小雅环境和自定义gym融合
自定义Gym环境并注册
Gym的环境都保存在gym/envs目录下,envs目录下包含了各种类型的环境例如:atari、classic_control等,我们研究飞行器等类型问题所建立的自定义环境一般可以放在classic_control中。
Step1:建立环境文件
在envs/classic_control目录下,建立环境文件ace.py
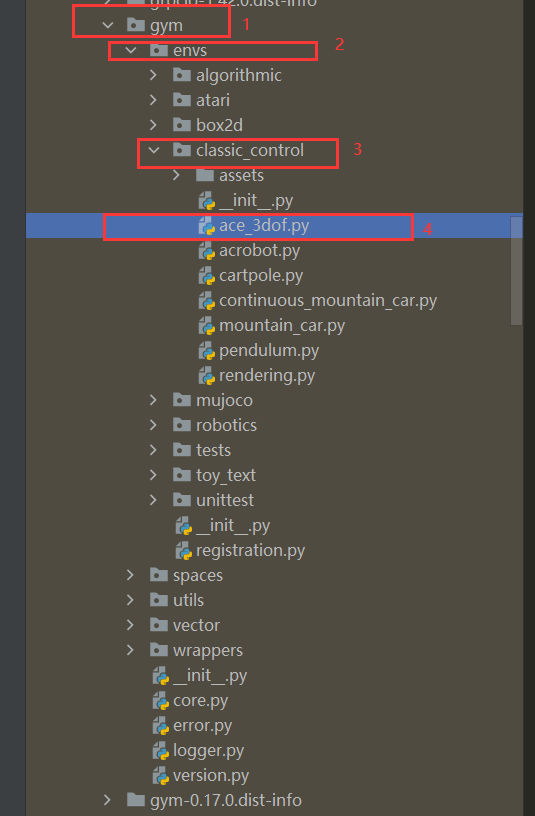
ace.py中应定义一个环境类一般以XxxEnv为名称,本文建立类名称为AceEnv,按照gym的工作原理,此类中应至少包含reset()、step()、init()、seed()、close()函数,其中,step函数必须返回obs, reward, done, info四个变量,reset返回初始化的状态。(注:此部分的函数定义格式可以参考classic_control内的其他函数,着重是要按照需求更改step和reset函数)。另外需要对环境的主要变量维数进行定义,方便外部强化学习算法直接调用生成模型网络,例如控制量维度、状态量维度等。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 11 16:31:53 2021
@author:
"""
import gym
from gym import spaces
from gym.utils import seeding
import numpy as np
from os import path
# from numba import jit
class Ace3DEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 30
}
def __init__(self):
self.simu_step = 0.5
self.max_step = 100
#测试开关量
self.k_gain = np.array([1, 1, 1, 0.2, 0.2]) #指标因子 r,aa,ata,act1,act2
self.noi = 1
self.if_RL_or_Trad = 1 # RL=1, Tradition_control=0
self.v = 200
# 行动
self.lim_dtheta = 40 / 57.3 # theta变化量,弧度/秒
self.lim_dpsi = 40 / 57.3 # psi变化量,弧度/秒
self.action_dim = 2 # 行动维度
# 行动空间
action_high = np.array([self.lim_dtheta, self.lim_dpsi], dtype=np.float32)
action_low = np.array([-self.lim_dtheta, -self.lim_dpsi], dtype=np.float32)
self.action_space = spaces.Box(low=action_low, high=action_high, dtype=np.float32)
