4. 相关概念和术语
在CUDA编程模型中,两个主要的硬件设备分别为CPU和GPU,它们都有自己专用的内存区域。
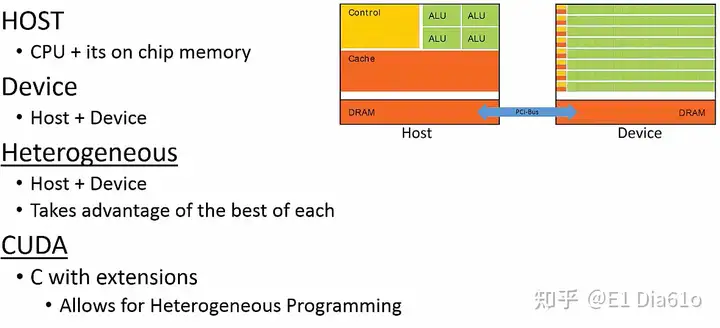
I 主机、设备和异构并行编程
- CPU连同它的计算机RAM被称为主机(Host)。CPU由于其结构特点非常适合运行串行程序。但CPU的问题是,如果其运行至一部分需要大规模并行运算的代码时,这部分程序很可能会导致程序流程出现瓶颈。因为CPU并非为大规模并行吞吐量而设计的。
- GPU连同它的专用DRAM被称为设备(Device)。由于GPU擅长运行带有并行运算的程序部分,将程序中带有大规模并行计算的部分由CPU转移到GPU上运行是更为合理的。
- 一起使用主机和设备称为异构并行编程 (heterogeneous parallel programming)。这就是CUDA发挥作用的部分。
- CUDA(Compute Unified Device Architecture)是专门为NVIDIA GPU设计的异构并行编程语言。CUDA 只是在C语言的基础上增加了一组允许Host和Device一起工作的扩展部分。
在应用CUDA编程时,像大部分在CPU上运行的软件一样,CUDA程序的主要部分还是由Host端控制。但每当遇到一段可以大规模并行的代码时,程序会将这部分代码的执行从Host端传递到Device端。Host端和Device端通过PCI Express总线进行通信。PCI Express总线的数据传输相对于Host和Device非常慢,因此在Host端和Device端之间数据交换的成本非常高。这就是只让大规模并行的部分在Device端执行的原因。
II 线程
- 核函数作为一组并行的线程(Threads)执行。
- 为了充分利用GPU上的大量CUDA核,我们想要执行核函数时同样有大量的线程。GPU的设计能让执行每个核函数时能有数千甚至数百万个线程。
- CUDA线程以单指令多数据的方式执行,在一些计算机体系结构的文献中通常被称作“SIMD”(single instruction multiple data),即每个线程执行相同的指令,但作用于不同数据。但CUDA线程执行的确切方式与SIMD模型的定义略有不同,NVIDIA将他们版本的SIMD称为“SIMT”(single instruction multiple thread),即单指令多线程。了解其不同可以参考:GPU架构和CUDA简单介绍(未来继续补充)
- 线程的操作彼此独立,且不全部以相同的速率执行,尽管每个线程都在执行相同的操作,它们执行操作的数据集合都不相同,导致来自同一核函数的线程以不同的速率执行。

线程的特点
5. 线程的组织
为了组织线程与GPU上CUDA核如何匹配,CUDA有一个层次结构。层次结构分为三个级别:线程(threads)、块(blocks)和网格(grids)。
- 最低级别的层次结构为单独线程。核函数以线程集合的形式执行,每个线程映射到一个CUDA核上。
- 中间级别的层次结构称为块。当核函数被执行时,线程集被分组到一个个块中,而块映射到相应的CUDA核的集合。
- 最高级别的层次结构为网格,网格是块的集合。整个核函数被执行时,创造出一个网格,网格被映射到整个GPU和其内存。简言之,一个核函数的启动作为一个网格执行,这个网格映射到整个设备上。
综上所述,可以将线程看作块的元素,将块看作网格的元素。
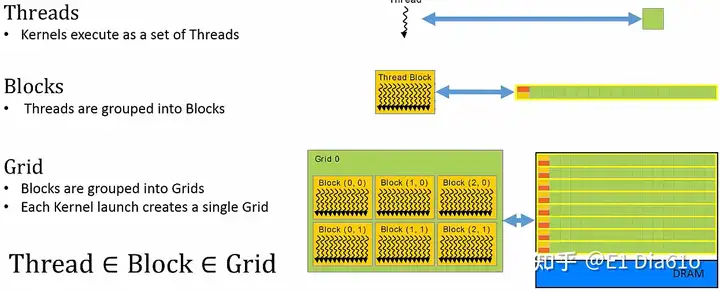
线程、块和网格
6. 网格和块的维度
每个网格由一组块组成,这些块以一维,二维或是三维结构组织在网格中。类似地,块由一组线程组成,这些线程也是以一维,二维或是三维结构组织在块中。下面的例子中,网格中有二维结构组成的6个块,每个块中有二维结构组成的12个线程。这个网格中共有72个线程。

