目录
- 1 付宇鹏,邓向阳,何明,等. 基于强化学习的固定翼飞机姿态控制方法研究_付宇鹏[J]. 控制与决策, : 1-6.
- 2 马一鸣. 基于强化学习的前馈控制器[D]. 华北电力大学(北京), 2021.
- 3廖拥文. 神经网络控制器在火电厂中的应用[D]. 华北电力大学(北京), 2021.
- 4王奎霖. 基于端到端学习的自动驾驶决策算法研究[D]. 吉林大学, 2021.
- 5 李岸荞,王志成,古勇,等. 基于深度强化学习的四足机器人后空翻动作生成方法[J]. 导航定位与授时, 2021, 8(6): 35-42.
- 乔通,周洲,程鑫,等. 基于Q-学习的底盘测功机自适应PID控制模型[J]. 计算机技术与发展, 2022, 32(5): 117-122.
- 郭可建,林晓波,郝程鹏,等. 基于神经网络状态估计器的高速AUV强化学习控制[J]. 水下无人系统学报, 2022, 30(2): 147-156.
- 欧阳名三,冯舒心. 稀疏奖励环境中的分层强化学习[J]. 佳木斯大学学报(自然科学版), 2022, 40(2): 54-57.
- 张鹏鹏,魏长赟,张恺睿,等. 旋翼无人机在移动平台降落的控制参数自学习调节方法_张鹏鹏[J]. 智能系统学报, 2022, (5): 1-9.
1 付宇鹏,邓向阳,何明,等. 基于强化学习的固定翼飞机姿态控制方法研究_付宇鹏[J]. 控制与决策, : 1-6.
输入输出
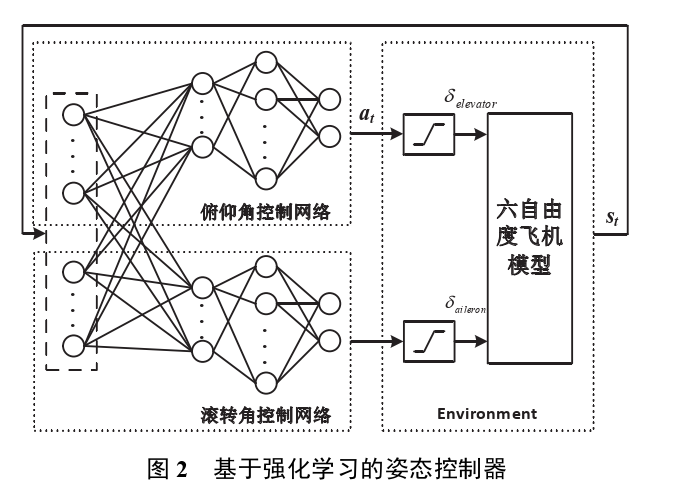
控制器输入为飞机纵向和横向状态变量以及姿态误差,输出升降舵和副翼偏转角度指令,实现不同初始条件下飞机姿态角快速响应