# 观测空间上下限
self.max_r = 10000/1000
self.max_dr = 400/100
self.max_q1 = 1 * np.pi
self.max_q2 = 1 * np.pi # q,弧度制
self.max_theta = 1 * np.pi
self.max_psi = 1 * np.pi
self.min_r = 0/1000
self.min_dr = -400/100
self.min_q1 = -1 * np.pi
self.min_q2 = -1 * np.pi # 弧度制
self.min_theta = -1 * np.pi
self.min_psi = -1 * np.pi
self.state_dim = 8 # 状态维度
#敌机b的行动,随机行动,限制其随机范围
self.u_b_theta = 0.001 * np.random.uniform(-5,5)
self.u_b_psi = 0.001 * np.random.uniform(-5,5)
# 观测空间
observation_high = np.array([self.max_r, self.max_dr, self.max_q1, self.max_q2, self.max_theta, self.max_psi,self.max_theta, self.max_psi],
dtype=np.float32)
observation_low = np.array([self.min_r, self.min_dr, self.min_q1, self.min_q2, self.min_theta, self.min_psi,self.min_theta, self.min_psi],
dtype=np.float32)
self.observation_space = spaces.Box(low=observation_low, high=observation_high, dtype=np.float32)
self.state = None
self.obs = None
#定义我方起始位置的锥角
self.zhuijiao = 45 / 180 * np.pi
self.x_max = -100
self.x_min = -5000
#评分记录
self.r_r = 0
self.r_aa = 0
self.r_ata = 0
self.r_act1 = 0
self.r_act2 = 0
self.np_random = None
self.k = 1
self.viewer = None
self.seed()
def seed(self, seed=None): # 随机种子
self.np_random, seed = seeding.np_random(seed)
return [seed]
def step(self, act):
