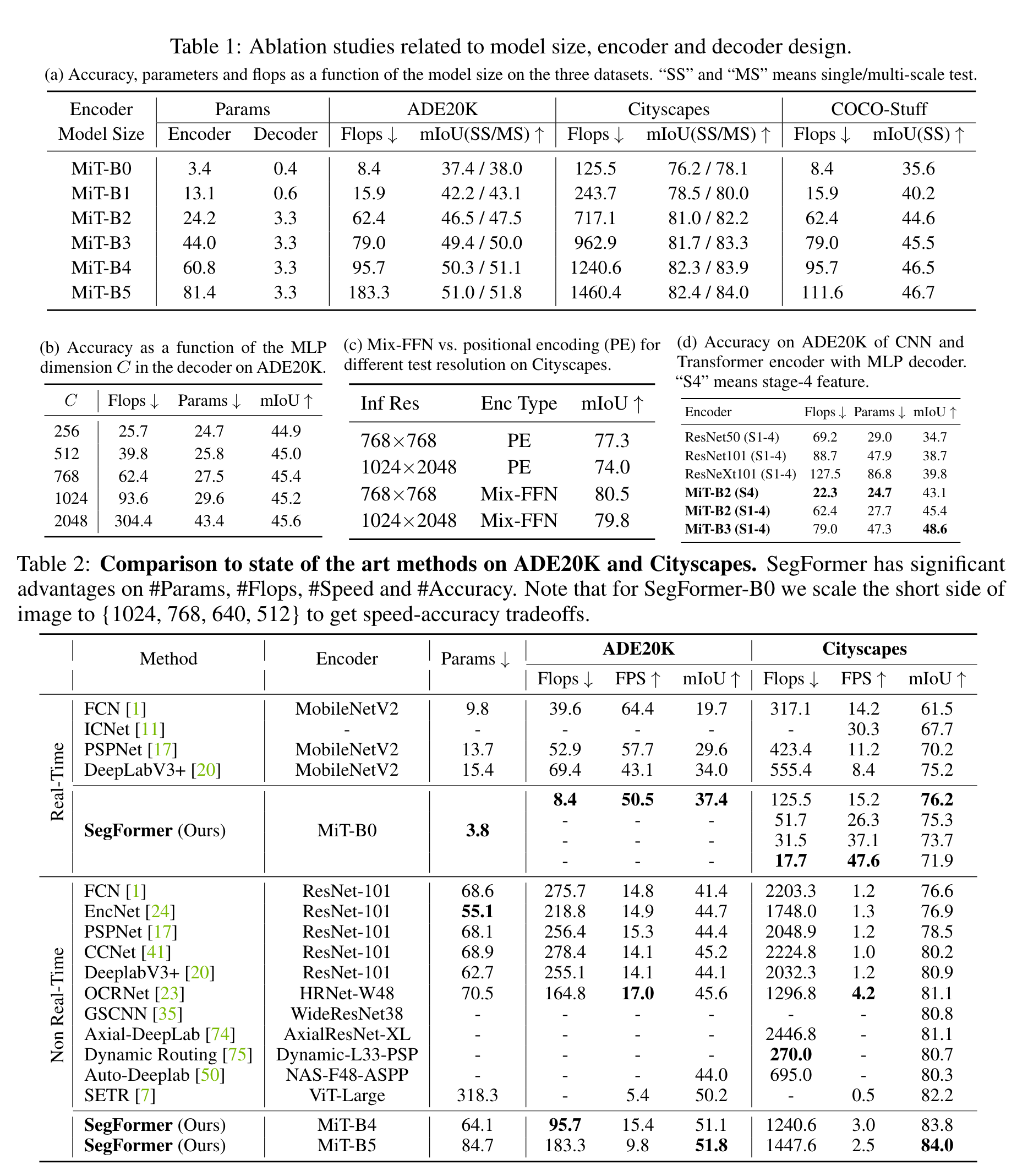
作者提出了基于Transformer的语义分割模型SegFormer,其有两个特点:层级式encoder输出多尺度的特征,无需位置编码从而避免对位置编码插值(当测试分辨率与训练不同时,插值会导致性能下降);使用MLP作为decoder聚合来自不同层的信息,轻量且高效。
方法
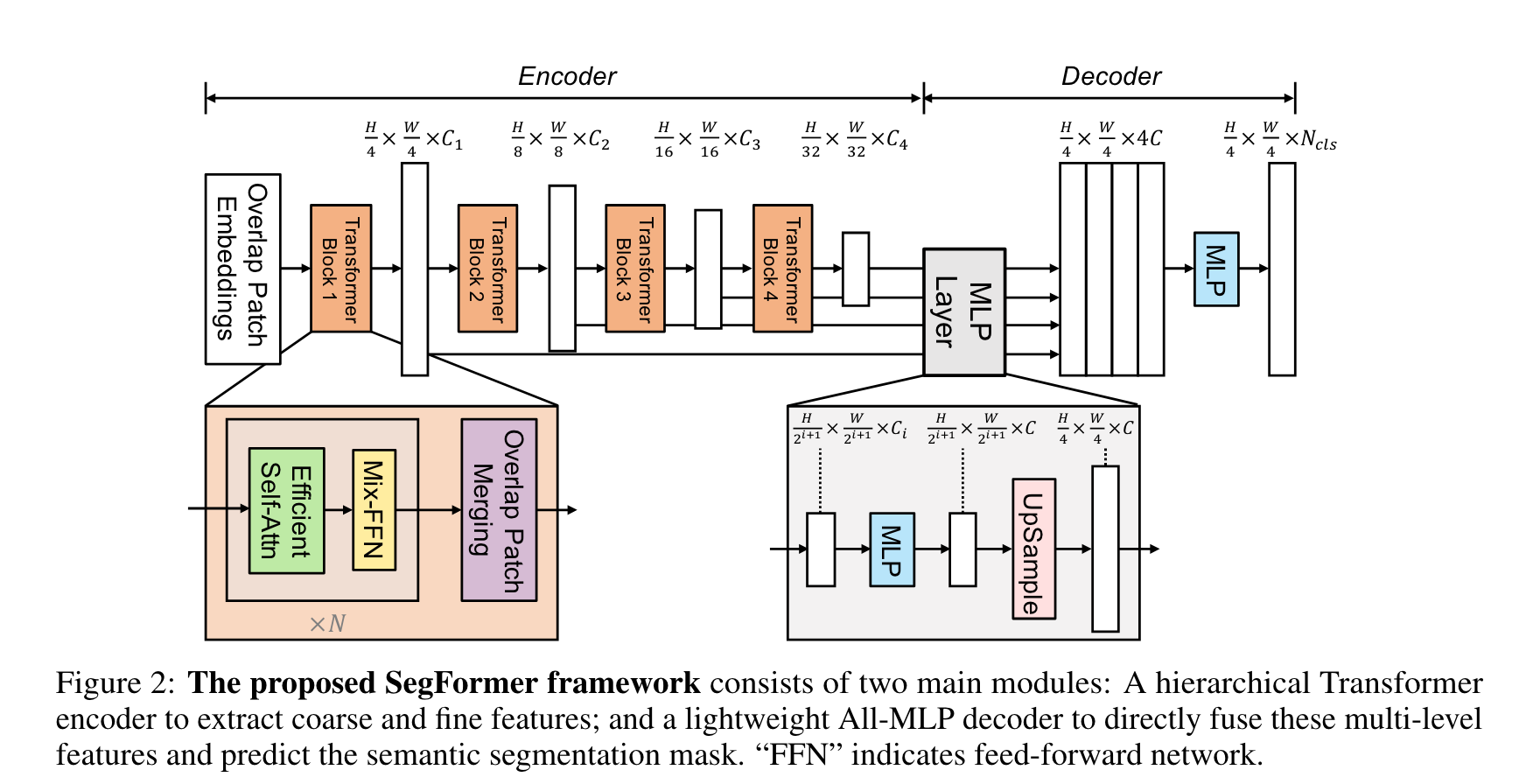
Hierarchical Transformer Encoder
Hierarchical Feature Representation。首先对于输入图像,将其打为\(4\times 4\)的patch(小的patch有利于密集预测)。通过设计的Mix Transformer encoder得到一系列不同尺度的特征图\(\frac{H}{2^{i + 1}}\times \frac{W}{2^{i+1}}\times C_i\),尺度不断变小的同时增大通道数。
Overlapped Patch Merging。 Non-overlapped Patch Merging可以将\(N\times N\times 3\)大小的Patch变为一个\(1\times 1\times C\)大小的vector,也可以将\(\frac{H}{4}\times \frac{W}{4}\times C_1\)大小的特征变为\(\frac{H}{8}\times \frac{W}{8}\times C_2\)。但这样会丢失Patch的局部连续性。因此作者设计了一种Overlapping Patch Merging方法,可以得到与non-overlapping方法相同大小的输出。
Efficient Self-Attention。 传统的计算self-attention的复杂度与sequence的长度的平方成正比。作者这里采用了Pyramid vision transformer提出的方法,通过比率因子R缩减序列长度:
\(\hat{K}=Reshape(\frac{N}{R}, C·R)(K)\),\(K=Linear(C·R, C)(\hat{K})\)
其中K是要缩减的序列。处理后得到的K的大小为\(\frac{N}{R}\times C\),整个操作的复杂度变为\(O(\frac{N^2}{R})\)。
Mix-FFN。传统的ViT的位置编码的输入图像分辨率都是固定的。如果测试时分辨率改变,需要对位置编码进行插值,可能会导致掉点。作者认为PE对于语义分割任务是非必要的,选择用Mix-FFN替换PE:
\(x_{out}=MLP(GELU(Conv_{3\times 3}(MLP(x_{in}))))+x_{in}\)
实验证明\(3\times 3\)的卷积能提供足够的位置信息。
Lightweight All-MLP Decoder
作者仅仅使用了MLP来构建Decoder,这样做的基础是本文提出的层级式Transformer的有效感受野比CNN encoder的有效感受野更大。这种纯MLP的decoder一共分为四步:首先通过encoder得到的多尺度的特征经过一个MLP层对通道维度进行统一;之后将特征上采样到原图\(\frac{1}{4}\)大小并在通道维度进行concat;再使用一个MLP层融合拼接得到的特征;最后使用一个MLP层处理融合的特征得到大小为\(\frac{H}{4}\times \frac{W}{4}\times N_{cls}\)的mask:

Effective Receptive Field Analysis。 作者这里分析了一下MLP decoder的有效性,与DeepLabV3+进行了对比:
Relationship to SETR
这部分作者对比了一下SETR,突出了SegFormer的优势~
实验