模型结构
分立的神经网络模型,提高了算法收敛效率
本设计参考传统 PID 控制器的实现方法,控制器同样将动作网络分为俯仰角和滚转角控制网络。不同之处在于,各通道输出指令本质上是通过气动力和气动力矩反映在各通道状态上,从而影响气动模型的状态转移函数,造成通道间的耦合,而不同通道的动作网络通过共享状态变量,经过一层感知机处理,实现对当前状态特征提取,再经过动作网络实现任意姿态下响应曲线的优化。
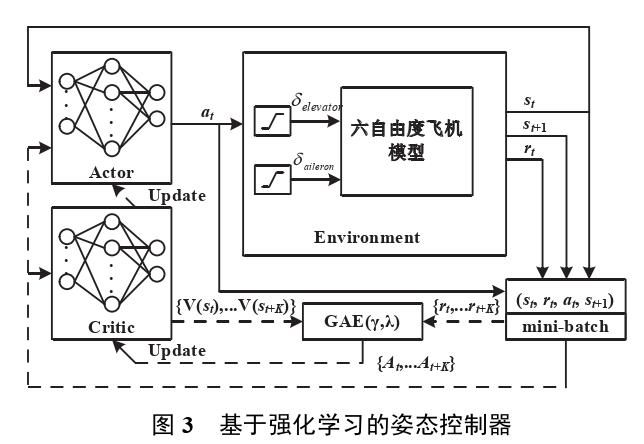
强化学习方法——ppo
奖励函数设置
在不同姿态角误差条件下,通过设置合理的奖励函数能够引导智能体到达期望的目标姿态角,例如可以要求滚转角和俯仰角满足最短时间或按照特定的响应曲线进行。本文模仿 PID 控制器的响应函数,将两通道的奖励函数分别设置
实现平台 训练技巧
采用 OpenAI gym 平台,飞机空气动力学模型基于 JSBSim 开源平台 F-16 气动模型, 姿态角初始化均值为 0°,初始空速在 200m/s,归一化方差均为 0.1,随着迭代次数增大方差逐渐增大,使智能体逐步探索状态空间,同时学习率逐步降低,避免梯度过大
效果
根据李雅普诺夫稳定性理论[21],利用神经网络拟合动力学系统渐进收敛,图 4 中系统在初始状态大幅度扰动情况下,控制系统均能保证姿态角恢复并实现零误差,具有稳定性。
为了验证控制器工作性能,本节进行了传统 PID控制器(PID control)与强化学习控制器(RLNNcontrol)跟踪目标姿态角时的响应对比。
2 马一鸣. 基于强化学习的前馈控制器[D]. 华北电力大学(北京), 2021.
DQN DDPG