# 行动,环境更新,状态方程
# 取出state里的数
x_r, y_r, z_r, theta_r, psi_r, x_b, y_b, z_b, theta_b, psi_b = self.state
# 取出双方状态
# 我方x,y,z,角度1,角度2
state_r = np.array([x_r, y_r, z_r, theta_r, psi_r])
# 敌方x,y,z,角度1,角度2
state_b = np.array([x_b, y_b, z_b, theta_b, psi_b])
'''敌方运动'''
# 决策
command_b = [self.u_b_theta, self.u_b_psi] # 随机运动
# command_b = [0, 0] # 随机运动
# command_b = self.OptimalChoice_r(state_b, state_r)
next_state_b = self.euler_func(state_b, command_b, self.simu_step, 0)
'''我方运动'''
# 决策
if self.if_RL_or_Trad == 1:
command_r = np.array([act[0], act[1]]) #采用外部给定控制量
# command_r = np.array([0, 0.0001])
else:
command_r = self.OptimalChoice_r(state_r, state_b) #采用传统策略控制量
next_state_r = self.euler_func(state_r, command_r, self.simu_step, 0)
# 更新状态空间,观测空间, 奖励, 判断是否终止
state_ = np.append(next_state_r, next_state_b)
self.state = state_.copy()
observation = self.get_obs(self.state)
rewards = self.score_Syn(act)
done = bool(z_r < 100 or self.r/1000 > self.max_r or self.k > self.max_step)
self.k += 1
return observation, rewards, done, {}
def score_Syn(self, act):
"""
计算当前情形下,动作的得分(奖励)
:param act:
:return:
"""
# r未归一化,AA与ATA为弧度
act1 = abs( act[0] / self.lim_dtheta) #对act进行归一化
act2 = abs( act[1] / self.lim_dpsi) #对act进行归一化
AA = abs(self.AA)
ATA = abs(self.ATA)
r = self.r
scoring_r = (10000 - r)**2 / 25e5 - 8 # [0,10000]=rewards:[-7,32]
