使用线程池的好处
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
ThreadPoolExecutor 分析
ThreadPoolExecutor 继承 AbstractExecutorService,也就是实现了 ExecutorService 接口
几个重要的字段

其中 ctl 字段包含两部分信息:
- 线程池的运行状态(runState)
- 线程池内有效线程的数量(workCount)
高三位保存 runState,低 29 位保存 workCount
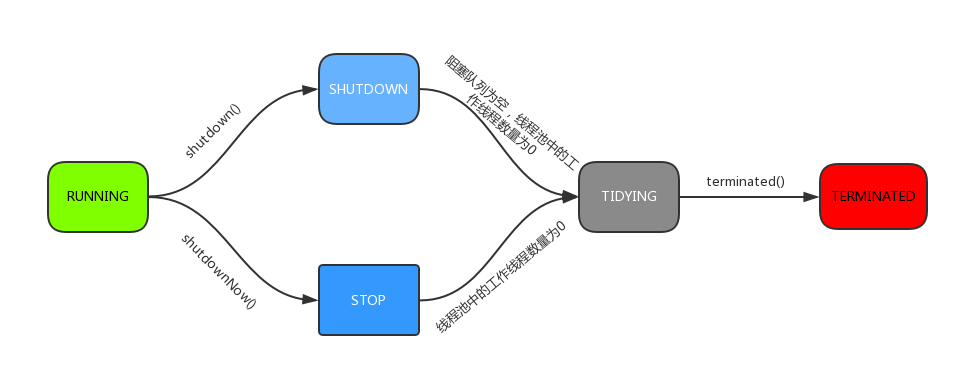
线程池共有五种状态:
- RUNNING
- SHUTDOWN
不接受新任务,可以继续处理阻塞队列里面的任务,当阻塞队列为空时,会减少工作线程。
- STOP
不接受新任务,也不会处理队列中的任务,会中断正在处理任务的线程。
- TIDYING
所有任务都终止,workCount = 0,进入该状态后会调用 terminate() 方法进入 TERMINATED 状态。
- TERMINATED
线程池状态的转换过程:
ThreadPoolExecutor 构造方法

- corePoolSize
核心线程数,当提交任务时,如果 workCount 小于核心线程数则创建线程来处理任务;当 workCount 大于核心线程数,小于最大线程数时,将任务放到 workQueue 队列中等待执行;当队列满了,workCount 大于核心线程数并且小于最大线程数,此时创建线程来处理任务,大于核心线程数以外的线程超过 keepAliveTime 后还没有任务处理则回收该线程;如果 队列已满且workCount 大于最大线程数,此时的用 handle 拒绝策略拒绝任务。
- maximumPoolSize
- keepAliveTime
- unit
- workQueue
- threadFactory
- handler
Execute 方法

主要的代码逻辑的流程为:

addWorker 方法
- 核心线程数判断场景:判断当前工作线程数是否小于核心线程数,如果是则添加 woker 对象,并执行任务
- 最大线程数判断场景:判断当前工作线程是否小于最大线程数,如果是则添加 worker 对象,并执行任务
Worker 类
Worker 类继承了 AQS,并且实现了 Runnable 接口。其中 firstTask 表示初始化传入的任务,thread 为初始化通过 threadFactory 创建出来的线程。因为创建线程的时候 将当前实现了 Runnable 接口的类Worker 传入,因此线程启动后,将执行 Worker 对象的 run 方法。
问题:为什么 Woker 需要继承 AQS,直接使用 ReentrantLock 可以吗?
-
lock 方法一旦获取了独占锁,表示当前线程正在执行任务中;
-
如果正在执行任务,则不应该中断线程;
-
如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断;
-
线程池在执行shutdown方法或t ryTerminate 方法时会调用 interruptIdleWorkers 方法来中断空闲的线程,interruptIdleWorkers 方法会使用 tryLock 方法来判断线程池中的线程是否是空闲状态;
-
之所以设置为不可重入,是因为我们不希望任务在调用像 setCorePoolSize 这样的线程池控制方法时重新获取锁。如果使用ReentrantLock,它是可重入的,这样如果在任务中调用了如 setCorePoolSize 这类线程池控制的方法,会中断正在运行的线程。
以下是调用 interruptIdleWorkers 的方法