强化学习算法拥有的无模型特点带来的通用性与自趋优,自学习的能力,非常
适合进行非线性系统优化控制的研究。本文研究强化学习算法的应用问题,将经典
过程控制算法及智能控制算法与强化学习相结合,设计相应的解决方案,为强化学
习算法的应用提供了一个新的思路,实现无模型的非线性系统自适应控制。
再次,研究利用前馈结构降低强化学习训练难度。通过前馈反馈结构,将强化
学习作为外挂优化器,保留原过程控制系统的反馈回路。从而将控制问题简化为优
化问题,加快强化学习收敛速度,通过与传统的强化学习方法对比,设计仿真实验
证明该方法的优越性。同时,考虑过程控制中存在的时变特性问题,传统的强化学
习算法会存在适应新对象的过渡问题。针对这一-问题,本文所述方法中反馈回路的存在会提高控制系统的鲁棒性,同样设计仿真实验验证时变对象本方法的有效性。
实现模型
钟摆非线性系统
强化学习能够实现模型理论最优的控制策略,但当模型是时变对象时,例如被
控对象的增益发生改变时,强化学习控制器需要学习新的控制策略来适应对象特性
的变化,这是存在一个学习过程的。然而,纯粹的强化学习算法,其训练过程需要
大量的数据,从而需要很长- -段时间来自趋优的学习到最优策略。因此,强化学习
算法独立用于时变对象过程控制时,收敛速度慢,鲁棒性不能得到保障。
强化学习自适应补偿控制系统结构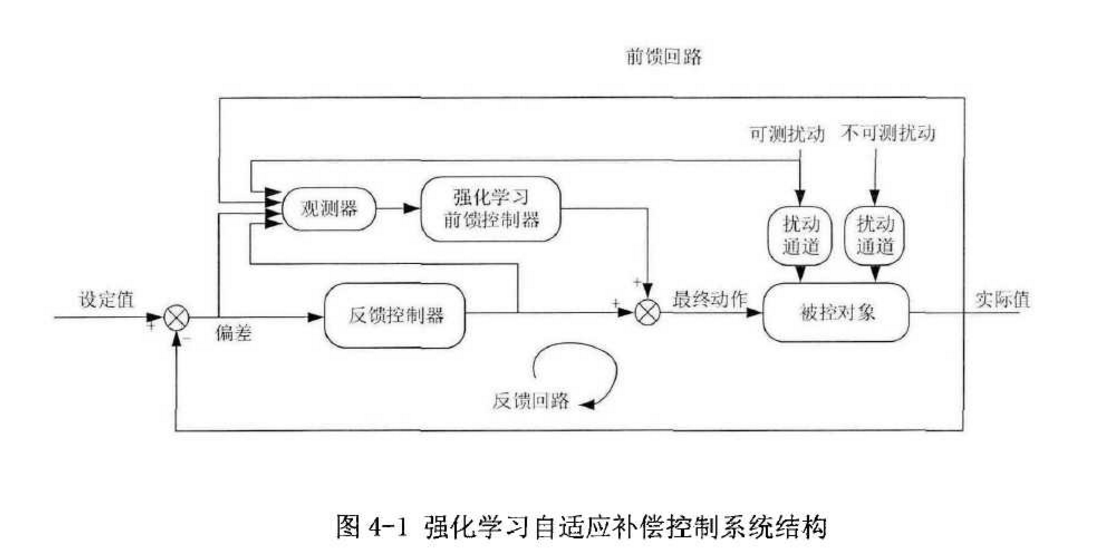
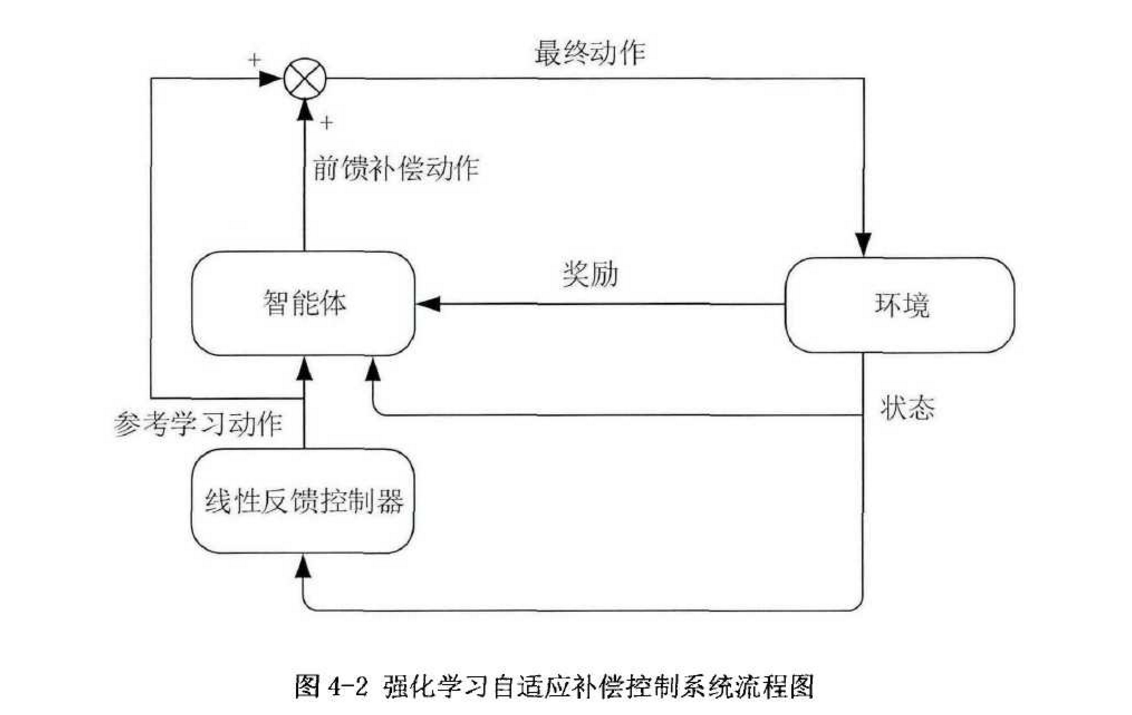
水箱液位控制系统
无模型 网络监督
3廖拥文. 神经网络控制器在火电厂中的应用[D]. 华北电力大学(北京), 2021.
