会议号:795-775-9627
首先是逝去的 NOIP。
我没想到 NOIP2022 倒在了我前面。
总结就是题整体不难,但是有病。
最有病的就是 random_shuffle 题目顺序。我觉得最优开题顺序是1342。
T1 是签到题。我是枚举所有 C 的左下角,这样如果再接上一个竖就是 F。然后随便整点前缀和就行了。
我不到为啥我常数能是别人的十倍。
T2 是不会题。 思路就是考虑留一个辅助栈,找到第一个再次出现的栈底,然后大力分类讨论。但是完全实现不出来。写了一大坨发现有问题一气之下全删了。看 T3。
T3 是套路题。
是谁说联赛不考边双的?
感谢出题老师。
说联赛不考边双的原因是边双的题比较裸,然后 NOIP 出了,果然是个裸题。首先缩个点,然后树形 DP。我的状态是 \(f_{i,0/1}\) 表示 \(i\) 的子树里选的点和 \(i\) 有没有构成 LCA,然后考虑加进一个子树之后的变化。具体来讲,如果需要加进当前子树,那么直接贡献到 \(f_{i,1}\),否则在子树里乱选一些边加到 \(f_{i,1}\) 里去。
然后考虑 \(f_{i,0}\) 的转移。要么是在前面已转移完的子树里乱选一些边,然后只选当前子树,或者是在当前子树里乱选一些边。
难点就是树形 DP,但也一般。
T4 也是个套路题。我非常怀疑如果我们去考了会吃大亏,理由的话就是这题基本上是原题。跟原题的差距就是一个求最大和最小的积,另外一个是求两个序列的最大。但毫无差别。link
我的暴力做法就是分治。
对询问区间分治。每次只找跨过分治中心的答案。然后枚举左区间的左端点,右边用点指针能直接维护分段函数,然后用前缀和统计答案。
我周日没想明白这玩意怎么优化。然后周一想通了。
就是把所有的询问放到一起分治。如果当前区间完全被询问包含,那就把区间下所有答案都统计到询问里。
然后考虑一堆询问跨过区间终点的答案。
就是把所有的询问按左端点排序,然后也是指针维护 \(a\) 和 \(b\) 到哪里最大值取左边,对于右区间每个位置,有四种情况:
- \(a\) 和 \(b\) 的最大值都取左边的。
- \(a\) 取右边的前缀最大值,\(b\) 取左边的最大值
- \(b\) 取右边的前缀最大值,\(a\) 取左边的最大值
- \(a,b\) 都取右边的前缀最大值
对于四种情况每个位置有四种不同的贡献,而每次加入一个左端点都是改变系数。所以用四个线段树维护贡献即可。
他们管这玩意叫猫树分治,但我至今不知道这玩意跟猫树有啥关系。不过是优秀的套路
在家效率骤减,一水题能写一下午。
[USACO17DEC]Milk Measurement S
就是整个线段树维护最大值,最大值数量,和取到最大值是哪个数。
如果最大值的数量变了,那一定有问题。
数量没变,但是取到的那个数变了一定也有问题,就加一下答案就行。
我试图补 ZSH 的模拟赛,但是一晚上就写了个弱化版。
线段树的优秀理解。
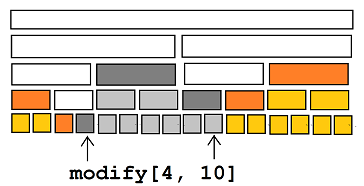
考虑对这五种节点分别维护答案。
假设 \(f_{i,p}\) 表示第 \(i\) 次操作后 \(p\) 点上的 tag的树的个数。
有些情况是不能维护的,因为涉及到祖先存不存在 tag。
所以再设一个 \(g_{i,p}\) 表示第 \(i\) 次操作后 \(p\) 节点到根的路径上不存在 tag 的树的数量。
这样对五种节点都能转移了。
然后经典线段树懒标记不下传。
被封在家里了。
竞赛的免回家卡失效了喵
在家看一天笔记本的屏脖子和眼睛都要废了喵。
喵喵喵。
标签:11.29,前缀,询问,线段,分治,然后,最大值,小记 From: https://www.cnblogs.com/cc0000/p/16936844.html