所以,Worker继承自AQS,用于判断线程是否空闲以及是否可以被中断。主要是看 tryAcquire 方法的实现。

runWorker 方法
总结一下runWorker方法的执行过程:
- while循环不断地通过getTask()方法获取任务;
- getTask()方法从阻塞队列中取任务;
- 如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态;
- 调用
task.run()执行任务; - 如果task为null则跳出循环,执行processWorkerExit()方法;
- runWorker方法执行完毕,也代表着Worker中的run方法执行完毕,销毁线程。
这里的beforeExecute方法和afterExecute方法在ThreadPoolExecutor类中是空的,留给子类来实现。
completedAbruptly变量来表示在执行任务过程中是否出现了异常,在processWorkerExit方法中会对该变量的值进行判断。

getTask 方法
getTask 方法是在线程启动执行 run 方法,run 方法里面调用 Worker 类的 runWorker 方法,runWorker 方法里面线程不断的执行任务,任务的来源就是从 getTask 方法中获取。
首先会进行线程池状态判断,如果状态 >= SHUTDOWN,也就是非 Running 状态,需要进行一下判断:
- rs >= STOP,表示线程池正在 STOP(STOP 状态的线程池会中断正在处理任务的线程,不管队列里是否还有任务)
- 阻塞队列为空,表示线程池执行了 SHUTDOWN (这个状态的线程池会继续处理阻塞队列的任务)
需要注意的是 keepAliveTime 在这个方法里面起作用,当工作线程数大于核心线程数以后就需要进行超时控制。超时控制是通过阻塞队列 workQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)方法控制,核心线程数是通过 workQueue.take 一直阻塞获取任务。

processWorkerExit方法
如果上述 getTask() 方法返回为 null,则会进入该方法。该方法主要做了这么几件事:
- 将当前工作线程完成的任务数添加至线程池总得完成任务数里面
- 从 workers 列表里面移除当前工作线程
- 调用 tryTerminate() 方法
- 判断工作线程是否抛出异常,如果是直接调用 addWorker() 方法,如果不是则判断当前工作线程数是否小于核心线程数,如果是则调用 addWorker() 方法
tryTerminate 方法
主要作用就是根据线程池的状态判断是否结束线程池
当前线程池的状态为以下几种情况时,直接返回:
- RUNNING,因为还在运行中,不能停止;
- TIDYING或TERMINATED,因为线程池中已经没有正在运行的线程了;
- SHUTDOWN并且等待队列非空,这时要执行完workQueue中的task;
当线程池的状态为 SHUTDOWN 并且工作线程数不为 0,且阻塞队列里面为空的时候就会调用interruptIdleWorkers(ONLY_ONE)

shutdown 方法
shutdown 方法要将线程池切换到 SHUTDOWN 状态,并调用 interruptIdleWorkers 方法请求中断所有空闲的 worker ,最后调用 tryTerminate 尝试结束线程池。
注意:
- getTask()方法没有加锁,run 方法里面加锁了,是为了线程在 getTask()方法获取 take 任务阻塞的时候,可以通过线程中断机制进行中断。
- 在 shutdown 方法中,中断机制又是通过 interruptIdleWorkers 方法进行的,遍历所有工作线程,找到空闲线程,执行中断 interrupt()方法。

interruptIdleWorkers 方法
遍历所有工作线程,找到第一个空闲线程,也就是 w.tryLock()方法获取到锁的线程就代表该线程没有在执行任务

shutdownNow 方法
和 showdown 方法类似,差异点在于:
- 设置线程池状态为 stop;
- 中断所有工作线程,无论是否在执行任务;
- 取出阻塞队列里面未执行的任务并返回。

线程池的监控
动态线程池,以及线程池监控的实现,就是通过线程池提供的内置方法来实现的:
- getTaskCount:线程池已经执行和未执行的任务总数;
- getCompletedTaskCount:线程池已经执行完了的任务数;
- getLargestPoolSize:线程池曾经创建过得最大线程数;
- getPoolSize:线程池当前的线程数量;
- getActiveCount:当前线程池正在执行任务的线程数量。
同时,ThreadPoolExecutor 提供了多个子类实现的方法,比如 beforeExecute 方法, afterExecute 方法以及 terminated 方法,可以用于任务执行耗时统计。
补充内容-线程状态