基于神经网络的逆控制器
设计了基于Elman神经网络的预估器。这种控制方法克服了实际工业现场时变和非线性的特性,有着良好的抗干扰能力,同时也解决了传统内模控制中逆控制器不易得到的问题,也不需要进行复杂的控制器参数整定,简单易行。将其运用于实际二号高加水位系统中,取得了良好的效果。
神经网络逆控制基本思想是采集被控对象的输入和输出数据,通过离线训练构造一个精确的神经网络逆模型作为控制器,从而获得良好的控制效果[24]。这种逆控制实际上是一种开环控制方案,避免了反馈控制带来的不稳定问题,并能获得更好的动态性能,在模型准确的情况下,这种逆控制器可以被视作-一种理想控制器,在不考虑限幅和限速的条件下将使被控量快速达到设定值。
针对上述方法的不足,本章在Levenberg-Marquard-BP算法的基础上,提出了一种新的神经网络逆控制方案,只需要根据输入和输出调整控制器参数,而不需要任何模型的先验知识,成功地防止了对象变化时控制质量恶化。为了提高大迟延对象的控制性能,设计了一个ELMAN神经网络作为预测器来预测r后的被控变量,其中r是对象的迟延。以简单的一阶对象为例,由于y(k+ 1)只与y(k)和u(k-T+1)有关,因此其控制框图如下:
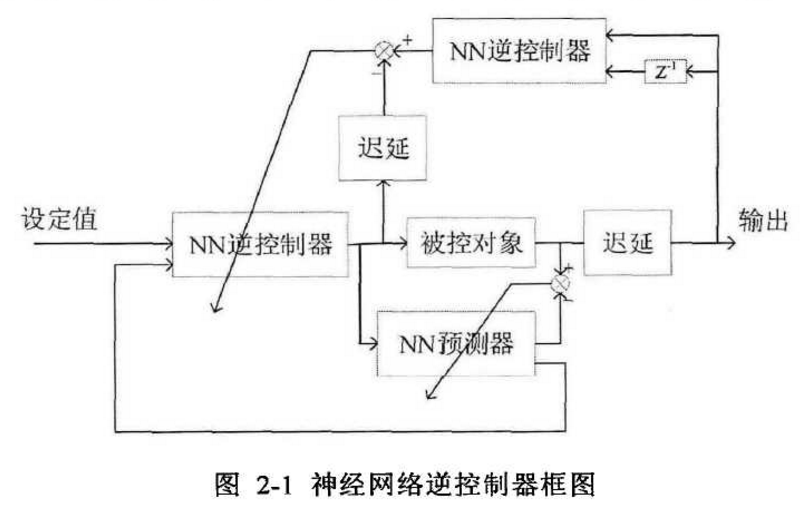
LM算法需要计算nXn矩阵H,只适用于小规模的神经网络,难以支撑对结构复杂的如卷积神经网络进行训练。考虑到本章使用的神经网络结构简单,权值数量也较少,LMBP算法能够满足我们的要求,帮助实现逆控制器的在线更新通过这种在线更新机制,神经网络逆控制器能在一定程度上克服模型时变造成的控制效果劣化,使控制器有了良好的鲁棒性。
因此,本章考虑使用ELMAN神经网络来逼近函数f,ELMAN网络是最简单的动态神经网络之一,与常规的BP神经网络不同,BP神经网络只有 前向计算过程,网络结构中并没有反馈环节,因此,过去时刻的信息只能通过增加输入端来输入网络之中,被控对象阶数越高,神经网络的输入就越多,因此网络规模变大,复杂度变高;为了解决动态系统辨识问题,