scoring_aa = 3 * (np.pi - AA)**2 - 10 # aa:[0-180] -> rewards:[-10,20]
scoring_ata = 3 * (np.pi - ATA)**2 - 10 # ata:[0-180] -> rewards:[-10,20]
scoring_act1 = 20 * (1 - act1)**2 - 15 # act:[0,1] -> rewards[-15,5] 侧重惩罚项
scoring_act2 = 20 * (1 - act2)**2 - 15 # act:[0,1] -> rewards[-15,5] 侧重惩罚项
k = self.k_gain
self.r_r = k[0] * scoring_r
self.r_aa = k[1] * scoring_aa
self.r_ata = k[2] * scoring_ata
self.r_act1 = k[3] * scoring_act1
self.r_act2 = k[4] * scoring_act2
scoring = k[0]*scoring_r + k[1]*scoring_aa + k[2]*scoring_ata + k[3]*scoring_act1 + k[4]*scoring_act2
return scoring
def reset(self, noi=True):
# 重置状态
self.k = 1
ang_nosie = self.noi * np.random.uniform(low=-30, high=30, size=4) # 初始指向随机值
# 蓝方的状态初始值
x_b = 2000
y_b = 0
z_b = 6500
theta_b = ang_nosie[2] / 180 * np.pi
psi_b = ang_nosie[3] / 180 * np.pi
# 红方的状态初始值
x_r = np.random.uniform(self.x_min,self.x_max) #锥形区域上随机选定距离,切出一个圆,x_r
polar_radius_max = x_r * np.tan(self.zhuijiao) #形成一个圆区域
polar_radius = np.random.uniform(0,polar_radius_max) #圆内以极坐标选取点(y,z),首先随机选半径:polar_r=[0,radius]
polar_ang = np.random.uniform(0,2*np.pi) #圆内以极坐标选取点(y,z),其次选角度:polar_angle=[0,2pi]
y_r = np.cos(polar_ang) * polar_radius # y = cos(ang)*radius
z_r = np.sin(polar_ang) * polar_radius + z_b # z = sin(ang)*radius
theta_r = ang_nosie[0] / 180 * np.pi
