# Stochastic Scene-Aware Motion Prediction #paper
1. paper-info
1.1 Metadata
- Author:: [[Mohamed Hassan]], [[Duygu Ceylan]], [[Ruben Villegas]], [[Jun Saito]], [[Jimei Yang]], [[Yi Zhou]], [[Michael Black]]
- 作者机构::
- Keywords:: #HMP
- Journal:: #ICCV
- Date:: [[2021-08-18]]
- 状态:: #Done
- 链接:: http://arxiv.org/abs/2108.08284
- 修改时间:: 2022.11.10
1.2. Abstract
A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
2. Introduction
- 领域:在真实场景下合成人体动作。
synthesizing 3D people in 3D scenes- 应用:
virtual worldsplacing humans into scenes - 问题:感知未知环境
perception of unseen environment、对人体动作合理的建模plausible human motion modeling、与复杂环境交互embodied interaction with complex scenes
- 应用:
- 作者的方法:
SAMP model ``Scene-aware Motion prediction:输入场景和交互的目标,采样生成符合目标的、基于场景的人体动作序列模型。- 模型构成:
MotionNet:生成动作序列GoalNet:生成多个合理的连接点,并且生成合理的目标方向path planning algorithm(A* search):生成合理的路径,目标人物不会和物体产生碰撞。
- dataset:现存的数据集缺乏真实的场景交互,作者采集了新的数据库----包含多目标的基于场景的人体动作序列集。
3. Methods
对于此类场景需要解决3个问题:
- 采样合成的动作需要真实并且符合自然的变化。
- 对于动作序列的停顿点(动作的变化点),需要生成合理的连接点,并且生成在此点的人体方向。
- 对于人体前进的路径不能够与场景中的物体有所碰撞。
作者提出的模型包含3部分,分别用于解决上面的3个问题
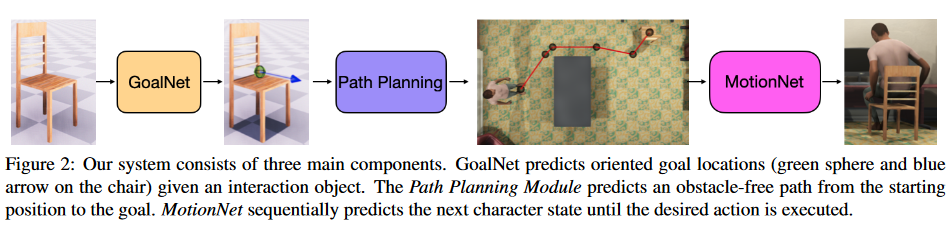
Fig.1 整体框架图
Source: http://arxiv.org/abs/2108.08284
3.1. MotionNet
该模型是一个自回归条件变分自编码模型an autoregressive conditional variational autoencoder(CVAE)模型,由encoder和decoder构成。模型结构图如Fig.2
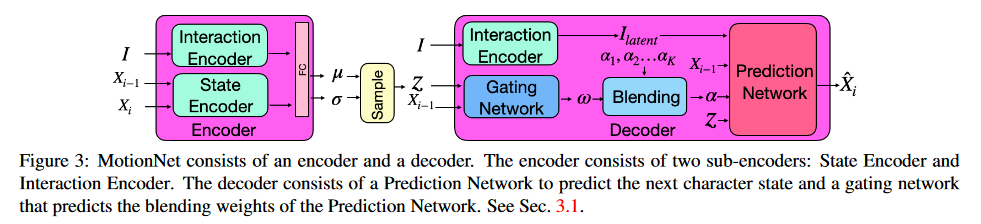
Fig. 2. MotionNet
Source: http://arxiv.org/abs/2108.08284
encoder
- State Encoder
将人物当前的状态和上一时刻的状态编码成一个低维度的向量。 - Interaction Encoder
将交互的物体\(I \in\mathbb{R}^{8\times8\times8}\)编码成低维的向量。
将object geometry编码成一个低维的向量
在第\(i\)frame的人体状态定义为:
\[X_i=\{j_i^p,j_r^r,j_r^v,\tilde{j}_i^p,t_i^p,t_i^d,\tilde{t}_i^p,\tilde{t}_i^d,t_i^a,g_i^p,g_i^d,g_i^a,c_j \} \]\(j_i^p,j_i^r,j_i^v\):每个关节点相对于根关节点的位置,旋转,速度。
\(\tilde{j}_i^p\in\mathbb{R}^{3j}\):相对于未来根节点的关节点位置。
\(t_i^p\in\mathbb{R}^{2t},t_i^d\in\mathbb{R}^{2t}\):前者是关于前一帧的根节点的关节点位置,后者是关于前一帧的根节点的方向。
\(\tilde{t}_i^p\in\mathbb{R}^{2t},\tilde{t}_i^d\in\mathbb{R}^{2t}\):相对于前一帧的目标的位置和方向。
\(t_i^a\in\mathbb{R}^{n_at}\):在\(t\)个采样中的动作标签,在作者的数据库中\(n_a=5\)(idle, walk, run, sit, lie down)。
\(g_i^p\in\mathbb{R}^{3t},g_i^d\in\mathbb{R}^{3t}\):目标点的位置和方向(目标点是指路径上姿态改变的点)
\(g_i^a\in\mathbb{R}^{n_at}\):动作标签的ont-hot编码
\(c_j\in\mathbb{R}^5\):盆骨、脚、手的标签
Decoder
decoder由两部分构成Prediction Network和Gating network 。
prediction network:
输入:\(X_{i-1}\)、\(\alpha\)、\(\mathcal{Z}\)
输出:\(\hat{X}_i\)
\(w\)是由Gating network生成
Gating Network:一个mixture of expects层
每个expects由一个3层的全连接层构成。
MotionNet的损失函数为:
重构损失函数和VAE的标准KL损失函数。
3.2. GoalNet
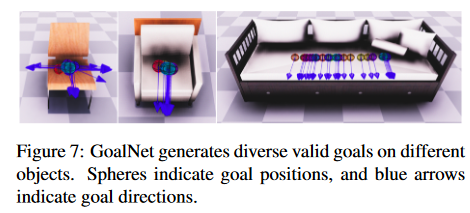
Fig.3
Source:
该网络模型的目标是根据目标的几何体生成人体姿态的方向和位置。网络模型如Fig4
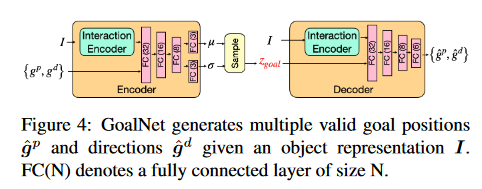
Fig. 4.GoalNet
Source: http://arxiv.org/abs/2108.08284
输入:
\(interaction-object\)\(I\)
goal position\(g_p\)
direction \(g_d\)
损失函数:
其他符合标准VAE
3.3. Path Planning
使用A* path planning algorithm去生成无阻碍的路径。
3.4. Training Strategy
为防止错误累计问题,使用scheduled sampling。
4. 总结
该文章解决的问题是如何在有密集物体的室内环境下,生成人体动作。分为3个部分,第一部分产生人体动作;第二部分选取场景中的连接点,生成在此连接点下的、符合物体方向的人体姿势和运动方向;第三部分为生成连接点之间的路径。模型的大致框架都是基于CVAE的,并且作者采样了新的数据库。关于该文章实验部分,没有深入了解。
标签:mathbb,right,动作,boldsymbol,生成,StochasticSceneAwareMotionPrediction,ICCV,Hassan,l From: https://www.cnblogs.com/guixu/p/16877355.html