基于强化学习的PID控制器
另一种控制方案是基于强化学习的PID控制器,将强化学习算法与PID控制相结合,采用强化学习领域中的A3C算法框架,离线对动作网络进行训练,用动作网络来动态调节PID参数,得到基于强化学习的PID控制器。这种控制方案对传统的PID控制算法做出了改进,用动作网络对PID参数进行实时动态的调节,经过离线训练,动作网络学习到了对一类对象的PID参数调节规律, 因此有着较好的鲁棒性,同时在一定程度上简化了控制器的设计。
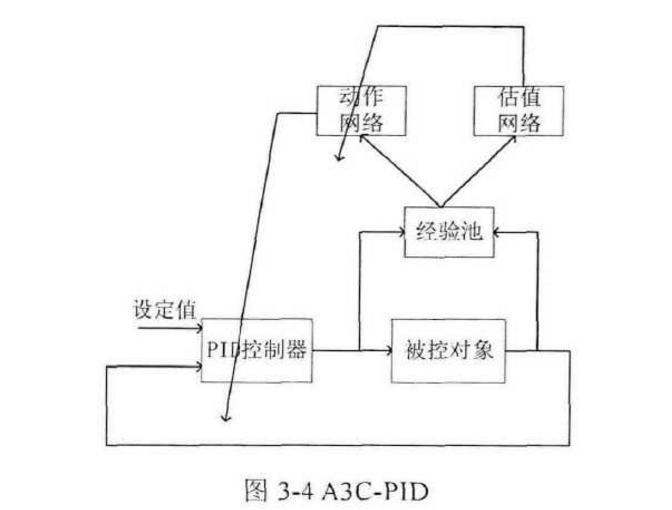
环境,MATLAB可以用simulink搭建环境,通过simulink与m文件之间的交互强化学习训练,减小了设计难度。本文之后将用MATLAB来进行仿真和编程工作。
4王奎霖. 基于端到端学习的自动驾驶决策算法研究[D]. 吉林大学, 2021.
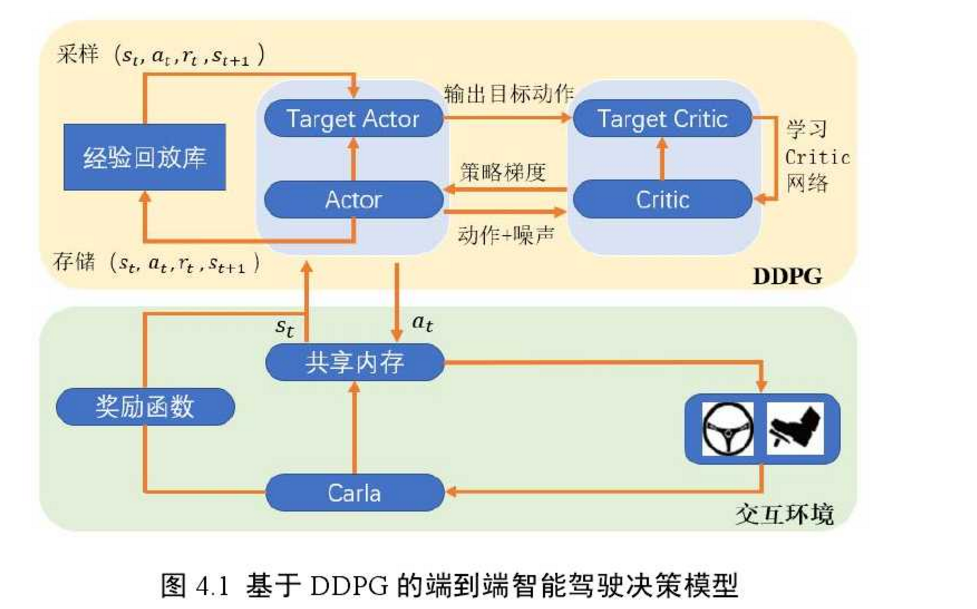
深度学系 端到端 车速转弯决策模型
端到端驾驶决策模型在新的融合特征基础上,选择车辆下一时刻应采取的动作(方向盘转角与车速)。
特征供下层网络学习。在端到端驾驶决策模型中,驾驶环境视觉特征与车辆纵向动作序列特征(车速)通过特征融合层进行融合。特征融合时需保证两组特征向量具有相同的尺寸。
训练过程
Comma.ai 数据集
在本章中采用Nadam[在本章中采用Nadam[61]([61](Nesterov-accelerated Adaptive Moment Estimation)算法作为神经网络模型的优化算法
基于控制障碍函数的强化学习控制算法
5 李岸荞,王志成,古勇,等. 基于深度强化学习的四足机器人后空翻动作生成方法[J]. 导航定位与授时, 2021, 8(6): 35-42.