网格和块示例
当核函数执行时,在上图这个网格对应的情况下,会有72个线程在GPU中同时运行。
二 程序模型
接下来我们了解一下CUDA程序是如何在代码中组织的。最重要的是要牢记CPU起到控制作用,即主机控制着程序的主要流程。就像C语言的程序一样,CUDA程序的流程也是由main()函数开始的。程序按正常的顺序运行,直到运行至我们想要加载到GPU上的代码部分。
将大规模并行计算的代码从CPU加载到GPU上运行是通过启动一个核函数来实现的,这个核函数在设备端作为一个网格来运行。然后对于程序的控制立即返回到主机端上。main()函数直接在核函数启动后的点继续运行 。main()函数继续执行任何串行代码,直到另一个核函数被启动。
需要注意的是,main()函数不会等待核函数运行完成。因此如果程序中需要收集一些特定的核函数运行结果,我们需要在主机端代码中创建一个明确的屏障来告诉main()函数去等待核函数运行结束后再继续运行。
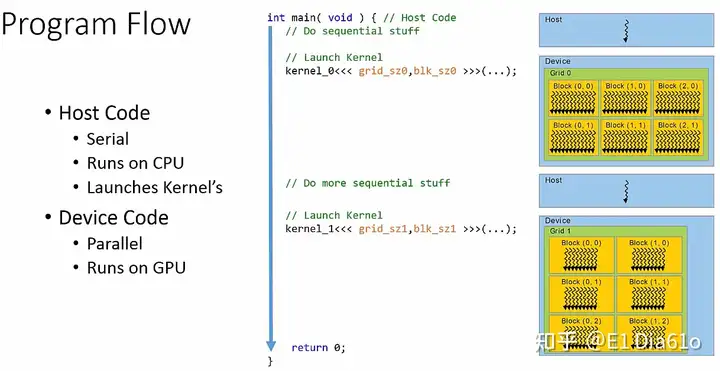
CUDA程序模型
1. 核函数的启动语法
核函数的启动就像调用任何普通C函数一样,以执行的核函数的名称开始,而传递给核函数的参数写在括号中。核函数的启动和普通函数的调用之间唯一的区别是必须指定网格和块的维度,这些信息要写在<<< >>>内。实现如下:
// Launch Kernel
kernelName<<< grid_size, block_size >>>( ... );因此在启动核函数之前,需要配置其启动参数。这些配置参数定义了网格和块的维度信息。具体实现如下:
// Block and Grid dimensions
dim3 grid_size(x, y, z);
dim3 block_size(x, y, z);表示形状的x, y, z为整数值。dim3是一个CUDA数据结构,其只是一个对应x, y, z的整数集合。grid_size和block_size是dim3数据结构的变量名称。其默认值为(1, 1, 1)。
用一个例子来演示核函数的启动语法。首先配置网格和块的尺寸,在这个例子中网格尺寸为3x2,而块的尺寸为4x3。然后使用指定的配置参数来启动核函数。
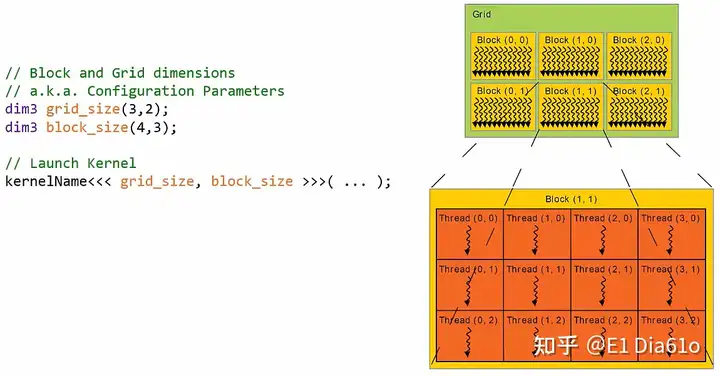
核函数启动示例
2. CUDA程序流程
I 流程细节
让我们更细致地了解CUDA程序的流程。需要注意的是,主机端和设备端有不同的内存区域。
- 为了对核函数中的任何数据进行操作,我们首先需要在设备端分配内存。
- 然后将所有相关的数据复制到设备端中分配的内存区域。在主机和设备间复制数据是驱动CUDA程序最重要和最有限制性的方面之一。
- 然后我们启动特定网格和块结构的核函数。 网格和块的结构随着启动参数的配置而被确定。
- 当我们需要从核函数的运行结果中检索数据时,需要将数据从设备端拷贝回主机端。
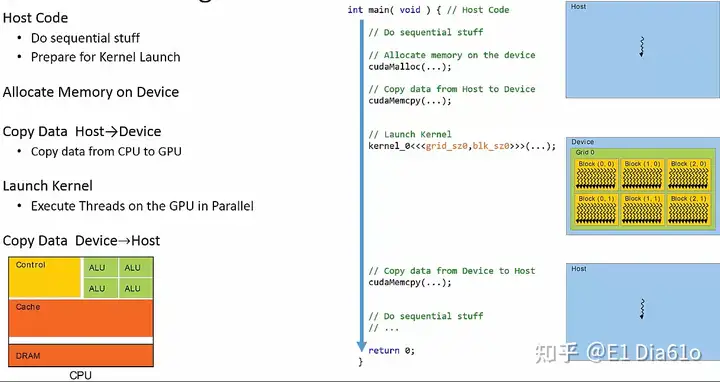
CUDA程序流程图
II 分配设备内存
CUDA中分配设备内存类似于C语言中的分配内存。在C语言中,分配内存需要调用malloc()函数;释放内存的函数是free()函数。
- 类似地,在设备端分配内存要调用
cudaMalloc()函数。cudaMalloc()函数有两个参数,第一个参数是我们想要将数据复制到的内存位置;第二个参数是分配的内存区域大小。 - 在设备端释放内存需要调用
cudaFree()函数,无需传入参数。
 C语言和CUDA中分配和释放内存函数
C语言和CUDA中分配和释放内存函数
3. 数据传递