psi_r = ang_nosie[1] / 180 * np.pi
self.state = np.array([x_r, y_r, z_r, theta_r, psi_r, x_b, y_b, z_b, theta_b, psi_b]) # 环境状态
return self.get_obs(self.state)
def get_obs(self, state):
"""
:param state: 当前状态空间,双方的位置、角度
:return: 输出[r / 1000, dr / 100, AA, ATA, q_alpha, q_beta]
"""
# 智能体观察值
x_r, y_r, z_r, theta_r, psi_r, x_b, y_b, z_b, theta_b, psi_b = state
v = self.v
# 求r
oyou = np.array([x_r, y_r, z_r]) # 友方(我方)位置矢量
vx = v * np.cos(theta_r) * np.cos(psi_r)
vy = v * np.cos(theta_r) * np.sin(psi_r)
vz = v * np.sin(theta_r)
vyou = np.array([vx, vy, vz]) # 友方(我方)速度矢量
oenemy = np.array([x_b, y_b, z_b]) # 敌方(对方)位置矢量
vx = v * np.cos(theta_b) * np.cos(psi_b)
vy = v * np.cos(theta_b) * np.sin(psi_b)
vz = v * np.sin(theta_b)
venemy = np.array([vx, vy, vz]) # 敌方(对方)速度矢量
LOS_you_enemy = oenemy - oyou # 我方:敌我视线角
# LOS_enemy_you = oyou - oenemy # 敌方:敌我视线角
self.AA = self.Cal3DAngle(venemy,LOS_you_enemy) # 根据速度矢量(敌方)和双方位置连线,计算夹角(弧度制)
self.ATA = self.Cal3DAngle(vyou,LOS_you_enemy) ## 根据速度矢量(我方)和双方位置连线,计算夹角(弧度制)
self.r = np.sqrt(LOS_you_enemy[0] ** 2 + LOS_you_enemy[1] ** 2 + LOS_you_enemy[2] ** 2) #计算距离
dr = np.sqrt(np.sum((vyou - venemy) ** 2)) #计算速度的
q_alpha = np.arctan2(LOS_you_enemy[2], np.sign(LOS_you_enemy[0]) * np.sqrt(LOS_you_enemy[0] ** 2 + LOS_you_enemy[1] ** 2)) #纵向平面视线角 atarn2(z,sign(x)*sqrt(x^2+y^2))