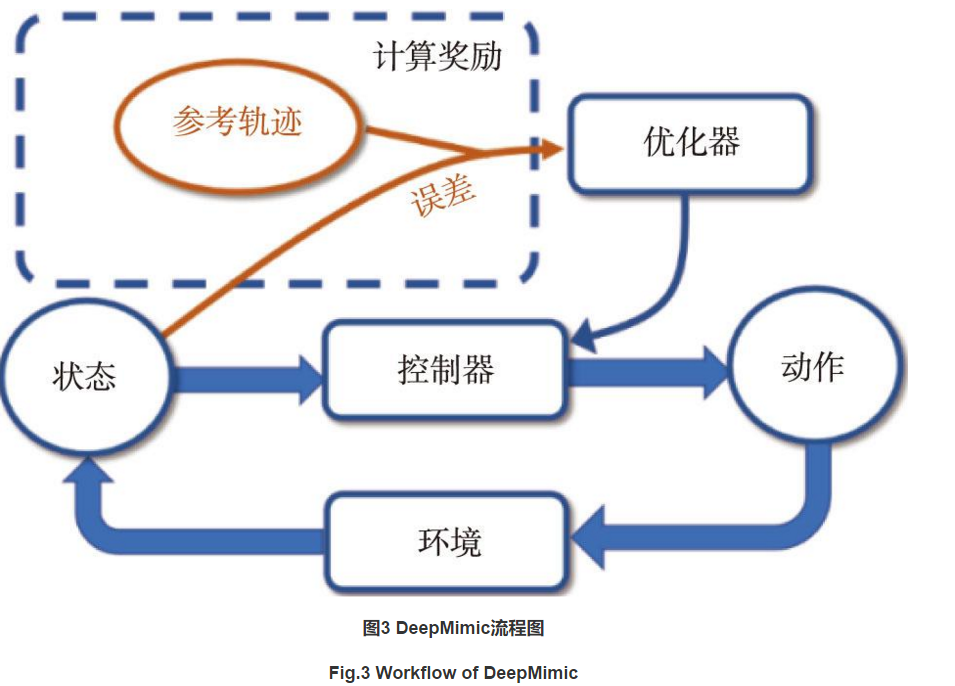
DeepMimic是一种基于模仿学习思想构造的深度强化学习框架[14],其使用的优化算法仍然是PPO算
在DeepMimic框架中,根据设置的奖励函数,神经网络的目标是缩小智能体的当前运动轨迹和目标运动轨迹的差值。如图3所示,在每一步动作之后,参考轨迹和当前状态的差值被输入到优化器中,优化器对控制器的优化目标为使智能体每一次完成动作后都与参考轨迹非常接近。
神经网络的输入为65维,输出为24维。
神经网络的输出选择为12维目标位置和12维目标速度信息,底层关节PD控制器接收到指令之后输出力矩信息。
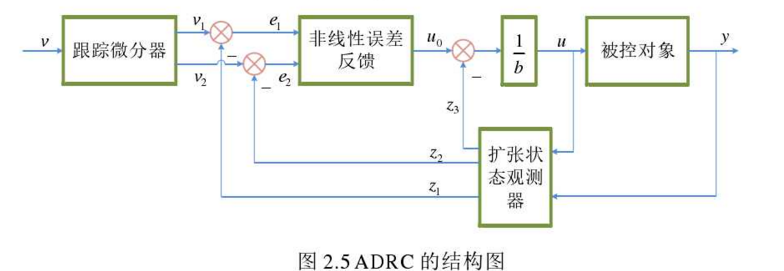
乔通,周洲,程鑫,等. 基于Q-学习的底盘测功机自适应PID控制模型[J]. 计算机技术与发展, 2022, 32(5): 117-122.