在主机和设备端的数据传递通过调用cudaMemcpy()函数来进行。函数语法如下:
cudaMemcpy(dst, src, numBytes, direction);cudaMemcpy()函数需要传入4个参数。第一个参数dst为要将数据拷贝到的内存地址指针。第二个参数src为指向被拷贝数据来源的内存地址指针。第三个参数numBytes为以字节为单位传输数据的大小。第四个参数direction为传输数据的方向,若将数据由主机端拷贝至设备端,设置为cudaMemcpyHostToDevice; 将数据从设备端拷贝回主机端,设置为cudaMemcpyDeviceToHost。
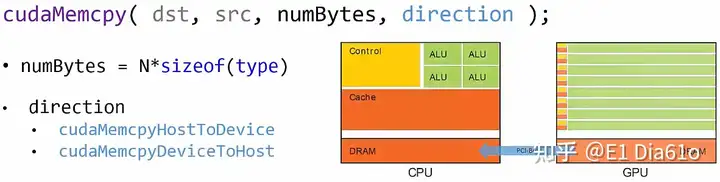 数据传递函数
数据传递函数
4. CUDA程序示例
将之前讨论的所有概念联系在一起,写一个CUDA程序作为示例。通过进入main()函数开始程序的执行,接下来定义两个指针变量h_c和d_c。由于主机和设备有单独的内存区域,在主机上端对设备端指针解引用会导致程序崩溃。为了区分主机端和设备端的变量,最好遵循特定的命名规则,如用字母h和d表示主机和设备。
 定义内存指针
定义内存指针
接下来,用cudaMalloc()函数分配设备端内存空间,同时传递两个参数:设备端内存位置的指针和分配内存大小。
 分配GPU内存空间
分配GPU内存空间
此时已经有数据储存在主机端变量中,因此假设h_c已经被初始化赋值数据。然后调用cudaMemcpy()函数去将此数据从主机内存复制到设备内存上。
 复制数据
复制数据
接下来,需要配置启动参数,以在特定的网格和块的维度下启动核函数。在例子中,设置网格和块的维度均为1x1x1。然后启动核函数,在<<< >>>内填入配置的维度参数,并传入核函数的相应参数。那么此例中的核函数作为一个包含单个线程的单个块进行执行。
 配置参数并启动核函数
配置参数并启动核函数
最后还是调用cudaMemcpy()函数将核函数的运行结果从设备端复制回主机端,并将设备端分配的内存空间释放。
 复制结果并释放内存空间
复制结果并释放内存空间
完整示例程序如下:
int main(void) {
// Declare variables
int *h_c, *d_c;
// Allocate memory on the device
cudaMalloc((void**)&d_c, sizeof(int)); // 传入的是d_c的地址,d_c也是地址类型的变量,存放的是设备端数据位置
// Copy data to device
cudaMemcpy(d_c, h_c, sizeof(int), cudaMemcpyHostToDevice);
// Configuration Parameters
dim3 grid_size(1);
dim3 block_size(1);
// Launch the Kernel
kernel<<<grid_size, block_size>>>(...);
// Copy data back to host
cudaMemcpy(h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost);
// De-allocate memory
cudaFree(d_c);
free(h_c); // h_c在cpu上
return 0;
}编辑于 2023-01-07 11:08・IP 属地黑龙江
标签:592721411,函数,主机,zhuanlan,网格,线程,CUDA,GPU,zhihu From: https://www.cnblogs.com/QuincyYi/p/17349483.html