q_beta = np.arctan2(LOS_you_enemy[1], LOS_you_enemy[0]) # 侧向视线角 atan2(y,x) , 正psi产生正y
return np.array([self.r / 1000, dr / 100, q_alpha, q_beta, theta_r, psi_r,theta_b, psi_b])
def Cal2DAngle(self, v1, v2):
"""
:param v1:
:param v2:
:return:
"""
# v1旋转到v2,逆时针为正,顺时针为负
# 2个向量模的乘积
TheNorm = np.linalg.norm(v1) * np.linalg.norm(v2)
# 叉乘
rho = np.arcsin(np.cross(v1, v2) / TheNorm)
# 点乘
theta = np.arccos(np.dot(v1, v2) / TheNorm)
if rho< 0:
return - theta #弧度
else:
return theta #弧度
def Cal3DAngle(self, v1, v2):
"""
:param v1: 向量1
:param v2: 向量1
:return: 向量之间的反正切值
"""
#计算弧度
V1xV2 = np.cross(v1, v2) #np.cross 计算两个向量的叉积
TheNorm = np.linalg.norm(V1xV2) #求2范数
theta = np.arctan2(TheNorm , np.dot(v1, v2)) # arctan2的输入不仅仅是正切值,而是要输入两个数x 1 x2 ,求反正切
if V1xV2[2] < 0:
return -theta #弧度
else:
return theta #弧度
def close(self):
if self.viewer:
self.viewer.close()
self.viewer = None
def OptimalChoice_r(self, you_plane, enemy_plane):
"""
传统策略选择函数 ,
:param you_plane:
:param enemy_plane:
:return:
"""
simu_step = self.simu_step
# 敌方Step一次,假设不作机动
state_enemy = enemy_plane.copy() # 敌人x, y, z, theta, psi
next_state_enemy = self.euler_func(state_enemy, np.array([0, 0]), simu_step , 0)
# 我方Step一次,根据pi*策略选择最优机动
state_you = you_plane.copy() # 我方x, y, z, theta, psi
# U = np.array([-5,-3,-1,1,3,5,7]) * 8 / 57.3
U = np.random.uniform(-5,5,7) * 8 / 57.3