该文提出了一种基于Q学习算法的PID控制器,用于调整底盘测功机的扭矩输出,整个控制器的结构如图1所示。系统的直接控制由一个传统的PID完成,而参数的自适应调整是基于Q-学习算法在训练过程中获得的Q表,传统的PID实现输入电压的调节
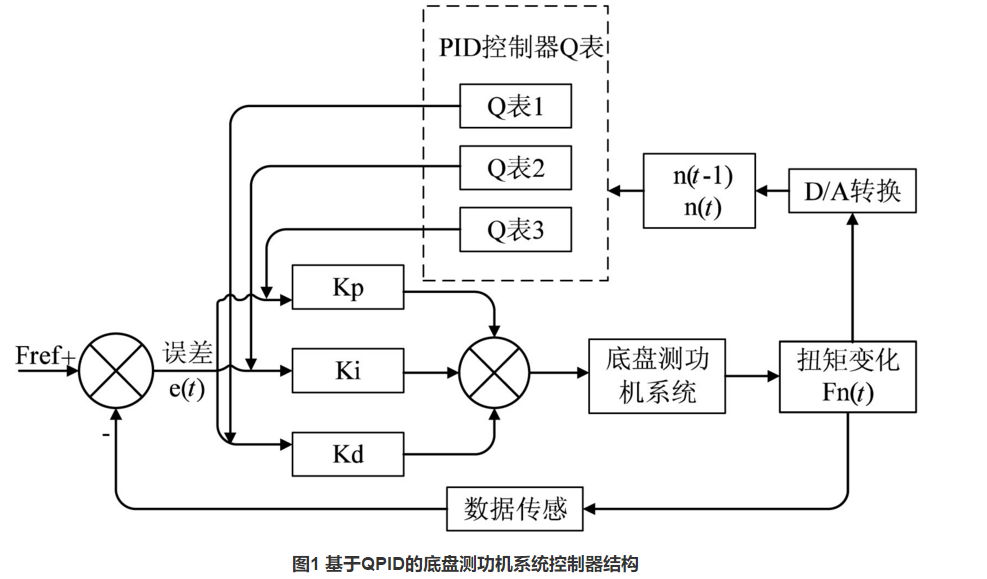
郭可建,林晓波,郝程鹏,等. 基于神经网络状态估计器的高速AUV强化学习控制[J]. 水下无人系统学报, 2022, 30(2): 147-156.
