# Overlooked Poses Actually Make Sense: Distilling Privileged Knowledge for Human Motion Prediction #paper
1. paper-info
1.1. Metadata
- Author:: [[Xiaoning Sun]], [[Qiongjie Cui]], [[Huaijiang Sun]], [[Bin Li]], [[Weiqing Li]], [[Jianfeng Lu]]
- 作者机构:: Nanjing University
- Keywords:: #HMP , #GCN
- Journal::
- Date:: [[2022/08/02]]
- 状态:: #Done
- 链接:: https://arxiv.org/abs/2208.01302v1
- 修改时间:: 2022.11.7
1.2. Abstract
Previous works on human motion prediction follow the pattern of building a mapping relation between the sequence observed and the one to be predicted. However, due to the inherent complexity of multivariate time series data, it still remains a challenge to find the extrapolation relation between motion sequences. In this paper, we present a new prediction pattern, which introduces previously overlooked human poses, to implement the prediction task from the view of interpolation. These poses exist after the predicted sequence, and form the privileged sequence. To be specific, we first propose an InTerPolation learning Network (ITP-Network) that encodes both the observed sequence and the privileged sequence to interpolate the in-between predicted sequence, wherein the embedded Privileged-sequence-Encoder (Priv-Encoder) learns the privileged knowledge (PK) simultaneously. Then, we propose a Final Prediction Network (FP-Network) for which the privileged sequence is not observable, but is equipped with a novel PK-Simulator that distills PK learned from the previous network. This simulator takes as input the observed sequence, but approximates the behavior of Priv-Encoder, enabling FP-Network to imitate the interpolation process. Extensive experimental results demonstrate that our prediction pattern achieves state-of-the-art performance on benchmarked H3.6M, CMU-Mocap and 3DPW datasets in both short-term and long-term predictions.
2. Introduction
- 领域:
- Human motion prediction
- 之前的方法:
- GCN-based
- RNN-based
- 之前方法:
- 会有错误累计的问题。
- 通常会收敛到静态平均姿势。
- 这些模型通常都是通过一段历史序列去预测另一段序列。
- 作者的方法:
- 将预测序列的未来序列加入模型中,为预测序列在提供一种先验。
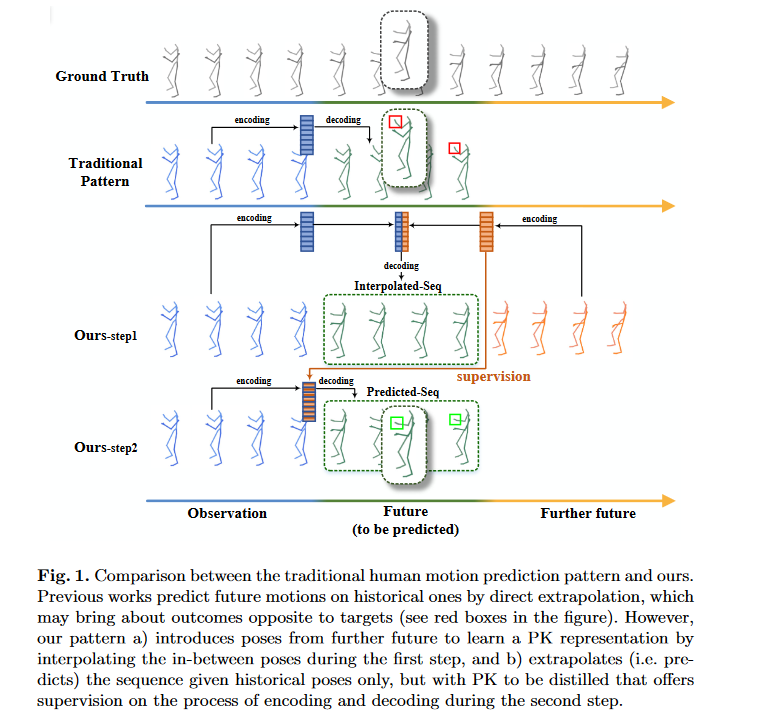
Fig.1
Source: https://arxiv.org/abs/2208.01302v1
Fig.1展示了作者模型的大致流程,分为两个过程:
InTerPolation learning Network(ITP-Network)Final Prediction Network(FP-Network)
整个网络模型是基于GCN的。
3. Proposed Method
定义:
\(X_{1:N}=[x_1,x_2,...,x_N]\):表示历史动作序列
\(X_{N+1:N+T}\):待预测的动作序列
\(X_{N+T+1:N+T+P}\):privileged sequence,也就是待预测序列的未来序列。
网络结构如Fig.2
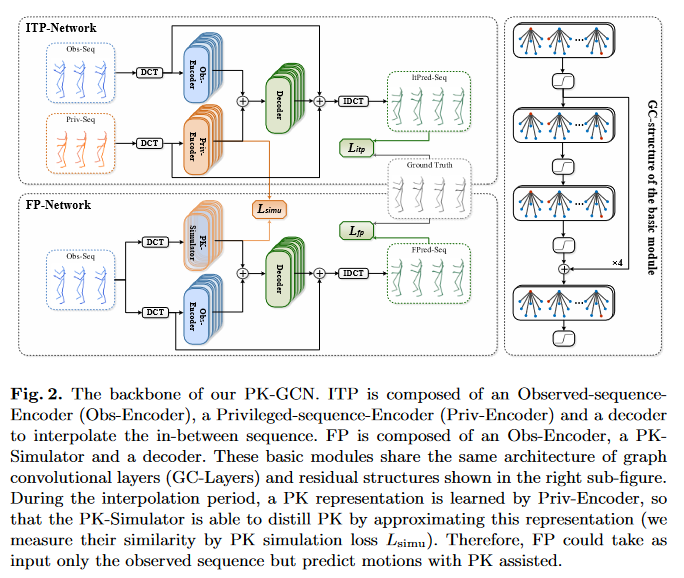
Fig.2. Network architecture
Source: https://arxiv.org/abs/2208.01302v1
3.1. Spatio-Temporal Encoding
作者使用一个全连接图来表示人体骨架结构,该图有\(K\)个\(node\), 用领接矩阵\(A \in \mathbb{R}^{K\times K}\) 来表示图中的边信息。
点信息:\(H^{(l)} \in \mathbb{R}^{K\times F^{(l)}}\)
权重矩阵:\(W^{(l)} \in \mathbb{R}^{F^{(l)}\times F^{(l+1)}}\)
将点信息喂入GCN-layer中,得到下一层的点信息。表达式如下:
3.2. Network Structure
The InterPolation learning Network
组成部分:
Obs-EncoderPriv-Encoder
分别对历史序列和privileged sequence进行编码,这里有一个残差连接。这两部分的残差连接比例为\(0.7:0.3\) 。
The Final Prediction Network(FP-network)
组成部分:
obs-Encoder:观测序列取与训练阶段相同时间步长的动作序列\(N+T+P\)PK-Simulator:用于训练得到的Priv-Encoder
3.3. Training
损失函数:
Mean Per Joint Position ErrorMean Angle Error
4. 总结
以往的文章只是利用历史序列,而该文章将预测序列的未来序列当做一直先验加入预测当中。利用GCN-based模型进行训练。
感觉这种方法结构不会优于使用Transformer-based模型
标签:KnowledgeForHumanMotionPrediction,Distilling,sequence,Sun,prediction,Encoder,序列, From: https://www.cnblogs.com/guixu/p/16867141.html