S_max = -np.inf # 初始分数非常小
cmd1 = np.array([0, 0]) # 初始化cmd1
# scoring = np.zeros((7,7))
for k1 in range(np.size(U)):
for k2 in range(np.size(U)):
next_state_you = self.euler_func(state_you, np.array([U[k1], U[k2]]), simu_step , 0)
state = np.append(next_state_you, next_state_enemy)
r, dr, q1, q2, AA, ATA = self._get_obs(state)
scoring = self.score_Syn(r *1000, AA, ATA, np.array([U[k1], U[k2]]))
if scoring > S_max:
S_max = scoring
cmd1 = np.array([U[k1], U[k2]]) # 弧度制
return cmd1 # 返回弧度制指令
def CalculationCommand(self):
'''单观察算行动'''
# 根据策略取行动
x_r, y_r, z_r, theta_r, psi_r, x_b, y_b, z_b, theta_b, psi_b = self.state # 使用状态值,观察值是归一化过的
state_r = np.array([x_r, y_r, z_r, theta_r, psi_r])
state_b = np.array([x_b, y_b, z_b, theta_b, psi_b])
command_r = self.OptimalChoice_r(state_r, state_b) # 决策函数
action = np.array([command_r[0], command_r[1]])
return action
def euler_func(self, state0, command, t, flag):
"""
评估当前状态是否可行
:param state0:
:param command:
:param t:
:param flag:
:return:
"""
v = self.v + 0 * flag
d_theta = command[0]
d_psi = command[1]
state = state0.copy()
state[3] += d_theta * t # 更新theta
if state[3] > 180 / 57.3:
state[3] = (-180 + 1e-3) / 57.3
if state[3] < -180 / 57.3:
state[3] = (180 - 1e-3) / 57.3
state[4] += d_psi * t # 更新psi
if state[4] > 180 / 57.3:
state[4] = (-180 + 1e-3) / 57.3