在AUV的控制过程中,由于位置环和姿态环的控制响应时间明显不同,因此针对位置和姿态分别设计了一个强化学习控制器,采用了强化学习中经典的DDPG,如图4所示结构。
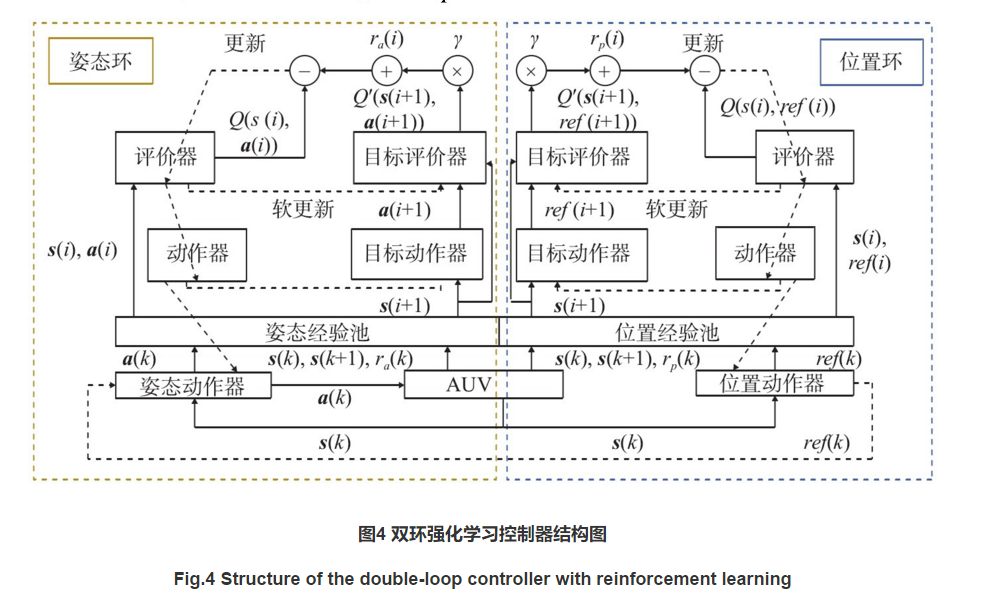
欧阳名三,冯舒心. 稀疏奖励环境中的分层强化学习[J]. 佳木斯大学学报(自然科学版), 2022, 40(2): 54-57.
从图4中可以看到,由于稀疏奖励问题,常规的RL算法会困在钥匙区域,尽管设置了较高的探索率,但智能体并没有动机去探索其他区域以到达锁的位置,所以只能得到钥匙的奖励回报,而DPC-HRL和Kmeans-HRL的分层学习结构都能在内部生成常规的奖励反馈可以得到最高的奖励回报。图5的任务平均成功率显示了DPC-HRL和Kmeans-HRL都能有效的解决稀疏奖励问题,完成路径导航的任务,且与Kmeans-HRL算法相比,提出的DPC-HRL算法可更快快收敛,但在初期的学习效率较低。
张鹏鹏,魏长赟,张恺睿,等. 旋翼无人机在移动平台降落的控制参数自学习调节方法_张鹏鹏[J]. 智能系统学报, 2022, (5): 1-9.
本文提出的方法将强化学习算法应用在 PID 控制算法的上层,方法的结构如图 3 所示,有两个控制模块,左边框为强化学习模块,右边框为 PID 控制模块,强化学习的输入状态由三个方向上的位置组成,输出 a 为 PID 控制模块的参数Pk ,Ik ,Dk 。
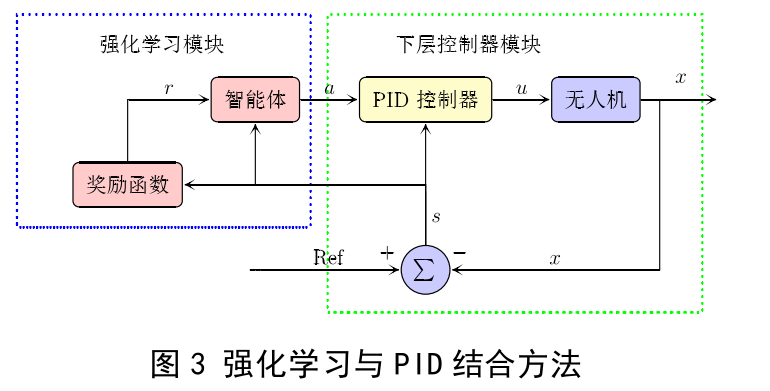
PID 模块和强化学习模块之间的通讯使用机器人操作系统(Robot Operation System)
标签:控制器,编程,PID,算法,学习,神经网络,空战,强化 From: https://www.cnblogs.com/zuti666/p/18092813