if state[4] < -180 / 57.3:
state[4] = (180 - 1e-3) / 57.3
state[0] += v * np.cos(state[3]) * np.cos(state[4]) * t # 更新x方向
state[1] += v * np.cos(state[3]) * np.sin(state[4]) * t # 更新y方向
state[2] += v * np.sin(state[3]) * t # 更新z方向
return np.array(state)
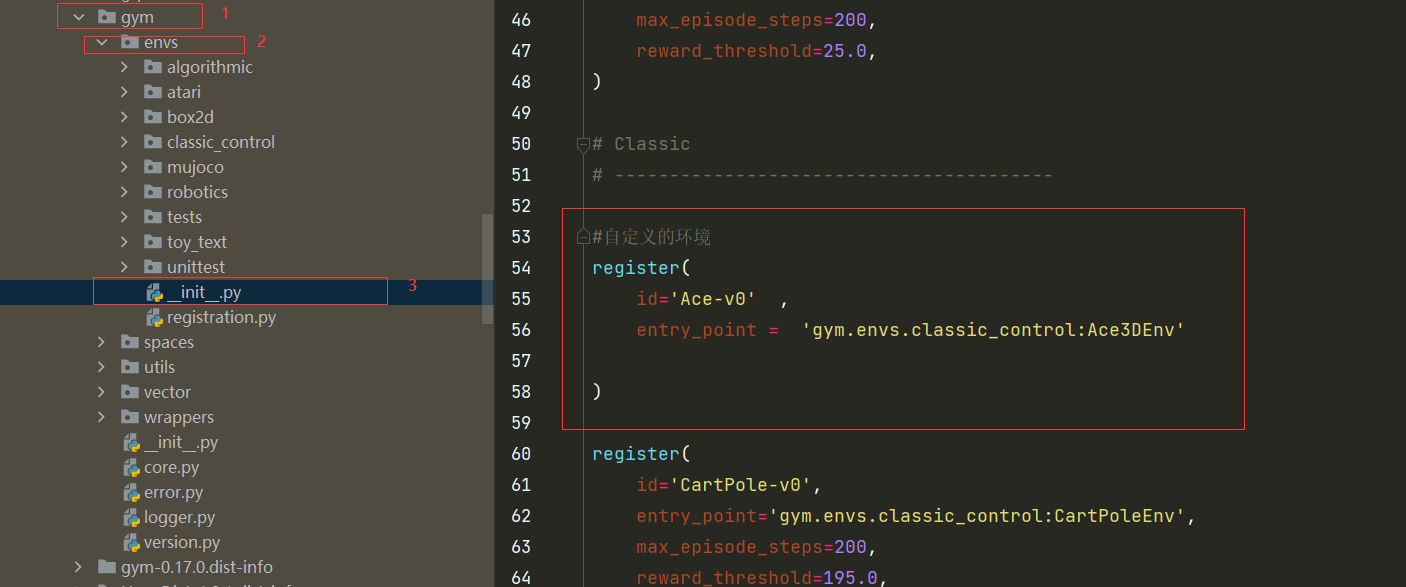
Step2:注册
在envs目录下,包含一个初始化函数__init__.py,当访问envs类时,会通过这个初始化函数自动注册各环境,因此需要在__init__环境中注册我们定义的环境,给出其调用名“ID”以及此“ID”对应的类。
在envs/init.py内的#Classic分类下,插入注册语句:
register(
id='Ace-v0', #此部分为环境调用的ID,可自由设定,与算法中调用一致即可。
entry_point='gym.envs.classic_control:AceEnv', #此部分为环境的类,注意:AceEnv是ace.py中定义的类,并不是文件名。
)
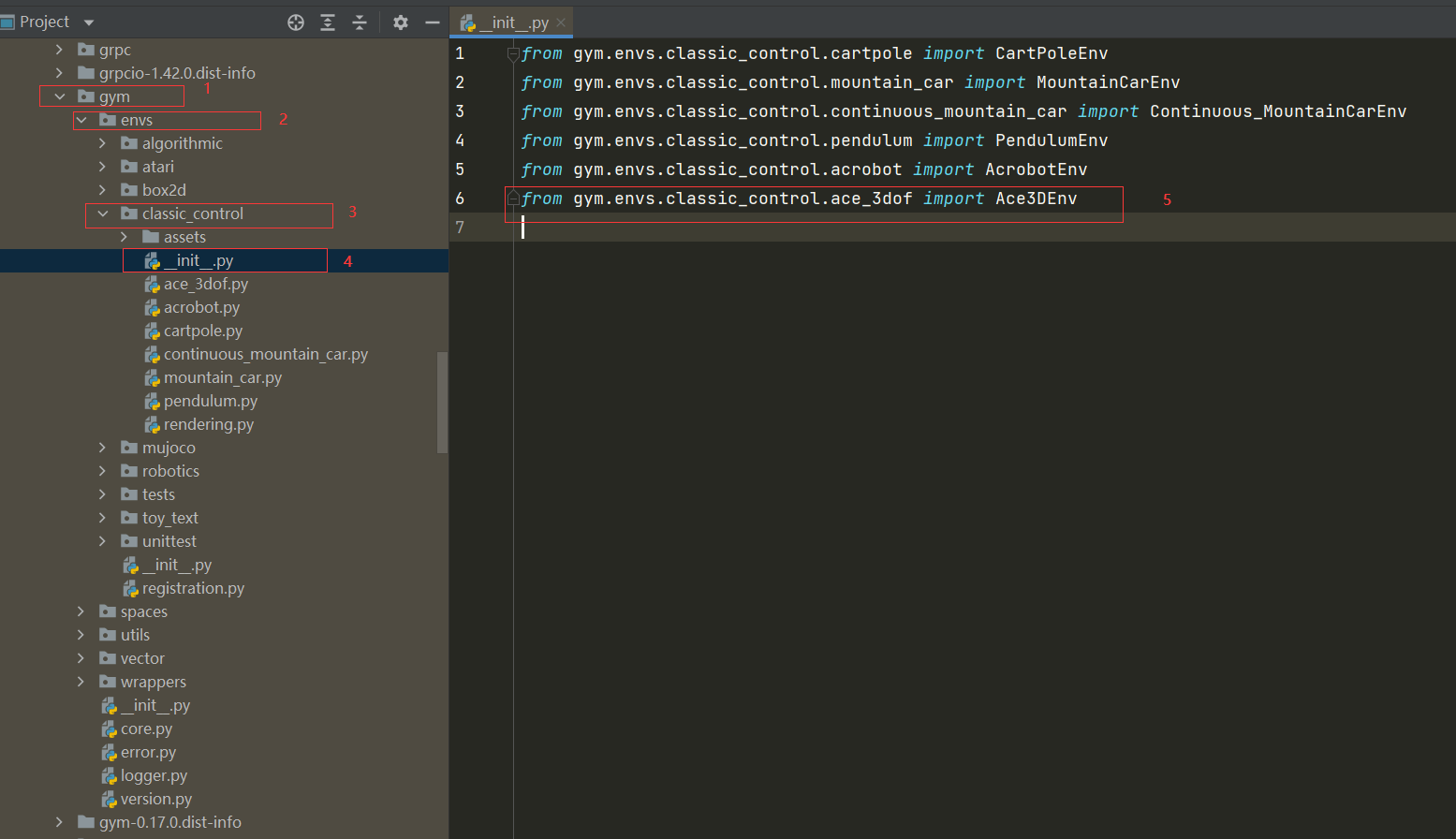
Step3: 引入环境
在envs/classic_control/init.py内,加入引用ace环境的语句
注意这里的文件名和文件里面类的名字要和Step1相一致
from gym.envs.classic_control.ace import AceEnv
Step4:在算法中进行调用
env = gym.make('Ace-v0')
配置小雅环境踩坑经历
主要是anaconda虚拟环境的使用
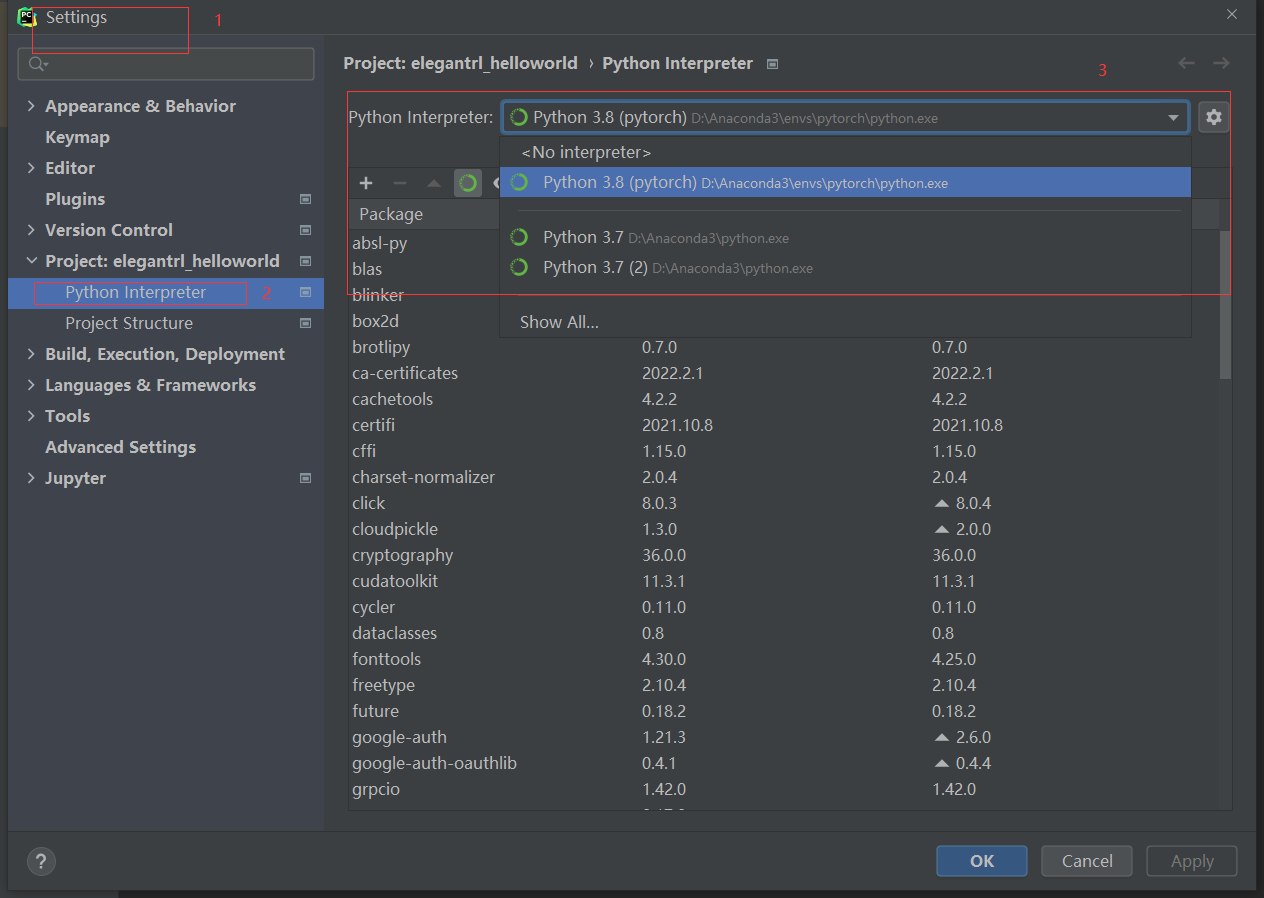
问题1 ,在anaconda中新建虚拟环境,但是在PyCharm中不显示
打开configurations
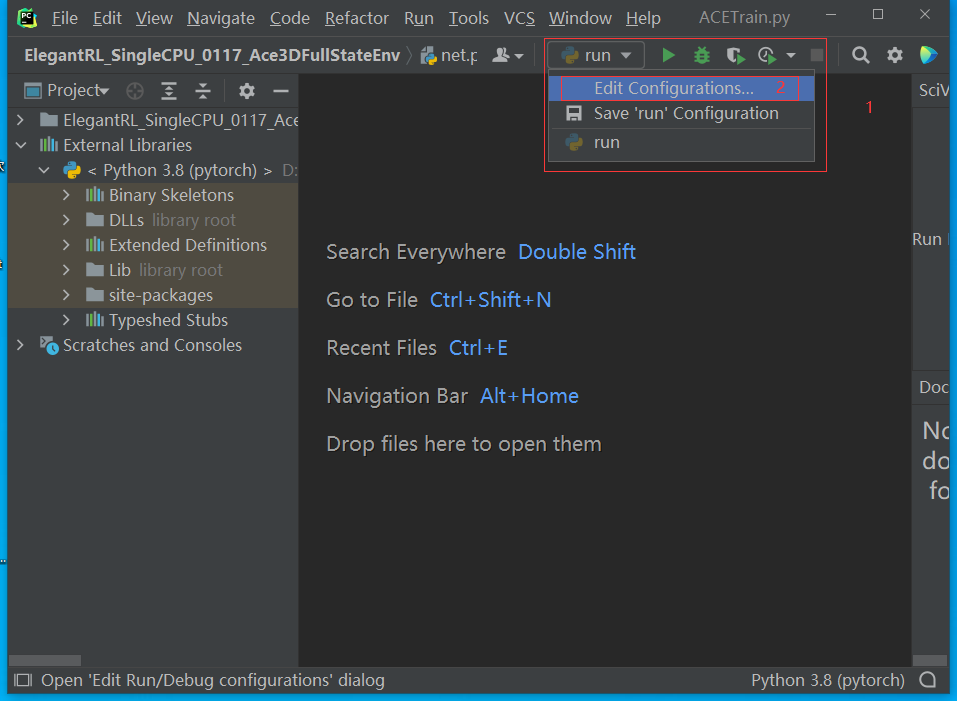
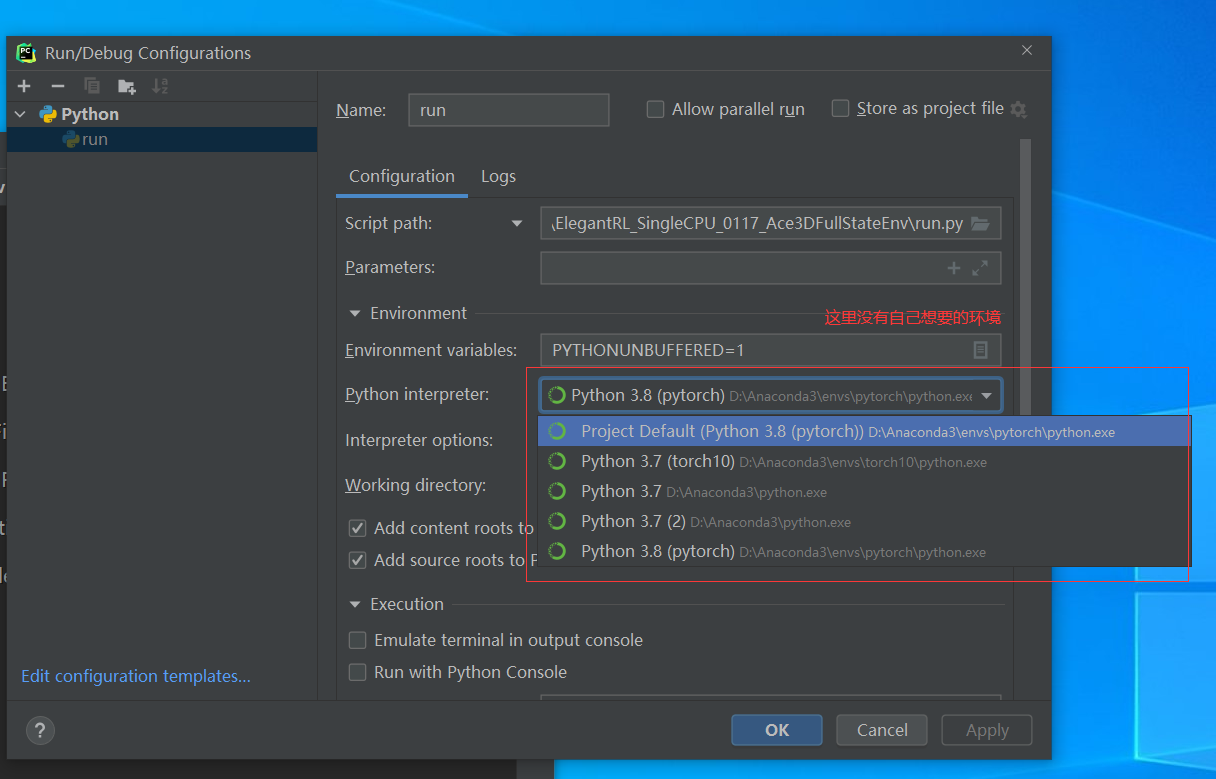
解决方法 新建项目
新建一个项目,这时候会显示新的python解释器,然后让他 make avaliabvle to all project ,也就是下面第二小个图中的选项要勾选上。
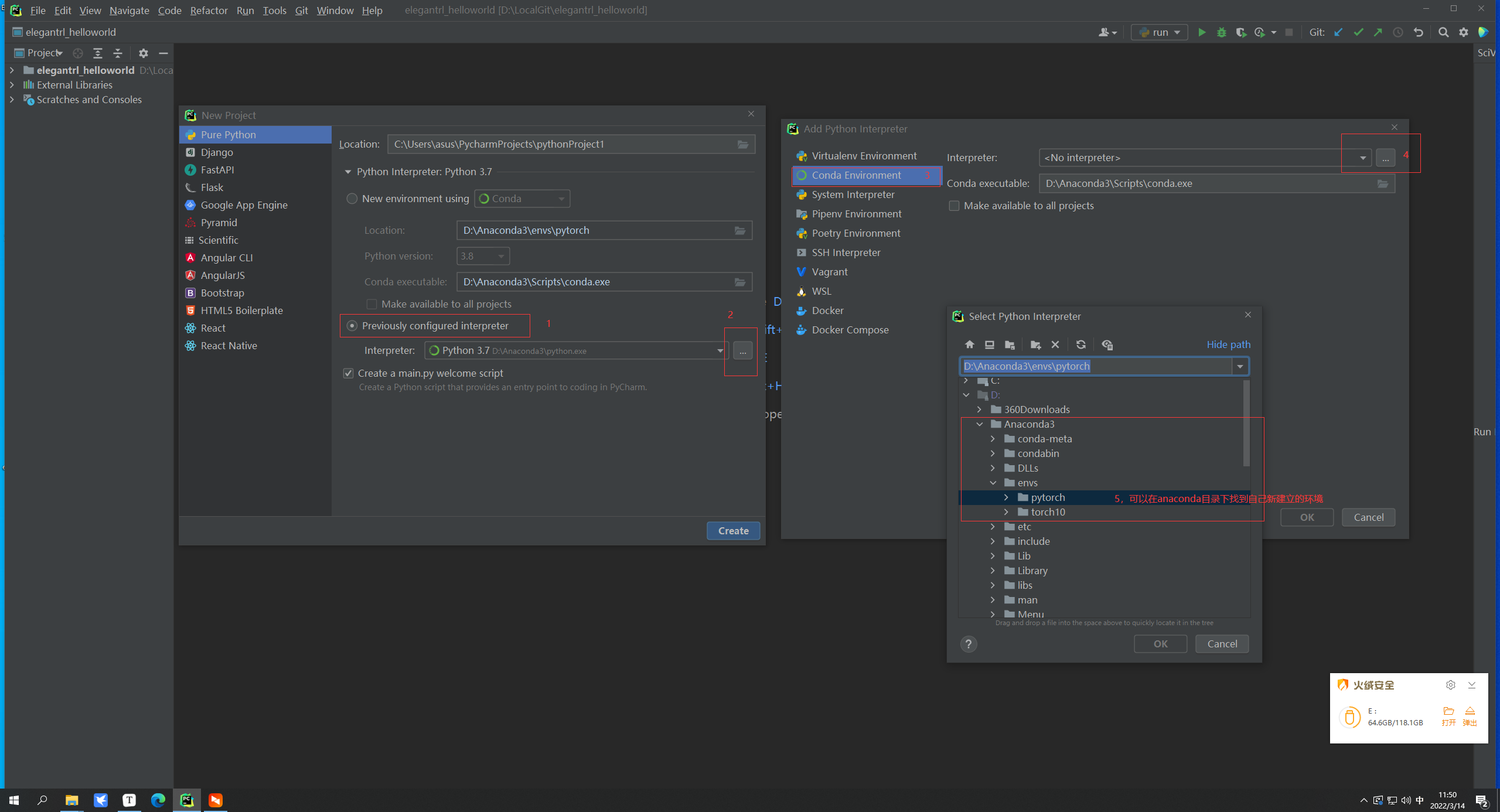
然后关闭所有项目,再次进入,就会发现能够找到新建立的环境,使用新的解释器
问题2 PyCharm项目中的 External Libraries 没有变成新环境
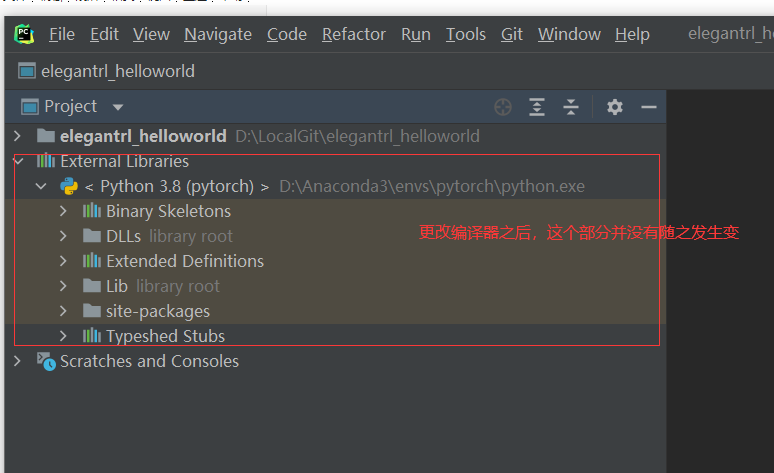
解决方法
File-Setting - Project Interpreter 选择新建立的环境